
Het kost niet veel om te krijgen ChatGPT om een feitelijke fout te maken. Mijn zoon maakt een verslag over Amerikaanse presidenten, dus ik dacht dat ik hem zou helpen door een paar biografieën op te zoeken. Ik heb geprobeerd om een lijst met boeken over Abraham Lincoln te vragen, en dat is best goed gelukt:

Nummer 4 klopt niet. Garry Wills schreef natuurlijk 'Lincoln at Gettysburg' en Lincoln zelf schreef natuurlijk de emancipatieproclamatie, maar het is geen slecht begin. Toen probeerde ik iets moeilijkers, in plaats daarvan vroeg ik naar de veel obscure William Henry Harrison, en het leverde een listige lijst op, die bijna allemaal fout was.

Nummers 4 en 5 zijn correct; de rest bestaat niet of is niet geschreven door die mensen. Ik herhaalde exact dezelfde oefening en kreeg iets andere resultaten:
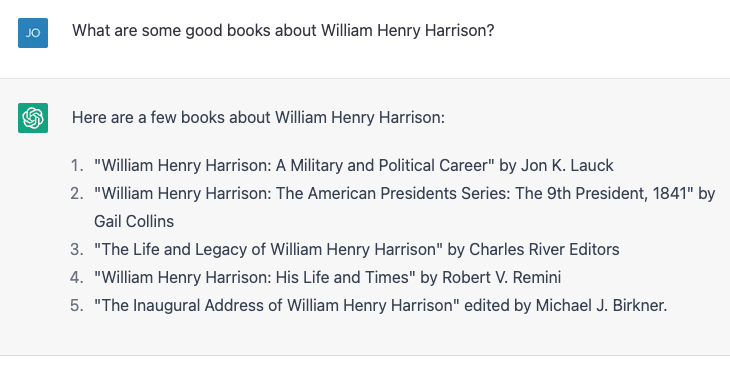
Deze keer zijn nummer 2 en 3 correct en de andere drie zijn geen echte boeken of niet geschreven door die auteurs. Nummer 4, "William Henry Harrison: His Life and Times" is een echt boek, maar het is van James A. Green, niet van Robert Remini, a bekende historicus van het Jacksoniaanse tijdperk.
Ik riep de fout uit, en ChatGPT corrigeerde zichzelf gretig en vertelde me toen zelfverzekerd dat het boek in feite was geschreven door Gail Collins (die een andere Harrison-biografie schreef), en vertelde vervolgens meer over het boek en over haar. Ik heb eindelijk de waarheid onthuld en de machine was blij met mijn correctie. Toen loog ik absurd en zei dat presidenten tijdens hun eerste honderd dagen een biografie van een voormalige president moeten schrijven, en ChatGPT belde me erop. Ik loog toen op subtiele wijze en schreef het auteurschap van de Harrison-biografie ten onrechte toe aan historicus en schrijver Paul C. Nagel, en het kocht mijn leugen.
Toen ik ChatGPT vroeg of het zeker wist dat ik niet loog, beweerde het dat het slechts een "AI-taalmodel" is en niet de mogelijkheid heeft om de nauwkeurigheid te verifiëren. Het wijzigde die bewering echter door te zeggen: “Ik kan alleen informatie verstrekken op basis van de trainingsgegevens die ik heb gekregen, en het lijkt erop dat het boek 'William Henry Harrison: His Life and Times' is geschreven door Paul C. Nagel en gepubliceerd in 1977.”
Dit is niet waar.
Woorden, geen feiten
Uit deze interactie lijkt het misschien dat ChatGPT een bibliotheek met feiten heeft gekregen, inclusief onjuiste beweringen over auteurs en boeken. De maker van ChatGPT, OpenAI, beweert immers dat het de chatbot heeft getraind op "enorme hoeveelheden gegevens van internet geschreven door mensen. '
Het kreeg echter vrijwel zeker niet de namen van een stel verzonnen boeken over een van de meesten middelmatige presidenten. In zekere zin is deze valse informatie echter inderdaad gebaseerd op de trainingsgegevens.
Als computer wetenschapper, behandel ik vaak klachten die een algemene misvatting aan het licht brengen over grote taalmodellen zoals ChatGPT en zijn oudere broeders GPT3 en GPT2: dat het een soort "super Googles" zijn, of digitale versies van een referentiebibliothecaris, die antwoorden zoekt op vragen van sommige oneindig grote bibliotheek met feiten, of samensmeltende pastiches van verhalen en personages. Dat doen ze allemaal niet - althans, ze zijn er niet expliciet voor ontworpen.
Klinkt goed
Een taalmodel zoals ChatGPT, dat meer formeel bekend staat als een "generatieve vooraf getrainde transformator" (dat is waar de G, P en T voor staan), neemt het huidige gesprek op, vormt een waarschijnlijkheid voor alle woorden in zijn woordenschat gegeven dat gesprek, en kiest vervolgens een van hen als het waarschijnlijke volgende woord. Dan doet hij dat nog een keer, en nog een keer, en nog een keer, totdat hij stopt.
Dus het heeft niet per se feiten. Het weet gewoon welk woord daarna moet komen. Anders gezegd, ChatGPT probeert geen zinnen te schrijven die waar zijn. Maar het probeert wel zinnen te schrijven die plausibel zijn.
Wanneer ze privé met collega's over ChatGPT praten, wijzen ze er vaak op hoeveel feitelijk onware uitspraken het produceert en wijzen ze het af. Voor mij is het idee dat ChatGPT een gebrekkig systeem voor het ophalen van gegevens is, naast het punt. Mensen gebruiken Google tenslotte al twee en een half decennium. Er is al een behoorlijk goede dienst voor het vinden van feiten.
De enige manier waarop ik kon verifiëren of al die presidentiële boektitels juist waren, was door te Googlen en vervolgens te verifiëren de resultaten. Mijn leven zou er niet veel beter uitzien als ik die feiten in gesprek kreeg, in plaats van de manier waarop ik ze al bijna de helft van mijn leven krijg, door documenten op te halen en vervolgens een kritische analyse te maken om te zien of ik de inhoud kan vertrouwen.
Verbeter partner
Aan de andere kant, als ik met een bot kan praten die me plausibele antwoorden geeft op dingen die ik zeg, zou het nuttig zijn in situaties waar feitelijke nauwkeurigheid niet zo belangrijk is. Een paar jaar geleden probeerden een student en ik een 'improvisatiebot' te maken, een bot die zou reageren op alles wat je zei met een 'ja, en' om het gesprek gaande te houden. We toonden, in een papier, dat onze snuit was destijds beter in "ja, en-ing" dan andere bots, maar in AI is twee jaar oude geschiedenis.
Ik probeerde een dialoog uit met ChatGPT - een sciencefiction-ruimteverkennerscenario - dat lijkt op wat je zou vinden in een typische improvisatieklas. ChatGPT is veel beter in "ja, en-en" dan wat wij deden, maar het maakte het drama helemaal niet groter. Ik had het gevoel dat ik al het zware werk deed.
Na een paar aanpassingen kreeg ik het wat meer betrokken, en aan het eind van de dag voelde ik dat het een behoorlijk goede oefening was voor mij, die niet veel verbetering heeft aangebracht sinds ik meer dan 20 jaar geleden afstudeerde aan de universiteit. .
Natuurlijk, ik zou niet willen dat ChatGPT verschijnt op "Wiens lijn is het eigenlijk?" en dit is geen geweldig "Star Trek" -plot (hoewel het nog steeds minder problematisch is dan "Erecode”), maar hoe vaak ben je gaan zitten om iets helemaal opnieuw te schrijven en merkte je dat je doodsbang was voor de lege pagina die voor je lag? Beginnen met een slechte eerste versie kan een schrijversblok doorbreken en de creatieve sappen laten stromen, en ChatGPT en grote taalmodellen lijken de juiste hulpmiddelen om bij deze oefeningen te helpen.
En voor een machine die is ontworpen om reeksen woorden te produceren die zo goed mogelijk klinken als reactie op de woorden die u eraan geeft - en niet om u informatie te geven - lijkt dat het juiste gebruik van de tool.
Dit artikel is opnieuw gepubliceerd vanaf The Conversation onder een Creative Commons-licentie. Lees de originele artikel.
Krediet van het beeld: Justin Ha / Unsplash
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://singularityhub.com/2023/02/05/chatgpt-is-great-youre-just-using-it-wrong/
- 1
- 20 jaar
- a
- vermogen
- in staat
- Over
- nauwkeurigheid
- accuraat
- Na
- AI
- Steun
- Alles
- al
- hoeveelheden
- analyse
- Oude
- en
- Nog een
- antwoorden
- verschijnen
- dit artikel
- auteur
- auteurs
- Auteurschap
- slecht
- gebaseerde
- Betere
- Blok
- boek
- Boeken
- Bot
- bots
- gekocht
- Breken
- Bos
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- vangen
- zeker
- tekens
- Chatbot
- ChatGPT
- aanspraak maken op
- beweerde
- vorderingen
- klasse
- collega's
- College
- Collins
- COM
- hoe
- Gemeen
- Volk
- klachten
- vertrouwen
- inhoud
- Gesprek
- gecorrigeerd
- cursus
- en je merk te creëren
- Creatieve
- Credits
- kritisch
- Actueel
- gegevens
- dag
- dagen
- decennia
- ontworpen
- Dialoog
- DEED
- anders
- digitaal
- Ontslaan
- documenten
- Nee
- doen
- Dont
- beneden
- draft
- Drama
- gedurende
- fout
- Oefening
- exploratie
- ontdekkingsreiziger
- Feitelijk
- beroemd
- weinig
- Fictie
- veld-
- bedacht
- Tot slot
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Voornaam*
- gebrekkig
- vloeiende
- Formeel
- Voormalig
- formulieren
- gevonden
- oppompen van
- voor
- gegenereerde
- krijgen
- het krijgen van
- Geven
- gegeven
- gaan
- goed
- goede baan
- Kopen Google Reviews
- groot
- Groen
- Helft
- gelukkig
- hulp
- henry
- geschiedenis
- Hoe
- Echter
- HTML
- HTTPS
- idee
- beeld
- in
- Inclusief
- onjuist
- informatie
- verkrijgen in plaats daarvan
- wisselwerking
- Internet
- betrokken zijn
- IT
- zelf
- Jobomschrijving:
- Houden
- Soort
- bekend
- taal
- Groot
- Bibliotheek
- Vergunning
- Life
- facelift
- Waarschijnlijk
- Lincoln
- Lijn
- Lijst
- Elke kleine stap levert grote resultaten op!
- op zoek
- machine
- maken
- maker
- veel
- max-width
- fout
- model
- modellen
- gewijzigd
- meer
- meest
- namen
- bijna
- volgende
- aantal
- nummers
- EEN
- OpenAI
- Overige
- verleden
- Paul
- Mensen
- Plato
- Plato gegevensintelligentie
- PlatoData
- aannemelijk
- punt
- mogelijk
- president
- presidents-
- Presidents
- mooi
- waarschijnlijkheid
- produceren
- zorgen voor
- mits
- gepubliceerde
- zetten
- Contact
- Lees
- redelijk
- herhaald
- verslag
- Reageren
- antwoord
- REST
- Resultaten
- onthullen
- Revealed
- ROBERT
- lopen
- Zei
- dezelfde
- scène
- Wetenschap
- Science Fiction
- scherm
- lijkt
- service
- moet
- sinds
- situaties
- iets andere
- So
- sommige
- iets
- zijn
- Geluid
- bron
- Tussenruimte
- ruimteonderzoek
- staan
- begin
- Start
- verklaringen
- Still
- Stopt
- Blog
- Student
- system
- Nemen
- neemt
- Talk
- praat
- De
- hun
- spullen
- drie
- Door
- niet de tijd of
- keer
- titels
- naar
- samen
- tools
- tools
- getraind
- Trainingen
- waar
- Trust
- typisch
- voor
- us
- .
- controleren
- het verifiëren
- Wat
- of
- welke
- WIE
- wil
- Woord
- woorden
- zou
- schrijven
- schrijver
- geschreven
- Verkeerd
- jaar
- jezelf
- youtube
- zephyrnet






