Robolayer. Krediet: halverwege de reis
Als je mijn werk leest, weet je waarschijnlijk dat ik mijn artikelen in de eerste plaats publiceer in mijn AI-nieuwsbrief, De Algoritmische Brug. Wat je misschien niet weet, is dat ik elke zondag een speciale column publiceer die ik 'wat je misschien hebt gemist' noem, waarin ik alles bekijk wat er in de loop van de week is gebeurd met analyses die je helpen het nieuws te begrijpen.
Microsoft-OpenAI $ 10 miljard deal
meldde Semafor twee weken geleden dat, als alles volgens plan verloopt, Microsoft voor eind januari een investeringsovereenkomst van $ 10 miljard met OpenAI zal sluiten (Satya Nadella, CEO van Microsoft, kondigde de uitgebreid partnerschap officieel op maandag).
Er is enige verkeerde informatie over de deal geweest, wat impliceerde dat OpenAI-execs niet zeker waren van de levensvatbaarheid van het bedrijf op de lange termijn. Echter, het werd later opgehelderd dat de deal er zo uitziet:
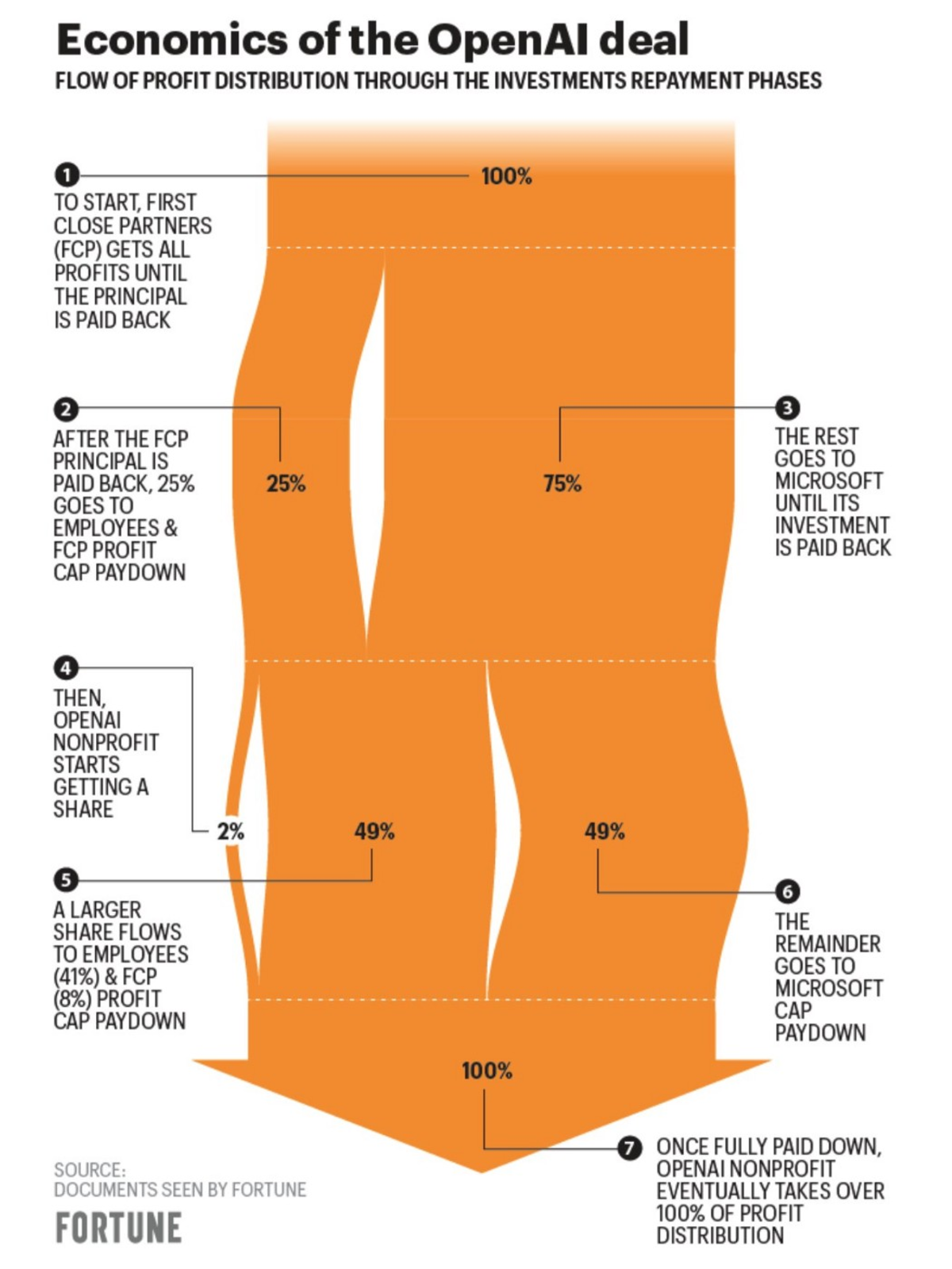
credit: Fortuin
Leo L'Orange, die The Neuron schrijft, legt uit dat "zodra $ 92 miljard aan winst plus $ 13 miljard aan initiële investering is terugbetaald aan Microsoft en zodra de andere venture-investeerders $ 150 miljard verdienen, keert al het eigen vermogen terug naar OpenAI."
Mensen zijn verdeeld. Sommigen zeggen dat de deal "cool" of "interessant" is, terwijl anderen zeggen dat het "vreemd" en "gek" is. Wat ik waarneem met mijn niet-expertogen is dat OpenAI en Sam Altman do vertrouwen (sommigen zouden zeggen oververtrouwen) het vermogen van het bedrijf om op lange termijn zijn doelen te bereiken.
Echter, als Will Knight schrijft voor WIRED: "het is onduidelijk welke producten op de technologie kunnen worden gebouwd." OpenAI moet snel een levensvatbaar bedrijfsmodel bedenken.
Wijzigingen in ChatGPT: nieuwe functies en het genereren van inkomsten
OpenAI heeft ChatGPT bijgewerkt op 9 jan (van de vorige update op 15 dec). Nu heeft de chatbot "verbeterde feitelijkheid" en kun je hem halverwege de generatie stoppen.
Ze werken ook aan een "professionele versie van ChatGPT" (waarvan het gerucht gaat dat ze uitkomen op $ 42 / maand) als voorzitter van OpenAI Greg Brockman aangekondigd op 11 januari. Dit zijn de drie belangrijkste kenmerken:
“Altijd beschikbaar (geen verduisterende ramen).
Snelle reacties van ChatGPT (dus geen throttling).
Zoveel berichten als je nodig hebt (minstens 2x de normale dagelijkse limiet).”
Om je aan te melden voor de wachtlijst moet je wel een formulier invullen waar ze je onder andere vragen hoeveel je zou willen betalen (en hoeveel te veel zou zijn).
Als u van plan bent het serieus te nemen, kunt u overwegen diep in de productstapel van OpenAI te duiken met de OpenAI-kookboekrepository. Bojan Tunguz zei dat het "de meest populaire opslagplaats op GitHub deze maand.” Altijd een goed teken.
ChatGPT, de nepwetenschapper
ChatGPT is het wetenschappelijke domein binnengetreden. Kareem Carr plaatste donderdag een screenshot van een paper waarvan ChatGPT co-auteur is.
Maar waarom, gezien het feit dat ChatGPT een tool is? “Mensen beginnen ChatGPT te behandelen alsof het een bonafide, goed onderbouwde wetenschapper is medewerker”, legt Gary Marcus uit in een Substack-post. "Wetenschappers, laat uw chatbots alsjeblieft niet uitgroeien tot coauteurs", pleit hij.
Zorgwekkender zijn die gevallen waarin het gebruik van AI niet wordt bekendgemaakt. Wetenschappers heb gevonden dat ze samenvattingen geschreven door ChatGPT niet op betrouwbare wijze kunnen identificeren - de welsprekende onzin houdt zelfs experts in hun vakgebied voor de gek. Zoals Sandra Wachter, die "technologie en regelgeving studeert" aan Oxford, tegen Holly Else zei een stuk over de natuur:
"Als we ons nu in een situatie bevinden waarin de experts niet kunnen bepalen wat waar is of niet, verliezen we de tussenpersoon die we hard nodig hebben om ons door ingewikkelde onderwerpen te loodsen."
ChatGPT's uitdaging voor het onderwijs
ChatGPT is verboden in onderwijscentra over de hele wereld (bijv Openbare scholen in New York, Australische universiteiten en Britse docenten ben erover aan het nadenken). Zoals ik betoogde een eerder essay, Ik denk niet dat dit de verstandigste beslissing is, maar slechts een reactie omdat we niet voorbereid zijn op de snelle ontwikkeling van generatieve AI.
Kevin Roose van NYT argumenteert dat "[ChatGPT's] potentieel als educatief hulpmiddel opweegt tegen de risico's." Terence Tao, de grote wiskundige, eens: “Op de lange termijn lijkt het zinloos om hiertegen te vechten; misschien moeten we als docenten overstappen op een 'open boeken, open AI'-examenmethode.'
Jaden stampers, de belangrijkste ethicus bij Hugging Face, legt de uitdaging uit waarmee scholen worden geconfronteerd met ChatGPT:
“Helaas lijkt het onderwijssysteem gedwongen zich aan te passen aan deze nieuwe technologieën. Ik denk dat het een begrijpelijke reactie is, aangezien er niet veel is gedaan om te anticiperen, te verzachten of alternatieve oplossingen uit te werken om de mogelijk resulterende problemen te schetsen. Ontwrichtende technologieën vereisen vaak educatie van gebruikers, omdat ze niet zomaar ongecontroleerd naar mensen kunnen worden geslingerd.”
Die laatste zin geeft perfect weer waar het probleem zich voordoet en de mogelijke oplossing ligt. We moeten ons extra inspannen om gebruikers te informeren over hoe deze technologie werkt en wat er wel en niet mee te doen is. Dat is de benadering die Catalonië heeft gevolgd. Als Francesc Bracero en Carina Farreras doen verslag voor La Vanguardia:
“In Catalonië gaat het ministerie van Onderwijs het niet verbieden 'in het hele systeem en voor iedereen, aangezien dit een ineffectieve maatregel zou zijn'. Volgens bronnen van het ministerie kun je de centra beter vragen om voorlichting te geven over het gebruik van AI, 'dat kan veel kennis en voordelen opleveren'.”
De beste vriend van de student: een database met ChatGPT-fouten
Gary Marcus en Ernest Davis hebben een “fout tracker” om de fouten vast te leggen en te classificeren die taalmodellen zoals ChatGPT maken (hier is meer info over waarom ze dit document samenstellen en wat ze ermee van plan zijn).
De database is openbaar en iedereen kan meedoen. Het is een geweldige bron die een grondige studie mogelijk maakt van hoe deze modellen zich misdragen en hoe mensen misbruik kunnen voorkomen. Hier is een hilarisch voorbeeld van waarom dit ertoe doet:
OpenAI is zich hiervan bewust en wil mis- en desinformatie tegengaan: “Voorspelling van mogelijk misbruik van taalmodellen voor desinformatiecampagnes - en hoe u risico's kunt verkleinen. '
Nieuwe informatie
liet Sam Altman doorschemeren bij een vertraging in de release van GPT-4 in een gesprek met Conny Loizos, de Silicon Valley-editor bij TechCrunch. Altman zei dat “we over het algemeen technologie veel langzamer gaan vrijgeven dan mensen zouden willen. We gaan er nog veel langer op zitten…” Dit is mijn mening:
(Altman zei ook dat er een videomodel in de maak is!)
Verkeerde informatie over GPT-4
Er is een "GPT-4 = 100T"-claim die overal op sociale media viraal gaat (ik heb het vooral gezien op Twitter en LinkedIn). Mocht je het nog niet gezien hebben, het ziet er zo uit:
Of dit:
Het zijn allemaal enigszins verschillende versies van hetzelfde: een aantrekkelijke visuele grafiek die de aandacht trekt, en een sterke hook met de GPT-4/GPT-3-vergelijking (ze gebruiken GPT-3 als een proxy voor ChatGPT).
Ik denk dat het goed is om geruchten en speculaties te delen en ze als zodanig in te kaderen (Ik voel me hier mede verantwoordelijk voor), maar het plaatsen van niet-verifieerbare informatie met een gezaghebbende toon en zonder referenties is laakbaar.
Mensen die dit doen, zijn niet ver van net zo nutteloos en gevaarlijk als ChatGPT als informatiebron - en met veel sterkere prikkels om het te blijven doen. Pas hiervoor op, want het zal in de toekomst elk informatiekanaal over AI vervuilen.
Een robotadvocaat
Joshua Browder, CEO van DoNotPay, plaatste dit op 9 januari:
Omdat het niet anders kon, ontstond deze gewaagde claim veel discussie tot het punt dat Twitter de tweet nu markeert met een link naar de Pagina van het Hooggerechtshof met verboden items.
Zelfs als ze het om juridische redenen uiteindelijk niet kunnen doen, is het de moeite waard om de vraag vanuit een ethisch en sociaal standpunt te bekijken. Wat gebeurt er als het AI-systeem een ernstige fout maakt? Zou kunnen mensen zonder toegang een advocaat profiteren van een volwassen versie van deze technologie?
De rechtszaak tegen Stable Diffusion is begonnen
Matthew Boterik publiceerde dit op 13 januari:
“Namens drie prachtige eisers van kunstenaars - Sara Andersen, Kelly McKernan en Karla Ortiz - we hebben een class action-rechtszaak aangespannen tegen Stabiliteit AI, DeviantArt en Halverwege de reis voor hun gebruik van Stabiele verspreiding, een 21e-eeuwse collagetool die de auteursrechtelijk beschermde werken remixt van miljoenen kunstenaars wiens werk werd gebruikt als trainingsgegevens.
Het begint — de eerste stappen in wat een lang gevecht belooft te worden om de training en het gebruik van generatieve AI te matigen. Ik ben het eens met de motivatie: "AI moet eerlijk en ethisch zijn voor iedereen."
Maar zoals vele anderen, Ik heb onnauwkeurigheden gevonden in de blogpost. Het gaat diep in op de technische details van Stable Diffusion, maar slaagt er niet in om sommige stukjes correct uit te leggen. Of dit opzettelijk is om de technische kloof te overbruggen voor mensen die niet weten - en geen tijd hebben om te leren - hoe deze technologie werkt (of als een middel om de technologie te karakteriseren op een manier die hen ten goede komt) ) of een fout staat open voor speculatie.
Zei ik in een vorig artikel dat op dit moment de botsing tussen AI-kunst en traditionele kunstenaars sterk emotioneel is. De reacties op deze rechtszaak zullen niet anders zijn. We zullen moeten wachten tot de jury de uitkomst beslist.
CNET publiceert door AI gegenereerde artikelen
Het futurisme meldde dit een paar weken geleden:
"CNET, een enorm populair nieuwscentrum voor technologie, gebruikt stilletjes de hulp van "automatiseringstechnologie" - een stilistisch eufemisme voor AI - voor een nieuwe golf van financiële uitlegartikelen.
Gael Breton, die dit voor het eerst zag, schreef vrijdag een diepere analyse. Hij legt uit dat Google het verkeer naar deze berichten niet lijkt te belemmeren. "Is AI-inhoud nu in orde?" hij vraagt.
Ik vind het de beslissing van CNET om het gebruik van AI volledig bekend te maken in hun artikelen een goed precedent. Hoeveel mensen publiceren op dit moment inhoud met behulp van AI zonder deze openbaar te maken? De consequentie is echter dat mensen hun baan kunnen verliezen als dit lukt (zoals ik, en vele anderen, voorspeld). Het gebeurt al:
Ik ben het volledig eens met deze tweet van Santiago:
RLHF voor het genereren van afbeeldingen
Als versterkend leren door menselijke feedback werkt voor taalmodellen, waarom dan niet voor tekst-naar-beeld? Dat is wat PickaPic probeert te bereiken.
De demo is voor onderzoeksdoeleinden, maar kan een interessante toevoeging zijn aan Stable Diffusion of DALL-E (Midjourney doet iets soortgelijks - ze begeleiden het model intern om mooie en artistieke beelden te produceren).
Een recept om "Siri/Alexa 10x beter te maken"
Recepten die verschillende generatieve AI-modellen combineren om iets beters te creëren dan de som der delen:
Albert Romero is een freelance schrijver die zich richt op technologie en AI. Hij schrijft De Algoritmische Brug, een nieuwsbrief die niet-technische mensen helpt nieuws en evenementen over AI te begrijpen. Hij is ook technisch analist bij CambrianAI, waar hij gespecialiseerd is in grote taalmodellen.
ORIGINELE. Met toestemming opnieuw gepost.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/02/chatgpt-gpt4-generative-ai-news.html?utm_source=rss&utm_medium=rss&utm_campaign=chatgpt-gpt-4-and-more-generative-ai-news
- 11
- 7
- 9
- a
- vermogen
- in staat
- Over
- over het
- samenvattingen
- Volgens
- Bereiken
- over
- aanpassen
- toevoeging
- voordelen
- tegen
- AI
- ai kunst
- algoritmische
- Alles
- toestaat
- al
- alternatief
- altijd
- onder
- analyse
- analist
- en
- aangekondigd
- anticiperen
- iedereen
- aantrekkelijk
- nadering
- Kunst
- artikelen
- artistiek
- Kunstenaars
- aandacht
- Beschikbaar
- terug
- verboden
- prachtige
- omdat
- vaardigheden
- wezen
- voordeel
- betekent
- BEST
- Betere
- tussen
- Oppassen
- Miljard
- Blog
- pin
- Boeken
- BRUG
- bebouwd
- bedrijfsdeskundigen
- bedrijfsmodel
- Bellen
- Campagnes
- kan niet
- vangen
- captures
- geval
- gevallen
- Centra
- ceo
- uitdagen
- Kanaal
- karakteriseren
- Chatbot
- chatbots
- ChatGPT
- aanspraak maken op
- Botsing
- classificeren
- Sluiten
- CNET
- Co-auteur
- Kolom
- COM
- Bedrijf
- vergelijking
- ingewikkeld
- Overwegen
- aangezien
- content
- Gesprek
- kon
- Koppel
- Rechtbank
- en je merk te creëren
- Credits
- dagelijks
- van dall
- gevaarlijk
- gegevens
- Database
- Davis
- transactie
- beslissing
- deep
- diepere
- vertraging
- Vraag
- afdeling
- Bepalen
- Ontwikkeling
- anders
- Verspreiding
- Openbaren
- openbaarmaking
- onthulling
- disinformatie
- verstorend
- Verdeeld
- document
- Nee
- doen
- domein
- Dont
- gedurende
- verdienen
- editor
- opvoeden
- Onderwijs
- onderwijs
- inspanning
- uitwerken
- ingevoerd
- Geheel
- billijkheid
- fouten
- Ether (ETH)
- ethisch
- Zelfs
- EVENTS
- Alle
- iedereen
- alles
- voorbeeld
- execs
- deskundigen
- Verklaren
- Verklaart
- extra
- Ogen
- Gezicht
- mislukt
- eerlijk
- nep
- SNELLE
- Voordelen
- feedback
- veld-
- vechten
- Figuur
- Tot slot
- financieel
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Voornaam*
- eerste stappen
- vlaggen
- richt
- vooral
- Naar voren
- gevonden
- freelance
- vriend
- oppompen van
- geheel
- kloof
- Gary
- Algemeen
- generatief
- generatieve AI
- GitHub
- gegeven
- wereldbol
- Go
- Doelen
- Goes
- gaan
- goed
- Kopen Google Reviews
- diagram
- groot
- Groeien
- gids
- gebeurd
- gebeurt
- hulp
- helpt
- hilarisch
- Hoe
- How To
- Echter
- HTML
- HTTPS
- menselijk
- identificeren
- beeld
- afbeeldingen
- impliciete
- in
- Incentives
- info
- informatie
- eerste
- Opzettelijk
- interessant
- inwendig
- investering
- Investeerders
- IT
- jan
- Januari
- Vacatures
- KDnuggets
- Houden
- Ridder
- blijven
- kennis
- taal
- Groot
- Achternaam*
- proces
- advocaat
- LEARN
- leren
- Juridisch
- LIMIT
- LINK
- lang
- langdurig
- LOOKS
- verliezen
- lot
- Hoofd
- maken
- MERKEN
- veel
- veel mensen
- Marcus
- massief
- Zaken
- volwassen
- middel
- maatregel
- Media
- Medium
- alleen
- berichten
- Microsoft
- Halverwege de reis
- ministerie
- Desinformatie
- fout
- Verzachten
- Mode
- model
- modellen
- maandag
- meer
- Motivatie
- beweging
- NATUUR
- Noodzaak
- behoeften
- New
- Nieuwe mogelijkheden
- Nieuwe technologieën
- nieuws
- Nieuws en evenementen
- Nieuwsbrief
- niet-technische
- Officieel
- Okay
- open
- OpenAI
- Overige
- Overig
- anders-
- Resultaat
- Oxford
- Papier
- deelnemen
- onderdelen
- Betaal
- Mensen
- misschien
- toestemming
- stuk
- plan
- Plato
- Plato gegevensintelligentie
- PlatoData
- pleit
- dan
- plus
- punt
- Populair
- mogelijk
- Post
- geplaatst
- Berichten
- potentieel
- Precedent
- vorig
- Principal
- waarschijnlijk
- probleem
- problemen
- Product
- Producten
- Profit
- verbieden
- Beloften
- zorgen voor
- volmacht
- publiek
- publiceren
- Reclame
- doeleinden
- vraag
- rustig
- reactie
- Lees
- redenen
- recept
- verminderen
- referenties
- regelmatig
- versterking van leren
- los
- onderzoek
- hulpbron
- verantwoordelijk
- verkregen
- beoordelen
- streng
- risico's
- robot
- Geruchten
- Zei
- Sam
- dezelfde
- Satya Nadella
- scholen
- lijkt
- seinpaal
- zin
- zin
- ernstig
- reeks
- delen
- moet
- teken
- Silicium
- Silicon Valley
- gelijk
- eenvoudigweg
- sinds
- situatie
- iets andere
- Langzaam
- Social
- social media
- oplossing
- Oplossingen
- sommige
- iets
- Spoedig
- bronnen
- special
- specialiseert
- speculatie
- stabiel
- stack
- Start
- Stappen
- stop
- sterke
- sterker
- sterk
- Studie
- dergelijk
- system
- Nemen
- tech
- tech news
- TechCrunch
- Technisch
- Technologies
- Technologie
- De
- hun
- ding
- spullen
- het denken
- drie
- Door
- niet de tijd of
- naar
- TONE
- ook
- tools
- top
- onderwerpen
- traditioneel
- verkeer
- Trainingen
- behandelen
- trending
- waar
- Trust
- tweet
- X
- typeform
- begrijpelijk
- bijwerken
- bijgewerkt
- us
- .
- Gebruiker
- gebruikers
- Vallei
- onderneming
- versie
- levensvatbaarheid
- rendabel
- Video
- wachten
- Wave
- week
- weken
- Wat
- of
- welke
- WIE
- wil
- gewillig
- ruiten
- zonder
- Mijn werk
- werkzaam
- Bedrijven
- waard
- zou
- schrijver
- geschreven
- Your
- zephyrnet