Welkom in het datatijdperk. De enorme hoeveelheid gegevens die dagelijks wordt vastgelegd, blijft groeien, waardoor platforms en oplossingen moeten evolueren. Diensten zoals Amazon eenvoudige opslagservice (Amazon S3) bieden een schaalbare oplossing die zich aanpast en toch kosteneffectief blijft voor groeiende datasets. De Amazon Sustainability Data Initiative (ASDI) maakt gebruik van de mogelijkheden van Amazon S3 om u een kosteloze oplossing te bieden voor het opslaan en delen van klimaatwetenschappelijke werklasten over de hele wereld. Met het Open Data Sponsorship Program van Amazon kunnen organisaties gratis hosten op AWS.
De afgelopen tien jaar hebben we een enorme toename van datawetenschapsframeworks tot wasdom zien komen, samen met een massale adoptie door de datawetenschapsgemeenschap. Eén zo’n raamwerk is Dashboard, dat krachtig is vanwege zijn vermogen om een orkestratie van computerknooppunten voor werknemers te bieden, waardoor complexe analyses van grote datasets worden versneld.
In dit bericht laten we u zien hoe u een custom AWS Cloud-ontwikkelingskit (AWS CDK) oplossing die de functionaliteit van Dask uitbreidt om interregionaal te werken binnen het wereldwijde netwerk van Amazon. De AWS CDK-oplossing zet een netwerk van Dask-werknemers in twee AWS-regio's in, die verbinding maken met een klantregio. Voor meer informatie, zie Richtlijnen voor gedistribueerd computergebruik met Cross Regional Dask op AWS en GitHub repo voor opensourcecode.
Na de implementatie heeft de gebruiker toegang tot een Jupyter-notebook, waar hij kan communiceren met twee datasets van ASDI op AWS: Gekoppeld modelintervergelijkingsproject 6 (CMIP6) en ECMWF ERA5 Heranalyse. CMIP6 richt zich op de zesde fase van het mondiale gekoppelde algemene circulatiemodel van de oceaan en de atmosfeer; ERA5 is de vijfde generatie ECMWF atmosferische heranalyses van het mondiale klimaat, en de eerste heranalyse die als operationele dienst wordt geproduceerd.
Deze oplossing is geïnspireerd op het werk met een belangrijke AWS-klant, de UK Met Office. Het Met Office werd opgericht in 1854 en is de nationale meteorologische dienst voor Groot-Brittannië. Ze bieden weer- en klimaatvoorspellingen om u te helpen betere beslissingen te nemen om veilig te blijven en te bloeien. Een samenwerking tussen het Met Office en EUMETSAT, gedetailleerd in Data Proximate Computation op een Dask-cluster verdeeld over datacentersbenadrukt de groeiende behoefte om een duurzame, efficiënte en schaalbare datawetenschapsoplossing te ontwikkelen. Deze oplossing bereikt dit door rekenkracht dichter bij de gegevens te brengen, in plaats van de gegevens te dwingen dichter bij de rekenbronnen te komen, wat kosten, latentie en energie met zich meebrengt.
Overzicht oplossingen
Elke dag produceert het Britse Met Office tot 300 TB aan weer- en klimaatgegevens, waarvan een deel wordt gepubliceerd naar ASDI. Deze datasets worden over de hele wereld gedistribueerd en gehost voor openbaar gebruik. Het Met Office wil consumenten in staat stellen meer uit hun gegevens te halen om kritische beslissingen te nemen over het aanpakken van kwesties zoals een betere voorbereiding op door klimaatverandering veroorzaakte bosbranden en overstromingen, en het verminderen van de voedselonzekerheid door betere analyse van de gewasopbrengsten.
Traditionele oplossingen die tegenwoordig worden gebruikt, vooral als het gaat om klimaatgegevens, zijn tijdrovend en niet duurzaam, omdat datasets over verschillende regio's heen worden gerepliceerd. Onnodige gegevensoverdracht op petabyteschaal is kostbaar, traag en verbruikt energie.
We schatten dat als deze praktijk door de Met Office-gebruikers zou worden overgenomen, het equivalent van het dagelijkse energieverbruik van 40 huishoudens elke dag zou kunnen worden bespaard, en dat ze ook de overdracht van gegevens tussen regio's zouden kunnen verminderen.
Het volgende diagram illustreert de oplossingsarchitectuur.
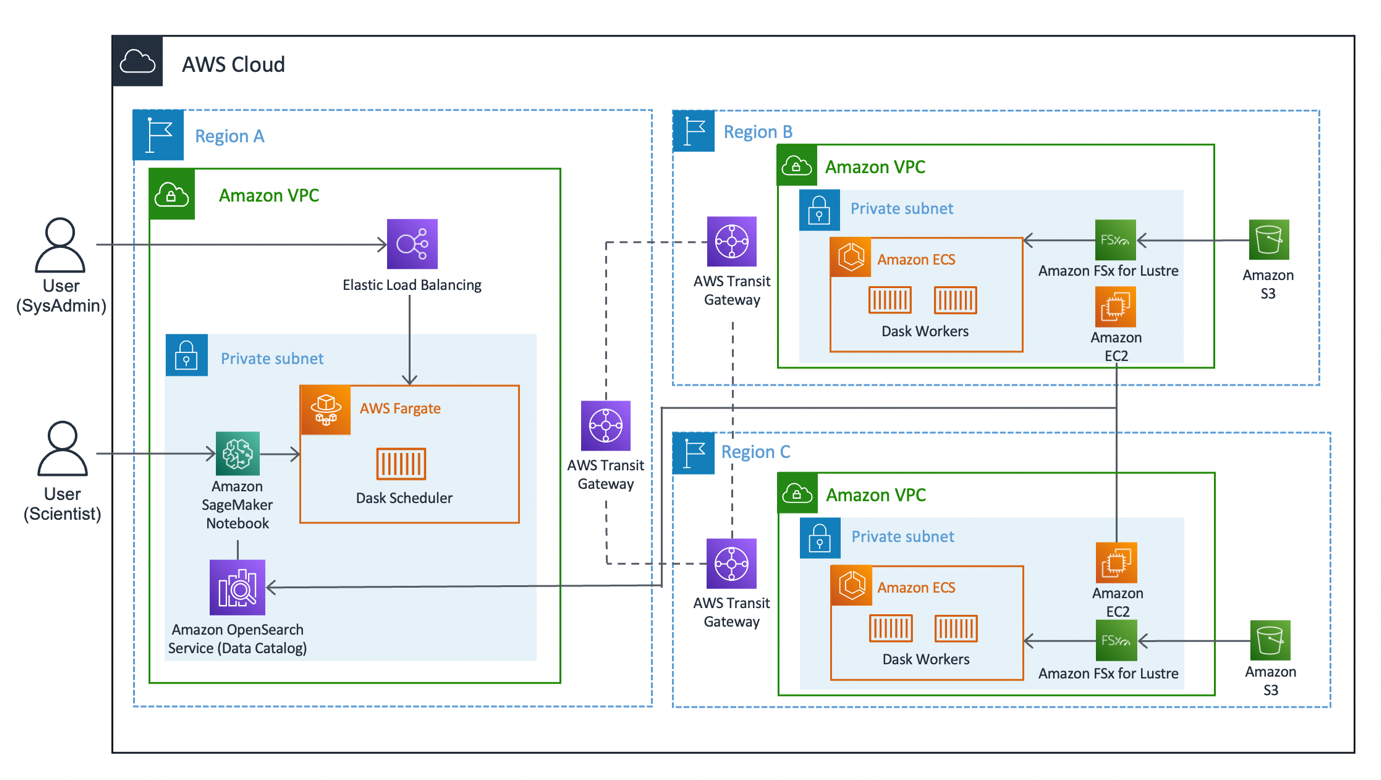
De oplossing kan worden onderverdeeld in drie hoofdsegmenten: klant, werknemers en netwerk. Laten we in elk ervan duiken en zien hoe ze samenkomen.
CLIËNT
De client vertegenwoordigt de bronregio waar datawetenschappers verbinding maken. Deze regio (regio A in het diagram) bevat een Amazon SageMaker-notebookeen Amazon OpenSearch-service domein, en een Dask-planner als sleutelcomponenten. Systeembeheerders hebben toegang tot het ingebouwde Dask-dashboard, toegankelijk via een Elastische Load Balancer.
Datawetenschappers hebben toegang tot de Jupyter-notebook die wordt gehost op SageMaker. De notebook kan verbinding maken en werklasten uitvoeren op de Dask-planner. Het OpenSearch Service-domein slaat metadata op over de datasets die zijn verbonden in de regio's. Notebook-gebruikers kunnen deze service opvragen om details op te halen, zoals de juiste Regio of Dask-werknemers, zonder dat ze vooraf de regionale locatie van de gegevens hoeven te kennen.
Arbeider
Elk van de werkerregio's (regio's B en C in het diagram) bestaat uit een Amazon Elastic Container-service (Amazon ECS) cluster van Dask-werkerseen Amazon FSx voor Luster bestandssysteem en een standalone Amazon Elastic Compute-cloud (Amazon EC2) exemplaar. Met FSx for Luster kunnen Dask-werknemers Amazon S3-gegevens openen en verwerken vanuit een krachtig bestandssysteem door uw bestandssystemen te koppelen aan S3-buckets. Het biedt latenties van minder dan een milliseconde, tot honderden GB/s aan doorvoer en miljoenen IOPS. Een belangrijk kenmerk van Lustre is dat alleen de metadata van het bestandssysteem worden gesynchroniseerd. Luster beheert het saldo van de bestanden die moeten worden geladen en warm gehouden, op basis van de vraag.
Werknemersclusters schalen op basis van CPU-gebruik, zorgen voor extra werknemers in langere perioden van vraag en schalen af als bronnen inactief worden.
Elke nacht om 0:00 UTC vraagt een gegevenssynchronisatietaak het Luster-bestandssysteem om opnieuw te synchroniseren met de gekoppelde S3-bucket, en haalt een up-to-date metadatacatalogus van de bucket op. Vervolgens pusht de zelfstandige EC2-instantie deze updates naar de OpenSearch Service, respectievelijk naar de index van die regio. OpenSearch Service biedt de klant de nodige informatie over welke pool van werknemers moet worden opgeroepen voor een bepaalde dataset.
Netwerk
Netwerken vormen de kern van deze oplossing, waarbij gebruik wordt gemaakt van het interne backbone-netwerk van Amazon. Door het gebruiken van AWS-transitgateway, kunnen we elk van de regio's met elkaar verbinden zonder dat we het openbare internet hoeven te gebruiken. Elk van de medewerkers kan dynamisch verbinding maken met de Dask-planner, waardoor datawetenschappers interregionale zoekopdrachten via Dask kunnen uitvoeren.
Voorwaarden
Het AWS CDK-pakket maakt gebruik van de programmeertaal TypeScript. Volg de stappen binnen Aan de slag voor AWS CDK om uw lokale omgeving in te stellen en uw ontwikkelingsaccount op te starten (u moet alle regio's opstarten die zijn opgegeven in de GitHub repo).
Voor een succesvolle implementatie heeft u het volgende nodig Docker geïnstalleerd en draait op uw lokale machine.
Implementeer het AWS CDK-pakket
Het implementeren van een AWS CDK-pakket is eenvoudig. Nadat u de vereisten hebt geïnstalleerd en uw account hebt opgestart, kunt u doorgaan met het downloaden van de codebasis.
- Download de GitHub-repository:
- Knooppuntmodules installeren:
- Implementeer de AWS CDK:
Het kan meer dan anderhalf uur duren voordat de stapel is geïmplementeerd.
Code doorloop
In deze sectie inspecteren we enkele van de belangrijkste kenmerken van de codebasis. Als u de volledige codebasis wilt inspecteren, raadpleegt u de GitHub-repository.
Configureer en pas uw stapel aan
In het bestand bin/variabelen.ts, vindt u twee variabele declaraties: één voor de klant en één voor werknemers. De clientdeclaratie is een woordenboek met een verwijzing naar een regio- en CIDR-bereik. Door deze variabelen aan te passen, verandert zowel het regio- als het CIDR-bereik waar clientbronnen worden ingezet.
De worker-variabele kopieert dezelfde functionaliteit; het is echter een lijst met woordenboeken waarin het toevoegen of verwijderen van datasets die de gebruiker wil opnemen, mogelijk is. Bovendien bevat elk woordenboek de toegevoegde velden van dataset en lustreFileSystemPath. Gegevensset wordt gebruikt om de verbindende S3-URI op te geven waarmee Luster verbinding kan maken. De lustreFileSystemPath variabele wordt gebruikt als een toewijzing voor hoe de gebruiker wil dat de gegevensset lokaal wordt toegewezen aan het werkbestandssysteem. Zie de volgende code:
Publiceer dynamisch het IP-adres van de planner
Een uitdaging die inherent was aan het interregionale karakter van dit project was het onderhouden van een dynamische verbinding tussen de Dask-werknemers en de planner. Hoe kunnen we een IP-adres publiceren dat kan veranderen, in alle AWS-regio's? Dit hebben wij kunnen realiseren door gebruik te maken van AWS Cloud-kaart en associeer-vpc-met-gehoste-zone. De service maakt het mogelijk dat AWS deze DNS-naamruimte privé kan beheren. Zie de volgende code:
Jupyter-notebookgebruikersinterface
De Jupyter-notebook die op SageMaker wordt gehost, biedt wetenschappers een kant-en-klare omgeving voor implementatie, zodat ze eenvoudig verbinding kunnen maken en kunnen experimenteren met de geladen datasets. Wij gebruikten een configuratiescript voor de levenscyclus om de notebook te voorzien van een vooraf geconfigureerde ontwikkelaarsomgeving en een voorbeeldcodebasis. Zie de volgende code:
Dask-werkerknooppunten
Als het om de Dask-workers gaat, is er meer aanpasbaarheid voorzien, meer specifiek op het gebied van instancetype, threads per container en schaalalarmen. Standaard worden de werkrollen ingericht op het instancetype m5d.4xlarge, bij het opstarten gekoppeld aan het Lustre-bestandssysteem en worden de werkrollen en threads dynamisch onderverdeeld in poorten. Dit alles is optioneel aanpasbaar. Zie de volgende code:
Performance
Om de prestaties te beoordelen, gebruiken we een voorbeeldberekening en plotten van de luchttemperatuur op 2 meter, gebaseerd op het verschil tussen de CMIP6-voorspelling voor een maand en de ERA5-gemiddelde luchttemperatuur voor 10 jaar. We hebben een benchmark van twee werknemers in elke regio vastgesteld en het verschil in tijdsbesparing beoordeeld naarmate er extra werknemers werden toegevoegd. In theorie zou er, naarmate de oplossing schaalt, een productief materieel verschil moeten zijn in het verminderen van de totale tijd.
De volgende tabel vat de details van onze dataset samen.
| dataset | Variabelen | Schijfgrootte | Grootte van Xarray-gegevensset | Regio |
| ERA5 | 2011–2020 (120 netcdf-bestanden) | 53.5GB | 364.1 GB | ons-oost-1 |
| CMIP6 | 1.13GB | 0.11 GB | ons-west-2 |
De volgende tabel toont de verzamelde resultaten, met de tijd (in seconden) voor elke berekening en voorspelling in drie fasen bij het berekenen van de CMIP6-voorspelling, ERA5 en het verschil.
| . | . | Aantal werknemers | |||
| Berekenen | Regio | 2(CMIP) + 2(ERA) | 2(CMIP) + 4(ERA) | 2(CMIP) + 8(ERA) |
2(CMIP) + 12(ERA) |
CMIP6 (predicted_tas_regridded) |
ons-west-2 | 11.8 | 11.5 | 11.2 | 11.6 |
ERA5 (historic_temp_regridded) |
ons-oost-1 | 1512 | 711 | 427 | 202 |
Verschil (propogated pool) |
us-west-2 en us-oost-1 | 1527 | 906 | 469 | 251 |
De volgende grafiek visualiseert de prestaties en schaal.
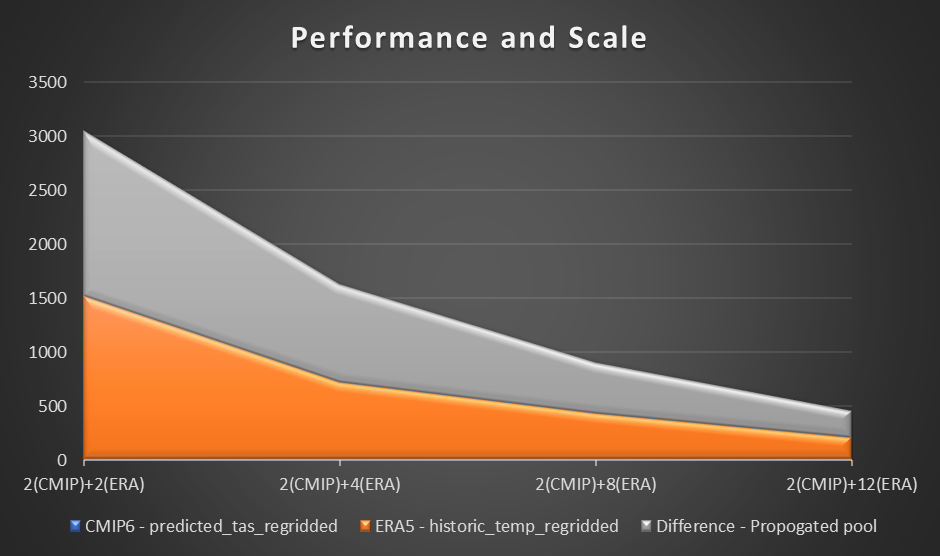
Uit ons experiment hebben we een lineaire verbetering in de berekeningen voor de ERA5-dataset waargenomen naarmate het aantal werknemers toenam. Naarmate het aantal werknemers toenam, werden de rekentijden soms gehalveerd.
Jupyter notitieboek
Als onderdeel van de lancering van de oplossing implementeren we een vooraf geconfigureerde Jupyter-notebook om de interregionale Dask-oplossing te helpen testen. Het notebook demonstreert de weggenomen zorg van het moeten weten van de regionale locatie van datasets, in plaats van het opvragen van een catalogus via een reeks Jupyter-notebooks die op de achtergrond draaien.
Volg de instructies in dit gedeelte om aan de slag te gaan.
De code voor de notebooks vind je in lib/SagemakerCode waarbij het primaire notebook is ux_notebook.ipynb. Dit notitieboekje doet een beroep op andere notitieboekjes en activeert helperscripts. ux_notebook is ontworpen als toegangspunt voor wetenschappers, zonder dat ze ergens anders heen hoeven te gaan.
Om aan de slag te gaan, opent u dit notitieboekje in SageMaker nadat u de AWS CDK hebt geïmplementeerd. De AWS CDK maakt een notebookinstantie waarbij alle bestanden in de repository zijn geladen en waarvan een back-up is gemaakt in een AWS Codecommit repository.
Om de toepassing uit te voeren, opent u de eerste cel van en voert u deze uit ux_notebook. Deze cel beheert de get_variables notebook op de achtergrond, waarin u wordt gevraagd om invoer voor de gegevens die u wilt selecteren. We nemen een voorbeeld op; Houd er echter rekening mee dat vragen pas verschijnen nadat de vorige optie is geselecteerd. Dit is opzettelijk gedaan om de keuzemogelijkheden in de vervolgkeuzelijsten te beperken en kan optioneel worden geconfigureerd door het get_variables notebook.
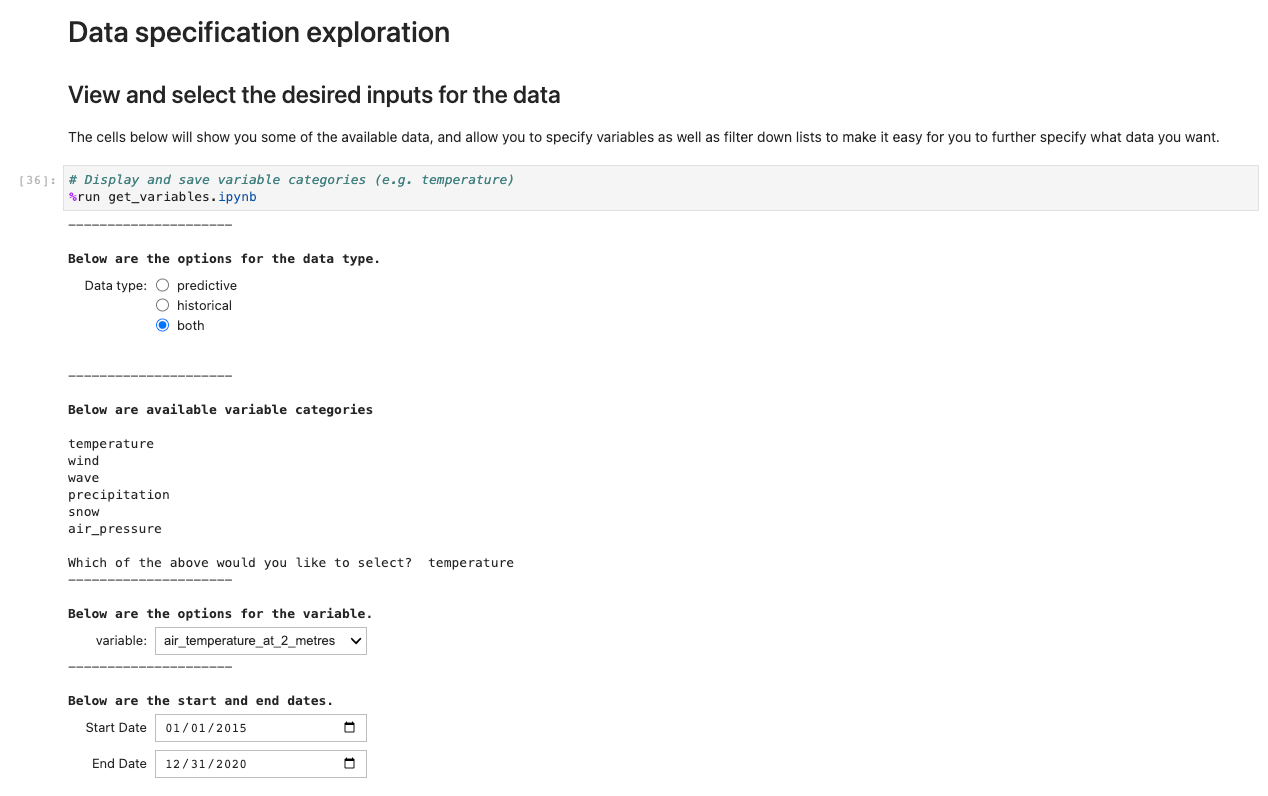
De voorgaande code slaat variabelen globaal op, zodat andere notebooks uw selectie van keuzes kunnen ophalen en laden. Ter demonstratie zou de volgende cel de opslagvariabelen van voorheen moeten uitvoeren.
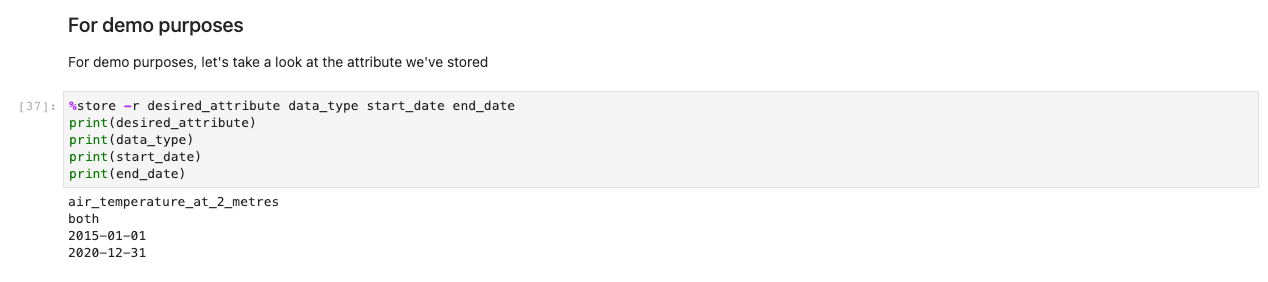
Vervolgens verschijnt een vraag om verdere gegevensspecificaties. Deze cel verfijnt de gegevens die u zoekt door de ID's van tabellen in een voor mensen leesbaar formaat weer te geven. Gebruikers selecteren alsof het een formulier is, maar de titels verwijzen naar tabellen op de achtergrond waarmee het systeem de juiste gegevenssets kan ophalen.
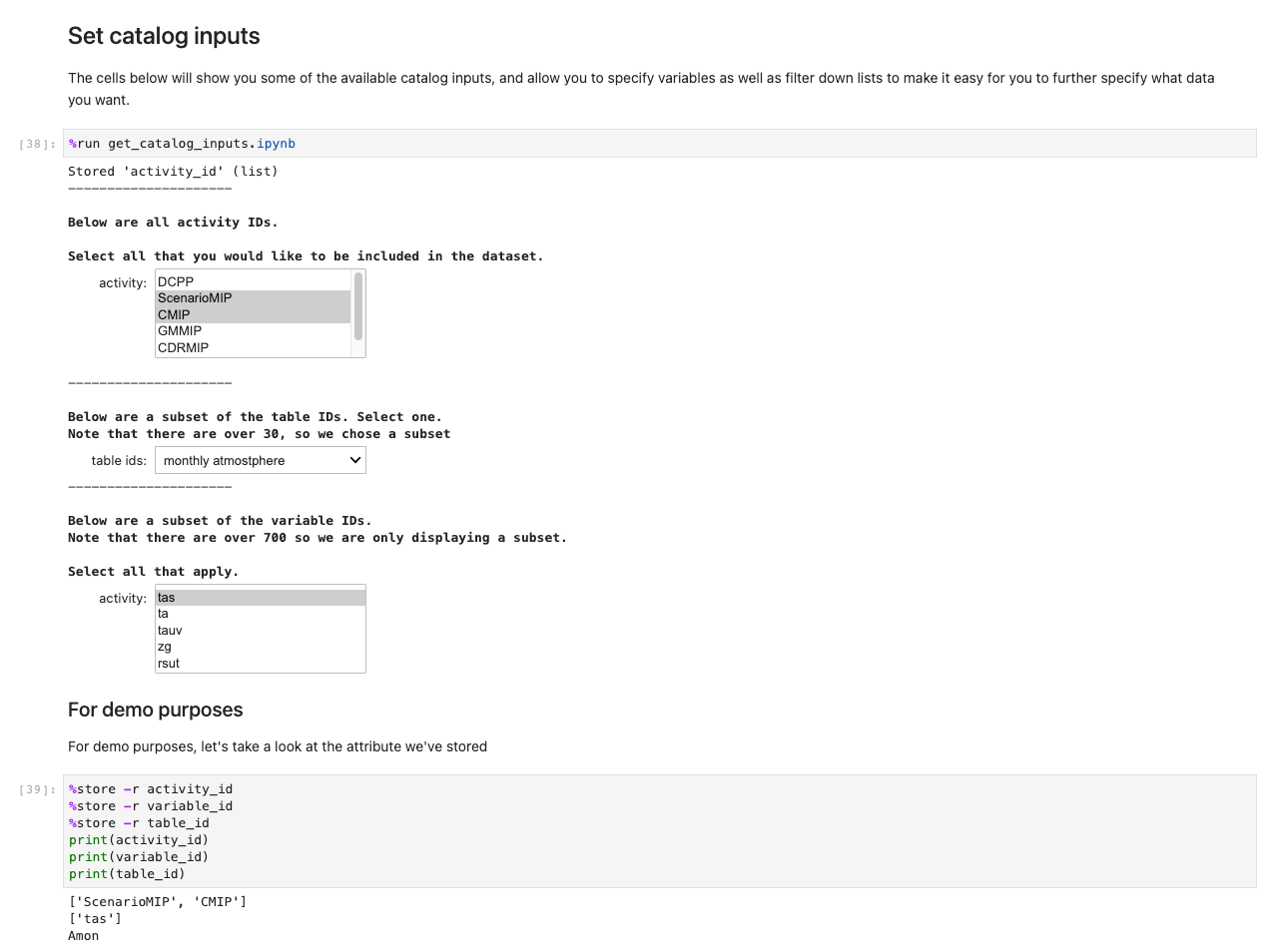
Nadat u al uw keuzes en selectiecellen hebt opgeslagen, laadt u de gegevens in de Regio's door de cel in het uit te voeren De gegevens ophalen reeks sectie. De opdracht %%capture onderdrukt onnodige uitvoer van de get_data notitieboekje. Let op: u kunt dit verwijderen om de uitvoer van de andere notebooks te inspecteren. Gegevens worden vervolgens opgehaald in de backend.
Terwijl andere notebooks op de achtergrond worden uitgevoerd, is het enige contactpunt voor de gebruiker het ux_notebook. Dit is bedoeld om het vervelende proces van het importeren van gegevens in een formaat te abstraheren dat elke gebruiker gemakkelijk kan volgen.
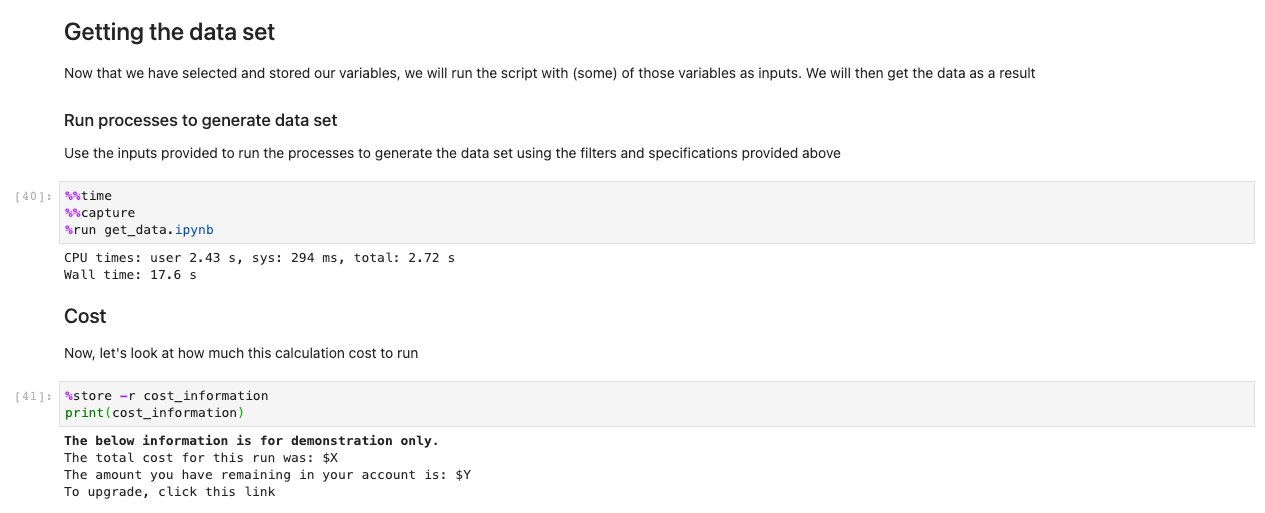
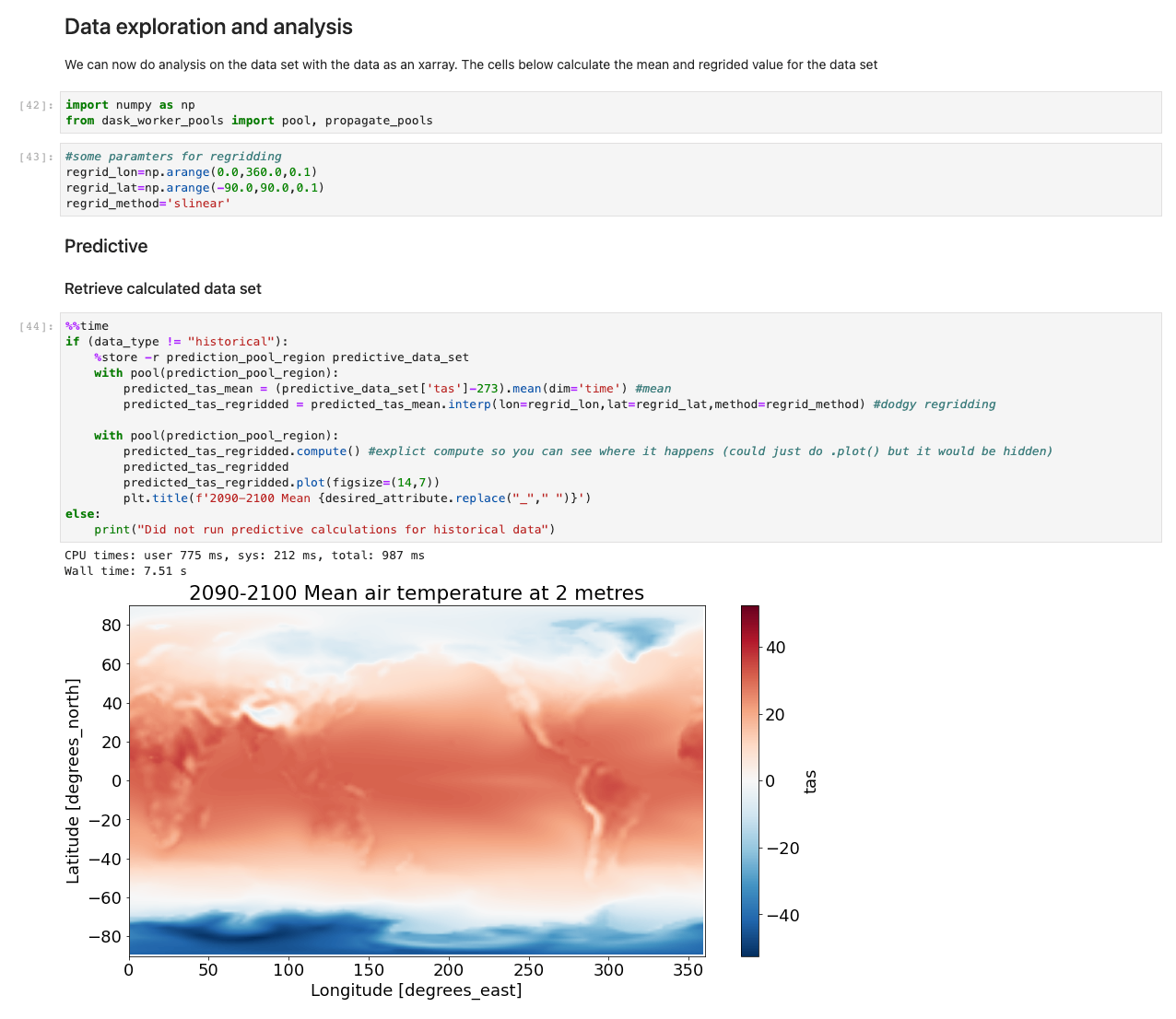
Nu de gegevens zijn geladen, kunnen we ermee beginnen te communiceren. De volgende cellen zijn voorbeelden van berekeningen die u kunt uitvoeren op basis van weergegevens. Gebruik makend van röntgenarrays, importeren, berekenen en plotten we die datasets.
Ons voorbeeld illustreert een plot van voorspellende gegevens waarbij gegevens worden opgehaald, de berekening wordt uitgevoerd en de resultaten in minder dan 7.5 seconden worden geplot – ordes van grootte sneller dan bij een typische aanpak.
Onder de motorkap
De notitieboekjes get_catalog_input en get_variables gebruik de bibliotheek ipywidgets om widgets weer te geven, zoals vervolgkeuzelijsten en selecties met meerdere vakjes. Deze opties worden globaal opgeslagen met behulp van de opdracht %%store, zodat ze toegankelijk zijn via de ux_notebook. Een van de opties vraagt u of u historische gegevens, voorspellende gegevens of beide wilt. Deze variabele wordt doorgegeven aan de get_data notebook om te bepalen welke volgende notebooks moeten worden uitgevoerd.
De get_data notebook haalt eerst het gedeelde OpenSearch Service-domein op waarin het is opgeslagen AWS Systems Manager-parameteropslag. Met dit domein kan onze notebook een query uitvoeren op het verzamelen van informatie die aangeeft waar de geselecteerde datasets regionaal zijn opgeslagen. Als deze datasets regionaal zijn gelokaliseerd, zal de notebook een verbindingspoging doen met de Dask-planner, waarbij de informatie wordt doorgegeven die is verzameld via de OpenSearch-service. De Dask-planner kan op zijn beurt een beroep doen op werknemers in de juiste regio's.
Hoe u de ontwikkeling kunt aanpassen en voortzetten
Deze notitieboekjes zijn bedoeld als voorbeeld van hoe u een manier kunt creëren waarop gebruikers kunnen communiceren met de gegevens. Het notitieboekje in dit bericht dient als illustratie van wat mogelijk is, en we nodigen u uit om verder te bouwen op de oplossing om de gebruikersbetrokkenheid verder te verbeteren. Het kernonderdeel van deze oplossing is de backend-technologie, maar zonder een mechanisme voor interactie met die backend zullen gebruikers niet het volledige potentieel van de oplossing realiseren.
Om te voorkomen dat er in de toekomst kosten in rekening worden gebracht, verwijdert u de bronnen. Laten we onze geïmplementeerde oplossing vernietigen met de volgende opdracht:
Conclusie
Dit bericht toont de uitbreiding van Dask interregionaal op AWS, en een mogelijke integratie met openbare datasets op AWS. De oplossing is gebouwd als een generiek patroon en er kunnen meer datasets worden geladen om hoge I/O-analyses van complexe gegevens te versnellen.
Data transformeren elk vakgebied en elk bedrijf. Omdat data echter sneller groeien dan de meeste bedrijven kunnen bijhouden, is het verzamelen van data en het verkrijgen van waarde uit die data een uitdaging. Een moderne datastrategie kan u helpen betere bedrijfsresultaten te behalen met data. AWS biedt de meest complete set services voor het end-to-end datatraject om u te helpen waarde uit uw data te halen en deze om te zetten in inzicht.
Voor meer informatie over de verschillende manieren waarop u uw gegevens in de cloud kunt gebruiken, gaat u naar de AWS Big Data-blog. We nodigen u verder uit om uw mening over dit bericht te geven en of dit een oplossing is die u van plan bent uit te proberen.
Over de auteurs
 Patrick O'Connor is een WWSO Prototyping Engineer gevestigd in Londen. Hij is een creatieve probleemoplosser, die zich kan aanpassen aan een breed scala aan technologieën, zoals IoT, serverloze technologie, 3D-ruimtelijke technologie en ML/AI, samen met een meedogenloze nieuwsgierigheid naar hoe technologie de dagelijkse aanpak kan blijven ontwikkelen.
Patrick O'Connor is een WWSO Prototyping Engineer gevestigd in Londen. Hij is een creatieve probleemoplosser, die zich kan aanpassen aan een breed scala aan technologieën, zoals IoT, serverloze technologie, 3D-ruimtelijke technologie en ML/AI, samen met een meedogenloze nieuwsgierigheid naar hoe technologie de dagelijkse aanpak kan blijven ontwikkelen.
 Chakra Nagarajan is een Principal Machine Learning Prototyping SA met 21 jaar ervaring in machine learning, big data en high-performance computing. In zijn huidige rol helpt hij klanten bij het oplossen van complexe bedrijfsproblemen in de echte wereld door prototypes te bouwen met end-to-end AI/ML-oplossingen in cloud- en edge-apparaten. Zijn ML-specialisatie omvat computervisie, natuurlijke taalverwerking, tijdreeksvoorspellingen en personalisatie.
Chakra Nagarajan is een Principal Machine Learning Prototyping SA met 21 jaar ervaring in machine learning, big data en high-performance computing. In zijn huidige rol helpt hij klanten bij het oplossen van complexe bedrijfsproblemen in de echte wereld door prototypes te bouwen met end-to-end AI/ML-oplossingen in cloud- en edge-apparaten. Zijn ML-specialisatie omvat computervisie, natuurlijke taalverwerking, tijdreeksvoorspellingen en personalisatie.
 Val Cohen is een senior WWSO Prototyping Engineer gevestigd in Londen. Val is van nature een probleemoplosser en schrijft graag code om processen te automatiseren, klantgerichte tools te bouwen en infrastructuur te creëren voor verschillende applicaties voor haar wereldwijde klantenbestand. Val heeft ervaring met een breed scala aan technologieën, zoals front-end webontwikkeling, backend-werk en AI/ML.
Val Cohen is een senior WWSO Prototyping Engineer gevestigd in Londen. Val is van nature een probleemoplosser en schrijft graag code om processen te automatiseren, klantgerichte tools te bouwen en infrastructuur te creëren voor verschillende applicaties voor haar wereldwijde klantenbestand. Val heeft ervaring met een breed scala aan technologieën, zoals front-end webontwikkeling, backend-werk en AI/ML.
 Niall Robinson is hoofd product futures bij het Britse Met Office. Hij en zijn team onderzoeken nieuwe manieren waarop het Met Office waarde kan bieden door middel van productinnovatie en strategische partnerschappen. Hij heeft een gevarieerde carrière achter de rug, waarbij hij leiding gaf aan een multidisciplinair R&D-team op het gebied van de informatica, academisch onderzoek op het gebied van datawetenschap, veldwetenschapper en expertise op het gebied van klimaatmodellen.
Niall Robinson is hoofd product futures bij het Britse Met Office. Hij en zijn team onderzoeken nieuwe manieren waarop het Met Office waarde kan bieden door middel van productinnovatie en strategische partnerschappen. Hij heeft een gevarieerde carrière achter de rug, waarbij hij leiding gaf aan een multidisciplinair R&D-team op het gebied van de informatica, academisch onderzoek op het gebied van datawetenschap, veldwetenschapper en expertise op het gebied van klimaatmodellen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/build-efficient-cross-regional-i-o-intensive-workloads-with-dask-on-aws/
- : heeft
- :is
- :waar
- $UP
- 1
- 10
- 100
- 11
- 12
- 20
- 24
- 3d
- 40
- 50
- 7
- 9
- a
- vermogen
- in staat
- Over
- boven
- SAMENVATTING
- samenvattingen
- academische
- academisch onderzoek
- versnellen
- versnellen
- toegang
- geraadpleegde
- accommoderen
- bereiken
- Account
- Bereikt
- over
- aanpast
- toegevoegd
- toe te voegen
- Extra
- Daarnaast
- adres
- aanpakken
- Voegt
- beheerders
- aangenomen
- Adoptie
- Na
- AI / ML
- AIR
- Alles
- Het toestaan
- toestaat
- langs
- ook
- Amazone
- Amazon EC2
- an
- analyse
- en
- elke
- verschijnen
- Aanvraag
- toepassingen
- nadering
- benaderingen
- passend
- architectuur
- ZIJN
- AS
- At
- Sfeer
- atmosferisch
- automatiseren
- vermijd
- AWS
- AWS-klant
- Ruggegraat
- met een rug
- backend
- achtergrond
- Balance
- baseren
- gebaseerde
- BE
- worden
- geweest
- vaardigheden
- wezen
- onder
- criterium
- Betere
- tussen
- Groot
- Big data
- Bootstrap
- zowel
- Bringing
- Kapot
- bouw
- Gebouw
- bebouwd
- ingebouwd
- bedrijfsdeskundigen
- maar
- by
- berekenen
- Bellen
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- bellen
- oproepen
- CAN
- mogelijkheden
- in staat
- Carrière
- catalogus
- CD
- Cellen
- uitdagen
- uitdagend
- verandering
- veranderende
- lading
- lasten
- keuzes
- Circulatie
- klant
- Klimaat
- dichterbij
- Cloud
- TROS
- CO
- code
- codebasis
- samenwerking
- Het verzamelen van
- hoe
- komt
- komst
- commentaar
- gemeenschap
- Bedrijven
- compleet
- complex
- componenten
- bestaat uit
- berekening
- Berekenen
- computer
- Computer visie
- computergebruik
- Configuratie
- Verbinden
- gekoppeld blijven
- Wij verbinden
- versterken
- Consumenten
- consumptie
- Containers
- bevat
- voortzetten
- blijft
- kopieën
- Kern
- te corrigeren
- Kosten
- kostenefficient
- kon
- gepaard
- CPU
- en je merk te creëren
- creëert
- Creatieve
- kritisch
- gewas
- Cross
- nieuwsgierigheid
- Actueel
- gewoonte
- klant
- Klanten
- aanpasbare
- aan te passen
- dagelijks
- dashboards
- gegevens
- data science
- gegevensstrategie
- datasets
- dag
- decennium
- beslissingen
- Standaard
- Vraag
- demonstreert
- implementeren
- ingezet
- inzet
- ontplooit
- ontworpen
- vernietigen
- gedetailleerd
- gegevens
- Bepalen
- ontwikkelen
- Ontwikkelaar
- Ontwikkeling
- systemen
- verschil
- invalide
- ontdekking
- Display
- verdeeld
- distributed computing
- dns
- havenarbeider
- domein
- beneden
- dynamisch
- dynamisch
- elk
- gemak
- gemakkelijk
- rand
- editing
- doeltreffend
- elders
- in staat stellen
- eind tot eind
- energie-niveau
- engagement
- ingenieur
- toegang
- Milieu
- Gelijkwaardig
- Tijdperk
- geschat
- Ether (ETH)
- Alle
- elke dag
- alledaags
- ontwikkelen
- voorbeeld
- voorbeelden
- ervaring
- experiment
- expertise
- Verken
- exporteren
- blootgestelde
- uitbreiding
- sneller
- Kenmerk
- Voordelen
- veld-
- Velden
- Dien in
- Bestanden
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Voornaam*
- richt
- volgen
- volgend
- eten
- Voor
- formulier
- formaat
- formulieren
- gevonden
- Opgericht
- Achtergrond
- frameworks
- Gratis
- oppompen van
- vrucht
- vol
- functionaliteit
- verder
- toekomst
- Futures
- Algemeen
- generatie
- krijgen
- het krijgen van
- Git
- Globaal
- wereldwijd netwerk
- Wereldwijd
- wereldbol
- gaan
- diagram
- meer
- Raster
- Groeien
- Groeiend
- HAD
- Helft
- gehalveerd
- Hebben
- he
- hoofd
- hulp
- helpt
- haar
- Hoge
- hoge performantie
- highlights
- zijn
- historisch
- gastheer
- gehost
- uur
- Hoe
- How To
- Echter
- HTML
- HTTPS
- leesbare
- Honderden
- Idle
- ids
- if
- illustreert
- importeren
- importeren
- verbeteren
- verbetering
- in
- omvatten
- omvat
- meer
- index
- aangeven
- informeren
- informatie
- Infrastructuur
- inherent
- Innovatie
- invoer
- onzekerheid
- inzicht
- geinspireerd
- installeren
- instantie
- verkrijgen in plaats daarvan
- instructies
- integratie
- Opzettelijk
- interactie
- interactie
- Interface
- intern
- Internet
- in
- uitnodigt
- iot
- IP
- IP-adres
- problemen
- IT
- HAAR
- Jobomschrijving:
- jpg
- Jupyter Notebook
- Houden
- sleutel
- blijven
- taal
- Groot
- Achternaam*
- Wachttijd
- lancering
- leidend
- LEARN
- leren
- Bibliotheek
- levenscyclus van uw product
- als
- Koppeling
- Lijst
- laden
- lokaal
- plaatselijk
- gelegen
- plaats
- London
- machine
- machine learning
- groot
- maken
- beheer
- manager
- beheert
- kaart
- in kaart brengen
- Massa
- Massa-adoptie
- materiaal
- Mei..
- gemiddelde
- mechanisme
- Metadata
- miljoenen
- ML
- model
- Modern
- Modules
- Maand
- maandelijks
- maandelijkse gegevens
- meer
- meest
- MOUNT
- multidisciplinaire
- naam
- nationaal
- Naturel
- Natuurlijke taal
- Natural Language Processing
- NATUUR
- noodzakelijk
- Noodzaak
- nodig
- netwerk
- New
- volgende
- nacht
- knooppunt
- knooppunten
- notitieboekje
- laptops
- nu
- aantal
- nummers
- of
- bieden
- Kantoor
- on
- EEN
- Slechts
- open
- open data
- open source
- open-sourcecode
- operationele
- Keuze
- Opties
- or
- orkestratie
- organisaties
- Overige
- onze
- uit
- resultaten
- uitgang
- over
- totaal
- pakket
- parameter
- deel
- bijzonder
- vooral
- partnerships
- voorbij
- Voorbijgaand
- Patronen
- prestatie
- periodes
- Personalisatie
- petabyte
- fase
- plan
- platforms
- Plato
- Plato gegevensintelligentie
- PlatoData
- punt
- zwembad
- havens
- mogelijk
- Post
- potentieel
- energie
- krachtige
- praktijk
- voorspelling
- Voorspellingen
- vereisten
- vorig
- primair
- Principal
- privaat
- probleem
- problemen
- processen
- verwerking
- geproduceerd
- Product
- Product innovatie
- productief
- Programma
- Programming
- project
- prototypes
- prototyping
- zorgen voor
- mits
- biedt
- voorziening
- publiek
- publiceren
- gepubliceerde
- Truien
- queries
- Contact
- R & D
- reeks
- liever
- pasklaar
- echte wereld
- realiseren
- verminderen
- vermindering
- reductie
- regio
- regionaal
- regio
- meedogenloos
- stoffelijk overschot
- verwijderen
- verwijderd
- bewaarplaats
- vertegenwoordigt
- onderzoek
- Resources
- degenen
- Resultaten
- Rol
- lopen
- lopend
- SA
- veilig
- sagemaker
- dezelfde
- Bespaar
- schaalbare
- Scale
- balans
- scaling
- Wetenschap
- Wetenschapper
- wetenschappers
- scripts
- seconden
- sectie
- zien
- gezien
- segmenten
- gekozen
- selectie
- senior
- -Series
- Serverless
- bedient
- service
- Diensten
- reeks
- Delen
- gedeeld
- moet
- tonen
- presentatie
- Shows
- Eenvoudig
- eenvoudigweg
- zesde
- traag
- So
- oplossing
- Oplossingen
- OPLOSSEN
- sommige
- bron
- ruimtelijke
- specifiek
- specificaties
- gespecificeerd
- sponsoring
- stack
- stadia
- standalone
- begin
- gestart
- blijven
- Stappen
- mediaopslag
- shop
- opgeslagen
- winkels
- eenvoudig
- strategisch
- Strategic Partnerships
- Strategie
- volgend
- Hierop volgend
- geslaagd
- dergelijk
- Oppervlak
- ontstaat
- Duurzaamheid
- duurzaam
- system
- Systems
- tafel
- Nemen
- team
- tech
- Technologies
- Technologie
- proef
- neem contact
- dat
- De
- de informatie
- De Bron
- Brittannië
- de wereld
- hun
- harte
- Er.
- daarbij
- Deze
- ze
- dit
- die
- drie
- Thrive
- Door
- doorvoer
- niet de tijd of
- Tijdreeksen
- keer
- titels
- naar
- vandaag
- samen
- tools
- spoor
- Tracking
- overdracht
- transformeren
- doorvoer
- triggering
- BEURT
- twee
- type dan:
- getypte tekst
- typisch
- Uk
- voor
- openen
- onhoudbaar
- up-to-date
- updates
- op
- URI
- Gebruik
- .
- gebruikt
- Gebruiker
- gebruikers
- gebruik
- GMT
- Gebruik makend
- VAL
- waarde
- variëteit
- divers
- via
- visie
- Bezoek
- volume
- willen
- wil
- warm
- was
- Manier..
- manieren
- we
- Weer
- web
- Webontwikkeling
- waren
- of
- welke
- breed
- Grote range
- wil
- wensen
- Met
- zonder
- Mijn werk
- werker
- werknemers
- wereld
- zorgen
- zou
- het schrijven van
- jaar
- nog
- Opbrengst
- u
- Your
- zephyrnet