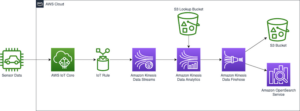
De waarde van data is tijdgevoelig. Realtime verwerking maakt gegevensgestuurde beslissingen nauwkeurig en uitvoerbaar in seconden of minuten in plaats van uren of dagen. Change data capture (CDC) verwijst naar het proces van het identificeren en vastleggen van wijzigingen in gegevens in een database en het vervolgens in realtime leveren van deze wijzigingen aan een stroomafwaarts systeem. Door elke verandering van transacties in een brondatabase vast te leggen en ze in realtime naar het doel te verplaatsen, blijven de systemen gesynchroniseerd en helpt het bij real-time analytische gebruiksscenario's en databasemigraties zonder downtime. Hieronder volgen enkele voordelen van CDC:
- Het elimineert de noodzaak van het bijwerken van bulkladingen en onhandige batchvensters door incrementeel laden of real-time streaming van gegevenswijzigingen naar uw doelrepository mogelijk te maken.
- Het zorgt ervoor dat gegevens in meerdere systemen gesynchroniseerd blijven. Dit is vooral belangrijk als u tijdgevoelige beslissingen neemt in een gegevensomgeving met hoge snelheid.
Kafka Connect is een open-sourcecomponent van Apache Kafka die werkt als een gecentraliseerde gegevenshub voor eenvoudige gegevensintegratie tussen databases, sleutel/waarde-archieven, zoekindexen en bestandssystemen. De AWS Lijm Schema Register stelt u in staat om datastroomschema's centraal te ontdekken, te controleren en te ontwikkelen. Kafka Connect en Schema Registry integreren om schema-informatie van connectors vast te leggen. Kafka Connect biedt een mechanisme voor het converteren van gegevens van de interne gegevenstypen die door Kafka Connect worden gebruikt naar gegevenstypen die worden weergegeven als Avro, Protobuf of JSON Schema. AvroConverter, ProtobufConverter en JsonSchemaConverter registreren automatisch schema's die zijn gegenereerd door Kafka-connectoren (bron) die gegevens naar Kafka produceren. Connectors (sink) die gegevens van Kafka gebruiken, ontvangen naast de gegevens voor elk bericht ook schema-informatie. Hierdoor kunnen sink-connectors de structuur van de gegevens kennen om mogelijkheden te bieden zoals het onderhouden van een databasetabelschema in een gegevenscatalogus.
De post laat zien hoe je een end-to-end CDC bouwt met behulp van Amazon MSK Connect, een door AWS beheerde service om Kafka Connect-applicaties en AWS Glue Schema Registry te implementeren en uit te voeren, waarmee u datastroomschema's centraal kunt ontdekken, controleren en ontwikkelen.
Overzicht oplossingen
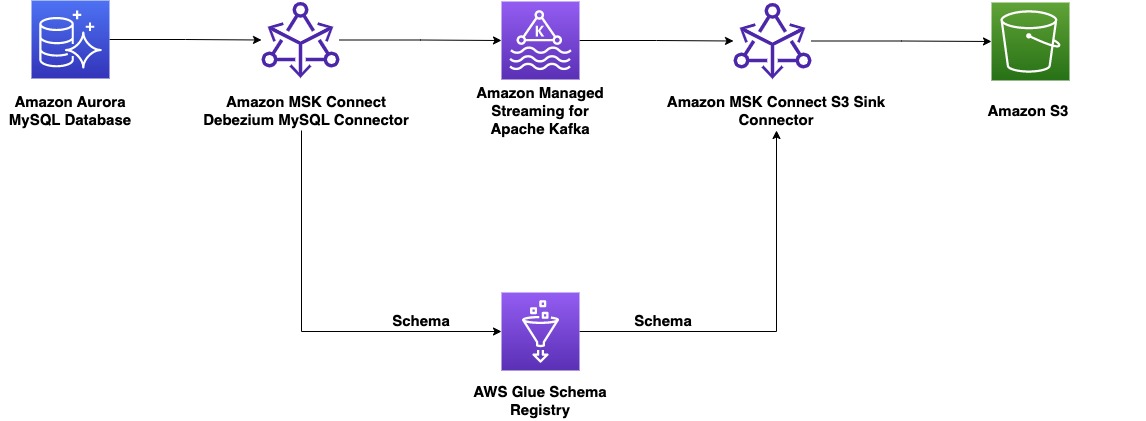
Aan de kant van de producent kiezen we voor dit voorbeeld een MySQL-compatibel Amazon Aurora database als gegevensbron, en we hebben een Debezium MySQL-connector om CDC uit te voeren. De Debezium-connector bewaakt continu de databases en pusht wijzigingen op rijniveau naar een Kafka-onderwerp. De connector haalt het schema op uit de database om de records te serialiseren naar een binaire vorm. Als het schema nog niet in het register bestaat, wordt het schema geregistreerd. Als het schema bestaat maar de serializer een nieuwe versie gebruikt, controleert het schemaregister het compatibiliteitsmodus van het schema voordat u het schema bijwerkt. In deze oplossing gebruiken we achterwaartse compatibiliteitsmodus. Het schemaregister retourneert een fout als een nieuwe versie van het schema niet achterwaarts compatibel is, en we kunnen Kafka Connect configureren om incompatibele berichten naar de dode letter-wachtrij te sturen.
Aan de consumentenkant gebruiken we een Amazon eenvoudige opslagservice (Amazon S3) sink-connector om de record te deserialiseren en wijzigingen in Amazon S3 op te slaan. We bouwen en implementeren de Debezium-connector en de Amazon S3-sink met behulp van MSK Connect.
Voorbeeld schema
Voor dit bericht gebruiken we het volgende schema als eerste versie van de tabel:
Voorwaarden
Voordat we de MSK-producent- en consumentenconnectors configureren, moeten we eerst een gegevensbron, MSK-cluster en nieuw schemaregister instellen. Wij bieden een AWS CloudFormatie sjabloon om de ondersteunende bronnen te genereren die nodig zijn voor de oplossing:
- Een MySQL-compatibele Aurora-database als gegevensbron. Om CDC uit te voeren, schakelen we binaire logboekregistratie in de DB-clusterparametergroep.
- Een MSK-cluster. Om de netwerkverbinding te vereenvoudigen, gebruiken we dezelfde VPC voor de Aurora-database en het MSK-cluster.
- Twee schemaregisters om schema's voor berichtsleutel en berichtwaarde te verwerken.
- Eén S3-bucket als data-sink.
- MSK Connect-plug-ins en werkconfiguratie nodig voor deze demo.
- One Amazon Elastic Compute-cloud (Amazon EC2) instantie om database-opdrachten uit te voeren.
Om bronnen in uw AWS-account in te stellen, voert u de volgende stappen uit in een AWS-regio die Amazon MSK, MSK Connect en de AWS Glue Schema Registry ondersteunt:
- Kies Start Stack:
- Kies Volgende.
- Voor Stack naam, voer een geschikte naam in.
- Voor Database-wachtwoord, voer het gewenste wachtwoord voor de databasegebruiker in.
- Houd andere waarden als standaard.
- Kies Volgende.
- Kies op de volgende pagina Volgende.
- Bekijk de details op de laatste pagina en selecteer Ik erken dat AWS CloudFormation IAM-bronnen kan creëren.
- Kies Maak een stapel.
Aangepaste plug-in voor de bron- en bestemmingsconnector
Een aangepaste plug-in is een set JAR-bestanden die de implementatie van een of meer connectoren, transformaties of converters bevatten. Amazon MSK installeert de plug-in op de werknemers van het MSK Connect-cluster waarop de connector draait. Als onderdeel van deze demo gebruiken we voor de bronconnector open-source Debezium MySQL-connector JAR's, en voor de bestemmingsconnector gebruiken we de licentie van de Confluent-community Amazon S3 gootsteenconnector JAR's. Beide plug-ins zijn ook toegevoegd met bibliotheken voor Avro-serializers en deserializers van het AWS Glue Schema-register. Deze aangepaste plug-ins zijn al gemaakt als onderdeel van de CloudFormation-sjabloon die in de vorige stap is geïmplementeerd.
Gebruik de AWS Glue Schema Registry met de Debezium-connector op MSK Connect als de MSK-producent
We implementeren eerst de bronconnector met behulp van de Debezium MySQL-plug-in om gegevens te streamen van een Amazon Aurora MySQL-compatibele editie database naar Amazon MSK. Voer de volgende stappen uit:
- Op de Amazon MSK-console, in het navigatievenster, onder MSK-verbinding, kiezen Connectoren.
- Kies Verbinding maken.
- Kies Gebruik bestaande aangepaste plug-in en kies vervolgens de aangepaste plug-in waarvan de naam begint
msk-blog-debezium-source-plugin. - Kies Volgende.
- Voer een geschikte naam in zoals
debezium-mysql-connectoren een optionele beschrijving. - Voor Apache Kafka-cluster, kiezen MSK-cluster en kies het cluster dat is gemaakt door de CloudFormation-sjabloon.
- In Connector configuratie, verwijder de standaardwaarden en gebruik de volgende configuratiesleutel-waardeparen en met de juiste waarden:
- naam – De naam die wordt gebruikt voor de connector.
- database.hostsnaam – De CloudFormation-uitvoer voor Database-eindpunt.
- database.gebruiker en database.wachtwoord – De parameters die zijn doorgegeven in de CloudFormation-sjabloon.
- database.history.kafka.bootstrap.servers – De CloudFormation-uitvoer voor Kafka-bootstrap.
- key.converter.region en waarde.converter.region – Uw regio.
Sommige van deze instellingen zijn algemeen en moeten voor elke connector worden opgegeven. Bijvoorbeeld:
- connector.class is de Java-klasse van de connector
- task.max is het maximale aantal taken dat voor deze connector moet worden gemaakt
Sommige instellingen (database.*, transforms.*) zijn specifiek voor de Debezium MySQL-connector. Verwijzen naar Configuratie-eigenschappen van de Debezium MySQL-bronconnector voor meer informatie.
Sommige instellingen (key.converter.* en value.converter.*) zijn specifiek voor het Schemaregister. Wij gebruiken de AWSKafkaAvroConverter van het AWS Glue Schema-registerbibliotheek als de formaatconverter. Configureren AWSKafkaAvroConverter, gebruiken we de waarde van de eigenschappen van de tekenreeksconstante in de AWSSchemaRegistryConstanten klasse:
key.converterenvalue.converterbeheer de indeling van de gegevens die naar Kafka worden geschreven voor source-connectors of worden gelezen van Kafka voor sink-connectors. We gebruikenAWSKafkaAvroConvertervoor Avro-formaat.key.converter.registry.nameenvalue.converter.registry.namedefiniëren welk schemaregister moet worden gebruikt.key.converter.compatibilityenvalue.converter.compatibilitydefinieer het compatibiliteitsmodel.
Verwijzen naar Kafka Connect gebruiken met AWS Glue Schema Registry voor meer informatie.
- Vervolgens configureren we Connector capaciteit. Wij kunnen kiezen Voorzien en laat andere eigenschappen als standaard staan
- Voor Werknemer configuratie, kies de custom worker-configuratie met naam die begint
msk-gsr-bloggemaakt als onderdeel van de CloudFormation-sjabloon. - Voor Toegangsrechten, gebruik het AWS Identiteits- en toegangsbeheer (IAM) rol gegenereerd door de CloudFormation-sjabloon
MSKConnectRole. - Kies Volgende.
- Voor Security, kies de standaardinstellingen.
- Kies Volgende.
- Voor Levering van logboekenselecteer Leveren aan Amazon CloudWatch Logs en blader naar de logboekgroep die is gemaakt door de CloudFormation-sjabloon (
msk-connector-logs). - Kies Volgende.
- Bekijk de instellingen en kies Verbinding maken.
Na een paar minuten verandert de connector in de actieve status.
Gebruik de AWS Glue Schema Registry met de Confluent S3-sinkconnector op MSK Connect als de MSK-consument
We implementeren de sink-connector met behulp van de Confluent S3-sink-plug-in om gegevens van Amazon MSK naar Amazon S3 te streamen. Voer de volgende stappen uit:
-
- Op de Amazon MSK-console, in het navigatievenster, onder MSK-verbinding, kiezen Connectoren.
- Kies Verbinding maken.
- Kies Gebruik bestaande aangepaste plug-in en kies de aangepaste plug-in met de naam die begint
msk-blog-S3sink-plugin. - Kies Volgende.
- Voer een geschikte naam in zoals
s3-sink-connectoren een optionele beschrijving. - Voor Apache Kafka-cluster, kiezen MSK-cluster en selecteer het cluster dat is gemaakt door de CloudFormation-sjabloon.
- In Connector configuratie, verwijder de opgegeven standaardwaarden en gebruik de volgende configuratiesleutel-waardeparen met de juiste waarden:
-
- naam – Dezelfde naam die wordt gebruikt voor de connector.
- s3.bucket.naam – De CloudFormation-uitvoer voor Emmernaam.
- s3.region, key.converter.region en waarde.converter.region – Uw regio.
-
- Vervolgens configureren we Connector capaciteit. Wij kunnen kiezen Voorzien en laat andere eigenschappen als standaard staan
- Voor Werknemer configuratie, kies de custom worker-configuratie met naam die begint
msk-gsr-bloggemaakt als onderdeel van de CloudFormation-sjabloon. - Voor Toegangsrechten, gebruik de IAM-rol die is gegenereerd door de CloudFormation-sjabloon
MSKConnectRole. - Kies Volgende.
- Voor Security, kies de standaardinstellingen.
- Kies Volgende.
- Voor Levering van logboekenselecteer Leveren aan Amazon CloudWatch Logs en blader naar de logboekgroep die is gemaakt door de CloudFormation-sjabloon
msk-connector-logs. - Kies Volgende.
- Bekijk de instellingen en kies Verbinding maken.
Na een paar minuten werkt de connector.
Test de end-to-end CDC-logboekstroom
Nu zowel de Debezium- als de S3-sinkconnector actief zijn, voert u de volgende stappen uit om de end-to-end CDC te testen:
- Navigeer op de Amazon EC2-console naar de Beveiligingsgroepen pagina.
- Selecteer de beveiligingsgroep
ClientInstanceSecurityGroupEn kies Bewerk inkomende regels. - Voeg een inkomende regel toe die SSH-verbinding vanaf uw lokale netwerk toestaat.
- Op de Gevallen pagina, selecteert u de instantie
ClientInstanceEn kies Verbinden. - Op de EC2-instantie verbinding maken tabblad, kies Verbinden.
- Zorg ervoor dat uw huidige werkmap is
/home/ec2-useren het heeft de bestandencreate_table.sql,alter_table.sql,initial_insert.sqleninsert_data_with_new_column.sql. - Maak een tabel in uw MySQL-database door de volgende opdracht uit te voeren (geef de hostnaam van de database op uit de CloudFormation-sjabloonuitvoer):
- Wanneer u om een wachtwoord wordt gevraagd, voert u het wachtwoord in uit de CloudFormation-sjabloonparameters.
- Voeg enkele voorbeeldgegevens in de tabel in met de volgende opdracht:
- Wanneer u om een wachtwoord wordt gevraagd, voert u het wachtwoord in uit de CloudFormation-sjabloonparameters.
- Kies op de AWS Glue-console: Schemaregisters in het navigatievenster en kies vervolgens schema's.
- Navigeer naar
db1.sampledatabase.moviesversie 1 om het nieuwe schema te controleren dat is gemaakt voor de filmstabel:
Er wordt een afzonderlijke S3-map gemaakt voor elke partitie van het Kafka-onderwerp en de gegevens voor het onderwerp worden in die map geschreven.
- Controleer op de Amazon S3-console of er gegevens zijn geschreven in Parquet-indeling in de map voor uw Kafka-onderwerp.
Schema evolutie
Nadat het initiële schema is gedefinieerd, moeten toepassingen dit mogelijk in de loop van de tijd ontwikkelen. Wanneer dit gebeurt, is het van cruciaal belang dat de downstreamconsumenten naadloos kunnen omgaan met gegevens die zijn gecodeerd met zowel het oude als het nieuwe schema. Met compatibiliteitsmodi kunt u bepalen hoe schema's in de loop van de tijd wel of niet kunnen evolueren. Deze modi vormen het contract tussen applicaties die gegevens produceren en consumeren. Raadpleeg voor gedetailleerde informatie over verschillende compatibiliteitsmodi die beschikbaar zijn in het AWS Glue Schema Registry AWS Lijm Schema Register. In ons voorbeeld gebruiken we achterwaartse kambaarheid om ervoor te zorgen dat consumenten zowel de huidige als de vorige schemaversies kunnen lezen. Voer de volgende stappen uit:
- Voeg een nieuwe kolom toe aan de tabel door de volgende opdracht uit te voeren:
- Voeg nieuwe gegevens in de tabel in door de volgende opdracht uit te voeren:
- Kies op de AWS Glue-console: Schemaregisters in het navigatievenster en kies vervolgens schema's.
- Navigeer naar het schema
db1.sampledatabase.moviesversie 2 om de nieuwe versie te controleren van het schema dat is gemaakt voor de movies table movies inclusief de landenkolom die je hebt toegevoegd:
- Controleer op de Amazon S3-console of er gegevens zijn geschreven in Parquet-indeling in de map voor het Kafka-onderwerp.
Opruimen
Verwijder de AWS-bronnen die u in dit bericht hebt gebruikt om ongewenste afschrijvingen op uw AWS-account te helpen voorkomen:
- Navigeer op de Amazon S3-console naar de S3-bucket die is gemaakt door de CloudFormation-sjabloon.
- Selecteer alle bestanden en mappen en kies Verwijder.
- Voer permanent verwijderen in zoals aangegeven en kies Objecten verwijderen.
- Verwijder op de AWS CloudFormation-console de stapel die u hebt gemaakt.
- Wacht tot de stapelstatus verandert in VERWIJDEREN_COMPLETE.
Conclusie
Dit bericht liet zien hoe Amazon MSK, MSK Connect en de AWS Glue Schema Registry kunnen worden gebruikt om een CDC-logstroom te bouwen en schema's voor gegevensstromen te ontwikkelen naarmate de bedrijfsbehoeften veranderen. U kunt dit architectuurpatroon toepassen op andere gegevensbronnen met verschillende Kafka-connectoren. Voor meer informatie, zie de MSK Connect-voorbeelden.
Over de auteur
 Kalyan Janaki is Senior Big Data & Analytics Specialist bij Amazon Web Services. Hij helpt klanten bij het ontwerpen en bouwen van zeer schaalbare, performante en veilige cloudgebaseerde oplossingen op AWS.
Kalyan Janaki is Senior Big Data & Analytics Specialist bij Amazon Web Services. Hij helpt klanten bij het ontwerpen en bouwen van zeer schaalbare, performante en veilige cloudgebaseerde oplossingen op AWS.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-change-data-capture-with-amazon-msk-connect-and-aws-glue-schema-registry/
- :is
- $UP
- 1
- 10
- 11
- 7
- 8
- a
- in staat
- Over
- toegang
- Account
- accuraat
- erkennen
- toegevoegd
- toevoeging
- Alles
- Het toestaan
- toestaat
- al
- Amazone
- Amazon EC2
- Amazon Web Services
- analytics
- en
- apache
- Apache Kafka
- toepassingen
- Solliciteer
- passend
- architectuur
- ZIJN
- AS
- Aurora
- webmaster.
- Beschikbaar
- AWS
- AWS CloudFormatie
- AWS lijm
- BE
- vaardigheden
- betekent
- tussen
- Groot
- Big data
- Bootstrap
- bouw
- bedrijfsdeskundigen
- by
- CAN
- mogelijkheden
- vangen
- Het vastleggen
- gevallen
- catalogus
- CDC
- gecentraliseerde
- verandering
- Wijzigingen
- lasten
- controle
- Controles
- Kies
- klasse
- TROS
- Kolom
- gemeenschap
- verenigbaarheid
- verenigbaar
- compleet
- bestanddeel
- Berekenen
- Configuratie
- ConFluent™
- Verbinden
- versterken
- troosten
- constante
- consumeren
- consument
- Consumenten
- doorlopend
- contract
- onder controle te houden
- Land
- en je merk te creëren
- aangemaakt
- kritisch
- Actueel
- gewoonte
- Klanten
- gegevens
- gegevens integratie
- Gegevensgestuurde
- Database
- databanken
- dagen
- beslissingen
- Standaard
- defaults
- gedefinieerd
- het leveren van
- Demo
- gedemonstreerd
- demonstreert
- implementeren
- ingezet
- beschrijving
- bestemming
- gedetailleerd
- gegevens
- anders
- Onthul Nu
- Nee
- Val
- elk
- elimineert
- waardoor
- eind tot eind
- verzekeren
- waarborgt
- Enter
- Milieu
- fout
- vooral
- Ether (ETH)
- Alle
- ontwikkelen
- voorbeeld
- bestaand
- bestaat
- weinig
- Velden
- Dien in
- Bestanden
- finale
- Voornaam*
- volgend
- Voor
- formulier
- formaat
- oppompen van
- voortbrengen
- gegenereerde
- Groep
- Groep
- handvat
- Behandeling
- gebeurt
- Hebben
- hulp
- helpt
- zeer
- geschiedenis
- gastheer
- HOURS
- Hoe
- How To
- HTML
- http
- HTTPS
- Naaf
- IAM
- het identificeren van
- Identiteit
- uitvoering
- belangrijk
- in
- Inclusief
- indexen
- informatie
- eerste
- installeren
- instantie
- verkrijgen in plaats daarvan
- integreren
- integratie
- intern
- IT
- Java
- jpg
- json
- kafka
- sleutel
- blijven
- Verlof
- bibliotheken
- Erkend
- als
- laden
- het laden
- lokaal
- lang
- gemaakt
- MERKEN
- maken
- beheerd
- meester
- max
- maximaal
- mechanisme
- Bericht
- berichten
- macht
- minuten
- model
- modi
- monitors
- meer
- Films
- bewegend
- meervoudig
- MySQL
- naam
- OP DEZE WEBSITE VIND JE
- Navigatie
- Noodzaak
- nodig
- behoeften
- netwerk
- New
- volgende
- aantal
- of
- Oud
- on
- EEN
- open source
- Overige
- uitgang
- pagina
- paren
- brood
- parameter
- parameters
- deel
- voorbij
- Wachtwoord
- Patronen
- uitvoeren
- blijvend
- kiezen
- Plato
- Plato gegevensintelligentie
- PlatoData
- inpluggen
- plugins
- Post
- voorkomen
- vorig
- verwerking
- produceren
- producent
- vastgoed
- zorgen voor
- mits
- biedt
- Lees
- vast
- real-time
- ontvangen
- record
- archief
- verwijst
- regio
- registreren
- geregistreerd
- register
- bewaarplaats
- vertegenwoordigd
- Resources
- Retourneren
- Rol
- Regel
- lopen
- lopend
- dezelfde
- schaalbare
- naadloos
- Ontdek
- seconden
- beveiligen
- veiligheid
- senior
- gevoelig
- apart
- service
- Diensten
- reeks
- settings
- moet
- Eenvoudig
- vereenvoudigen
- oplossing
- Oplossingen
- sommige
- bron
- bronnen
- specialist
- specifiek
- gespecificeerd
- stack
- Start
- Status
- Stap voor
- Stappen
- mediaopslag
- shop
- winkels
- stream
- streaming
- streams
- structuur
- geschikt
- Ondersteuning
- steunen
- synchroniseren.
- system
- Systems
- tafel
- doelwit
- taken
- sjabloon
- proef
- dat
- De
- De Bron
- Ze
- Deze
- niet de tijd of
- tijdsgevoelig
- Titel
- naar
- onderwerp
- Transacties
- BEURT
- types
- voor
- ongewenste
- bijwerken
- .
- Gebruiker
- waarde
- Values
- versie
- web
- webservices
- welke
- wil
- ruiten
- Met
- werker
- werknemers
- werkzaam
- Bedrijven
- geschreven
- Your
- zephyrnet