Amazone Athene is een interactieve query-service waarmee u eenvoudig gegevens kunt analyseren in Amazon eenvoudige opslagservice (Amazon S3) en gegevensbronnen in AWS, on-premises of andere cloudsystemen die SQL of Python gebruiken. Athena is gebouwd op open-source Trino- en Presto-engines en Apache Spark-frameworks, zonder dat er voorzieningen of configuratie-inspanningen nodig zijn. Athena is serverloos, dus u hoeft geen infrastructuur te beheren en u betaalt alleen voor de zoekopdrachten die u uitvoert.
Apache-ijsberg is een open tabelformaat voor zeer grote analytische datasets. Het beheert grote verzamelingen bestanden als tabellen en ondersteunt moderne analytische data lake-bewerkingen zoals invoegen, bijwerken, verwijderen en tijdreizen op recordniveau. Athena ondersteunt lees-, tijdreis-, schrijf- en DDL-query's voor Apache Iceberg-tabellen die de Apache Parquet-indeling gebruiken voor gegevens en de AWS-lijmgegevenscatalogus voor hun metawinkel.
Functie-engineering is een proces waarbij ruwe gegevens (afbeeldingen, tekstbestanden, video's, enzovoort) worden geïdentificeerd en getransformeerd, ontbrekende gegevens worden aangevuld en een of meer betekenisvolle gegevenselementen worden toegevoegd om context te bieden, zodat een machine learning-model (ML) ervan kan leren. Gegevenslabeling is vereist voor verschillende gebruiksscenario's, waaronder prognoses, computervisie, natuurlijke taalverwerking en spraakherkenning.
Gecombineerd met de mogelijkheden van Athena levert Apache Iceberg een vereenvoudigde workflow voor datawetenschappers om nieuwe datafuncties te creëren zonder de volledige dataset te hoeven kopiëren of opnieuw te creëren. U kunt functies maken met behulp van standaard SQL op Athena zonder gebruik te maken van een andere service voor functie-engineering. Datawetenschappers kunnen de tijd die wordt besteed aan het voorbereiden en kopiëren van datasets verminderen en zich in plaats daarvan concentreren op het ontwikkelen van datafuncties, het experimenteren en het analyseren van data op schaal.
In dit bericht bespreken we de voordelen van het gebruik van Athena met het open-tabelformaat Apache Iceberg en hoe het algemene feature-engineeringtaken voor datawetenschappers vereenvoudigt. We demonstreren hoe Athena een bestaande tabel in Apache Iceberg-indeling kan converteren, vervolgens kolommen kan toevoegen, kolommen kan verwijderen en de gegevens in de tabel kan wijzigen zonder de gegevensset opnieuw te maken of te kopiëren, en deze mogelijkheden kan gebruiken om nieuwe functies op Apache Iceberg-tabellen te creëren.
Overzicht oplossingen
Datawetenschappers zijn over het algemeen gewend om met grote datasets te werken. Gegevenssets worden meestal opgeslagen in JSON, CSV, ORC of Apache Parket formaat, of soortgelijke voor lezen geoptimaliseerde formaten voor snelle leesprestaties. Datawetenschappers creëren vaak nieuwe datafuncties en vullen dergelijke datafuncties aan met geaggregeerde en aanvullende gegevens. Historisch gezien werd deze taak volbracht door een weergave bovenaan de tabel te maken met de onderliggende gegevens in Apache Parquet-indeling, waarbij dergelijke kolommen en gegevens tijdens runtime werden toegevoegd, of door een nieuwe tabel met extra kolommen te maken. Hoewel deze workflow zeer geschikt is voor veel gebruiksscenario's, is deze inefficiënt voor grote datasets, omdat gegevens tijdens runtime moeten worden gegenereerd of datasets moeten worden gekopieerd en getransformeerd.
Athene heeft geïntroduceerd ACID-transactie (atomiciteit, consistentie, isolatie, duurzaamheid). mogelijkheden die INSERT-, UPDATE-, DELETE-, MERGE- en tijdreisoperaties toevoegen Apache Iceberg-tafels. Deze mogelijkheden stellen datawetenschappers in staat nieuwe datafuncties te creëren en bestaande datafuncties op bestaande datasets te verwijderen zonder zich zorgen te hoeven maken over het kopiëren of transformeren van de dataset of het abstraheren ervan met een bepaalde visie. Datawetenschappers kunnen zich concentreren op feature engineering-werk en vermijden het kopiëren en transformeren van de datasets.
De bewerking Athena Iceberg UPDATE schrijft Apache Iceberg-positieverwijderingsbestanden en nieuw bijgewerkte rijen als gegevensbestanden in dezelfde transactie. Met één UPDATE-verklaring kunt u recordcorrecties uitvoeren.
Met de release van Athena engine versie 3 zijn de mogelijkheden voor Apache Iceberg-tabellen verbeterd met de ondersteuning voor bewerkingen zoals MAAK TABEL ALS SELECTIE (CTAS) en MERGE-opdrachten die het levenscyclusbeheer van uw Iceberg-gegevens stroomlijnen. CTAS maakt het snel en efficiënt om tabellen te maken vanuit andere formaten zoals Apache Paquet en SAMENVOEGEN IN voorwaardelijke updates, verwijderingen of invoegingen van rijen in een ijsbergtabel. Eén enkele instructie kan acties voor bijwerken, verwijderen en invoegen combineren.
Voorwaarden
Zet een Athena-werkgroep op met Athena-engine versie 3 om CTAS- en MERGE-opdrachten te gebruiken met een Apache Iceberg-tabel. Om uw bestaande Athena-engine te upgraden naar versie 3 in uw Athena-werkgroep, volgt u de instructies in Upgrade naar Athena Engine versie 3 om de queryprestaties te verbeteren en toegang te krijgen tot meer analysefuncties of verwijzen naar De motorversie wijzigen in de Athena-console.
dataset
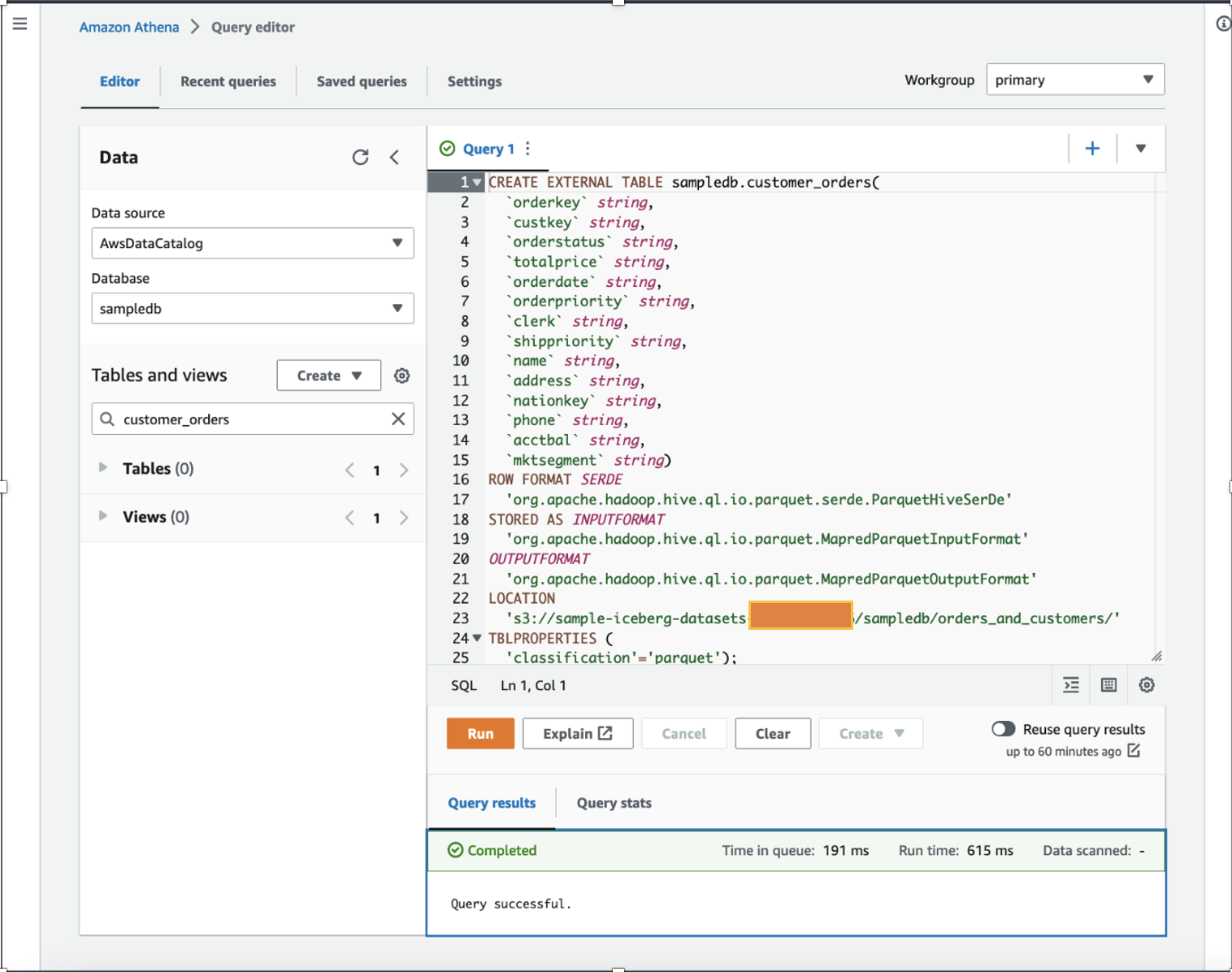
Ter demonstratie gebruiken we een Apache Parquet-tabel die enkele miljoenen records bevat met willekeurig verdeelde fictieve verkoopgegevens van de afgelopen jaren, opgeslagen in een S3-bucket. Downloaden de dataset, pak deze uit naar uw lokale computer en upload deze naar uw S3-bucket. In dit bericht hebben we onze dataset geüpload naar s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/.
De volgende tabel toont de indeling van de tabel customer_orders.
| Kolomnaam | Data type | Omschrijving |
| bestelsleutel | snaar | Bestelnummer van de bestelling |
| sleutel | snaar | Klantidentificatienummer |
| bestelstatus | snaar | Status van de bestelling |
| totale prijs | snaar | Totale prijs van de bestelling |
| besteldatum | snaar | Datum van de bestelling |
| volgordeprioriteit | snaar | Prioriteit van de bestelling |
| klerk | snaar | Naam van de medewerker die de bestelling heeft verwerkt |
| prioriteit van het schip | snaar | Prioriteit op de verzending |
| naam | snaar | Klantnaam |
| adres | snaar | Klant adres |
| natiesleutel | snaar | Landsleutel klant |
| phone | snaar | Telefoonnummer klant |
| acctbal | snaar | Saldo van klantrekening |
| mktsegment | snaar | Klantenmarktsegment |
Functie-engineering uitvoeren
Als datawetenschapper willen wij presteren functie-engineering op de klantordergegevens door de berekende totale aankopen over één jaar en de gemiddelde aankopen over één jaar voor elke klant in de bestaande dataset op te tellen. Voor demonstratiedoeleinden hebben we de customer_orders tafel in de sampledb database met behulp van Athena, zoals weergegeven in de volgende DDL-opdracht. (U kunt al uw bestaande datasets gebruiken en de stappen volgen die in dit bericht worden vermeld.) De customer_orders dataset is gegenereerd en opgeslagen in de S3-bucketlocatie s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/ in Parquet-formaat. Deze tafel is geen Apache Iceberg-tafel.
![]()
Valideer de gegevens in de tabel door een query uit te voeren:
![]()
We willen nieuwe functies aan deze tabel toevoegen om een beter inzicht te krijgen in de verkoop aan klanten, wat kan resulteren in snellere modeltraining en waardevollere inzichten. Als u nieuwe functies aan de gegevensset wilt toevoegen, converteert u de customer_orders Athena-tafel naar Apache-ijsbergtafel op Athena. Probleem een CTAS query-instructie om een nieuwe tabel met Apache Iceberg-indeling te maken vanuit de customer_orders tafel. Daarbij wordt een nieuwe functie toegevoegd om het totale aankoopbedrag van het afgelopen jaar (max. jaar van de dataset) van elke klant te achterhalen.
In de volgende CTAS-query wordt een nieuwe kolom genoemd one_year_sales_aggregate met de standaardwaarde als 0.0 van gegevenstype double wordt toegevoegd en table_type is ingesteld op ICEBERG:
![]()
Voer de volgende query uit om de gegevens in de Apache Iceberg-tabel met de nieuwe kolom te verifiëren one_year_sales_aggregate waarden als 0.0:
![]()
We willen de waarden voor de nieuwe functie invullen one_year_sales_aggregate in de dataset om het totale aankoopbedrag voor elke klant te krijgen op basis van hun aankopen in het afgelopen jaar (max. jaar van de dataset). Geef een MERGE-queryinstructie uit aan de Apache Iceberg-tabel met behulp van Athena om waarden in te vullen voor de one_year_sales_aggregate functie:
![]()
Voer de volgende query uit om de bijgewerkte waarde voor de totale uitgaven van elke klant in het afgelopen jaar te valideren:
![]()
We besluiten een nieuwe functie toe te voegen aan een bestaande Apache Iceberg-tabel om het gemiddelde aankoopbedrag van elke klant in het afgelopen jaar te berekenen en op te slaan. Geef een ALTER-queryinstructie uit om een nieuwe kolom toe te voegen aan een bestaande tabel voor het object one_year_sales_average:
![]()
Voordat u de waarden voor dit nieuwe element invult, kunt u de standaardwaarde voor het element instellen one_year_sales_average naar 0.0. Gebruik dezelfde Apache Iceberg-tabel op Athena en voer een UPDATE-queryinstructie uit om de waarde voor de nieuwe functie in te vullen als 0.0:
![]()
Voer de volgende query uit om te verifiëren dat de bijgewerkte waarde voor de gemiddelde uitgaven van elke klant in het afgelopen jaar is ingesteld 0.0:
![]()
Nu willen we de waarden voor de nieuwe functie invullen one_year_sales_average in de dataset om het gemiddelde aankoopbedrag voor elke klant te krijgen op basis van hun aankopen in het afgelopen jaar (max. jaar van de dataset). Geef een MERGE-queryinstructie uit aan de bestaande Apache Iceberg-tabel op Athena met behulp van de Athena-engine om waarden voor de functie in te vullen one_year_sales_average:
![]()
Voer de volgende query uit om de bijgewerkte waarden voor de gemiddelde uitgaven van elke klant te verifiëren:
![]()
Zodra extra datafuncties aan de dataset zijn toegevoegd, gaan datawetenschappers over het algemeen door met het trainen van ML-modellen en het maken van conclusies met behulp van Amazon Sagemaker of een gelijkwaardige toolset.
Conclusie
In dit bericht hebben we gedemonstreerd hoe je feature-engineering kunt uitvoeren met Athena met Apache Iceberg. We hebben ook gedemonstreerd hoe we de CTAS-query gebruiken om een Apache Iceberg-tabel op Athena te maken op basis van een bestaande gegevensset in Apache Parquet-indeling, nieuwe functies toe te voegen aan een bestaande Apache Iceberg-tabel op Athena met behulp van de ALTER-query, en UPDATE- en MERGE-query-instructies te gebruiken om de kenmerkwaarden van bestaande kolommen.
We raden u aan om CTAS-query's te gebruiken om snel en efficiënt tabellen te maken, en de MERGE-queryinstructie te gebruiken om tabellen in één stap te synchroniseren om de gegevensvoorbereiding te vereenvoudigen en taken bij te werken bij het transformeren van de functies met Athena met Apache Iceberg. Als u opmerkingen of feedback heeft, kunt u deze achterlaten in het opmerkingengedeelte.
Over de auteurs
![]() Vivek Gautam is een Data Architect met specialisatie in data lakes bij AWS Professional Services. Hij werkt met zakelijke klanten aan het bouwen van dataproducten, analyseplatforms en oplossingen op AWS. Als Vivek geen moderne dataplatforms bouwt en ontwerpt, is hij een voedselliefhebber die ook graag nieuwe reisbestemmingen ontdekt en wandelingen maakt.
Vivek Gautam is een Data Architect met specialisatie in data lakes bij AWS Professional Services. Hij werkt met zakelijke klanten aan het bouwen van dataproducten, analyseplatforms en oplossingen op AWS. Als Vivek geen moderne dataplatforms bouwt en ontwerpt, is hij een voedselliefhebber die ook graag nieuwe reisbestemmingen ontdekt en wandelingen maakt.
![]() Michail Vaynshteyn is een oplossingsarchitect bij Amazon Web Services. Mikhail werkt samen met klanten in de gezondheidszorg en life sciences om oplossingen te ontwikkelen die de resultaten van patiënten helpen verbeteren. Mikhail is gespecialiseerd in data-analysediensten.
Michail Vaynshteyn is een oplossingsarchitect bij Amazon Web Services. Mikhail werkt samen met klanten in de gezondheidszorg en life sciences om oplossingen te ontwikkelen die de resultaten van patiënten helpen verbeteren. Mikhail is gespecialiseerd in data-analysediensten.
![]() Naresh Gautam is een Data Analytics en AI/ML leider bij AWS met 20 jaar ervaring, die het leuk vindt om klanten te helpen bij het ontwerpen van zeer beschikbare, krachtige en kosteneffectieve data-analyse en AI/ML-oplossingen om klanten te voorzien van datagestuurde besluitvorming . In zijn vrije tijd houdt hij van meditatie en koken.
Naresh Gautam is een Data Analytics en AI/ML leider bij AWS met 20 jaar ervaring, die het leuk vindt om klanten te helpen bij het ontwerpen van zeer beschikbare, krachtige en kosteneffectieve data-analyse en AI/ML-oplossingen om klanten te voorzien van datagestuurde besluitvorming . In zijn vrije tijd houdt hij van meditatie en koken.
![]() Harsha Tadiparthi is een specialist Principal Solutions Architect, Analytics bij AWS. Hij vindt het leuk om complexe klantproblemen in databases en analyses op te lossen en succesvolle resultaten te leveren. Buiten zijn werk brengt hij graag tijd door met zijn gezin, films kijken en waar mogelijk reizen.
Harsha Tadiparthi is een specialist Principal Solutions Architect, Analytics bij AWS. Hij vindt het leuk om complexe klantproblemen in databases en analyses op te lossen en succesvolle resultaten te leveren. Buiten zijn werk brengt hij graag tijd door met zijn gezin, films kijken en waar mogelijk reizen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- EVM Financiën. Uniforme interface voor gedecentraliseerde financiën. Toegang hier.
- Quantum Media Groep. IR/PR versterkt. Toegang hier.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/accelerate-data-science-feature-engineering-on-transactional-data-lakes-using-amazon-athena-with-apache-iceberg/
- : heeft
- :is
- :niet
- :waar
- $UP
- 10
- 100
- 12
- 17
- 20
- 20 jaar
- 23
- 27
- 7
- a
- Over
- versnellen
- toegang
- volbracht
- Account
- acties
- toevoegen
- toegevoegd
- toe te voegen
- Extra
- adres
- AI / ML
- ook
- Hoewel
- Amazone
- Amazone Athene
- Amazon Sage Maker
- Amazon Web Services
- bedragen
- an
- analytisch
- Analytisch
- analytics
- analyseren
- het analyseren van
- en
- Nog een
- elke
- apache
- Apache Spark
- ZIJN
- AS
- At
- Beschikbaar
- gemiddelde
- vermijd
- AWS
- AWS professionele services
- gebaseerde
- BE
- omdat
- geweest
- betekent
- bouw
- Gebouw
- bebouwd
- by
- berekend
- CAN
- mogelijkheden
- gevallen
- classificatie
- Cloud
- collecties
- Kolom
- columns
- combineren
- opmerkingen
- Gemeen
- complex
- Berekenen
- computer
- Computer visie
- Configuratie
- bevat
- verband
- converteren
- koken
- kopiëren
- Correcties
- kostenefficient
- en je merk te creëren
- aangemaakt
- Wij creëren
- klant
- Klanten
- gegevens
- gegevens Analytics
- Datameer
- data science
- data scientist
- Gegevensgestuurde
- Database
- databanken
- datasets
- Datum
- beslissen
- Besluitvorming
- diepere
- Standaard
- het leveren van
- levert
- tonen
- gedemonstreerd
- ontwerpen
- bestemmingen
- verdeeld
- doen
- verdubbelen
- Val
- duurzaamheid
- elk
- En het is heel gemakkelijk
- doeltreffend
- efficiënt
- inspanning
- beide
- geeft je de mogelijkheid
- machtigen
- in staat stellen
- aanmoedigen
- Motor
- Engineering
- Motoren
- verbeterde
- Enterprise
- zakelijke klanten
- enthousiast
- Geheel
- Gelijkwaardig
- Ether (ETH)
- bestaand
- ervaring
- Verken
- extern
- vals
- familie
- SNELLE
- sneller
- Kenmerk
- Voordelen
- feedback
- Bestanden
- Focus
- volgen
- volgend
- eten
- Voor
- formaat
- frameworks
- Gratis
- oppompen van
- algemeen
- gegenereerde
- krijgen
- Go
- Groep
- Hadoop
- Hebben
- he
- gezondheidszorg
- hulp
- het helpen van
- hoge performantie
- zeer
- Hikes
- zijn
- historisch
- Bijenkorf
- Hoe
- How To
- HTML
- HTTPS
- Identificatie
- het identificeren van
- if
- afbeeldingen
- verbeteren
- in
- Inclusief
- Laat uw omzet
- ondoeltreffend
- Infrastructuur
- Inzetstukken
- inzichten
- verkrijgen in plaats daarvan
- instructies
- interactieve
- in
- geïntroduceerd
- isolatie
- kwestie
- IT
- jpg
- json
- etikettering
- meer
- taal
- Groot
- Achternaam*
- Layout
- leider
- LEARN
- leren
- Verlof
- Life
- Bio
- levenscyclus van uw product
- LIMIT
- lokaal
- plaats
- houdt
- machine
- machine learning
- maken
- MERKEN
- beheer
- management
- beheert
- veel
- Markt
- op elkaar afgestemd
- max
- zinvolle
- Meditatie
- vermeld
- gaan
- miljoen
- vermist
- ML
- model
- modellen
- Modern
- wijzigen
- meer
- Films
- naam
- Genoemd
- natie
- Naturel
- Natuurlijke taal
- Natural Language Processing
- Noodzaak
- nodig
- New
- nieuwe functie
- Nieuwe mogelijkheden
- onlangs
- geen
- aantal
- of
- vaak
- on
- EEN
- Slechts
- open
- open source
- operatie
- Operations
- or
- orders
- Overige
- onze
- resultaten
- buiten
- verleden
- Betaal
- uitvoeren
- prestatie
- phone
- platforms
- Plato
- Plato gegevensintelligentie
- PlatoData
- dan
- positie
- mogelijk
- Post
- voorbereiding
- prijs
- Principal
- problemen
- verwerkt
- verwerking
- Producten
- professioneel
- zorgen voor
- inkomsten
- aankopen
- doeleinden
- Python
- queries
- snel
- Rauw
- ruwe data
- Lees
- erkenning
- record
- archief
- verminderen
- los
- nodig
- resultaat
- beoordelen
- RIJ
- lopen
- lopend
- sagemaker
- verkoop
- dezelfde
- Scale
- Wetenschap
- WETENSCHAPPEN
- Wetenschapper
- wetenschappers
- sectie
- Serverless
- service
- Diensten
- reeks
- verscheidene
- getoond
- Shows
- gelijk
- Eenvoudig
- vereenvoudigd
- vereenvoudigen
- single
- So
- Oplossingen
- Het oplossen van
- bronnen
- Vonk
- specialist
- specialiseert
- toespraak
- Spraakherkenning
- besteden
- besteed
- SQL
- standaard
- Statement
- verklaringen
- Stap voor
- Stappen
- mediaopslag
- shop
- opgeslagen
- gestroomlijnd
- Draad
- geslaagd
- dergelijk
- ondersteuning
- steunen
- Systems
- tafel
- Taak
- taken
- dat
- De
- de fusie
- hun
- Ze
- harte
- Er.
- Deze
- dit
- niet de tijd of
- Tijdreizen
- naar
- top
- Totaal
- Trainen
- Trainingen
- transactie
- transactionele
- getransformeerd
- transformeren
- reizen
- type dan:
- die ten grondslag liggen
- begrip
- bijwerken
- bijgewerkt
- updates
- upgrade
- geüpload
- .
- gebruik
- doorgaans
- BEVESTIG
- waardevol
- waarde
- Values
- divers
- controleren
- versie
- zeer
- via
- Video's
- Bekijk
- visie
- willen
- was
- Bekijk de introductievideo
- we
- web
- webservices
- waren
- wanneer
- telkens als
- welke
- en
- WIE
- Met
- zonder
- Mijn werk
- workflow
- Werkgroep
- werkzaam
- Bedrijven
- zou
- schrijven
- jaar
- jaar
- u
- Your
- zephyrnet
- Postcode