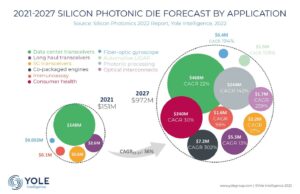
Volgens sommige AI-dromers zijn we er bijna. We hebben niet langer hardware- of software-ontwerpexperts nodig; alleen iemand die de basisvereisten invoert, waarna volledig gerealiseerde systeemtechnologieën aan de andere kant zullen afhaken. De meningen van deskundigen in de sector zijn enthousiast, maar minder hyperbolisch. Bob O'Donnell, president, oprichter en hoofdanalist bij TECHnalysis Research modereerde een panel over dit onderwerp op CadenceLIVE met panelleden Rob Christy (technisch directeur en Distinguished Engineer, Implementation – Central Engineering Systems bij Arm), Prabal Dutta (Associate Professor, Electrical Engineering en Computerwetenschappen, aan de Universiteit van Californië, Berkeley), Dr. Paul Cunningham (Senior Vice President en General Manager van de System & Verification Group bij Cadence), Chris Rowen (VP Engineering, Collaboration AI bij Cisco) en Igor Markov (Research Wetenschapper bij Meta) – mensen die meer dan de meesten van ons weten over chipontwerp en AI. Alle panelleden boden waardevolle inzichten. Ik heb de discussie hier samengevat.

Zal generatieve AI het chipontwerp veranderen?
De consensus was ja en nee. AI kan een groot deel van de mens-in-de-lus-interactie automatiseren bovenop de noodzakelijke bouwsteentechnologieën: plaats-en-route, logische simulatie, circuitsimulatie, enz. Dit stelt ons in staat een breder – misschien veel breder – scala aan mogelijkheden te verkennen. opties dan mogelijk zou zijn via handmatige verkenning.
AI is fundamenteel probabilistisch, ideaal waar probabilistische antwoorden geschikt zijn (over het algemeen verbeterend ten opzichte van een basislijn), maar niet waar hoge precisie verplicht is (bijvoorbeeld het synthetiseren van poorten). Bovendien zijn generatieve modellen tegenwoordig zeer goed op een beperkt aantal terreinen, en niet noodzakelijkerwijs elders. Ze zijn bijvoorbeeld erg inefficiënt in wiskundige toepassingen. Het is ook belangrijk om te onthouden dat ze in werkelijkheid geen vaardigheden leren, maar leren nabootsen. Er is geen onderliggend begrip van bijvoorbeeld elektrotechniek, natuurkunde of wiskunde. In de praktijk kunnen sommige beperkingen worden gecompenseerd door een sterke verificatie.
Dat gezegd hebbende, is het opmerkelijk wat ze kunnen doen op het gebied van taaltoepassingen. In andere enorme domeinspecifieke datasets, zoals in netwerken, zouden grote modellen structuur kunnen leren en veel interessante dingen kunnen afleiden die niets met taal te maken hebben. Je zou je superlineair leren op sommige domeinen kunnen voorstellen als het leren zou kunnen botsen met wereldwijde corpora, ervan uitgaande dat we netelige IP- en privacykwesties onder de knie kunnen krijgen.
Kunnen generatieve methoden de ontwikkeling van vaardigheden stimuleren?
Op het gebied van halfgeleider- en systeemontwerp worden we geconfronteerd met een ernstig tekort aan talent. Panelleden zijn van mening dat AI jongere, minder ervaren ingenieurs zal helpen sneller te accelereren naar een meer ervaren prestatieniveau. Deskundigen zullen ook beter worden en meer tijd krijgen om nieuwe technieken te bestuderen en toe te passen vanuit de voortdurend verleggende grenzen in microarchitectuur- en implementatieonderzoek. Dit zou een herinnering moeten zijn dat op leren gebaseerde methoden zullen helpen bij het verkrijgen van ‘elke ervaren ontwerper weet’-kennis, maar altijd achter de expertcurve zullen blijven.
Zullen dergelijke tools ons in staat stellen verschillende soorten chips te maken? Op de korte termijn zal AI helpen betere chips te maken in plaats van nieuwe soorten chips. Generatieve modellen zijn goed met reeksen stappen; als je vaak hetzelfde ontwerpproces doorloopt, kan AI die sequenties beter optimaliseren/automatiseren dan wij. Verderop kunnen generatieve methoden ons helpen nieuwe soorten AI-chips te bouwen, wat interessant zou kunnen zijn omdat we ons realiseren dat steeds meer problemen kunnen worden herschikt als AI-problemen.
Een ander interessant gebied is het ontwerp met meerdere matrijzen. Dit is zelfs voor ontwerpexperts een nieuw gebied. Tegenwoordig denken we aan chipletblokken met interfaces die zijn opgebouwd als vooraf bepaalde Lego-stukken. Generatieve AI kan nieuwe manieren voorstellen om betere optimalisaties te ontsluiten en andere antwoorden bieden dan zelfs experts snel zouden kunnen vinden.
Valkuilen
Wat zijn de potentiële valkuilen bij het toepassen van generatieve AI op chip- en/of systeemontwerp? Wij vertegenwoordigen zelf één probleem. Als de AI het goed doet, begin je er dan meer op te vertrouwen dan zou moeten? Soortgelijke vragen zijn al een punt van zorg voor autonoom rijden en autonome bewapende drones. Vertrouwen is een delicaat evenwicht. We kunnen vertrouwen maar verifiëren, maar wat als verificatie ook op leren gebaseerd wordt om met complexiteit om te gaan? Wanneer verificatie-AI de juistheid van een door AI gegenereerd ontwerp bewijst, waar overschrijden we dan de grens tussen gerechtvaardigd en ongerechtvaardigd vertrouwen?
ChatGPT is een waarschuwend voorbeeld. De grote fascinatie en de grote misvatting van ChatGPT is dat je alles kunt vragen. Wij staan versteld van de specifieke slimheid en van het feit dat het zoveel verschillende terreinen bestrijkt. Het voelt alsof het automatische algemene intelligentieprobleem is opgelost.
Maar bijna alle toepassingen in de echte wereld zullen veel beperkter zijn en op andere criteria worden beoordeeld dan het vermogen om te verbazen of te entertainen. In het bedrijfsleven, de techniek en andere toepassingen in de echte wereld verwachten we resultaten van hoge kwaliteit. Het lijdt geen twijfel dat dergelijke toepassingen steeds beter zullen worden, maar als de hype te ver vooruitloopt op de werkelijkheid, zullen de verwachtingen de bodem in worden geslagen en zal het vertrouwen in verdere vooruitgang stagneren.
Pragmatischer: kunnen we gevestigde puntvaardigheden integreren in generatieve systemen? Nogmaals, ja en nee. Er zijn enkele augmented-modellen die zeer productief zijn en rekenkundige en formulemanipulatie aankunnen, bijvoorbeeld WolframAlpha, dat al is geïntegreerd met ChatGPT. WolframAlpha biedt symbolisch en numeriek redeneren, als aanvulling op AI. Beschouw AI als de mens-machine-interface en de WolframAlpha-augmentatie als het diepe begrip achter die interface.
Is het mogelijk om augmentatie te omzeilen, om vaardigheden rechtstreeks in de AI te leren en als modules te laden, zoals Neo King Fu in de Matrix kon leren? Hoe lokaal is de weergave van dergelijke vaardigheden in taalmodellen? Helaas worden aangeleerde vaardigheden zelfs nu nog weergegeven door gewichten in het model en zijn ze mondiaal. In zoverre is het niet mogelijk om een getrainde module te laden als uitbreiding op een bestaand getraind platform.
Er is een enigszins verwante vraag over de waarde van wereldwijde training versus interne training. De theorie is dat als ChatGPT zo goed werk kan leveren door te trainen op een mondiale dataset, ontwerptools hetzelfde zouden moeten kunnen doen. Deze theorie struikelt op twee manieren. Ten eerste zijn de ontwerpgegevens die nodig zijn voor training zeer bedrijfseigen en mogen ze onder geen enkele omstandigheid worden gedeeld. Mondiale training lijkt ook niet nodig; EDA-bedrijven kunnen een goed startpunt bieden op basis van ontwerpvoorbeelden die routinematig worden gebruikt om niet-AI-tools te verfijnen. Klanten die op die basis voortbouwen en trainen met behulp van hun eigen gegevens, rapporteren betekenisvolle verbeteringen voor hun doeleinden.
Ten tweede is het onduidelijk of gedeeld leren binnen veel verschillende ontwerpdomeinen überhaupt nuttig zou zijn. Elk bedrijf wil optimaliseren voor zijn eigen speciale voordelen, niet via een multifunctionele soep van ‘best practices’.
Hoop op hergebruik in AI en kijk vooruit
Zitten we, gegeven eerdere antwoorden, vast aan unieke modellen voor elk beperkt domein? Het is niet duidelijk dat één architectuur alles kan doen, maar open interfaces zullen een ecosysteem van mogelijkheden stimuleren, misschien als een protocolstapel. Apps zullen uiteenlopen, maar er kan nog steeds veel gedeelde infrastructuur zijn. Als we aan toepassingen denken die een reeks getrainde modellen vereisen, zijn sommige van die modellen mogelijk minder bedrijfseigen dan andere.
Vooruitkijkend is generatieve AI een snel bewegende trein. Er verschijnen maandelijks, zelfs dagelijks, nieuwe ideeën, dus wat vandaag niet mogelijk is, kan relatief snel mogelijk worden of op een andere manier worden opgelost. Er zijn nog steeds grote privacyproblemen op elk gebied, afhankelijk van training in brede datasets. Bewijzen dat aangeleerd gedrag in dergelijke gevallen geen inbreuk maakt op patenten of bedrijfsgeheimen lijkt een heel moeilijk probleem, dat waarschijnlijk het beste kan worden vermeden door dergelijke training te beperken tot niet-gevoelige vaardigheden.
Ondanks alle kanttekeningen is dit een gebied waar we niet bang voor moeten zijn. Generatieve AI zal transformatief zijn. We moeten onszelf trainen om AI beter in te zetten in ons dagelijks leven. En op zijn beurt het toepassen van ons geleerde om ambitieuzer te zijn voor ons gebruik in ontwerptechnologieën.
Geweldig gesprek. Hoopvol, met goede inzichten in beperkingen en praktische toepassingen.
Lees ook:
Takeaways van CadenceLIVE 2023
Anirudh-keynote bij Cadence Live
Petri Nets die DRAM-protocollen valideren. Innovatie in verificatie
Deel dit bericht via:
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://semiwiki.com/artificial-intelligence/328667-opinions-on-generative-ai-at-cadencelive/
- : heeft
- :is
- :niet
- :waar
- $UP
- a
- vermogen
- in staat
- Over
- versnellen
- over
- voorschotten
- voordelen
- weer
- tegen
- vooruit
- AI
- Alles
- toelaten
- toestaat
- al
- ook
- altijd
- ambitieus
- an
- analist
- en
- antwoorden
- elke
- iets
- toepassingen
- Solliciteer
- Het toepassen van
- passend
- apps
- architectuur
- ZIJN
- GEBIED
- gebieden
- ARM
- rond
- AS
- Associëren
- At
- aangevuld
- automatiseren
- Automatisch
- autonoom
- vermeden
- Balance
- baseren
- gebaseerde
- Baseline
- basis-
- BE
- omdat
- worden
- wordt
- geweest
- achter
- geloofd wie en wat je bent
- heilzaam
- Berkeley
- BEST
- Betere
- tussen
- Groot
- Blok
- Blokken
- bob
- boost
- bouw
- Gebouw
- bebouwd
- bedrijfsdeskundigen
- maar
- by
- Cadans
- Californië
- CAN
- mogelijkheden
- gevallen
- Voorzichtig
- centraal
- verandering
- ChatGPT
- chef
- spaander
- chips
- Chris
- situatie
- Cisco
- duidelijk
- samenwerking
- Bedrijven
- afstand
- ingewikkeldheid
- computer
- Bezorgdheid
- Overeenstemming
- permanent
- kon
- heeft betrekking op
- en je merk te creëren
- criteria
- Cross
- curve
- Klanten
- dagelijks
- gegevens
- datasets
- transactie
- deep
- Afhankelijk
- Design
- ontwerpproces
- leesmaatjes
- Ontwikkeling
- anders
- direct
- Director
- discussie
- Gedistingeerd
- Divergeren
- do
- doen
- domein
- domeinen
- Dont
- twijfelen
- aandrijving
- Drones
- Val
- e
- elk
- Vroeger
- ecosysteem
- Elektrotechniek
- elders
- aanmoedigen
- einde
- ingenieur
- Engineering
- Ingenieurs
- vermaken
- enthousiast
- gevestigd
- etc
- Ether (ETH)
- Zelfs
- alles
- voorbeeld
- voorbeelden
- bestaand
- uit te breiden
- verwachten
- verwachtingen
- ervaren
- expert
- deskundigen
- exploratie
- Verken
- uitbreiding
- Gezicht
- feit
- ver
- snelbewegend
- Velden
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- Voornaam*
- Voor
- formule
- Naar voren
- oprichter
- oppompen van
- Frontiers
- fu
- geheel
- fundamenteel
- verder
- Gates
- Algemeen
- algemene intelligentie
- algemeen
- generatief
- generatieve AI
- krijgen
- het krijgen van
- Globaal
- gaan
- goed
- goede baan
- groot
- Groep
- handvat
- Hard
- Hardware
- Hebben
- hulp
- hier
- Hoge
- zeer
- hoopvol
- Hoe
- HTTPS
- Hype
- i
- ideaal
- ideeën
- if
- beeld
- uitvoering
- belangrijk
- verbeteren
- verbetering
- het verbeteren van
- in
- Anders
- -industrie
- ondoeltreffend
- Infrastructuur
- Innovatie
- invoer
- inzichten
- integreren
- geïntegreerde
- Intelligentie
- wisselwerking
- interessant
- Interface
- interfaces
- in
- IP
- problemen
- IT
- HAAR
- Jobomschrijving:
- jpg
- geoordeeld
- Grondtoon
- koning
- blijven
- kennis
- taal
- Groot
- LEARN
- geleerd
- leren
- minder
- Niveau
- Hefboomwerking
- als
- beperkingen
- Beperkt
- Lijn
- Lives
- laden
- het laden
- lokaal
- logica
- langer
- op zoek
- lot
- maken
- manager
- verplicht
- Manipulatie
- handboek
- veel
- massief
- meester
- wiskunde
- Matrix
- max-width
- Mei..
- zinvolle
- meta
- methoden
- macht
- model
- modellen
- module
- Modules
- maandelijks
- meer
- meest
- veel
- Dan moet je
- Nabij
- nodig
- noodzakelijk
- Noodzaak
- nodig
- NEO
- Netten
- netwerken
- nooit
- New
- geen
- niets
- nu
- of
- aangeboden
- compenseren
- on
- EEN
- open
- Meningen
- Optimaliseer
- Opties
- or
- Overige
- Overig
- onze
- onszelf
- uit
- het te bezitten.
- paneel
- Octrooien
- Paul
- prestatie
- Fysica
- stukken
- platform
- Plato
- Plato gegevensintelligentie
- PlatoData
- punt
- mogelijk
- Post
- potentieel
- PRAKTISCH
- Praktische toepassingen
- precisie
- president
- privacy
- waarschijnlijk
- probleem
- problemen
- productief
- Hoogleraar
- progressief
- gepatenteerd
- protocol
- protocollen
- zorgen voor
- biedt
- het verstrekken van
- doeleinden
- kwaliteit
- vraag
- Contact
- sneller
- snel
- liever
- Lees
- echte wereld
- Realiteit
- realiseerde
- realiseren
- werkelijk
- verfijnen
- verwant
- relatief
- opmerkelijk
- niet vergeten
- verslag
- vertegenwoordigen
- vertegenwoordiging
- vertegenwoordigd
- vereisen
- Voorwaarden
- onderzoek
- Resultaten
- hergebruiken
- beroven
- routinematig
- lopen
- Zei
- dezelfde
- WETENSCHAPPEN
- Wetenschapper
- lijkt
- halfgeleider
- senior
- Volgorde
- ernstig
- reeks
- gedeeld
- schaarste
- moet
- gelijk
- simulatie
- bekwaamheid
- vaardigheden
- So
- Software
- sommige
- Iemand
- enigszins
- Spoedig
- special
- specifiek
- stack
- begin
- Start
- Stappen
- Still
- sterke
- structuur
- Studie
- struikelt
- dergelijk
- stel
- system
- Systems
- Systeemontwerp
- Talent
- Talk
- Technisch
- technieken
- Technologies
- termijn
- neem contact
- dat
- De
- hun
- harte
- theorie
- Er.
- ze
- spullen
- denken
- dit
- die
- Door
- niet de tijd of
- keer
- naar
- vandaag
- ook
- tools
- top
- onderwerp
- handel
- Trainen
- getraind
- Trainingen
- transformatieve
- Trust
- BEURT
- twee
- types
- voor
- die ten grondslag liggen
- begrip
- helaas
- unieke
- universiteit-
- University of California
- openen
- us
- .
- gebruikt
- gebruik
- waardevol
- waarde
- Verificatie
- controleren
- Tegen
- zeer
- via
- Vice President
- wil
- was
- Manier..
- manieren
- we
- Wat
- Wat is
- wanneer
- welke
- WIE
- breed
- wil
- Met
- wereldwijd
- zou
- ja
- u
- Jonger
- zephyrnet