概要
薄暗い図書館に立って、他の何十もの文書をやりくりしながら、複雑な文書を解読するのに苦労しているところを想像してみてください。これは、「注意こそが必要だ」という新聞が革命的なスポットライトを明らかにする前の、トランスフォーマーの世界でした。 注意メカニズム.
目次
RNN の制限
従来のシーケンシャル モデルのような リカレントニューラルネットワーク(RNN)、言語を単語ごとに処理するため、いくつかの制限が生じます。
- 短距離依存性: RNN は遠く離れた単語間のつながりを把握するのに苦労し、主語と動詞が遠く離れている「昨日動物園を訪れた男性」のような文の意味を誤解することがよくありました。
- 制限された並列処理: 情報を逐次的に処理するのは本質的に遅く、特に長いシーケンスの場合、計算リソースの効率的なトレーニングと利用が妨げられます。
- ローカルコンテキストに焦点を当てます。 RNN は主に隣接するものを考慮するため、文の他の部分から重要な情報が失われる可能性があります。
これらの制限により、Transformers が機械翻訳や自然言語理解などの複雑なタスクを実行する能力が妨げられていました。それから来たのは、 注意メカニズムは、単語間の隠れたつながりを明らかにし、言語処理に対する私たちの理解を変える革新的なスポットライトです。しかし、アテンションは正確に何を解決し、トランスフォーマーのゲームをどのように変えたのでしょうか?
次の 3 つの主要な領域に焦点を当てましょう。
長距離依存関係
- 問題: 従来のモデルは、「丘に住んでいる女性は昨夜流れ星を見た」のような文でつまずくことがよくありました。距離があるため「女性」と「流れ星」を結びつけるのに苦労し、誤解を招いてしまった。
- 注意メカニズム: モデルが文全体に明るい光を当て、「女性」と「流れ星」を直接結び付け、文全体を理解しているところを想像してください。距離に関係なく関係を捉えるこの機能は、機械翻訳や要約などのタスクにとって非常に重要です。
また読む: 長短期記憶(LSTM)の概要
並列処理能力
- 問題: 従来のモデルは、本をページごとに読むように、情報を順番に処理していました。これは、特に長いテキストの場合、遅くて非効率的でした。
- 注意メカニズム: 複数のスポットライトがライブラリを同時にスキャンし、テキストのさまざまな部分を並行して分析することを想像してください。これにより、モデルの作業が劇的に高速化され、大量のデータを効率的に処理できるようになります。この並列処理能力は、複雑なモデルをトレーニングし、リアルタイムの予測を行うために不可欠です。
グローバルなコンテキスト認識
- 問題: 従来のモデルでは、個々の単語に焦点を当て、文のより広範なコンテキストが欠けていることがよくありました。これにより、皮肉や二重の意味などの誤解が生じました。
- 注意メカニズム: スポットライトが図書館全体を照らし、すべての本を手に取り、それらが互いにどのように関係しているかを理解するところを想像してください。このグローバルなコンテキスト認識により、モデルは各単語を解釈する際にテキスト全体を考慮できるようになり、より豊かでニュアンスのある理解が可能になります。
多義語の曖昧さをなくす
- 問題: 「銀行」や「リンゴ」などの単語は名詞、動詞、さらには会社になる可能性があり、従来のモデルでは解決するのに苦労していた曖昧さが生じます。
- 注意メカニズム: モデルが文中に出現するすべての単語「bank」にスポットライトを当て、周囲のコンテキストや他の単語との関係を分析していると想像してください。文法構造、近くの名詞、さらには過去の文を考慮することで、注意メカニズムは意図された意味を推測できます。多義語を明確にするこの機能は、機械翻訳、テキスト要約、対話システムなどのタスクにとって非常に重要です。
これら 4 つの側面 (長距離依存性、並列処理能力、グローバルなコンテキスト認識、曖昧さの排除) は、注意メカニズムの変革力を示しています。彼らは Transformers を自然言語処理の最前線に押し上げ、驚くべき精度と効率で複雑なタスクに取り組むことを可能にしました。
NLP、特に LLM が進化し続けるにつれて、注意メカニズムがさらに重要な役割を果たすことは間違いありません。それらは、単語の直線的なシーケンスと人間の言語の豊かなタペストリーの間の架け橋であり、最終的にはこれらの言語の驚異の真の可能性を解き放つ鍵となります。この記事では、さまざまな種類の注意メカニズムとその機能について詳しく説明します。
1. セルフ・アテンション: トランスフォーマーの導きの星
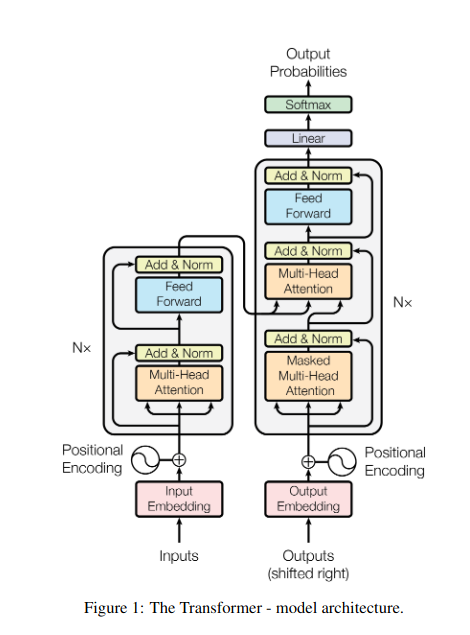
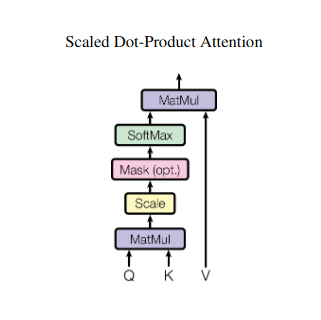
複数の本を読みこなして、要約を書くときにそれぞれの本の特定の一節を参照する必要があることを想像してみてください。自己注意またはスケールドドット積注意はインテリジェントアシスタントのように機能し、モデルが文や時系列などの連続データに対して同じことを行うのを支援します。これにより、シーケンス内の各要素が他のすべての要素に対応できるようになり、長距離の依存関係や複雑な関係を効果的に捉えることができます。
ここでは、その核となる技術的側面を詳しく見ていきます。
ベクトル表現
各要素 (単語、データ ポイント) は高次元ベクトルに変換され、その情報内容がエンコードされます。このベクトル空間は、要素間の相互作用の基礎として機能します。
QKV 変換
3 つの主要なマトリックスが定義されています。
- クエリ (Q): 各要素が他の要素に投げかける「質問」を表します。 Q は、現在の要素の情報ニーズを捕捉し、シーケンス内の関連情報の検索をガイドします。
- キー (K): 各要素の情報への「鍵」を保持します。 K は各要素のコンテンツの本質をエンコードし、他の要素が独自のニーズに基づいて潜在的な関連性を識別できるようにします。
- 値 (V): 各要素が共有したい実際のコンテンツを保存します。 V には、他の要素が注意スコアに基づいてアクセスして利用できる詳細情報が含まれています。
注意スコアの計算
各要素ペア間の互換性は、それぞれの Q ベクトルと K ベクトルの間のドット積によって測定されます。スコアが高いほど、要素間の潜在的な関連性がより強いことを示します。
スケーリングされた注意の重み
相対的な重要性を確保するために、これらの互換性スコアはソフトマックス関数を使用して正規化されます。これにより、現在の要素のコンテキストに対する各要素の重み付けされた重要性を表す、0 から 1 の範囲の注意の重みが得られます。
加重コンテキスト集約
注意の重みが V マトリックスに適用され、基本的に、現在の要素との関連性に基づいて各要素からの重要な情報が強調表示されます。この加重合計により、シーケンス内の他のすべての要素から収集した洞察を組み込んだ、現在の要素のコンテキスト化された表現が作成されます。
強化された要素表現
表現が強化されたことで、要素は、シーケンス内の他の要素との関係だけでなく、それ自体の内容についてもより深く理解できるようになりました。この変換された表現は、モデル内での後続の処理の基礎を形成します。
この複数のステップのプロセスにより、次のことへの自己注意が可能になります。
- 長距離の依存関係をキャプチャします。 たとえ複数の要素が介在していても、離れた要素間の関係は容易に明らかになります。
- 複雑な相互作用をモデル化します。 シーケンス内の微妙な依存関係と相関関係が明らかになり、データ構造とダイナミクスのより深い理解につながります。
- 各要素をコンテキスト化します。 このモデルは、各要素を個別に分析するのではなく、シーケンスのより広範な枠組み内で分析するため、より正確で微妙な予測や表現が可能になります。
セルフアテンションは、モデルが連続データを処理する方法に革命をもたらし、機械翻訳、自然言語生成、時系列予測などのさまざまな分野にわたって新たな可能性を解き放ちました。シーケンス内の隠された関係を明らかにする機能は、洞察を明らかにし、幅広いタスクで優れたパフォーマンスを達成するための強力なツールを提供します。
2. マルチヘッドアテンション: 異なるレンズを通して見る
自己注意により全体的なビューが得られますが、場合によってはデータの特定の側面に焦点を当てることが重要です。ここで、マルチヘッドの注意が必要になります。複数のアシスタントがいて、それぞれに異なるレンズが装備されていると想像してください。
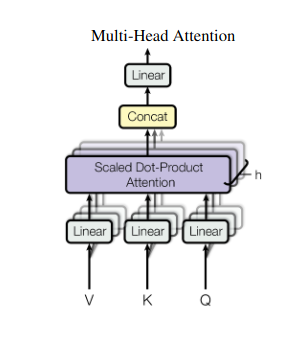
- 複数の「頭」 が作成され、それぞれが独自の Q、K、V 行列を通じて入力シーケンスに対応します。
- 各頭は、長距離の依存関係、構文関係、ローカルな単語の相互作用など、データのさまざまな側面に焦点を当てることを学びます。
- 次に、各ヘッドからの出力が連結されて最終的な表現に投影され、入力の多面的な性質が捉えられます。
これにより、モデルはさまざまな視点を同時に考慮できるようになり、データをより豊かで微妙な理解につながります。
3. クロスアテンション: シーケンス間にブリッジを構築する
さまざまな情報間のつながりを理解する能力は、多くの NLP タスクにとって重要です。書評を書くことを想像してみてください。テキストを一字一句要約するだけではなく、章全体にわたる洞察やつながりを引き出すことになります。入力 交差注意、シーケンス間に橋を架ける強力なメカニズムで、モデルが 2 つの異なるソースからの情報を活用できるようにします。
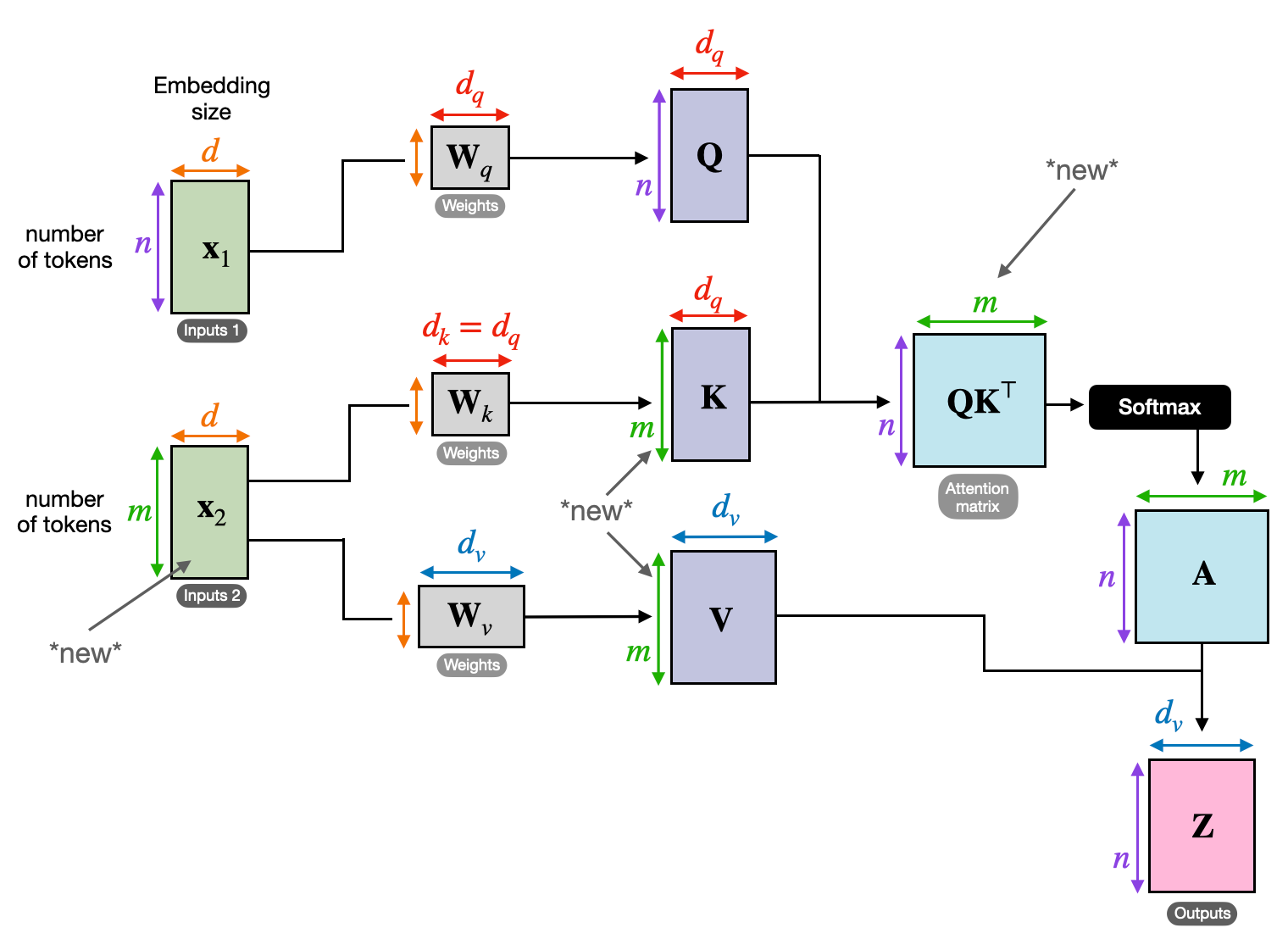
- Transformers のようなエンコーダ/デコーダ アーキテクチャでは、 エンコーダ 入力シーケンス (本) を処理し、隠された表現を生成します。
- デコーダ 出力シーケンス (レビュー) を生成する際に、各ステップでクロスアテンションを使用してエンコーダーの非表示表現に注目します。
- デコーダーの Q マトリックスはエンコーダーの K および V マトリックスと相互作用するため、レビューの各文を書きながら本の関連部分に焦点を当てることができます。
このメカニズムは、入力シーケンスと出力シーケンスの間の関係を理解することが不可欠な、機械翻訳、要約、質問応答などのタスクにとって非常に貴重です。
4. 因果的注意:時間の流れを維持する
文中の次の単語を先を読むことなく予測することを想像してみてください。従来のアテンション メカニズムは、テキスト生成や時系列予測など、情報の時間的順序を保持する必要があるタスクに苦労しています。これらはシーケンス内で容易に「先読み」してしまい、不正確な予測につながります。因果的注意は、予測が以前に処理された情報のみに依存するようにすることで、この制限に対処します。
仕組みはこちら
- マスキングメカニズム: 特定のマスクがアテンション ウェイトに適用され、シーケンス内の将来の要素へのモデルのアクセスが効果的にブロックされます。たとえば、「the women who…」の 2 番目の単語を予測する場合、モデルは「the」のみを考慮でき、「who」以降の単語は考慮できません。
- 自己回帰処理: 情報は直線的に流れ、各要素の表現はその前に現れる要素のみから構築されます。モデルはシーケンスを単語ごとに処理し、その時点までに確立されたコンテキストに基づいて予測を生成します。
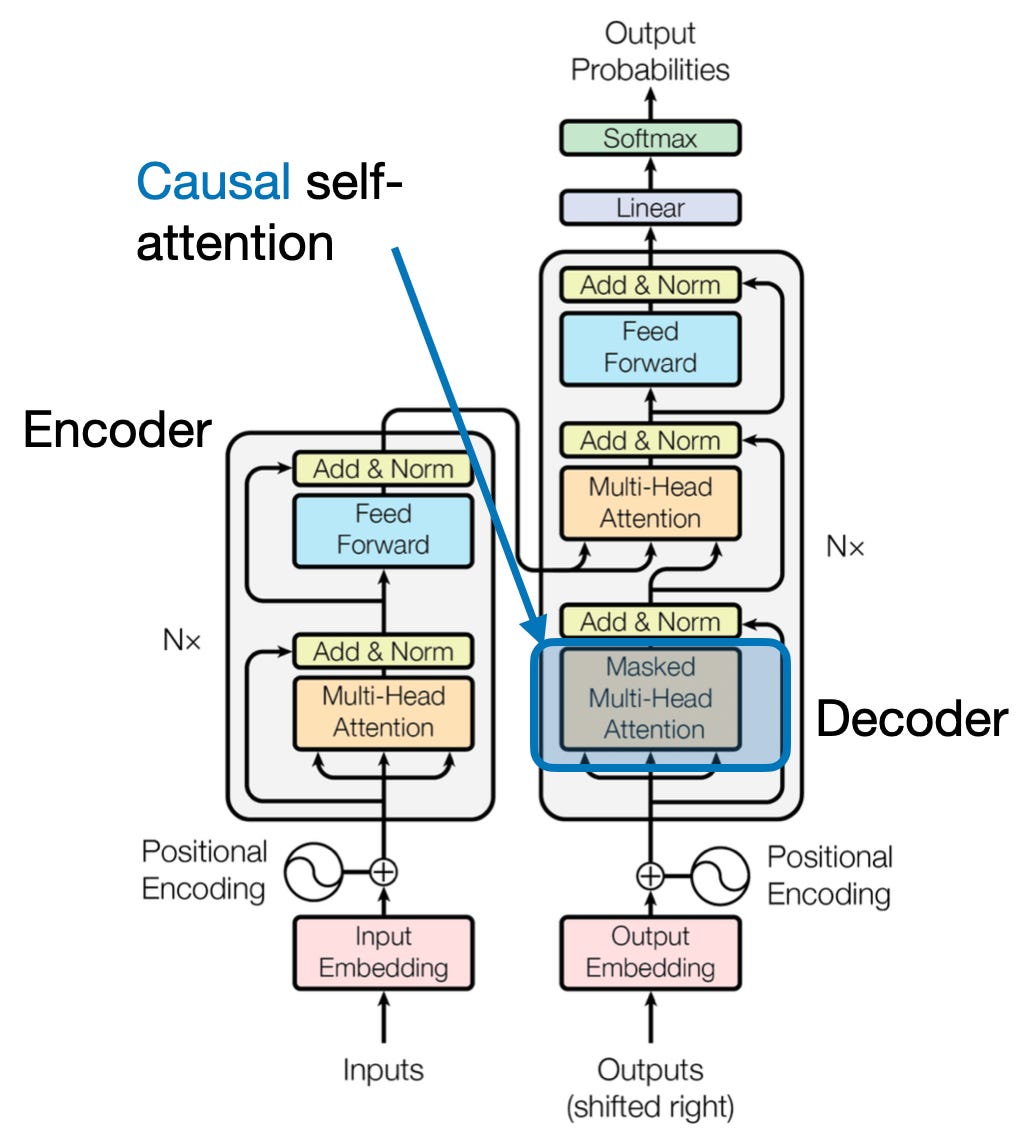
テキスト生成や時系列予測などのタスクでは、因果関係への注意が非常に重要であり、正確な予測にはデータの時間的順序を維持することが不可欠です。
5. グローバルな関心とローカルな関心: バランスをとる
アテンション メカニズムは、長距離の依存関係の把握と効率的な計算の維持という重要なトレードオフに直面しています。これは、次の 2 つの主要なアプローチで明らかになります。 グローバルな注目 および 地元の注目。本全体を読むのと、特定の章に集中して読むことを想像してみてください。グローバル アテンションはシーケンス全体を一度に処理しますが、ローカル アテンションは小さなウィンドウに焦点を当てます。
- 世界的な注目 長距離の依存関係と全体的なコンテキストをキャプチャしますが、長いシーケンスでは計算コストが高くなる可能性があります。
- 地元の注目 効率的ですが、遠く離れた関係を逃す可能性があります。
グローバルな注目とローカルな注目のどちらを選択するかは、いくつかの要因によって決まります。
- タスクの要件: 機械翻訳のようなタスクでは、遠方の関係を把握する必要があり、グローバルな注目を集める必要がありますが、センチメント分析はローカルな注目を集める可能性があります。
- シーケンスの長さ: シーケンスが長くなると、グローバルな注目が計算コストにかかるため、ローカルまたはハイブリッドのアプローチが必要になります。
- モデル容量: リソースの制約により、グローバル コンテキストを必要とするタスクであっても、ローカルな注意が必要になる場合があります。
最適なバランスを達成するために、モデルは以下を採用できます。
- 動的切り替え: 重要な要素には全体的な注意を使用し、他の要素には局所的な注意を使用し、重要性と距離に基づいて適応します。
- ハイブリッドアプローチ: 両方のメカニズムを同じレイヤー内で組み合わせて、それぞれの強みを活用します。
また読む: 深層学習におけるニューラル ネットワークの種類の分析
まとめ
最終的に、理想的なアプローチは、グローバルな注目とローカルな注目の間の範囲にあります。これらのトレードオフを理解し、適切な戦略を採用することで、モデルがさまざまなスケールにわたって関連情報を効率的に活用できるようになり、シーケンスをより豊かで正確に理解できるようになります。
参考文献
- ラシュカ、S. (2023)。 「LLM におけるセルフ アテンション、マルチヘッド アテンション、クロス アテンション、および因果的注意の理解とコーディング」
- Vaswani、A.、他。 (2017年)。 「必要なのは注意力だけです。」
- ラドフォード、A.ら。 (2019年)。 「言語モデルは教師なしのマルチタスク学習者です。」
関連記事
私はデータ愛好家で、データ内の隠れたパターンを抽出して理解することが大好きです。機械学習とデータサイエンスの分野で学び、成長したいと考えています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2024/01/different-types-of-attention-mechanisms/
- :持っている
- :は
- :not
- :どこ
- $UP
- 1
- 2017
- 2019
- 2023
- 302
- 320
- 321
- 7
- a
- 能力
- アクセス
- 精度
- 正確な
- 達成する
- 達成する
- 越えて
- 使徒行伝
- 実際の
- アドレス
- 採用
- 先んじて
- AL
- すべて
- 許可
- ことができます
- am
- 曖昧さ
- 金額
- an
- 分析
- 分析
- 分析する
- および
- 応答
- 離れて
- 見かけ上
- 適用された
- アプローチ
- アプローチ
- です
- エリア
- 記事
- AS
- 側面
- アシスタント
- アシスタント
- At
- 出席する
- 出席する
- 注意
- 認知度
- ベース
- 基礎
- BE
- ビーム
- になる
- の間に
- 越えて
- ブロッキング
- 本
- 本
- 両言語で
- BRIDGE
- ブリッジ
- 明るい
- より広い
- た
- 建物
- 構築します
- 内蔵
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 来ました
- 缶
- キャプチャー
- キャプチャ
- キャプチャ
- 例
- 変化する
- 章
- 章
- 選択
- クローザー
- コーディング
- 組み合わせる
- 来ます
- 企業
- 互換性
- 複雑な
- 計算
- 計算的
- お問合せ
- 接続する
- Connections
- 検討
- 考えると
- 制約
- 含まれています
- コンテンツ
- コンテキスト
- 続ける
- 基本
- 相関関係
- 作成した
- 作成します。
- 作成
- 重大な
- 重大な
- 電流プローブ
- データ
- データサイエンス
- 解読
- 深いです
- より深い
- 定義済みの
- 探求する
- 決まる
- 依存性
- 依存関係
- 依存関係
- 依存
- 詳細な
- 対話
- DID
- 異なります
- 直接に
- 距離
- 遠い
- 明確な
- 異なる
- do
- ドキュメント
- DOT
- 数十
- 劇的に
- ドロー
- 原因
- ダイナミクス
- E&T
- 各
- 効果的に
- 効率
- 効率的な
- 効率良く
- 素子
- 要素は
- エンパワーメント
- 可能
- 有効にする
- エンコーディング
- 豊かな
- 確保
- 確保する
- 入力します
- 全体
- 全体
- 装備
- 特に
- 本質
- 本質的な
- 本質的に
- 設立
- さらに
- あらゆる
- 進化
- 正確に
- 高価な
- 悪用する
- エキス
- 顔
- 要因
- 遠く
- 賛成
- フィールド
- フィールズ
- ファイナル
- フロー
- 流れ
- フォーカス
- 焦点を当て
- 焦点を当てて
- 焦点
- 最前線
- フォーム
- Foundation
- 4
- フレームワーク
- から
- function
- 機能性
- 未来
- ゲーム
- 生成
- 生成
- 世代
- グローバル
- グローバルコンテキスト
- 把握
- 成長する
- ガイド
- 案内
- ハンドル
- 持ってる
- 持って
- 助け
- 隠されました
- ハイ
- より高い
- 強調表示
- 保持している
- 包括的な
- 認定条件
- HTTPS
- 人間
- ハイブリッド
- i
- 理想
- 識別する
- if
- 絵
- 即時の
- 重要性
- 重要
- in
- 不正確
- 組み込む
- 示す
- 個人
- 非効率的な
- 情報
- 本質的に
- 洞察
- インテリジェント-
- 意図された
- 相互作用
- 相互作用
- 相互作用する
- 介入する
- に
- 貴重な
- 分離
- IT
- ITS
- JPG
- ただ
- キー
- 重要な場所
- 言語
- 姓
- 層
- 主要な
- LEARN
- 学び、成長する
- 学習者
- 学習
- ツェッペリン
- レンズ
- レンズをセットすることで
- 活用します
- 活用
- 図書館
- ある
- 光
- ような
- 制限
- 制限
- ローカル
- 長い
- より長いです
- 見て
- 愛
- 機械
- 機械学習
- 機械翻訳
- 保守
- make
- 作成
- man
- 多くの
- mask
- マトリックス
- 最大幅
- 意味
- 意味
- 測定された
- メカニズム
- メカニズム
- メモリ
- かもしれない
- ミス
- 行方不明
- モデル
- 他には?
- もっと効率的
- 多面
- の試合に
- ナチュラル
- 自然言語
- 自然言語の生成
- 自然言語処理
- 自然言語理解
- 自然
- 必要
- 必要
- ニーズ
- 隣人
- ネットワーク
- ニューラル
- ニューラルネットワーク
- 新作
- 次の
- 夜
- NLP
- 名詞
- 今
- 微妙
- of
- 頻繁に
- on
- かつて
- の
- 最適な
- or
- 注文
- その他
- その他
- 私たちの
- でる
- 出力
- outputs
- 全体
- 概要
- 自分の
- ページ
- ペア
- 紙素材
- 並列シミュレーションの設定
- 部品
- 通路
- 過去
- パターン
- 実行する
- パフォーマンス
- 視点
- ピース
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- プレイ
- ポイント
- ポーズ
- 所持
- の可能性
- 強力な
- 潜在的な
- :
- 電力
- 強力な
- 予測
- 予測
- 保存する
- 予防
- 前に
- 主に
- 主要な
- プロセス
- 処理されました
- ラボレーション
- 処理
- 処理能力
- プロダクト
- 投影
- 推進
- は、大阪で
- 質問
- 範囲
- 測距
- むしろ
- 読む
- すぐに
- リーディング
- への
- 参照
- 関係なく
- の関係
- 相対
- 関連性
- 関連した
- 顕著
- 表現
- 表します
- 表し
- 必要とする
- 解決する
- リソースを追加する。
- リソース
- それらの
- 結果
- レビュー
- 革新的な
- 革命を起こした
- 富裕層
- 職種
- s
- 同じ
- 皮肉
- 見ました
- 秤
- スキャニング
- 科学
- スコア
- スコア
- を検索
- 二番
- 見ること
- 文
- 感情
- シーケンス
- シリーズ
- 仕える
- いくつかの
- シェアする
- 輝く
- 射撃
- ショート
- ショーケース
- 同時に
- 遅く
- より小さい
- もっぱら
- 解決する
- 時々
- ソース
- スペース
- 特定の
- 特に
- スペクトラム
- 速度
- スポットライト
- スタンディング
- 星
- 手順
- 店舗
- 作戦
- 強み
- 強い
- 構造
- 奮闘
- 苦労して
- テーマ
- それに続きます
- そのような
- 適当
- 合計
- まとめる
- 概要
- 優れた
- 周囲の
- システム
- タックル
- 取得
- タペストリー
- タスク
- 技術的
- 期間
- 클라우드 기반 AI/ML및 고성능 컴퓨팅을 통한 디지털 트윈의 기초 – Edward Hsu, Rescale CPO 많은 엔지니어링 중심 기업에게 클라우드는 R&D디지털 전환의 첫 단계일 뿐입니다. 클라우드 자원을 활용해 엔지니어링 팀의 제약을 해결하는 단계를 넘어, 시뮬레이션 운영을 통합하고 최적화하며, 궁극적으로는 모델 기반의 협업과 의사 결정을 지원하여 신제품을 결정할 때 데이터 기반 엔지니어링을 적용하고자 합니다. Rescale은 이러한 혁신을 돕기 위해 컴퓨팅 추천 엔진, 통합 데이터 패브릭, 메타데이터 관리 등을 개발하고 있습니다. 이번 자리를 빌려 비즈니스 경쟁력 제고를 위한 디지털 트윈 및 디지털 스레드 전략 개발 방법에 대한 인사이트를 나누고자 합니다.
- テキスト生成
- それ
- 世界
- アプリ環境に合わせて
- それら
- その後
- ボーマン
- 彼ら
- この
- 三
- 介して
- 時間
- 時系列
- 〜へ
- ツール
- 伝統的な
- トレーニング
- 変形させる
- 変換
- トランス
- トランスフォーマー
- 変換
- インタビュー
- true
- 2
- 最終的に
- わかる
- 理解する
- 間違いなく
- ロック解除
- 発表する
- 発表
- つかいます
- 使用されます
- さまざまな
- 広大な
- 対
- 詳しく見る
- 訪問
- 極めて重要な
- vs
- 欲しいです
- 望んでいる
- ました
- WELL
- この試験は
- いつ
- while
- 誰
- 全体
- ワイド
- 広い範囲
- 意志
- ウィンドウを使用して入力ファイルを追加します。
- 以内
- 無し
- 女性
- Word
- 言葉
- 仕事
- 世界
- 書き込み
- 昨日
- 貴社
- ゼファーネット
- ZOO