による画像 jcomp on Freepik
時系列は、データ サイエンス分野で唯一のデータセットです。 データは時間-頻度 (たとえば、毎日、毎週、毎月など) で記録され、各観測は他の観測に関連しています。 時系列データは、時間の経過とともにデータに何が起こるかを分析し、将来の予測を作成する場合に役立ちます。
時系列予測は、過去の時系列データに基づいて将来の予測を作成する方法です。 時系列予測には、次のような多くの統計手法があります。 有馬 or 指数平滑化.
時系列予測はビジネスで頻繁に使用されるため、時系列モデルの開発方法を知っておくことはデータ サイエンティストにとって有益です。 この記事では、XNUMX つの一般的な予測 Python パッケージを使用して時系列を予測する方法を学習します。 statsmodels と預言者。 それに入りましょう。
統計モデル Python パッケージは、時系列予測モデルを含むさまざまな統計モデルを提供するオープンソース パッケージです。 サンプル データセットでパッケージを試してみましょう。 この記事では、 デジタル通貨時系列 Kaggle からのデータ (CC0: パブリック ドメイン)。
データをクリーンアップして、持っているデータセットを見てみましょう。
import pandas as pd df = pd.read_csv('dc.csv') df = df.rename(columns = {'Unnamed: 0' : 'Time'})
df['Time'] = pd.to_datetime(df['Time'])
df = df.iloc[::-1].set_index('Time') df.head()
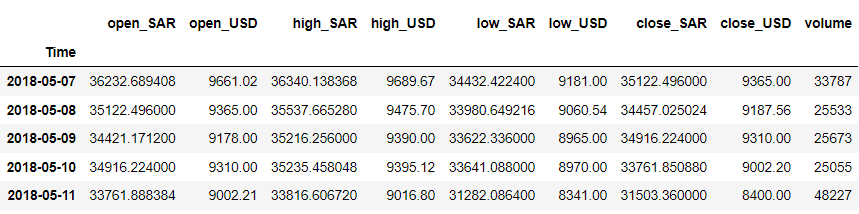
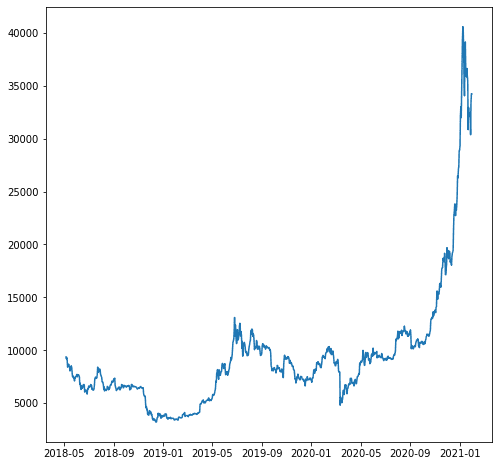
この例では、「close_USD」変数を予測したいとしましょう。 時間の経過に伴うデータ パターンを見てみましょう。
import matplotlib.pyplot as plt plt.plot(df['close_USD'])
plt.show()
上記のデータに基づいて予測モデルを構築しましょう。 モデリングする前に、データをトレーニング データとテスト データに分割しましょう。
# Split the data
train = df.iloc[:-200] test = df.iloc[-200:]
時系列データであり、順序を維持する必要があるため、データをランダムに分割しません。 代わりに、以前のトレーニング データと最新データのテスト データを取得しようとします。
statsmodels を使用して予測モデルを作成しましょう。 の 統計モデル は多くの時系列モデル API を提供しますが、例として ARIMA モデルを使用します。
from statsmodels.tsa.arima.model import ARIMA #sample parameters
model = ARIMA(train, order=(2, 1, 0)) results = model.fit() # Make predictions for the test set
forecast = results.forecast(steps=200)
forecast
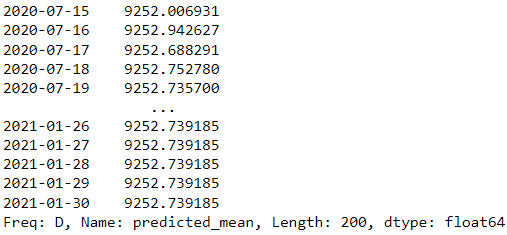
上記の例では、statsmodels の ARIMA モデルを予測モデルとして使用し、次の 200 日を予測しようとしています。
モデルの結果は良好ですか? それらを評価してみましょう。 時系列モデルの評価では、通常、可視化グラフを使用して、実際の値と予測値を、平均絶対誤差 (MAE)、二乗平均平方根誤差 (RMSE)、MAPE (平均絶対パーセント誤差) などの回帰指標と比較します。
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np #mean absolute error
mae = mean_absolute_error(test, forecast) #root mean square error
mse = mean_squared_error(test, forecast)
rmse = np.sqrt(mse) #mean absolute percentage error
mape = (forecast - test).abs().div(test).mean() print(f"MAE: {mae:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"MAPE: {mape:.2f}%")
MAE: 7956.23 RMSE: 11705.11 MAPE: 0.35%
上のスコアは問題ないように見えますが、視覚化するとどうなるか見てみましょう。
plt.plot(train.index, train, label='Train')
plt.plot(test.index, test, label='Test')
plt.plot(forecast.index, forecast, label='Forecast')
plt.legend()
plt.show()
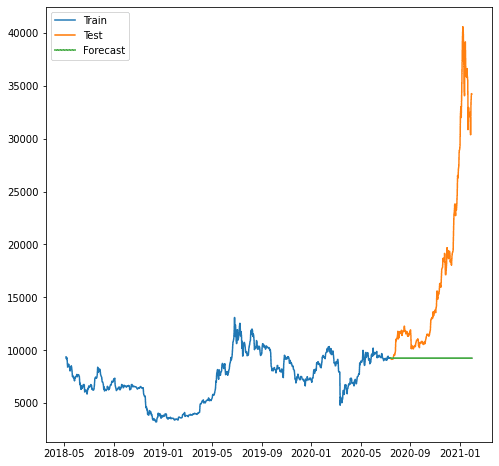
ご覧のとおり、モデルは増加傾向を予測できないため、予測は悪化しました。 私たちが使用するモデル ARIMA は、予測するには単純すぎるようです。
statsmodels 以外の別のモデルを使用してみるとよいかもしれません。 Facebook の有名な預言者パッケージを試してみましょう。
預言者 は、季節効果のあるデータに最適な時系列予測モデル パッケージです。 Prophet は、欠損データや異常値を処理できるため、堅牢な予測モデルとも見なされました。
Prophet パッケージを試してみましょう。 まず、パッケージをインストールする必要があります。
pip install prophet
その後、予測モデルのトレーニング用にデータセットを準備する必要があります。 Prophet には特定の要件があります。時間列の名前を「ds」、値を「y」にする必要があります。
df_p = df.reset_index()[["Time", "close_USD"]].rename( columns={"Time": "ds", "close_USD": "y"}
)
データの準備ができたら、データに基づいて予測予測を作成してみましょう。
import pandas as pd
from prophet import Prophet model = Prophet() # Fit the model
model.fit(df_p) # create date to predict
future_dates = model.make_future_dataframe(periods=365) # Make predictions
predictions = model.predict(future_dates) predictions.head()
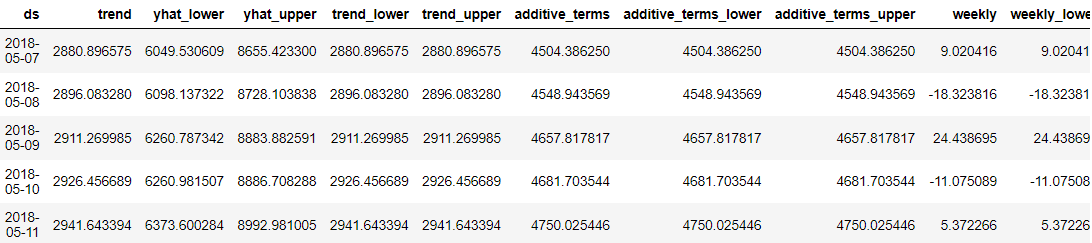
Prophet の優れた点は、すべての予測データ ポイントが詳細であり、ユーザーが理解できるようになったことです。 しかし、データだけで結果を把握することは困難です。 したがって、Prophet を使用してそれらを視覚化することができます。
model.plot(predictions)
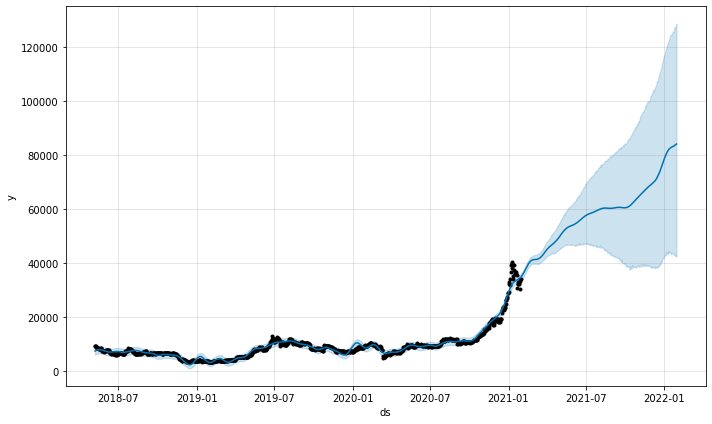
モデルの予測プロット関数は、予測の信頼性を示します。 上記のプロットから、予測が上昇傾向にあることがわかりますが、予測が長くなるほど不確実性が増します。
また、以下の関数で予測成分を調べることも可能です。
model.plot_components(predictions)
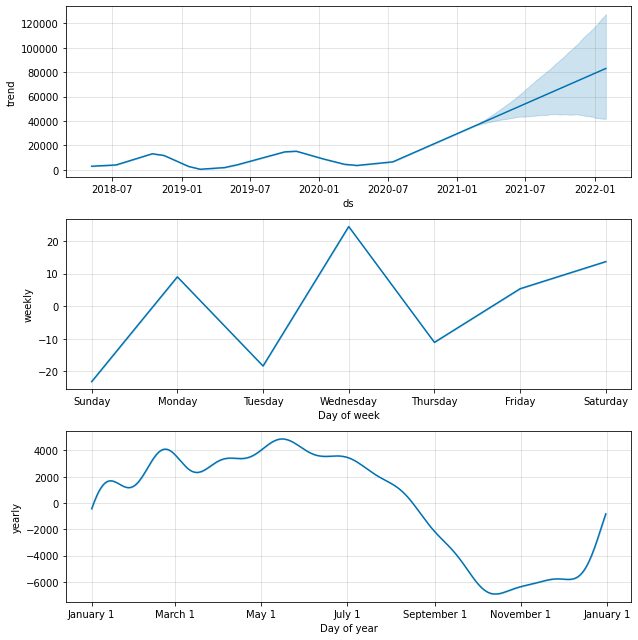
デフォルトでは、年次および週次の季節性のデータ傾向を取得します。 これは、データに何が起こるかを説明する良い方法です。
プロフェットモデルも評価できるのでしょうか? 絶対。 Prophet には、使用できる診断測定が含まれています。 時系列交差検証. この方法では、履歴データの一部を使用し、カットオフ ポイントまでのデータを使用して毎回モデルを適合させます。 次に、預言者は予測と実際の予測を比較します。 コードを使ってみましょう。
from prophet.diagnostics import cross_validation, performance_metrics # Perform cross-validation with initial 365 days for the first training data and the cut-off for every 180 days. df_cv = cross_validation(model, initial='365 days', period='180 days', horizon = '365 days') # Calculate evaluation metrics
res = performance_metrics(df_cv) res
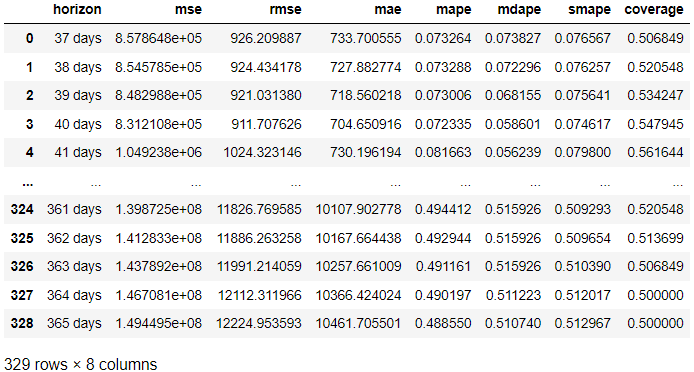
上記の結果では、各予測日における予測と比較した実績から評価結果を取得しました。 次のコードを使用して結果を視覚化することもできます。
from prophet.plot import plot_cross_validation_metric
#choose between 'mse', 'rmse', 'mae', 'mape', 'coverage' plot_cross_validation_metric(df_cv, metric= 'mape')
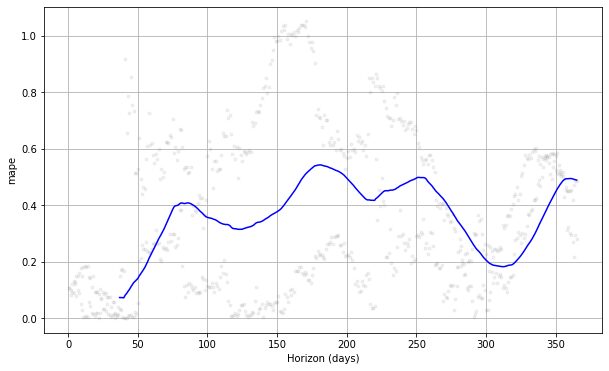
上記のプロットを見ると、予測誤差が日によって変化し、いくつかのポイントで 50% の誤差を達成する可能性があることがわかります。 このようにして、エラーを修正するためにモデルをさらに微調整したい場合があります。 を確認できます。 ドキュメント さらなる調査のために。
予測は、ビジネスで発生する一般的なケースの XNUMX つです。 予測モデルを開発する簡単な方法の XNUMX つは、statsforecast および Prophet Python パッケージを使用することです。 この記事では、予測モデルを作成し、statsforecast と Prophet で評価する方法を学びます。
コーネリアス・ユダ・ウィジャヤ は、データ サイエンス アシスタント マネージャー兼データ ライターです。 Allianz Indonesia でフルタイムで働いている間、彼はソーシャル メディアやライティング メディアを通じて Python とデータのヒントを共有するのが大好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/03/time-series-forecasting-statsmodels-prophet.html?utm_source=rss&utm_medium=rss&utm_campaign=time-series-forecasting-with-statsmodels-and-prophet
- :は
- $UP
- 1
- 11
- 7
- 8
- 9
- a
- 私たちについて
- 上記の.
- 絶対の
- 絶対に
- 達成する
- 取得
- アリアンツ
- 分析します
- &
- 別の
- API
- です
- 記事
- AS
- アシスタント
- At
- ベース
- BE
- なぜなら
- 有益な
- BEST
- より良いです
- の間に
- ビルド
- ビジネス
- by
- 計算する
- 缶
- 例
- CC0
- チェック
- コード
- コラム
- コラム
- コマンドと
- 比較します
- 比べ
- コンポーネント
- 確信して
- 見なさ
- 可能性
- カバレッジ
- 作ります
- 通貨
- daily
- データ
- データサイエンス
- データサイエンティスト
- 日付
- 中
- 日
- dc
- デフォルト
- 詳細な
- 開発する
- ドメイン
- ドント
- e
- 各
- 前
- 効果
- エラー
- 等
- 評価する
- 評価
- あらゆる
- 例
- 説明する
- 探査
- 有名な
- フィールド
- 終わり
- 名
- フィット
- 修正する
- フォロー中
- 予想
- から
- function
- さらに
- 未来
- 取得する
- GitHubの
- 良い
- グラフ
- 素晴らしい
- ハンドル
- 起こります
- ハード
- 持ってる
- 歴史的
- 地平線
- 認定条件
- How To
- しかしながら
- HTML
- HTTPS
- import
- in
- 含ま
- 含めて
- 増加した
- の増加
- index
- インドネシア
- 初期
- install
- を取得する必要がある者
- IT
- JPG
- KDナゲット
- 知っている
- 最新の
- LEARN
- より長いです
- 見て
- LOOKS
- make
- マネージャー
- 多くの
- matplotlib
- メディア
- 方法
- メソッド
- メトリック
- かもしれない
- 行方不明
- モデリング
- モデル
- monthly
- 名前付き
- 必要
- ニーズ
- 次の
- numpy
- 入手する
- of
- 提供すること
- on
- ONE
- オープンソース
- 注文
- その他
- 外側
- パッケージ
- パッケージ
- パンダ
- パラメータ
- 部
- パターン
- 割合
- 実行する
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポイント
- ポイント
- 人気
- 可能
- 予測する
- 予測
- 予測
- 準備
- 提供します
- は、大阪で
- 公共
- Python
- 準備
- 記録された
- 回帰
- 関連する
- 要件
- 結果
- 結果
- 堅牢な
- ルート
- 科学
- 科学者
- と思われる
- シリーズ
- セッションに
- シェアする
- 簡単な拡張で
- So
- 社会
- ソーシャルメディア
- 一部
- 特定の
- split
- 広場
- 統計的
- そのような
- 取る
- test
- それ
- それら
- 時間
- 時系列
- ヒント
- 〜へ
- あまりに
- トレーニング
- トレーニング
- トレンド
- 不確実性
- わかる
- ユニーク
- 名前なし
- 上向きに
- us
- つかいます
- users
- 通常
- 貴重な
- 値
- さまざまな
- 、
- 可視化
- 仕方..
- weekly
- WELL
- この試験は
- while
- Wikipedia
- 意志
- 以内
- ワーキング
- 作品
- でしょう
- 作家
- 書き込み
- あなたの
- ゼファーネット