AWS グルースタジオ での抽出、変換、ロード (ETL) ジョブの作成、実行、監視を容易にするグラフィカル インターフェイスです。 AWSグルー. これにより、さまざまなデータ処理ステップを表すノードを使用して、データ変換ワークフローを視覚的に構成できます。これらのステップは、後で実行するコードに自動的に変換されます。
AWS グルースタジオ 最近リリースされた コーディング スキルがなくても、より高度なジョブを視覚的に作成できるようにする 10 個のビジュアル トランスフォーム。 この投稿では、一般的な ETL のニーズを反映した潜在的なユース ケースについて説明します。
この記事で紹介する新しい変換は、連結、文字列の分割、列への配列、現在のタイムスタンプの追加、行から列へのピボット、列から行へのピボット解除、ルックアップ、配列の展開または列へのマップ、派生列、自動バランス処理です。 .
ソリューションの概要
このユース ケースでは、ストック オプション操作を含む JSON ファイルがいくつかあります。 分析を容易にするために、データを保存する前にいくつかの変換を行い、別のデータセットの要約も作成したいと考えています。
このデータセットでは、各行がオプション契約の取引を表しています。 オプションは、固定価格で株式を売買する権利を提供する金融商品ですが、義務ではありません。 行使価格) 定義された有効期限の前。
入力データ
データは次のスキーマに従います。
- 注文ID – 一意の ID
- シンボル – 通常、基礎となる株式を発行する企業を識別するための数文字に基づくコード
- 楽器 – 売買される特定のオプションを識別する名前
- 通貨 – 価格を表す ISO 通貨コード
- ブランド – 各オプション コントラクトの購入に対して支払われた金額 (ほとんどの取引所では、100 つのコントラクトで XNUMX 株を売買できます)
- 交換 – オプションが取引された交換センターまたは会場のコード
- 売ら – これが売り取引である場合に売り注文を約定するために割り当てられた契約数のリスト
- 買った – これが買い取引である場合、買い注文を約定するために割り当てられた契約数のリスト
以下は、この記事のために生成された合成データのサンプルです。
ETL 要件
古いシステムでよく見られるように、このデータには多くの固有の特性があり、データの使用を困難にしています。
ETL 要件は次のとおりです。
- インストルメント名には、人間が理解できるように意図された貴重な情報が含まれています。 分析を容易にするために、それを個別の列に正規化します。
- 属性
bought&sold相互に排他的です。 契約番号を含む単一の列にそれらを統合し、契約がこの順序で売買されたかどうかを示す別の列を持つことができます。 - 個々のコントラクト割り当てに関する情報を保持したいのですが、ユーザーに数値の配列を処理させるのではなく、個々の行として保持したいと考えています。 数字を合計することはできますが、注文がどのように約定されたか (市場の流動性を示す) に関する情報は失われます。 代わりに、テーブルを非正規化することを選択して、各行に単一の契約数が含まれるようにし、複数の番号を持つ注文を別々の行に分割します。 圧縮された列形式では、圧縮が適用されると、この繰り返しの余分なデータセット サイズが小さくなることが多いため、データセットをクエリしやすくすることは許容されます。
- 各株式の各オプション タイプ (コールとプット) の出来高の要約テーブルを生成したいと考えています。 これは、各株式の市場センチメントと一般的な市場 (貪欲と恐怖) の指標を提供します。
- 全体的な取引の要約を可能にするために、各操作に総計を提供し、おおよその換算参照を使用して通貨を米ドルに標準化します。
- これらの変換が行われた日付を追加します。 これは、たとえば、いつ通貨換算が行われたかを参照するのに役立ちます。
これらの要件に基づいて、ジョブは XNUMX つの出力を生成します。
- シンボルとタイプごとの契約数の概要を含む CSV ファイル
- 指示された変換を行った後、注文の履歴を保持するためのカタログ テーブル
前提条件
このユースケースに従うには、独自の S3 バケットが必要です。 新しいバケットを作成するには、次を参照してください。 バケットを作成する.
合成データを生成する
この投稿に従う (またはこの種のデータを自分で実験する) ために、このデータセットを合成的に生成できます。 次の Python スクリプトは、Boto3 がインストールされ、アクセスできる Python 環境で実行できます。 Amazon シンプル ストレージ サービス (Amazon S3)。
データを生成するには、次の手順を実行します。
- AWS Glue Studio で、オプションを使用して新しいジョブを作成します Python シェル スクリプト エディタ.
- ジョブに名前を付けて、 仕事の詳細 タブで、 適切な役割 および Python スクリプトの名前。
- 仕事の詳細 セクション、展開 高度なプロパティ 下にスクロールして ジョブパラメータ.
- という名前のパラメータを入力してください
--bucketサンプルデータの保存に使用するバケットの名前を値として割り当てます。 - 次のスクリプトを AWS Glue シェル エディタに入力します。
- ジョブを実行し、[実行] タブで正常に完了したと表示されるまで待ちます (数秒かかります)。
実行ごとに、指定されたバケットとプレフィックスの下に 1,000 行を含む JSON ファイルが生成されます transformsblog/inputdata/. より多くの入力ファイルでテストする場合は、ジョブを複数回実行できます。
合成データの各行は、次のような JSON オブジェクトを表すデータ行です。
AWS Glue ビジュアル ジョブを作成する
AWS Glue ビジュアル ジョブを作成するには、次の手順を実行します。
- AWS Glue Studio に移動し、オプションを使用してジョブを作成します 真っ白なキャンバスを使ったビジュアル.
- 編集
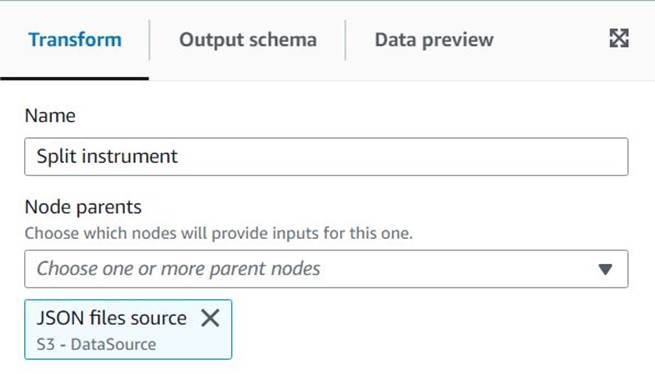
Untitled job名前を付けて割り当てる AWS Glue に適したロール 仕事の詳細 タブには何も表示されないことに注意してください。 - S3 データ ソースを追加します (名前を付けることができます
JSON files source) を入力し、ファイルが保存されている S3 URL を入力します (たとえば、s3://<your bucket name>/transformsblog/inputdata/)、次に選択します JSONの データ形式として。 - 選択 スキーマを推測する そのため、データに基づいて出力スキーマを設定します。
このソース ノードから、トランスフォームをチェーンし続けます。 各トランスフォームを追加するときは、選択したノードが最後に追加されたノードであることを確認してください。これにより、手順で特に指定されていない限り、親として割り当てられます。
適切な親を選択しなかった場合は、親を選択し、構成ペインで別の親を選択することで、いつでも親を編集できます。
追加されたノードごとに、特定の名前を付けて (ノードの目的がグラフに表示されるように)、 最適化の適用 タブには何も表示されないことに注意してください。
変換によってスキーマが変更される (たとえば、新しい列が追加される) たびに、出力スキーマを更新して、下流の変換から見えるようにする必要があります。 出力スキーマを手動で編集することもできますが、データ プレビューを使用して行う方が実用的で安全です。
さらに、そのようにして、変換が期待どおりに機能していることを確認できます。 これを行うには、 データプレビュー タブをクリックして変換を選択し、プレビュー セッションを開始します。 変換されたデータが期待どおりであることを確認したら、 出力スキーマ タブを選択して データ プレビュー スキーマを使用する スキーマを自動的に更新します。
新しい種類の変換を追加すると、不足している依存関係に関するメッセージがプレビューに表示される場合があります。 こうなったら選ぶ セッションの終了 新しいノードを開始すると、プレビューは新しい種類のノードを選択します。
機器情報の抽出
計測器名に関する情報を処理して、結果の出力テーブルでアクセスしやすい列に正規化することから始めましょう。
- 加える 分割文字列 ノードに名前を付けます
Split instrument、空白の正規表現を使用して計器列をトークン化します。s+(この場合は XNUMX つのスペースで十分ですが、この方法の方が柔軟で視覚的にも明確です)。 - 元の楽器情報をそのまま保持したいので、分割配列の新しい列名を入力します。
instrument_arr.
- 追加する 配列から列へ ノードに名前を付けます
Instrument columns作成したばかりの配列列を新しいフィールドに変換します。symbol、既に列があります。 - 列を選択します
instrument_arr、最初のトークンをスキップして、出力列を抽出するように指示しますmonth, day, year, strike_price, type索引の使用2, 3, 4, 5, 6(カンマの後のスペースは読みやすくするためのもので、構成には影響しません)。
抽出された年は XNUMX 桁のみで表されます。 彼らがXNUMX桁だけを使用する場合、それが今世紀にあると仮定するために一時しのぎを置きましょう.
- 加える 派生列 ノードに名前を付けます
Four digits year. - 入力します
year派生列としてオーバーライドして、次の SQL 式を入力します。CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
便宜上、 expiration_date オプションを行使できる最後の日付の参照としてユーザーが持つことができるフィールド。
- 加える 列の連結 ノードに名前を付けます
Build expiration date. - 新しい列に名前を付ける
expiration_date、列を選択しますyear,month,day(この順序で)、およびスペーサーとしてのハイフン。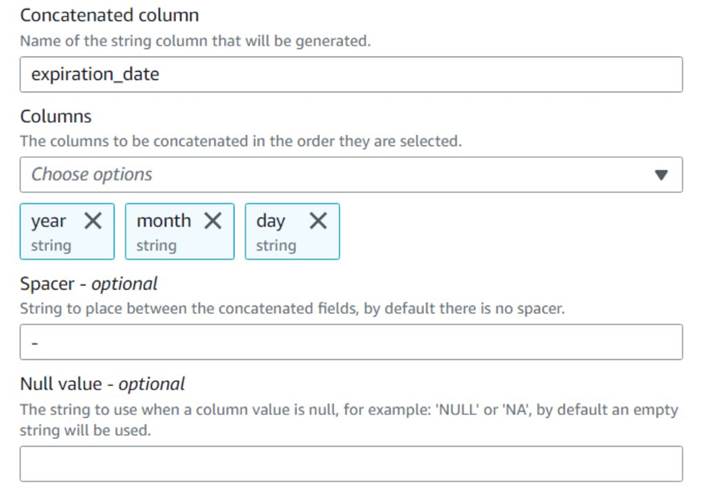
ここまでの図は、次の例のようになります。
![]()
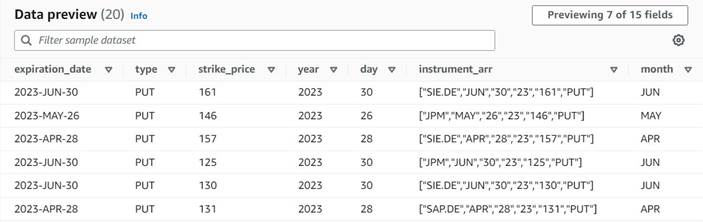
これまでの新しい列のデータ プレビューは、次のスクリーンショットのようになります。
契約数の正規化
データの各行は、売買された各オプションの契約数と、注文が約定されたバッチを示しています。 個々のバッチに関する情報を失わずに、個々の行にそれぞれの金額を XNUMX つの金額値で保持し、残りの情報は生成された各行に複製する必要があります。
まず、金額を XNUMX つの列にマージしましょう。
- 追加する 行への列のピボット解除 ノードに名前を付けます
Unpivot actions. - 列を選択する
bought&soldピボットを解除して、名前と値を名前付きの列に保存しますaction&contractsそれぞれ。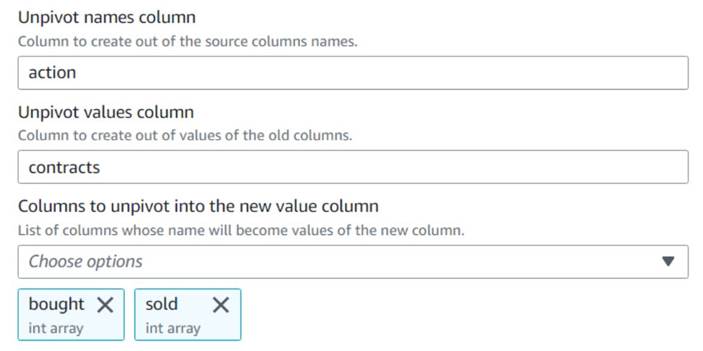
プレビューで、新しい列がcontractsこの変換後もまだ数値の配列です。
- 追加する 配列の分解または行へのマップ 名前付きの行
Explode contracts. - 選択する
contracts列と入力contractsそれをオーバーライドする新しい列として (元の配列を保持する必要はありません)。
プレビューに、各行に XNUMX つの行があることが示されるようになりました contracts 残りのフィールドは同じです。
これはまた、 order_id は一意のキーではなくなりました。 独自のユースケースでは、データをモデル化する方法と、非正規化するかどうかを決定する必要があります。![]()
次のスクリーンショットは、これまでの変換後の新しい列の例です。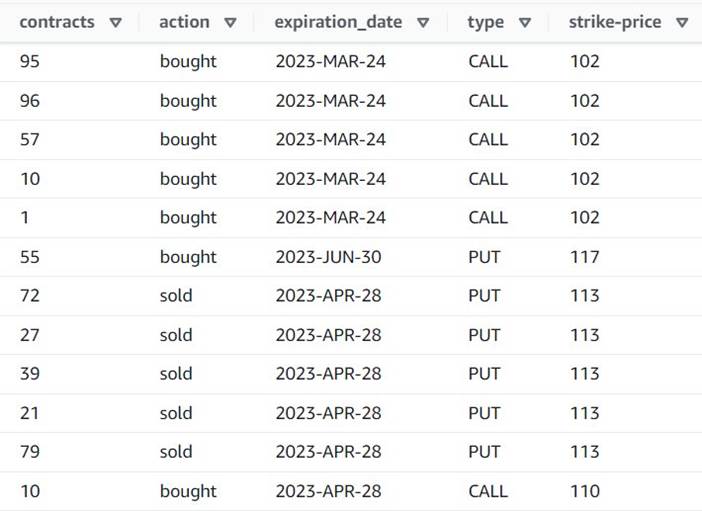
集計表を作成する
ここで、タイプごと、銘柄ごとに取引された契約数を含むサマリー テーブルを作成します。
説明のために、処理されたファイルが XNUMX 日のものであると仮定してみましょう。したがって、この要約は、その日の市場の関心とセンチメントに関する情報をビジネス ユーザーに提供します。
- 加える フィールドを選択 ノードを開き、次の列を選択して要約用に保持します。
symbol,type,contracts.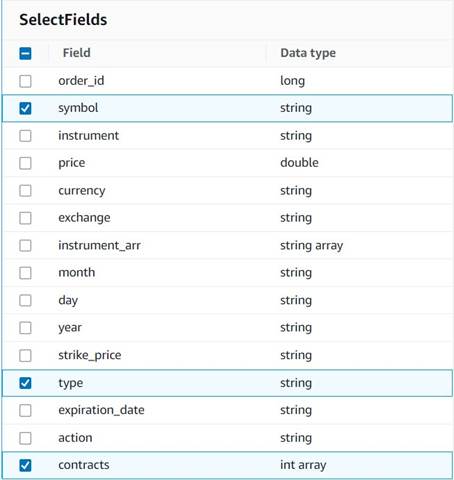
- 加える 行を列にピボットする ノードに名前を付けます
Pivot summary. - で集計
contracts使用する列sum変換することを選択しますtypeコラム。
通常、参照用に外部データベースまたはファイルに保存します。 この例では、Amazon S3 に CSV ファイルとして保存します。
- 追加する オートバランス処理 ノードに名前を付けます
Single output file. - その変換タイプは通常、並列処理を最適化するために使用されますが、ここでは出力を XNUMX つのファイルに減らすために使用します。 したがって、
1パーティション構成の数で。
- S3 ターゲットを追加して名前を付ける
CSV Contract summary. - データ形式として CSV を選択し、ジョブロールがファイルを保存できる S3 パスを入力します。
ジョブの最後の部分は、次の例のようになります。![]()
- ジョブを保存して実行します。 使用 Active Runs タブをクリックして、正常に終了したことを確認します。
そのパスの下に、その拡張子がないにもかかわらず、CSV であるファイルが見つかります。 ダウンロード後に拡張機能を追加して開く必要がある場合があります。
CSV を読み取ることができるツールでは、概要は次の例のようになります。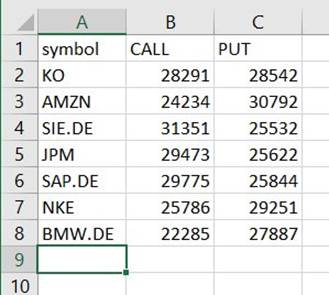
一時列のクリーンアップ
将来の分析のために注文を履歴テーブルに保存する準備として、途中で作成されたいくつかの一時的な列をクリーンアップしましょう。
- 加える ドロップ フィールド のノード
Explode contracts親として選択されたノード (別の出力を生成するためにデータ パイプラインを分岐しています)。 - ドロップするフィールドを選択します。
instrument_arr,month,day,year.
保持したい残りの部分は、後で作成する履歴テーブルに保存されます。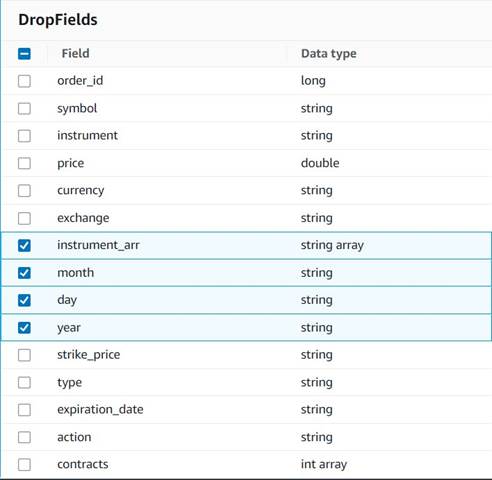
通貨の標準化
この合成データには、XNUMX つの通貨に対する架空の操作が含まれていますが、実際のシステムでは、世界中の市場から通貨を取得できます。 扱う通貨を単一の参照通貨に標準化すると、レポートや分析のために簡単に比較および集計できるため便利です。
を使用しております アマゾンアテナ 定期的に更新されるおおよその通貨換算でテーブルをシミュレートします (ここでは、換算が比較の目的で合理的な代表となるように、注文をタイムリーに処理すると想定しています)。
- AWS Glue を使用しているのと同じリージョンで Athena コンソールを開きます。
- 次のクエリを実行して、Athena と AWS Glue の両方のロールが読み書きできる S3 の場所を設定してテーブルを作成します。 また、テーブルを別のデータベースに保存することもできます。
default(その場合は、提供されている例に応じて、テーブルの修飾名を更新してください)。 - いくつかの変換例を表に入力します。
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - 次のクエリでテーブルを表示できるようになりました。
SELECT * FROM default.exchange_rates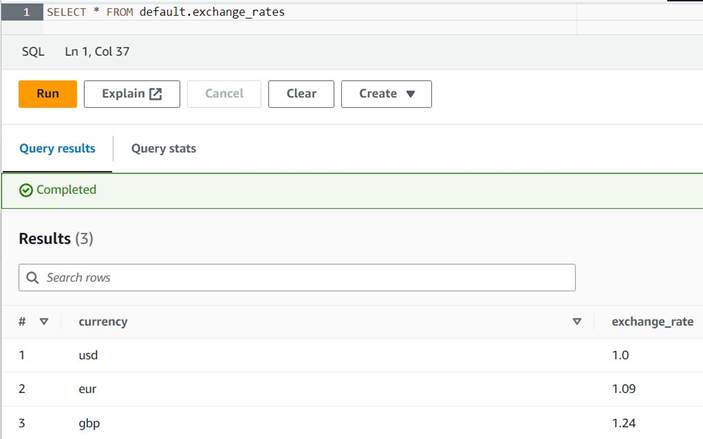
- AWS Glue ビジュアル ジョブに戻り、 見上げる ノード (の子として
Drop Fields)それに名前を付けるExchange rate. - 作成したばかりのテーブルの修飾名を入力します。
currencyキーとして、exchange_rate使用するフィールド。
フィールドにはデータとルックアップ テーブルの両方で同じ名前が付けられているため、名前を入力するだけで済みます。currencyマッピングを定義する必要はありません。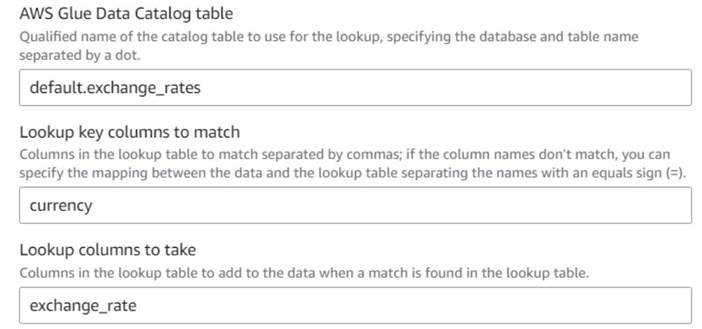
この記事の執筆時点では、ルックアップ変換はデータ プレビューでサポートされておらず、テーブルが存在しないというエラーが表示されます。 これはデータのプレビューのみを目的としており、ジョブの正常な実行を妨げるものではありません。 この投稿の残りのいくつかの手順では、スキーマを更新する必要はありません。 他のノードでデータ プレビューを実行する必要がある場合は、ルックアップ ノードを一時的に削除してから元に戻すことができます。 - 加える 派生列 ノードに名前を付けます
Total in usd. - 派生列に名前を付ける
total_usd次の SQL 式を使用します。round(contracts * price * exchange_rate, 2)
- 加える 現在のタイムスタンプを追加 ノードに名前を付けて列に名前を付けます
ingest_date. - フォーマットを使用する
%Y-%m-%dタイムスタンプ (デモンストレーションの目的で、日付を使用しているだけです。必要に応じて、より正確にすることができます)。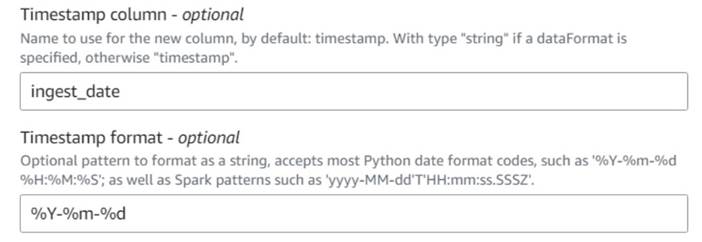
過去の注文テーブルを保存する
過去の注文テーブルを保存するには、次の手順を実行します。
- S3 ターゲット ノードを追加して名前を付ける
Orders table. - snappy 圧縮を使用して Parquet 形式を構成し、結果を保存するための S3 ターゲット パスを提供します (概要とは別に)。
- 選択 Data Catalog にテーブルを作成し、その後の実行でスキーマを更新して新しいパーティションを追加します.
- ターゲット データベースと新しいテーブルの名前を入力します。たとえば、次のようになります。
option_orders.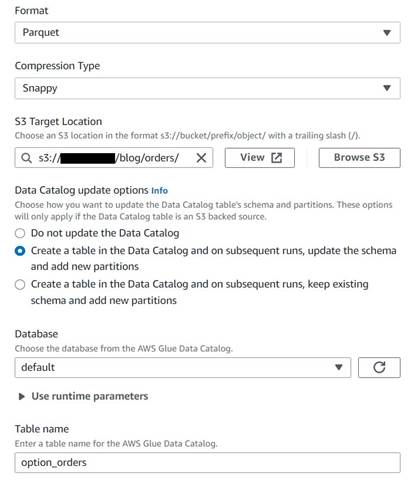
ダイアグラムの最後の部分は、次のようになり、XNUMX つの別個の出力に XNUMX つのブランチが表示されます。![]()
ジョブを正常に実行した後、Athena などのツールを使用して、新しいテーブルをクエリすることにより、ジョブが生成したデータを確認できます。 Athena リストでテーブルを見つけて選択できます。 プレビュー表 または、単に SELECT クエリを実行します (テーブル名を、使用した名前とカタログに更新します)。
SELECT * FROM default.option_orders limit 10
テーブルのコンテンツは、次のスクリーンショットのようになります。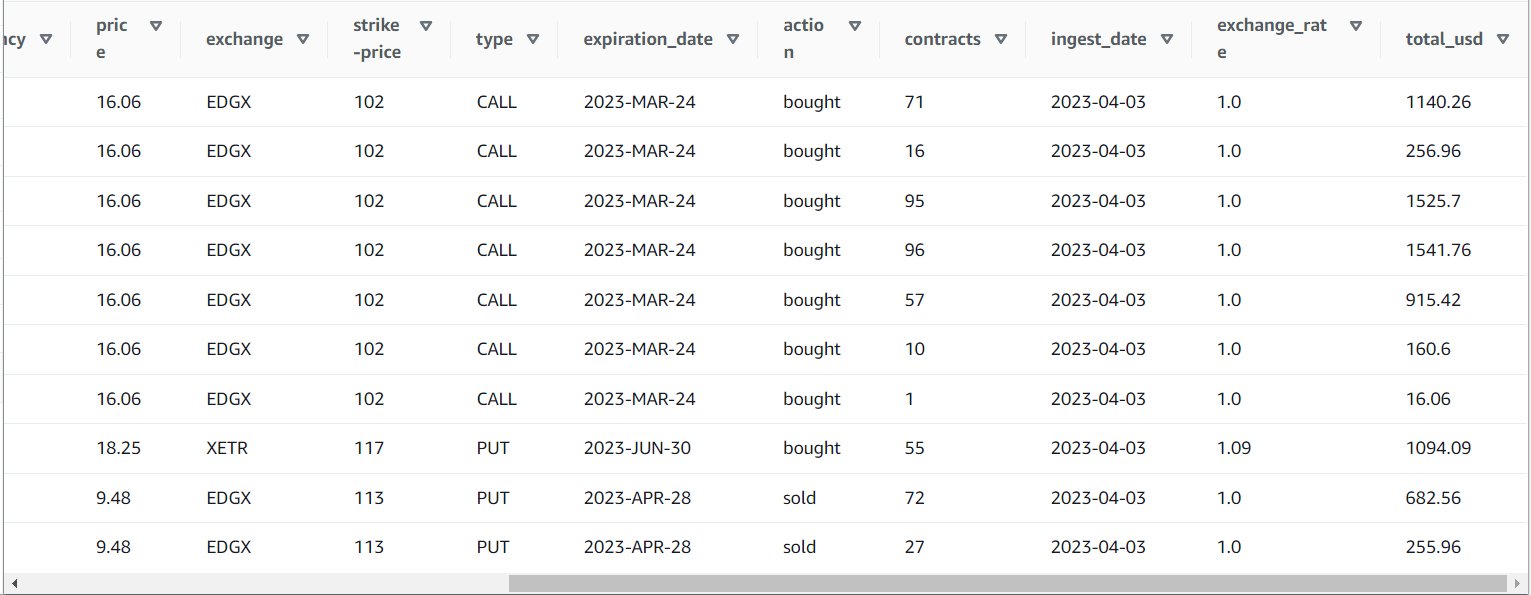
クリーンアップ
この例を維持したくない場合は、作成した 3 つのジョブ、Athena の XNUMX つのテーブル、および入力ファイルと出力ファイルが保存されていた SXNUMX パスを削除します。
まとめ
この投稿では、AWS Glue Studio の新しい変換が、最小限の構成でより高度な変換を行うのにどのように役立つかを示しました。 これは、コードを記述して維持する必要なく、より多くの ETL ユース ケースを実装できることを意味します。 新しい変換は AWS Glue Studio で既に利用可能であるため、ビジュアルジョブで新しい変換を今すぐ使用できます。
著者,
![]() ゴンザロエレロス AWS Glue チームのシニアビッグデータアーキテクトです。
ゴンザロエレロス AWS Glue チームのシニアビッグデータアーキテクトです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 未来を鋳造する w エイドリエン・アシュリー。 こちらからアクセスしてください。
- PREIPO® を使用して PRE-IPO 企業の株式を売買します。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- :持っている
- :は
- :not
- :どこ
- $UP
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 視聴者の38%が
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- できる
- 私たちについて
- ことができます。
- アクセス
- それに応じて
- 加えます
- 追加されました
- 追加
- 高度な
- 後
- すべて
- 割り当てられました
- 割り当て
- 許す
- ことができます
- 沿って
- 既に
- また
- 常に
- Amazon
- 量
- 金額
- an
- 分析
- 分析します
- &
- 別の
- どれか
- 適用された
- 近似
- 4月
- です
- 引数
- 配列
- AS
- 割り当てられた
- At
- 属性
- 自動的に
- 利用できます
- AWS
- AWSグルー
- バック
- ベース
- BE
- さ
- ビッグ
- ビッグデータ
- ブランク
- BMW
- 両言語で
- 買った
- 支店
- ビルド
- ビジネス
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- 購入
- by
- コール
- 缶
- 場合
- 例
- カタログ
- センター
- 世紀
- 変更
- 特性
- チェック
- 子
- 選択する
- 選択する
- より明確に
- コード
- コーディング
- コラム
- コラム
- コマンドと
- 比べ
- 比較
- コンプリート
- 記入済みの
- 領事
- 統合します
- 含まれています
- コンテンツ
- 縮小することはできません。
- 契約
- 利便性
- 変換
- コンバージョン
- 変換
- 変換
- 株式会社
- 可能性
- 作ります
- 作成した
- 作成
- 通貨
- 通貨
- 電流プローブ
- DAG
- データ
- データベース
- 日付
- 試合日
- 日付時刻
- 中
- 取引
- 取引
- 決めます
- デフォルト
- 定義済みの
- 実証
- 依存関係
- 派生
- にもかかわらず
- 細部
- 異なります
- 数字
- 話し合います
- do
- そうではありません
- すること
- ドル
- ドント
- ダウン
- Drop
- 落とした
- 各
- 容易
- 簡単に
- 簡単に
- エディタ
- enable
- 十分な
- 入力します
- 環境
- エラー
- エーテル(ETH)
- EUR
- 例
- 例
- 除く
- 交換
- 交換について
- 特別
- 存在する
- 詳細
- 予想される
- 実験
- 期限切れ
- 表現
- 外部
- 余分な
- エキス
- 遠く
- 恐怖
- 少数の
- 架空の
- フィールド
- フィールズ
- File
- 埋める
- 埋め
- ファイナンシャル
- 金融商品
- もう完成させ、ワークスペースに掲示しましたか?
- 名
- 固定の
- フレキシブル
- フォロー中
- 次
- 形式でアーカイブしたプロジェクトを保存します.
- 発見
- から
- 未来
- GBP
- 一般に
- 生成する
- 生成された
- 取得する
- 与える
- 与える
- Go
- グラフ
- 欲
- ハンドリング
- 起こります
- 持ってる
- 持って
- 助けます
- こちら
- 歴史的
- history
- 認定条件
- How To
- HTML
- HTTP
- HTTPS
- 人間
- i
- 識別する
- 識別する
- if
- 影響
- 実装する
- import
- in
- インデックス
- 示された
- を示し
- 示します
- 表示
- 個人
- 情報
- を取得する必要がある者
- 説明書
- 楽器
- 楽器
- 関心
- インタフェース
- に
- ISO
- IT
- ITS
- ジョブ
- Jobs > Create New Job
- JPG
- JSON
- ただ
- キープ
- キー
- 種類
- 姓
- 後で
- ような
- LIMIT
- LINE
- 流動性
- リスト
- 負荷
- 場所
- より長いです
- 見て
- のように見える
- LOOKS
- 検索
- 失う
- 負け
- 製
- 維持する
- make
- 作る
- 手動で
- 地図
- マッピング
- 市場
- 市場センチメント
- マーケット
- 五月..
- 手段
- マージ
- メッセージ
- かもしれない
- 最小
- 行方不明
- モニター
- 他には?
- 最も
- の試合に
- 互いに
- 名
- 名前付き
- 名
- 必要
- ニーズ
- 新作
- いいえ
- ノード
- 通常は
- 今
- 数
- 番号
- オブジェクト
- of
- 頻繁に
- on
- ONE
- の
- 開いた
- 操作
- 業務執行統括
- 最適化
- オプション
- オプション
- or
- 注文
- 受注
- オリジナル
- その他
- さもないと
- 出力
- が
- 全体
- オーバーライド
- 自分の
- 支払われた
- ペイン
- パラメーター
- 部
- path
- ピック
- パイプライン
- 枢軸
- 場所
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポスト
- 潜在的な
- 実用的
- 正確な
- 防ぐ
- プレビュー
- ブランド
- 多分
- プロセス
- 処理
- 作り出す
- 生産された
- 提供します
- 提供
- は、大阪で
- 購入
- 目的
- 目的
- 置きます
- Python
- 修飾
- 上げる
- ランダム
- 読む
- リアル
- 合理的な
- 減らします
- 反映する
- 地域
- 残り
- 削除します
- 複製された
- 各種レポート作成
- 表す
- 代表者
- 表します
- 表し
- 必要とする
- 要件
- 必要
- それぞれ
- REST
- 結果として
- 結果
- レビュー
- 職種
- 役割
- 行
- ラン
- ランニング
- より安全な
- 同じ
- 樹液
- Save
- 節約
- スクロール
- 秒
- 選択
- 選択
- 売る
- シニア
- 感情
- 別
- セッション
- セット
- 設定
- 株式
- シェル(Shell)
- すべき
- 表示する
- 作品
- 同様の
- 簡単な拡張で
- サイズ
- スキル
- 小さい
- So
- これまでのところ
- 売ら
- 一部
- 何か
- ソース
- スペース
- スペース
- 特定の
- 指定の
- split
- スプレッドシート
- SQL
- start
- ステップ
- まだ
- 株式
- ストレージ利用料
- 店舗
- 保存され
- 文字列
- 研究
- それに続きます
- 首尾よく
- 適当
- 概要
- サポート
- シンボル
- 合成
- 合成データ
- 総合的に
- システム
- テーブル
- 取る
- ターゲット
- チーム
- 言う
- 一時的
- 10
- test
- より
- それ
- グラフ
- 情報
- 世界
- それら
- その後
- したがって、
- ボーマン
- 彼ら
- この
- それらの
- 時間
- <font style="vertical-align: inherit;">回数</font>
- タイムスタンプ
- 〜へ
- 今日
- トークン
- トークン化する
- 取った
- ツール
- トータル
- トレード
- 取引
- 最適化の適用
- 変換
- 変換
- 変換
- 2
- type
- 下
- 根本的な
- わかる
- ユニーク
- まで
- アップデイト
- 更新しました
- 更新
- URL
- us
- 米ドル
- USD
- つかいます
- 使用事例
- 中古
- ユーザー
- users
- 貴重な
- 貴重な情報
- 値
- 価値観
- 会場
- 検証
- 確認する
- 詳しく見る
- 目に見える
- ボリューム
- vs
- wait
- 欲しいです
- ました
- 仕方..
- we
- した
- この試験は
- いつ
- which
- while
- 意志
- 無し
- ワークフロー
- ワーキング
- 世界
- でしょう
- 書きます
- 書き込み
- 年
- 貴社
- あなたの
- ゼファーネット











