07年2023月XNUMX日(
Nanowerkニュース) OpenAI の GPT-3 のような大規模な言語モデルは、詩からプログラミング コードまで、人間のようなテキストを生成できる大規模なニューラル ネットワークです。 大量のインターネット データを使用してトレーニングされたこれらの機械学習モデルは、少量の入力テキストを受け取り、次に来る可能性が高いテキストを予測します。 しかし、これらのモデルができることはそれだけではありません。 研究者は、文脈内学習として知られる興味深い現象を調査しています。これは、大規模な言語モデルが、そのタスク用に訓練されていないにもかかわらず、ほんの数例を見ただけでタスクを達成することを学習するというものです。 たとえば、誰かがモデルにいくつかの例文とその感情 (肯定的または否定的) を入力してから、新しい文でモデルにプロンプトを出すと、モデルは正しい感情を与えることができます。 通常、GPT-3 のような機械学習モデルは、この新しいタスクのために新しいデータで再トレーニングする必要があります。 このトレーニング プロセス中、モデルはタスクを学習するために新しい情報を処理するときにパラメーターを更新します。 しかし、インコンテキスト学習では、モデルのパラメーターは更新されないため、モデルは何も学習せずに新しいタスクを学習しているように見えます。 MIT、Google Research、スタンフォード大学の科学者たちは、この謎の解明に取り組んでいます。 彼らは、パラメータを更新せずにどのように学習できるかを確認するために、大規模な言語モデルに非常によく似たモデルを調査しました。 研究者の理論的結果は、これらの大規模なニューラル ネットワーク モデルが、内部に埋め込まれたより小さくて単純な線形モデルを含むことができることを示しています。 次に、大規模なモデルに単純な学習アルゴリズムを実装して、この小規模な線形モデルをトレーニングし、大規模なモデルに既に含まれている情報のみを使用して新しいタスクを完了することができます。 パラメータは固定のままです。 この研究は、インコンテキスト学習の背後にあるメカニズムを理解するための重要なステップであり、これらの大規模モデルが実装できる学習アルゴリズムに関するさらなる調査への扉を開くと、コンピューター サイエンスの大学院生で論文の筆頭著者である Ekin Akyürek は述べています (
「インコンテキスト学習とはどのような学習アルゴリズムですか? 線形モデルによる調査」) この現象を調査しています。 インコンテキスト学習をよりよく理解することで、研究者は、コストのかかる再トレーニングを必要とせずに、モデルが新しいタスクを完了できるようにすることができます。 「通常、これらのモデルを微調整したい場合は、ドメイン固有のデータを収集し、複雑なエンジニアリングを行う必要があります。 しかし今では、入力と XNUMX つの例を与えるだけで、目的を達成できます。 したがって、インコンテキスト学習は非常にエキサイティングな現象です」と Akyürek 氏は言います。 この論文で Akyürek に加わっているのは、Google Brain の研究科学者であり、アルバータ大学のコンピューティング サイエンスの教授である Dale Schuurmans です。 上級著者のジェイコブ・アンドレアス氏は、MIT の電気工学およびコンピューター科学部門の X コンソーシアム助教授であり、MIT コンピューター科学および人工知能研究所 (CSAIL) のメンバーです。 スタンフォード大学のコンピューター サイエンスと統計学の助教授である Tengyu Ma 氏。 そして、Google Brain の主任科学者兼リサーチ ディレクターである Danny Zhou 氏は次のように述べています。 この研究は、学習表現に関する国際会議で発表されます。
モデル内のモデル
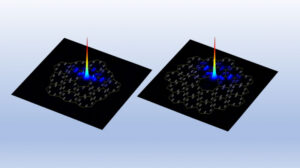
機械学習の研究コミュニティでは、多くの科学者が、大規模な言語モデルがコンテキスト内学習を実行できると信じるようになったのは、それらがどのようにトレーニングされているかによると考えています、と Akyürek は言います。 たとえば、GPT-3 には数千億のパラメーターがあり、ウィキペディアの記事から Reddit の投稿まで、インターネット上の膨大な量のテキストを読み取ることによってトレーニングされました。 したがって、誰かが新しいタスクのモデル例を示すとき、トレーニング データセットには何十億もの Web サイトからのテキストが含まれているため、非常によく似たものを既に見ている可能性があります。 新しいタスクを実行することを学習するのではなく、トレーニング中に見たパターンを繰り返します。 Akyürek は、コンテキスト内の学習者は、以前に見たパターンに一致するだけでなく、実際に新しいタスクを実行することを学んでいるという仮説を立てました。 彼と他の人々は、これまでどこにも見られなかった合成データを使用してこれらのモデルにプロンプトを与える実験を行い、モデルがほんの数例から学習できることを発見しました。 Akyürek と彼の同僚は、おそらくこれらのニューラル ネットワーク モデルには、モデルが新しいタスクを完了するためにトレーニングできる小さな機械学習モデルが内部にあるのではないかと考えました。 「これは、これらの大規模モデルで見られたほとんどすべての学習現象を説明できる可能性があります」と彼は言います。 この仮説を検証するために、研究者はトランスフォーマーと呼ばれるニューラル ネットワーク モデルを使用しました。トランスフォーマーは GPT-3 と同じアーキテクチャを持ちますが、インコンテキスト学習用に特別にトレーニングされています。 このトランスフォーマーのアーキテクチャを調査することにより、彼らは、隠れた状態内で線形モデルを記述できることを理論的に証明しました。 ニューラル ネットワークは、データを処理する相互接続されたノードの多くの層で構成されています。 隠れ状態は、入力層と出力層の間の層です。 彼らの数学的評価は、この線形モデルが変圧器の最初の層のどこかに書かれていることを示しています。 次に、トランスフォーマーは、単純な学習アルゴリズムを実装して線形モデルを更新できます。 本質的に、モデルはそれ自体のより小さなバージョンをシミュレートしてトレーニングします。
隠れ層の探索
研究者は、調査実験を使用してこの仮説を調査し、トランスフォーマーの隠れ層を調べて、特定の量を回収しようとしました。 「この場合、実際の解を線形モデルに復元しようとしましたが、パラメーターが隠れた状態で記述されていることを示すことができました。 これは、線形モデルがどこかにあることを意味します」と彼は言います。 この理論的な作業を基に構築することで、研究者はニューラル ネットワークに XNUMX つのレイヤーを追加するだけで、トランスフォーマーがコンテキスト内学習を実行できるようになる可能性があります。 Akyürek 氏は、それが可能になる前に解決すべき技術的な詳細がまだたくさんあると警告していますが、エンジニアが新しいデータで再トレーニングする必要なく新しいタスクを完了できるモデルを作成するのに役立つ可能性があります。 Akyürek は今後も、この研究で研究した線形モデルよりも複雑な関数を使用して、コンテキスト内学習を探求し続ける予定です。 また、これらの実験を大規模な言語モデルに適用して、その行動が単純な学習アルゴリズムによっても記述されるかどうかを確認することもできます。 さらに、インコンテキスト学習を可能にする事前トレーニング データの種類をさらに深く掘り下げたいと考えています。 「この作業により、これらのモデルが手本からどのように学習できるかを視覚化できるようになりました。 ですから、私の希望は、インコンテキスト学習に対する一部の人々の見方を変えることです」と Akyürek 氏は言います。 「これらのモデルは、人々が考えるほど愚かではありません。 彼らはこれらのタスクを暗記するだけではありません。 彼らは新しいタスクを学ぶことができ、私たちはそれがどのようにできるかを示しました。」