著者による画像
教師なし学習パラダイムに精通している場合は、次元削減と、次のような次元削減に使用されるアルゴリズムに出会ったことがあるでしょう。 主成分分析 (PCA)。 機械学習用のデータセットには通常、多数の特徴が含まれていますが、このような高次元の特徴空間が常に役立つとは限りません。
一般的に、すべての機能は次のとおりです。 同様に重要であり、データセット内の分散の大部分を占める特定の特徴が存在します。 次元削減アルゴリズムは、特徴空間の次元を元の次元数の一部に削減することを目的としています。 その際、分散の高い特徴は依然として保持されますが、それは変換された特徴空間内にあります。 主成分分析 (PCA) は、最も一般的な次元削減アルゴリズムの XNUMX つです。
このチュートリアルでは、主成分分析 (PCA) の仕組みと、scikit-learn ライブラリを使用してそれを実装する方法を学びます。
scikit-learn で主成分分析 (PCA) を実装する前に、PCA がどのように機能するかを理解しておくと役立ちます。
前述したように、主成分分析は次元削減アルゴリズムです。 つまり、特徴空間の次元が削減されます。 しかし、どうやってこの削減を達成するのでしょうか?
このアルゴリズムの背後にある動機は、元のデータセットの分散の大部分を捕捉する特定の特徴があることです。 したがって、それを見つけることが重要です 最大分散の方向 データセット内。 これらの方向はと呼ばれます 主成分。 そして PCA は本質的に、データセットを主成分に投影したものです。
では、主成分はどうやって見つければよいのでしょうか?
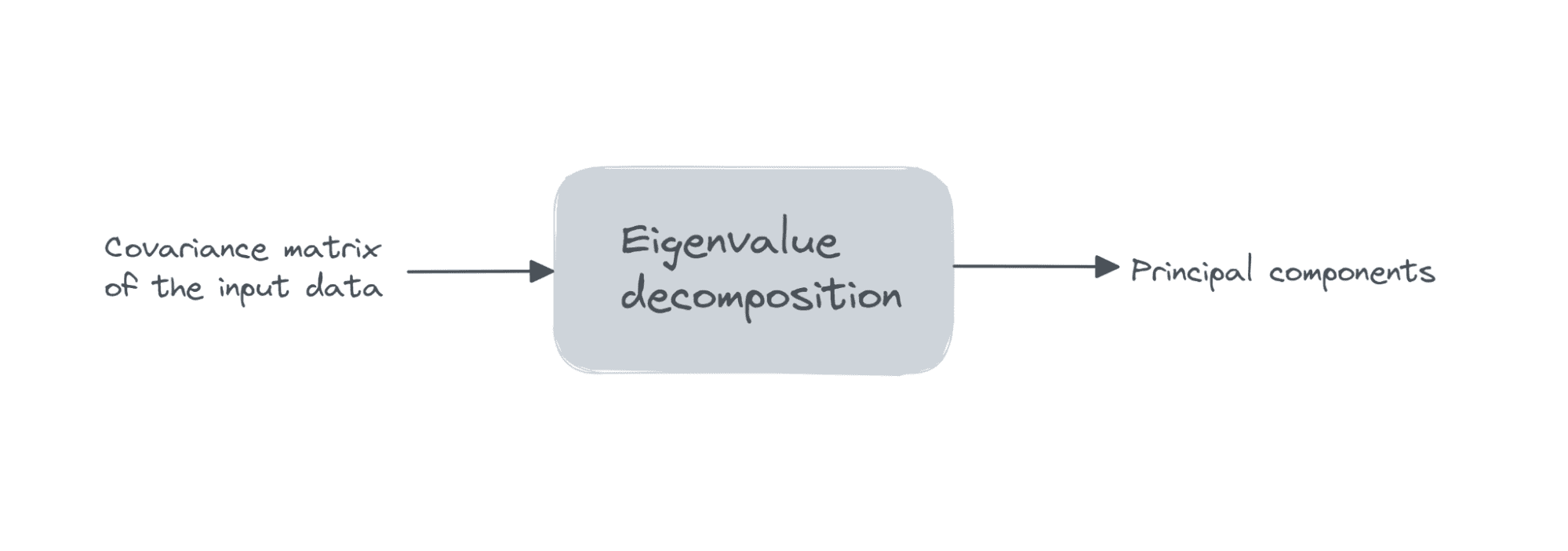
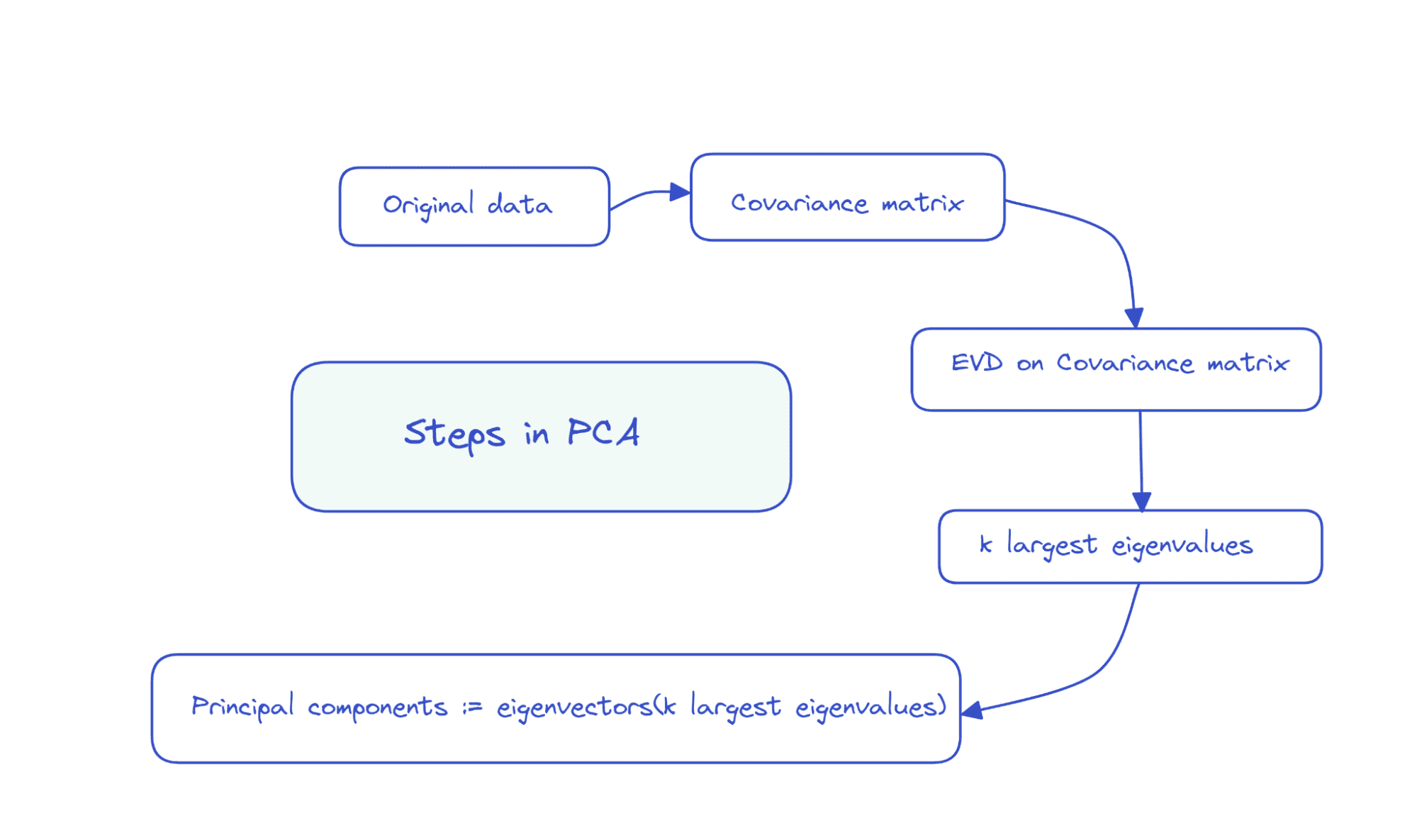
データ行列 X の次元を仮定します。 観測数 x 特徴数、私たちは実行します 固有値分解 共分散行列 Xの。
特徴がすべて平均ゼロの場合、共分散行列は XT X で与えられます。ここで、XT は行列 X の転置です。特徴が最初からすべてゼロ平均ではない場合は、各エントリから列 i の平均を減算できます。その列で共分散行列を計算します。 共分散行列が次数の正方行列であることは簡単にわかります。 num_features.
著者による画像
最初の k 主成分は次のとおりです。 固有ベクトル 対応する k 個の最大固有値.
したがって、PCA の手順は次のように要約できます。
著者による画像
共分散行列は対称で正の半定値であるため、固有分解は次の形式になります。
XT X = D Λ DT
ここで、D は固有ベクトルの行列、Λ は固有値の対角行列です。
主成分の計算に使用できるもう XNUMX つの行列因数分解手法は、特異値分解 (SVD) です。
特異値分解 (SVD) はすべての行列に対して定義されます。 行列 X が与えられると、X の SVD は次のようになります。 X = U Σ VT ここで、U、Σ、V はそれぞれ左特異ベクトル、特異値、右特異ベクトルの行列です。 VT は V の転置です。
したがって、X の共分散行列の SVD は次のように求められます。

XNUMX つの行列分解の等価性を比較します。

以下のものがあります。
行列の SVD を計算するための、計算効率の高いアルゴリズムがあります。 PCA の scikit-learn 実装では、内部で SVD を使用して主成分を計算します。
主成分分析の基本を学習したので、同じものを scikit-learn で実装してみましょう。
ステップ 1 – データセットをロードする
主成分分析の実装方法を理解するために、単純なデータセットを使用してみましょう。 このチュートリアルでは、scikit-learn の一部として利用可能な wine データセットを使用します。 データセット モジュールを開きます。
データセットをロードして前処理することから始めましょう。
from sklearn import datasets
wine_data = datasets.load_wine(as_frame=True)
df = wine_data.data
全部で 13 の機能と 178 のレコードがあります。
print(df.shape)
Output >> (178, 13)
print(df.info())
Output >>
RangeIndex: 178 entries, 0 to 177
Data columns (total 13 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 alcohol 178 non-null float64 1 malic_acid 178 non-null float64 2 ash 178 non-null float64 3 alcalinity_of_ash 178 non-null float64 4 magnesium 178 non-null float64 5 total_phenols 178 non-null float64 6 flavanoids 178 non-null float64 7 nonflavanoid_phenols 178 non-null float64 8 proanthocyanins 178 non-null float64 9 color_intensity 178 non-null float64 10 hue 178 non-null float64 11 od280/od315_of_diluted_wines 178 non-null float64 12 proline 178 non-null float64
dtypes: float64(13)
memory usage: 18.2 KB
Noneステップ 2 – データセットの前処理
次のステップとして、データセットを前処理しましょう。 機能はすべて異なるスケールにあります。 それらすべてを共通のスケールに合わせるために、 StandardScaler これは特徴量をゼロ平均と単位分散を持つように変換します。
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
scaled_df = std_scaler.fit_transform(df)ステップ 3 – 前処理されたデータセットに対して PCA を実行する
主成分を見つけるには、scikit-learn の PCA クラスを使用できます。 分解 モジュールを開きます。
主成分の数を渡して PCA オブジェクトをインスタンス化しましょう n_components コンストラクターに。
主成分の数は、特徴空間を縮小する次元の数です。 ここでは、コンポーネントの数を 3 に設定します。
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
pca.fit_transform(scaled_df)
を呼び出す代わりに fit_transform() メソッドを呼び出すこともできます fit() 続いて transform() 方法。
scikit-learn の PCA 実装を使用すると、共分散行列の計算、共分散行列の固有分解または特異値分解を実行して主成分を取得するなどの主成分分析のステップがすべて抽象化されていることに注目してください。
ステップ 4 – PCA オブジェクトのいくつかの有用な属性を調べる
PCA インスタンス pca 私たちが作成したファイルには、内部で何が起こっているのかを理解するのに役立ついくつかの便利な属性があります。
属性 components_ 最大分散の方向 (主成分) を格納します。
print(pca.components_)
Output >>
[[ 0.1443294 -0.24518758 -0.00205106 -0.23932041 0.14199204 0.39466085 0.4229343 -0.2985331 0.31342949 -0.0886167 0.29671456 0.37616741 0.28675223] [-0.48365155 -0.22493093 -0.31606881 0.0105905 -0.299634 -0.06503951 0.00335981 -0.02877949 -0.03930172 -0.52999567 0.27923515 0.16449619 -0.36490283] [-0.20738262 0.08901289 0.6262239 0.61208035 0.13075693 0.14617896 0.1506819 0.17036816 0.14945431 -0.13730621 0.08522192 0.16600459 -0.12674592]]
主成分はデータセット内の最大分散の方向であると述べました。 しかし、どうやって測定するのでしょうか 合計の差異はどれくらいですか 選択した主成分の数に含まれるでしょうか?
explained_variance_ratio_ 属性は、各主成分が取得する合計分散の比率を取得します。 したがって、比率を合計して、選択した成分数の合計分散を取得できます。
print(sum(pca.explained_variance_ratio_))
Output >> 0.6652996889318527
ここでは、66.5 つの主成分がデータセット内の合計分散の XNUMX% 以上を捉えていることがわかります。
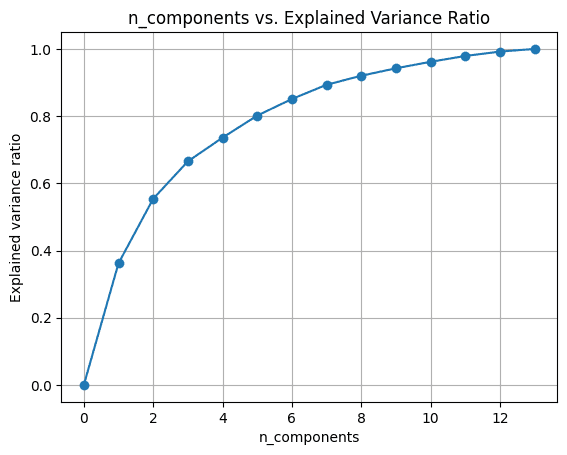
ステップ 5 – 説明された分散比の変化を分析する
成分の数を変えて主成分分析を実行してみることができます。 n_components.
import numpy as np
nums = np.arange(14)
var_ratio = []
for num in nums: pca = PCA(n_components=num) pca.fit(scaled_df) var_ratio.append(np.sum(pca.explained_variance_ratio_))
視覚化するには explained_variance_ratio_ 成分の数については、次のように XNUMX つの量をプロットしてみましょう。
import matplotlib.pyplot as plt plt.figure(figsize=(4,2),dpi=150)
plt.grid()
plt.plot(nums,var_ratio,marker='o')
plt.xlabel('n_components')
plt.ylabel('Explained variance ratio')
plt.title('n_components vs. Explained Variance Ratio')
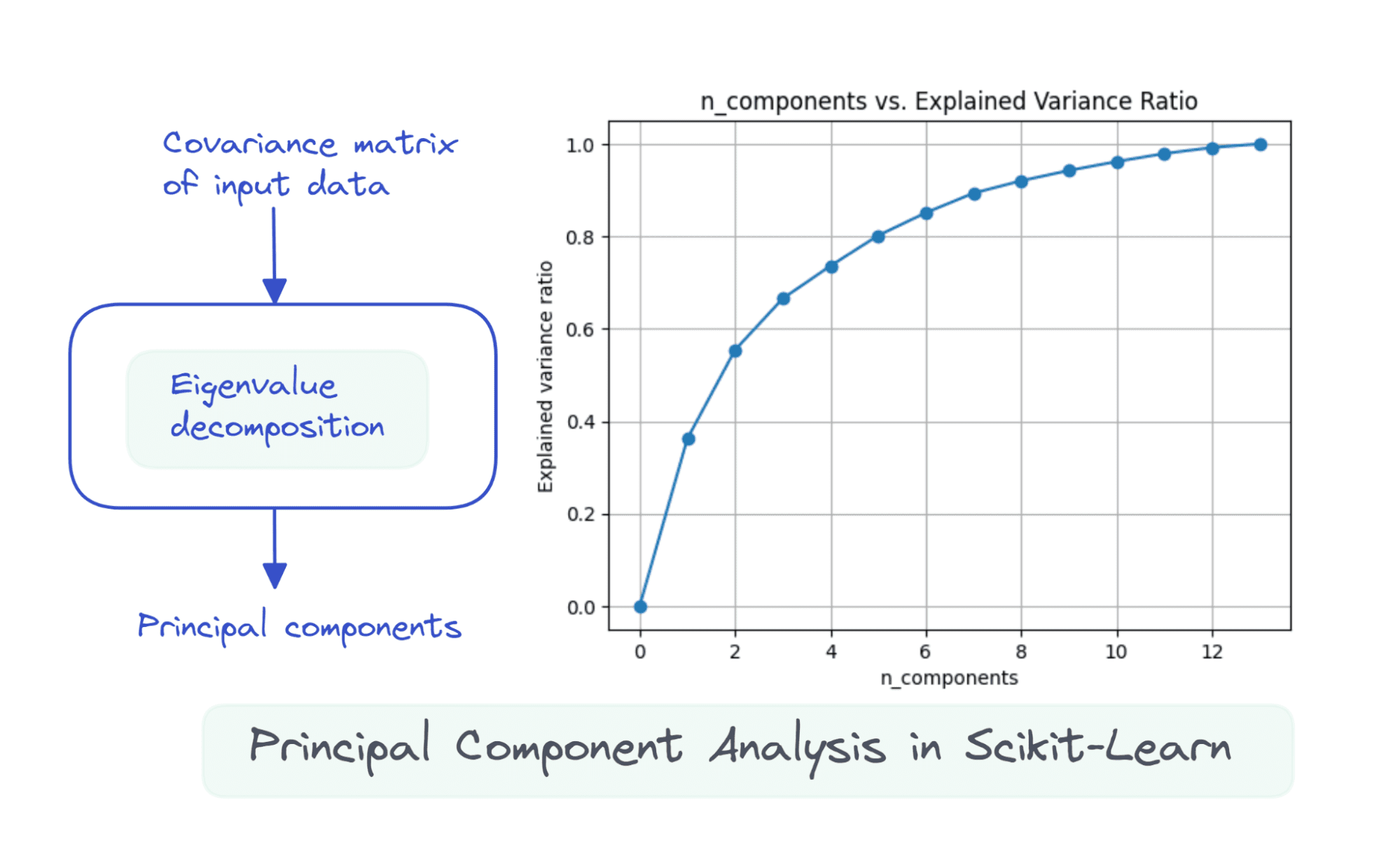
13 個のコンポーネントをすべて使用すると、 explained_variance_ratio_ は 1.0 で、データセット内の分散を 100% 捕捉したことを示します。
この例では、6 つの主成分を使用すると、入力データセットの分散の 80% 以上を捕捉できることがわかります。
scikit-learn ライブラリの組み込み機能を使用して主成分分析を実行する方法を学習できたと思います。 次に、選択したデータセットに PCA を実装してみることができます。 作業に適したデータセットを探している場合は、このリストをチェックしてください。 データ サイエンス プロジェクト用のデータセットを見つけるための Web サイト.
【1] 計算線形代数、速い.ai
バラ プリヤ C インド出身の開発者兼テクニカル ライターです。 彼女は、数学、プログラミング、データ サイエンス、コンテンツ作成が交わる場所で働くのが好きです。 彼女の興味と専門分野には、DevOps、データ サイエンス、自然言語処理が含まれます。 彼女は読書、執筆、コーディング、コーヒーが好きです。 現在、彼女はチュートリアル、ハウツー ガイド、意見記事などを作成して、学習し、開発者コミュニティと知識を共有することに取り組んでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 未来を鋳造する w エイドリエン・アシュリー。 こちらからアクセスしてください。
- PREIPO® を使用して PRE-IPO 企業の株式を売買します。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/05/principal-component-analysis-pca-scikitlearn.html?utm_source=rss&utm_medium=rss&utm_campaign=principal-component-analysis-pca-with-scikit-learn
- :持っている
- :は
- :not
- $UP
- 1
- 10
- 11
- 12
- 13
- 14
- 66
- 7
- 8
- 9
- a
- できる
- 達成する
- 越えて
- 先んじて
- 目指す
- アルコール
- アルゴリズム
- アルゴリズム
- すべて
- また
- 常に
- 分析
- 分析する
- および
- です
- エリア
- AS
- At
- 属性
- オーサリング
- 利用できます
- 離れて
- の基礎
- BE
- き
- 背後に
- 持って来る
- 内蔵
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 計算
- コール
- 呼ばれます
- 呼び出し
- 缶
- キャプチャー
- キャプチャ
- 一定
- 変化する
- チェック
- 選択
- 選んだ
- 選ばれた
- class
- コーディング
- コラム
- コラム
- 来ます
- コマンドと
- コミュニティ
- コンポーネント
- コンポーネント
- 計算
- コンピューティング
- コンテンツ
- コンテンツ作成
- 対応する
- 作成した
- 創造
- 現在
- データ
- データサイエンス
- データセット
- 定義済みの
- Developer
- DevOps
- 異なります
- 次元
- 大きさ
- 方向
- do
- ありません
- すること
- 各
- 効率的な
- エントリ
- 平等に
- 本質的に
- 調べる
- 例
- 専門知識
- 説明
- おなじみの
- スピーディー
- 特徴
- 特徴
- もう完成させ、ワークスペースに掲示しましたか?
- 名
- 続いて
- フォロー中
- 次
- フォーム
- 分数
- から
- 機能性
- 取得する
- 与えられた
- 与える
- Go
- 行く
- 良い
- ガイド
- 持ってる
- 助けます
- 役立つ
- 彼女の
- こちら
- ハイ
- フード
- 希望
- 認定条件
- How To
- HTML
- HTTPS
- i
- if
- 実装する
- 実装
- import
- 重要
- in
- include
- インド
- 示します
- 当初
- 関心
- 交差点
- IT
- ただ
- KDナゲット
- 知識
- 言語
- 大
- 最大の
- LEARN
- 学んだ
- 学習
- 左
- 図書館
- ような
- リスト
- ll
- 負荷
- ローディング
- 探して
- 機械
- 機械学習
- math
- matplotlib
- マトリックス
- 意味する
- 意味
- だけど
- メモリ
- 言及した
- 方法
- モジュール
- 他には?
- 最も
- 一番人気
- 動機
- ずっと
- ナチュラル
- 自然言語
- 自然言語処理
- 次の
- 数
- numpy
- オブジェクト
- of
- on
- ONE
- 意見
- or
- 注文
- オリジナル
- でる
- 出力
- が
- パラダイム
- 部
- 通過
- 割合
- 実行する
- 実行
- ピース
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 人気
- 正の
- 校長
- 処理
- プログラミング
- 投影
- 比
- リーディング
- 記録
- 減らします
- 軽減
- 削減
- それぞれ
- 右
- ランニング
- s
- 同じ
- 規模
- 秤
- 科学
- scikit-学ぶ
- セッションに
- いくつかの
- 形状
- シェアリング
- 彼女
- 示す
- 簡単な拡張で
- 単数
- So
- 一部
- スペース
- スペース
- 広場
- start
- 手順
- ステップ
- まだ
- 店舗
- そのような
- 取り
- 技術的
- より
- それ
- 基礎
- それら
- その後
- そこ。
- ボーマン
- この
- 三
- 〜へ
- トータル
- 変換
- 試します
- チュートリアル
- チュートリアル
- 2
- 一般的に
- 下
- わかる
- 単位
- 教師なし学習
- us
- 使用法
- つかいます
- 中古
- 値
- 価値観
- vs
- we
- この試験は
- 何ですか
- いつ
- Wikipedia
- ワイン
- 仕事
- ワーキング
- 作品
- 作家
- 書き込み
- X
- 貴社
- あなたの
- ゼファーネット
- ゼロ



