
AI がクラウドからエッジに移行するにつれて、異常検出からスマート ショッピング、監視、ロボット工学、工場オートメーションなどのアプリケーションに至るまで、そのテクノロジーがますます拡大するさまざまなユースケースで使用されていることがわかります。 したがって、万能の解決策はありません。 しかし、カメラ対応デバイスの急速な成長に伴い、リアルタイム ビデオ データの分析に AI が最も広く採用され、ビデオ監視を自動化して安全性を強化し、運用効率を向上させ、より良い顧客エクスペリエンスを提供することで、最終的に業界での競争力を獲得しています。 。 ビデオ分析をより適切にサポートするには、エッジ AI 導入におけるシステム パフォーマンスを最適化する戦略を理解する必要があります。
- 必要なパフォーマンス レベルを満たす、またはそれを超える適切なサイズのコンピューティング エンジンを選択します。 AI アプリケーションの場合、これらのコンピューティング エンジンは、ビジョン パイプライン全体の機能 (ビデオの前処理および後処理、ニューラル ネットワーク推論など) を実行する必要があります。
(CPU または GPU で AI 推論を実行するのではなく) 専用の AI アクセラレータが、個別のものであっても、SoC に統合されたものであっても、必要になる場合があります。
- スループットとレイテンシーの違いを理解する。 ここで、スループットはシステム内でデータが処理できる速度であり、レイテンシはシステム全体のデータ処理遅延を測定し、多くの場合、リアルタイムの応答性に関連付けられます。 たとえば、システムは 100 フレーム/秒 (スループット) で画像データを生成できますが、画像がシステムを通過するのに 100 ミリ秒 (遅延) かかります。
- ニーズの増大、要件の変化、テクノロジーの進化(機能性と精度の向上のためのより高度な AI モデルなど)に対応するために、将来的に AI のパフォーマンスを簡単に拡張できることを検討します。 モジュール形式の AI アクセラレータを使用するか、追加の AI アクセラレータ チップを使用して、パフォーマンスのスケーリングを実現できます。
実際のパフォーマンス要件はアプリケーションによって異なります。 通常、ビデオ分析の場合、システムは 30p または 60k の解像度で 1080 ~ 4 フレーム/秒でカメラから受信するデータ ストリームを処理する必要があると予想されます。 AI 対応カメラは単一のストリームを処理します。 エッジ アプライアンスは複数のストリームを並行して処理します。 いずれの場合も、エッジ AI システムは、カメラのセンサー データを AI 推論セクションの入力要件に一致する形式に変換する前処理機能をサポートする必要があります (図 1)。
前処理関数は生データを取り込み、AI アクセラレータで実行されているモデルに入力を供給する前に、サイズ変更、正規化、色空間変換などのタスクを実行します。 前処理では、OpenCV などの効率的な画像処理ライブラリを使用して、前処理時間を短縮できます。 後処理には、推論の出力の分析が含まれます。 非最大抑制 (NMS はほとんどの物体検出モデルの出力を解釈します) や画像表示などのタスクを使用して、境界ボックス、クラス ラベル、信頼スコアなどの実用的な洞察を生成します。

図 1. AI モデル推論の場合、前処理機能と後処理機能は通常、アプリケーション プロセッサ上で実行されます。
AI モデルの推論では、アプリケーションの機能に応じて、フレームごとに複数のニューラル ネットワーク モデルを処理するという追加の課題が発生する可能性があります。 コンピューター ビジョン アプリケーションには通常、複数のモデルのパイプラインを必要とする複数の AI タスクが含まれます。 さらに、あるモデルの出力が次のモデルの入力になることもよくあります。 つまり、アプリケーション内のモデルは相互に依存していることが多く、順番に実行する必要があります。 実行するモデルの正確なセットは静的ではなく、フレームごとであっても動的に変化する可能性があります。
複数のモデルを動的に実行するという課題には、モデルを保存するのに十分な大きさの専用メモリを備えた外部 AI アクセラレータが必要です。 多くの場合、SoC 内の共有メモリ サブシステムやその他のリソースによって課される制約により、SoC 内の統合 AI アクセラレータはマルチモデル ワークロードを管理できません。
たとえば、動き予測に基づくオブジェクト追跡は、継続的な検出に依存して、将来の位置にある追跡オブジェクトを識別するために使用されるベクトルを決定します。 このアプローチには真の再識別機能がないため、その有効性は限られています。 動き予測では、たとえ瞬間的であっても、検出の見逃し、遮蔽、またはオブジェクトが視野から外れたために、オブジェクトの追跡が失われる可能性があります。 一度失われた場合、オブジェクトのトラックを再度関連付けることはできません。 再識別を追加するとこの制限は解決されますが、視覚的な外観の埋め込み (つまり、画像フィンガープリント) が必要です。 外観の埋め込みでは、第 XNUMX のネットワークが、第 XNUMX のネットワークによって検出されたオブジェクトの境界ボックス内に含まれる画像を処理して特徴ベクトルを生成する必要があります。 この埋め込みを使用すると、時間や空間に関係なく、オブジェクトを再識別することができます。 視野内で検出されたオブジェクトごとにエンベディングを生成する必要があるため、シーンが混雑するにつれて処理要件が増加します。 再識別によるオブジェクト追跡では、高精度/高解像度/高フレーム レートの検出を実行することと、埋め込みのスケーラビリティのために十分なオーバーヘッドを確保することとの間で慎重に検討する必要があります。 処理要件を解決する XNUMX つの方法は、専用の AI アクセラレータを使用することです。 前述したように、SoC の AI エンジンは共有メモリ リソースの不足によって問題が発生する可能性があります。 モデルの最適化を使用して処理要件を下げることもできますが、パフォーマンスや精度に影響を与える可能性があります。
スマート カメラまたはエッジ アプライアンスでは、統合 SoC (つまり、ホスト プロセッサ) がビデオ フレームを取得し、前に説明した前処理ステップを実行します。 これらの機能は、SoC の CPU コアまたは GPU (利用可能な場合) で実行できますが、SoC の専用ハードウェア アクセラレータ (画像信号プロセッサなど) で実行することもできます。 これらの前処理ステップが完了すると、SoC に統合された AI アクセラレータは、システム メモリからこの量子化された入力に直接アクセスできるようになります。または、離散型 AI アクセラレータの場合、入力は、通常は推論のために配信されます。 USB または PCIe インターフェイス。
統合 SoC には、CPU、GPU、AI アクセラレータ、ビジョン プロセッサ、ビデオ エンコーダ/デコーダ、画像信号プロセッサ (ISP) などを含むさまざまな計算ユニットを含めることができます。 これらの計算ユニットはすべて同じメモリ バスを共有するため、同じメモリにアクセスします。 さらに、CPU と GPU も推論で役割を果たす必要がある場合があり、これらのユニットはデプロイされたシステム内の他のタスクの実行で多忙になります。 これがシステムレベルのオーバーヘッドの意味です (図 2)。
多くの開発者は、全体のパフォーマンスに対するシステム レベルのオーバーヘッドの影響を考慮せずに、SoC に組み込まれた AI アクセラレータのパフォーマンスを誤って評価しています。 例として、SoC に統合された 50 TOPS AI アクセラレータで YOLO ベンチマークを実行すると、100 推論/秒 (IPS) のベンチマーク結果が得られる可能性があります。 しかし、他のすべての計算ユニットがアクティブな展開されたシステムでは、これらの 50 TOPS は 12 TOPS 程度に減少する可能性があり、使用率を 25% と十分に想定した場合、全体のパフォーマンスは 25 IPS しか得られません。 プラットフォームがビデオ ストリームを継続的に処理している場合、システム オーバーヘッドは常に要因となります。 あるいは、個別の AI アクセラレータ (Kinara Ara-1、Hailo-8、Intel Myriad X など) を使用すると、ホスト SoC が推論機能を開始して AI モデルの入力を転送すると、システムレベルの使用率が 90% を超える可能性があります。データを取得すると、アクセラレータはモデルの重みとパラメータにアクセスするために専用メモリを利用して自律的に実行されます。
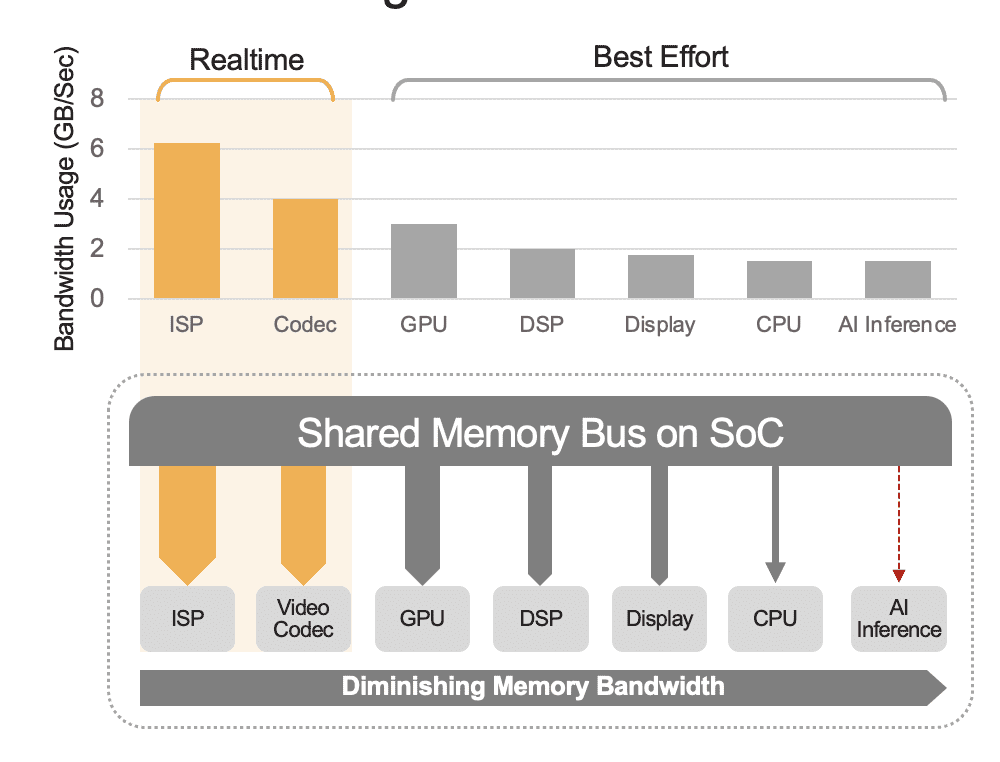
図 2. 共有メモリ バスはシステム レベルのパフォーマンスを制御します。ここでは推定値が示されています。 実際の値は、アプリケーションの使用モデルと SoC のコンピューティング ユニット構成によって異なります。
ここまで、AI のパフォーマンスについて 150 秒あたりのフレーム数と TOPS の観点から説明してきました。 しかし、低遅延は、システムのリアルタイム応答性を実現するためのもう XNUMX つの重要な要件です。 たとえば、ゲームでは、特にモーション コントロール ゲームや仮想現実 (VR) システムでは、シームレスで応答性の高いゲーム エクスペリエンスのために低遅延が重要です。 自動運転システムでは、安全性の低下を避けるために、リアルタイムの物体検出、歩行者認識、車線検出、交通標識認識において低遅延が不可欠です。 自動運転システムでは通常、検出から実際の動作まで XNUMX ミリ秒未満のエンドツーエンドの遅延が必要です。 同様に、製造においても、リアルタイムの欠陥検出、異常認識、ロボット誘導には低遅延が不可欠であり、効率的な運用を確保し、生産のダウンタイムを最小限に抑えるために低遅延のビデオ分析に依存しています。
一般に、ビデオ分析アプリケーションの遅延には 3 つの要素があります (図 XNUMX)。
- データ キャプチャ レイテンシーは、カメラ センサーがビデオ フレームをキャプチャしてから、分析システムがそのフレームを処理できるようになるまでの時間です。 この遅延を最適化するには、高速センサーと低遅延プロセッサを搭載したカメラを選択し、最適なフレーム レートを選択し、効率的なビデオ圧縮形式を使用します。
- データ転送遅延とは、キャプチャされて圧縮されたビデオ データがカメラからエッジ デバイスまたはローカル サーバーに送信されるまでの時間です。 これには、各エンドポイントで発生するネットワーク処理の遅延が含まれます。
- データ処理レイテンシーとは、エッジ デバイスがフレーム解凍や分析アルゴリズム (動き予測ベースのオブジェクト追跡、顔認識など) などのビデオ処理タスクを実行する時間を指します。 前に指摘したように、ビデオ フレームごとに複数の AI モデルを実行する必要があるアプリケーションでは、処理遅延がさらに重要になります。
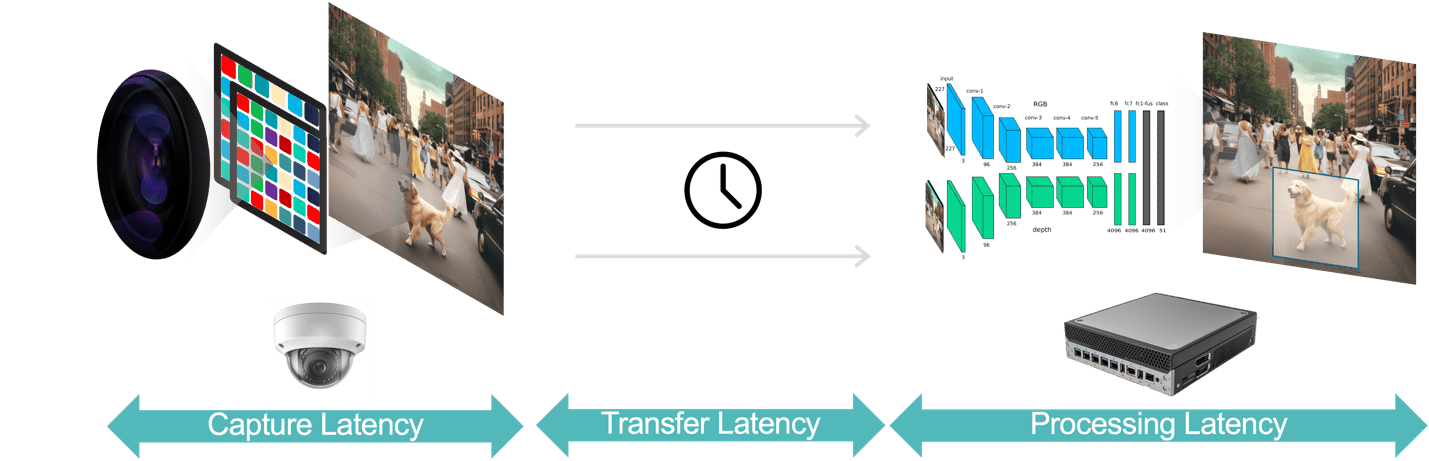
図 3. ビデオ分析パイプラインは、データ キャプチャ、データ転送、データ処理で構成されます。
データ処理レイテンシは、チップ全体、およびコンピューティングとさまざまなレベルのメモリ階層間のデータ移動を最小限に抑えるように設計されたアーキテクチャを備えた AI アクセラレータを使用して最適化できます。 また、遅延とシステム レベルの効率を改善するには、アーキテクチャがモデル間のスイッチング時間をゼロ (またはほぼゼロ) にサポートし、前に説明したマルチモデル アプリケーションをより適切にサポートする必要があります。 パフォーマンスと遅延の両方を向上させるもう XNUMX つの要因は、アルゴリズムの柔軟性に関係します。 言い換えれば、一部のアーキテクチャは特定の AI モデル上でのみ最適な動作をするように設計されていますが、AI 環境の急速な変化に伴い、より高いパフォーマンスとより優れた精度を実現する新しいモデルが毎日のように登場しています。 したがって、モデル トポロジ、演算子、サイズに実質的な制限がないエッジ AI プロセッサを選択してください。
エッジ AI アプライアンスのパフォーマンスを最大化するには、パフォーマンスと遅延の要件、システム オーバーヘッドなど、考慮すべき要素が数多くあります。 戦略を成功させるには、SoC の AI エンジンのメモリとパフォーマンスの制限を克服するために、外部 AI アクセラレータを考慮する必要があります。
CHチー Chee は優れた製品マーケティングおよび管理責任者であり、企業および消費者を含む複数の市場向けのビジョンベースの AI、接続性、およびビデオ インターフェイスに重点を置き、半導体業界での製品およびソリューションの販売促進に豊富な経験を持っています。 起業家として、Chee はビデオ半導体の新興企業 XNUMX 社を共同設立しましたが、これらの企業は上場半導体会社に買収されました。 Chee は製品マーケティング チームを率いており、優れた結果を達成することに重点を置いた小規模なチームと協力することを楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- :持っている
- :は
- :not
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- 能力
- 加速器
- 加速器
- アクセス
- アクセス
- 対応する
- こちらからお申し込みください。
- 精度
- 達成する
- 取得
- を買収
- 越えて
- Action
- アクティブ
- 実際の
- 追加
- NEW
- 採択
- 高度な
- 後
- 再び
- AI
- AIエンジン
- AIモデル
- アルゴリズムの
- アルゴリズム
- すべて
- また
- 常に
- an
- 分析
- 分析論
- 分析する
- および
- 異常検出
- 別の
- 申し込み
- アプローチ
- 建築
- です
- AS
- 関連する
- At
- 自動化する
- オートメーション
- 自律的
- 自律的に
- 賃貸条件の詳細・契約費用のお見積り等について
- 利用できます
- 避ける
- ベース
- 基礎
- BE
- なぜなら
- になる
- き
- さ
- ベンチマーク
- より良いです
- の間に
- 両言語で
- ボックス
- ボックス
- 内蔵
- バス
- 忙しい
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- カメラ
- カメラ
- 缶
- 機能
- 機能
- キャプチャー
- 捕捉した
- キャプチャ
- 注意深い
- 場合
- 例
- 挑戦する
- 変化
- チップ
- チップ
- 選択する
- class
- クラウド
- カラー
- 到来
- 会社
- 競争力のある
- 記入済みの
- コンポーネント
- 妥協する
- 計算
- 計算的
- 計算
- コンピュータ
- Computer Vision
- コンピュータ ビジョン アプリケーション
- 信頼
- 接続性
- その結果
- 検討
- 考慮
- 見なさ
- 考えると
- からなる
- 制約
- consumer
- 含む
- 含まれている
- 連続的な
- 連続的に
- 変換
- 可能性
- CPU
- 重大な
- 顧客
- データ
- データ処理
- 中
- 専用の
- 遅らせる
- 遅延
- 配信する
- 配信
- 依存
- によっては
- 展開
- 配備
- 記載された
- 設計
- 検出された
- 検出
- 決定する
- 開発者
- Devices
- 違い
- 直接に
- 議論する
- ディスプレイ
- ダウンタイム
- 運転
- 原因
- 動的に
- e
- 各
- 前
- 簡単に
- エッジ(Edge)
- 効果
- 有効
- 効率
- 効率
- 効率的な
- どちら
- 埋め込み
- end
- 端から端まで
- エンジン
- エンジン
- 高めます
- 確保
- Enterprise
- 全体
- 起業家
- 環境
- 本質的な
- 推定
- 評価する
- さらに
- あらゆる
- 進化
- 例
- 超えます
- 実行します
- 実行された
- エグゼクティブ
- 期待する
- 体験
- エクスペリエンス
- 広範囲
- 豊富な経験
- 外部
- 顔
- 顔認識
- 要因
- 要因
- 工場
- スピーディー
- 特徴
- 摂食
- フィールド
- フィギュア
- 指紋
- 名
- 柔軟性
- 焦点を当てて
- 焦点
- 形式でアーカイブしたプロジェクトを保存します.
- FRAME
- から
- function
- 機能性
- 機能
- さらに
- 未来
- 獲得
- Games
- 賭博
- ゲーム体験
- 生成する
- 生成された
- 寛大な
- Go
- GPU
- GPU
- 素晴らしい
- 大きい
- 成長
- 成長性
- ガイダンス
- Hardware
- 持ってる
- それゆえ
- こちら
- 階層
- ハイ
- より高い
- host
- HTTPS
- i
- 識別する
- if
- 画像
- 影響
- 重要
- 課さ
- 改善します
- 改善されました
- in
- その他の
- 含ま
- 含めて
- 増える
- 増加した
- 産業
- 産業を変えます
- 開始する
- 内部
- 洞察
- 統合された
- インテル
- インタフェース
- インターフェース
- に
- 巻き込む
- 関与
- 無関係に
- ISP
- IT
- ITS
- KDナゲット
- ラベル
- 欠如
- レーン
- 大
- レイテンシ
- 残す
- ツェッペリン
- less
- レベル
- ライブラリ
- ような
- 制限
- 制限
- 限定的
- ローカル
- 失われた
- ロー
- 下側
- 管理します
- 管理
- 製造業
- 多くの
- マーケティング
- マーケット
- 最大化します
- 最大化
- 五月..
- 意味する
- 措置
- 大会
- メモリ
- 言及した
- かもしれない
- 逃した
- モデル
- モジュール
- モニタリング
- 他には?
- 最も
- モーション
- 運動
- の試合に
- しなければなりません
- 無数の
- 近く
- ニーズ
- ネットワーク
- ニューラル
- ニューラルネットワーク
- 新作
- 次の
- いいえ
- オブジェクト
- オブジェクト検出
- 発生する
- of
- 頻繁に
- on
- かつて
- ONE
- の
- OpenCV
- 操作
- オペレーショナル
- 演算子
- 反対した
- 最適な
- 最適化
- 最適化
- 最適化
- 最適化
- or
- その他
- でる
- 出力
- が
- 全体
- 克服する
- 並列シミュレーションの設定
- パラメータ
- 特に
- 以下のために
- 実行する
- パフォーマンス
- 実行
- 実行
- 実行する
- パイプライン
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- プレイ
- ポイント
- 位置
- 後処理
- 実用的
- 予測
- プロセス
- 処理されました
- 処理
- プロセッサ
- プロセッサ
- プロダクト
- 生産
- 製品
- 推進
- 提供します
- 公共
- 範囲
- 測距
- 急速な
- 急速に
- レート
- 価格表
- Raw
- 生データ
- リアル
- への
- 現実
- 認識
- 減らします
- 指し
- 必要とする
- の提出が必要です
- 要件
- 要件
- 必要
- 解像度
- リソース
- 反応する
- 制限
- 結果
- 結果
- ロボット工学
- 職種
- ラン
- ランニング
- runs
- 安全性
- 同じ
- スケーラビリティ
- 規模
- スケールai
- スケーリング
- シーン
- スコア
- シームレス
- 二番
- セクション
- と思われる
- 選択
- 半導体
- セッションに
- シェアする
- shared
- ショッピング
- すべき
- 示す
- 符号
- シグナル
- 同様に
- から
- サイズ
- 小さい
- スマート
- 溶液
- ソリューション
- 解決する
- 解決する
- 一部
- 何か
- スペース
- 特定の
- ベンチャー
- ステップ
- 店舗
- 作戦
- 戦略
- 流れ
- ストリーム
- 成功した
- そのような
- 十分な
- サポート
- 抑制
- 監視
- システム
- 取る
- 取り
- タスク
- チーム
- チーム
- テクノロジー
- テクノロジー
- 条件
- より
- それ
- 未来
- アプリ環境に合わせて
- その後
- そこ。
- したがって、
- ボーマン
- 彼ら
- この
- それらの
- 三
- 介して
- スループット
- 時間
- <font style="vertical-align: inherit;">回数</font>
- 〜へ
- トップス
- トータル
- 追跡する
- 追跡
- トラフィック
- 転送
- 転送
- 最適化の適用
- 旅行
- true
- 2
- 一般的に
- 最終的に
- できません
- わかる
- 単位
- ユニット
- 使用法
- USB
- つかいます
- 中古
- 使用されます
- 通常
- 活用
- 価値観
- 多様
- さまざまな
- ビデオ
- 詳しく見る
- バーチャル
- バーチャルリアリティ
- ビジョン
- 極めて重要な
- vr
- 仕方..
- we
- した
- この試験は
- かどうか
- which
- 広く
- 意志
- 無し
- 言葉
- ワーキング
- でしょう
- X
- 産出
- ヨロ
- 貴社
- あなたの
- ゼファーネット
- ゼロ







