手書き/印刷されたテキストを機械でエンコードされたテキストに変換する方法である光学式文字認識(OCR)は、さまざまなドメインにわたる多数のアプリケーションにより、常にコンピュータービジョンの主要な研究分野です。銀行はOCRを使用してステートメントを比較します。 政府は、調査のフィードバック収集にOCRを使用しています。

手書きと印刷されたテキストスタイルの多様性により、OCRの最近のアプローチでは、より高い精度を得るためにディープラーニングが組み込まれています。 ディープラーニングではモデルトレーニングに大量のデータが必要になるため、Googleのような企業はOCRサービスで有望な結果を生み出すことに優位に立っています。
この記事では、Pythonでの簡単なチュートリアル、アプリケーションの範囲、価格設定、その他の代替案など、GoogleVisionOCRの詳細について詳しく説明します。
- Google Cloud Vision OCR とは何ですか?
- 簡単なチュートリアル
- なぜOCRなのか?
- ユースケースの例
- 価格(英語)
- Google Cloud VisionOCRの主な機能
- 代替案
- 一般的な問題
Google Cloud Visionとは何ですか?

Google Cloud Vision OCRは、画像からテキストを抽出するためのGoogle Cloud VisionAPIの一部です。 具体的には、文字認識に役立つXNUMXつの注釈があります。
- テキスト_注釈: 任意の画像(ストリートビューや風景の写真など)から機械でエンコードされたテキストを抽出して出力します。 当初はさまざまな照明状況で使用できるように設計されていたため、モデルはある意味でさまざまなスタイルの単語を読み取る際により堅牢ですが、レベルはよりまばらです。 返されるJSONファイルには、文字列全体と、個々の単語およびそれに対応する境界ボックスが含まれます。
- ドキュメント_テキスト_注釈: これは、特に、密に表示されるテキストドキュメント(スキャンされた本など)用に設計されています。 したがって、より小さく、より集中したテキストの読み取りをサポートしますが、実際の画像への適応性は低くなります。 段落、ブロック、区切りなどの情報は、出力JSONファイルに含まれています。
GoogleCloudVisionの欠点を克服するOCRソリューションを探している ゾーンOCR? ナノネットを与える™ より高い精度、より高い柔軟性、そしてより広いドキュメントタイプのためのスピン!
簡単なチュートリアル
次のセクションでは、Google Vision APIの使用を開始するための簡単なチュートリアル、特にGoogle Cloud VisionOCRサービスでの使用方法を紹介します。
簡単な概要
この背後にある考え方は非常に直感的でシンプルです。
1)基本的に画像を(リモートまたはローカルストレージから)Google Cloud VisionAPIに送信します。
2)画像はGoogle Cloudでリモート処理され、呼び出した関数に対応するJSON形式が生成されます。
3)関数が呼び出された後、JSONファイルが出力として返されます。
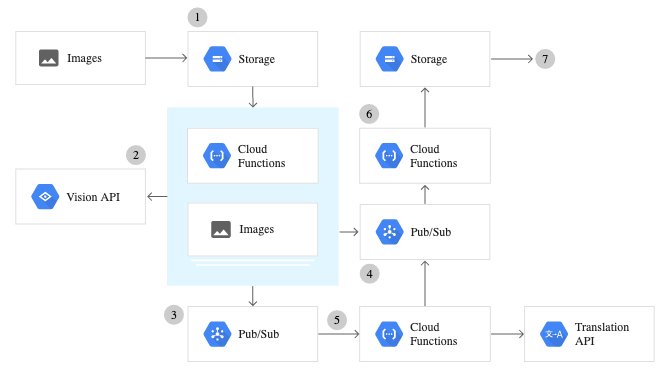
Google Cloud VisionAPIの設定
Google Vision APIが提供するサービスを使用するには、Google Cloud Consoleを設定し、認証のための一連の手順を実行する必要があります。 以下は、VisionAPIサービス全体をセットアップする方法の段階的な概要です。
- Google Cloud Consoleでプロジェクトを作成する— Visionサービスの使用を開始するには、プロジェクトを作成する必要があります。 プロジェクトは、共同編集者、API、価格情報などのリソースを整理します。
- 請求を有効にする— Vision APIを有効にするには、最初にプロジェクトの請求を有効にする必要があります。 価格設定の詳細については、後のセクションで説明します。
- VisionAPIを有効にする
- サービスアカウントの作成—サービスアカウントを作成し、作成したプロジェクトにリンクしてから、サービスアカウントキーを作成します。 キーが出力され、JSONファイルとしてコンピューターにダウンロードされます。
- 環境変数GOOGLE_APPLICATION_CREDENTIALSを設定します。 この環境変数を設定するには、Mac/LinuxまたはWindowsでこれを実行します。
- Mac / Linuxのコードブロック
- Windowsのコードブロック
前述の手順のより詳細な手順は、GoogleCloudが提供する公式ドキュメントから見つけることができます。
https://cloud.google.com/vision/docs/quickstart-client-libraries
PythonのシンプルなGoogleVisionOCR関数
Google Cloud Vision APIは、Java、Node.js、Pythonから、Google独自の言語であるGoまで、さまざまな一般的な言語で動作します。 簡単にするために、Pythonで簡単な呼び出しメソッドを紹介します。
def detect_text(path): """Detects text in the file.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.text_detection(image=image) texts = response.text_annotations print('Texts:') for text in texts: print('n"{}"'.format(text.description)) vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]) print('bounds: {}'.format(','.join(vertices))) つまり、メソッドは結果的に関数を呼び出します テキスト注釈、次に応答をさらに抽出し、情報を出力します。 document_text_annotation 密なテキストを取得するために同じ方法を使用して呼び出すこともできます。 次の方法で画像を設定することにより、リモートで画像を検出することもできます。
image.source.image_uri = uriここで、uri は画像の URI です。
コードの詳細はここで取得できます:
https://cloud.google.com/vision
Google Cloud Visionの欠点を克服するOCRソリューションをお探しですか? ナノネットを与える™ より高い精度、より高い柔軟性、そしてより広いドキュメントタイプのためのスピン!
提供される出力のレベル
テキストのさらなるデータ分析を支援するために、XNUMXつのGoogle OCR関数は、ユーザーが使用できるさまざまなレベルの出力を提供します。 テキスト注釈、文字列全体(GoogleによってXNUMXつの文またはフレーズと見なされる場合)とその中の個々の単語の両方。 にとって document_text_annotation、モデルは高密度のテキスト用に最適化されているため、ページ、ブロック、段落、単語、および区切りはすべて出力の一部として提供されます。
それはどれくらいうまく機能しますか?
モデルはどの程度堅牢ですか?
前述のように、GoogleはXNUMXつの異なる状況でOCR用にXNUMXつの機能を提供しています。 以下では、異なるタイプのデータを取得する際のXNUMXつの関数の機能について説明します。
印刷されたデータ
解釈するのが最も簡単なタイプのデータは、印刷されたテキストデータ、つまり、印刷されてスキャンされたコンピューターで書かれたテキストです。 OCRは、元のマシンでエンコードされたテキストではなく、これらのデータの印刷されたコピーしかない場合に必要です。 これらのテキストのほとんどはタイトでページに詰め込まれているため、 document_text_annotation より良い選択肢になるでしょう。
手書きデータ
コンテンツには手書きのテキストが含まれている場合があり、手書きのデータのスタイルは大幅に異なる場合があります。 それにもかかわらず、Google Vision OCRは、手書きのメモが乱雑になりすぎない限り、まともな精度を提供します。 手書きデータの媒体がどのようにパックされているかに応じて、ケースバイケースでXNUMXつの関数のいずれかを使用します。
ローテーション/インザワイルドデータ
画像またはスキャンされた写真が非正統的または位置合わせされていない角度で提示されている場合、それらは実際のデータと見なされます。 そもそもテキストを検出するのが難しい可能性があるため、通常は テキスト注釈 そもそもインザワイルドデータを処理するために設計された関数。 さまざまな角度でキャプチャされた垂直テキストと道路標識を通過するいくつかの実験に基づいて、Google VisionOCRが実際にさまざまな環境からのデータに対して適切に機能することを示します。
なぜOCRなのか?
現在私たちが持っているデータの多くは、構造化されていない形式です。 たとえば、画像、スキャンされたドキュメント、または写真が与えられた場合、人間はテキストをすばやく認識して意味をさらに解釈できますが、すべてのテキストデータは色付きのピクセルであり、マシンに実際の意味を提供しません。

企業や大企業が大量の事務処理を行っている場合、データ量が多いと、分類やデータ処理を人間の努力だけで行うことは不可能になります。これは、機械でエンコードされたテキストが便利になる場合です。
OCR変換後、データの性質に応じて、複数の異なる方法で情報を分析できます。
- 数値データの場合、統計的手法を直接適用して、相関関係を分析できます。 また、従来の機械学習手法(KNN、K-Means、線形回帰など)または深層学習アプローチを採用して、回帰や分類の予測モデルを作成することもできます。
- テキストデータの場合、より多くの処理段階が必要になる場合があります。 テキストデータを分析して意味のある統計に解釈するプロセスは、自然言語処理(NLP)と呼ばれることがよくあります。 具体的には、特定のコンテンツに基づいて、数値やセマンティクス/雰囲気を抽出することができます。
これらすべての分析により、企業、特に毎日大量の新しいデータを使用する企業は、堅牢なモデルを作成し、多くのプロセスを自動化し、従来の労働集約的でエラー満載のアプローチを置き換えることができます。 次のセクションでは、OCRの使用方法の詳細な例をいくつか詳しく説明します。
Google Cloud Visionの欠点を克服するOCRソリューションをお探しですか? ナノネットを与える™ より高い精度、より高い柔軟性、そしてより広いドキュメントタイプのためのスピン!
ユースケースの例
ナンバープレートの読み取り

おそらく、今日のOCRの最も一般的な使用法のXNUMXつは、ナンバープレート読み取りのアプリケーションです。 先進国では、駐車場には、入口時間、出口時間、さらには車ごとの正確な駐車場所を決定するためのナンバープレート読み取りモデルが付属していることがよくあります。 一部の駐車場は、政府のネットワークに接続されており、駐車料金を家族に直接請求しています。これらはすべて、冗長な人的労力を軽減します。
ナンバープレートOCRモデルは、交通違反の検出にも採用できるため、警察が違反車のデータを手動で入力する時間を短縮できます。
領収書と請求書のスキャン

財務予測と企業の資産と負債のバランスを取ることは、どの企業にとっても重要な活動です。 大企業は年間を通じて複数のセクターから大量の購入を行うため、財務諸表を作成する際には、すべての請求書と領収書を細心の注意を払って収集して処理する必要があります。
OCRの助けを借りて、自動パイプラインを作成できます。 多くの請求書フォーマットを認識する そしてそれらを数値に変換します。労働力はチェックのためだけに必要であり、構造化されたデータと数値により、企業は資金の流入と流出を迅速に均衡させ、財務予測を作成し、会社の財務に対する悪意のある操作を監視することができます。
電気医療記録

患者のデータは、個人のライフスタイルに応じて、地域、国、さらには国全体に散在していることがよくあります。 診療所と病院のスタイルが異なるため(大規模な病院ではデータベースを整理している場合がありますが、小規模な診療所の医師は手作業で記録を書き留める場合があります)、患者の年齢(高齢の患者は、改修および組み込みの前に特定のデータベースに挿入される場合があります)コンピュータ)、および個人の場所(人々は別の都市または海外に移動する可能性があります)、普遍的な医療を維持することは実際には非常に難しい場合があります。
したがって、十分に訓練されたOCRは、EMRをある病院から別の病院に転送したり、手書きのデータをマシンテキストに変換したりするときに便利です。どちらも、患者の病歴をすばやく簡潔に理解するプロセスを促進できます。
フォームと調査

組織(政府機関であろうと非政府機関であろうと)は、現在の販促計画や製品を改善するために、顧客や市民からのフィードバックを必要とすることがよくあります。 フォームは通常手作業で作成されるため、直接的な統計分析を実行することは潜在的に困難です。 したがって、計算を容易にするために非構造化データと手書きの調査を数値に変換するプロセスは、OCRによって支援および加速される可能性があります。
Google Cloud Visionの欠点を克服するOCRソリューションをお探しですか? ナノネットを与える™ より高い精度、より高い柔軟性、そしてより広いドキュメントタイプのためのスピン!
クラウドビジョンの価格
グーグルによると ウェブサイト、 どちらも テキスト注釈 および document_text_annotation 以下と同じ価格レベルで提供されます。
毎月、最初の1000ユニットは無料で提供され、1000-5000000は1.5ユニットあたり1000ドルで課金されます。 5000000マークに達した後、価格は0.6ユニットあたり1000ドルに下がります(Google Vision APIを介して送信された各画像はXNUMXユニットと見なされます)。
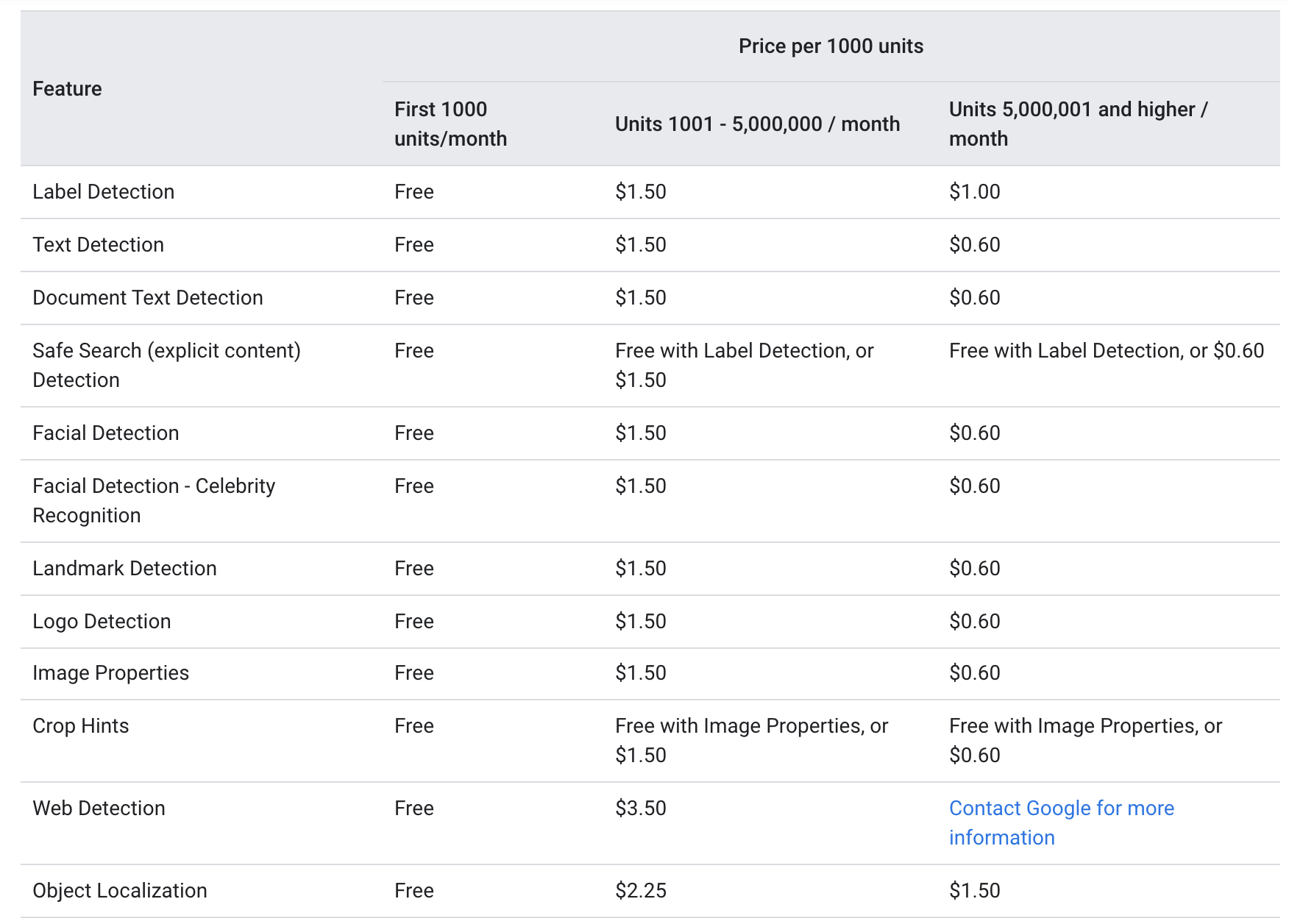
上記の価格設定は、OCRサービスが、使用頻度の低い中小企業と、月に5000000回以上サービスが必要な大企業の両方にとって比較的手頃な価格であることを示しています。
Google Cloud VisionOCRの主な機能
Google OCRにはさまざまな利点があります。ここでは、最も重要な利点のいくつかについて説明します。
- 堅牢な - ユーザーの決定に応じてXNUMX種類のテキストドキュメントを提供するXNUMXつの機能により、Google VisionOCRは単一モデルのOCRエンジンよりも比較的堅牢になります。
- 言語サポート— おそらく最大の言語データベースを備えたGoogleは、OCRが60以上の言語に適用可能であり、さらに数十の言語で実験し、残りの多くを別の言語コードまたは一般的な言語認識機能にマッピングすることをアドバイスしています。
- 使いやすさ - モデル自体は、組み込みのGoogleVisionライブラリの一部です。 APIキーを構成するためのもう少し厄介なプロセス(ほとんどすべてのOCRエンジンで必要です)の後、関数呼び出しメソッドは非常に簡単な方法で多くの言語で使用できます。
- スケーラビリティ— Googleの価格戦略では、使用量が多いほど平均価格が安くなるため、ユーザーはAPIの使用量を増やすことが推奨されます。
- 速度 - Google Cloudのストレージプラットフォームは、APIの使用に見事に対応しています。 イメージをドライブにアップロードすることにより、APIの応答時間は非常に高速でスケーラブルになります。

Google Cloud Visionの欠点を克服するOCRソリューションをお探しですか? ナノネットを与える™ より高い精度、より高い柔軟性、そしてより広いドキュメントタイプのためのスピン!
代替案
以下は、Google Vision API以外のいくつかの代替OCRサービスと、各サービスの長所と短所です。
アビー
ABBYY FineReader PDFは、ABBYYによって開発されたOCRであり、特にPDFの読み取りに重点を置いています。
- 長所: ABBYYは、価格設定がより小さなセクター(1000、2000ページなど)に分割されているため、個々のユーザーにとってはるかにコストに優しいです。 また、商用アプリであるため、エンジニアリング以外のお客様を対象としています。
- 短所: ソフトウェアはPDF形式のみに焦点を当てており、大規模なOCRを実行すると価格が非常に高くなります。
- 使用する場合: PDFをすばやく処理したい個々のユーザーにとって、ABBYYはGoogle Vision APIよりも実行可能なオプションである可能性があります。これにより、柔軟性は向上しますが、追加のコードが必要になります。
Microsoft
Microsoft Azureは、OCR用のReadAPIも提供しています。
- 長所: マイクロソフトは、使用するデータの数がさらに多い場合に、より安い価格を提供します。 Azureクラウドストレージは、GoogleCloudと同様のサービスを提供します。
- 短所: 無料利用枠はありませんが、他のオプションでは使用率の低い無料のAPI呼び出しが提供されます。
- 使用する場合: 非常に大規模なOCR生産パイプラインは、Microsoftの価格設定の恩恵を受ける可能性があります。
コファックス
ABBYYと同様に、KofaxはPDFのOCR読み取りも提供します
- 長所: 価格は個人使用に応じて固定されており、企業には割引が適用されます。 24時間年中無休のカスタマーサポートも提供されます。
- 短所: 品質はABBYYほど高くないと言われています。
- 使用する場合: 使用要件が低い中小企業。
AWS テキストラクト
AWS Textractは、Google VisionAPIと比較して非常によく似た役割を果たします。 彼らのサービスと価格設定は非常に似ているので、どちらを採用するかは完全に顧客の好みに基づいています。
ナノネット
前述のサービスとは異なり、NanonetsのOCRはさらに特定のカテゴリに分類され、各データタイプ(領収書、請求書、運転免許証など)でトレーニングされた堅牢なモデルがあります。
- 長所: カテゴリ固有のOCR。したがって、企業がターゲット固有のアプリケーションにOCRを必要とする場合、精度の点でさらに優れた結果が得られます。
- 短所: Nanonets OCRは、非常に具体的で調整されたモデルのため、実際の設定にはあまり適用できない可能性があります
- 使用する場合: 企業が請求書などの特定の種類のデータにOCRを必要とする場合、Nanonetsはコストに優しく非常に正確なオプションになる可能性があります。
また、ご購読はいつでも停止することが可能です ここでNanonetsOnlineOCRを試してください。
クラウドビジョンに関する一般的な問題
この最後のセクションでは、ドキュメントスキャンとOCRに関するStackoverflowからのいくつかの質問に対処することを目指しています
ニューラルネットワークを使用したドキュメントの認識
これはGoogleOCRの正確な使用法です! 上記の手順に従って、ドキュメントをスキャンし、テキスト検索を実行します。
OCR後に最も重要な詳細を取得する
ドキュメント内の最も意味のあるコンテンツを解析するという考え方は、自然言語処理と呼ばれます。 すべてのドキュメントにはそのような情報がさまざまな形式で含まれているため、いくつかのMLアプローチを採用することをお勧めします。 もちろん、すべてのカードが同じ形式である場合、特定のキー文字を含むテキストを取得するルールベースの方法(たとえば、@が含まれている場合は電子メール)も機能するはずです。
オフラインで実行できますか?
リンク: https://stackoverflow.com/questions/63315520/google-cloud-vision-api-can-it-run-offline
残念だけど違う。 APIはGoogleCloud OCRをリモートで呼び出しますが、APIには費用がかかるため、オフラインで作業することはできません。
テキストが太字か斜体かを検出できますか?
いいえ。Google OCR は、太字や斜体であってもテキスト コンテンツを検出する可能性が高くなりますが、OCR モデルはフォントの種類を理解するように設計されていません。
アップデート: 読者からの質問に基づいて、より多くの情報を追加しました。
- &
- a
- 加速された
- 正確な
- 越えて
- 活動
- 住所
- 利点
- すべて
- 代替案
- 選択肢
- 常に
- 金額
- 分析
- 分析します
- 別の
- API
- API
- アプリ
- 適用可能な
- 申し込み
- 適用された
- アプローチ
- AREA
- 周りに
- 記事
- 資産
- 認証
- 自動化する
- 自動化
- 平均
- Azure
- アズールクラウド
- 背景
- 銀行
- 基礎
- 恩恵
- 利点
- 請求
- ブロック
- 大胆な
- 本
- 国境
- 休憩
- 自動車
- カード
- 一定
- 文字
- チャージ
- 荷担した
- 安い
- 点検
- 市町村
- 分類
- クラウド
- コード
- コマンドと
- 企業
- 会社
- 比べ
- 完全に
- コンピュータ
- コンピューター
- 交流
- 検討
- 領事
- 含まれています
- コンテンツ
- 中身
- 変換
- 法人
- 対応する
- コスト
- 可能性
- 国
- 国
- 作ります
- 作成した
- 作成
- 電流プローブ
- 顧客
- カスタマーサービス
- Customers
- データ
- データ分析
- データ処理
- データベース
- データベースを追加しました
- 中
- 取引
- 決定
- 深いです
- 依存
- によっては
- 説明する
- 設計
- 詳細な
- 細部
- 検出された
- 決定する
- 発展した
- 異なります
- 難しい
- 直接
- 直接に
- 多様性
- 医師
- ドキュメント
- ドメイン
- ダウン
- ドライブ
- 運転
- 各
- イージング
- エッジ(Edge)
- 努力
- 努力
- 登場
- enable
- 励ます
- 企業
- 環境
- 特に
- 本質的に
- 等
- 例
- 出口
- 抽出物
- 家族
- スピーディー
- 特徴
- フィードバック
- 費用
- 財源
- ファイナンシャル
- 会社
- 名
- 固定の
- 柔軟性
- 焦点を当てて
- フォロー中
- 形式でアーカイブしたプロジェクトを保存します.
- フォーム
- 発見
- 無料版
- から
- function
- 機能
- さらに
- 受け
- でログイン
- 政府の
- 政府
- 大きい
- ハンドル
- 助けます
- こちら
- ハイ
- より高い
- 非常に
- history
- 病院
- 認定条件
- How To
- HTTPS
- 人間
- 人間
- アイデア
- 画像
- 画像
- 重要
- 不可能
- 改善します
- 含まれました
- 含ま
- 含めて
- 個人
- 個人
- info
- 情報
- 直観的な
- 問題
- IT
- 自体
- Java
- 保管
- キー
- 労働
- 言語
- ESL, ビジネスESL <br> 中国語/フランス語、その他
- 大
- より大きい
- 最大の
- リード
- 学習
- レベル
- レベル
- 図書館
- ライセンス
- ライセンス
- ライフスタイル
- 可能性が高い
- LINK
- ローカル
- 場所
- 場所
- 長い
- 機械
- 機械学習
- マシン
- 主要な
- make
- 方法
- 手動で
- ゲレンデマップ
- マーク
- 大規模な
- 意味
- 意味のある
- 医療の
- ミディアム
- 言及した
- メソッド
- Microsoft
- ML
- モデル
- お金
- 月
- 他には?
- 最も
- の試合に
- ナチュラル
- 自然
- ニーズ
- ネットワーク
- それにもかかわらず
- ノート
- 数
- 番号
- 多数の
- 提供
- オファー
- 公式
- オンライン
- オンライン
- 最適化
- オプション
- オプション
- 注文
- 整理
- その他
- 自分の
- パック
- パーキング
- 部
- 特定の
- 特に
- 通過
- のワークプ
- おそらく
- プラン
- プラットフォーム
- 警察
- 人気
- 強力な
- ブランド
- 価格設定
- プロセス
- ラボレーション
- 処理
- 生産
- 製品
- プロジェクト
- 予測
- 有望
- 昇進の
- 提供します
- 提供
- は、大阪で
- 提供
- 購入
- 品質
- すぐに
- 範囲
- 測距
- RE
- 読者
- リーディング
- 最近
- 認識する
- 記録
- に対する
- 地域
- リモート
- 必要とする
- の提出が必要です
- 要件
- 必要
- 研究
- リソース
- 応答
- REST
- 結果
- ロード
- 職種
- ラン
- 同じ
- ド電源のデ
- 規模
- スキャン
- スキャニング
- セクター
- センス
- シリーズ
- サービス
- サービス
- サービング
- セッションに
- 設定
- 重要
- サイン
- 同様の
- 簡単な拡張で
- から
- 小さい
- So
- ソフトウェア
- 固体
- 溶液
- 一部
- 特定の
- 特に
- スピン
- ステージ
- 開始
- 文
- 統計的
- 統計
- ストレージ利用料
- 戦略
- ストリート
- 構造化された
- サポート
- サポート
- Survey
- 条件
- したがって、
- 介して
- 全体
- 時間
- <font style="vertical-align: inherit;">回数</font>
- 今日
- に向かって
- 伝統的な
- トラフィック
- トレーニング
- 転送
- 変換
- 下
- わかる
- 理解する
- ユニット
- ユニバーサル
- つかいます
- users
- 通常
- さまざまな
- ビジョン
- ボリューム
- よく見る
- かどうか
- while
- 誰
- より広い
- ウィンドウズ
- 以内
- 言葉
- 仕事
- 作品
- でしょう
- X
- 年
- あなたの