AmazonOpenSearchサービス は、AWS クラウド内で大規模な OpenSearch クラスターの保護、デプロイ、運用を簡単にするマネージド サービスです。 昨年もご紹介しましたが、 シャードインデックスバックプレッシャー および アドミッションコントロールクラスターのリソースと受信トラフィックを監視し、メモリー不足などの安定性のリスクを引き起こし、メモリー競合、CPU 飽和、GC オーバーヘッドなどによりクラスターのパフォーマンスに影響を与えるリクエストを選択的に拒否します。
私たちは今回、OpenSearch Service 向けの検索バックプレッシャーと CPU ベースのアドミッション コントロールを導入し、クラスターの復元力をさらに強化できることを嬉しく思います。 これらの改善は、すべての OpenSearch バージョン 1.3 以降で利用できます。
検索バックプレッシャー
バックプレッシャーは、システムが作業で圧倒されるのを防ぎます。 これは、クラッシュやデータ損失を防ぎ、パフォーマンスを向上させ、システムの完全な障害を回避するために、トラフィック レートを制御するか過剰な負荷を軽減することによって行われます。
検索バックプレッシャーは、ノードが圧迫されている場合に、リソースを大量に消費する実行中の検索リクエストを特定してキャンセルするメカニズムです。 これは、リソース使用率が異常に高い検索ワークロード (複雑なクエリ、遅いクエリ、多数のヒット、または大量の集計など) に対して効果的です。そうでないと、ノードのクラッシュが発生し、クラスターの健全性に影響を与える可能性があります。
Search Backpressure は、タスク リソース追跡フレームワークの上に構築されており、各タスクのリソース使用状況を監視するための使いやすい API を提供します。 検索バックプレッシャーは、ノードのリソース使用量を定期的に測定するバックグラウンド スレッドを使用し、CPU 時間、ヒープ割り当て、経過時間などの要素に基づいて、実行中の各検索タスクにキャンセル スコアを割り当てます。 キャンセルスコアが高いほど、より多くのリソースを消費する検索リクエストに対応します。 ノードを迅速に回復するために、検索リクエストはキャンセル スコアの降順にキャンセルされますが、無駄な作業を避けるためにキャンセルの数はレート制限されています。
次の図は、検索バックプレッシャーのワークフローを示しています。
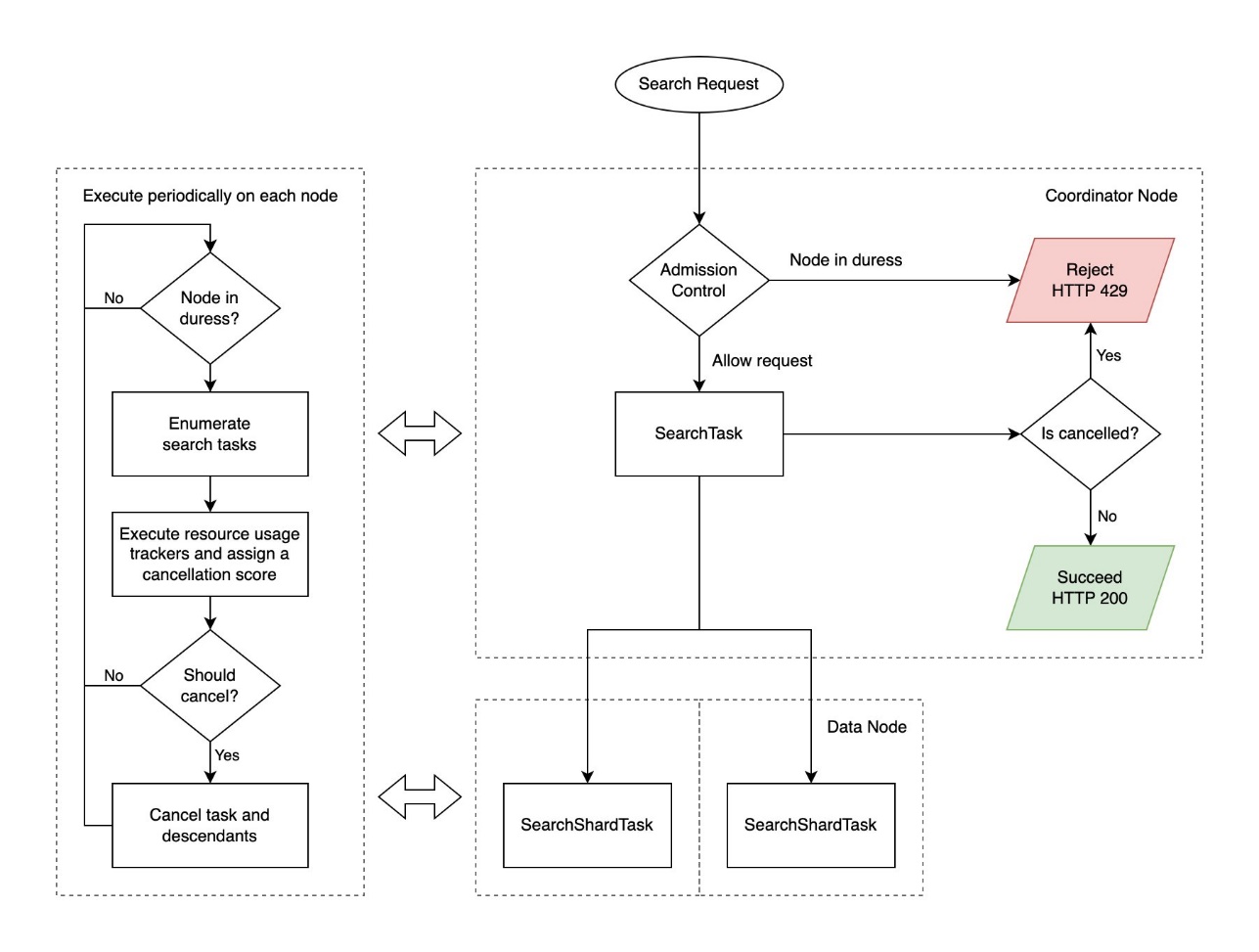
検索リクエストは、キャンセル時に HTTP 429「リクエストが多すぎます」ステータス コードを返します。 一部のシャードのみが失敗し、部分的な結果が許可される場合、OpenSearch は部分的な結果を返します。 次のコードを参照してください。
検索バックプレッシャーの監視
ノード統計 API を使用して、検索バックプレッシャーの詳細な状態を監視できます。
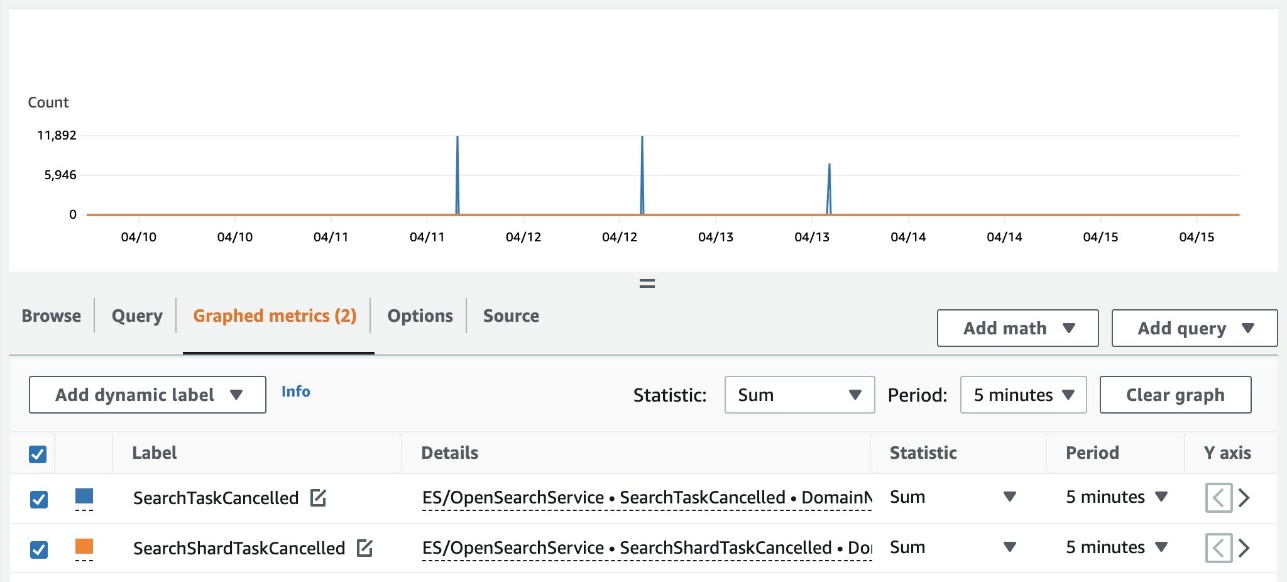
次を使用して、クラスター全体のキャンセルの概要を表示することもできます。 アマゾンクラウドウォッチ。 次のメトリクスが、 ES / OpenSearchService 名前空間:
- 検索タスクキャンセルされました – コーディネーターノードのキャンセル数
- 検索シャードタスクキャンセルされました – データノードのキャンセル数
次のスクリーンショットは、CloudWatch コンソールでこれらのメトリクスを追跡する例を示しています。
CPU ベースのアドミッション コントロール
アドミッション コントロールは、トラフィックの自然な増加とスパイクの両方に対して、現在の容量に基づいてノードへのリクエストの数をプロアクティブに制限するゲートキーピング メカニズムです。
JVM のメモリ負荷とリクエスト サイズのしきい値に加えて、各ノードの移動平均 CPU 使用率も監視して、受信を拒否するようになりました。 _search および _bulk リクエスト。 これにより、ホットスポット、パフォーマンスの問題、リクエストのタイムアウト、その他の連鎖的な障害につながる、ノードが多すぎるリクエストで圧倒されるのを防ぎます。 過剰なリクエストは、拒否時に HTTP 429「リクエストが多すぎます」ステータス コードを返します。
HTTP 429 エラーの処理
ノードに過剰なトラフィックを送信すると、HTTP 429 エラーが発生します。 これは、クラスター リソースの不足、リソースを大量に消費する検索リクエスト、またはワークロードの意図しないスパイクのいずれかを示します。
検索バックプレッシャーは拒否の理由を提供し、リソースを大量に消費する検索リクエストを微調整するのに役立ちます。 トラフィックが急増した場合は、指数関数的なバックオフとジッターを使用してクライアント側で再試行することをお勧めします。
次のトラブルシューティング ガイドに従って過剰な拒否をデバッグすることもできます。
まとめ
検索バックプレッシャーは過剰な負荷を軽減するための事後的なメカニズムであるのに対し、アドミッション コントロールはノードへの要求の数をその容量を超えて制限するためのプロアクティブなメカニズムです。 両方が連携して動作し、OpenSearch クラスターの全体的な復元力を向上させます。
検索バックプレッシャーは次の場所で利用できます。 Opensearch、私たちは常に探しています 外部貢献。 を参照できます。 RFC 始めるために。
著者について
 ケタン・ヴェルマ Amazon OpenSearch Service に取り組むシニア SDE です。 彼は、大規模な分散システムの構築、パフォーマンスの向上、単純な抽象化による複雑なアイデアの簡素化に情熱を注いでいます。 仕事以外では、読書をしたり、ホーム バリスタのスキルを向上させることが好きです。
ケタン・ヴェルマ Amazon OpenSearch Service に取り組むシニア SDE です。 彼は、大規模な分散システムの構築、パフォーマンスの向上、単純な抽象化による複雑なアイデアの簡素化に情熱を注いでいます。 仕事以外では、読書をしたり、ホーム バリスタのスキルを向上させることが好きです。
 スレッシュ NS Amazon OpenSearch Service に取り組むシニア SDE です。 彼は大規模な分散システムの問題の解決に情熱を注いでいます。
スレッシュ NS Amazon OpenSearch Service に取り組むシニア SDE です。 彼は大規模な分散システムの問題の解決に情熱を注いでいます。
 プリトクマール・ラダニ は、Amazon OpenSearch Service で動作する SDE-2 です。 彼はオープンソース ソフトウェア開発に貢献することが好きで、分散システムに情熱を持っています。 彼はアマチュアのバドミントン選手で、トレッキングが趣味です。
プリトクマール・ラダニ は、Amazon OpenSearch Service で動作する SDE-2 です。 彼はオープンソース ソフトウェア開発に貢献することが好きで、分散システムに情熱を持っています。 彼はアマチュアのバドミントン選手で、トレッキングが趣味です。
 ブフタワル・カーン Amazon OpenSearch Service に取り組むプリンシパルエンジニアです。 彼は分散型自律システムの構築に興味を持っています。 彼は OpenSearch のメンテナーであり、積極的な貢献者でもあります。
ブフタワル・カーン Amazon OpenSearch Service に取り組むプリンシパルエンジニアです。 彼は分散型自律システムの構築に興味を持っています。 彼は OpenSearch のメンテナーであり、積極的な貢献者でもあります。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- EVMファイナンス。 分散型金融のための統一インターフェイス。 こちらからアクセスしてください。
- クォンタムメディアグループ。 IR/PR増幅。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/improved-resiliency-with-backpressure-and-admission-control-for-amazon-opensearch-service/
- :は
- 1
- 1.3
- 100
- 26
- 7
- 77
- a
- 私たちについて
- アクティブ
- 添加
- に対して
- すべて
- 割り当て
- また
- 常に
- 素人
- Amazon
- Amazon Webサービス
- an
- および
- API
- です
- AS
- At
- 自律的
- 自律システム
- 利用できます
- 平均
- 避ける
- AWS
- 背景
- バリスタ
- ベース
- さ
- 越えて
- 両言語で
- 建物
- 内蔵
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 缶
- 容量
- 原因となる
- クラウド
- クラスタ
- コード
- 複雑な
- 領事
- 貢献する
- 寄稿者
- コントロール
- 制御
- コーディネーター
- 対応する
- 可能性
- CPU
- 電流プローブ
- データ
- データ損失
- 展開します
- 詳細な
- 開発
- 配布
- 分散システム
- ありません
- 原因
- 各
- 使いやすい
- 効果的な
- どちら
- エンジニア
- 強化
- エラー
- エラー
- エーテル(ETH)
- 例
- 超過
- 興奮した
- 指数関数
- 要因
- フェイル
- 不良解析
- フォロー中
- フレームワーク
- から
- さらに
- ゲートキーピング
- 取得する
- ガイド
- he
- 健康
- ヘビー
- 助けます
- ハイ
- より高い
- 彼の
- ヒット
- ホーム
- HOT
- HTTP
- HTTPS
- 考え
- 識別する
- if
- 説明する
- 影響
- 改善します
- 改善されました
- 改善
- 改善
- in
- 入ってくる
- 増加
- index
- を示し
- 興味がある
- 紹介する
- 導入
- IT
- ITS
- JPG
- 大
- 大規模
- 姓
- 昨年
- 主要な
- ような
- LIMIT
- 制限
- 負荷
- 探して
- 損失
- 作る
- マネージド
- 多くの
- 措置
- メカニズム
- メモリ
- メトリック
- モニター
- モニター
- 他には?
- ノード
- 今
- 数
- of
- on
- の
- 開いた
- オープンソース
- 操作する
- or
- 注文
- オーガニック
- その他
- さもないと
- でる
- 外側
- 全体
- 圧倒
- 情熱的な
- パフォーマンス
- 相
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- プレイヤー
- 圧力
- 防ぐ
- を防止
- 校長
- 先を見越した
- 問題
- は、大阪で
- クエリ
- すぐに
- レート
- 読む
- 理由
- 受け取ります
- 推奨する
- 回復する
- 要求
- リクエスト
- リソースを追加する。
- リソースを大量に消費する
- リソース
- 結果
- return
- 収益
- リスク
- 圧延
- 規模
- スコア
- を検索
- 安全に
- 送信
- シニア
- サービス
- サービス
- 小屋
- 作品
- 簡単な拡張で
- 単純化
- サイズ
- スキル
- 遅く
- So
- ソフトウェア
- ソフトウェア開発
- 解決
- 一部
- ソース
- スパイク
- スパイク
- 安定性
- 開始
- 都道府県
- 統計情報
- Status:
- そのような
- 概要
- システム
- タンデム
- 仕事
- それ
- アプリ環境に合わせて
- ボーマン
- 時間
- 〜へ
- あまりに
- top
- トータル
- に向かって
- 追跡
- トラフィック
- true
- type
- 下
- に
- 使用法
- 使用されます
- 詳しく見る
- ました
- we
- ウェブ
- Webサービス
- いつ
- which
- while
- 仕事
- ワークフロー
- ワーキング
- でしょう
- 年
- 貴社
- ゼファーネット