概要
の合併 人工知能 (AI) と芸術性は、拡散モデルを通じて顕著に、創造的なデジタル アートの新しい道を明らかにします。これらのモデルは、クリエイティブな AI アート生成において際立っており、従来のニューラル ネットワークとは異なるアプローチを提供します。この記事では、拡散モデルの深部への探究の旅にあなたを導き、視覚的に見事で創造性に富んだアートワークを作成する際のそのユニークなメカニズムを解明します。拡散モデルのニュアンスを理解し、高度な AI テクノロジーのレンズを通して芸術表現を再定義する際の拡散モデルの役割について洞察を得ることができます。

学習目標
- AI の拡散モデルの基本概念を理解します。
- アート生成における拡散モデルと従来のニューラル ネットワークの違いを探ります。
- 拡散モデルを使用してアートの作成プロセスを分析します。
- デジタル アートにおける AI の創造的および美的影響を評価します。
- AI によって生成されたアートワークにおける倫理的考慮事項について話し合います。
この記事は、の一部として公開されました データサイエンスブログ。
目次
拡散モデルを理解する

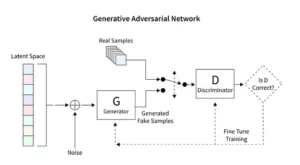
拡散モデルは生成 AI に革命をもたらし、敵対的生成ネットワーク (GAN) のような従来の技術とは異なる独自の画像作成方法を提供します。これらのモデルは、ランダムなノイズから始まり、芸術家が絵画を微調整するのと同じように、徐々にノイズを改良し、複雑で一貫した画像をもたらします。
この段階的な改良プロセスは、拡散の系統的な性質を反映しています。ここでは、反復するたびにノイズが微妙に変化し、最終的な芸術的ビジョンに近づいていきます。出力は単なるランダム性の産物ではなく、進化した芸術作品であり、その進行と仕上がりが際立っています。
拡散モデルのコーディングには、ニューラル ネットワークと TensorFlow や PyTorch などの機械学習フレームワークを深く理解する必要があります。結果として得られるコードは複雑で、AI によって生成されたアートで観察される微妙な効果を実現するには、広大なデータセットに対する広範なトレーニングが必要です。
安定した拡散を芸術に応用する
安定した拡散モデルのような AI アート ジェネレーターの出現には、TensorFlow や PyTorch などのプラットフォーム内での高度なコーディングが必要です。これらのモデルは、アーティストが予備スケッチを磨き上げて鮮やかな傑作を完成させるのと同じように、ランダム性を体系的に構造に変換する能力で際立っています。
安定した拡散モデルは、GAN の特徴である競争ダイナミクスを回避し、ランダム性から整然とした画像を彫刻することで AI アート シーンを再形成します。彼らは概念的なプロンプトを視覚芸術に解釈することに優れており、AI の能力と人間の創意工夫の間の相乗的なダンスを促進します。 PyTorch を利用することで、これらのモデルがどのように繰り返しカオスを明晰に洗練し、初期のアイデアから洗練された作品に至るまでのアーティストの旅を反映しているかを観察します。
AI が生成したアートの実験
このデモンストレーションでは、畳み込みニューラル ネットワークを使用して、AI によって生成されたアートの魅力的な世界を掘り下げます。 変換拡散モデル。このモデルは、図面、絵画、彫刻、彫刻を含むさまざまなアート画像でトレーニングされています。 この Kaggle データセット。私たちの目標は、これらの芸術作品の複雑な美学を捉えて再現するモデルの能力を探ることです。
モデルのアーキテクチャとトレーニング
建築設計
ConvDiffusionModel の核心はニューラル エンジニアリングの驚異であり、アート生成の要求に合わせて調整された洗練されたエンコーダー/デコーダー アーキテクチャを特徴としています。モデルの構造は複雑なニューラル ネットワークであり、アート生成のために特別に磨かれた洗練されたエンコーダー/デコーダー メカニズムが統合されています。追加の畳み込みレイヤーと芸術的な直観をエミュレートするスキップ接続により、モデルは構成とスタイルを鋭敏に理解して芸術を分析し、再構築することができます。
- エンコーダ: エンコーダーはモデルの分析眼であり、すべての入力画像の細部を精査します。画像がエンコーダーの畳み込み層を通過するにつれて、画像は潜在空間 (元のアートワークのコンパクトなエンコード表現) に徐々に圧縮されます。私たちのエンコーダーは、入力画像を精査するだけでなく、追加のレイヤーとバッチ正規化技術のおかげで、知覚の深さを強化して精査します。この拡張された検討により、潜在空間内でより豊かで凝縮された表現が可能になり、主題についてのアーティストの深い熟考が反映されます。
- デコーダ: 対照的に、デコーダーはモデルの創造的な手として機能し、エンコーダーから抽象的なスケッチを取り出し、それらに命を吹き込みます。完全なイメージが現れるまで、潜在的な空間からレイヤーごと、細部ごとにアートワークを再構築します。私たちのデコーダーはスキップ接続の恩恵を受け、より正確にアートワークを再構築できます。入力の抽象化された本質を再考し、それを徐々に装飾して、ソース素材により忠実な表現を実現します。強化されたレイヤーは連携して動作し、最終的な画像が入力の芸術性を反映した鮮やかで複雑な作品になるようにします。
トレーニングプロセス
ConvDiffusionModel のトレーニングは、150 エポックにわたる芸術的な風景を巡る旅です。各エポックはデータセット全体の完全なパスを表し、モデルは理解を深め、生成された画像の忠実度を向上させるよう努めます。
- ハイブリッド損失関数: トレーニングの中心となるのは、平均二乗誤差 (MSE) 損失関数です。この機能は、オリジナルの傑作とモデルの再現との違いを定量化し、最小化するための明確な指標を提供します。平均二乗誤差 (MSE) メトリクスを補完する、事前トレーニングされた VGG ネットワークから派生した知覚損失コンポーネントを導入します。この二重損失戦略により、オリジナルの芸術的完全性を尊重しながら、細部の技術的再現を完璧にするモデルが推進されます。
- オプティマイザ: Adam オプティマイザーは、スケジューラーによって学習率が動的に調整されるため、より賢明なモデルの学習を導きます。この適応的なアプローチにより、芸術の複製と革新を学習する際のモデルの進歩が安定して堅牢になることが保証されます。
- 反復と改良: トレーニングの反復は、芸術的本質の保存と技術的な複製の追求の間で行われます。サイクルが進むごとに、モデルは忠実さと創造性の統合に近づいていきます。
- 進行状況の視覚化: モデルの進行状況を視覚化するために、トレーニング中に画像が定期的に保存されます。。これらのスナップショットは、モデルの学習曲線への窓を提供し、生成されたアートがどのように進化し、時代ごとにより明確に、より詳細に、より芸術的に一貫したものになるかを示します。



上記は、次のコード部分によって示されます。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')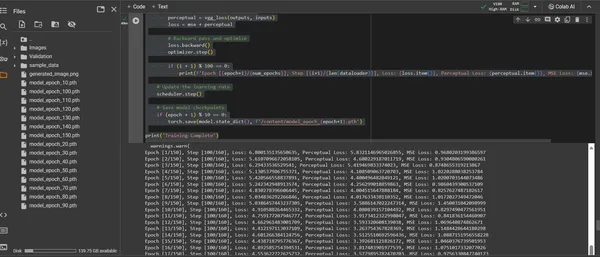
生成されたアートワークの視覚化
AI が作り上げた芸術性の表現
ConvDiffusionModel が完全にトレーニングされたことで、焦点は抽象的なものから具体的なもの、つまり潜在的なものから AI によって作られたアートの実現へと移ります。後続のコード スニペットは、モデルが学習した芸術的能力を具体化し、入力データを表現のデジタル キャンバスに変換します。
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()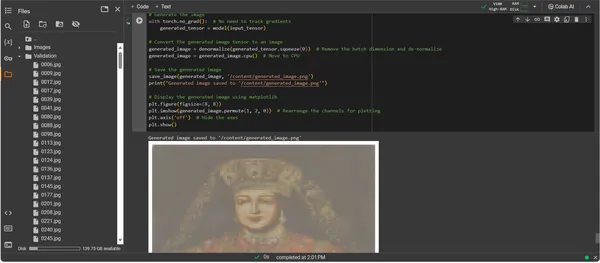

アートワーク生成コードのチュートリアル
- モデルの復活: アートワーク生成の最初のステップは、トレーニングされた ConvDiffusionModel を復活させることです。モデルの学習された重みがロードされて評価モードになり、パラメータをさらに変更することなく作成の準備が整います。
- 画像変換: トレーニング方式との一貫性を確保するために、入力画像は同じ一連の変換を通じて処理されます。これには、モデルの入力次元に一致するサイズ変更、PyTorch 互換性のためのテンソル変換、トレーニング データの統計プロファイルに基づく正規化が含まれます。
- 非正規化ユーティリティ: カスタム関数は前処理効果を反転し、テンソルを元のイメージの色範囲に再スケーリングします。このステップは、生成された出力を視覚的に正確な表現にレンダリングするために不可欠です。
- 入力の準備: 画像がロードされ、前述の変換が行われます。この画像が AI がインスピレーションを引き出すミューズとして機能することに注意することが重要です。静かなささやきがモデルの総合的な想像力を刺激します。
- アートワークの合成: 順伝播の繊細なダンスで、モデルは入力テンソルを解釈し、そのレイヤーが協力して新しい芸術的ビジョンを生み出すことができるようにします。ここではトレーニングではなくアプリケーションの領域にいるため、勾配を追跡せずにこのプロセスを実行します。
- 画像変換: デジタルで生まれたアートワークを保持するモデルのテンソル出力は非正規化され、モデルの作成を私たちの目が認識できる色と光の馴染みのある空間に変換し直します。
- アートワークの啓示: 変換されたテンソルはデジタル キャンバス上にレイアウトされ、最終的に保存された画像ファイルになります。このファイルは、AI の創造的な魂への窓であり、AI に命を与えた動的なプロセスの静的なエコーです。
- アートワークの取得: スクリプトは、生成されたイメージを指定されたパスに保存し、その完了を通知することで終了します。保存されたイメージは、学習した芸術的原則と新たな創造性を統合したもので、すぐに表示したり熟考したりできます。
出力の分析
ConvDiffusionModel の出力は、歴史的芸術を明確に反映した図を示します。精巧な衣装をまとった AI レンダリングの画像は、古典的な肖像画の壮大さを反映しながらも、独特で現代的なタッチを加えています。被験者の服装は質感が豊かで、モデルが学習したパターンと斬新な解釈が融合しています。繊細な顔の特徴と光と影の微妙な相互作用は、伝統的な芸術技法に対する AI の微妙な理解を示しています。このアートワークはモデルの洗練されたトレーニングの証であり、高度な機械学習のプリズムを通じて歴史的な芸術性のエレガントな統合を反映しています。本質的に、それは現在のアルゴリズムで作られた、過去へのデジタルオマージュです。
課題と倫理的考慮事項
アート生成のための拡散モデルの実装には、考慮すべきいくつかの課題と倫理的考慮事項が伴います。
- データの証明: トレーニング データセットは責任を持ってキュレーションする必要があります。拡散モデルのトレーニングに使用されるデータに、適切な許可なしに著作権で保護された作品が含まれていないことを確認することが不可欠です。
- 偏見と表現: AI モデルは、トレーニング データにバイアスを永続させる可能性があります。 AI によって生成されたアートにおける固定観念の強化を避けるためには、多様で包括的なデータセットを確保することが重要です。
- 出力の制御: 拡散モデルは幅広い出力を生成する可能性があるため、不適切または攻撃的なコンテンツの作成を防ぐために境界を設定する必要があります。
- 法的枠組み: 創造的なプロセスにおける AI の微妙な違いに対処するための強固な法的枠組みの欠如が課題となっています。関係者全員の権利を保護するために法律を進化させる必要があります。
まとめ
AI とアートにおける拡散モデルの台頭は、計算精度と美的探求を融合させた変革の時代を迎えています。アートの世界での彼らの旅は、大きなイノベーションの可能性を浮き彫りにしますが、複雑さも伴います。独創性、影響力、倫理的な創作、既存の作品への敬意のバランスをとることは、芸術のプロセスに不可欠です。
主要な取り組み
- 拡散モデルは、芸術創作における変革の最前線にあります。彼らは、従来の境界を超えて芸術表現のキャンバスを広げる新しいデジタルツールを提供します。
- AI で強化された芸術においては、デジタル芸術の完全性を維持するために、トレーニング データの倫理的な収集を優先し、クリエイターの知的財産を尊重することが不可欠です。
- 芸術的ビジョンと技術革新の融合により、アーティストと AI 開発者の共生関係への扉が開かれます。革新的なアートを生み出すコラボレーション環境を育みます。
- AI によって生成されたアートが幅広い視点を表現できるようにすることが重要です。さまざまな文化や視点の豊かさを反映するさまざまなデータを組み込み、包括性を促進します。
- AI によって作られたアートへの関心が高まっているため、強固な法的枠組みの確立が必要となっています。これらの枠組みでは、著作権の問題を明確にし、貢献を認識し、AI によって生成されたアートワークの商業利用を管理する必要があります。
この芸術的進化の夜明けは、創造的な可能性に満ちた道を提供しますが、注意深い後見が必要です。責任ある文化的に配慮した実践に基づいて、AI とアートの融合が繁栄する環境を育むことが私たちの義務です。
よくある質問
A. 拡散モデルは、ランダムなノイズのパターンから始めて、それを徐々に一貫した画像に成形することで画像を作成する生成 ML アルゴリズムです。このプロセスは、アーティストが空白のキャンバスから始めて、徐々に詳細のレイヤーを追加していくのに似ています。
A. GAN、拡散モデルでは、出力を判断するために別のネットワークは必要ありません。ノイズの追加と削除を繰り返し行うことで機能し、多くの場合、より詳細でニュアンスのある画像が得られます。
A. はい、拡散モデルは画像のデータセットから学習することでオリジナルのアート作品を生成できます。ただし、独自性はトレーニング データの多様性と範囲によって影響されます。これらのモデルをトレーニングするために既存のアートワークを使用することの倫理については、現在も議論が行われています。
A. 倫理的な懸念には、AI によって生成されたアートの著作権侵害を回避することが含まれます。人間のアーティストの独創性を尊重し、偏見の永続を防ぎ、AI の創作プロセスの透明性を確保します。
A. AI 生成アートの将来は有望に見えます。拡散モデルはアーティストやクリエイターに新しいツールを提供します。テクノロジーの進歩に伴い、より洗練された複雑な芸術作品が見られることが期待されます。ただし、クリエイティブ コミュニティは倫理的な考慮事項を考慮し、明確なガイドラインとベスト プラクティスに向けて取り組む必要があります。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- :は
- :not
- :どこ
- 001
- 1
- 10
- 100
- 11
- 12
- 視聴者の38%が
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- 能力
- 私たちについて
- 上記の.
- 抽象
- 正確な
- 達成する
- 達成する
- アダム
- 適応
- 追加
- NEW
- 住所
- 調整
- 高度な
- 進歩
- 出現
- 敵対者
- AI
- 愛アート
- 同族の
- アルゴリズム
- すべて
- 許可
- ことができます
- an
- 分析的
- 分析論
- 分析Vidhya
- および
- 発表
- 申し込み
- 認める
- アプローチ
- 建築
- です
- 宝品
- 記事
- アーティスト
- 芸術的
- 芸術的に
- 芸術性
- Artists
- 芸術作品
- 作品
- AS
- At
- 増強された
- 承認
- 利用できます
- 通り
- 避ける
- 回避
- 軸
- バック
- 悪い
- バランシング
- ベース
- BE
- になる
- 利点
- BEST
- ベストプラクティス
- の間に
- 越えて
- バイアス
- バイアス
- ブランク
- 混合
- ブログソン
- 生まれる
- 両言語で
- 境界
- 呼吸
- あふれんばかり
- もたらす
- 広い
- た
- 急成長
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 計算する
- 呼ばれます
- 缶
- キャンバス
- 機能
- 機能
- キャプチャー
- 挑戦する
- 課題
- チャンネル
- カオス
- 特性
- チェック
- 点検
- クランプ
- 明瞭
- class
- クリア
- より明確に
- クローザー
- コード
- コーディング
- コヒーレント
- 協力します
- 共同
- カラー
- comes
- コマーシャル
- コミュニティ
- コンパクト
- 互換性
- 競争力のある
- コンプリート
- 完成
- 複雑な
- 複雑さ
- コンポーネント
- 構図
- 計算的
- 計算
- コンセプト
- 概念の
- 懸念事項
- コンサート
- 結論
- Connections
- 検討
- 検討事項
- 含む
- コンテンツ
- コントラスト
- 貢献
- 従来の
- 収束
- 変換
- 変換
- たたみ込みニューラルネットワーク
- 著作権
- 著作権侵害
- 基本
- 腐敗した
- CPU
- 細工された
- 作ります
- 作成
- 創造
- クリエイティブ
- 創造的に
- 創造性
- クリエイター
- 重大な
- 頂点
- 育てる
- 文化的に
- キュレーション
- 曲線
- カスタム
- サイクル
- ダンス
- データ
- データセット
- 議論
- 深いです
- 定義
- 需要
- 実証
- 深さ
- どん底
- 派生
- 指定された
- 詳細
- 詳細な
- 細部
- 開発者
- デバイス
- 異なる
- 違い
- 異なります
- デジタル
- デジタルアート
- デジタル処理で
- 次元
- 大きさ
- 裁量
- ディスプレイ
- 表示
- 明確な
- 違い
- 異なる
- 多様性
- do
- ありません
- ドア
- ドロー
- 図面
- 間に
- ダイナミック
- 動的に
- ダイナミクス
- e
- 各
- echo
- エコー
- 効果
- 手の込んだ
- ほかに
- 出てくる
- エンコード
- 含む
- 包含する
- エンジニアリング
- 強化された
- 確保
- 確実に
- 確保する
- 全体
- 環境
- 時代
- エポック
- 時代
- エラー
- 本質
- 本質的な
- 設立
- エーテル(ETH)
- 倫理的な
- 倫理
- 評価
- あらゆる
- 進化
- 進化
- 進化
- 進化する
- 検査
- Excel
- 除く
- 既存の
- 詳細
- 広大な
- 期待する
- 探査
- 探る
- 表現
- で
- 広範囲
- 目
- 視線
- フェイシャル
- 忠実な
- false
- おなじみの
- 魅惑的な
- 特徴
- 特色
- 忠実
- フィギュア
- File
- ファイナル
- 仕上げ
- 名
- フォーカス
- フォロー中
- 最前線
- フォワード
- 育てる
- 助長
- フレームワーク
- フレームワーク
- から
- 完全に
- function
- 機能的な
- 基本的な
- さらに
- 融合
- 未来
- 利得
- GAN
- 集まり
- 与えた
- 生成する
- 生成された
- 生成
- 世代
- 生々しい
- 生成的な敵対的ネットワーク
- 生成AI
- 発電機
- 与える
- 目標
- GPU
- 勾配
- 徐々に
- 壮大さ
- 把握
- 大きい
- 画期的な
- ガイド付きの
- ガイドライン
- ガイド
- ハンド
- 利用する
- ハート
- こちら
- 隠す
- ハイライト
- 歴史的
- 開催
- オマージュ
- 名誉
- 認定条件
- しかしながら
- HTTPS
- 人間
- i
- アイデア
- if
- 発火する
- 画像
- 画像
- 想像力
- 命令的
- 実装
- 意義
- import
- 重要
- 改善します
- in
- 含ま
- 包括的
- 包括性
- 組み込む
- 増加した
- インクリメンタル
- 現職
- 影響
- 影響を受け
- 侵害
- 独創性
- 革新します
- 革新的手法
- 入力
- 洞察力
- インテグラル
- 統合
- 整合性
- 知的
- 知的財産
- 関心
- 解釈
- に
- 複雑な
- 紹介する
- 直感
- 関係する
- 問題
- IT
- 繰り返し
- 繰り返し
- ITS
- 旅
- JPG
- 裁判官
- 欠如
- 風景
- 層
- 層
- 学んだ
- 学習
- リーガルポリシー
- 法的枠組み
- 立法
- レンズ
- ある
- 生活
- 光
- ような
- ローディング
- LOOKS
- 損失
- 損失
- 機械
- 機械学習
- 維持する
- 驚異
- 傑作
- 一致
- 材料
- matplotlib
- 意味する
- メカニズム
- メカニズム
- メディア
- 単に
- マージ
- 方法
- 整然とした
- メトリック
- 最小限に抑えます
- 分
- ミラーリング
- ML
- MLアルゴリズム
- モード
- モデル
- モダン
- モジュール
- 他には?
- ずっと
- ミューズ
- しなければなりません
- 名
- 新生
- 自然
- ナビゲート
- 必要
- ニーズ
- ネットワーク
- ネットワーク
- ニューラル
- 神経工学
- ニューラルネットワーク
- ニューラルネットワーク
- 新作
- ノイズ
- 注意
- 小説
- 今
- ニュアンス
- 観察する
- 観測された
- of
- オフ
- 攻撃
- 提供
- 提供すること
- オファー
- 頻繁に
- on
- 継続
- の
- 開きます
- 最適化
- or
- オリジナル
- 独創
- オリジナル
- OS
- その他
- 私たちの
- でる
- 出力
- outputs
- が
- 所有している
- 絵画
- 絵画
- パラメーター
- パラメータ
- 部
- パーティー
- パス
- 過去
- path
- パターン
- パターン
- 知覚
- 完璧な
- 実行する
- 視点
- 画像
- ピース
- ピース
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 肖像画
- 潜在的な
- プラクティス
- 精度
- 予備
- 現在
- プレゼント
- 保存する
- 防ぐ
- 予防
- 原則
- printing
- 優先順位付け
- プロセス
- 処理されました
- 作成
- プロダクト
- プロフィール
- 深遠な
- 進捗
- 進行
- 徐々に
- 有望
- 推進
- プロンプト
- 伝播
- 適切な
- 財産
- 守る
- 保護された
- 来歴
- 提供
- 公表
- 追求
- パイトーチ
- 定量化する
- ランダム
- ランダム
- 範囲
- レート
- 準備
- realm
- 認識する
- 再定義
- リファイン
- 洗練された
- 反射
- 反映
- 政権
- レギュラー
- 関係
- 除去
- レンダリング
- レプリケーション
- 表現
- 表し
- 再現
- 必要とする
- 必要
- 似ている
- 形を変える
- 尊重
- 尊敬する
- 責任
- 責任をもって
- 結果として
- return
- 啓示
- 復活させる
- 革命を起こす
- RGB
- 富裕層
- 権利
- 上昇
- 堅牢な
- 職種
- 同じ
- 保存されました
- 節約
- シーン
- 科学
- スコープ
- スクリプト
- 自己
- 敏感な
- 別
- シーケンス
- 仕える
- セッションに
- 設定
- いくつかの
- Shadow
- シェーピング
- シフト
- シフト
- すべき
- ショーケース
- 展示の
- 示す
- 重要
- から
- ゆっくり
- スニペット
- So
- 洗練された
- 魂
- ソース
- 調達
- スペース
- 緊張
- 特に
- スペクトラム
- 二乗
- 安定した
- ステージ
- スタンド
- 起動
- 統計的
- 着実
- 手順
- 戦略
- 努力
- 構造
- 見事な
- テーマ
- それに続きます
- そのような
- 共生
- 相乗的
- 合成
- 合成
- テーラード
- 取り
- 取得
- ターゲット
- 技術的
- テクニック
- 技術の
- テクノロジー
- テクノロジー
- テンソルフロー
- 遺言
- それ
- 未来
- ソース
- アプリ環境に合わせて
- それら
- そこ。
- ボーマン
- 彼ら
- この
- 繁栄する
- 介して
- 従って
- 〜へ
- 豊富なツール群
- トーチ
- トーチビジョン
- touch
- に向かって
- 追跡
- 伝統的な
- トレーニング
- 訓練された
- トレーニング
- 最適化の適用
- 変換
- 変換
- 変形させる
- 変換
- 変換
- トランスフォーム
- 透明性
- true
- 試します
- わかる
- 理解する
- ユニーク
- まで
- 発表
- 更新
- に
- us
- つかいます
- 中古
- ユーティリティ
- 有効な
- 検証する
- 、
- 鑑賞
- 視点
- ビジョン
- ビジュアル
- 視覚芸術
- 可視化
- 視覚化する
- 視覚的に
- 極めて重要な
- ました
- we
- webp
- この試験は
- 何ですか
- which
- while
- ウィスパー
- 誰
- ワイド
- 広い範囲
- 意志
- ウィンドウを使用して入力ファイルを追加します。
- 以内
- 無し
- 仕事
- 作品
- 世界
- X
- はい
- まだ
- 貴社
- ゼファーネット
- ゼロ