編集者による画像
OpenAI の GPT-3、Google の BERT、Meta の LLaMA などの大規模言語モデル (LLM) は、マーケティング コピーやデータ サイエンスのスクリプトから詩まで、幅広いテキストを生成できる機能により、さまざまな分野に革命をもたらしています。
ChatGPT の直感的なインターフェイスは、今日ではほとんどの人々のデバイスになんとか組み込まれていますが、多様なソフトウェア統合で LLM を使用するための未開発の可能性がまだ広大に残っています。
主な問題?
ほとんどのアプリケーションでは、LLM とのより流動的でネイティブな通信が必要です。
そして、まさにここで LangChain が活躍します。
生成 AI と LLM に興味がある場合、このチュートリアルはあなたに合わせて作成されています。
それでは…始めましょう!
洞窟の中に住んでいて、最近何もニュースを受け取っていない人のために、大規模言語モデル (LLM) について簡単に説明します。
LLM は、人間のようなテキストの理解と生成を模倣するために構築された高度な人工知能システムです。 膨大なデータセットでトレーニングすることにより、これらのモデルは複雑なパターンを識別し、言語の微妙な点を把握し、一貫した出力を生成します。
これらの AI を活用したモデルをどのように操作するか疑問に思われる場合は、主に次の XNUMX つの方法があります。
- 最も一般的で直接的な方法は、モデルと話すかチャットすることです。 これには、プロンプトを作成し、それを AI 搭載モデルに送信し、応答としてテキストベースの出力を取得することが含まれます。
- もう XNUMX つの方法は、テキストを数値配列に変換することです。 このプロセスには、AI のプロンプトを作成し、返される数値配列を受け取ることが含まれます。 一般に「埋め込み」として知られているもの。 最近では、ベクター データベースとセマンティック検索が急増しています。
そして、LangChain が対処しようとしているのは、まさにこれら XNUMX つの主要な問題です。 LLM との対話に関する主な問題に興味がある場合は、この記事を確認してください。 こちら.
LangChain は、LLM を中心に構築されたオープンソース フレームワークです。 これにより、LLM 駆動型アプリケーションのアーキテクチャを合理化するツール、コンポーネント、インターフェイスが豊富に提供されます。
LangChain を使用すると、言語モデルの操作、多様なコンポーネントの相互リンク、API やデータベースなどの資産の組み込みが簡単になります。 この直感的なフレームワークにより、LLM アプリケーションの開発作業が大幅に簡素化されます。
Long Chain の核となるアイデアは、チェーンとも呼ばれるさまざまなコンポーネントまたはモジュールを接続して、より洗練された LLM を活用したソリューションを作成できるということです。
LangChain の優れた機能をいくつか紹介します。
- 対話を標準化するカスタマイズ可能なプロンプト テンプレート。
- 洗練されたユースケースに合わせて調整されたチェーンリンクコンポーネント。
- OpenAI の GPT や HuggingFace Hub の GPT など、主要な言語モデルとのシームレスな統合。
- 特定の問題やタスクを評価するための、組み合わせて使用するアプローチのためのモジュール式コンポーネント。
著者による画像
LangChain は、適応性とモジュール設計に重点を置いていることが特徴です。
LangChain の背後にある主なアイデアは、自然言語処理シーケンスを個々の部分に分割し、開発者が要件に基づいてワークフローをカスタマイズできるようにすることです。
このような多用途性により、LangChain はさまざまな状況や業界で AI ソリューションを構築するための主要な選択肢となります。
その最も重要なコンポーネントのいくつかは次のとおりです…
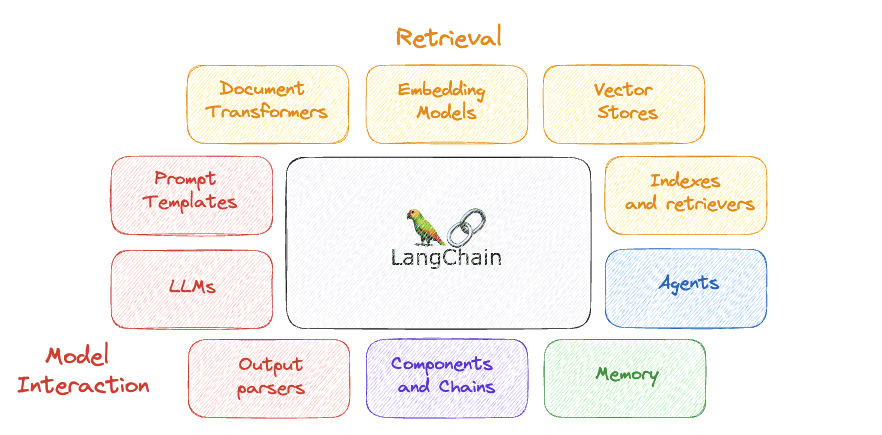
著者による画像
1.LLM
LLM は、人間のようなテキストを理解して生成するために、膨大な量のトレーニング データを活用する基本的なコンポーネントです。 これらは LangChain 内の多くの操作の中核であり、テキスト入力の分析、解釈、応答に必要な言語処理機能を提供します。
使用法: チャットボットを強化し、さまざまなアプリケーション向けに人間のようなテキストを生成し、情報検索を支援し、その他の言語処理を実行します。
2. プロンプトテンプレート
プロンプトは LLM と対話するための基本であり、特定のタスクに取り組む場合、プロンプトの構造は類似する傾向があります。 プロンプト テンプレートは、チェーン全体で使用できる事前設定されたプロンプトであり、特定の値を追加することで「プロンプト」を標準化できます。 これにより、LLM の適応性とカスタマイズ性が強化されます。
使用法: LLM と対話するプロセスの標準化。
3. 出力パーサー
出力パーサーは、チェーンの前のステージから生の出力を取得し、それを構造化フォーマットに変換するコンポーネントです。 この構造化データは、後続の段階でより効果的に使用したり、エンド ユーザーへの応答として配信したりできます。
使用法: たとえば、チャットボットでは、出力パーサーが言語モデルから生のテキスト応答を取得し、重要な情報を抽出して、構造化された応答にフォーマットします。
4. コンポーネントとチェーン
LangChain では、各コンポーネントは言語処理シーケンスの特定のタスクを担当するモジュールとして機能します。 これらのコンポーネントを接続して形成することができます。 チェーン カスタマイズされたワークフロー向け。
使用法: 特定のチャットボットでセンチメント検出および応答ジェネレーター チェーンを生成します。
5。 メモリ
LangChain のメモリとは、ワークフロー内の情報の保存および取得メカニズムを提供するコンポーネントを指します。 このコンポーネントにより、LLM との対話中に他のコンポーネントがアクセスして操作できるデータの一時的または永続的なストレージが可能になります。
使用法: これは、コンテキストを認識した応答を提供するために会話履歴をチャットボットに保存するなど、処理のさまざまな段階にわたってデータを保持する必要があるシナリオで役立ちます。
6. エージェント
エージェントは、処理するデータに基づいてアクションを実行できる自律的なコンポーネントです。 他のコンポーネント、外部システム、またはユーザーと対話して、LangChain ワークフロー内の特定のタスクを実行できます。
使用法: たとえば、エージェントはユーザーとの対話を処理し、受信リクエストを処理し、チェーンを通るデータ フローを調整して適切な応答を生成します。
7. インデックスとレトリバー
インデックスとレトリバーは、データを効率的に管理し、アクセスする上で重要な役割を果たします。 インデックスは、モデルのトレーニング データからの情報とメタデータを保持するデータ構造です。 一方、レトリーバーは、これらのインデックスと対話して、指定された基準に基づいて関連するデータをフェッチし、関連するコンテキストを提供することでモデルがより適切に応答できるようにするメカニズムです。
使用法: これらは、大規模なデータセットから関連するデータやドキュメントを迅速に取得するのに役立ちます。これは、情報検索や質問応答などのタスクに不可欠です。
8. ドキュメントトランスフォーマー
LangChain のドキュメント トランスフォーマーは、ドキュメントをさらなる分析や処理に適した方法で処理および変換するように設計された特殊なコンポーネントです。 これらの変換には、テキストの正規化、特徴抽出、テキストの別の形式への変換などのタスクが含まれる場合があります。
使用法: 機械学習モデルによる分析や効率的な検索のためのインデックス作成など、後続の処理段階のためにテキスト データを準備します。
9. モデルの埋め込み
これらは、テキスト データを高次元空間の数値ベクトルに変換するために使用されます。 これらのモデルは、単語とフレーズの間の意味的な関係をキャプチャし、機械可読な表現を可能にします。 これらは、LangChain エコシステム内のさまざまな下流の自然言語処理 (NLP) タスクの基盤を形成します。
使用法: テキストの数値表現を提供することで、意味検索、類似性の比較、その他の機械学習タスクを容易にします。
10. ベクターストア
埋め込みを介して情報を保存および検索することに特化したデータベース システムの種類。基本的にはテキストのようなデータの数値表現を分析します。 VectorStore は、これらの埋め込みのストレージ機能として機能します。
使用法: 意味的な類似性に基づいた効率的な検索が可能になります。
PIPを使用してインストールする
まず最初に、環境に LangChain がインストールされていることを確認する必要があります。
pip install langchain
環境設定
LangChain を利用するということは、通常、さまざまなモデル プロバイダー、データ ストア、API などのコンポーネントと統合することを意味します。 そして、すでにご存知のとおり、他の統合と同様に、関連する正しい API キーを提供することが LangChain の運用にとって重要です。
OpenAI API を使用したいと想像してください。 これは XNUMX つの方法で簡単に実現できます。
- キーを環境変数として設定する
OPENAI_API_KEY="..."
or
import os
os.environ['OPENAI_API_KEY'] = “...”
環境変数を設定しないことを選択した場合は、OpenAI LLM クラスを開始するときに、openai_api_key 名前付きパラメーターを通じてキーを直接提供するオプションがあります。
- 該当するクラスにキーを直接設定します。
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")LLM 間の切り替えが簡単になります
LangChain は、OpenAI や Hugging Face などのさまざまな言語モデル プロバイダーと対話できる LLM クラスを提供します。
LLM の最も基本的で実装が簡単な機能はテキストの生成だけであるため、LLM を使い始めるのは非常に簡単です。
ただし、まったく同じプロンプトを異なる LLM に同時に要求することは、それほど簡単ではありません。
ここでLangChainが活躍します…
LLM の最も簡単な機能に戻ると、文字列プロンプトを取得し、指定した LLM の出力を返すアプリケーションを LangChain で簡単に構築できます。
著者によるコード
同じプロンプトを使用するだけで、数行のコード内で XNUMX つの異なるモデルの応答を取得できます。
著者によるコード
印象的ですね…そうですよね?
プロンプト テンプレートを使用してプロンプトに構造を与える
言語モデル (LLM) に関する一般的な問題は、複雑なアプリケーションをエスカレーションできないことです。 LangChain は、プロンプト作成プロセスを合理化するソリューションを提供することでこの問題に対処します。プロンプト作成プロセスは、AI のペルソナの概要を説明し、事実の正確性を確保する必要があるため、単にタスクを定義するよりも複雑なことがよくあります。 この重要な部分には、定型文の繰り返しが含まれます。 LangChain は、新しいプロンプトにボイラープレート テキストを自動的に含めるプロンプト テンプレートを提供することでこの問題を軽減します。これにより、プロンプトの作成が簡素化され、さまざまなタスク間での一貫性が確保されます。
著者によるコード
出力パーサーを使用して構造化された応答を取得する
チャットベースの対話では、モデルの出力は単なるテキストです。 ただし、ソフトウェア アプリケーション内では、さらなるプログラミング操作が可能になるため、構造化された出力を持つことが望ましいです。 たとえば、データセットを生成する場合、CSV や JSON などの特定の形式で応答を受信することが望まれます。 AI から一貫性のある適切な形式の応答を引き出すようにプロンプトを作成できると仮定すると、この出力を管理するツールが必要になります。 LangChain は、構造化された出力を効果的に処理および利用するための出力パーサー ツールを提供することで、この要件に応えます。
著者によるコード
私のコード全体をチェックしてください GitHubの.
少し前まで、ChatGPT の高度な機能に私たちは畏敬の念を抱きました。 しかし、技術環境は常に変化しており、今では LangChain のようなツールがすぐに使えるようになり、パーソナル コンピューターからわずか数時間で優れたプロトタイプを作成できるようになりました。
無料で利用できる Python プラットフォームである LangChain は、ユーザーが LLM (言語モデル モデル) に基づいたアプリケーションを開発する手段を提供します。 このプラットフォームは、さまざまな基本モデルへの柔軟なインターフェイスを提供し、プロンプト処理を合理化し、プロンプト テンプレート、追加の LLM、外部情報、エージェントを介したその他のリソースなどの要素のネクサスとして機能します (現在のドキュメントの時点)。
チャットボット、デジタル アシスタント、言語翻訳ツール、感情分析ユーティリティを想像してみてください。 これらすべての LLM 対応アプリケーションは、LangChain によって実現されます。 開発者はこのプラットフォームを利用して、個別の要件に対応するカスタム調整された言語モデル ソリューションを作成します。
自然言語処理の視野が広がり、その採用が深まるにつれて、その応用範囲は無限であるように見えます。
ジョセップ・フェレール バルセロナ出身の分析エンジニアです。 彼は物理工学を卒業し、現在は人間の移動に適用されるデータ サイエンス分野で働いています。 彼は、データ サイエンスとテクノロジーに焦点を当てた非常勤のコンテンツ クリエイターです。 あなたは彼に連絡することができます LinkedIn, Twitter or M.
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/how-to-make-large-language-models-play-nice-with-your-software-using-langchain?utm_source=rss&utm_medium=rss&utm_campaign=how-to-make-large-language-models-play-nice-with-your-software-using-langchain
- :持っている
- :は
- :not
- :どこ
- $UP
- 7
- a
- 能力
- アクセス
- アクセス
- こちらからお申し込みください。
- 精度
- 越えて
- 演技
- 行動
- 使徒行伝
- 追加
- 住所
- アドレス
- アドレッシング
- 養子縁組
- 高度な
- エージェント
- エージェント
- 前
- AI
- AI電源
- すべて
- 許す
- 許可
- ことができます
- 既に
- また
- 間で
- 金額
- an
- 分析
- 分析論
- 分析します
- 分析する
- 固着
- および
- どれか
- API
- API
- 申し込み
- アプリケーション開発
- 適用された
- アプローチ
- 適切な
- 建築
- です
- 周りに
- 配列
- アーセナル
- 記事
- 人工の
- 人工知能
- AS
- 質問
- 評価する
- 資産
- アシスタント
- At
- 自律的
- 利用できます
- WE敬の念
- バック
- バルセロナ
- ベース
- 基本
- BE
- になる
- になる
- き
- 背後に
- より良いです
- の間に
- 無限の
- 破壊
- 簡潔に
- もたらす
- ビルド
- 建物
- 内蔵
- by
- 缶
- 機能
- できる
- キャプチャー
- 場合
- 例
- ケータリング
- 洞窟
- チェーン
- チェーン
- チャットボット
- チャットボット
- AI言語モデルを活用してコードのデバッグからデータの異常検出まで、
- チャット
- チェック
- 選択
- 選択する
- class
- コード
- コヒーレント
- 来ます
- コマンドと
- 一般に
- コミュニケーション
- 比較
- 複雑な
- コンポーネント
- コンポーネント
- コンピューター
- お問合せ
- 交流
- 整合性のある
- 接触
- コンテンツ
- コンテキスト
- 会話
- 変換
- 変換
- 変換
- 調整する
- 基本
- 正しい
- クラフト
- 細工された
- 作ります
- 作成
- 創造
- クリエイター
- 基準
- 重大な
- 電流プローブ
- 現在
- カスタム化
- カスタマイズ
- カスタマイズ
- データ
- データサイエンス
- データセット
- データベース
- データベースを追加しました
- 深くなる
- 定義
- 配信
- 提供します
- 設計
- 指定された
- 設計
- 希望
- 検出
- 開発する
- 開発者
- 開発
- Devices
- 異なります
- デジタル
- 直接
- 直接に
- 識別する
- 明確な
- 優れました
- 異なる
- do
- ドキュメント
- ドキュメント
- ドキュメント
- ダウン
- 間に
- 各
- 最も簡単
- 簡単に
- 簡単に
- エコシステム
- 効果的に
- 効率的な
- 効率良く
- 要素は
- 埋め込み
- 有効にする
- end
- 魅力的
- エンジニア
- エンジニアリング
- 強化
- 巨大な
- 確保する
- 環境
- エスカレート
- 本質的な
- 本質的に
- 確立する
- エーテル(ETH)
- 刻々と変化する
- 例
- 拡大する
- 経験豊かな
- 説明する
- 外部
- エキス
- 抽出
- 顔
- 施設
- 事実上
- 特徴
- 特徴
- 少数の
- フィールド
- 指先
- 名
- フレキシブル
- フロー
- 流体
- フォーカス
- 焦点を当て
- フォーム
- 形式でアーカイブしたプロジェクトを保存します.
- Foundation
- 基礎
- フレームワーク
- 自由に
- から
- 機能性
- 基本的な
- さらに
- 生成する
- 生成
- 世代
- 生々しい
- 生成AI
- ジェネレータ
- 取得する
- 受け
- Go
- Googleの
- 把握
- ハンド
- ハンドル
- ハンドリング
- 持ってる
- 持って
- he
- 彼に
- history
- 開催
- 地平線
- HOURS
- 認定条件
- How To
- HTTPS
- ハブ
- 抱き合う顔
- 人間
- 私は
- アイデア
- if
- import
- 重要
- in
- できないこと
- include
- 含めて
- 入ってくる
- 組み込む
- インデックス
- 個人
- 産業
- 情報
- 開始する
- install
- インストルメンタル
- 統合
- 統合
- 統合
- インテリジェンス
- 対話
- 相互作用
- 相互作用
- 相互作用
- 興味がある
- インタフェース
- インターフェース
- インターリンク
- に
- 複雑な
- 直観的な
- 関与
- 問題
- IT
- ITS
- 旅
- JSON
- ただ
- KDナゲット
- キー
- キー
- キック
- 知っている
- 既知の
- 風景
- 言語
- 大
- 主要な
- 学習
- 左
- 活用します
- 生活
- ような
- ライン
- LINK
- 生活
- ラマ
- 長い
- 機械
- 機械学習
- メイン
- make
- 作る
- 管理します
- マネージド
- 管理する
- 操作
- 多くの
- マーケティング
- 五月..
- 手段
- メカニズム
- メカニズム
- 単に
- 方法
- かもしれない
- モビリティ
- モデル
- モジュラー
- モジュール
- モジュール
- 他には?
- 最も
- my
- 名前付き
- ネイティブ
- ナチュラル
- 自然言語
- 自然言語処理
- 必要
- 必要
- ニーズ
- 新作
- ニュース
- ネクサス
- nice
- NLP
- 今
- of
- 提供すること
- 頻繁に
- on
- かつて
- オープンソース
- OpenAI
- 操作
- 業務執行統括
- オプション
- or
- OS
- その他
- 私たちの
- 概説する
- 出力
- outputs
- 傑出した
- パラメーター
- 部
- 特定の
- 部品
- パターン
- のワークプ
- 実行する
- 実行
- 個人的な
- パソコン
- フレーズ
- 物理学
- ピース
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- プレイ
- 詩
- ポジション
- 潜在的な
- 正確に
- 好ましいです
- 素数
- 問題
- 問題
- プロセス
- 処理
- 作り出す
- プログラミング
- プロンプト
- プロトタイプ
- 提供します
- プロバイダ
- は、大阪で
- 提供
- Python
- 質問
- すぐに
- 非常に
- Raw
- realm
- 受け入れ
- 最近
- 指し
- の関係
- 関連した
- 反復的な
- 返信
- 表現
- リクエスト
- 必要とする
- 要件
- 要件
- 必要
- リソース
- 反応します
- 応答
- 回答
- 責任
- 保持された
- return
- 収益
- 革命
- 右
- 職種
- s
- 同じ
- シナリオ
- 科学
- 科学技術
- スクリプト
- を検索
- 検索
- セクター
- と思われる
- 送信
- 感情
- シーケンス
- 仕える
- セッションに
- セット
- 設定
- 重要
- 同様の
- 簡素化する
- 単純化
- 単に
- 状況
- So
- ソフトウェア
- 溶液
- ソリューション
- 一部
- 洗練された
- スペース
- 専門の
- 専門にする
- 特定の
- 指定の
- ステージ
- ステージ
- 標準化
- 開始
- まだ
- ストレージ利用料
- 店舗
- 店舗
- 流線
- 合理化
- 文字列
- 構造
- 構造化された
- 構造
- それに続きます
- 実質上
- そのような
- 適当
- 補給
- 確か
- 発生します
- システム
- テーブル
- テーラード
- 取る
- 取得
- 会話
- 仕事
- タスク
- 技術の
- テクノロジー
- テンプレート
- 一時的
- 傾向がある
- 클라우드 기반 AI/ML및 고성능 컴퓨팅을 통한 디지털 트윈의 기초 – Edward Hsu, Rescale CPO 많은 엔지니어링 중심 기업에게 클라우드는 R&D디지털 전환의 첫 단계일 뿐입니다. 클라우드 자원을 활용해 엔지니어링 팀의 제약을 해결하는 단계를 넘어, 시뮬레이션 운영을 통합하고 최적화하며, 궁극적으로는 모델 기반의 협업과 의사 결정을 지원하여 신제품을 결정할 때 데이터 기반 엔지니어링을 적용하고자 합니다. Rescale은 이러한 혁신을 돕기 위해 컴퓨팅 추천 엔진, 통합 데이터 패브릭, 메타데이터 관리 등을 개발하고 있습니다. 이번 자리를 빌려 비즈니스 경쟁력 제고를 위한 디지털 트윈 및 디지털 스레드 전략 개발 방법에 대한 인사이트를 나누고자 합니다.
- テキスト
- より
- それ
- アプリ環境に合わせて
- それら
- その後
- そこ。
- ボーマン
- 彼ら
- もの
- この
- それらの
- しかし?
- 介して
- 従って
- 〜へ
- 今日
- 一緒に
- 豊富なツール群
- トレーニング
- 最適化の適用
- 変換
- トランスフォーマー
- インタビュー
- チュートリアル
- 2
- 一般的に
- わかる
- 理解する
- 未開発
- us
- 使用可能な
- つかいます
- 中古
- ユーザー
- users
- 公益事業
- 活用する
- 価値観
- 変数
- 多様
- さまざまな
- 広大な
- 汎用性
- 非常に
- 、
- 欲しいです
- 仕方..
- 方法
- we
- この試験は
- 何ですか
- いつ
- which
- 全体
- ワイド
- 以内
- 不思議
- 言葉
- ワークフロー
- ワークフロー
- ワーキング
- まだ
- 貴社
- あなたの
- ゼファーネット