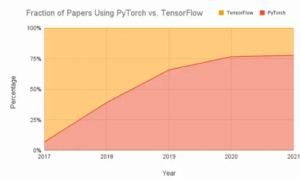
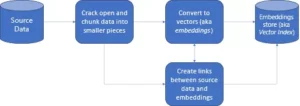
概要
急速に進化する生成 AI の状況において、ベクトル データベースの極めて重要な役割がますます明らかになってきています。この記事では、ベクトル データベースと生成 AI ソリューションの間の動的な相乗効果について詳しく説明し、これらの技術的基盤が人工知能の創造性の未来をどのように形作っているのかを探ります。この強力な提携の複雑さを乗り越える旅に参加し、ベクトル データベースが革新的な AI ソリューションの最前線にもたらす変革的な影響についての洞察を解き明かしましょう。
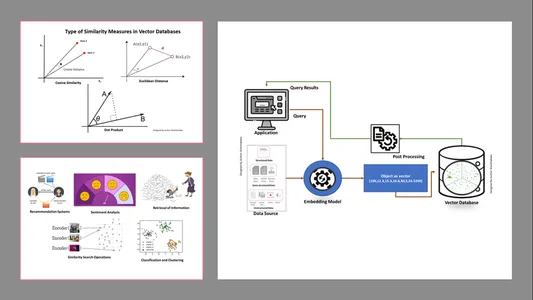
学習目標
この記事は、以下の Vector データベースの側面を理解するのに役立ちます。
- ベクター データベースとその主要コンポーネントの重要性
- Vectorデータベースと従来のデータベースの比較の詳細な研究
- アプリケーションの観点からのベクトル埋め込みの探索
- Pincone を使用したベクトル データベースの構築
- langchain LLM モデルを使用した松ぼっくりベクトル データベースの実装
この記事は、の一部として公開されました データサイエンスブログ。
目次
ベクターデータベースとは何ですか?
ベクトル データベースは、空間に保存されるデータ収集の形式です。それでも、ここでは、データベースに保存された形式により、オープン AI モデルが入力を記憶しやすくなり、オープン AI アプリケーションがさまざまなユースケースでコグニティブ検索、レコメンデーション、およびテキスト生成を使用できるようになるため、数学的表現で保存されています。デジタル変革された業界。データの保存と取得は、「ベクター エンベディング」または「エンベディング」と呼ばれます。さらに、これは数値配列形式で表現されます。大規模なインデックス機能を備えた AI パースペクティブに使用される従来のデータベースよりも検索がはるかに簡単です。
ベクトルデータベースの特徴
- これらのベクトル埋め込みの力を利用して、大規模なデータセット全体のインデックス作成と検索を実現します。
- あらゆるデータ形式 (画像、テキスト、データ) で圧縮可能。
- 埋め込み技術と高度にインデックス化された機能を適応させるため、特定の問題に対するデータと入力を管理するための完全なソリューションを提供できます。
- ベクトル データベースは、数百の次元を含む高次元ベクトルを通じてデータを編成します。非常に迅速に設定できます。
- 各次元は、それが表すデータ オブジェクトの特定の機能またはプロパティに対応します。
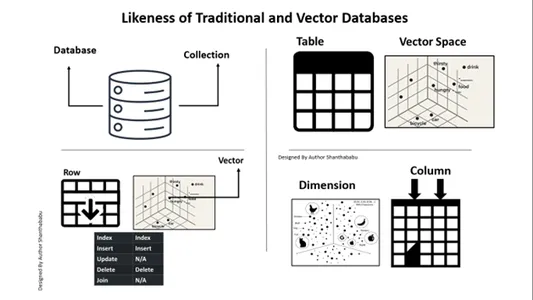
従来型 vs.ベクターデータベース
- この図は、従来のベクトル データベースの高レベルのワークフローを示しています。
- データベースの正式なやり取りは次のように行われます。 SQL ステートメントとデータは行ベースおよび表形式で保存されます。
- Vector データベースでは、インタラクションはプレーン テキスト (英語など) と数学的表現で保存されたデータを通じて行われます。
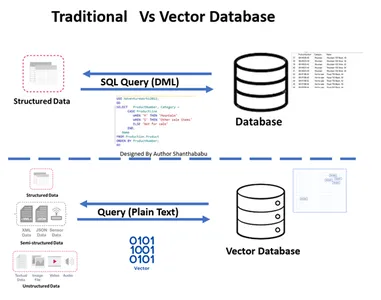
従来のデータベースとベクター データベースの類似性
Vector データベースが従来のデータベースとどのように異なるかを考慮する必要があります。ここでこれについて議論しましょう。簡単に挙げられる違いは、従来のデータベースとの違いです。データは正確にそのまま保存されます。ビジネス ロジックを追加してデータを調整し、ビジネス要件や需要に基づいてデータを結合または分割することもできます。ただし、ベクトル データベースには大規模な変換が行われ、データは複雑なベクトル表現になります。
これは、視点を理解し、明確にするためのマップです。 リレーショナルデータベース ベクトルデータベースに対して。下の図は、従来のデータベースを使用したベクトル データベースを理解するために一目瞭然です。つまり、Update ステートメントではなく、ベクター データベースへの挿入と削除を実行できます。
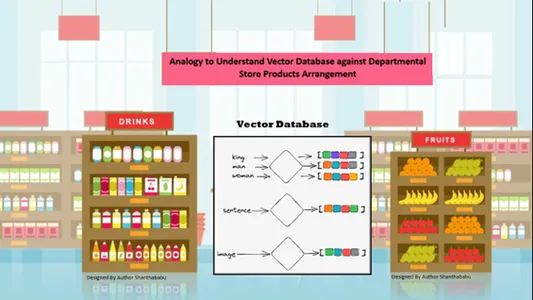
ベクトル データベースを理解するための簡単な例え話
データは、保存された情報の内容の類似性によって空間的に自動的に配置されます。そこで、ベクトル データベースに例えてデパートを考えてみましょう。すべての製品は、性質、目的、製造、用途、数量ベースに基づいて棚に配置されます。同様の動作で、データは次のようになります。
データの保存またはアクセス中にジャンルが明確に定義されていない場合でも、同様の並べ替えによってベクター データベース内で自動的に配置されます。
ベクトル データベースでは、特定の類似点について優れた粒度と次元が可能になるため、顧客は希望の製品、メーカー、数量を検索し、その商品をカートに入れておくことができます。ベクター データベースは、すべてのデータを完璧なストレージ構造に保存します。ここでは、機械学習および AI エンジニアが、保存されているコンテンツに手動でラベルを付けたりタグ付けしたりする必要がありません。
ベクトル データベースの背後にある基本的な理論
- ベクトル埋め込みとその範囲
- インデックス作成の要件
- セマンティック検索と類似性検索について
ベクトル埋め込みとその範囲
ベクトル埋め込みは、数値によるベクトル表現です。圧縮形式では、エンベディングは元のデータの固有のプロパティと関連性をキャプチャし、人工知能と機械学習のユースケースでの定番となっています。元のデータに関する関連情報を低次元空間にエンコードするように埋め込みを設計すると、高い検索速度、計算効率、効率的なストレージが保証されます。
より同一構造の方法でデータの本質を捉えることは、「埋め込みモデル」を形成するベクトル埋め込みのプロセスです。最終的に、これらのモデルはすべてのデータ オブジェクトを考慮し、データ ソース内の意味のあるパターンと関係を抽出し、それらをベクトル埋め込みに変換します。 。その後、アルゴリズムはこれらのベクトル埋め込みを利用してさまざまなタスクを実行します。高度に開発された多数の埋め込みモデルは、オンラインで無料または従量課金制で利用でき、ベクトル埋め込みの実現を容易にします。
アプリケーションの観点から見たベクトル埋め込みの範囲
これらの埋め込みはコンパクトで、複雑な情報を含み、ベクトル データベースに保存されているデータ間の関係を継承し、理解と意思決定を促進する効率的なデータ処理分析を可能にし、あらゆる組織全体でさまざまな革新的なデータ製品を動的に構築します。
ベクトル埋め込み技術は、読み取り可能なデータと複雑なアルゴリズムの間のギャップを結び付けるために不可欠です。データ型が数値ベクトルであるため、利用可能なオープン AI モデルとともに、多種多様な生成 AI アプリケーションの可能性を解き放つことができました。
ベクトル埋め込みを使用した複数のジョブ
このベクトル埋め込みは、複数のジョブを実行するのに役立ちます。
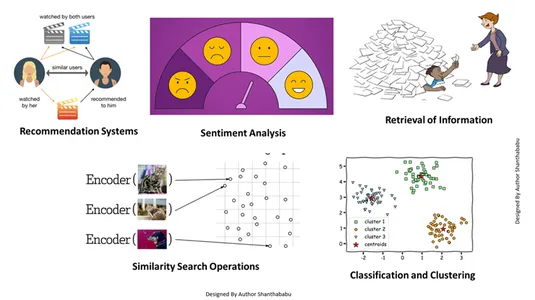
- 情報の取得: これらの強力な技術の助けを借りて、保存されたファイル、ドキュメント、またはメディアからのユーザーのクエリに基づいて応答を見つけるのに役立つ影響力のある検索エンジンを構築できます。
- 類似性検索操作: これはよく整理され、索引付けされています。これは、ベクトル データ内の異なる出現間の類似性を見つけるのに役立ちます。
- 分類とクラスタリング: これらの埋め込み手法を使用すると、これらのモデルを実行して、関連する機械学習アルゴリズムをトレーニングし、それらをグループ化して分類できます。
- レコメンデーションシステム: 埋め込み技術が適切に体系化されているため、履歴データに基づいて製品、メディア、記事を正確に関連付けたレコメンデーション システムが実現されます。
- 感情分析: この埋め込みモデルは、センチメント ソリューションを分類して導き出すのに役立ちます。
インデックス作成の要件
ご存知のとおり、インデックスはベクトル データベースと同様、従来のデータベースのテーブルからのデータの検索を改善し、インデックス機能を提供します。
ベクトル データベースは、ベクトル埋め込みを直接表現する「フラット インデックス」を提供します。検索機能は包括的であり、事前トレーニングされたクラスターは使用されません。クエリ ベクトルは各単一ベクトル埋め込みに対して実行され、K 個の距離が各ペアに対して計算されます。
- このインデックスは簡単であるため、新しいインデックスを作成するために必要な計算は最小限で済みます。
- 実際、フラット インデックスはクエリを効率的に処理でき、取得時間を短縮できます。
セマンティック検索と類似性検索について
ベクトル データベースでは、意味検索と類似性検索という 2 つの異なる検索を実行します。
- セマンティック検索: 情報を検索する際、キーワードで検索するのではなく、有意義な会話方法論に基づいて情報を見つけることができます。迅速なエンジニアリングは、入力をシステムに渡す際に重要な役割を果たします。この検索により、間違いなく、革新的なアプリケーション、SEO、テキスト生成、および要約に提供できる高品質の検索と結果が可能になります。
- 類似性検索: データ分析では常に、類似性検索により、構造化されていない、より適切なデータセットが可能になります。ベクトル データベースに関しては、2 つのベクトル (表、テキスト、文書、画像、単語、音声ファイル) の近さと、それらが互いにどのように似ているかを確認する必要があります。理解の過程で、ベクトル間の類似性が、特定のデータセット内のデータ オブジェクト間の類似性として明らかになります。この演習は、相互作用を理解し、パターンを特定し、洞察を抽出し、アプリケーションの観点から意思決定を行うのに役立ちます。セマンティック検索と類似性検索は、業界の利益をもたらす以下のアプリケーションを構築するのに役立ちます。
- 情報検索: Open AI と Vector Database を使用して、ビジネス ユーザーまたはエンド ユーザーのクエリとベクター DB 内のインデックス付きドキュメントを使用して情報を検索するための検索エンジンを構築します。
- 分類とクラスタリング:同様のデータ ポイントまたはオブジェクトのグループを分類またはクラスタリングするには、共通の特性に基づいてそれらを複数のカテゴリに割り当てる必要があります。
- 異常検出: データ点の類似性を測定し、異常を発見することで、通常のパターンから異常を発見します。
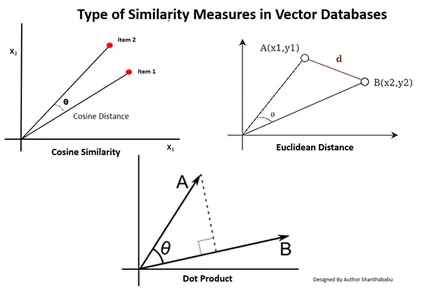
ベクトル データベースにおける類似性測定の種類
測定方法はデータの性質とアプリケーション固有によって異なります。一般に、機械学習との類似性と親近感を測定するには 3 つの方法が使用されます。
ユークリッド距離
簡単に言えば、2 つのベクトル間の距離は、st を測定する 2 つのベクトル点間の直線距離です。
内積
これは、2 つのベクトル間の位置関係を理解するのに役立ち、それらが同じ方向を向いているか、反対方向を向いているか、または互いに直交しているかを示します。
コサイン類似性
図に示すように、2 つのベクトル間の角度を使用して、2 つのベクトルの類似性を評価します。この場合、ベクトルの値と大きさは重要ではなく、結果には影響しません。計算では角度のみが考慮されます。
従来のデータベース 正確に一致する SQL ステートメントを検索し、表形式でデータを取得します。同時に、プロンプトエンジニアリング技術を使用して、平易な英語の入力クエリに最も類似したベクトルを検索するベクトルデータベースを扱います。データベースは、近似最近傍 (ANN) 検索アルゴリズムを使用して、類似したデータを検索します。高いパフォーマンス、精度、応答時間で、常に適度に正確な結果を提供します。
動作メカニズム
- ベクトル データベースは、まずデータを埋め込みベクトルに変換し、それをベクトル データベースに保存し、検索を高速化するためのインデックスを作成します。
- アプリケーションからのクエリは、埋め込みベクトルと対話し、インデックスを使用してベクトル データベース内の最近傍データまたは同様のデータを検索し、アプリケーションに渡された結果を取得します。
- ビジネス要件に基づいて、取得されたデータは微調整され、フォーマットされて、エンド ユーザー側またはクエリまたはアクションのフィードに表示されます。
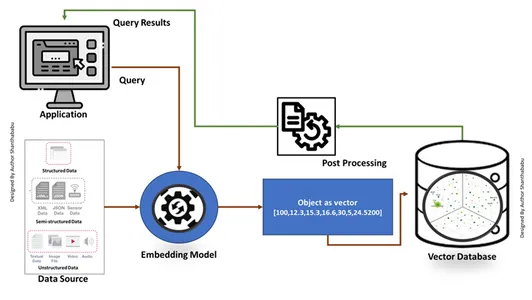
ベクターデータベースの作成
松ぼっくりとつながりましょう。
Google、GitHub、または Microsoft ID を使用して Pinecone に接続できます。
用途に合わせて新しいユーザー ログインを作成します。
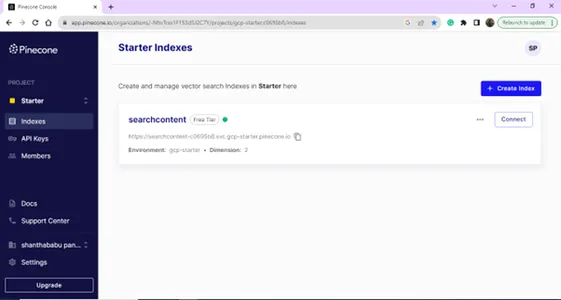
ログインに成功すると、[インデックス] ページが表示されます。 Vector Database の目的でインデックスを作成できます。 「インデックスの作成」ボタンをクリックします。
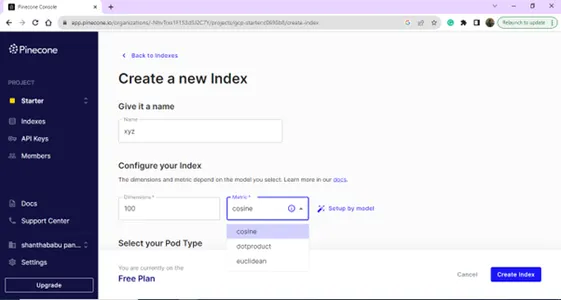
名前とディメンションを指定して、新しいインデックスを作成します。
インデックス一覧ページ、
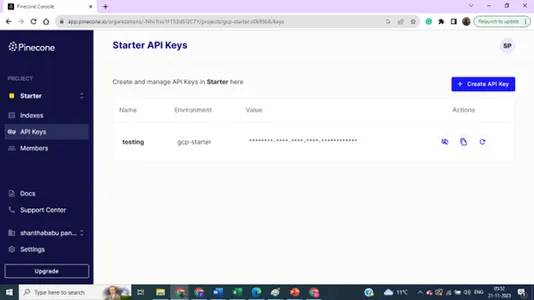
インデックスの詳細 – 名前、地域、環境 – モデル構築コードからベクトル データベースに接続するには、これらすべての詳細が必要です。
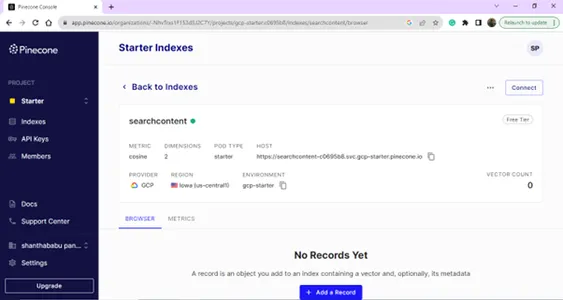
プロジェクト設定の詳細、
プロジェクトの目的に応じて、複数のインデックスとキーの設定をアップグレードできます。
これまで、Pinecone でのベクター データベースのインデックスと設定の作成について説明してきました。
Python を使用したベクトル データベースの実装
では、コーディングをしてみましょう。
ライブラリのインポート
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAIOpenAIおよびVectorデータベースのAPIキーの提供
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxx"
PINECONE_API_KEY = os.environ.get('PINECONE_API_KEY', 'xxxxxxxxxxxxxxxxxxxxxxx')
PINECONE_API_ENV = os.environ.get('PINECONE_API_ENV', 'gcp-starter')
api_keys="xxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(OpenAI=api_keys, temperature=0.1)LLM の開始
llm=OpenAI(openai_api_key=os.environ["OPENAI_API_KEY"],temperature=0.6)松ぼっくりの開始
import pinecone
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
index_name = "demoindex" ベクトル データベースを構築するための .csv ファイルの読み込み
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/content/drive/My Drive/Colab_Notebooks/cereal.csv"
,source_column="name")
data = loader.load()テキストをチャンクに分割する
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=20)
text_chunks = text_splitter.split_documents(data)text_chunk 内のテキストの検索
text_chunks出力
[Document(page_content='name: 100% Brannmfr: Nntype: Cnカロリー: 70nたんぱく質: 4nfat: 1nsodium: 130nfiber: 10ncarbo: 5nsgars: 6npotass: 280nvitamins: 25nshelf: 3nweight: 1ncups: 0.33nrated: 68.402973n推奨事項: 子供向け、メタデータ={ 'source': '100% ブラン', 'row': 0}), , …..
建物の埋め込み
embeddings = OpenAIEmbeddings()「data」からベクターデータベースの松ぼっくりインスタンスを作成する
vectordb = Pinecone.from_documents(text_chunks,embeddings,index_name="demoindex")ベクトル データベースにクエリを実行するためのレトリーバーを作成します。
retriever = vectordb.as_retriever(score_threshold = 0.7)ベクトルデータベースからデータを取得する
rdocs = retriever.get_relevant_documents("Cocoa Puffs")
rdocsプロンプトを使用してデータを取得する
from langchain.prompts import PromptTemplate
prompt_template = """Given the following context and a question,
generate an answer based on this context only.
,Please state "I don't know." Don't try to make up an answer.
CONTEXT: {context}
QUESTION: {question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
input_key="query",
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs)
データをクエリしてみましょう。
chain('Can you please provide cereal recommendation for Kids?')クエリからの出力
{'query': 'Can you please provide cereal recommendation for Kids?',
'result': [Document(page_content='name: Crispixnmfr: Kntype: Cncalories: 110nprotein: 2nfat: 0nsodium: 220nfiber: 1ncarbo: 21nsugars: 3npotass: 30nvitamins: 25nshelf: 3nweight: 1ncups: 1nrating: 46.895644nrecommendation: Kids', metadata={'row': 21.0, 'source': '/content/drive/My Drive/Colab_Notebooks/cereal.csv'}), ..]まとめ
ベクター データベースの仕組み、そのコンポーネント、アーキテクチャ、Generative AI ソリューションにおけるベクター データベースの特性についてご理解いただければ幸いです。ベクトル データベースが従来のデータベースとどのように異なるのか、また従来のデータベース要素との比較を理解します。実際、この類似性は、ベクトル データベースをより深く理解するのに役立ちます。松ぼっくりベクトル データベースとインデックス作成の手順は、ベクトル データベースを作成し、次のコード実装のキーを提供するのに役立ちます。
主要な取り組み
- 構造化データ、非構造化データ、および半構造化データを圧縮可能。
- 埋め込み技術と高度にインデックス化された機能を適応させます。
- インタラクションは、プロンプト (英語など) を使用したプレーン テキストで行われます。そしてデータは数学的表現で保存されます。
- ベクトル データベースの類似度は、ユークリッド距離、コサイン類似度、ドット積によって調整されます。
よくある質問
A. ベクトル データベースは、データのコレクションを空間に保存します。データを数学的表現で保持します。データベースに保存された形式により、オープン AI モデルが以前の入力を記憶しやすくなり、オープン AI アプリケーションがデジタル変革産業のさまざまなユースケースに対してコグニティブ検索、レコメンデーション、正確なテキスト生成を使用できるようになるためです。
A. いくつかの特徴は次のとおりです。 1. これらのベクトル埋め込みの力を活用し、大規模なデータセット全体のインデックス作成と検索を実現します。 2. 構造化データ、非構造化データ、および半構造化データを圧縮可能。 3. ベクトル データベースは、数百次元を含む高次元ベクトルを通じてデータを編成します。
A. データベース ==> コレクション
表==> ベクトル空間
行==>セクター
列==>寸法
従来のデータベースと同様に、Vector データベースでも挿入と削除が可能です。
更新と参加は範囲外です。
– 大量のデータ収集のための情報の迅速な取得。
– 巨大なサイズのドキュメントからの意味検索および類似性検索操作。
– 分類およびクラスタリング アプリケーション。
– レコメンデーションおよびセンチメント分析システム。
A5: 類似性を測定する方法は以下の XNUMX つです。
– ユークリッド距離
– コサイン類似度
– ドット積
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/12/vector-databases-in-generative-ai-solutions/
- :持っている
- :は
- :not
- $UP
- 1
- 10
- 12
- 13
- 46
- 7
- 8
- 9
- a
- できる
- 私たちについて
- アクセス
- 精度
- 正確な
- 正確にデジタル化
- 越えて
- 適応する
- 加えます
- 影響を及ぼす
- AI
- AIモデル
- アルゴリズム
- アルゴリズム
- アラインメント
- すべて
- アライアンス
- 許す
- ことができます
- 沿って
- 常に
- 間で
- an
- 分析
- 分析論
- 分析Vidhya
- および
- 回答
- どれか
- API
- 見かけ上
- 申し込み
- 特定用途向け
- 近似
- 建築
- です
- 整えられた
- 配列
- 記事
- 物品
- 人工の
- 人工知能
- 人工知能と機械学習
- AS
- 側面
- 評価する
- 団体
- At
- オーディオ
- 自動的に
- 利用できます
- ベース
- BE
- になる
- になる
- 行動
- 背後に
- さ
- 以下
- 利点
- より良いです
- の間に
- ブログソン
- 持って来る
- ビルド
- 建物
- ビジネス
- (Comma Separated Values) ボタンをクリックして、各々のジョブ実行の詳細(開始/停止時間、変数値など)のCSVファイルをダウンロードします。
- by
- 計算された
- 計算
- 呼ばれます
- 缶
- 機能
- 機能
- キャプチャー
- 場合
- 例
- カテゴリ
- チェーン
- チェーン
- 特性
- 明瞭
- 分類
- 分類します
- クリック
- クラスタリング
- コード
- コーディング
- 認知
- コレクション
- 一般に
- コンパクト
- 比較します
- 比較
- コンプリート
- 複雑な
- コンポーネント
- 包括的な
- 計算
- 計算的
- お問合せ
- 接続する
- 検討
- 見なさ
- 含む
- コンテンツ
- コンテキスト
- 従来の
- 会話
- 変換
- 対応する
- 可能性
- 作ります
- 作成
- 創造性
- 顧客
- データ
- データ分析
- データポイント
- データ処理
- データベース
- データベースを追加しました
- データセット
- 取引
- 意思決定
- 決定
- 需要
- 派生する
- 設計
- 希望
- 細部
- 検出
- 発展した
- 異なる
- 違い
- 異なります
- デジタル処理で
- 次元
- 大きさ
- 直接
- 方向
- 方向
- 発見する
- 裁量
- 話し合います
- 議論する
- 表示される
- 距離
- do
- ドキュメント
- ありません
- ドン
- DOT
- ダイナミック
- 動的に
- e
- 各
- 緩和する
- 容易
- 効果的に
- 効率
- 効率的な
- どちら
- 要素は
- 埋め込み
- enable
- end
- エンジニアリング
- エンジニア
- エンジン
- 英語
- 確実に
- 環境
- 本質
- 本質的な
- エーテル(ETH)
- さらに
- 進化
- 実行します
- 運動
- 探る
- エキス
- 容易にする
- 親しみ
- 遠く
- 特徴
- 特徴
- FRBは
- フィギュア
- File
- もう完成させ、ワークスペースに掲示しましたか?
- 名
- フラットな
- フォロー中
- 最前線
- フォーム
- 形式でアーカイブしたプロジェクトを保存します.
- 無料版
- から
- 未来
- ギャップ
- 生成する
- 世代
- 生々しい
- 生成AI
- ジャンル
- GitHubの
- 与える
- 与えられた
- でログイン
- グループ
- グループの
- ハンドル
- 起こる
- 持ってる
- 助けます
- ことができます
- こちら
- ハイ
- ハイレベル
- 非常に
- 歴史的
- 認定条件
- しかしながら
- HTTPS
- 巨大な
- 何百
- i
- ID
- 識別する
- if
- 画像
- 影響
- 実装
- import
- 改善します
- in
- ますます
- index
- 索引付けされた
- インデックス
- 示します
- 索引
- 産業
- 産業を変えます
- 影響力のある
- 情報
- 固有の
- 革新的な
- 入力
- インサート
- 内部
- 洞察
- を取得する必要がある者
- インテリジェンス
- 対話
- 相互作用
- 相互作用
- に
- 複雑さ
- 関与
- IT
- ITS
- Jobs > Create New Job
- join
- 参加しませんか
- 旅
- ただ
- キー
- キー
- キーワード
- 子供たち
- 知っている
- ラベル
- 土地
- 風景
- 大
- 主要な
- リード
- 学習
- 活用します
- レバレッジ
- ような
- リスト
- ローダ
- ロジック
- ログイン
- 機械
- 機械学習
- 主要な
- make
- 作る
- 作成
- 管理する
- 方法
- 手動で
- メーカー
- 地図
- 大規模な
- マッチ
- 数学的
- 意味のある
- だけど
- 措置
- 計測
- メカニズム
- メディア
- マージ
- 方法論
- メソッド
- Microsoft
- 最小限の
- モデル
- 他には?
- さらに
- 最も
- ずっと
- の試合に
- しなければなりません
- 名
- 自然
- 必要
- 新作
- 今
- 多数の
- オブジェクト
- オブジェクト
- of
- 提供
- on
- ONE
- もの
- オンライン
- の
- 開いた
- OpenAI
- 業務執行統括
- 反対
- or
- 組織
- 整理
- 整理する
- オリジナル
- OS
- その他
- 私たちの
- 所有している
- ページ
- ペア
- 部
- 渡された
- 通過
- パターン
- 完璧
- 実行する
- パフォーマンス
- 実行
- 実行する
- 視点
- 視点
- 画像
- 極めて重要な
- シンプルスタイル
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 演劇
- お願いします
- ポイント
- ポイント
- 可能
- 潜在的な
- 電力
- 強力な
- 実用的
- 実用化
- 正確な
- 正確に
- プ
- 前
- 問題
- プロセス
- プロダクト
- 製品
- プロジェクト
- 著名な
- プロンプト
- 正しく
- プロパティ
- 財産
- 提供します
- 提供
- 準備
- 公表
- パフ
- 目的
- 目的
- 量
- クエリ
- 質問
- クイック
- より速い
- すぐに
- 急速に
- おすすめ
- 提言
- に対する
- 地域
- 関係
- の関係
- 関連した
- 表現
- で表さ
- 表し
- の提出が必要です
- 要件
- 応答
- 回答
- 結果
- 結果
- 明らかに
- 職種
- 行
- s
- 同じ
- 科学
- スコープ
- を検索
- 検索エンジン
- 検索
- 検索
- 感情
- SEO
- 設定
- 形状
- シェーピング
- shared
- 棚
- ショート
- 示す
- 作品
- 側
- 同様の
- 類似
- 簡単な拡張で
- から
- サイズ
- So
- 溶液
- ソリューション
- 一部
- ソース
- スペース
- 特定の
- スピード
- split
- スポッティング
- SQL
- 都道府県
- ステートメント
- 文
- ステップ
- まだ
- ストレージ利用料
- 店舗
- 保存され
- 店舗
- 構造
- 構造化された
- 勉強
- 続いて
- 成功した
- 相乗効果
- システム
- T
- テーブル
- TAG
- タスク
- テクニック
- 技術の
- 条件
- 클라우드 기반 AI/ML및 고성능 컴퓨팅을 통한 디지털 트윈의 기초 – Edward Hsu, Rescale CPO 많은 엔지니어링 중심 기업에게 클라우드는 R&D디지털 전환의 첫 단계일 뿐입니다. 클라우드 자원을 활용해 엔지니어링 팀의 제약을 해결하는 단계를 넘어, 시뮬레이션 운영을 통합하고 최적화하며, 궁극적으로는 모델 기반의 협업과 의사 결정을 지원하여 신제품을 결정할 때 데이터 기반 엔지니어링을 적용하고자 합니다. Rescale은 이러한 혁신을 돕기 위해 컴퓨팅 추천 엔진, 통합 데이터 패브릭, 메타데이터 관리 등을 개발하고 있습니다. 이번 자리를 빌려 비즈니스 경쟁력 제고를 위한 디지털 트윈 및 디지털 스레드 전략 개발 방법에 대한 인사이트를 나누고자 합니다.
- テキスト生成
- より
- それ
- 未来
- アプリ環境に合わせて
- それら
- ボーマン
- 彼ら
- この
- 三
- 介して
- 時間
- <font style="vertical-align: inherit;">回数</font>
- 〜へ
- 伝統的な
- トレーニング
- 最適化の適用
- 変換
- 変形させる
- 変換
- 試します
- 2
- 最終的に
- わかる
- 理解する
- 間違いなく
- アンロック
- ロック解除
- アップデイト
- アップグレード
- us
- 使用法
- つかいます
- 中古
- ユーザー
- 使用されます
- いつもの
- 価値観
- 多様
- さまざまな
- 非常に
- 極めて重要な
- vs
- ました
- we
- webp
- 明確な
- した
- この試験は
- 何ですか
- かどうか
- which
- while
- 意志
- 以内
- 言葉
- 仕事
- ワーキング
- でしょう
- 貴社
- あなたの
- ゼファーネット