この記事では、学習します CPU のみのコンピューターに GPT4All モデルを展開して使用する方法 (私が使用しているのは のMacBook Pro GPUなしで!)

コンピューターで GPT4All を使用する — 写真提供: 著者
この記事では、ローカル コンピューターに GPT4All (強力な LLM) をインストールし、Python でドキュメントを操作する方法を説明します。 PDF またはオンライン記事のコレクションが、質問と回答のナレッジ ベースになります。
ノーザンダイバー社の 公式ウェブサイト GPT4All それは次のように説明されています 無料で使用でき、ローカルで実行され、プライバシーを意識したチャットボットです。 GPU やインターネットは必要ありません。
GTP4All はトレーニングとデプロイのためのエコシステムです 強力な および カスタマイズ 実行される大規模な言語モデル 局部的に コンシューマーグレードの CPU で。
当社の GPT4All モデルは 4GB ファイルで、ダウンロードして GPT4All オープンソース エコシステム ソフトウェアにプラグインできます。 ノミックAI 高品質で安全なソフトウェア エコシステムを促進し、個人や組織が独自の大規模な言語モデルをローカルで簡単にトレーニングして実装できるようにする取り組みを推進します。
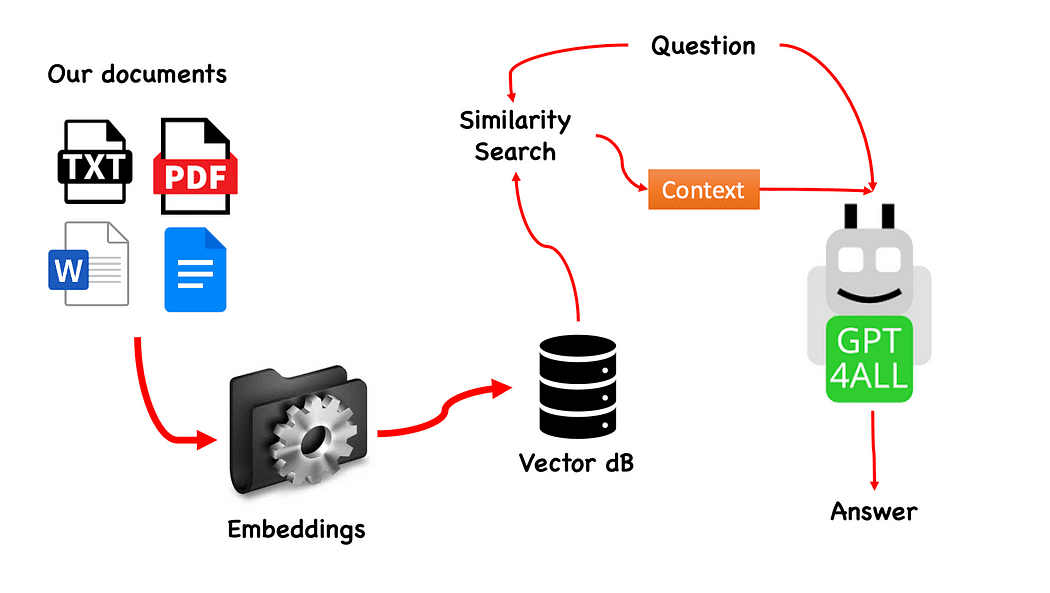
GPT4All を使用した QnA のワークフロー — 著者が作成
このプロセスは (わかっていれば) 非常に簡単で、他のモデルでも繰り返すことができます。 手順は次のとおりです。
- GPT4All モデルをロードします
- つかいます ラングチェーン ドキュメントを取得してロードするため
- 埋め込みによって消化できる小さなチャンクにドキュメントを分割する
- FAISS を使用して、埋め込みを含むベクトル データベースを作成します。
- GPT4All に渡したい質問に基づいて、ベクトル データベースで類似性検索 (セマンティック検索) を実行します。これは、 コンテキスト 私たちの質問に対して
- 質問とコンテキストを GPT4All にフィードします。 ラングチェーン そして答えを待ちます。
したがって、必要なのは埋め込みです。 埋め込みとは、テキスト、ドキュメント、画像、音声などの情報を数値的に表現したものです。この表現は、埋め込まれているものの意味論的な意味を捉えており、これがまさに必要なものです。 このプロジェクトでは、重い GPU モデルに依存することはできません。そのため、Alpaca ネイティブ モデルをダウンロードして、から使用します。 ラングチェーン ラマCpp埋め込み。 心配しないで! すべてが段階的に説明されています
仮想環境を作成する
新しい Python プロジェクト用の新しいフォルダーを作成します (例: GPT4ALL_Fabio) (名前を入力してください)。
mkdir GPT4ALL_Fabio
cd GPT4ALL_Fabio次に、新しい Python 仮想環境を作成します。 複数の Python バージョンがインストールされている場合は、希望のバージョンを指定します。この場合、Python 3.10 に関連付けられたメインのインストールを使用します。
python3 -m venv .venvコマンド python3 -m venv .venv という名前の新しい仮想環境を作成します .venv (ドットは venv という隠しディレクトリを作成します)。
仮想環境では、分離された Python インストールが提供されます。これにより、システム全体の Python インストールや他のプロジェクトに影響を与えることなく、特定のプロジェクトのみにパッケージと依存関係をインストールできます。 この分離により、一貫性が維持され、異なるプロジェクト要件間の潜在的な競合を防ぐことができます。
仮想環境が作成されたら、次のコマンドを使用してアクティブ化できます。
source .venv/bin/activate 
アクティブ化された仮想環境
インストールするライブラリ
私たちが構築しているプロジェクトでは、それほど多くのパッケージは必要ありません。 必要なのは以下だけです:
- GPT4All の Python バインディング
- ドキュメントを操作するための Langchain
LangChain は、言語モデルを利用してアプリケーションを開発するためのフレームワークです。 これにより、API 経由で言語モデルを呼び出すだけでなく、言語モデルを他のデータ ソースに接続し、言語モデルがその環境と対話できるようになります。
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4LangChain については、バージョンも指定していることがわかります。 このライブラリは最近多くの更新を受け取っているため、セットアップが明日も確実に動作するようにするには、正常に動作することがわかっているバージョンを指定することをお勧めします。 非構造化は PDF ローダーに必要な依存関係であり、 ピテセラクト および pdf2画像 同様に。
注意: GitHub リポジトリには、requirements.txt ファイルがあります (推奨: JL ACR) このプロジェクトに関連付けられたすべてのバージョン。 次のコマンドを使用してメイン プロジェクト ファイル ディレクトリにダウンロードした後、インストールを XNUMX 回で実行できます。
pip install -r requirements.txt記事の最後に作成したのは、 トラブルシューティングのセクション。 GitHub リポジトリには、これらすべての情報が記載された更新された READ.ME もあります。
一部のことに留意してください ライブラリにはPythonのバージョンに応じて利用可能なバージョンがあります 仮想環境上で実行されています。
モデルを PC にダウンロードする
これは本当に重要なステップです。
このプロジェクトには GPT4All が必ず必要です。 Nomic AI で説明されているプロセスは非常に複雑で、(私のように) 誰もが持っているわけではないハードウェアが必要です。 それで ここにモデルへのリンクがあります すでに変換されており、すぐに使用できます。 ダウンロードをクリックするだけです。
GPT4All モデルをダウンロードする
冒頭で簡単に説明したように、埋め込み用のモデル、つまりクラッシュせずに CPU 上で実行できるモデルも必要です。 クリック alpaca-native-7B-ggml をダウンロードするにはここにリンクしてください すでに 4 ビットに変換されており、埋め込みのモデルとして使用する準備ができています。

の横にあるダウンロード矢印をクリックします ggml-model-q4_0.bin
なぜ埋め込みが必要なのでしょうか? フロー図を覚えていると思いますが、ナレッジ ベースのドキュメントを収集した後、必要な最初のステップは次のとおりです。 埋め込みます 彼ら。 この Alpaca モデルの LLamaCPP 埋め込みは、このジョブに完全に適合しており、このモデルも非常に小さい (4 Gb) です。 ちなみに、QnA にアルパカ モデルを使用することもできます。
更新 2023.05.25: Mani Windows ユーザーは、llamaCPP 埋め込みを使用する際に問題に直面しています。 これは主に、次のような Python パッケージ llama-cpp-python のインストール中に発生します。
pip install llama-cpp-pythonpip パッケージはライブラリのソースからコンパイルされます。 通常、Windows にはデフォルトで CMake または C コンパイラがインストールされていません。 でも心配しないでください、解決策はあります
Windows 上で llamaEmbeddings を使用した LangChain に必要な llama-cpp-python のインストールを実行する CMake C コンパイラはデフォルトではインストールされないため、ソースからビルドすることはできません。
Xtools を使用する Mac ユーザーと Linux では、通常、C コンパイラは OS ですでに利用可能です。
問題を回避するには 事前にコンパイルされたホイールを使用する必要があります.
ここに行きます https://github.com/abetlen/llama-cpp-python/releases
そして、あなたのアーキテクチャとPythonのバージョンに準拠したホイールを探してください。 Weels バージョン 0.1.49 を取得する必要があります それより上位のバージョンには互換性がないためです。
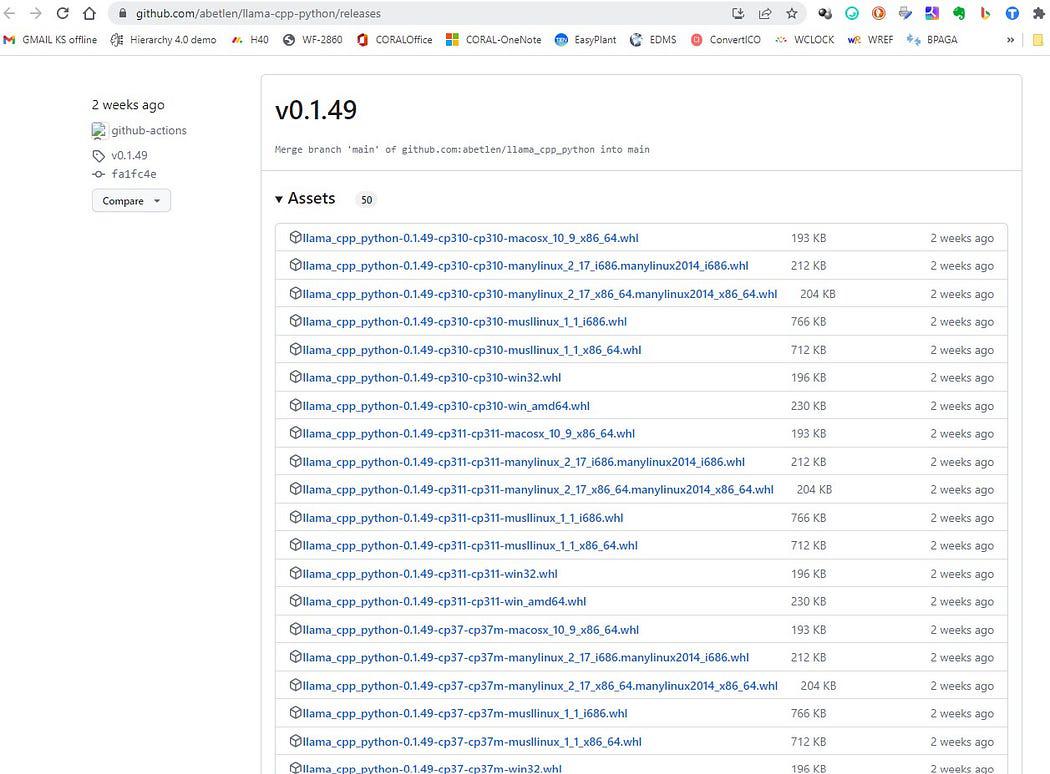
スクリーンショット https://github.com/abetlen/llama-cpp-python/releases
私の場合、Windows 10、64ビット、Python 3.10を使用しています。
したがって、私のファイルは llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl です
ダウンロード後、以下に示すように、XNUMX つのモデルを models ディレクトリに配置する必要があります。

ディレクトリ構造とモデルファイルの配置場所
GPT モデルで対話を制御したいので、Python ファイル (これを Python ファイルと呼びます) を作成する必要があります。 pygpt4all_test.py)、依存関係をインポートし、モデルに指示を与えます。 それは非常に簡単であることがわかります。
from pygpt4all.models.gpt4all import GPT4Allこれはモデルの Python バインディングです。 これで、それを呼び出して質問を開始できます。 創造的なものを試してみましょう。
モデルからコールバックを読み取る関数を作成し、GPT4All に文を完成させるよう依頼します。
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)最初のステートメントは、モデルを見つける場所をプログラムに指示しています (上のセクションで行ったことを思い出してください)。
XNUMX 番目のステートメントは、モデルに応答を生成し、プロンプト「昔々、」を完了するように要求しています。
これを実行するには、仮想環境がまだアクティブ化されていることを確認し、単に次を実行します。
python3 pygpt4all_test.pyモデルの読み込みテキストと文の完成を確認する必要があります。 ハードウェア リソースによっては、少し時間がかかる場合があります。
結果はあなたのものとは異なるかもしれません…しかし私たちにとって重要なのは、LangChain が機能し、LangChain を使って高度なものを作成できるということです。
注意事項(2023.05.23更新): pygpt4all に関連するエラーが発生した場合は、このトピックのトラブルシューティング セクションで提供される解決策を確認してください。 ラジニーシュ・アガルワル or オスカー・チョン著。
LangChain フレームワークは本当に素晴らしいライブラリです。 それは提供します コンポーネント 使いやすい方法で言語モデルを操作できるほか、以下の機能も提供します。 チェーン。 チェーンは、特定の使用例を最適に達成するために、これらのコンポーネントを特定の方法で組み立てるものと考えることができます。 これらは、ユーザーが特定のユースケースを簡単に開始できる、より高レベルのインターフェイスを目的としています。 これらのチェーンはカスタマイズできるように設計されています。
次の Python テストでは、 プロンプトテンプレート。 言語モデルはテキストを入力として受け取ります。そのテキストは一般にプロンプトと呼ばれます。 通常、これは単にハードコードされた文字列ではなく、テンプレート、いくつかの例、およびユーザー入力の組み合わせです。 LangChain は、プロンプトの構築と操作を容易にするいくつかのクラスと関数を提供します。 私たちにもそれができる方法を見てみましょう。
新しい Python ファイルを作成して呼び出します my_langchain.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])GPT モデルと直接対話できるように、LangChain からプロンプト テンプレートとチェーン、および GPT4All llm クラスをインポートしました。
次に、(以前と同様に) llm パスを設定した後、クエリに対する応答をキャッチできるようにコールバック マネージャーをインスタンス化します。
テンプレートの作成は非常に簡単です。 ドキュメントチュートリアル このようなものを使用できます…
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])template variable は、モデルとの対話構造を含む複数行の文字列です。中括弧内に外部変数をテンプレートに挿入します。このシナリオでは、 質問.
これは変数であるため、ハードコードされた質問であるか、ユーザー入力の質問であるかを決定できます。ここでは XNUMX つの例を示します。
# Hardcoded question
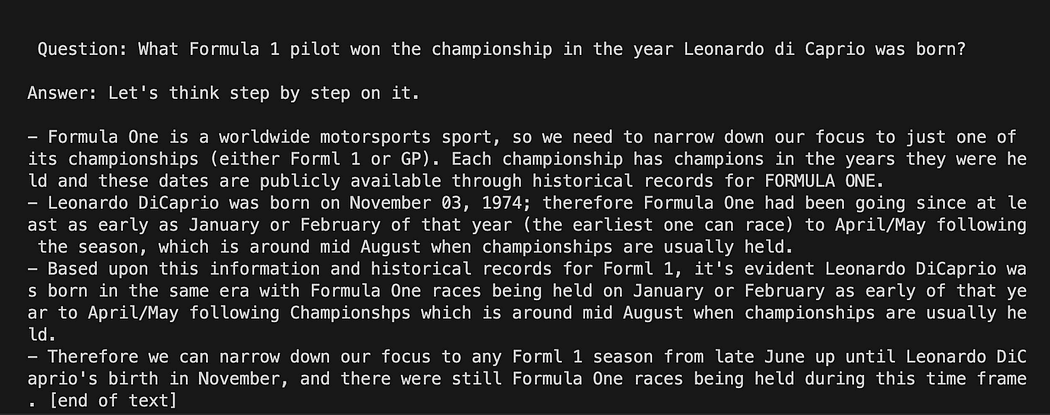
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")テスト実行では、ユーザーが入力したものにコメントを付けます。 あとは、テンプレート、質問、言語モデルをリンクするだけです。
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)仮想環境がまだアクティブであることを忘れずに確認し、次のコマンドを実行してください。
python3 my_langchain.py私とは異なる結果が得られるかもしれません。 驚くべきことは、GPT4All が答えを得ようとしている推論全体を確認できることです。 質問を調整すると、より良い結果が得られる場合もあります。
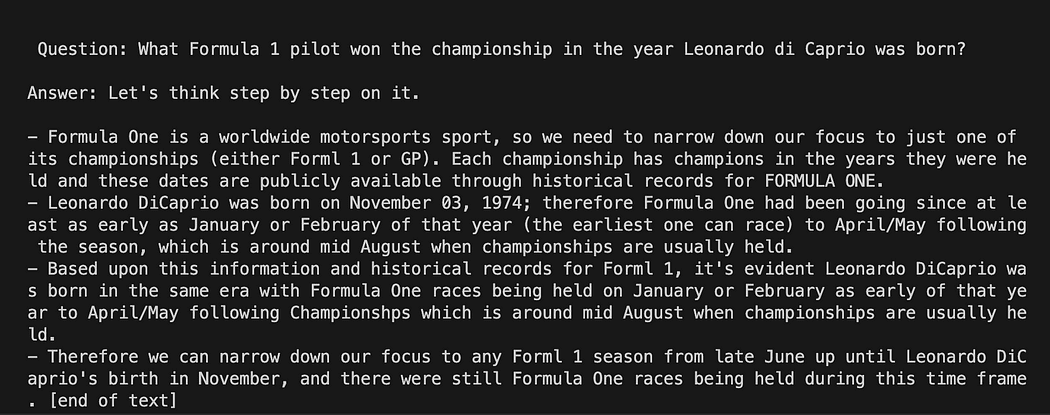
GPT4All のプロンプト テンプレートを使用した Langchain
ここからが驚くべき部分の始まりです。質問に応答するチャットボットとして GPT4All を使用してドキュメントと対話することになるからです。
手順のシーケンスは、以下を参照してください。 GPT4All を使用した QnA のワークフロー、pdf ファイルをロードし、チャンクに分割することです。 その後、埋め込み用の Vector Store が必要になります。 情報を取得するには、チャンク化されたドキュメントをベクター ストアにフィードする必要があります。その後、LLM クエリのコンテキストとして、類似性検索とともにそれらのドキュメントをこのデータベースに埋め込みます。
この目的のために、FAISS を直接使用します。 ラングチェーン 図書館。 FAISS は、Facebook AI Research のオープンソース ライブラリであり、高次元データの大きなコレクションから類似のアイテムを迅速に見つけるように設計されています。 データセット内で最も類似したアイテムをより簡単かつ迅速に見つけるためのインデックス作成および検索方法を提供します。 それは簡素化されるので、私たちにとって特に便利です 情報検索 作成したデータベースをローカルに保存できるようにします。これは、最初の作成後、その後の使用のために非常に高速にロードされることを意味します。
ベクトルインデックスDBの作成
新しいファイルを作成して呼び出します my_knowledge_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetime最初のライブラリは以前に使用したものと同じです。さらに、 ラングチェーン ベクター ストア インデックス作成の場合、 ラマCpp埋め込み Alpaca モデル (4 ビットに量子化され、cpp ライブラリでコンパイルされた) および PDF ローダーと対話します。
また、LLM を独自のパス (埋め込み用とテキスト生成用) でロードしましょう。
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)テストとして、すべての pfd ファイルを読み取ることができたかどうかを確認してみましょう。最初のステップは、それぞれの単一ドキュメントで使用される 3 つの関数を宣言することです。 XNUMX つ目は抽出されたテキストをチャンクに分割すること、XNUMX つ目はメタデータ (ページ番号など) を含むベクトル インデックスを作成すること、そして最後のものは類似性検索をテストすることです (後ほど詳しく説明します)。
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sourcesこれで、ドキュメントのインデックス生成をテストできます。 ドキュメント ディレクトリ: すべての PDF をそこに置く必要があります。 ラングチェーン ファイルの種類に関係なく、フォルダー全体をロードする方法もあります。後処理が複雑なので、LaMini モデルに関する次の記事で説明します。

私のdocsディレクトリには4つのPDFファイルが含まれています
関数をリストの最初のドキュメントに適用します。
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)最初の行では、os ライブラリを使用して PDFファイルのリスト docs ディレクトリ内。 次に、最初のドキュメントをロードします (ドキュメントリスト[0]) docs フォルダーから ラングチェーン、チャンクに分割し、次のベクトル データベースを作成します。 ラマ 埋め込み。
ご覧のとおり、私たちは pyPDF メソッド。 これは、ファイルを XNUMX つずつロードする必要があるため、使用するのに少し時間がかかりますが、次を使用して PDF をロードします。 pypdf ドキュメントの配列にすると、各ドキュメントにページのコンテンツとメタデータが含まれる配列を作成できます。 page 番号。 これは、クエリで GPT4All に与えるコンテキストのソースを知りたいときに非常に便利です。 ここでは readthedocs の例を示します。
スクリーンショット ラングチェーンのドキュメント
ターミナルからコマンドを使用して Python ファイルを実行できます。
python3 my_knowledge_qna.py埋め込み用のモデルをロードした後、インデックス作成のためにトークンが動作しているのがわかります。特に私のように CPU のみで実行する場合は時間がかかりますので、慌てる必要はありません (8 分かかりました)。
最初のベクトルデータベースの完成
説明したように、pyPDF メソッドは遅いですが、類似性検索のための追加データを提供します。 すべてのファイルを反復処理するには、異なるデータベースをマージできる FAISS の便利なメソッドを使用します。 ここで行うことは、上記のコードを使用して最初のデータベースを生成することです (これを db0) そして、for ループを使用して、リスト内の次のファイルのインデックスを作成し、それをすぐにマージします。 db0.
コードは次のとおりです。 を使用して進行状況を示すためにいくつかのログを追加したことに注意してください。 datetime.datetime.now() 終了時間と開始時間の差分を出力して、操作にかかった時間を計算します (気に入らない場合は削除できます)。
マージ手順は次のとおりです
# merge dbi with the existing db0
db0.merge_from(dbi)最後の手順の XNUMX つは、データベースをローカルに保存するためのものです。生成全体には数時間かかることもあります (ドキュメントの数によって異なります)。そのため、これを XNUMX 回だけ実行すればよいのは非常に良いことです。
# Save the databasae locally
db0.save_local("my_faiss_index")コード全体は次のとおりです。 フォルダーからインデックスを直接ロードする GPT4All と対話するときに、その多くの部分をコメントします。
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  Python ファイルの実行には 22 分かかりました
Python ファイルの実行には 22 分かかりました
ドキュメントについて GPT4All に質問する
今、私たちはここにいます。 インデックスがあり、それをロードし、プロンプト テンプレートを使用して GPT4All に質問に答えるように依頼できます。 ハードコーディングされた質問から始めて、入力された質問をループしていきます。
次のコードを Python ファイル内に配置します db_loading.py ターミナルからコマンドで実行します python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])印刷されたテキストは、クエリに最もよく一致する 3 つの情報源のリストであり、文書名とページ番号も示されます。
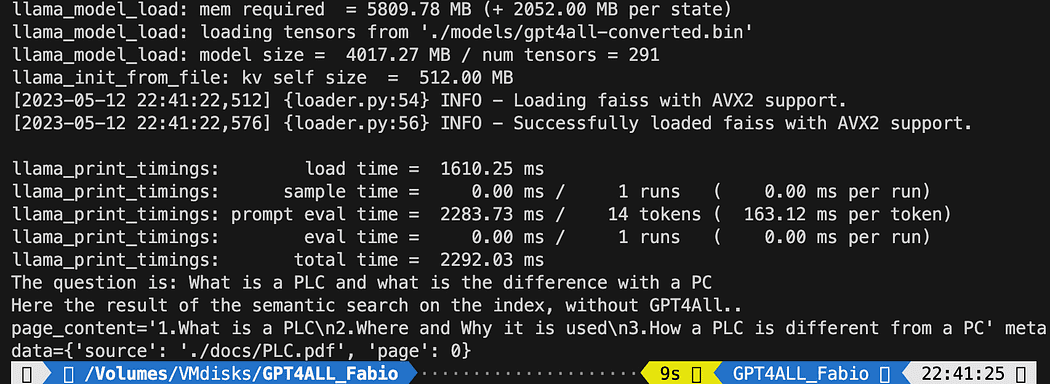
ファイルを実行したセマンティック検索の結果 db_loading.py
これで、プロンプト テンプレートを使用して、クエリのコンテキストとして類似性検索を使用できるようになりました。 3 つの関数の後に、すべてのコードを次のものに置き換えるだけです。
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))実行すると、次のような結果が得られます (ただし、異なる場合があります)。 すごいですね!
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.ユーザー入力の質問で行を置き換えたい場合
question = "What is a PLC and what is the difference with a PC"次のようなもので:
question = input("Your question: ")実験してみましょう。 ドキュメントに関連するすべてのトピックについてさまざまな質問をして、結果を確認してください。 確かにプロンプトとテンプレートには改善の余地が大きくあります。ぜひご覧ください。 インスピレーションを得るためにここに。 しかし ラングチェーン ドキュメントは本当に素晴らしいです(私はそれを理解することができました!!)。
記事のコードに従うか、で確認できます。 私のgithubリポジトリ.
ファビオ・マトリカルディ 教育者、教師、エンジニア、学習愛好家。 彼は 15 年間若い学生に教えてきましたが、現在は Key Solution Srl で新入社員の研修を行っています。 彼は 2010 年に産業オートメーション エンジニアとして私のキャリアをスタートさせました。XNUMX 代の頃からプログラミングに情熱を持っていた彼は、何かに命を吹き込むためのソフトウェアとヒューマン マシン インターフェイスを構築することの美しさを発見しました。 最新の管理スキルを備えた情熱的なリーダーになる方法を勉強するだけでなく、ティーチングとコーチングも私の日課の一部です。 エンジニアリングのライフサイクル全体を通じて、機械学習と人工知能を使用した、より優れた設計、予測システム統合を目指す旅に私と一緒に参加しましょう。
元の。 許可を得て転載。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- EVMファイナンス。 分散型金融のための統一インターフェイス。 こちらからアクセスしてください。
- クォンタムメディアグループ。 IR/PR増幅。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free
- :持っている
- :は
- :not
- :どこ
- $UP
- 1
- 10
- 11
- 12
- 13
- 14
- 15年
- 視聴者の38%が
- 16
- 2023
- 22
- 23
- 25
- 420
- 7
- 8
- 9
- a
- 能力
- できる
- 私たちについて
- 上記の.
- こちらからお申し込みください。
- 行為
- 活性化
- 追加されました
- 添加
- NEW
- 高度な
- 影響
- 後
- AI
- 愛の研究
- すべて
- 許す
- ことができます
- 既に
- また
- am
- 驚くべき
- an
- 分析
- および
- 回答
- どれか
- API
- 申し込む
- 建築
- です
- 配列
- 記事
- 物品
- 人工の
- 人工知能
- AS
- 関連する
- At
- オーディオ
- 自動化
- 自動的に
- オートメーション
- 利用できます
- 避ける
- ベース
- ベース
- BE
- 美容
- なぜなら
- き
- さ
- 以下
- BEST
- より良いです
- の間に
- 越えて
- ビッグ
- BIN
- 拘束
- ビット
- 生まれる
- 簡潔に
- 持って来る
- ビルド
- 建物
- 内蔵
- バス
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 計算する
- コール
- 呼ばれます
- コール
- 缶
- 容量
- キャプチャ
- キャリア
- キャリー
- 場合
- レスリング
- CD
- 一定
- 確かに
- チェーン
- チェーン
- チャンピオンシップ
- チャットボット
- AI言語モデルを活用してコードのデバッグからデータの異常検出まで、
- チェック
- 化学物質
- class
- クラス
- クリック
- コーチング
- コード
- コード
- 収集する
- コレクション
- コレクション
- 組み合わせ
- コメント
- 一般に
- 伝える
- コミュニケーション
- 互換性のあります
- コンプリート
- 記入済みの
- 完成
- 複雑な
- 複雑な
- コンポーネント
- コンピュータ
- コンピューター
- お問合せ
- 交流
- 構築
- consumer
- 含まれています
- コンテンツ
- コンテキスト
- コントロール
- コントローラ
- controls
- 便利
- 変換
- 可能性
- カバー
- CPU
- 作ります
- 作成した
- 作成します。
- 作成
- 創造
- クリエイティブ
- 重大な
- カスタマイズ可能な
- daily
- データ
- データベース
- データベースを追加しました
- 日付
- 日付時刻
- 決めます
- デフォルト
- 定義済みの
- デルタ
- 依存関係
- によっては
- 依存
- 展開します
- 記載された
- 設計
- 設計
- 希望
- 開発
- デバイス
- Devices
- DID
- 違い
- 異なります
- 消化しやすい
- デジタル
- 直接に
- 発見する
- 発見
- do
- ドキュメント
- ドキュメント
- ドキュメント
- ありません
- doesnの
- 行われ
- ドント
- DOT
- ダウンロード
- 運転
- 間に
- 各
- 容易
- 簡単に
- 簡単に
- エコシステム
- 生態系
- 努力
- 埋め込みます
- 埋め込まれた
- 埋め込み
- 社員
- enable
- end
- エンジニア
- エンジニアリング
- 入力します
- 熱狂者
- 全体
- 環境
- エラー
- 特に
- 等
- エーテル(ETH)
- さらに
- すべてのもの
- 正確に
- 例
- 例
- 実行
- 既存の
- 実験
- 説明する
- 説明
- 説明
- 外部
- 顔
- 促進する
- 向い
- スピーディー
- 速いです
- File
- もう完成させ、ワークスペースに掲示しましたか?
- 終わり
- 名
- フィット
- フロー
- 続いて
- フォロー中
- 次
- フォーム
- 形式でアーカイブしたプロジェクトを保存します.
- 式
- F1に関するニュース
- フレームワーク
- から
- function
- 機能
- さらに
- 生成する
- 生成
- 世代
- 取得する
- GitHubの
- 与える
- 与えられた
- 与える
- 与え
- 行く
- 良い
- GPU
- グレード
- ハンドリング
- 起こります
- ハード
- Hardware
- 持ってる
- he
- ヘビー
- ことができます
- こちら
- 隠されました
- ハイ
- より高い
- HOURS
- 認定条件
- How To
- HTML
- HTTP
- HTTPS
- 人間
- i
- ICS
- if
- 画像
- 直ちに
- 実装する
- import
- 重要
- 改善
- in
- include
- index
- インデックス
- 個人
- インダストリアル
- 産業自動化
- 産業
- 情報
- 入出力
- 入力
- install
- インストール
- 説明書
- 統合
- インテリジェンス
- 意図された
- 対話
- 相互作用
- インタフェース
- インターフェース
- インターネット
- に
- 概要
- 分離された
- 分離
- IT
- リーディングシート
- 繰り返し
- ITS
- ジョブ
- join
- 旅
- ただ
- KDナゲット
- キー
- 知っている
- 知識
- 言語
- 大
- 姓
- 後で
- リーダー
- 学習
- レベル
- ライブラリ
- 図書館
- 生活
- wifecycwe
- ような
- ライン
- LINK
- linuxの
- リスト
- 少し
- 負荷
- ローダ
- ローディング
- ローカル
- 局部的に
- ロジック
- 長い
- より長いです
- 見て
- たくさん
- MAC
- 機械
- 機械学習
- 機械
- メイン
- 主に
- 維持する
- make
- マネージド
- 管理
- マネージャー
- マネージャー
- 製造業
- 多くの
- 五月..
- 意味
- 手段
- メモリ
- マージ
- マージ
- 方法
- メソッド
- マインド
- 分
- モデル
- 他には?
- 最も
- の試合に
- しなければなりません
- my
- 名
- ネイティブ
- 必要
- ネットワーク
- 新作
- 次の
- 今
- 数
- 番号
- オブジェクト
- of
- オファー
- on
- かつて
- ONE
- オンライン
- の
- オープンソース
- 操作
- 業務執行統括
- or
- 注文
- 組織
- OS
- その他
- 私たちの
- でる
- 出力
- が
- 自分の
- パッケージ
- パッケージ
- ページ
- 並列シミュレーションの設定
- 部
- 特定の
- 特に
- パス
- 情熱的な
- path
- PC
- のワークプ
- 実行する
- 許可
- 個人的な
- 画像
- ピース
- パイロット
- 植物
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- PLC
- お願いします
- プラグ
- ポート
- 位置
- ポスト
- 潜在的な
- 電力
- 発電所
- パワード
- 強力な
- プレ
- 防ぐ
- 印刷物
- printing
- 問題
- プロセス
- 処理されました
- ラボレーション
- 演奏曲目
- プログラム
- プログラミング
- 進捗
- プロジェクト
- プロジェクト(実績作品)
- プロトコル
- は、大阪で
- 目的
- 置きます
- Python
- 品質
- 質問
- 質問
- すぐに
- むしろ
- 読む
- 準備
- 本当に
- 受け入れ
- 最近
- 言及
- 指し
- 関係なく
- レジスタ
- 関連する
- 信頼性
- 頼る
- 覚えています
- 削除します
- 繰り返される
- replace
- レポート
- 倉庫
- 表現
- の提出が必要です
- 要件
- 必要
- 研究
- リソース
- 応答
- 回答
- 結果
- 結果
- return
- ルーム
- ラン
- ランニング
- s
- 安全性
- 同じ
- Save
- 節約
- シナリオ
- を検索
- 検索
- 二番
- セクション
- 安全に
- センサー
- 文
- シーケンス
- シリアル
- 設定
- いくつかの
- ショット
- すべき
- 示す
- 同様の
- 簡単な拡張で
- 単に
- から
- スキル
- 小さい
- So
- ソフトウェア
- 溶液
- 一部
- 何か
- ソース
- ソース
- 専門の
- 特別に
- 特定の
- 指定の
- split
- Spot
- start
- 開始
- 起動
- ステートメント
- Status:
- 手順
- ステップ
- まだ
- 店舗
- 文字列
- 構造
- 生徒
- 勉強
- そのような
- 取る
- Talk
- タスク
- 教師
- ティーチング
- ティーンエイジャー
- template
- ターミナル
- test
- テスト走行
- テスト
- テキスト生成
- より
- それ
- アプリ環境に合わせて
- それら
- その後
- そこ。
- ボーマン
- 彼ら
- 考える
- この
- 考え
- 介して
- 全体
- 時間
- 〜へ
- 一緒に
- トークン
- 明日
- あまりに
- 取った
- トピック
- トピック
- に向かって
- トレーニング
- 試します
- 2
- type
- 典型的な
- 一般的に
- 更新しました
- 更新版
- に
- us
- 使用法
- USB
- つかいます
- 使用事例
- 中古
- ユーザー
- users
- 通常
- 利用された
- さまざまな
- 確認する
- バージョン
- 非常に
- 、
- バーチャル
- W3
- wait
- 欲しいです
- ました
- 仕方..
- 方法
- we
- ウェブサイト
- WELL
- この試験は
- 何ですか
- ホイール
- いつ
- which
- 誰
- なぜ
- 広く
- 意志
- ウィンドウズ
- Windowsユーザー
- 以内
- 無し
- 勝った
- 仕事
- ワーキング
- 年
- 年
- 貴社
- 若い
- あなたの
- ゼファーネット










