Web スクレイピングは、Web サイトからデータを抽出するための強力なツールになる可能性がありますが、複雑で時間のかかるプロセスになる可能性もあります。 幸いなことに、Google スプレッドシートは、複雑なコードを記述する必要なく、ウェブサイトからデータをスクレイピングするためのユーザー フレンドリーなソリューションを提供します。 Google スプレッドシートの機能を活用することで、ウェブページから簡単にデータを抽出し、さまざまな方法で分析できます。 このブログでは、Google スプレッドシートを使用して Web ページをスクレイピングし、独自のプロジェクトで Web スクレイピングの可能性を解き放つ方法を説明します。 それでは、始めましょう!
Web スクレイピングは時間がかかり、複雑で、多くのコーディングが必要になる場合があります。 非コーダー向け。 Google スプレッドシートは、Web スクレイピングの優れた代替手段です。 Google シートの Web スクレイピングはコーディングを必要とせず、Web サイトのデータを分析するためのさまざまな方法を提供します。
このブログでは、Google スプレッドシートを使用して Web ページを簡単にスクレイピングする方法について説明します。 それでは始めましょう!
Web スクレイピングに Google スプレッドシートを使用する理由
Google スプレッドシートが Web スクレイピングの優れたツールである理由はいくつかあります。
- Google スプレッドシートは使いやすく、使い慣れたインターフェースを備えています。
- プログラミング言語の知識は必要ありません。
- Google スプレッドシートはどこからでもアクセスできます。
- Google スプレッドシートは無料で、個人や中小企業にとって手頃な価格です。
- Google は他のスイート ツールと簡単に統合できます。
- マクロまたはスクリプトを使用して、Web スクレイピング タスクを自動化できます。
- Google スプレッドシートの数式を使用して、スクレイピングされたデータを簡単に分析できます。
ワンクリックで任意の Web ページからテキストを抽出します。 ナノネットに向かう ウェブサイトスクレイパー、URLを追加して「スクレイプ」をクリックすると、ウェブページのテキストをファイルとして即座にダウンロードできます。 今すぐ無料でお試しください。
Google スプレッドシートの Web スクレイピングに使用する関数は何ですか?
Google スプレッドシートを使用して Web ページをスクレイピングする必要がある場合に使用できる関数をいくつか紹介します。
インポートHTML:
HTML ページからテーブルとリストを抽出します。
=IMPORTHTML(url, query, index)- url: スクレイピングしたいウェブページのリンクです
- クエリ: データ型 – テーブル、リスト
- index: 特定のテーブルを抽出する場合は、これを使用できます
例:
=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)","table",1)インポート XML:
XML ページからデータを抽出します。
=IMPORTXML(url, xpath_query)- url: スクレイピングしたいウェブページへのリンクです
- xpath_query: 抽出するデータを識別する XPath 式
例:
=IMPORTXML("https://www.w3schools.com/xml/note.xml", "//note/to")インポートデータ:
CSV および TSV ファイルからデータを抽出します。
=IMPORTDATA(url)- url: データを抽出する CSV または TSV ファイルの URL
例:
=IMPORTDATA("https://www.stats.govt.nz/assets/Uploads/Annual-enterprise-survey/Annual-enterprise-survey-2021-financial-year-provisional/Download-data/annual-enterprise-survey-2021-financial-year-provisional-size-bands.csv")正規表現抽出:
この関数は、正規表現パターンに一致するデータを抽出できます。
=REGEXEXTRACT(text, regular_expression)- text: パターンを検索するテキスト
- regular_expression: 一致させたいパターン
例:
=REGEXEXTRACT("1 pound = $1.40", "$d+.d+")注: これらの機能は、すべての Web サイトで機能するとは限りません。 サイトのレイアウトにもよります。 さらにデータが必要な場合は、Python と Java を使用した Web スクレイピングのチュートリアルに頼るか、Nanonets のような Web サイトからテキストへのツールを使用できます。
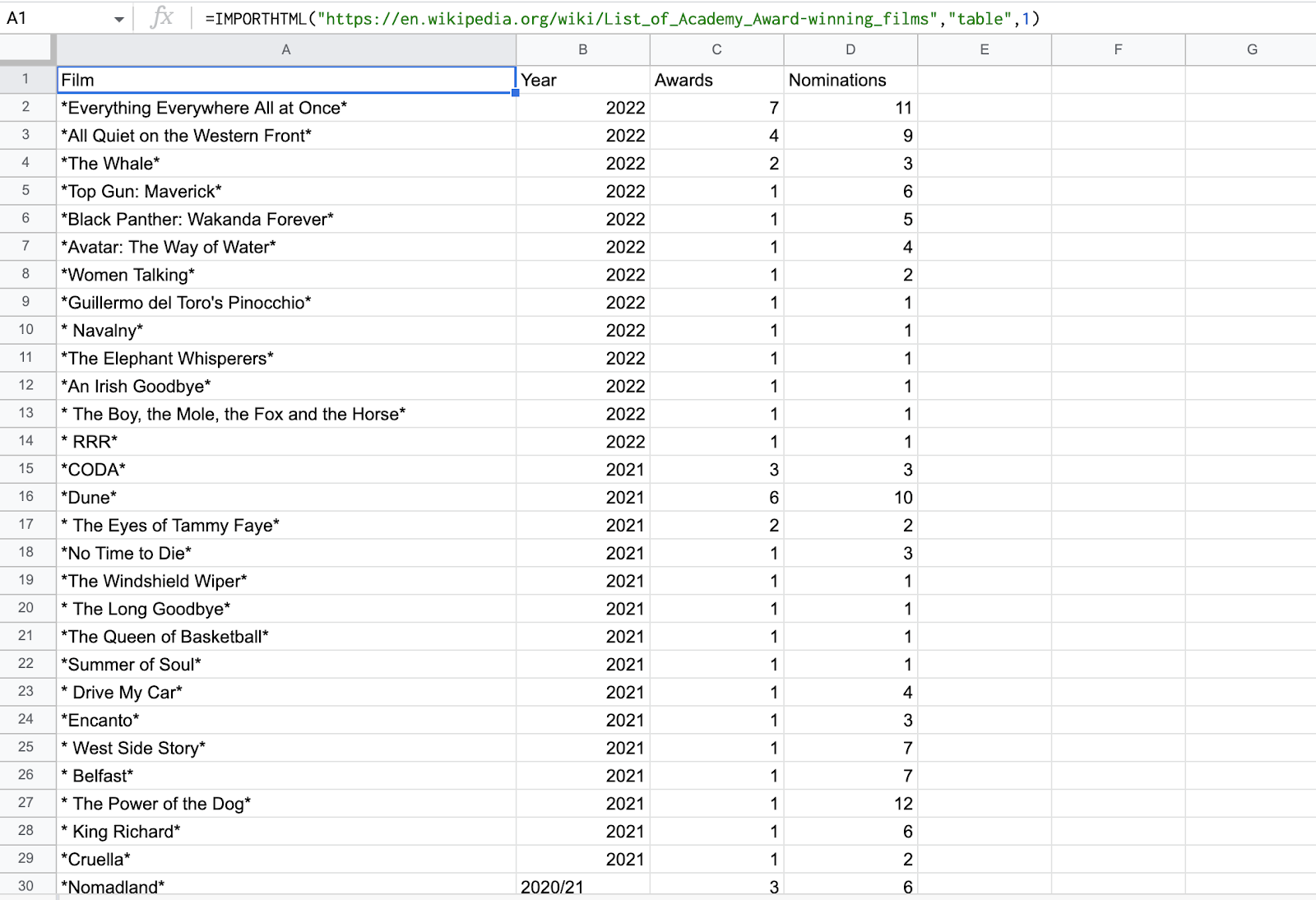
HTML テーブルを Google スプレッドシートに抽出してみましょう。 からテーブルをこすり取ろうとします。 ウィキペディアのアカデミー賞受賞映画のリスト。
- Googleスプレッドシートを開きます。
- 新しいセルに、「=IMPORTHTML(url, query, index)」と入力します。
1.私たちのコードは、
=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_Academy_Award-winning_films","table",1) =IMPORTHTML(“https://en.wikipedia.org/wiki/List_of_Academy_受賞作品”,”表”,1)
ウィキペディアのページの最初のテーブルをスクレイピングします
3.結果を確認する
Google スプレッドシートの Web スクレイピングを使用してデータをスクレイピングするには?
Google スプレッドシートを使用して、タイトル、説明、H1 などをスクレイピングする方法を見てみましょう。 Google スプレッドシートで H1 スクレイピングを開始するために、この特定の IMPORTXML 関数を使用します。 ナノネットのページ. 手順は次のとおりです。
- 新規または既存の Google スプレッドシートを開きます。
- セルに次の数式を入力します。
=IMPORTXML(“https://nanonets.com/image-to-text”, “//h1/text()”)- H1 タグを抽出するには、次の XPath 式を使用します: //h1/text()
- タイトル タグを抽出するには、次の XPath 式を使用します: //title/text()
- メタ記述タグを抽出するには、次の XPath 式を使用します: //meta[@name='description']/@content
- すべてのページ リンクを抽出するには、次の XPath 式を使用します: //a/@href
Enter キーを押すと、Google スプレッドシートが自動的にデータを収集し、選択したセルに表示します。
次に、数式を他のセルにコピーして、同じまたは別の Web ページから追加のデータをスクレイピングできます。
ワンクリックで任意の Web ページからテキストを抽出します。 ナノネットに向かう ウェブサイトスクレイパー、URLを追加して「スクレイプ」をクリックすると、ウェブページのテキストをファイルとして即座にダウンロードできます。 今すぐ無料でお試しください。
Google Sheets Web Scraper を使用するデメリットは何ですか?
- Google スプレッドシートの機能は限られています。 複雑なレイアウトになると、動的コンテンツを処理できません。
- Google スプレッドシートの Web スクレイピング式を使用してデータをスクレイピングすると、データの不一致が生じる可能性があります。
- Web サイトからデータをスクレイピングする場合、機密情報や機密情報を誤ってスクレイピングする可能性があります。 これにより、特にスクレイピングされたデータが共有されているか、安全でない場所に保存されている場合、プライバシーとセキュリティの問題が発生する可能性があります.
ヒント: Google スプレッドシートの Web スクレイピングは、メタ タイトル、リスト、テーブルの抽出などの複雑でない Web スクレイピング タスクの優れた代替手段です。 複雑なタスクの場合は、Web スクレイピング ツールを使用する必要があります。
よくあるご質問
Google スプレッドシートで Web スクレイピングできますか?
はい、Google スプレッドシートには IMPORTHTML、IMPORTXML、IMPORTDATA、
Web サイトから直接 Google スプレッドシートにデータをキャプチャできるようにする REGEXTRACT。 ただし、機能が制限される場合があり、より複雑な Web スクレイピング タスクでは、別の Web スクレイパーを使用するか、カスタム コードを記述する必要がある場合があります。
データを Google シートにスクレイピングするにはどうすればよいですか?
IMPORTHTML、IMPORTXML、IMPORTDATA、REGEXTRACT などの組み込み関数のいずれかを使用して、データを Google スプレッドシートにスクレイピングできます。 これらの関数を使用すると、Web サイト、CSV または TSV ファイルからデータを抽出し、正規表現パターンに一致させることができます。 URL、クエリ、インデックス、または正規表現パターンを指定するだけで、データがスクレイピングされ、Google スプレッドシートに取り込まれます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://nanonets.com/blog/scrape-websites-using-google-sheets-formulas/
- :は
- 1
- 11
- 2023
- 7
- a
- アカデミー
- アクセス可能な
- NEW
- 手頃な価格の
- すべて
- 代替案
- 分析します
- および
- どこにでも
- です
- AS
- 自動化する
- 自動的に
- 受賞歴のある
- BE
- になる
- ブログ
- 内蔵
- ビジネス
- by
- 缶
- 機能
- キャプチャー
- 場合
- 細胞
- チェック
- クリック
- 閉じる
- コード
- コーディング
- 複雑な
- 懸念事項
- コンテンツ
- カスタム
- データ
- 依存
- 説明
- 異なります
- 直接に
- ディスプレイ
- ダウンロード
- ダイナミック
- 各
- 簡単に
- 入力します
- 特に
- エーテル(ETH)
- あらゆる
- 優れた
- 既存の
- エキス
- 抽出
- おなじみの
- 特徴
- File
- 名
- フォロー中
- 式
- 幸いにも
- 無料版
- から
- function
- 機能性
- 機能
- 取得する
- でログイン
- 政府
- 素晴らしい
- ガイド
- ハンドル
- 助けます
- こちら
- 認定条件
- How To
- しかしながら
- HTML
- HTTPS
- i
- 識別する
- in
- index
- 個人
- 情報
- 統合する
- インタフェース
- 巻き込む
- IT
- Java
- 一つだけ
- 知識
- 言語
- レイアウト
- 活用
- ような
- 限定的
- LINK
- リンク
- リスト
- 場所
- たくさん
- マクロ
- 作成
- 多くの
- 一致
- Meta
- かもしれない
- 他には?
- 必要
- 必要
- 新作
- of
- オファー
- on
- ONE
- 注文
- その他
- 自分の
- ページ
- 特定の
- パターン
- パターン
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 人口
- 潜在的な
- ポンド
- 電力
- 強力な
- プライバシー
- プライバシーとセキュリティ
- プロセス
- プログラミング
- プロジェクト(実績作品)
- は、大阪で
- Python
- 上げる
- 理由は
- レギュラー
- 必要とする
- 必要
- リゾート
- s
- 同じ
- こすること
- スクリプト
- を検索
- セキュリティ
- 選択
- 敏感な
- 別
- いくつかの
- shared
- すべき
- 簡単な拡張で
- 単に
- 小さい
- 中小企業
- So
- 溶液
- 一部
- 特定の
- 開始
- 統計情報
- ステップ
- 保存され
- そのような
- スイート
- テーブル
- テーブル抽出
- TAG
- タスク
- それ
- ボーマン
- 介して
- 時間がかかる
- 役職
- タイトル
- 〜へ
- ツール
- 豊富なツール群
- チュートリアル
- アンロック
- 無担保
- URL
- つかいます
- 「DeckleBenchは非常に使いやすく最適なソリューションを簡単に見つけることができるため、稼働率が向上しコストも削減した。当社の旧システムは良かったが改善は期待していなかった。
- 多様
- 方法
- ウェブ
- ウェブスクレイピング
- ウェブサイト
- ウェブサイト
- Wikipedia
- 意志
- 無し
- 仕事
- 書きます
- 書き込み
- XML
- あなたの
- ゼファーネット