
による画像 rawpixel.com on Freepik
どのようなビジネスに携わっていても、データドリブンの時代には、データの分析方法を知ることがこれまで以上に重要になっています。 データ分析により、企業は競争力を維持し、より適切な意思決定を行うことができるようになります。
データ分析の重要性により、すべての人がデータ分析の実行方法を知るようになります。 ただし、データ分析には時間がかかりすぎる場合があります。 だからこそ、ChatGPT を利用してデータ ファイルから完全なレポートを作成できるのです。
この記事では、CSV ファイルから完全な分析レポートを作成する XNUMX つの簡単な手順について説明します。 これら XNUMX つのステップには次のものが含まれます。
ステップ 1: CSV ファイルをインポートする
ステップ 2: データの概要と前処理
ステップ 3: データ分析
ステップ 4: データの視覚化
ステップ 5: レポートの生成
前提条件として、この記事は読者が ChatGPT Plus に登録していることを前提としています。 それを念頭に置いて、始めましょう。
最初のステップは、分析してレポートを作成する CSV ファイルを準備することです。 このファイルは信頼できるソースから取得することができますが、この記事では次の Telecom Churn データセットを使用します。 Kaggle.
データが構造化され、整理されており、明確なヘッダーがあることを確認します。 分析したい特定のターゲットがある場合は、そのデータをファイルに含めることを忘れないでください。 この例では、チャーン列の分析を実行しようとします。
データの準備ができたら、それらを ChatGPT にアタッチし、モデルに作業を実行させます。
次のステップでは、CSV ファイルからデータの概要を取得し、前処理します。 データをアップロードするときに次のプロンプトを入力します。
Provide the data summary to this file and perform appropriate data processing for the dataset.上記のプロンプトでは次の結果が得られます。
データセットの概要は次のとおりです。
行の数: 3333
列の数: 11
列名:
チャーン
アカウントウィーク
契約更新
データプラン
データ使用量
CustServCalls
日分
デイコール
月額料金
超過料金
ローミングミンズ
データ型:
整数: Churn、AccountWeeks、ContractRenewal、DataPlan、CustServCalls、DayCalls
Float: DataUsage、DayMins、MonthlyCharge、OverageFee、RoamMins
欠損値: どの列にも欠損値はありません。
ChatGPT は明らかにデータをうまく読み取ることができ、指定されたデータセットを提供できました。 次の結果は、ChatGPT からのデータの前処理です。
データセットには欠損値がないため、データのクリーニングと前処理の主な焦点は次のとおりです。
- データ内の外れ値や異常をチェックします。
- 必要に応じて、特に連続した数値を含む列のデータを正規化または標準化します。
- 必要に応じて、カテゴリデータを分析に適した形式に変換します。
これらの手順を進めてみましょう。
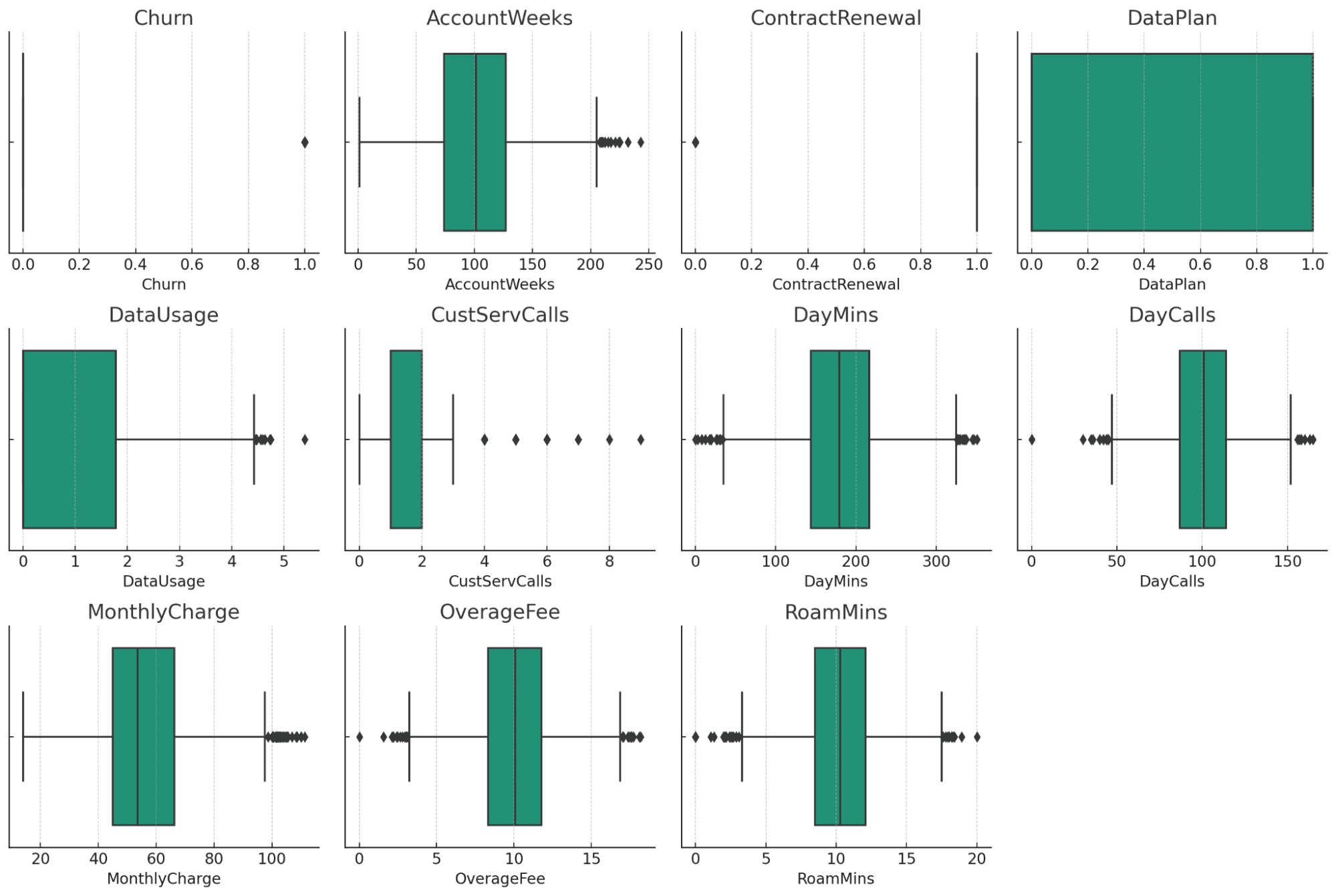
箱ひげ図は、データセットの各数値列の潜在的な外れ値の視覚的な概要を提供します。 以下にいくつかの所見を示します。
- AccountWeeks、CustServCalls、DayCalls: これらの列は、いくつかの外れ値を含むかなり正規分布を示しています。
- DataUsage、DayMins、MonthlyCharge、OverageFee、RoamMins: これらの列には外れ値も示されていますが、データの性質を考慮すると妥当な範囲内であると思われます。
- チャーン、契約更新、データプラン: これらの列はカテゴリ/バイナリ データであるため、従来の外れ値は表示されません。
この情報を考慮すると、データ クリーニングと前処理の次のステップには次のものが含まれる可能性があります。
- 外れ値の処理: お客様の特定の分析ニーズとドメイン知識に基づいて、外れ値を削除するか、制限するか、その他の方法で処理するかを決定できます。
- データ変換: 必要に応じて、特にデータの規模に敏感なアルゴリズムを使用する予定の場合、DayMins、MonthlyCharge などの列を正規化または標準化できます。
- カテゴリデータのエンコーディング: 変換が必要な場合は、カテゴリデータを分析に適した形式に変換します。
ChatGPT にデータのクリーニングと前処理の追加手順を実行させることも、そのままにすることもできます。 この例では、次のステップに進みます。
次に、ChatGPT を使用してデータ分析を実行します。 データ分析は、何を達成したいかによって異なります。 私たちの場合は、Churn POV からデータ分析を実行したいと考えています。
上記のケースでは、次のプロンプトを使用して ChatGPT でデータ分析を実行します。
Please perform the data analysis based on the data above with respect to the churn data.
データ分析は次の結果で確認できます。
チャーン データに関するデータ分析を実行するには、さまざまな要因が顧客チャーンにどのように関係するかを理解することに焦点を当てます。 チャーンは 0 値変数 (チャーンなしの場合は 1、チャーンありの場合は XNUMX) であり、通常、分類方法を通じて、また他の変数との関係を調べることによって分析されます。 計画は次のとおりです。
- 相関分析: まず、各数値特徴がチャーンとどのように相関するかを見ていきます。 これにより、どの要因がチャーンとより密接に関係しているかを最初に理解できます。
- 統計テスト: ContractRenewal や DataPlan などのカテゴリ変数の場合、統計テストを使用して、さまざまなカテゴリ間で解約率に大きな違いがあるかどうかを確認できます。
- 視覚的分析: これらの関係をさらに調査するために、いくつかの視覚化を作成します。 これには、さまざまなグループ間での解約率の比較や、解約に対する主要な変数のプロットが含まれます。
- 概要統計: 平均や分布に顕著な違いがあるかどうかを確認するために、チャーン ステータスに基づいてさまざまなグループの概要統計を提供します。
相関分析から始めて、次のステップに進みましょう。
チャーンとの相関分析
さまざまな変数とチャーンとの相関関係は次のとおりです (最も強い負の相関から最も強い正の相関の順)。
負の相関:
- ContractRenewal: 最も強い負の相関。 契約を更新しない顧客は解約する可能性が高いことを示します。
- データプラン: データプランを持たない顧客は、解約する可能性がわずかに高くなります。
- DataUsage: データ使用量が増えると、チャーンの可能性がわずかに減少します。
正の相関:
- AccountWeeks、DayCalls: 非常に弱い正の相関があり、チャーンへの影響が最小限であることを示唆しています。
- RoamMins: ローミング時間を増やすと、チャーンの可能性がわずかに増加します。
- MonthlyCharge: 月額料金が増加すると、解約率がわずかに高くなります。
- 超過料金: 超過料金が高くなると、解約率の増加と適度な相関関係があります。
- DayMins: XNUMX 日の分が長いほど、チャーンの増加と適度に相関しています。
- CustServCalls: 強い正の相関。 顧客サービスへの問い合わせが増えると、解約率も高くなります。
これらの相関関係に基づくと、契約更新、顧客サービスへの電話、毎日の通話時間、超過料金などの要素が解約とより密接に関係しているようです。 特にContractRenewalやDataPlanなどのカテゴリ変数については、視覚的な分析と統計テストを通じてこれらの要因をさらに調査できます。
視覚的分析
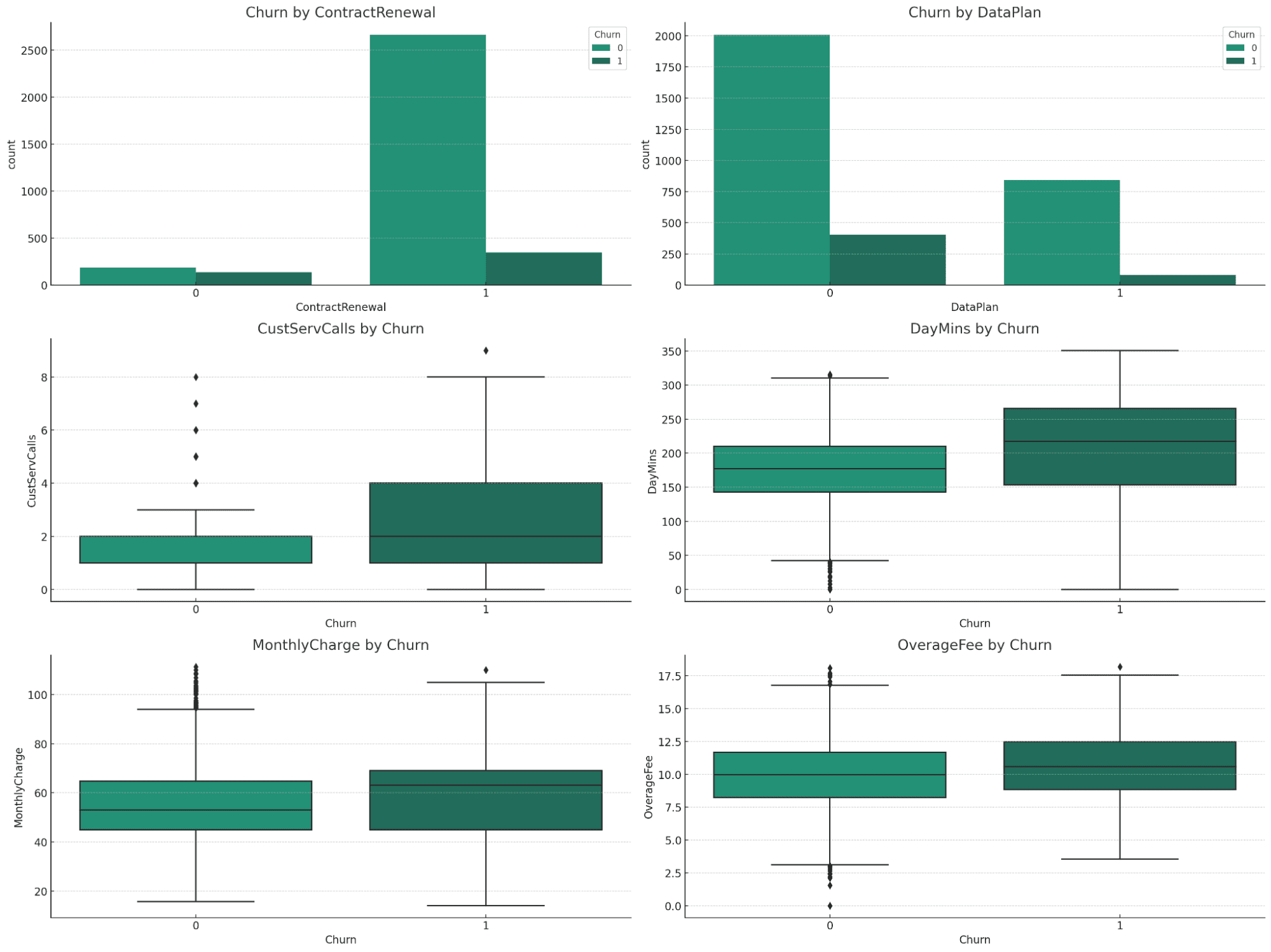
視覚化により、さまざまな変数とチャーンの関係について貴重な洞察が得られます。
ContractRenewal と DataPlan によるチャーン:
- ContractRenewal: 解約率の大きな違いは明らかです。 契約を更新しなかった顧客の解約率は高くなります。
- データプラン: 顧客がデータ プランを持っているかどうかに基づいて解約率に顕著な違いがあり、データ プランを持っていない顧客の解約率が高くなります。
チャーン別の数値変数 (CustServCalls、DayMins、MonthlyCharge、OverageFee):
- CustServCalls: カスタマー サービスへの通話回数が多い顧客ほど、解約が多くなる傾向があります。
- DayMins: XNUMX 日の分が長いほど、チャーンの可能性が高くなります。
- MonthlyCharge: 月額料金が高いほど、解約率が高くなります。
- 超過料金: 超過料金が高くなると、解約率も増加します。
分析からの結論
- 契約更新ステータスとデータ プランの有無は、顧客離れの重要な要因です。
- 使用量 (XNUMX 日あたりの分数) と料金 (月額料金および超過料金) が高いと、解約率が高くなります。
- カスタマー サービスへの通話数が多いことは、潜在的な顧客離れを示す強力な指標です。
次のステップ
これらの洞察に基づいて、顧客サービスの改善、価格設定戦略の見直し、契約更新やデータ プランのサブスクリプションに対するインセンティブの提供など、顧客離れを減らすための的を絞った戦略を策定できます。
XNUMX つのプロンプトで、ChatGPT がどれほど完全なデータ分析を提供し、データから洞察を導き出すことができるかを確認できます。 分析の目的を微調整して、そこから始めることができます。
データの視覚化は、データ分析と全体的なレポートを改善するための支援アクティビティです。 視覚化することで、データを理解するためのより包括的なレポートを作成できます。
次のプロンプトを使用すると、ChatGPT でデータの視覚化を実行できます。
Please perform data visualization from the data analysis to explain the data better.データ分析結果の理解を深めるために、顧客離れに関連する主要な調査結果を明確に示す一連の視覚化を作成します。 これらの視覚化には次のものが含まれます。
- カテゴリ変数の棒グラフ:
- 契約更新がある顧客とない顧客の解約率を比較します。
- データ プランがある顧客とない顧客の解約率を比較します。
- 主要な数値変数の箱ひげ図:
- カスタマーサービスへの電話とチャーン。
- 毎日の分とチャーン。
- 月額料金とチャーン。
- 超過料金とチャーン。
- 相関関係のヒートマップ:
すべての変数とチャーンとの相関関係を視覚化します。
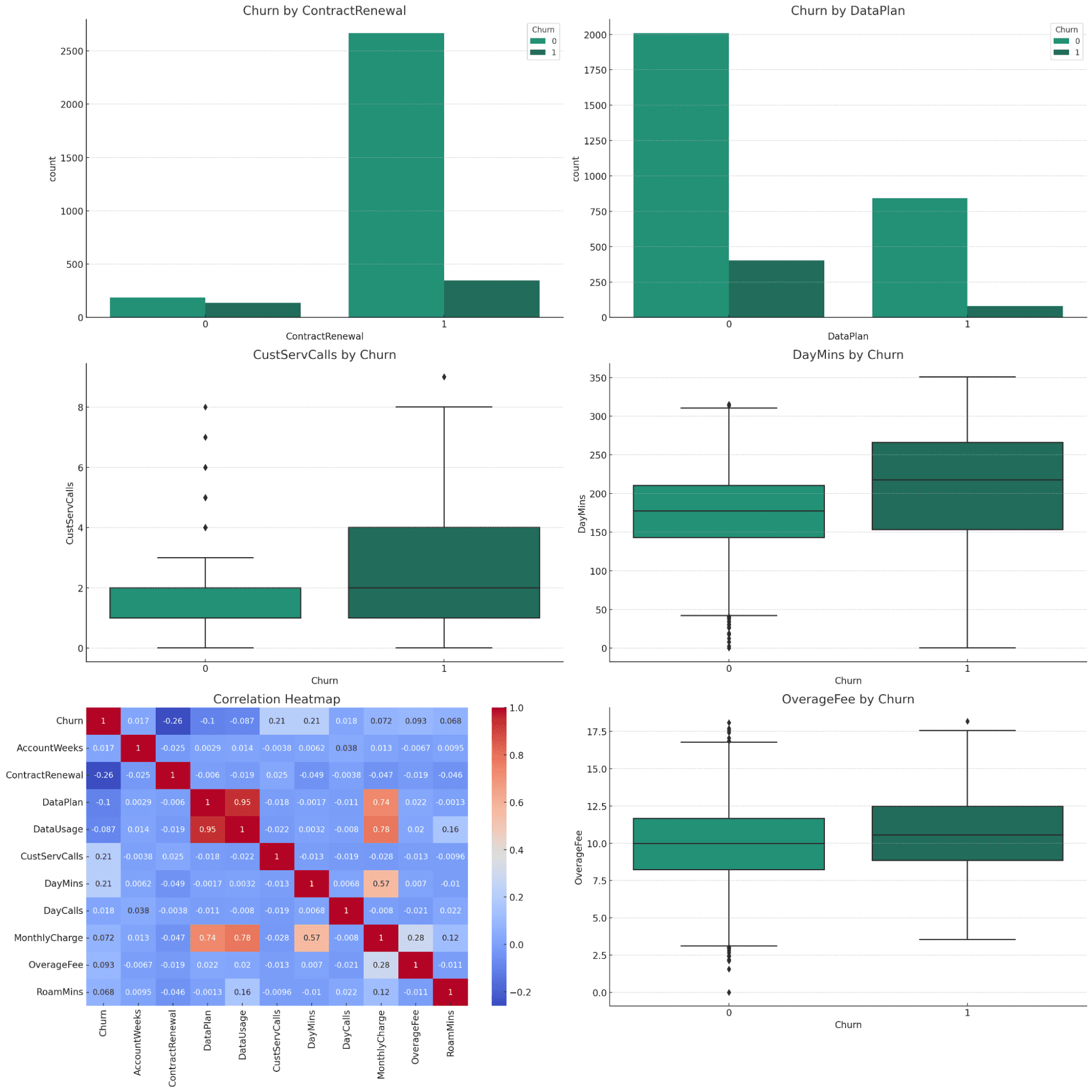
視覚化では、データセット全体をカプセル化するすべての重要なプロットが表示されます。 各プロットについてのより詳細な説明を求めることができますので、個別に試してみることができます。
最後のステップでは、前のステップに基づいてレポートを生成します。 残念ながら、ChatGPT はデータ分析からすべての説明と洞察を取得できない可能性がありますが、それでもレポートの簡易バージョンを取得できます。
次のプロンプトを使用して、以前の分析に基づいて PDF レポートを生成します。
Please provide me with the pdf report from the first step to the last step.以前の分析がカバーされた PDF リンク結果を取得します。 結果が不十分であると感じた場合、または変更したい点がある場合は、手順を繰り返してみてください。
データ分析は、今の時代で最も必要とされるスキルの XNUMX つであるため、誰もが知っておくべきアクティビティです。 ただし、データ分析の実行方法を学ぶには長い時間がかかる場合があります。 ChatGPT を使用すると、そのようなアクティビティ時間を最小限に抑えることができます。
この記事では、CSV ファイルから完全な分析レポートを 5 つのステップで生成する方法について説明しました。 ChatGPT は、ファイルのインポートからレポートの作成まで、エンドツーエンドのデータ分析アクティビティをユーザーに提供します。
コーネリアス・ユダ・ウィジャヤ は、データ サイエンス アシスタント マネージャー兼データ ライターです。 Allianz Indonesia でフルタイムで働いている間、彼はソーシャル メディアやライティング メディアを通じて Python とデータのヒントを共有するのが大好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/from-csv-to-complete-analytical-report-with-chatgpt-in-5-simple-steps?utm_source=rss&utm_medium=rss&utm_campaign=from-csv-to-complete-analytical-report-with-chatgpt-in-5-simple-steps
- :持っている
- :は
- :not
- $UP
- 1
- 7
- a
- 能力
- できる
- 私たちについて
- 上記の.
- 達成する
- 越えて
- アクティビティ
- NEW
- に対して
- 目指して
- アルゴリズム
- すべて
- アリアンツ
- また
- an
- 分析
- 分析的
- 分析します
- 分析
- および
- どれか
- 適切な
- です
- 記事
- AS
- 頼む
- アシスタント
- 関連する
- と仮定する
- At
- アタッチ
- バー
- ベース
- BE
- さ
- より良いです
- の間に
- ボックス
- ビジネス
- ビジネス
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- コール
- 缶
- キャップ
- キャプチャー
- 場合
- カテゴリ
- 一定
- 変化する
- 課金
- AI言語モデルを活用してコードのデバッグからデータの異常検出まで、
- 点検
- 分類
- クリーニング
- クリア
- はっきりと
- 密接に
- コラム
- コラム
- 来ます
- 比較
- 競争力のある
- コンプリート
- 包括的な
- プロフェッショナルな方法で
- 考えると
- 続ける
- 連続的な
- 縮小することはできません。
- 契約
- 変換
- 変換
- 相関
- 相関
- 相関関係
- 可能性
- カバー
- 作ります
- 電流プローブ
- 顧客
- 顧客サービス
- Customers
- daily
- データ
- データ分析
- データ処理
- データサイエンス
- データの可視化
- データ駆動型の
- 中
- 決めます
- 決定
- 減少
- によっては
- 説明
- 詳細な
- 発展した
- DID
- 違い
- の違い
- 異なります
- 議論する
- ディストリビューション
- ディストリビューション
- do
- ドメイン
- ドン
- ドント
- ドライブ
- 各
- enable
- エンコーディング
- 端から端まで
- 高めます
- 時代
- 特に
- 等
- EVER
- あらゆる
- 誰も
- 明らか
- 調べる
- 例
- 実行します
- 説明する
- 探る
- 要因
- かなり
- 特徴
- 感じます
- 費用
- 少数の
- File
- 調査結果
- 名
- 五
- フォーカス
- フォロー中
- 次
- 形式でアーカイブしたプロジェクトを保存します.
- から
- さらに
- 生成する
- 取得する
- 与える
- 与えられた
- 与える
- 大きい
- グループの
- ハンドル
- ハンドリング
- 持ってる
- 持って
- he
- こちら
- ハイ
- より高い
- 認定条件
- How To
- しかしながら
- HTTPS
- i
- if
- 影響
- 重要性
- 重要
- インポート
- 改善します
- 改善
- in
- インセンティブ
- include
- 含ま
- 増える
- 増加した
- 単独で
- を示し
- インジケータ
- 個人
- インドネシア
- 情報
- 初期
- 洞察力
- 洞察
- に
- IT
- JPG
- KDナゲット
- キー
- 知っている
- 知っている
- 知識
- 姓
- 学習
- う
- ような
- 尤度
- 可能性が高い
- LINK
- ll
- 長い
- 長い時間
- 見て
- で
- メイン
- make
- マネージャー
- 問題
- me
- 手段
- メディア
- メソッド
- かもしれない
- マインド
- 最小限の
- 最小限に抑えます
- 分
- 行方不明
- monthly
- 他には?
- 最も
- ずっと
- 名
- 自然
- 必要
- 必要とされる
- ニーズ
- 負
- 次の
- いいえ
- 通常の
- 数
- 番号
- 観測
- of
- 提供
- 提供すること
- on
- ONE
- or
- 整理
- その他
- さもないと
- 私たちの
- 全体
- 概要
- 実行する
- 実行
- 計画
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- さらに
- 正の
- 潜在的な
- 準備
- プレゼンス
- 前
- 価格設定
- 進む
- 処理
- 作成
- 提供します
- は、大阪で
- Python
- 範囲
- レート
- 価格表
- 読む
- リーダー
- 準備
- 合理的な
- 減らします
- 関連する
- 関係
- の関係
- 頼る
- 削除します
- レポート
- レポート
- の提出が必要です
- 尊重
- 結果
- 結果
- s
- 規模
- 科学
- 思われる
- と思われる
- 見て
- 敏感な
- シリーズ
- サービス
- シェアする
- すべき
- 表示する
- 表示
- 重要
- 簡単な拡張で
- スキル
- 社会
- ソーシャルメディア
- 一部
- 時々
- ソース
- 特定の
- 標準化
- start
- 開始
- 統計的
- 統計
- Status:
- 滞在
- 手順
- ステップ
- まだ
- 作戦
- 強い
- 最強
- 構造化された
- サブスクリプション
- そのような
- 適当
- 概要
- 支持する
- T
- 取る
- 取り
- ターゲット
- 対象となります
- 電気通信
- 条件
- テスト
- より
- それ
- アプリ環境に合わせて
- それら
- その後
- そこ。
- ボーマン
- 彼ら
- 物事
- この
- それらの
- 介して
- 時間
- ヒント
- 〜へ
- あまりに
- 伝統的な
- 変換
- 信頼できる
- 試します
- 微調整
- 一般的に
- わかる
- 理解する
- 残念ながら
- us
- 使用法
- つかいます
- users
- 貴重な
- 価値観
- 変数
- バージョン
- 非常に
- 、
- ビジュアル
- 可視化
- 視覚化する
- vs
- 欲しいです
- ました
- we
- WELL
- この試験は
- かどうか
- which
- while
- 誰
- 全体
- なぜ
- 意志
- 以内
- 無し
- 仕事
- ワーキング
- でしょう
- 作家
- 書き込み
- 貴社
- あなたの
- ゼファーネット







