
2023 年 9 月 20 日
基本モデル (FM) 新しい時代の始まりを告げています 機械学習(ML) および 人工知能(AI)これにより、幅広い下流タスクに適応し、さまざまなアプリケーションに合わせて微調整できる AI の開発が迅速化されます。
作業が実行される場所でのデータ処理の重要性が高まる中、企業エッジで AI モデルを提供することで、データ主権とプライバシーの要件を遵守しながら、ほぼリアルタイムの予測が可能になります。 を組み合わせることで、 IBMワトソンx エッジ コンピューティングを備えた FM 向けのデータおよび AI プラットフォーム機能を利用すると、企業は運用エッジで FM の微調整と推論のための AI ワークロードを実行できます。 これにより、企業は AI 導入をエッジで拡張できるようになり、導入にかかる時間とコストが削減され、応答時間が短縮されます。
エッジ コンピューティングに関するこのブログ投稿シリーズのすべての記事を必ずチェックしてください。
基本モデルとは何ですか?
基礎モデル (FM) は、ラベルのない広範なデータセットで大規模にトレーニングされ、最先端の人工知能 (AI) アプリケーションを推進しています。 これらは、幅広い下流タスクに適応でき、さまざまなアプリケーションに合わせて微調整できます。 単一ドメインで特定のタスクを実行する最新の AI モデルは、FM がより一般的に学習し、ドメインや問題を超えて機能するため、FM に取って代わられています。 名前が示すように、FM は AI モデルの多くのアプリケーションの基盤となることができます。
FM は、企業による AI 導入の拡大を妨げている XNUMX つの重要な課題に対処します。 まず、企業はラベルのない大量のデータを生成しますが、AI モデルのトレーニング用にラベルが付けられているのはその一部だけです。 第 XNUMX に、このラベル付けと注釈のタスクは非常に人力が必要であり、多くの場合、対象分野の専門家 (SME) の数百時間の時間を必要とします。 そのため、複数の中小企業やデータ専門家が必要となるため、ユースケース全体に拡張するには法外なコストがかかります。 FM は、大量のラベルなしデータを取り込み、モデルのトレーニングに自己教師ありの手法を使用することで、これらのボトルネックを解消し、企業全体に AI を大規模に導入する道を開きました。 あらゆるビジネスに存在するこれらの大量のデータは、洞察を引き出すために解き放たれるのを待っています。
大規模言語モデルとは何ですか?
大規模言語モデル (LLM) は、次の層で構成される基礎モデル (FM) のクラスです。 ニューラルネットワーク これらの大量のラベルなしデータに基づいてトレーニングされたものです。 自己教師あり学習アルゴリズムを使用して、さまざまな処理を実行します。 自然言語処理(NLP) 人間が言語を使用する方法と同様の方法でタスクを実行します (図 1 を参照)。
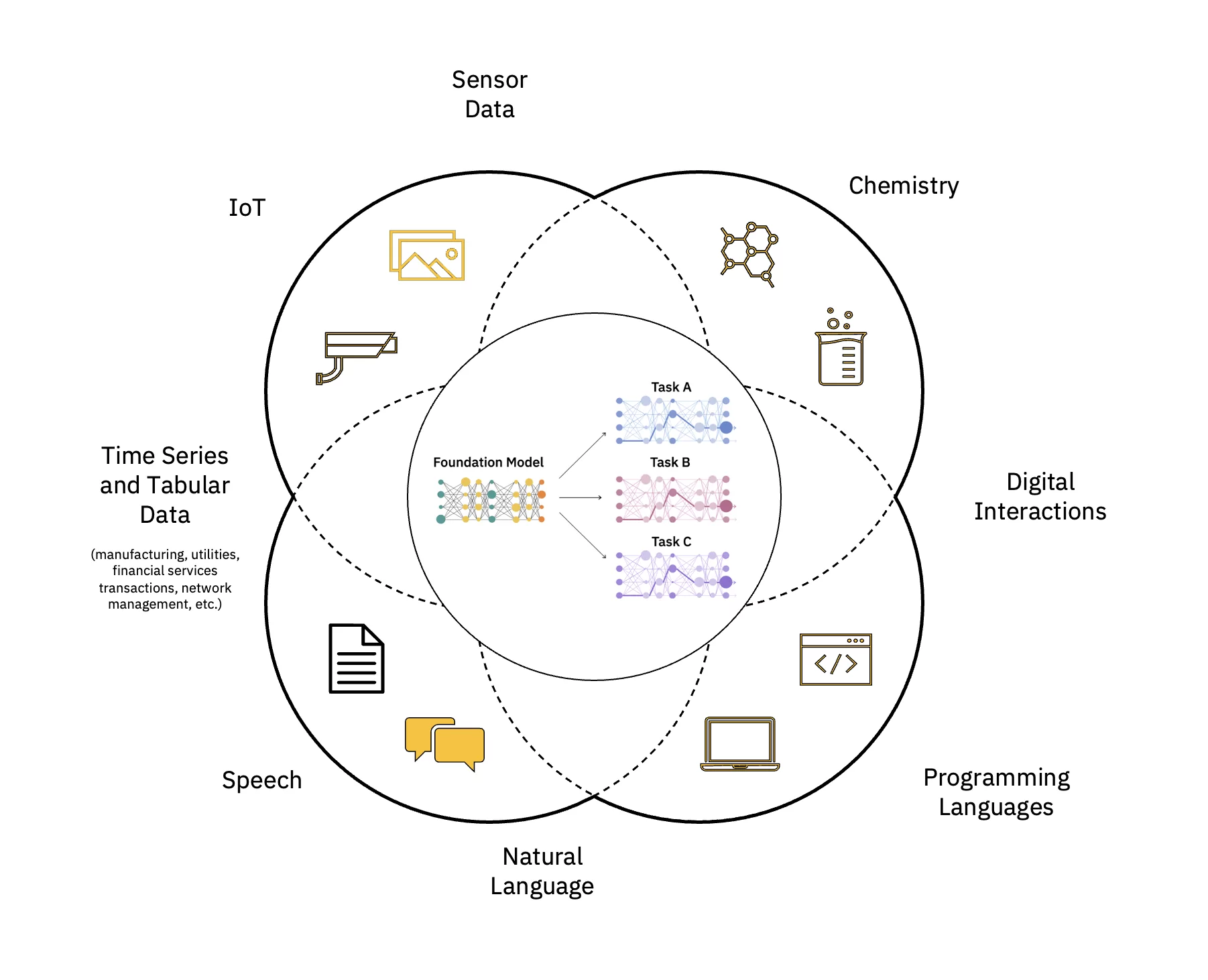
AI の影響を拡大し加速する
基本モデル (FM) を構築してデプロイするには、いくつかの手順があります。 これらには、データの取り込み、データの選択、データの前処理、FM の事前トレーニング、XNUMX つ以上の下流タスクへのモデルの調整、推論の提供、データと AI のモデルのガバナンスとライフサイクル管理が含まれます。これらはすべて次のように説明できます。 FMOps.
これらすべてを支援するために、IBM は、これらの FM の力を活用するために必要なツールと機能を企業に提供しています。 IBMワトソンxは、企業全体に AI の影響を倍増させるように設計された、エンタープライズ対応の AI およびデータ プラットフォームです。 IBM watsonx は以下で構成されます。
- IBM ワトソンx.ai 新しいものをもたらす generative AI FM と従来の機械学習 (ML) を活用した機能を、AI ライフサイクル全体にわたる強力なスタジオに統合します。
- IBM watsonx.data は、オープン レイクハウス アーキテクチャ上に構築された目的に適したデータ ストアで、場所を問わず、すべてのデータの AI ワークロードを拡張します。
- IBM watsonx.governance は、責任があり、透明性があり、説明可能な AI ワークフローを可能にするために構築された、エンドツーエンドの自動化された AI ライフサイクル ガバナンス ツールキットです。
もう XNUMX つの重要なベクトルは、産業拠点、製造現場、小売店、通信会社のエッジ サイトなど、エンタープライズ エッジでのコンピューティングの重要性が高まっていることです。より具体的には、エンタープライズ エッジでの AI により、作業が実行されているデータの処理が可能になります。ほぼリアルタイムの分析。 エンタープライズ エッジは、膨大な量の企業データが生成され、AI が貴重でタイムリーで実用的なビジネス インサイトを提供できる場所です。
AI モデルをエッジで提供することで、データ主権とプライバシーの要件を遵守しながら、ほぼリアルタイムの予測が可能になります。 これにより、検査データの取得、送信、変換、処理に伴う待ち時間が大幅に短縮されます。 エッジで作業することで、企業の機密データを保護し、応答時間を短縮してデータ転送コストを削減できます。
しかし、データ (異質性、ボリューム、規制) や制約のあるリソース (コンピューティング、ネットワーク接続、ストレージ、さらには IT スキル) 関連の課題の中で、エッジでの AI 導入のスケーリングは簡単な作業ではありません。 これらは大きく XNUMX つのカテゴリに分類できます。
- 導入にかかる時間とコスト: 各展開は、展開前にインストール、構成、テストする必要があるハードウェアとソフトウェアのいくつかの層で構成されます。 現在、サービス専門家による設置には最大 XNUMX ~ XNUMX 週間かかる場合があります。 各場所で、 これにより、企業が組織全体に展開を迅速かつコスト効率よくスケールアップできる方法が大幅に制限されます。
- 2 日目の管理: 導入されたエッジの数と各導入の地理的位置により、これらの導入を監視、保守、更新するために各拠点でローカル IT サポートを提供すると、法外な費用がかかることがよくあります。
エッジAIの導入
IBM は、統合されたハードウェア/ソフトウェア (HW/SW) アプライアンス モデルをエッジ AI 導入に導入することで、これらの課題に対処するエッジ アーキテクチャを開発しました。 これは、AI 導入のスケーラビリティを支援するいくつかの重要なパラダイムで構成されています。
- ポリシーベースの完全なソフトウェア スタックのゼロタッチ プロビジョニング。
- エッジシステムの健全性を継続的に監視
- ソフトウェア、セキュリティ、構成の更新を管理し、多数のエッジ ロケーションにプッシュする機能。すべて中央のクラウドベースのロケーションから Day 2 管理を実現します。
分散ハブアンドスポーク アーキテクチャを利用して、エンタープライズ AI 導入をエッジで拡張できます。中央のクラウドまたはエンタープライズ データ センターがハブとして機能し、エッジインボックス アプライアンスがエッジ ロケーションのスポークとして機能します。. このハブ アンド スポーク モデルは、ハイブリッド クラウドとエッジ環境にまたがり、FM 運用に必要なリソースを最適に利用するために必要なバランスを最もよく示しています (図 2 を参照)。
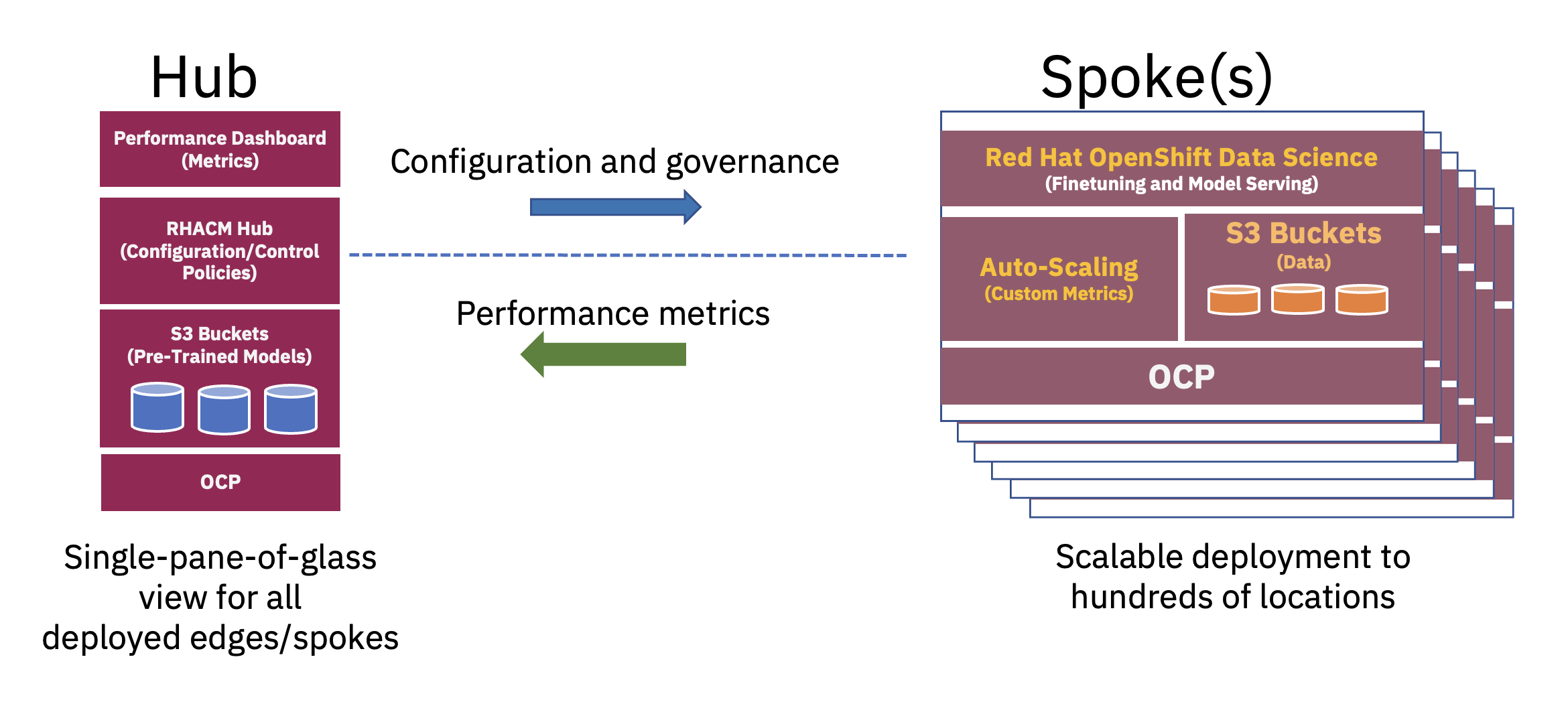
これらの基本的な大規模言語モデル (LLM) や、ラベルなしの広大なデータセットに対する自己教師あり手法を使用した他のタイプの基礎モデルの事前トレーニングには、多くの場合、大量のコンピューティング (GPU) リソースが必要であり、ハブで実行するのが最適です。 事実上無制限のコンピューティング リソースとクラウドに保存される大規模なデータの山により、大規模なパラメーター モデルの事前トレーニングと、これらの基本基盤モデルの精度の継続的な向上が可能になります。
一方で、数十から数百のラベル付きデータ サンプルと推論処理のみを必要とするダウンストリーム タスク向けのこれらのベース FM の調整は、エンタープライズ エッジの数個の GPU だけで実現できます。 これにより、機密ラベル付きデータ (または企業の最高級データ) を企業の運用環境内に安全に保管できると同時に、データ転送コストも削減できます。
データ サイエンティストは、アプリケーションをエッジにデプロイするためのフルスタック アプローチを使用して、モデルの微調整、テスト、デプロイを実行できます。 これは、新しい AI モデルをエンド ユーザーに提供するための開発ライフサイクルを短縮しながら、単一の環境で実現できます。 Red Hat OpenShift Data Science (RHODS) や最近発表された Red Hat OpenShift AI などのプラットフォームは、本番環境に対応した AI モデルを迅速に開発およびデプロイするためのツールを提供します。 分散クラウド およびエッジ環境。
最後に、エンタープライズ エッジで微調整された AI モデルを提供することで、データの取得、送信、変換、処理に伴う遅延が大幅に削減されます。 クラウドでの事前トレーニングをエッジでの微調整や推論から切り離すことで、推論タスクに関連する所要時間とデータ移動コストが削減され、全体の運用コストが削減されます (図 3 を参照)。
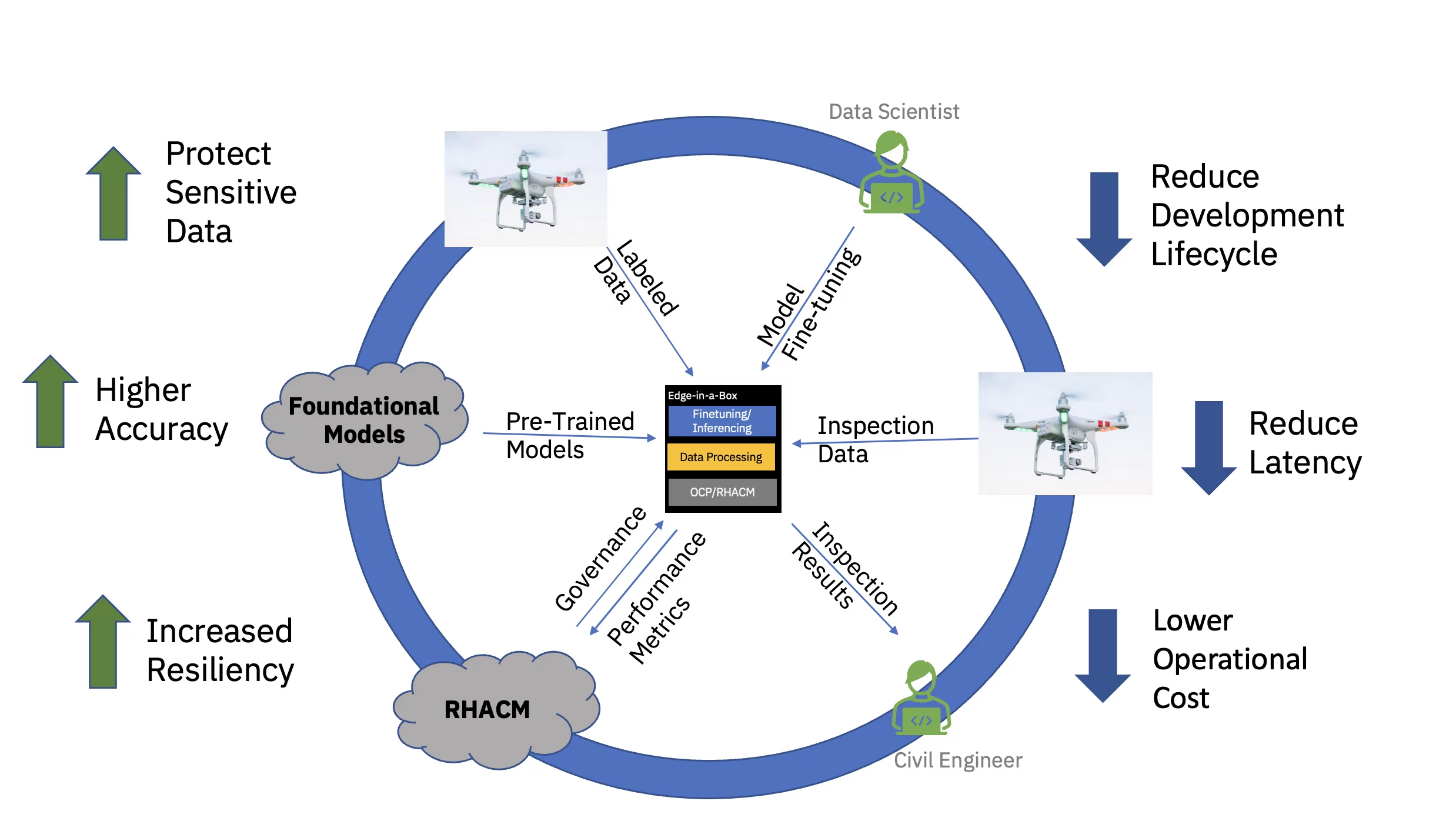
この価値提案をエンドツーエンドで実証するために、民間インフラストラクチャ向けの模範的なビジョン トランスフォーマー ベースの基盤モデル (業界固有のパブリックおよびカスタム データセットを使用して事前トレーニング済み) が微調整され、XNUMX ノード エッジでの推論のためにデプロイされました。 (話し)クラスター。 ソフトウェア スタックには、Red Hat OpenShift Container Platform と Red Hat OpenShift Data Science が含まれていました。 このエッジ クラスターは、クラウドで実行されている Red Hat Advanced Cluster Management for Kubernetes (RHACM) ハブのインスタンスにも接続されました。
ゼロタッチプロビジョニング
ポリシーベースのゼロタッチプロビジョニングは、ポリシーと配置タグを介して Red Hat Advanced Cluster Management for Kubernetes (RHACM) で実行され、特定のエッジクラスターをソフトウェアコンポーネントと設定のセットにバインドします。 これらのソフトウェア コンポーネントは、フルスタックに拡張され、コンピューティング、ストレージ、ネットワーク、AI ワークロードをカバーしており、さまざまな OpenShift オペレーター、必要なアプリケーション サービスのプロビジョニング、および S3 バケット (ストレージ) を使用してインストールされました。
事前トレーニングされた土木インフラの基礎モデル (FM) は、ラベル付きデータを使用して Red Hat OpenShift Data Science (RHODS) 内の Jupyter Notebook を介して微調整され、コンクリート橋で見つかった XNUMX 種類の欠陥を分類しました。 この微調整された FM の推論サービスも、Triton サーバーを使用して実証されました。 さらに、このエッジ システムの健全性の監視は、Prometheus を介してハードウェアおよびソフトウェア コンポーネントから可観測性メトリクスをクラウド内の中央の RHACM ダッシュボードに集約することによって可能になりました。 民間インフラ企業は、これらの FM をエッジ ロケーションに導入し、ドローン画像を使用してほぼリアルタイムで欠陥を検出できます。これにより、洞察までの時間が短縮され、クラウドとの間で大量の高解像度データを移動するコストが削減されます。
まとめ
結合 IBMワトソンx Edge-in-a-Box アプライアンスを使用した基盤モデル (FM) のデータおよび AI プラットフォーム機能により、企業は運用エッジで FM の微調整と推論のための AI ワークロードを実行できます。 このアプライアンスは、複雑なユースケースをすぐに処理でき、集中管理、自動化、セルフサービスのためのハブアンドスポークフレームワークを構築します。 Edge FM の導入は、再現性の高い成功、高い復元力、セキュリティを実現し、数週間から数時間に短縮できます。
エッジ コンピューティングに関するこのブログ投稿シリーズのすべての記事を必ずチェックしてください。
クラウドの詳細




- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.ibm.com/blog/foundational-models-at-the-edge/
- :持っている
- :は
- :not
- :どこ
- $UP
- 08
- 1
- 10
- 13
- 視聴者の38%が
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- 私たちについて
- 加速する
- アクセス
- 熟達した
- 精度
- 買収
- 越えて
- 使徒行伝
- 適合しました
- さらに
- 住所
- アドレス
- 養子縁組
- 高度な
- 進歩
- 広告運用
- AI
- AIの採用
- AIモデル
- AIプラットフォーム
- 援助
- アルゴリズム
- すべて
- 許す
- ことができます
- また
- の中で
- 量
- 金額
- amp
- an
- 分析
- 分析論
- および
- 発表の
- どれか
- どこにでも
- 申し込み
- アプローチ
- 建築
- です
- 配列
- 記事
- 人工の
- 人工知能
- 人工知能(AI)
- AS
- 関連する
- At
- 著者
- 自動化
- オートメーション
- 利用できます
- 大通り
- バック
- 銀行
- 銀行
- ベース
- BE
- なぜなら
- になる
- になる
- き
- 開始
- さ
- 信じる
- BEST
- バインド
- ブログ
- ブログの投稿
- ブログ
- 両言語で
- ボックス
- ブリッジ
- 持参
- もたらす
- 広い
- 広く
- 建物
- 構築します
- 内蔵
- ビジネス
- by
- 缶
- 機能
- 資本
- キャプチャ
- カーボン
- カード
- カード
- 例
- CAT
- カテゴリ
- 原因となる
- センター
- 中央の
- 中央銀行
- 中央銀行デジタル通貨
- 集中型の
- チェーン
- 課題
- 変化する
- 変化
- チェック
- 選択肢
- 円
- CIS
- 市民の
- class
- 分類します
- クリア
- クライアント
- 密接に
- クラウド
- クラスタ
- カラー
- カラフル
- 結合
- 競争力のある
- 複雑な
- 複雑さ
- コンプライアンス
- コンポーネント
- 計算
- コンピューティング
- 設定された
- 交流
- 接続性
- からなる
- コンテナ
- 続ける
- コントロール
- 費用
- コスト
- 可能性
- カバーする
- cryptocurrency
- CSS
- 通貨
- カスタム
- 顧客
- 顧客満足体験
- Customers
- ダッシュボード
- データ
- データセンター
- データサイエンス
- データサイエンティスト
- データセット
- 日付
- 専用の
- デフォルト
- 定義
- 配信する
- 実証します
- 実証
- 展開します
- 展開
- 展開する
- 展開
- 配備
- 記載された
- 説明
- 設計
- 開発する
- 発展した
- 開発
- デジタル
- デジタル通貨
- デジタル化
- 途絶
- 破壊的な
- 中断剤
- 配布
- 地区
- ドメイン
- ドメイン
- 行われ
- ドライブ
- 運転
- ドローン
- 各
- 簡単に
- エコシステム
- エッジ(Edge)
- エッジコンピューティング
- エレベート
- 高い
- enable
- 可能
- end
- 端から端まで
- エンジニア
- エンジニアリング
- 入力します
- Enterprise
- 企業
- 入ってきます
- 環境
- 環境
- 時代
- 特に
- 等
- エーテル(ETH)
- さらに
- イベント
- あらゆる
- 進化
- 調べる
- 例
- 実行します
- 存在する
- 出口
- 高価な
- 体験
- 専門家
- 説明可能なAI
- 説明
- 延伸
- 非常に
- 要因
- スピーディー
- 速いです
- 少数の
- フィールド
- フィギュア
- ファイナンシャル
- 金融機関
- 資金調達
- 名
- 床
- フォロー中
- フォント
- 最前線
- 発見
- Foundation
- 分数
- フレームワーク
- から
- フル
- フルスタック
- さらに
- 一般に
- 生成された
- ジェネレータ
- 地理的
- 地政学
- 与え
- グローバル
- グローバルな貿易
- ガバナンス
- GPU
- GPU
- グリッド
- ハンド
- ハンドル
- Hardware
- 持っています
- 持ってる
- 健康
- 高さ
- 助けます
- 助け
- ことができます
- 高精細度の
- より高い
- 非常に
- history
- host
- HOURS
- 認定条件
- How To
- しかしながら
- HTTPS
- ハブ
- 人間
- 何百
- ハイブリッド
- ハイブリッドクラウド
- IBM
- IBMクラウド
- ICO
- ICON
- 説明する
- 画像
- 影響
- 重要性
- 改善
- in
- include
- 含まれました
- の増加
- ますます
- index
- インダストリアル
- 産業
- 産業を変えます
- 業界固有
- インフレ
- 屈曲
- 変曲点
- 影響を受け
- インフラ関連事業
- イニシアチブ
- 革新的手法
- 革新的な
- 入力
- 洞察
- 機関
- 統合された
- インテリジェンス
- 本質的な
- 導入
- IT
- ITサポート
- 旅
- JPG
- ジャンプ
- ジュピターノート
- ただ
- 一つだけ
- 保管
- キー
- Kubernetes
- ラベリング
- 言語
- 大
- 主として
- レイテンシ
- 最新の
- 層
- 主要な
- LEARN
- 学習
- 活用します
- wifecycwe
- ような
- 限りない
- linuxの
- ローカル
- ローカル
- 場所
- 場所
- 長い
- 見て
- 機械
- 機械学習
- 製
- 維持する
- make
- 作る
- 管理します
- 管理
- 製造業
- 多くの
- マーキング
- 大規模な
- マスター
- 問題
- 最大幅
- メカニズム
- メソッド
- メトリック
- 分
- 最小化
- 分
- ML
- モバイル
- モデル
- モダン
- 近代化
- 近代化します
- モニター
- モニタリング
- 他には?
- 運動
- 移動する
- 名
- ナビゲーション
- 近く
- 必要
- 必要
- 必要とされる
- ニーズ
- ネットワーク
- 新作
- 次の
- NLP
- ノート
- 何も
- 今
- 数
- 多数の
- of
- 提供すること
- 頻繁に
- on
- ONE
- の
- 開いた
- 開かれた
- オペレーショナル
- 業務執行統括
- 演算子
- 最適化
- or
- 組織
- その他
- 私たちの
- でる
- 全体
- パッケージ
- ページ
- パラメーター
- 支払い
- 支払方法
- 支払い
- 実行する
- 実行
- PHP
- 配置
- プラットフォーム
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- プラグイン
- ポイント
- ポリシー
- 方針
- 位置
- 可能
- ポスト
- 投稿
- 潜在的な
- 電力
- 強力な
- 予測
- 事前の
- プライバシー
- プライベート
- 問題
- 処理
- 作り出す
- プロ
- 命題
- 提供します
- 公共
- プッシュ
- 範囲
- 急速に
- リーディング
- への
- 最近
- 記録
- 録音
- レッド
- レッドハット
- 減らします
- 電話代などの費用を削減
- 軽減
- 縮小
- 規制
- レギュレータ
- レギュレータ
- 関連する
- 削除済み
- 繰り返し可能
- 必要とする
- の提出が必要です
- 要件
- 必要条件
- 研究
- リソース
- 応答
- 責任
- 反応する
- 小売
- 上昇
- ロボット
- ラン
- ランニング
- 安全に
- 同じ
- スケーラビリティ
- 規模
- スケールai
- スケーリング
- 科学
- 科学者
- 画面
- スクリプト
- 二番
- しっかりと
- セキュリティ
- 見ること
- 選択
- セルフサービス
- 敏感な
- SEO
- 9月
- シリーズ
- サービス
- サービス
- サービング
- セッション
- セッション
- セッションに
- いくつかの
- シェアする
- 表示する
- 重要
- 著しく
- 同様の
- から
- シンガポール
- 単一環境
- ウェブサイト
- サイト
- SIX
- スキル
- 小さい
- EMSの
- 中小企業
- ソフトウェア
- ソフトウェアコンポーネント
- 溶液
- 主権
- スペース
- 緊張
- 特定の
- 特に
- スポンサー
- スタック
- start
- 最先端の
- 滞在
- ステップ
- ストレージ利用料
- 店舗
- 保存され
- 店舗
- ストーム
- 研究
- テーマ
- 成功
- そのような
- 提案する
- 供給
- サプライチェーン
- サポート
- 確か
- 取る
- 撮影
- 仕事
- タスク
- テクニック
- テクノロジー
- 電話会社
- テメノス
- 十
- テラフォーム
- テスト
- テスト
- それ
- アプリ環境に合わせて
- テーマ
- そこ。
- ボーマン
- 彼ら
- この
- 介して
- 時間
- タイムリーな
- <font style="vertical-align: inherit;">回数</font>
- 役職
- 〜へ
- 今日
- 一緒に
- ツールキット
- 豊富なツール群
- top
- トレード
- 伝統的な
- トレーニング
- 訓練された
- トレーニング
- 転送
- 最適化の適用
- 変換
- 変換
- トランスペアレント
- トリトン
- さえずり
- 2
- type
- 解き放たれました
- アップデイト
- 更新版
- URL
- us
- つかいます
- 中古
- users
- 活用する
- 利用された
- 貴重な
- 値
- 価値命題
- 多様
- さまざまな
- 広大な
- 、
- 詳しく見る
- 事実上
- ボリューム
- ボリューム
- W
- 待っています
- 財布
- ました
- ウェーブ
- 仕方..
- 方法
- we
- 週間
- ウィークス
- この試験は
- 何ですか
- いつ
- which
- while
- 誰
- なぜ
- ワイド
- 広い範囲
- 以内
- 女性
- WordPress
- 仕事
- ワークフロー
- ワーキング
- でしょう
- 書かれた
- あなたの
- ゼファーネット











