
著者からの画像 | Bing イメージ クリエーター
ドリー2.0 は、人間が生成したデータセットに基づいて微調整された、オープンソースの命令従う大規模言語モデル (LLM) です。 研究目的と商業目的の両方に使用できます。
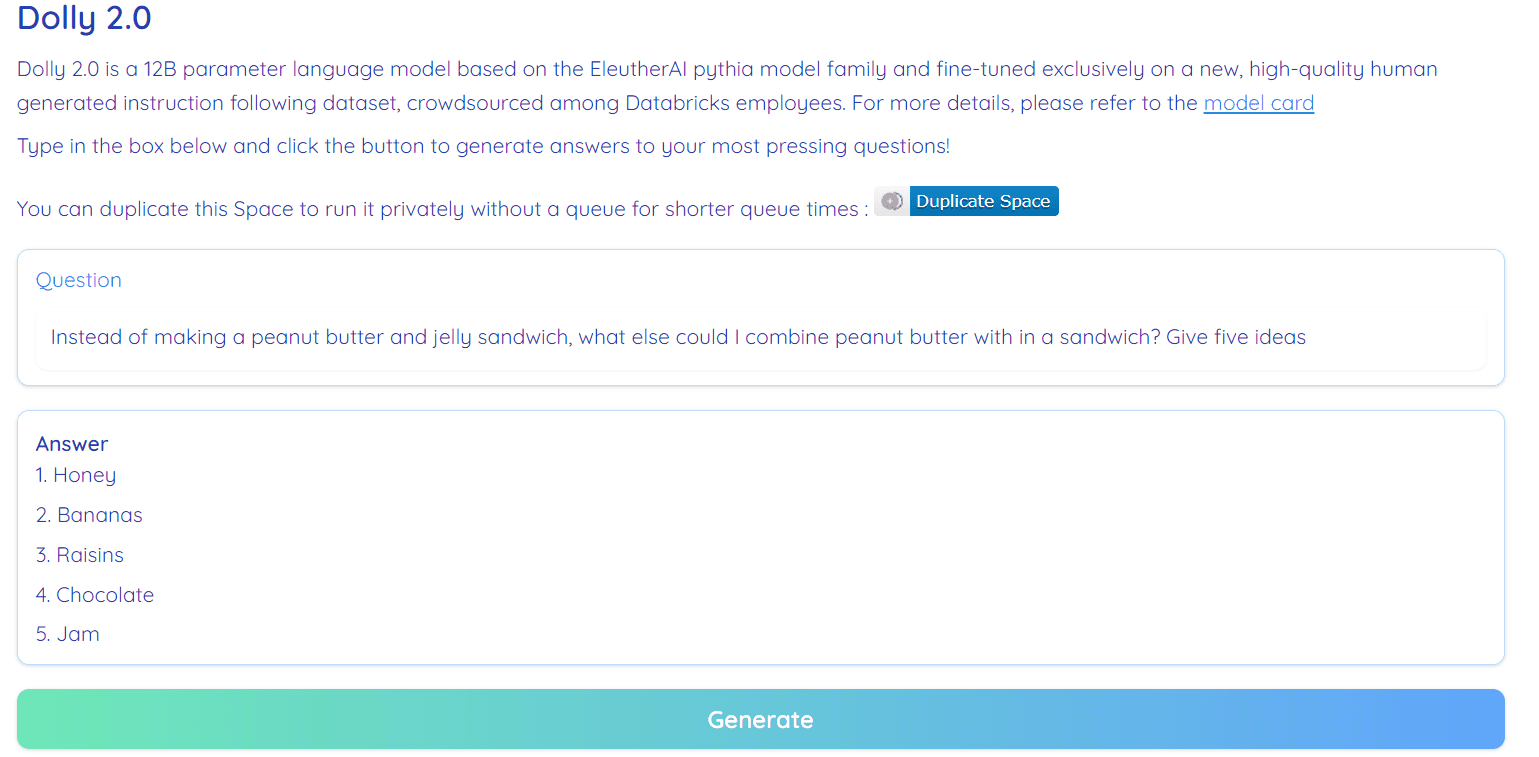
Image from
ハグフェイススペース by RamAnanth1
以前、Databricks チームは ドリー1.0, LLM は、ChatGPT のような命令追従能力を示し、トレーニング費用は 30 ドル未満です。 これは、制限付きライセンス (研究のみ) の下にある Stanford Alpaca チームのデータセットを使用していました。
Dolly 2.0 は、12B パラメータ言語モデルを微調整することでこの問題を解決しました (ピティア) は、Datbricks 従業員によってラベル付けされた、次のデータセット内の人間が生成した高品質の命令についてです。 モデルとデータセットは両方とも商用利用できます。
Dolly 1.0 は、OpenAI API を使用して作成された Stanford Alpaca データセットでトレーニングされました。 データセットには ChatGPT からの出力が含まれており、OpenAI と競合するためにそれを使用することを防ぎます。 つまり、このデータセットに基づいて商用チャットボットや言語アプリケーションを構築することはできません。
過去数週間にリリースされた最新モデルのほとんどは同じ問題に悩まされていました。 アルパカ, コアラ, GPT4すべて, ビキューナ。 これを回避するには、商用利用できる新しい高品質のデータセットを作成する必要があります。これは、Databricks チームが databricks-dolly-15k データセットを使用して行ったことです。
新しいデータセットには、大規模な言語モデルを調整する命令の設計に使用できる、人間がラベル付けした高品質のプロンプト/応答ペアが 15,000 個含まれています。 の データブリック-ドリー-15k データセットには付属しています クリエイティブ・コモンズ表示 - 継承 3.0 非移植ライセンス、誰でもそれを使用、変更し、商用アプリケーションを作成することができます。
databricks-dolly-15k データセットはどのようにして作成されたのでしょうか?
OpenAI の研究 紙 元の InstructGPT モデルは 13,000 のプロンプトと応答でトレーニングされたと述べています。 Databricks チームはこの情報を使用して作業を開始しましたが、13 の質問と回答を生成するのは困難な作業であることが判明しました。 合成データや AI 生成データを使用することはできず、すべての質問に対して独自の回答を生成する必要があります。 ここで、Databricks の 5,000 人の従業員を利用して人間が生成したデータを作成することにしました。
Databricks は、上位 20 名のラベル作成者に大きな賞が与えられるコンテストを設定しました。 このコンテストには、LLM に非常に興味を持つ 5,000 人の Databricks 従業員が参加しました。
dolly-v2-12b は最先端のモデルではありません。 一部の評価ベンチマークでは、dolly-v1-6b よりもパフォーマンスが劣ります。 これは、基礎となる微調整データセットの構成とサイズが原因である可能性があります。 Dolly モデル ファミリは現在開発が進められているため、将来的にはパフォーマンスが向上した更新バージョンが登場する可能性があります。
つまり、dolly-v2-12b モデルは、EleutherAI/gpt-neox-20b および EleutherAI/pythia-6.9b よりも優れたパフォーマンスを示しています。

Image from
フリードリー
Dolly 2.0 は 100% オープンソースです。 これには、トレーニング コード、データセット、モデルの重み、推論パイプラインが付属しています。 すべてのコンポーネントは商用利用に適しています。 ハグフェイススペースでモデルを試すことができます ドリー V2 by RamAnanth1.
Image from
ハグ顔
リソース:
ドリー 2.0 デモ: ドリー V2 by RamAnanth1
アビッド・アリ・アワン (@ 1abidaliawan)は、機械学習モデルの構築を愛する認定データサイエンティストの専門家です。 現在、彼はコンテンツの作成と、機械学習とデータサイエンステクノロジーに関する技術ブログの執筆に注力しています。 Abidは、技術管理の修士号と電気通信工学の学士号を取得しています。 彼のビジョンは、精神疾患に苦しんでいる学生のためにグラフニューラルネットワークを使用してAI製品を構築することです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 未来を鋳造する w エイドリエン・アシュリー。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- :持っている
- :は
- :not
- $UP
- 000
- 1
- 20
- a
- 能力
- アクティブ
- AI
- すべて
- ことができます
- 代替案
- an
- &
- 回答
- 誰も
- API
- 申し込み
- です
- 周りに
- 著者
- 利用できます
- 賞
- ベース
- BE
- ベンチマーク
- バークリー
- より良いです
- ビッグ
- ビング
- ブログ
- 両言語で
- ビルド
- 建物
- by
- 缶
- 認証
- チャットボット
- AI言語モデルを活用してコードのデバッグからデータの異常検出まで、
- コード
- コマーシャル
- コモンズ
- 競争する
- コンポーネント
- 含まれています
- コンテンツ
- コンテンツ作成
- コンテスト
- コスト
- 作ります
- 作成した
- 創造
- 現在
- データ
- データサイエンス
- データサイエンティスト
- データブリック
- データセット
- 決定しました
- 度
- デモ
- 設計
- 開発
- DID
- 難しい
- ドリー
- 従業員
- 社員
- エンジニアリング
- 評価
- あらゆる
- 展示
- 顔
- 家族
- 少数の
- 焦点
- フォロー中
- から
- 未来
- 生成する
- 生成
- 生々しい
- 取得する
- グラフ
- グラフ ニューラル ネットワーク
- 持ってる
- he
- 高品質
- 保持している
- HTML
- HTTPS
- 病気
- 画像
- in
- 情報
- 興味がある
- 問題
- 問題
- IT
- JPG
- KDナゲット
- 言語
- 大
- 姓
- 最新の
- 学習
- ライセンス
- ような
- 機械
- 機械学習
- 管理
- マスター
- メンタル
- 精神疾患
- かもしれない
- モデル
- 修正する
- 必要
- ネットワーク
- ニューラル
- ニューラルネットワーク
- 新作
- of
- on
- の
- 開いた
- オープンソース
- OpenAI
- or
- オリジナル
- 出力
- 足
- パラメーター
- 参加
- パフォーマンス
- パイプライン
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- プロダクト
- プロ
- 目的
- 質問
- 質問
- リリース
- 研究
- 解決
- 制限されました
- s
- 同じ
- 科学
- 科学者
- セッションに
- ショート
- サイズ
- So
- 一部
- ソース
- スペース
- スペース
- スタンフォード
- 開始
- 最先端の
- 米国
- 苦労して
- 生徒
- 適当
- 合成
- 合成データ
- 仕事
- チーム
- 技術的
- テクノロジー
- テクノロジー
- テレコミュニケーション
- より
- それ
- 未来
- 彼ら
- この
- 〜へ
- top
- トレーニング
- 訓練された
- トレーニング
- 下
- 根本的な
- 更新しました
- つかいます
- 中古
- バージョン
- ビジョン
- ました
- we
- ウィークス
- した
- この試験は
- which
- 誰
- 仕事
- でしょう
- 書き込み
- 貴社
- ゼファーネット










