Amazonレッドシフト は、フルマネージドのペタバイト規模のクラウド データ ウェアハウスであり、何万もの顧客が毎日エクサバイトのデータを処理して分析ワークロードを強化するために使用しています。 次元モデルを使用すると、データを構造化し、ビジネス プロセスを測定し、貴重な洞察を迅速に得ることができます。 Amazon Redshift は、次元モデルからのモデリング、オーケストレーション、レポートのプロセスを高速化するための組み込み機能を提供します。
この投稿では、ディメンション モデル、特に キンボールの方法論。 Amazon Redshift 内でのディメンションと事実の実装について説明します。 データ レイクから生データをステージング レイヤーに取得してモデリングを実行することに重点を置いた統合プロセスである抽出、変換、読み込み (ELT) を実行する方法を示します。 全体として、この投稿では、Amazon Redshift でのディメンション モデリングの使用方法を明確に理解できます。
ソリューションの概要
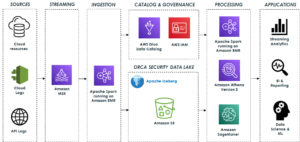
次の図は、ソリューションのアーキテクチャを示しています。

次のセクションでは、まず次元モデルの重要な側面について説明し、実証します。 その後、Amazon Redshift を使用して、ディメンション テーブルとファクト テーブルを含むディメンション データ モデルを使用してデータ マートを作成します。 データは、 COPY コマンドを使用すると、ディメンション内のデータがロードされます。 MERGE ステートメントを作成すると、事実が洞察が得られる次元に結合されます。 を使用してディメンションとファクトの読み込みをスケジュールします。 AmazonRedshiftクエリエディターV2。 最後に、私たちが使用するのは、 アマゾンクイックサイト QuickSight ダッシュボードの形式でモデル化されたデータに関する洞察を得ることができます。
このソリューションでは、Amazon Redshift がイベント チケット販売用に提供するサンプル データセット (正規化された) を使用します。 この投稿では、簡素化とデモンストレーションの目的でデータセットを絞り込みました。 次の表は、チケット販売と会場のデータの例を示しています。


による キンボール次元モデリング手法、次元モデルの設計には XNUMX つの重要な手順があります。
- ビジネスプロセスを特定します。
- データの粒度を宣言します。
- ディメンションを特定して実装します。
- 事実を特定して実行します。
さらに、デモンストレーションの目的で、ビジネス イベントのレポートと分析という XNUMX 番目のステップを追加します。
前提条件
このチュートリアルでは、次の前提条件を満たしている必要があります。
ビジネスプロセスを特定する
簡単に言えば、ビジネス プロセスを特定することは、組織内でデータを生成する測定可能なイベントを特定することです。 通常、企業はデータを生の形式で生成する何らかの運用ソース システムを持っています。 これは、ビジネス プロセスのさまざまなソースを特定するための良い出発点となります。
ビジネス プロセスは、 データマート 次元と事実の形で。 前述のサンプル データセットを見ると、ビジネス プロセスが特定のイベントで行われた売上であることが明確にわかります。
よくある間違いは、会社の部門をビジネス プロセスとして使用することです。 データ (ビジネス プロセス) はさまざまな部門間で統合される必要があります。この場合、マーケティング部門は販売データにアクセスできます。 正しいビジネス プロセスを特定することが重要です。この手順を誤ると、データ マート全体に影響を与える可能性があります (最終レポートで粒度が重複し、不正確なメトリクスが表示される可能性があります)。
データの粒度を宣言する
粒度の宣言は、データ ソース内のレコードを一意に識別する行為です。 ファクト テーブルでは粒度を使用してデータを正確に測定し、さらにロールアップできるようにします。 この例では、これは販売ビジネス プロセスの品目である可能性があります。
私たちのユースケースでは、販売が行われたトランザクション時間を調べることで、販売を一意に識別できます。 これは最も原子的なレベルになります。

ディメンションを特定して実装する
ディメンション テーブルには、ファクト テーブルとその属性が記述されます。 ビジネス プロセスの説明的なコンテキストを特定するときは、ファクト テーブルの粒度を念頭に置いて、テキストを別のテーブルに保存します。 ディメンション テーブルをファクト テーブルに結合する場合、ファクト テーブルに関連付けられる行は XNUMX つだけである必要があります。 この例では、次のテーブルを使用してディメンション テーブルに分割します。 これらのフィールドは、測定する事実を記述します。
次元モデル (スキーマ) の構造を設計するときは、次のいずれかを作成できます。 星 or スノーフレーク スキーマ。 構造はビジネス プロセスと密接に一致している必要があります。 したがって、スター スキーマがこの例に最適です。 次の図は、エンティティ関係図 (ERD) を示しています。

次のセクションでは、ディメンションを実装する手順について詳しく説明します。
ソースデータをステージングする
ディメンション テーブルを作成してロードする前に、ソース データが必要です。 したがって、ソース データをステージング テーブルまたは一時テーブルにステージングします。 これはよく次のように呼ばれます。 ステージング層、これはソース データの生のコピーです。 Amazon Redshift でこれを行うには、 COPYコマンド にある Dimension-modeling-in-amazon-redshift パブリック S3 バケットからデータをロードします。 us-east-1 領域。 COPY コマンドでは AWS IDおよびアクセス管理 (IAM) ロール Amazon S3 へのアクセス。 役割は次のとおりである必要があります クラスターに関連付けられている。 ソース データをステージングするには、次の手順を実行します。
- 作ります
venueソーステーブル:
- 会場データをロードします。
- 作ります
salesソーステーブル:
- 販売ソース データをロードします。
- 作ります
calendarテーブル:
- カレンダーデータをロードします。
寸法表を作成する
ディメンション テーブルの設計は、ビジネス要件に応じて異なります。たとえば、長期にわたるデータの変更を追跡する必要があるかどうかなどです。 がある XNUMX つの異なる寸法タイプ。 この例では、次を使用します。 1を入力 歴史的な変化を追跡する必要がないからです。 タイプ 2 の詳細については、を参照してください。 Amazon Redshift のタイプ 2 のゆっくりと変化するディメンションへのデータのロードを簡素化する。 ディメンション テーブルは、主キー、代理キー、およびテーブルへの変更を示すいくつかの追加フィールドを使用して非正規化されます。 次のコードを参照してください。
ディメンション テーブルの作成に関するいくつかの注意事項:
- フィールド名はビジネス向けの名前に変換されます
- 私たちの主キーは
VenueID、販売が行われた会場を一意に識別するために使用されます。 - レコードがいつ挿入および更新されたかを示す XNUMX つの行が追加されます (変更を追跡するため)。
- 私たちが使用しているのは、 AUTO配信スタイル Amazon Redshift に配布スタイルの選択と調整の責任を与える
次元モデリングで考慮すべきもう XNUMX つの重要な要素は、 代理キー。 サロゲート キーは、ディメンション モデリングでディメンション テーブル内の各レコードを一意に識別するために使用される人工キーです。 これらは通常、連続する整数として生成され、ビジネス ドメインでは何の意味も持ちません。 これらは通常、自然キーよりも小さく、代理キーとして時間が経っても変化しないため、一意性の確保や結合のパフォーマンスの向上など、いくつかの利点があります。 これにより、一貫性が保たれ、ファクトとディメンションをより簡単に結合できるようになります。
Amazon Redshift では、通常、IDENTITY キーワードを使用して代理キーが作成されます。 たとえば、前述の CREATE ステートメントは、次のディメンション テーブルを作成します。 VenueSkey 代理キー。 の VenueSkey 新しい行がテーブルに追加されると、列には一意の値が自動的に入力されます。 この列を使用して、会場テーブルを FactSaleTransactions 列で番号の横にあるXをクリックします。
代理キーを設計するためのいくつかのヒント:
- 代理キーには小さい固定幅のデータ型を使用します。 これにより、パフォーマンスが向上し、ストレージ容量が削減されます。
- IDENTITY キーワードを使用するか、連続値または GUID 値を使用して代理キーを生成します。 これにより、代理キーが一意になり、変更できないことが保証されます。
MERGEを使用してディムテーブルをロードします。
ディムテーブルをロードするにはさまざまな方法があります。 パフォーマンス、データ量、場合によっては SLA 読み込み時間など、特定の要素を考慮する必要があります。 とともに MERGE ステートメントを使用すると、複数の挿入および更新コマンドを指定する必要なく、更新/挿入を実行できます。 設定できるのは、 MERGE のステートメント ストアドプロシージャ データを入力します。 次に、クエリ エディターを使用してプログラムで実行するストアド プロシージャをスケジュールします。これについては、この記事で後ほど説明します。 次のコードは、というストアド プロシージャを作成します。 SalesMart.DimVenueLoad:
ディメンションのロードに関するいくつかの注意事項:
- レコードが初めて挿入されると、挿入日と更新日が設定されます。 値が変更されるとデータが更新され、更新された日付には変更された日付が反映されます。 挿入された日付は残ります。
- データはビジネス ユーザーによって使用されるため、NULL 値がある場合は、よりビジネスに適した値に置き換える必要があります。
事実を特定して実行する
穀物が特定の時間に発生した販売イベントであると宣言したので、ファクト テーブルにはビジネス プロセスの数値ファクトが保存されます。
測定すべき次の数値的事実を特定しました。
- 販売ごとのチケット販売枚数
- 販売手数料
事実を実践する
全 XNUMX 種類のファクト テーブル (トランザクション ファクト テーブル、定期スナップショット ファクト テーブル、蓄積スナップショット ファクト テーブル)。 それぞれがビジネス プロセスの異なるビューを提供します。 この例では、トランザクション ファクト テーブルを使用します。 次の手順を実行します。
- ファクトテーブルを作成する
挿入された日付とデフォルト値が追加され、レコードがロードされたかどうか、およびいつロードされたかを示します。 ファクト テーブルを再ロードするときにこれを使用して、重複を避けるためにすでにロードされているデータを削除できます。
ファクト テーブルのロードは、関連するディメンションを結合する単純な挿入ステートメントで構成されます。 から参加します DimVenue 事実を説明する作成された表。 ベストプラクティスですが、必須ではありません 暦日 ディメンション。エンドユーザーがファクト テーブル内を移動できるようになります。 データは、新しいセールが発生したときにロードすることも、毎日ロードすることもできます。 ここで、挿入された日付またはロードされた日付が役に立ちます。
ストアド プロシージャを使用してファクト テーブルをロードし、日付パラメーターを使用します。
- 次のコードを使用してストアド プロシージャを作成します。 ディメンションのロードで適用したのと同じデータの整合性を維持するために、NULL 値がある場合は、それをよりビジネスに適した値に置き換えます。
- 次のコマンドでプロシージャを呼び出してデータをロードします。
データロードのスケジュールを設定する
Amazon Redshift Query Editor V2 でストアド プロシージャをスケジュールすることで、モデリング プロセスを自動化できるようになりました。 次の手順を実行します。
- 最初にディメンション ロードを呼び出し、ディメンション ロードが正常に実行された後、ファクト ロードが開始されます。
ディメンションのロードが失敗すると、ファクトのロードは実行されません。 古いディメンションを含むファクト テーブルをロードしたくないため、これによりデータの一貫性が確保されます。
- ロードをスケジュールするには、次を選択します。 スケジュール クエリ エディター V2 で。

- クエリを毎日午前 5:00 に実行するようにスケジュールします。
- オプションで、有効にすることで失敗通知を追加できます。 Amazon シンプル通知サービス (Amazon SNS) 通知。

Amazon Quicksight でデータをレポートおよび分析する
QuickSight は、洞察を簡単に提供できるビジネス インテリジェンス サービスです。 フルマネージド サービスである QuickSight を使用すると、任意のデバイスからアクセスしてアプリケーション、ポータル、Web サイトに埋め込むことができるインタラクティブなダッシュボードを簡単に作成して公開できます。
データ マートを使用して、ダッシュボードの形式で事実を視覚的に表示します。 QuickSight を開始してセットアップするには、次を参照してください。 自動検出されないデータベースを使用したデータセットの作成.
QuickSight でデータ ソースを作成した後、サロゲート キーに基づいてモデル化されたデータ (データ マート) が結合されます。 skey。 このデータセットを使用してデータ マートを視覚化します。

当社のエンド ダッシュボードにはデータ マートの洞察が含まれており、会場ごとの合計コミッションや最も売上が高かった日などの重要なビジネス上の質問に答えます。 次のスクリーンショットは、データ マートの最終製品を示しています。

クリーンアップ
今後料金が発生しないようにするには、この投稿の一部として作成したリソースをすべて削除してください。
まとめ
これで、 DimVenue, DimCalendar, FactSaleTransactions テーブル。 私たちの倉庫は完成していません。 より多くのファクトを使用してデータ マートを拡張し、より多くのマートを実装できるようになり、ビジネス プロセスと要件が時間の経過とともに増大するにつれて、データ ウェアハウスも増大します。 この投稿では、Amazon Redshift でのディメンションモデリングの理解と実装についてエンドツーエンドの視点を示しました。
始めましょう Amazonレッドシフト 今日は立体模型。
著者について
 バーナード・ヴァースター は、スケーラブルで効率的なデータ モデルの作成、データ統合戦略の定義、データ ガバナンスとセキュリティの確保に長年携わってきた経験豊富なクラウド エンジニアです。 彼は、ビジネス要件と目標に合わせながら、データを使用して洞察を引き出すことに情熱を持っています。
バーナード・ヴァースター は、スケーラブルで効率的なデータ モデルの作成、データ統合戦略の定義、データ ガバナンスとセキュリティの確保に長年携わってきた経験豊富なクラウド エンジニアです。 彼は、ビジネス要件と目標に合わせながら、データを使用して洞察を引き出すことに情熱を持っています。
 アビシェーク・パン は、AWS インドの公共部門の顧客と協力する WWSO スペシャリスト SA-Analytics です。 彼は顧客と連携してデータ主導の戦略を定義し、分析のユースケースに関する詳細なセッションを提供し、スケーラブルでパフォーマンスの高い分析アプリケーションを設計します。 彼は 12 年の経験があり、データベース、分析、AI/ML に情熱を持っています。 彼は熱心な旅行者であり、カメラのレンズを通して世界を捉えようとしています。
アビシェーク・パン は、AWS インドの公共部門の顧客と協力する WWSO スペシャリスト SA-Analytics です。 彼は顧客と連携してデータ主導の戦略を定義し、分析のユースケースに関する詳細なセッションを提供し、スケーラブルでパフォーマンスの高い分析アプリケーションを設計します。 彼は 12 年の経験があり、データベース、分析、AI/ML に情熱を持っています。 彼は熱心な旅行者であり、カメラのレンズを通して世界を捉えようとしています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 自動車/EV、 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- ブロックオフセット。 環境オフセット所有権の近代化。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :持っている
- :は
- :not
- :どこ
- $UP
- 1
- 100
- 12
- 視聴者の38%が
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- 私たちについて
- 加速する
- アクセス
- アクセス
- 正確にデジタル化
- 越えて
- 行為
- 加えます
- 追加されました
- NEW
- 後
- AI / ML
- 整列する
- 整列
- 許す
- ことができます
- 既に
- am
- Amazon
- Amazon Webサービス
- an
- 分析
- 分析的
- 分析論
- 分析します
- および
- 回答
- どれか
- 適用された
- 適切な
- 建築
- です
- 人工の
- AS
- 側面
- 関連する
- At
- 属性
- オート
- 自動化する
- 自動的に
- 避ける
- AWS
- b
- ベース
- BE
- なぜなら
- 始まる
- 利点
- BEST
- 内蔵
- ビジネス
- ビジネス・インテリジェンス
- ビジネス プロセス
- ビジネスプロセス
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- カレンダー
- コール
- 呼ばれます
- 呼び出し
- カメラ
- 缶
- キャプチャー
- 場合
- 例
- 原因となる
- 一定
- 変化する
- 変更
- 変更
- 変化
- 文字
- 課金
- 選択する
- クリア
- はっきりと
- 密接に
- クラウド
- コード
- コラム
- comes
- 委員会
- コマンドと
- 企業
- 会社
- コンプリート
- 検討
- 整合性のある
- からなる
- コンテキスト
- 正しい
- 可能性
- 作ります
- 作成した
- 作成します。
- 作成
- 創造
- 重大な
- Customers
- daily
- ダッシュボード
- ダッシュボード
- データ
- データ統合
- データレイク
- データウェアハウス
- データ駆動型の
- データ主導の戦略
- データベース
- データベースを追加しました
- 日付
- 試合日
- 日付時刻
- 中
- 深いです
- ディープダイブ
- デフォルト
- 定義
- 配信する
- 実証します
- 部署
- 派生
- 説明する
- 設計
- 設計
- 詳細
- デバイス
- 異なります
- 次元
- 大きさ
- 話し合います
- 明確な
- ディストリビューション
- do
- ドメイン
- 行われ
- ドント
- ダウン
- ドライブ
- 複製
- 各
- 前
- 簡単に
- 簡単に
- エディタ
- 効率的な
- どちら
- 埋め込まれた
- enable
- 有効にする
- end
- 端から端まで
- 従事する
- エンジニア
- 確保
- 確実に
- 確保する
- 全体
- エンティティ
- エーテル(ETH)
- イベント
- イベント
- あらゆる
- 毎日
- 例
- 例
- 詳細
- 体験
- 経験豊かな
- 暴露
- エキス
- 実際
- 要因
- 要因
- 事実
- 失敗
- 不良解析
- 特徴
- 少数の
- フィールド
- フィールズ
- 第5
- フィギュア
- filter
- ファイナル
- 名
- 初回
- フィット
- 焦点を当て
- フォロー中
- フォーム
- 形式でアーカイブしたプロジェクトを保存します.
- 4
- から
- 完全に
- さらに
- 未来
- 利得
- 生成する
- 生成された
- 生成
- 取得する
- 受け
- 与える
- 与えられた
- 良い
- ガバナンス
- 成長する
- ハンディ
- 持ってる
- he
- 最高
- 彼の
- 歴史的
- 休日
- 認定条件
- How To
- HTML
- HTTP
- HTTPS
- IAM
- 特定され
- 識別する
- 識別
- アイデンティティ
- if
- 説明する
- 影響
- 実装する
- 実装
- 実装
- 重要
- 改善します
- 改善
- in
- 含めて
- インド
- 示す
- 示します
- info
- 洞察
- 統合された
- 統合
- 整合性
- インテリジェンス
- 相互作用的
- に
- IT
- ITS
- join
- 参加した
- 参加
- ジョイン
- JPG
- キープ
- 保管
- キー
- キー
- 湖
- 言語
- 後で
- 最新の
- 層
- 左
- レンズ
- ことができます
- レベル
- LINE
- 負荷
- ローディング
- 負荷
- 位置して
- 探して
- 製
- 作る
- マネージド
- マーケティング
- マッチ
- 意味
- だけど
- 言及した
- マージ
- メトリック
- マインド
- ミス
- モデリング
- モデリング
- モデル
- 月
- 他には?
- 最も
- の試合に
- 名
- ナチュラル
- ナビゲート
- 必要
- 必要
- ニーズ
- 新作
- ノート
- 通知
- 通知
- 今
- 多数の
- 目的
- of
- 提供
- 頻繁に
- on
- の
- オペレーショナル
- or
- 組織
- 私たちの
- が
- 全体
- パラメーター
- 部
- 情熱的な
- 以下のために
- 実行する
- パフォーマンス
- おそらく
- periodic
- 場所
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポイント
- 人口
- ポスト
- 電力
- 練習
- 前提条件
- 現在
- 主要な
- 手続き
- 手続き
- プロセス
- ラボレーション
- プロダクト
- 提供します
- 提供
- は、大阪で
- 公共
- パブリッシュ
- 目的
- 質問
- すぐに
- 上げる
- Raw
- 生データ
- 記録
- 記録
- 減らします
- 言及
- 反映
- 地域
- 関係
- 残っている
- 削除します
- replace
- レポート
- 各種レポート作成
- レポート
- 要件
- リソース
- 責任
- 職種
- ロール
- 行
- ラン
- runs
- 塩
- セールス
- 同じ
- サンプル データセット
- ド電源のデ
- スケジュール
- スケジューリング
- セクション
- セクター
- セキュリティ
- 別
- 仕える
- サービス
- サービス
- セッション
- セッションに
- いくつかの
- すべき
- 表示する
- 作品
- 簡単な拡張で
- 単純
- ゆっくり
- 小さい
- より小さい
- Snapshot
- So
- 売ら
- 溶液
- 一部
- ソース
- ソース
- スペース
- 専門家
- 特定の
- 特に
- ステージ
- ステージング
- 星
- 開始
- 起動
- ステートメント
- 手順
- ステップ
- ストレージ利用料
- 店舗
- 保存され
- 作戦
- 戦略
- 構造
- 成功した
- 首尾よく
- そのような
- テーブル
- 一時的
- 十
- 条件
- より
- それ
- ソース
- 世界
- アプリ環境に合わせて
- その後
- そこ。
- したがって、
- ボーマン
- 彼ら
- この
- 数千
- 介して
- チケット
- チケット販売
- チケット
- 時間
- <font style="vertical-align: inherit;">回数</font>
- タイムスタンプ
- ヒント
- 〜へ
- 今日
- 一緒に
- 取った
- トータル
- 追跡する
- トランザクション
- 最適化の適用
- 変換
- 旅行者
- type
- 一般的に
- 理解する
- ユニーク
- 独特に
- 一意性
- 未知の
- アップデイト
- 更新しました
- us
- 使用法
- つかいます
- 使用事例
- 中古
- users
- 使用されます
- 通常
- 貴重な
- 値
- 価値観
- さまざまな
- 会場
- 会場
- 、
- 詳しく見る
- ボリューム
- ウォークスルー
- 欲しいです
- 倉庫
- ました
- 方法
- we
- ウェブ
- Webサービス
- ウェブサイト
- 週間
- いつ
- which
- while
- 意志
- 以内
- 無し
- ワーキング
- 世界
- 間違った
- 年
- 年
- 貴社
- あなたの
- ゼファーネット