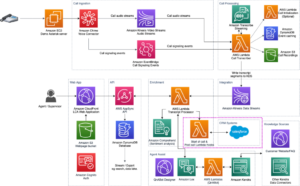
これは、AWS と Voxel51 が共同執筆した共同投稿です。 Voxel51 は、高品質のデータセットとコンピューター ビジョン モデルを構築するためのオープンソース ツールキットである FiftyOne の背後にある会社です。
ある小売会社は、顧客の衣類の購入を支援するモバイル アプリを構築しています。 このアプリを作成するには、さまざまなカテゴリのラベルが付けられた衣服の画像を含む高品質のデータセットが必要です。 この投稿では、データ クリーニング、前処理、およびゼロショット分類モデルによる事前ラベル付けを通じて、既存のデータセットを再利用する方法を示します。 XNUMX、これらのラベルを調整します Amazon SageMakerグラウンドトゥルース.
Ground Truth と FiftyOne を使用して、データ ラベル付けプロジェクトを加速できます。 XNUMX つのアプリケーションをシームレスに併用して、高品質のラベル付きデータセットを作成する方法を説明します。 このユースケース例では、 Fashion200K データセット、ICCV 2017でリリースされました。
ソリューションの概要
Ground Truth は、データ サイエンティスト、機械学習 (ML) エンジニア、研究者が高品質のデータセットを構築できるようにする、完全にセルフサービスで管理されたデータ ラベル付けサービスです。 XNUMX by ボクセル51 は、コンピューター ビジョン データセットをキュレーション、視覚化、評価するためのオープンソース ツールキットです。これにより、ユース ケースを加速してより良いモデルをトレーニングおよび分析できるようになります。
次のセクションでは、次のことを行う方法を示します。
- FiftyOne でデータセットを視覚化する
- FiftyOne のフィルタリングと画像重複排除を使用してデータセットをクリーンアップする
- FiftyOne のゼロ ショット分類を使用して、クリーニングされたデータに事前にラベルを付けます。
- 厳選された小規模なデータセットに Ground Truth のラベルを付ける
- Ground Truth からのラベル付き結果を FiftyOne に挿入し、FiftyOne でラベル付き結果をレビューします
ユースケースの概要
あなたが小売会社を経営しており、ユーザーが何を着るかを決めるのに役立つパーソナライズされた推奨事項を提供するモバイル アプリケーションを構築したいとします。 見込みユーザーは、クローゼット内のどの衣類がどのアイテムと相性が良いかを教えてくれるアプリケーションを探しています。 ここにチャンスがあります。良い服装を特定できれば、これを使用して、顧客がすでに所有している衣服を補完する新しい衣服を推奨できます。
エンドユーザーにとって作業をできるだけ簡単にしたいと考えています。 理想的には、あなたのアプリケーションを使用する人は自分のワードローブにある服の写真を撮るだけでよく、ML モデルは舞台裏で魔法のように機能します。 汎用モデルをトレーニングしたり、何らかの形式のフィードバックを使用して各ユーザーの独自のスタイルに合わせてモデルを微調整したりすることができます。
ただし、最初に、ユーザーがキャプチャしている服装の種類を特定する必要があります。 シャツですか? ズボンXNUMX着? または、他の何か? 結局のところ、複数のドレスや複数の帽子がある服装は推奨したくないでしょう。
この最初の課題に対処するために、さまざまなパターンとスタイルのさまざまな衣料品の画像で構成されるトレーニング データセットを生成する必要があります。 限られた予算でプロトタイプを作成するには、既存のデータセットを使用してブートストラップします。
この投稿ではプロセスを図解して説明するために、ICCV 200 でリリースされた Fashion2017K データセットを使用します。これは確立され、よく引用されているデータセットですが、あなたのユースケースには直接適していません。
衣料品にはカテゴリ (およびサブカテゴリ) のラベルが付けられ、元の製品説明から抽出されたさまざまな役立つタグが含まれていますが、データにはパターンやスタイルの情報が体系的にラベル付けされていません。 あなたの目標は、この既存のデータセットを衣類分類モデルの堅牢なトレーニング データセットに変えることです。 データをクリーンアップして、スタイル ラベルを使用してラベル付けスキーマを強化する必要があります。 そして、できるだけ少ない費用で、迅速にそれを実行したいと考えています。
データをローカルにダウンロードする
最初に、women.tar zip ファイルと labels フォルダー (およびそのすべてのサブフォルダー) をダウンロードします。 Fashion200K データセット GitHub リポジトリ。 両方を解凍したら、親ディレクトリ「fashion200k」を作成し、ラベルとウィメンズ フォルダーをこのディレクトリに移動します。 幸いなことに、これらの画像はすでに物体検出境界ボックスに合わせて切り取られているため、物体検出について心配するのではなく、分類に集中できます。
モニカに「200K」が含まれているにもかかわらず、抽出した女性ディレクトリには 338,339 枚の画像が含まれています。 公式の Fashion200K データセットを生成するために、データセットの作成者は 300,000 を超える製品をオンラインでクロールし、説明に XNUMX 語以上を含む製品のみがカットされました。 製品の説明が必須ではない目的のために、クロールされたすべての画像を使用できます。
このデータがどのように構成されているかを見てみましょう。女性フォルダー内では、画像は最上位の記事タイプ (スカート、トップス、パンツ、ジャケット、ドレス) と記事タイプのサブカテゴリ (ブラウス、T シャツ、長袖トップス)。
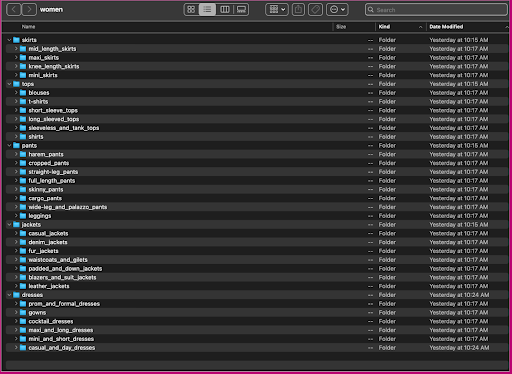
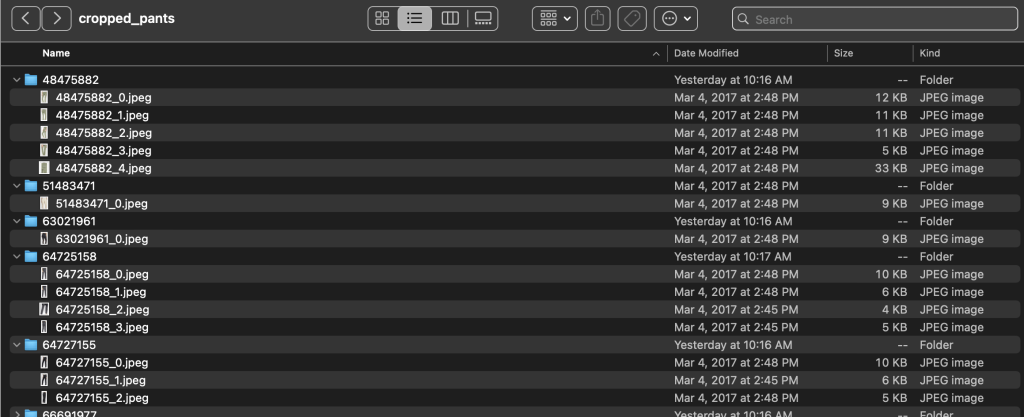
サブカテゴリ ディレクトリ内には、各製品リストのサブディレクトリがあります。 これらのそれぞれには、可変数の画像が含まれています。 たとえば、cropped_pants サブカテゴリには、次の製品リストと関連する画像が含まれています。
ラベル フォルダーには、トレーニング分割とテスト分割の両方について、トップレベルの記事タイプごとにテキスト ファイルが含まれています。 これらの各テキスト ファイル内には、画像ごとに個別の行があり、相対ファイル パス、スコア、製品説明のタグを指定します。
データセットを再利用しているため、トレーニング イメージとテスト イメージをすべて結合します。 これらを使用して、高品質のアプリケーション固有のデータセットを生成します。 このプロセスが完了したら、結果のデータセットを新しいトレーニング分割とテスト分割にランダムに分割できます。
FiftyOne でデータセットを挿入、表示、キュレートする
まだインストールしていない場合は、pip を使用してオープンソースの FiftyOne をインストールします。
ベスト プラクティスは、新しい仮想 (venv または conda) 環境内でこれを行うことです。 次に、関連するモジュールをインポートします。 基本ライブラリ fiftyone、ML メソッドが組み込まれている FiftyOne Brain、ゼロショット ラベルを生成するモデルをロードする FiftyOne Zoo、および効率的にフィルタリングできる ViewField をインポートします。データセット内のデータ:
また、glob および os Python モジュールもインポートする必要があります。これは、ディレクトリの内容に対するパスとパターンの一致を処理するのに役立ちます。
これで、データセットを FiftyOne にロードする準備ができました。 まず、fashion200k という名前のデータセットを作成して永続化します。これにより、計算負荷の高い操作の結果を保存できるため、上記の量を XNUMX 回計算するだけで済みます。
これで、すべてのサブカテゴリ ディレクトリを反復処理して、製品ディレクトリ内のすべての画像を追加できるようになりました。 各サンプルに、画像のトップレベルの記事カテゴリが入力されたフィールド名article_typeを持つ FiftyOne 分類ラベルを追加します。 また、カテゴリとサブカテゴリの両方の情報をタグとして追加します。
この時点で、セッションを起動して FiftyOne アプリでデータセットを視覚化できます。
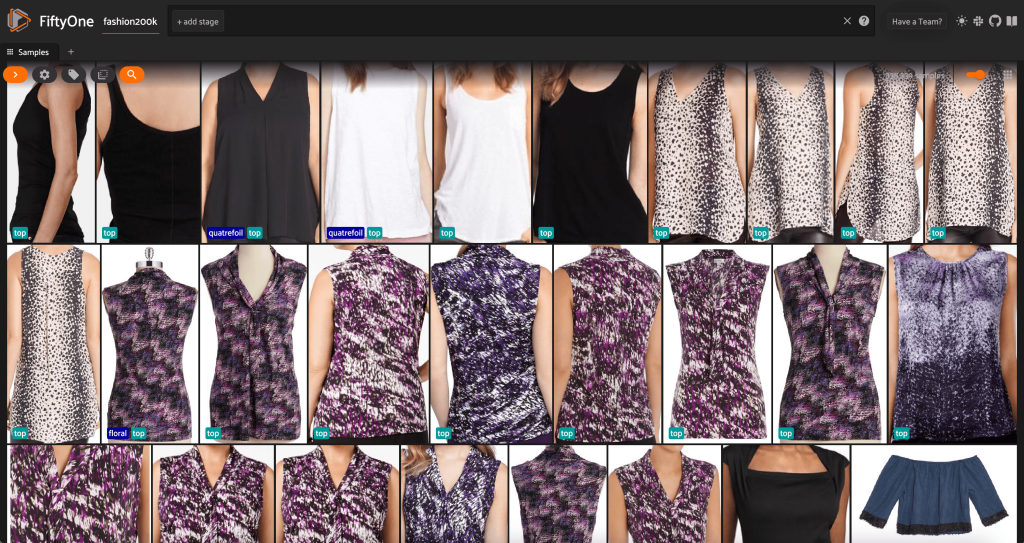
次を実行して、Python でデータセットの概要を出力することもできます。 print(dataset):
からタグを追加することもできます labels データセットのサンプルへのディレクトリ:
データを見ると、いくつかのことが明らかになります。
- 一部の画像はかなり粗く、解像度が低くなります。 これは、これらの画像がオブジェクト検出境界ボックス内の初期画像をトリミングすることによって生成されたためであると考えられます。
- 人物が着用しているものもあれば、自ら撮影したものもあります。 これらの詳細は、
viewpointプロパティ。 - 同じ製品の画像の多くは非常に似ているため、少なくとも最初は、製品ごとに複数の画像を含めても、予測力はあまり向上しない可能性があります。 ほとんどの場合、各製品の最初の画像 (末尾は
_0.jpeg)が最もきれいです。
最初に、これらの画像の制御されたサブセットで衣服スタイル分類モデルをトレーニングしたいと思うかもしれません。 この目的のために、私たちは製品の高解像度画像を使用し、製品ごとに代表的なサンプルを XNUMX つだけ表示するように制限しています。
まず、低解像度の画像をフィルタリングして除外します。 私たちが使用するのは、 compute_metadata() データセット内の各画像の画像の幅と高さをピクセル単位で計算して保存するメソッド。 次に、FiftyOne を採用します。 ViewField 最小許容幅と高さの値に基づいて画像をフィルタリングします。 次のコードを参照してください。
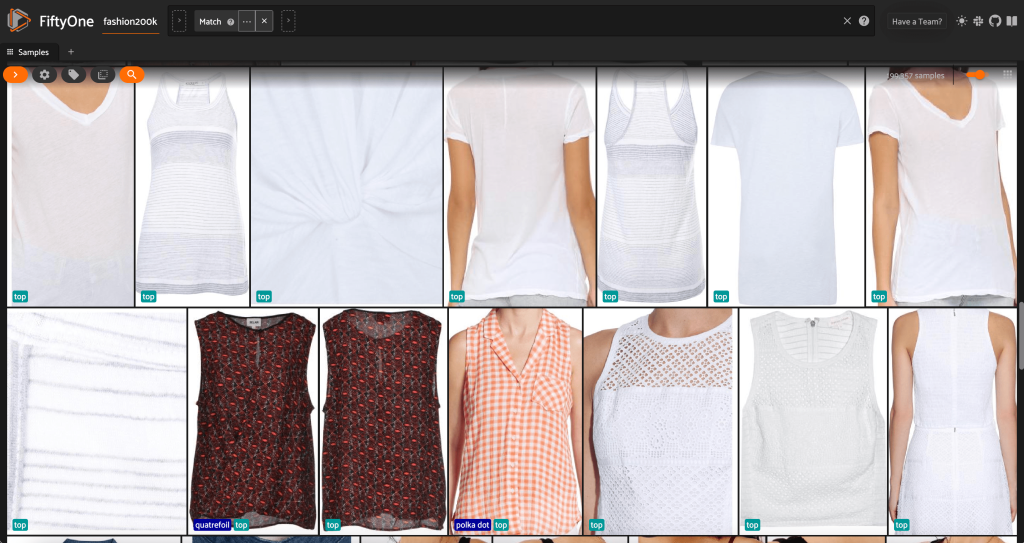
この高解像度サブセットには 200,000 弱のサンプルが含まれています。
このビューから、各製品の代表的なサンプルを (最大でも) XNUMX つだけ含む新しいビューをデータセットに作成できます。 私たちは、 ViewField もう一度、で終わるファイル パスのパターン マッチングを行います。 _0.jpeg:
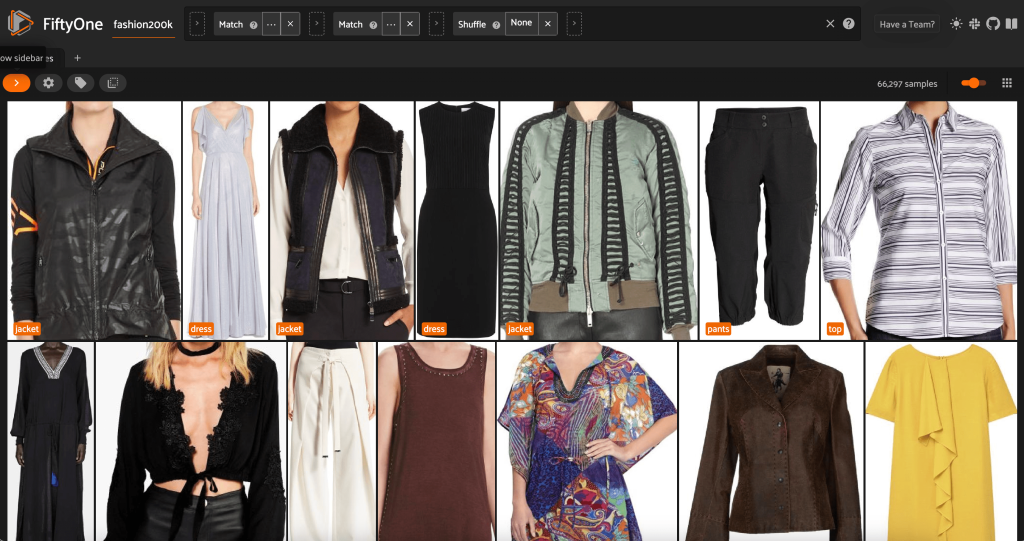
このサブセット内の画像のランダムにシャッフルされた順序を見てみましょう。
データセット内の冗長な画像を削除する
このビューには 66,297 枚の画像が含まれており、元のデータセットの 19% をわずかに上回っています。 しかし、ビューを見ると、非常によく似た製品がたくさんあることがわかります。 これらのコピーをすべて保持すると、ラベル付けとモデルのトレーニングにコストがかかるだけで、パフォーマンスが著しく向上することはありません。 代わりに、ほぼ重複するものを取り除き、同じパンチを詰め込んだ小さなデータセットを作成しましょう。
これらの画像は完全な複製ではないため、ピクセル単位で等しいかどうかを確認することはできません。 幸いなことに、FiftyOne Brain を使用して、データセットをきれいにすることができます。 特に、各画像の埋め込み (画像を表す低次元ベクトル) を計算し、埋め込みベクトルが互いに近い画像を探します。 ベクトルが近いほど、画像は似ています。
CLIP モデルを使用して、各画像の 512 次元の埋め込みベクトルを生成し、これらの埋め込みをデータセット内のサンプルのフィールド埋め込みに保存します。
次に、埋め込み間の近さを計算します。 コサイン類似性、類似度があるしきい値よりも大きい 0 つのベクトルはほぼ重複している可能性が高いと主張します。 コサイン類似度スコアは [1, 0.5] の範囲内にあり、データを見ると、しきい値スコア thresh=XNUMX がほぼ適切であるように見えます。 繰り返しますが、これは完璧である必要はありません。 いくつかのほぼ重複した画像が予測能力を台無しにする可能性は低く、いくつかの重複しない画像を破棄してもモデルのパフォーマンスに重大な影響を与えることはありません。
重複しているとされるものを表示して、それらが実際に冗長であることを確認できます。
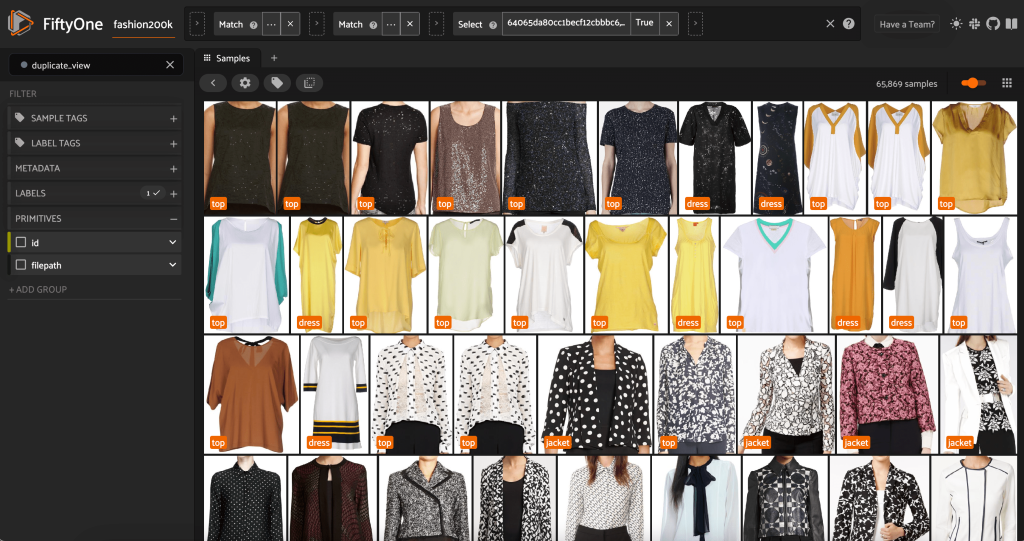
結果に満足し、これらの画像が確かに重複に近いと確信できる場合は、同様のサンプルの各セットから XNUMX つのサンプルを選択して保持し、その他を無視できます。
現在、このビューには 3,729 個の画像があります。 FiftyOne では、データをクリーニングして Fashion200K データセットの高品質なサブセットを特定することで、焦点を 300,000 枚以上から 4,000 枚弱に制限することができ、98% の削減に相当します。 埋め込みを使用して重複に近い画像を削除するだけで、検討中の画像の総数が 90% 以上減少しましたが、このデータでトレーニングされるモデルにはほとんど影響がありませんでした。
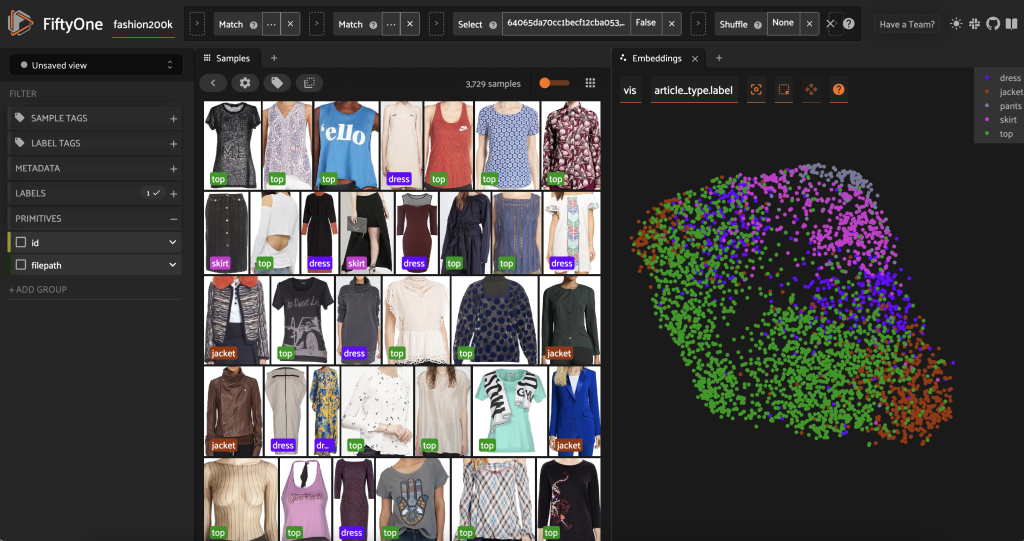
このサブセットを事前にラベル付けする前に、既に計算した埋め込みを視覚化することで、データをよりよく理解できます。 FiftyOne Brain の内蔵機能を使用できます。 compute_visualization() メソッドでは、一様多様体近似 (UMAP) 手法を使用して 512 次元の埋め込みベクトルを XNUMX 次元空間に投影し、視覚化できます。
新規オープンいたします 埋め込みパネル FiftyOne アプリで記事の種類ごとに色分けすると、これらの埋め込みが (とりわけ) 記事の種類の概念を大まかにエンコードしていることがわかります。
これで、このデータに事前にラベルを付ける準備ができました。
これらの非常にユニークで高解像度の画像を検査することで、ラベル付け前のゼロショット分類でクラスとして使用する適切なスタイルの初期リストを生成できます。 これらの画像に事前にラベルを付ける目的は、必ずしも各画像に正しくラベルを付けることではありません。 むしろ、私たちの目標は、人間のアノテーターに良い出発点を提供して、ラベル付けの時間とコストを削減できるようにすることです。
その後、このアプリケーションのゼロショット分類モデルをインスタンス化できます。 画像と自然言語の両方でトレーニングされた汎用モデルである CLIP モデルを使用します。 「Clothing in the style」というテキスト プロンプトを使用して CLIP モデルをインスタンス化します。これにより、モデルは、与えられた画像に対して、「Clothing in the style [class]」が最適なクラスを出力します。 CLIP は小売業やファッション特有のデータに基づいてトレーニングされていないため、これは完璧ではありませんが、ラベル付けと注釈のコストを節約できます。
次に、このモデルを縮小されたサブセットに適用し、結果を article_style フィールド:
もう一度 FiftyOne アプリを起動すると、これらの予測されたスタイル ラベルを使用して画像を視覚化できます。 予測の信頼度によって並べ替えるので、最も信頼度の高いスタイル予測が最初に表示されます。
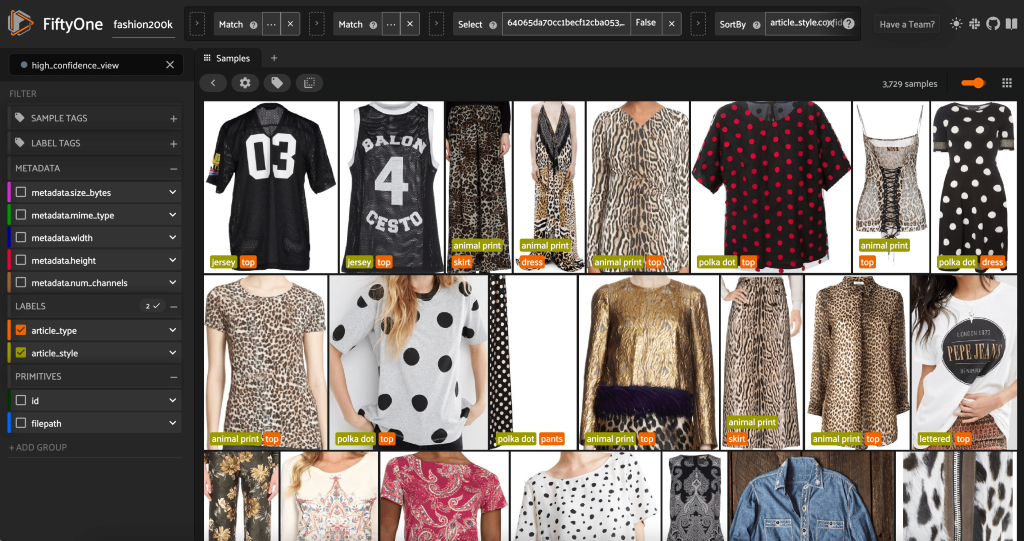
最も信頼性の高い予測は、「ジャージ」、「アニマル プリント」、「水玉模様」、および「レタード」スタイルであることがわかります。 これらのスタイルは比較的異なるため、これは当然のことです。 また、ほとんどの場合、予測されたスタイル ラベルは正確であるようです。
最も信頼度の低いスタイルの予測も確認できます。
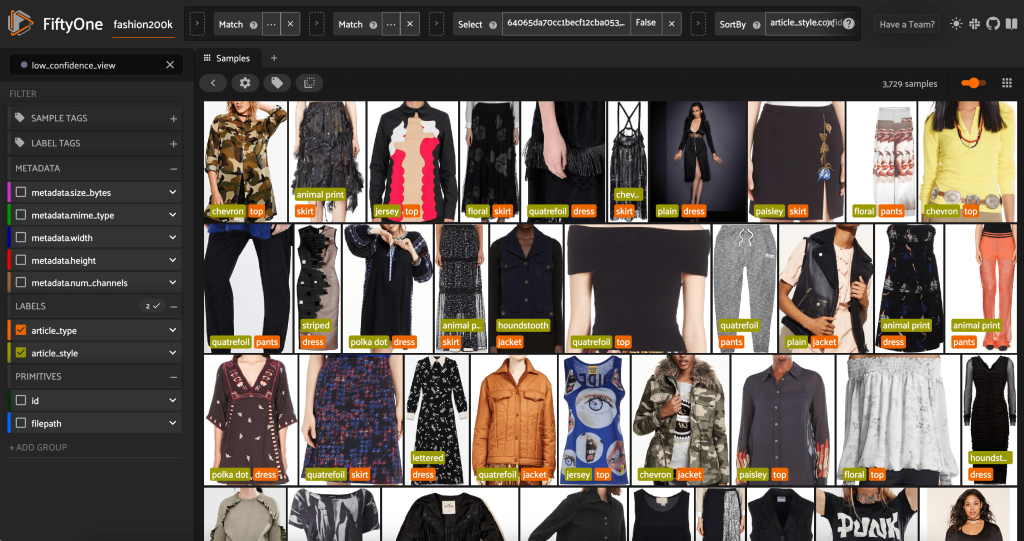
これらの画像の一部では、適切なスタイル カテゴリが提供されたリストに含まれており、衣類のラベルが誤って付けられています。 たとえば、グリッド内の最初の画像は、「シェブロン」ではなく、明らかに「迷彩」である必要があります。 ただし、製品がスタイル カテゴリにうまく収まらない場合もあります。 たとえば、XNUMX 行目の XNUMX 番目の画像のドレスは正確には「ストライプ」ではありませんが、同じラベル付けオプションを与えられた場合、人間のアノテーターも矛盾した可能性があります。 データセットを構築する際には、このようなエッジ ケースを削除するか、新しいスタイル カテゴリを追加するか、データセットを拡張するかを決定する必要があります。
FiftyOne から最終データセットをエクスポートする
次のコードを使用して、最終的なデータセットをエクスポートします。
より小さいデータセット (たとえば、16 枚の画像) をフォルダーにエクスポートできます。 200kFashionDatasetExportResult-16Images。 これを使用して Ground Truth 調整ジョブを作成します。
修正されたデータセットをアップロードし、ラベル形式を Ground Truth に変換し、Amazon S3 にアップロードして、調整ジョブ用のマニフェスト ファイルを作成します。
データセット内のラベルを変換して、 出力マニフェストスキーマ Ground Truth バウンディング ボックス ジョブの画像をアップロードし、 Amazon シンプル ストレージ サービス (Amazon S3) バケットを起動する Ground Truth 調整ジョブ:
次のコードを使用して、マニフェスト ファイルを Amazon S3 にアップロードします。
Ground Truth を使用して修正されたスタイル付きラベルを作成する
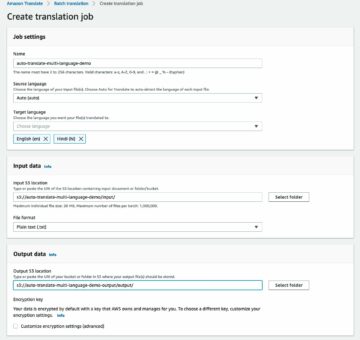
Ground Truth を使用してデータにスタイル ラベルの注釈を付けるには、「」で概説されている手順に従って、境界ボックスのラベル付けジョブを開始するために必要な手順を完了します。 グラウンド トゥルースの使用を開始する 同じ S3 バケット内のデータセットをガイドします。
- SageMaker コンソールで、Ground Truth ラベル付けジョブを作成します。
- をセットする 入力データセットの場所 前の手順で作成したマニフェストになります。
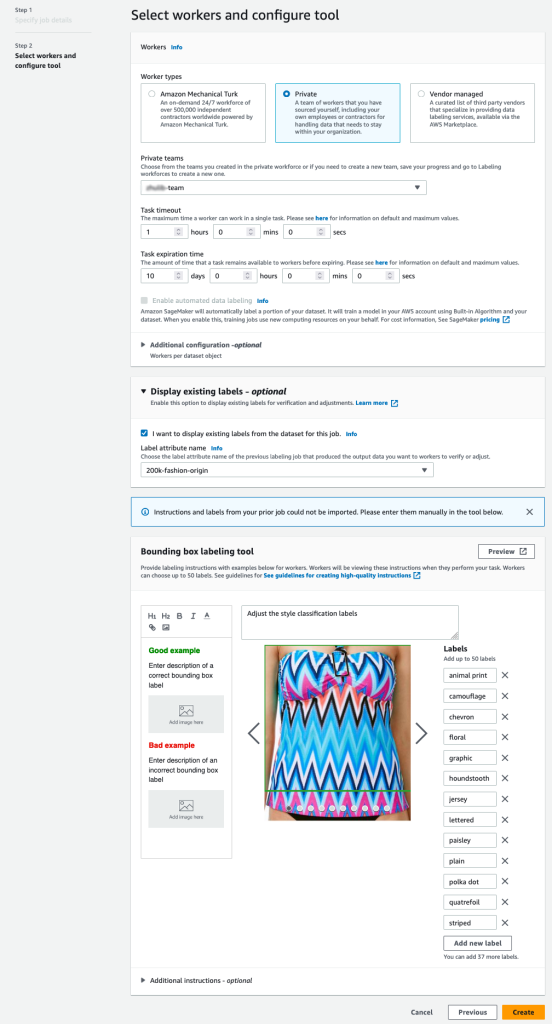
- の S3 パスを指定します 出力データセットの場所.
- IAMの役割、選択する カスタム IAM ロールを入力します RNA、次にロール ARN を入力します。
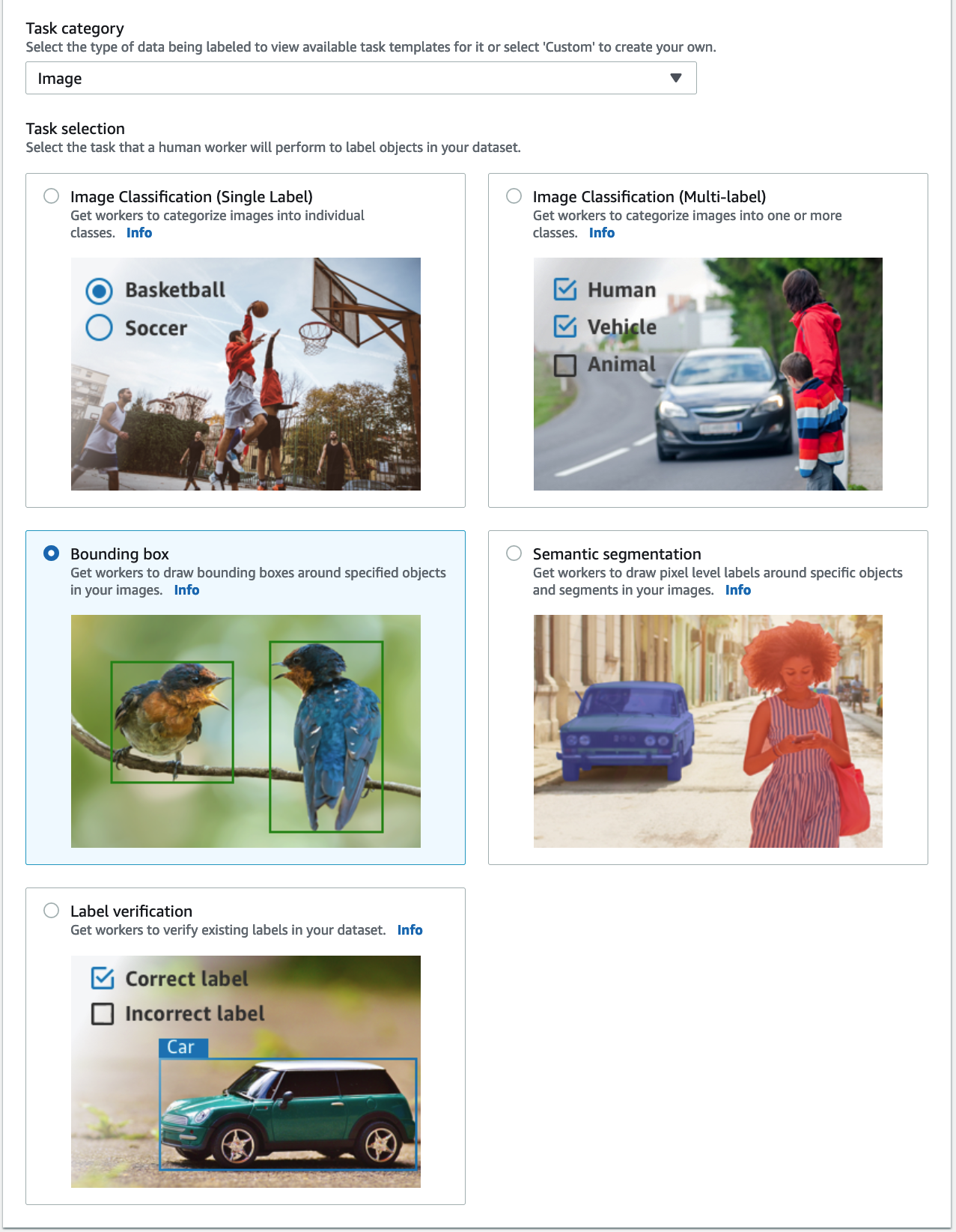
- タスクカテゴリ、選択する 画像 をクリックして 境界ボックス.
- 選択する Next.
- 労働者 セクションで、使用したい従業員のタイプを選択します。
従業員は次の方法で選択できます Amazon Mechanical Turk、サードパーティ ベンダー、または自社の個人従業員。 従業員オプションの詳細については、次を参照してください。 労働力の作成と管理. - 詳細 既存のラベルの表示オプション をクリックして このジョブのデータセットから既存のラベルを表示したいと考えています。
- ラベル属性 name では、調整のために表示するラベルに対応する名前をマニフェストから選択します。
前の手順で選択したタスク タイプに一致するラベルのラベル属性名のみが表示されます。 - ラベルを手動で入力します バウンディング ボックス ラベル付けツール.
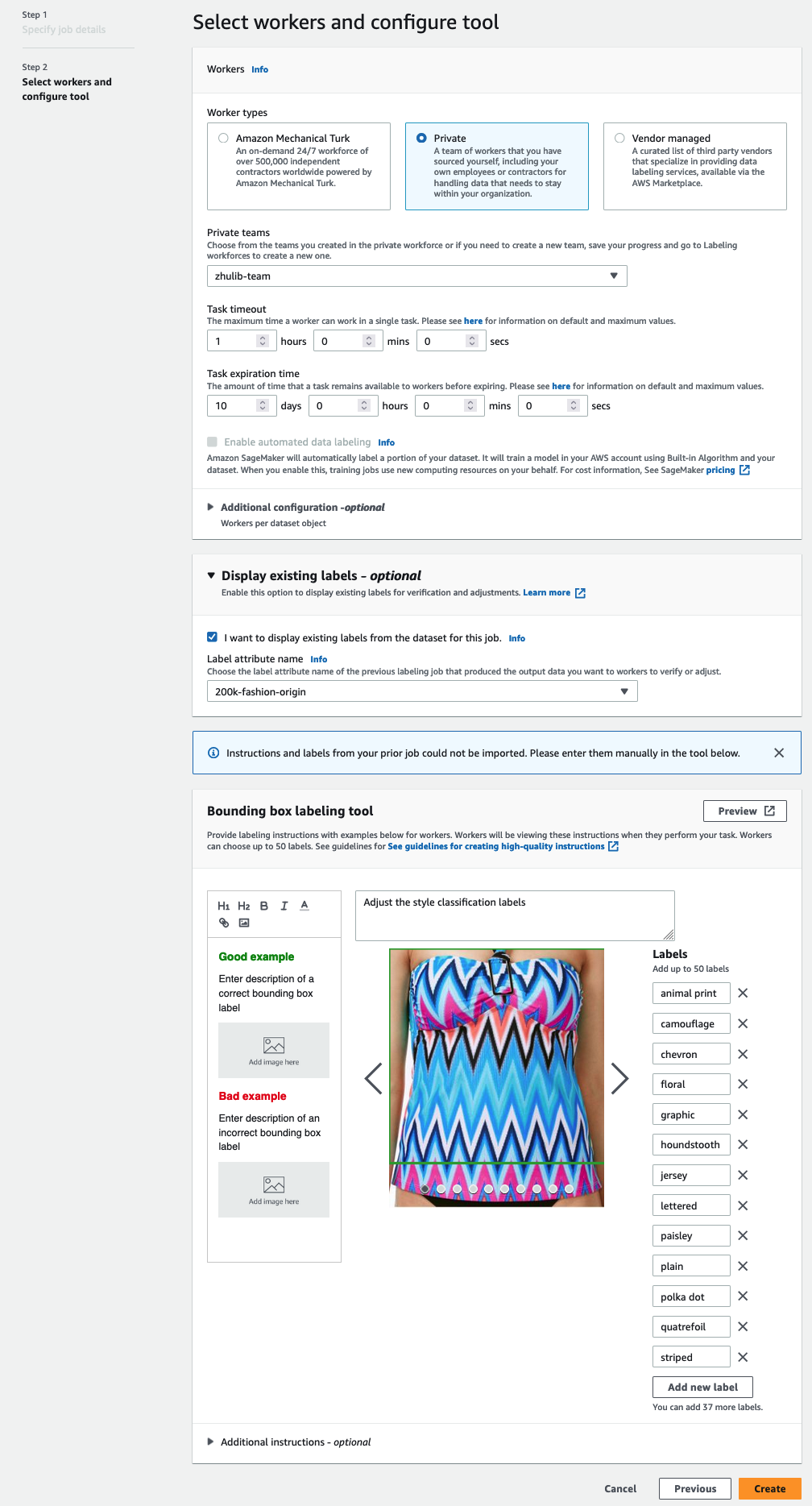 ラベルには、パブリック データセットで使用されているのと同じラベルが含まれている必要があります。 新しいラベルを追加できます。 次のスクリーンショットは、ワーカーを選択し、ラベル付けジョブ用にツールを構成する方法を示しています。
ラベルには、パブリック データセットで使用されているのと同じラベルが含まれている必要があります。 新しいラベルを追加できます。 次のスクリーンショットは、ワーカーを選択し、ラベル付けジョブ用にツールを構成する方法を示しています。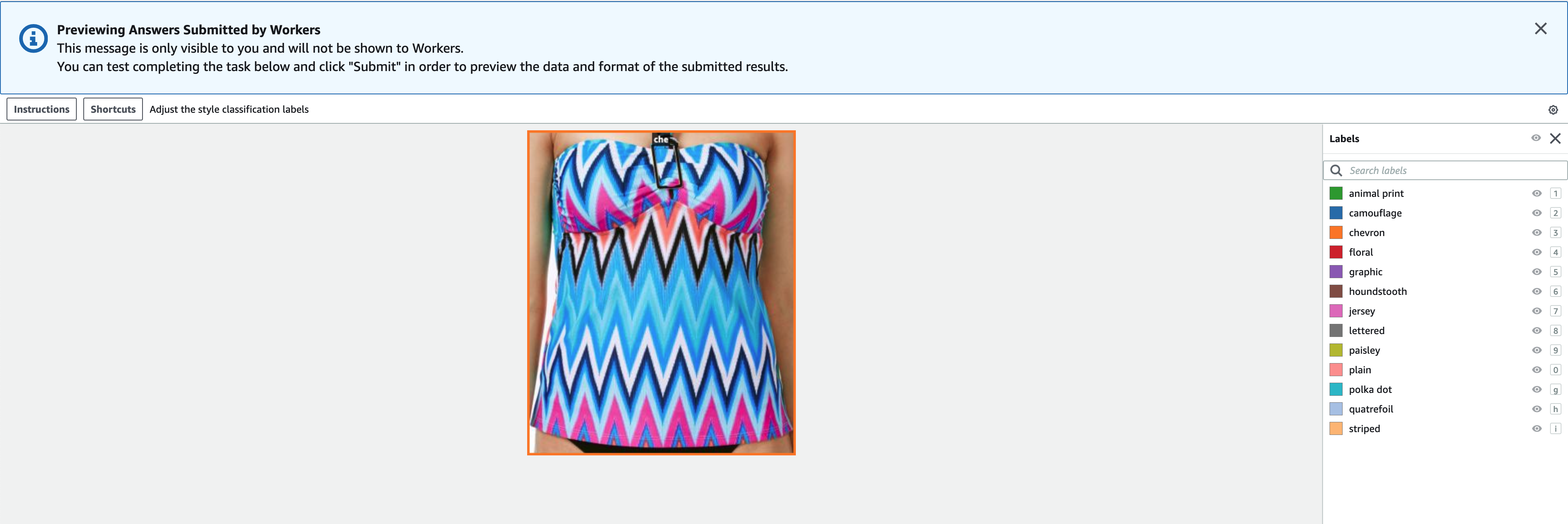
- 選択する プレビュー 画像と元の注釈をプレビューします。
これで、Ground Truth でラベル付けジョブが作成されました。 ジョブが完了したら、新しく生成されたラベル付きデータを FiftyOne にロードできます。 Ground Truth は、Ground Truth 出力マニフェストに出力データを生成します。 出力マニフェスト ファイルの詳細については、次を参照してください。 バウンディングボックスジョブの出力。 次のコードは、この出力マニフェスト形式の例を示しています。
FiftyOne で Ground Truth からのラベル付き結果を確認する
ジョブが完了したら、Amazon S3 からラベル付けジョブの出力マニフェストをダウンロードします。
出力マニフェスト ファイルを読み取ります。
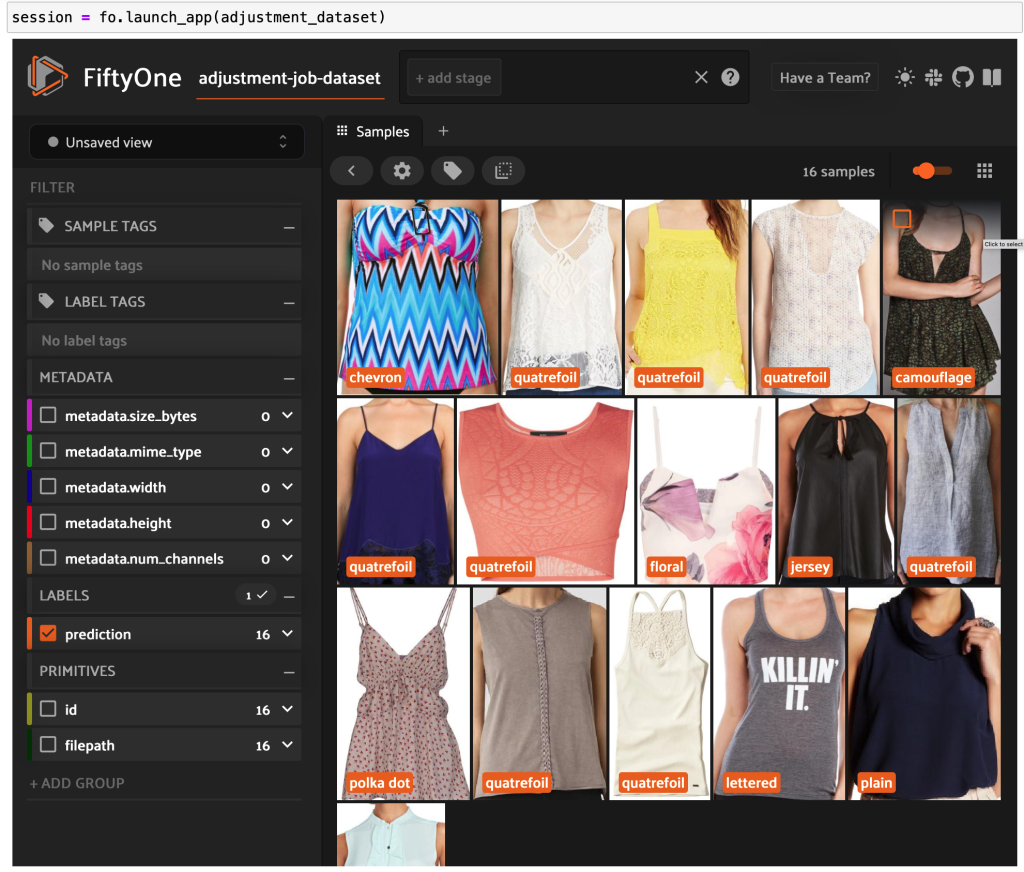
FiftyOne データセットを作成し、マニフェスト行をデータセット内のサンプルに変換します。
FiftyOne で Ground Truth からの高品質のラベル付きデータを確認できるようになりました。
まとめ
この投稿では、次の機能を組み合わせて高品質のデータセットを構築する方法を説明しました。 XNUMX by ボクセル51データセットの管理、追跡、視覚化、キュレーションを可能にするオープンソース ツールキットと、構築された複数のデータセットへのアクセスを提供することで、ML システムのトレーニングに必要なデータセットに効率的かつ正確にラベルを付けることができるデータ ラベル付けサービス Ground Truth です。 - タスク テンプレートを使用し、Mechanical Turk、サードパーティ ベンダー、または自社の個人従業員を通じて多様な従業員にアクセスできます。
FiftyOne インスタンスをインストールし、Ground Truth コンソールを使用して開始して、この新機能を試してみることをお勧めします。 Ground Truth の詳細については、次を参照してください。 ラベルデータ, Amazon SageMaker データのラベル付けに関するよくある質問、 そしてその AWS機械学習ブログ.
と接続する 機械学習と AI コミュニティ 質問やフィードバックがあれば!
フィフティワン コミュニティに参加しましょう!
今日のコンピューター ビジョンで最も困難な問題のいくつかを解決するために、すでに FiftyOne を使用している何千人ものエンジニアやデータ サイエンティストに加わりましょう!
著者について
シャレンドラチャブラ 現在、Amazon SageMaker Human-in-the-Loop (HIL) サービスの製品管理責任者です。 以前は、Shalendra は Microsoft Teams Meetings の Language and Conversational Intelligence を育成および主導し、Amazon Alexa Techstars Startup Accelerator の EIR であり、製品およびマーケティング担当副社長でした。 ディスカッション.io、Clipboard (Salesforce が買収) の製品およびマーケティング責任者、Swype (Nuance が買収) のリード プロダクト マネージャー。 全体で、Shalendra は XNUMX 億人以上の生活に影響を与えた製品の構築、出荷、販売を支援してきました。
ジェイコブ・マークス Voxel51 の機械学習エンジニア兼開発者エバンジェリストであり、世界中のデータに透明性と明瞭性をもたらすことに貢献しています。 Voxel51 に参加する前に、ジェイコブは新興ミュージシャンがファンと創造的なコンテンツを結び付けて共有できるように支援するスタートアップを設立しました。 それ以前は、Google X、Samsung Research、Wolfram Research で働いていました。 前世では、ジェイコブは理論物理学者であり、スタンフォード大学で博士号を取得し、そこで物質の量子相を研究しました。 ジェイコブは自由時間には、登山、ランニング、SF 小説の読書を楽しんでいます。
ジェイソン・コルソ Voxel51 の共同創設者兼 CEO であり、最先端の柔軟なソフトウェアを通じて世界のデータに透明性と明瞭性をもたらす戦略を指揮しています。 彼はミシガン大学のロボット工学、電気工学、コンピューター サイエンスの教授でもあり、コンピューター ビジョン、自然言語、物理プラットフォームの交差点における最先端の問題に焦点を当てています。 ジェイソンは自由時間には、家族と過ごしたり、読書、自然の中で過ごすこと、ボードゲームをしたり、あらゆる種類の創造的な活動を楽しんでいます。
ブライアンムーア Voxel51 の共同創設者兼 CTO であり、技術戦略とビジョンを主導しています。 彼はミシガン大学で電気工学の博士号を取得しており、そこでは大規模な機械学習問題に対する効率的なアルゴリズム、特にコンピューター ビジョン アプリケーションに重点を置いて研究を行っていました。 自由時間には、バドミントン、ゴルフ、ハイキング、双子のヨークシャー テリアと遊ぶことを楽しんでいます。
ジューリン・バイ アマゾン ウェブ サービスのソフトウェア開発エンジニアです。 彼女は、機械学習の問題を解決するための大規模分散システムの開発に取り組んでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 未来を鋳造する w エイドリエン・アシュリー。 こちらからアクセスしてください。
- PREIPO® を使用して PRE-IPO 企業の株式を売買します。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- :持っている
- :は
- :not
- :どこ
- $UP
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- 私たちについて
- 加速する
- 加速している
- 加速器
- アクセス
- 正確な
- 正確にデジタル化
- 取得
- 活動
- 加えます
- 追加
- 住所
- 調整
- 調整
- 後
- 再び
- AI
- アレクサ
- アルゴリズム
- すべて
- ことができます
- 一人で
- 既に
- また
- Amazon
- アマゾンアレクサ
- アマゾンセージメーカー
- Amazon SageMakerグラウンドトゥルース
- Amazon Webサービス
- 間で
- an
- 分析します
- &
- 動物
- どれか
- アプリ
- 申し込み
- 申し込む
- 適切な
- です
- 整えられた
- 記事
- 物品
- AS
- 関連する
- At
- 著者
- 離れて
- AWS
- ベース
- ベース
- BE
- なぜなら
- になる
- き
- 背後に
- 舞台裏で
- さ
- 信じる
- BEST
- より良いです
- の間に
- 10億
- ボード
- ボードゲーム
- 骨
- ブートストラップ
- 両言語で
- ボックス
- ボックス
- 脳
- ブレーク
- 持って来る
- た
- 予算
- ビルド
- 建物
- 内蔵
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- 購入
- by
- 缶
- キャプチャ
- 場合
- 例
- カテゴリ
- カテゴリー
- 最高経営責任者(CEO)
- 挑戦する
- 挑戦
- チェック
- 選択する
- 明瞭
- class
- クラス
- 分類
- クリーニング
- クリア
- はっきりと
- クライアント
- クライミング
- 閉じる
- クローザー
- 服
- アパレル
- 共同創設者
- コード
- 組み合わせる
- 結合
- 会社
- 補体
- コンプリート
- 完了
- 計算
- コンピュータ
- コンピュータサイエンス
- Computer Vision
- コンピュータ ビジョン アプリケーション
- 信頼
- 確信して
- お問合せ
- 考慮
- からなる
- 領事
- 含まれています
- コンテンツ
- 中身
- 制御
- 会話
- 変換
- コピー
- 基本
- 訂正さ
- 対応する
- 費用
- コスト
- 作ります
- 作成した
- クリエイティブ
- Credentials
- CTO
- キュレーション
- キュレーション
- 現在
- カスタム
- 顧客
- Customers
- カット
- 最先端
- データ
- データセット
- 決めます
- 実証します
- デニム生地
- 深さ
- 説明
- 細部
- 検出
- Developer
- 開発
- 開発
- 異なります
- 直接に
- ディレクトリ
- ディスプレイ
- 明確な
- 配布
- 分散システム
- 異なる
- do
- そうではありません
- 犬
- すること
- 行われ
- ドント
- DOT
- ダウン
- ダウンロード
- 複製
- e
- 各
- 簡単に
- エッジ(Edge)
- 効果
- 効率的な
- 効率良く
- 電気工学
- 埋め込み
- 新興の
- 強調
- 従業員
- 力を与える
- カプセル化
- 奨励する
- end
- エンジニア
- エンジニアリング
- エンジニア
- 入力します
- 環境
- 平等
- 本質的な
- 設立
- エーテル(ETH)
- 評価します
- エバンジェリスト
- 正確に
- 例
- 既存の
- export
- かなり
- 家族
- ファン
- フィードバック
- 少数の
- フィクション
- フィールド
- フィールズ
- File
- filter
- フィルタリング
- ファイナル
- 名
- フィット
- フレキシブル
- フォーカス
- 焦点を当て
- 焦点を当てて
- フォロー中
- フォーム
- 形式でアーカイブしたプロジェクトを保存します.
- 幸いにも
- 設立
- 4
- 無料版
- から
- 完全に
- 機能性
- Games
- 一般的用途
- 生成する
- 生成された
- 取得する
- GitHubの
- 与える
- 与えられた
- 目標
- ゴルフ
- 良い
- でログイン
- 大きい
- グリッド
- 陸上
- グループ
- ガイド
- ハッピー
- 持ってる
- he
- 高さ
- 助けます
- 助けました
- 役立つ
- ことができます
- こちら
- 高品質
- 高解像度の
- 最高
- 非常に
- ハイキング
- 彼の
- 保持している
- 認定条件
- How To
- しかしながら
- HTML
- HTTP
- HTTPS
- 人間
- i
- IAM
- ID
- 識別する
- 識別
- イド
- if
- 画像
- 画像
- 影響
- import
- 改善
- in
- その他の
- 含めて
- 間違って
- 培養
- 情報
- 初期
- 当初
- install
- インストールする
- を取得する必要がある者
- 説明書
- インテリジェンス
- 交差点
- に
- IT
- ITS
- ジャージー
- ジョブ
- 参加
- ジョイント
- JSON
- ただ
- キープ
- 保管
- ラベル
- ラベリング
- ラベル
- 言語
- 大規模
- 起動する
- 発射
- つながる
- リード
- LEARN
- 学習
- 最低
- ツェッペリン
- 左
- ことができます
- 図書館
- 生活
- ような
- 可能性が高い
- LIMIT
- 限定的
- LINE
- ライン
- リスト
- リスト
- <font style="vertical-align: inherit;"><font style="vertical-align: inherit;">アップロード履歴
- 少し
- 命
- 負荷
- 見て
- 探して
- たくさん
- ロー
- 機械
- 機械学習
- 製
- マジック
- make
- 作る
- 管理します
- マネージド
- 管理
- マネージャー
- 多くの
- 地図
- 市場
- マーケティング
- 一致
- マッチング
- 実質的に
- 問題
- 五月..
- 機械的な
- メディア
- ミーティング
- Meta
- 方法
- メソッド
- ミシガン州
- Microsoft
- マイクロソフトチーム
- かもしれない
- 最小
- ML
- モバイル
- モバイルアプリ
- モデル
- モジュール
- 他には?
- 最も
- ずっと
- の試合に
- ミュージシャン
- しなければなりません
- 名
- 名前付き
- 名
- ナチュラル
- 自然言語
- 自然
- 近く
- 必ずしも
- 必要
- 必要
- ニーズ
- 新作
- 著しく
- 概念
- 今
- ニュアンス
- 数
- オブジェクト
- オブジェクト検出
- オブジェクト
- of
- 公式
- on
- かつて
- ONE
- オンライン
- の
- 開いた
- オープンソース
- 業務執行統括
- 機会
- オプション
- or
- 整理
- オリジナル
- OS
- その他
- その他
- 私たちの
- でる
- 概説
- 出力
- が
- 自分の
- 所有する
- パック
- 対になった
- 部
- 特定の
- 過去
- path
- パターン
- パターン
- 完璧
- パフォーマンス
- 人
- カスタマイズ
- 物質の相
- 物理的な
- 選ぶ
- ピクチャー
- PLAID
- シンプルスタイル
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 再生
- ポイント
- 人口
- 可能
- ポスト
- 電力
- 練習
- 予測
- 予測
- 予測
- プレビュー
- 前
- 前に
- 印刷物
- 事前の
- プライベート
- 多分
- 問題
- プロセス
- プロダクト
- 製品管理
- プロダクトマネージャー
- 製品
- 東京大学大学院海洋学研究室教授
- プロジェクト
- 財産
- プロスペクティブ
- プロトタイプ
- 提供します
- 提供
- 提供
- 公共
- パンチ
- 目的
- Python
- 量子
- 質問
- すぐに
- 範囲
- むしろ
- リーディング
- 準備
- 推奨する
- 提言
- 減らします
- 電話代などの費用を削減
- 削減
- 相対的に
- リリース
- 関連した
- 削除します
- 代表者
- 表します
- の提出が必要です
- 研究
- 研究者
- 解像度
- 制限する
- 結果
- 結果として
- 結果
- 小売
- return
- レビュー
- 取り除きます
- ロボット工学
- 堅牢な
- 職種
- 大体
- 行
- 台無しにする
- ランニング
- セージメーカー
- 前記
- salesforce
- 同じ
- サムスン
- Save
- シーン
- 科学
- サイエンスフィクション
- 科学者たち
- スコア
- シームレス
- 二番
- セクション
- セクション
- 思われる
- と思われる
- 選択
- センス
- 別
- サービス
- サービス
- セッション
- セッションに
- シェアする
- 彼女
- すべき
- 表示する
- 作品
- YES
- 同様の
- 簡単な拡張で
- より小さい
- So
- ソフトウェア
- ソフトウェア開発
- 解決する
- 一部
- 誰か
- 何か
- スペース
- 過ごす
- 支出
- split
- 分割
- スタンフォード
- start
- 開始
- 起動
- スタートアップ
- 起動アクセラレーター
- 最先端の
- ステップ
- まだ
- ストレージ利用料
- 店舗
- 戦略
- スタイル
- 概要
- サポート
- システム
- 取る
- 仕事
- チーム
- 技術的
- TechStars
- 伝える
- テンプレート
- test
- より
- それ
- アプリ環境に合わせて
- それら
- その後
- 理論的な
- そこ。
- ボーマン
- 彼ら
- 物事
- 考える
- サードパーティ
- この
- 数千
- しきい値
- 介して
- 投げる
- 時間
- 〜へ
- 一緒に
- ツール
- ツールキット
- top
- トップレベル
- トップス
- トータル
- 触れ
- 追跡する
- トレーニング
- 訓練された
- トレーニング
- 最適化の適用
- 透明性
- true
- 真実
- 順番
- 2
- type
- 下
- わかる
- ユニーク
- 大学
- ミシガン大学
- アップデイト
- us
- つかいます
- 使用事例
- 中古
- ユーザー
- users
- 価値観
- 多様
- さまざまな
- ベンダー
- 確認する
- 非常に
- 、
- 詳しく見る
- バーチャル
- ビジョン
- 欲しいです
- ました
- we
- ウェブ
- Webサービス
- WELL
- した
- この試験は
- いつ
- かどうか
- which
- Wikipedia
- 意志
- 以内
- 無し
- レディース
- 言葉
- 仕事
- 働いていました
- 労働者
- 労働人口
- 作品
- 世界の
- 不安
- でしょう
- 書きます
- X
- 貴社
- あなたの
- ゼファーネット
- 〒
- ZOO