概要
Confluence はアトラシアンが開発したコラボレーション ツールで、チームが効率的にコラボレーションして知識を共有できるように設計されています。 現代のワークスペースでは、デジタルで共同作業できる機能は非常に貴重です。 Confluence は、チームが XNUMX か所でプロジェクトを作成、共有、共同作業できるプラットフォームを提供することでこれを促進します。 Confluence は単なるコラボレーションを超えて、リアルタイム編集、他のアトラシアン製品との統合、ユーザーフレンドリーなインターフェイスなどの機能で傑出しており、多くの組織に好まれる選択肢となっています。
Confluence の組み込み検索機能の使用に関するチュートリアル
Confluence では、情報または特定のアイテムの検索は簡単ですが、限定的な機能です。 Confluence の検索機能を最大限に活用する方法は次のとおりです。
1. 基本的な検索:
基本的な検索を開始するには:
- ヘッダーにある虫眼鏡アイコンをクリックするか、単にショートカットを使用します
Shift + /をクリックして検索フィールドに焦点を当てます。 - ページの上部に表示される検索バーにクエリを入力します。 入力すると、Confluence はライブ検索結果を提供し、サイトで利用可能なコンテンツに基づいて提案を行います。
2.高度な検索:
さらに絞り込んだ結果を得るには、高度な検索にアクセスしてください。
- 虫眼鏡アイコンをクリックし、検索バーの横にある「詳細検索」をクリックするか、ショートカットを使用します。
Shift + /続いa. - ここでは、コンテンツの種類 (ページ、ブログ、添付ファイルなど)、スペース、投稿者、日付範囲などのさまざまな基準に基づいて検索をフィルタリングできます。
3. 検索構文の使用:
Confluence は、検索を絞り込むのに役立つさまざまな検索構文をサポートしています。
- 引用符: 完全に一致する語句を検索するには、引用符を使用します。 たとえば「会議メモ」。
- ワイルドカード: アスタリスクを使用します
*単語内の任意の数の文字を表すワイルドカードとして使用します。 - ブール演算子: 使用
AND,OR,NOT用語を結合または除外します。 - 近接検索: チルダを使用します
~数値の後に続けて、一定の距離内にある単語を検索します。 例えば「アニュアルレポート」~10. - フィールド検索: 次のような構文を使用して特定のフィールド内を検索します。
title:,text:,creator:,modifier:とりわけ。
4. 添付ファイルの検索:
特定の添付ファイルを探す場合:
- MFAデバイスに移動する
Search > Advanced Search. - 「タイプ」セクションで「添付ファイル」を選択します。
- 検索構文を利用する
/.*<attachment type>.*/。 たとえば、PNG ファイルを検索するには、次のようにします。/.*png.*/.
5. データベース検索 (サーバーおよびデータセンター展開の場合):
Confluence データベースにアクセスできるユーザーは、特定の SQL クエリを使用して、特定の添付ファイルの種類を検索できます。 たとえば、すべての PNG 添付ファイルを検索するには、次の SQL クエリを使用できます。
select c.TITLE as Attachment_Name, s.spacename,
c2.TITLE as Page_Title, 'http://<confluence_base_url>/pages/viewpageattachments.action?pageId='||c.PAGEID as Location
from CONTENT c
join CONTENT c2 ON c.PAGEID = c2.CONTENTID
join SPACES s on c2.SPACEID = s.SPACEID
where c.CONTENTTYPE = 'ATTACHMENT' and c.title like '%.png%';
SQL クエリは、検索している添付ファイルの種類に基づいて調整できます。
6. 添付ファイル フォルダーの検索 (特定のプラットフォーム):
特定のプラットフォームでは、Confluence の添付ファイル フォルダー内で Unix 検索構文を直接使用して、特定のファイル タイプを検索できます。
find /<confluence_home>/attachments -type f | xargs file | grep PNG
これにより、Confluence インスタンスの添付ファイル ディレクトリ内のすべての PNG ファイルが検索され、一覧表示されます。
これらの各メソッドは、異なるレベルの粒度と検索制御を提供し、Confluence で必要なものを正確に見つけることができます。
これらの記事を読むことで、Confluence の組み込み検索をさらに詳しく調べることができます。
Confluence の組み込み検索機能の欠点
Confluence の検索に固有の複雑さは、Google などの検索エンジンとは異なり、検索クエリのコンテキストの本質を利用できないことが主な原因です。 課題の内訳は次のとおりです。
- 検索クエリの繰り返し: 過去の検索から得られるコンテキスト データが最小限であるため、検索履歴内で同一の検索クエリが限定的に出現すると、検索結果の精度が損なわれることがよくあります。 これは、ユーザーが更新された情報や最新の情報を検索している場合に特に問題となり、古い情報や関連性の低い結果に埋もれてしまう可能性があります。
- 意味の理解: 同義語を識別したりストップワードを無視したりする機能がプラットフォームに欠けているため、関連性の低いコンテンツが提案されることがよくあります。 たとえば、Information Technology の頭字語としての「IT」と代名詞としての「it」を区別するのは難しい場合があります。 さらに、この意味的理解の欠如は、一般的な業界用語や頭字語が検索クエリで使用されるときに混乱を引き起こす可能性があります。
- 完全一致のジレンマ: ストップ ワードを排除しようとすると、Confluence は完全一致検索を妨害する場合があり、タスクがさらに困難になります。 これにより、ユーザーが探している正確なドキュメントや情報を見つけられなくなり、生産性が低下する可能性があります。
- 万能のジレンマ: 組織構造、内部情報、ユーザーの意図が多様であるため、よりパーソナライズされた検索システムが必要です。 初歩的な機械学習 (ML) アプローチは、ユーザー インタラクション データを活用して時間の経過とともに検索の関連性を絞り込むことで、検索エクスペリエンスを向上させる可能性があります。 ML について議論すると、Confluence の検索をより直感的でユーザー中心にするために、協調フィルタリングやディープ ラーニングなどのアルゴリズムが検討される可能性があります。
簡単に言うと、アリスが今日トピック (X としましょう) を検索し、役立つ文書 (doc3) を見つけた場合、明日ボブが同じトピック (X) を検索すると、doc3 が検索結果の上位に表示されるはずです。アリスに役立つ。 これを実現するには、システムはユーザーがどのドキュメントが役立つと判断したかを追跡する必要があります。 ただし、この追跡はプライバシーを尊重した方法で行う必要があるため、特定のドキュメントを見ることになっている人だけがドキュメントを見ることができます。 また、このプロセスではメモリやストレージなどのコンピュータ リソースが大量に消費される可能性があるため、懸念される場合があります。 組織によっては、これを管理するための追加のリソースやスタッフがいない可能性があるため、時間の経過とともに改善されないかもしれないが、保守が容易で、メモリ不足などのさらなる頭痛の種を与えない、よりシンプルなシステムを好む場合があります。
Confluence を検索する Nanonets Confluence ボットを使用する
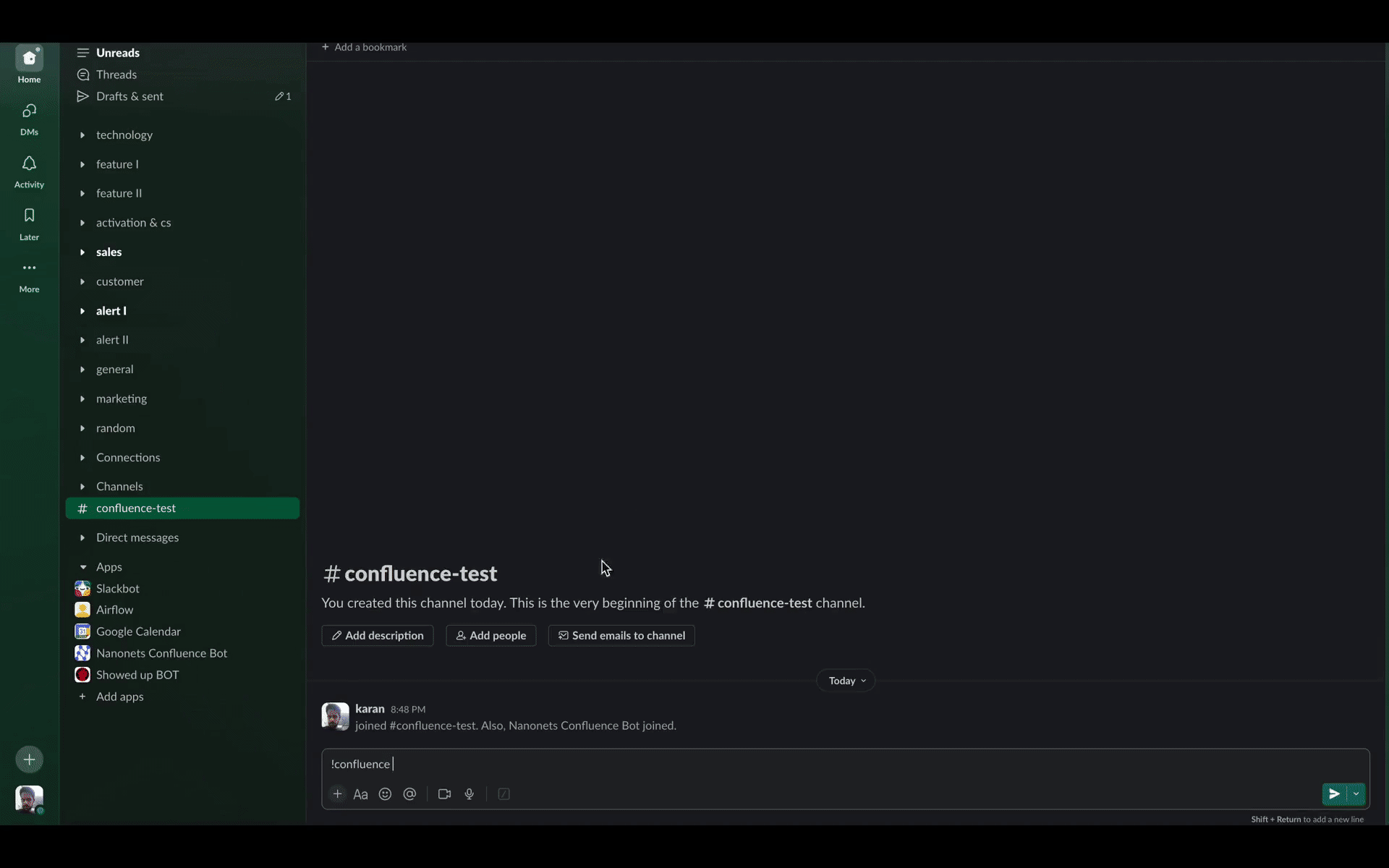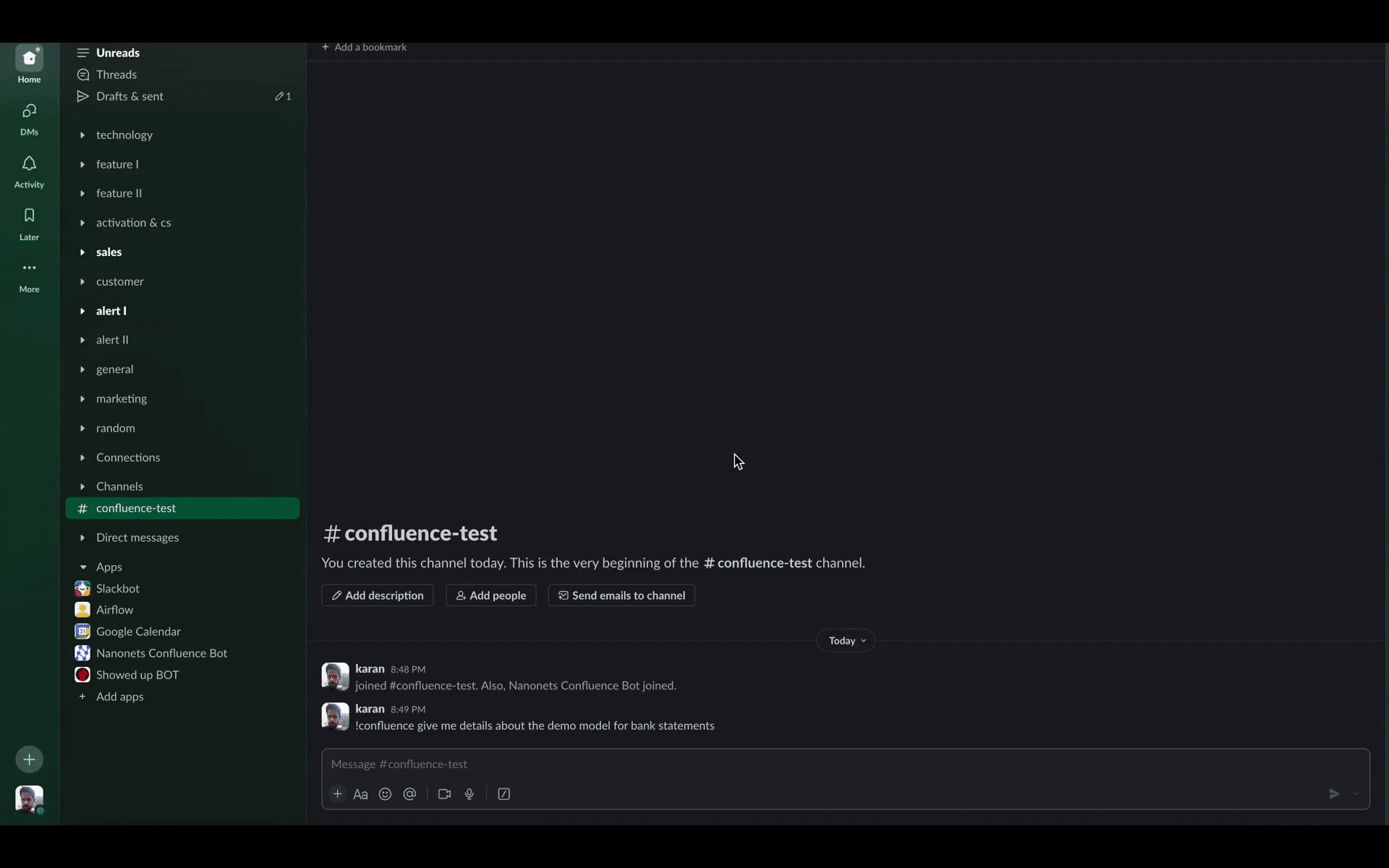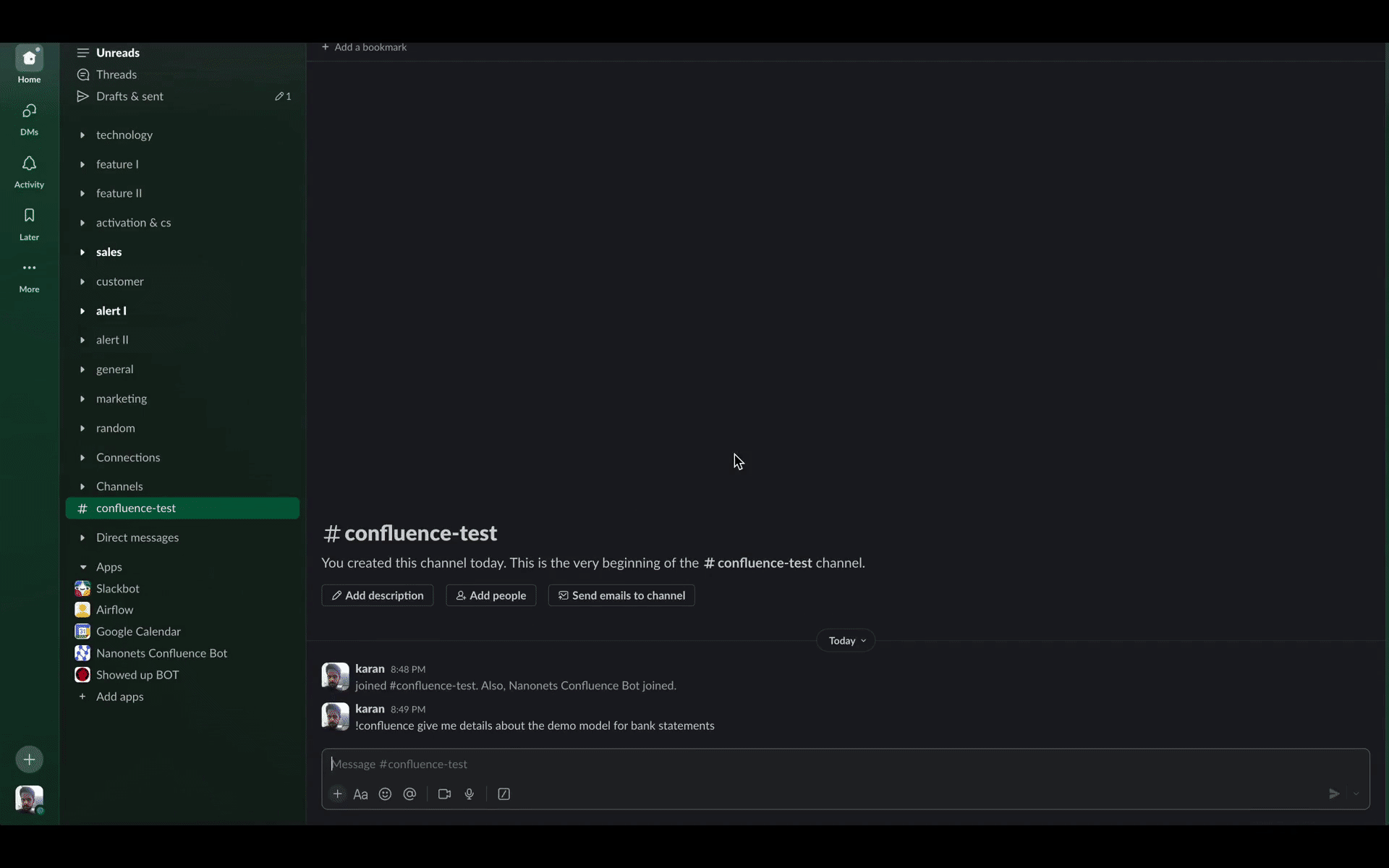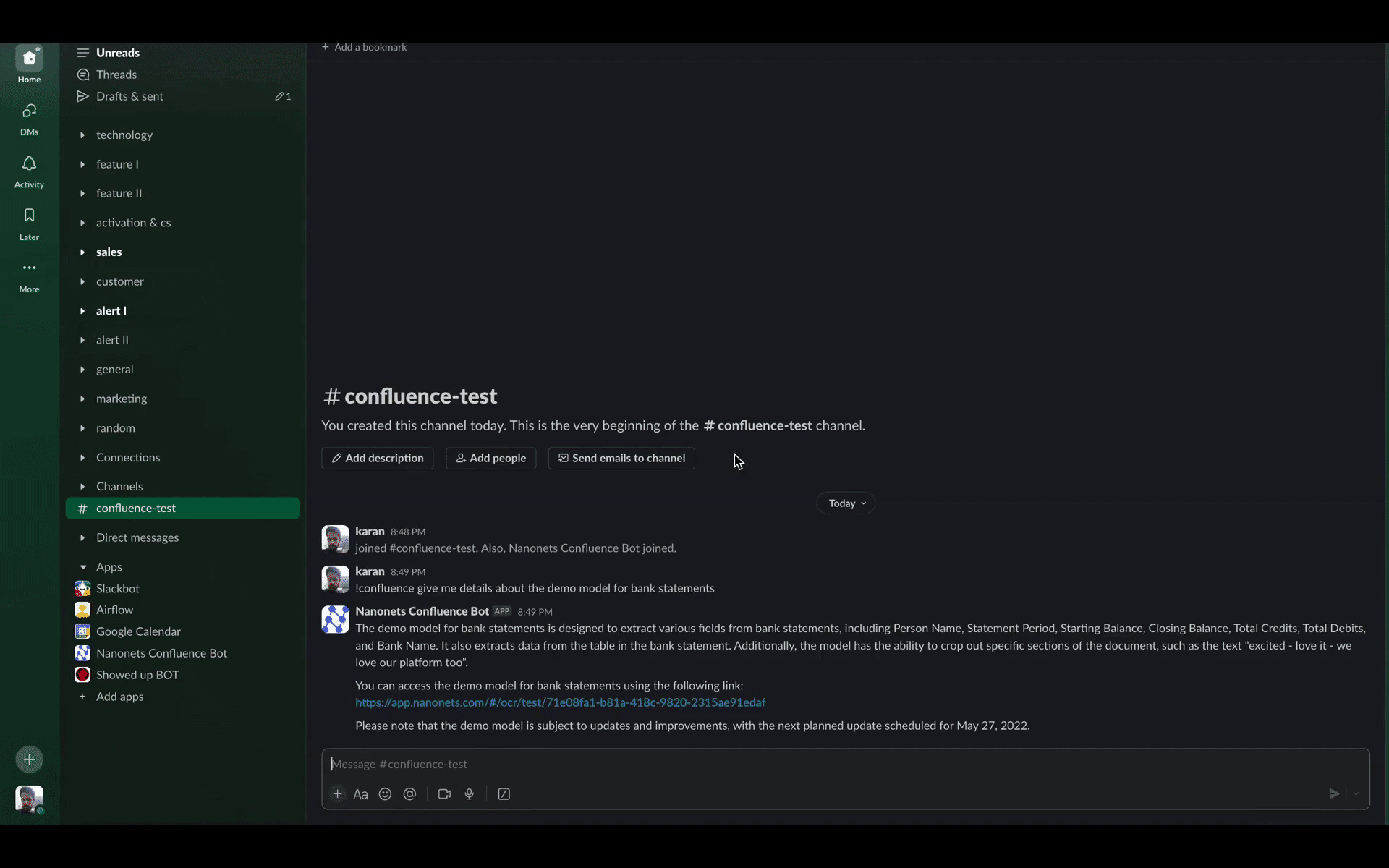
Nanonets は、Confluence の検索機能で遭遇する前述の課題に対する革新的なソリューションを導入します。 カスタム LLM ベースのチャットボットをアシスタントとして採用すると、ギャップを大幅に埋め、ユーザーの検索エクスペリエンスを向上させることができます。 その方法は次のとおりです。
- 文脈理解: 従来の検索方法とは異なり、チャットボットは検索クエリのコンテキストを理解します。 たとえば、「Java」を検索すると、島やコーヒーではなく、プログラミング言語に関連した結果が表示されます。 当社のチャットボットの背後にある LLM (言語モデル) テクノロジーは、ニュアンスやコンテキストをよりよく理解できるように特に調整されており、より正確で関連性の高い検索結果が提供されます。
- ユーザーインタラクションから学ぶ: 私たちのチャットボットは、ユーザーが検索エンジンとどのように対話するかから学習できます。 ドキュメントが特定のクエリを介して頻繁にアクセスされる場合、そのドキュメントは、「アジャイル手法」で検索されたときに人気が高まるのと同様に、今後の同様の検索で上位にランク付けされます。 時間が経つにつれて、この学習はユーザーのニーズをより正確に予測できるように進化し、検索プロセスがより直感的になる可能性があります。
- 意味論的な関係: LLM ベースのチャットボットは同義語や関連用語を認識できるため、検索候補が向上します。 たとえば、「バグ追跡」を検索すると、「問題追跡」や「エラー追跡」に関連するドキュメントも表示されます。
- ユーザーが提案したコンテンツ: ユーザーは特定の検索クエリに対してコンテンツを提案できるため、時間の経過とともに検索データベースが強化されます。 これにより、「スクラムの実践」に関するクエリに対してドキュメントが見やすくなるなど、ドキュメントが見つけやすくなります。
- アクセス権管理: 承認されたユーザーのみが検索中に特定のドキュメントにアクセスできるようにします。 たとえば、XNUMX つのプロジェクトに機密ドキュメントがある場合、検索では検索者自身のプロジェクトのドキュメントのみが表示され、他のプロジェクトのドキュメントは機密のままになります。
- リソースの最適化: 当社のソリューションは効率的に動作し、時間とコストの両方を節約します。これは、業務を合理化し、業務経費を削減したいと考えている組織にとって非常に重要です。
Nanonets Confluence ボットの Slack 統合
当社のチャットボットには、すぐに使用できる Slack 統合が付属しています。 チャットボットの準備ができたら、Slack ワークスペースを認証し、数回クリックするだけで統合を構成できます。 完了すると、アプリを切り替えることなく、Slack アプリから直接ボットと質問したり、Confluence スペースに関する詳細な会話をしたりできるようになります。 この統合により、統合されたデジタル ワークスペースが促進され、コミュニケーションとコラボレーションが合理化され、生産性とユーザー満足度が向上します。
以下のデモをご覧ください。
まとめ
アトラシアンの Confluence はデジタル チームワークを促進しますが、基本的な検索機能も備えています。 Nanonets Confluence ボットは、コンテキストを理解し、ユーザー インタラクションから学習することでこれを大幅に改善し、検索をより直感的にします。 また、ドキュメント アクセスのセキュリティも維持され、許可されたユーザーのみが特定の情報にアクセスできるようになります。 さらに、Slack の統合により、統合されたデジタル ワークスペースが促進され、生産性とユーザー満足度が向上します。 これらの改善により、Nanonets Confluence ボットは Confluence での検索エクスペリエンスを改良し、ユーザーとチームにとってより効果的なコラボレーション環境に貢献します。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://nanonets.com/blog/search-in-confluence/
- :持っている
- :は
- :not
- :どこ
- $UP
- a
- 能力
- できる
- 私たちについて
- アクセス
- アクセス
- 精度
- 正確な
- 略語
- Action
- NEW
- さらに
- 調整
- 高度な
- 使い勝手のいい
- アルゴリズム
- ショット
- すべて
- 許可
- また
- 間で
- an
- および
- 毎年恒例の
- 予想する
- どれか
- アプリ
- 登場する
- アプローチ
- アプリ
- です
- 物品
- AS
- 頼む
- アシスタント
- At
- アトラシアン
- 試みる
- 認証
- 許可
- 利用できます
- バー
- ベース
- 基本
- BE
- なぜなら
- になる
- になる
- 背後に
- 以下
- より良いです
- の間に
- 越えて
- ブログ
- ボブ
- ロボット
- 両言語で
- 内訳
- BRIDGE
- 持って来る
- バグ
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 缶
- 機能
- 容量
- センター
- 一定
- 課題
- 挑戦
- 文字
- チャットボット
- チャットボット
- 選択
- コーヒー
- 協力します
- 環境、テクノロジーを推奨
- 共同
- 組み合わせる
- 来ます
- コマンドと
- コミュニケーション
- 複雑さ
- コンピュータ
- 懸念
- 結論
- 合流
- 混乱
- コンテンツ
- コンテキスト
- 文脈上の
- 貢献
- 貢献者
- コントロール
- 会話
- 費用
- 可能性
- カップル
- 作ります
- 基準
- 重大な
- カスタム
- データ
- データセンター
- データベース
- 日付
- 深いです
- 深い学習
- より深い
- 掘り下げる
- デモ
- 配備
- 設計
- 詳細な
- 発展した
- 異なります
- デジタル
- デジタル処理で
- 直接に
- 識別する
- 議論
- 距離
- 多様性
- ドキュメント
- ドキュメント
- そうではありません
- 行われ
- ダウン
- 間に
- 各
- 容易
- 簡単に
- 編集
- 効果的な
- 効率良く
- 排除する
- 埋め込まれた
- 採用
- エンジン
- エンジン
- 高めます
- 強化
- 確保
- 確保する
- 環境
- エラー
- 特に
- 本質
- 等
- エーテル(ETH)
- さらに
- 進化
- 正確に
- 例
- 経費
- 体験
- 調査済み
- 余分な
- 促進する
- 特徴
- 特徴
- フィールド
- フィールズ
- File
- filter
- フィルタリング
- もう完成させ、ワークスペースに掲示しましたか?
- 発見
- 発見
- フォーカス
- 続いて
- フォロー中
- から
- 機能性
- 未来
- ギャップ
- GIF
- 与える
- ガラス
- でログイン
- 起こる
- 持ってる
- 持って
- 頭痛
- 助けます
- 役立つ
- こちら
- より高い
- history
- 認定条件
- しかしながら
- HTTP
- HTTPS
- ICON
- 同一の
- if
- 無視する
- 改善します
- 改善
- 向上させる
- 改善
- in
- できないこと
- 産業を変えます
- 情報
- 情報技術
- 固有の
- 開始する
- 統合
- 対話
- 相互作用
- 相互作用
- インタフェース
- 内部
- に
- 紹介します
- 概要
- 直観的な
- 貴重な
- 島
- 問題
- IT
- リーディングシート
- ITS
- 専門用語
- Java
- join
- キープ
- 保管
- 知識
- 欠如
- 言語
- つながる
- リード
- LEARN
- 学習
- less
- う
- レベル
- 活用
- ような
- 限定的
- リスト
- ライブ
- 場所
- 見て
- 探して
- LOOKS
- たくさん
- 機械
- 機械学習
- 維持する
- 維持
- make
- 作る
- 作成
- 管理します
- 管理
- 多くの
- 一致
- 五月..
- ご相談
- メモリ
- 単なる
- 方法論
- メソッド
- かもしれない
- 最小限の
- ML
- モダン
- 他には?
- さらに
- 最も
- ずっと
- 必要
- ニーズ
- 次の
- ノート
- ニュアンス
- 数
- of
- 提供すること
- 頻繁に
- on
- かつて
- ONE
- の
- 操作する
- オペレーショナル
- 業務執行統括
- 演算子
- 最適化
- or
- 組織の
- 組織
- その他
- その他
- 私たちの
- でる
- が
- 自分の
- ページ
- ページ
- 特定の
- 特に
- 過去
- のワークプ
- 実行する
- カスタマイズ
- 場所
- プラットフォーム
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 人気
- :
- プラクティス
- 好む
- 優先
- 現在
- 主に
- プライバシー
- プロセス
- 生産性
- 製品
- プログラミング
- プロジェクト
- プロジェクト(実績作品)
- 促進する
- 提供します
- は、大阪で
- 提供
- クエリ
- 質問
- 範囲
- ランク
- RE
- リーディング
- 準備
- への
- 最近
- 認識する
- 減らします
- リファイン
- 洗練された
- 関連する
- の関係
- 関連した
- レポート
- 表す
- リソース
- 敬意
- 結果
- 権利
- ランニング
- s
- 同じ
- 満足
- 節約
- 言う
- を検索
- 検索エンジン
- 検索エンジン
- 検索
- 検索
- セクション
- セキュリティ
- シェアする
- すべき
- 表示する
- 著しく
- 同様の
- 簡単な拡張で
- 単に
- ウェブサイト
- スラック
- So
- 溶液
- ソリューション
- 一部
- 時々
- スペース
- 特定の
- SQL
- スタッフ
- スタンド
- 茎
- Force Stop
- ストレージ利用料
- 簡単な
- 流線
- 合理化された
- 構造
- 示唆する
- サポート
- 想定
- スイッチ
- 構文
- テーラード
- 仕事
- チーム
- チームワーク
- テクノロジー
- 条件
- それ
- それら
- その後
- それによって
- ボーマン
- 彼ら
- この
- それらの
- 介して
- 従って
- 時間
- 役職
- 〜へ
- 今日
- 一緒に
- 明日
- ツール
- top
- トピック
- 追跡する
- 追跡
- 伝統的な
- 変形させる
- チュートリアル
- 2
- type
- 下
- わかる
- 理解する
- 理解する
- 統一
- UNIX
- 異なり、
- 更新しました
- つかいます
- 中古
- ユーザー
- ユーザー中心
- 「DeckleBenchは非常に使いやすく最適なソリューションを簡単に見つけることができるため、稼働率が向上しコストも削減した。当社の旧システムは良かったが改善は期待していなかった。
- users
- 活用する
- 利用された
- さまざまな
- 、
- VIMEO
- 目に見える
- ました
- 仕方..
- we
- この試験は
- いつ
- which
- while
- 誰
- 意志
- 以内
- 無し
- Word
- 言葉
- 仕事
- 共に働く
- X
- 貴社
- あなたの
- ゼファーネット