
著者による画像
データを分析するときに私たちが念頭に置いているのは、隠れたパターンを見つけて、意味のある洞察を抽出することです。 ML ベースの学習の新しいカテゴリ、つまり教師なし学習に入ってみましょう。この学習では、クラスタリング タスクを解決する強力なアルゴリズムの 1 つが、データ理解に革命をもたらす K-Means クラスタリング アルゴリズムです。
K-Means has become a useful algorithm in machine learning and data mining applications. In this article, we will deep dive into the workings of K-Means, its implementation using Python, and exploring its principles, applications, etc. So, let’s start the journey to unlock the secret patterns and harness the potential of the K-Means clustering algorithm.
K-Means アルゴリズムは、教師なし学習クラスに属するクラスタリング問題を解決するために使用されます。このアルゴリズムを利用すると、観測値の数を K 個のクラスターにグループ化できます。
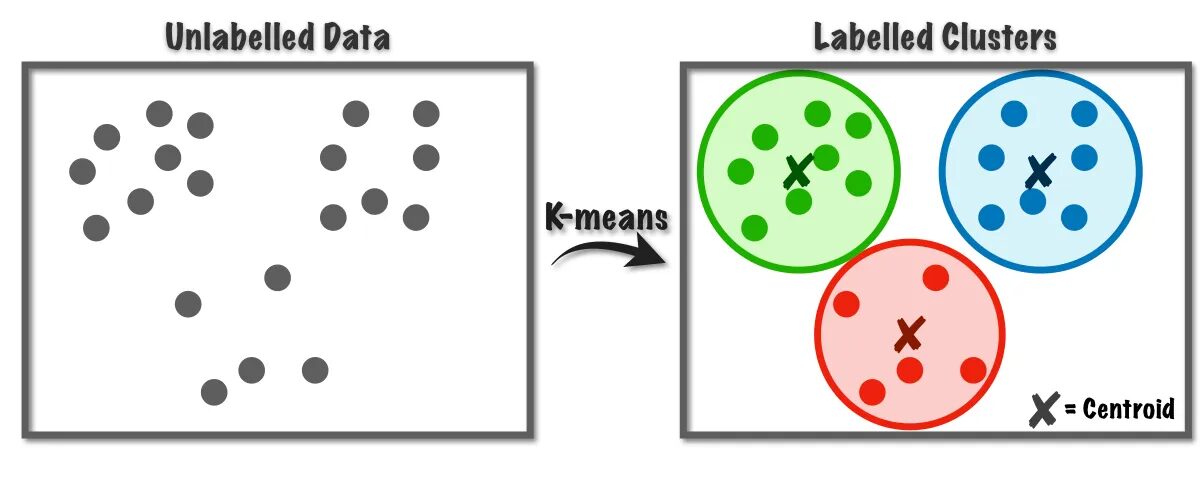
図 1 K 平均法アルゴリズムの動作 |からの画像 データサイエンスに向けて
このアルゴリズムは内部でベクトル量子化を使用しており、これによりデータセット内の各観測値を最小距離のクラスターに割り当てることができます。これがクラスタリング アルゴリズムのプロトタイプです。このクラスタリング アルゴリズムは、類似性メトリクスに基づいてデータを K 個のクラスターに分割するためのデータ マイニングと機械学習で一般的に使用されます。したがって、このアルゴリズムでは、観測値とそれに対応する重心の間の距離の二乗和を最小限に抑える必要があり、その結果、最終的には個別で均質なクラスターが得られます。
K 平均法クラスタリングの応用
このアルゴリズムの標準的なアプリケーションのいくつかを次に示します。 K 平均法アルゴリズムは、クラスタリング関連の問題を解決するための産業用ユースケースで一般的に使用される手法です。
- 顧客セグメンテーション: K-means クラスタリングでは、興味に基づいてさまざまな顧客をセグメント化できます。銀行、通信、電子商取引、スポーツ、広告、販売などに適用できます。
- ドキュメントのクラスタリング: この手法では、一連の文書から類似した文書をクラブ化し、同じクラスター内に類似した文書が生成されます。
- レコメンデーション エンジン: 場合によっては、K 平均法クラスタリングを使用して推奨システムを作成できます。たとえば、友達に曲を勧めたいとします。その人が好きな曲を調べ、クラスタリングを使用して類似した曲を見つけ、最も類似した曲を推奨できます。
皆さんもすでに思いついたアプリケーションが他にもたくさんあると思います。おそらくこの記事の下のコメント セクションで共有しているでしょう。
このセクションでは、主にデータ サイエンス プロジェクトで使用される Python を使用して、データセットの 1 つに K 平均法アルゴリズムの実装を開始します。
1. 必要なライブラリと依存関係をインポートする
まず、NumPy、Pandas、Seaborn、Marplotlib など、K 平均法アルゴリズムの実装に使用する Python ライブラリをインポートしましょう。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb2. データセットの読み込みと分析
このステップでは、学生データセットを Pandas データフレームに保存して読み込みます。データセットをダウンロードするには、リンクを参照してください。 こちら.
問題の完全なパイプラインを以下に示します。

図 2 プロジェクトのパイプライン |著者による画像
df = pd.read_csv('student_clustering.csv')
print("The shape of data is",df.shape)
df.head()3. データセットの散布図
ここで、モデリングのステップとしてデータを視覚化することになります。そのため、matplotlib を使用して散布図を描画し、クラスタリング アルゴリズムがどのように機能するかを確認し、さまざまなクラスターを作成します。
# Scatter plot of the dataset
import matplotlib.pyplot as plt
plt.scatter(df['cgpa'],df['iq'])
出力:
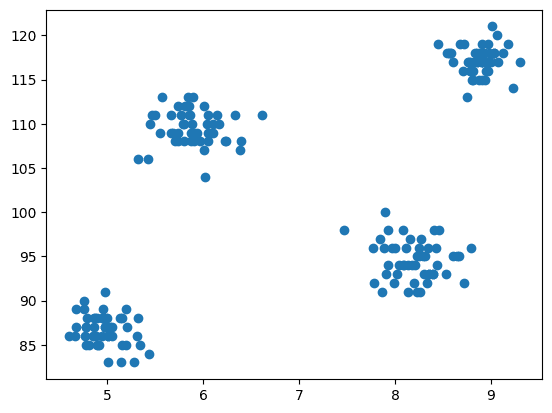
図3 散布図 |著者による画像
4. Scikit-learn のクラスタークラスから K-Means をインポートする
ここで、K-Means クラスタリングを実装する必要があるため、最初にクラスター クラスをインポートし、次にそのクラスのモジュールとして KMeans を用意します。
from sklearn.cluster import KMeans5. エルボー法を使用して K の最適値を求める
このステップでは、アルゴリズムを実装しながら、ハイパーパラメーターの 1 つである K の最適な値を見つけます。 K 値は、データセットに対して作成する必要があるクラスターの数を示します。この値を直感的に見つけることは不可能であるため、最適な値を見つけるために、WCSS(クラスター二乗和内) とさまざまな K 値の間のプロットを作成し、その K を選択する必要があります。 WCSS の最小値が得られます。
# create an empty list for store residuals
wcss = [] for i in range(1,11): # create an object of K-Means class km = KMeans(n_clusters=i) # pass the dataframe to fit the algorithm km.fit_predict(df) # append inertia value to wcss list wcss.append(km.inertia_)
ここで、エルボ プロットをプロットして、K の最適な値を見つけてみましょう。
# Plot of WCSS vs. K to check the optimal value of K
plt.plot(range(1,11),wcss)
出力:
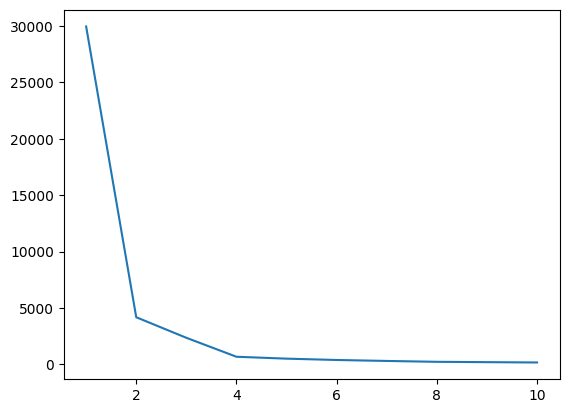
図4 エルボプロット |著者による画像
上のエルボ プロットから、K=4 であることがわかります。 WCSS の値にはディップがあります。つまり、最適値として 4 を使用すると、その場合、クラスタリングによって良好なパフォーマンスが得られます。
6. K 平均アルゴリズムを K の最適値に適合させます。
K の最適な値を見つける作業は完了しました。次に、すべての特徴を含む完全なデータセットを格納する X 配列を作成するモデリングを実行しましょう。教師なし問題であるため、ここではターゲット ベクトルと特徴ベクトルを分離する必要はありません。その後、選択した K 値を使用して KMeans クラスのオブジェクトを作成し、それを提供されたデータセットに適合させます。最後に、形成されたさまざまなクラスターの平均を示す y_means を出力します。
X = df.iloc[:,:].values # complete data is used for model building
km = KMeans(n_clusters=4)
y_means = km.fit_predict(X)
y_means7. 各カテゴリのクラスタ割り当てを確認する
データセット内のすべてのポイントがどのクラスターに属しているかを確認してみましょう。
X[y_means == 3,1]
これまで、重心の初期化には K-Means++ 戦略を使用してきましたが、今度は K-Means++ の代わりにランダムな重心を初期化し、同じプロセスに従って結果を比較してみましょう。
km_new = KMeans(n_clusters=4, init='random')
y_means_new = km_new.fit_predict(X)
y_means_new
一致する値がいくつあるかを確認します。
sum(y_means == y_means_new)8. クラスターの視覚化
各クラスターを視覚化するために、それらを軸上にプロットし、形成された 4 つのクラスターを簡単に確認できる異なる色を割り当てます。
plt.scatter(X[y_means == 0,0],X[y_means == 0,1],color='blue')
plt.scatter(X[y_means == 1,0],X[y_means == 1,1],color='red') plt.scatter(X[y_means == 2,0],X[y_means == 2,1],color='green') plt.scatter(X[y_means == 3,0],X[y_means == 3,1],color='yellow')
出力:
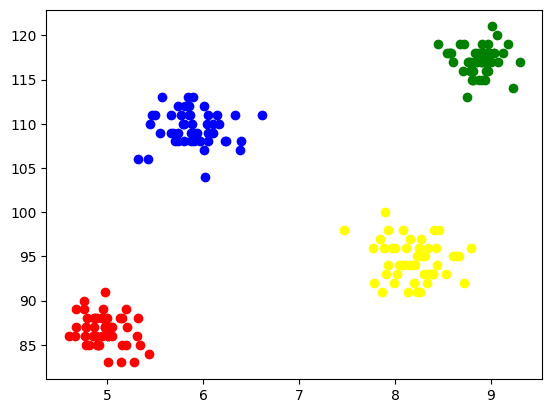
図 5 形成されたクラスターの視覚化 |著者による画像
9. 3D データの K 平均法
前のデータセットには 2 つの列があるため、2 次元の問題が発生します。次に、3 次元の問題に対して同じ一連の手順を利用して、n 次元データのコードの再現性を分析してみます。
# Create a synthetic dataset from sklearn
from sklearn.datasets import make_blobs # make synthetic dataset
centroids = [(-5,-5,5),(5,5,-5),(3.5,-2.5,4),(-2.5,2.5,-4)]
cluster_std = [1,1,1,1]
X,y = make_blobs(n_samples=200,cluster_std=cluster_std,centers=centroids,n_features=3,random_state=1)
# Scatter plot of the dataset
import plotly.express as px
fig = px.scatter_3d(x=X[:,0], y=X[:,1], z=X[:,2])
fig.show()
出力:
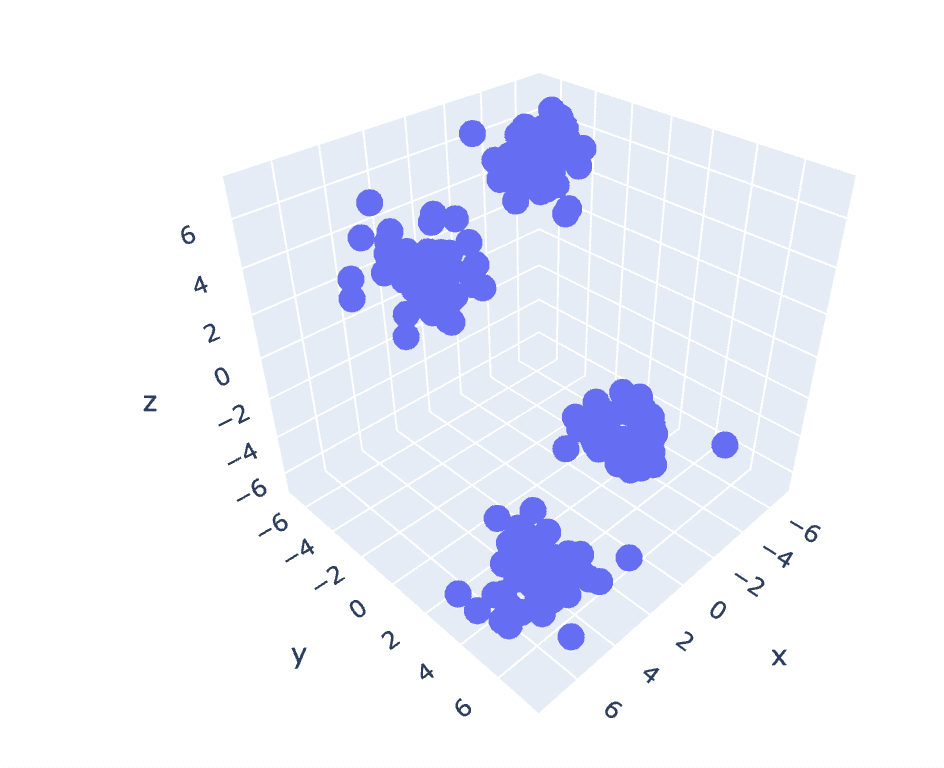
図 6 3 次元データセットの散布図 |著者による画像
wcss = []
for i in range(1,21): km = KMeans(n_clusters=i) km.fit_predict(X) wcss.append(km.inertia_) plt.plot(range(1,21),wcss)
出力:

図7 エルボプロット |著者による画像
# Fit the K-Means algorithm with the optimal value of K
km = KMeans(n_clusters=4)
y_pred = km.fit_predict(X)
# Analyse the different clusters formed
df = pd.DataFrame()
df['col1'] = X[:,0]
df['col2'] = X[:,1]
df['col3'] = X[:,2]
df['label'] = y_pred fig = px.scatter_3d(df,x='col1', y='col2', z='col3',color='label')
fig.show()
出力:
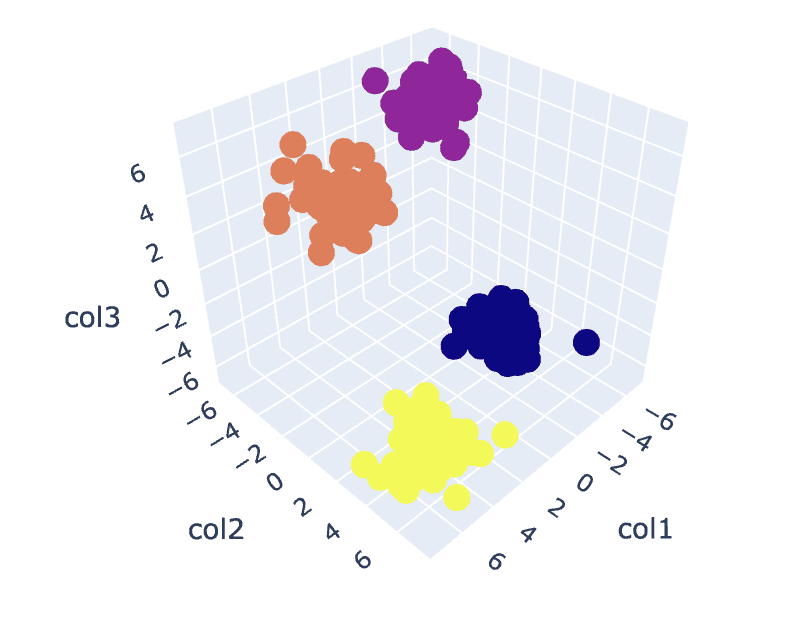
図8。クラスターの視覚化 |著者による画像
You can find the complete code here – コラボノート
これで議論は終わりです。 K-Means の仕組み、実装、およびアプリケーションについて説明しました。結論として、クラスタリング タスクの実装は、データセットの観察をグループ化するためのシンプルで直感的なアプローチを提供する教師なし学習のクラスで広く使用されているアルゴリズムです。このアルゴリズムの主な利点は、アルゴリズムを実装しているユーザーの助けを借りて、選択された類似性メトリクスに基づいて観測値を複数のセットに分割することです。
ただし、最初のステップでの重心の選択に基づいて、アルゴリズムは異なる動作をし、局所最適または大域最適に収束します。したがって、アルゴリズムを実装するクラスターの数の選択、データの前処理、外れ値の処理などが、良好な結果を得るために重要です。しかし、このアルゴリズムの限界の裏側を観察すると、K 平均法はさまざまな分野で探索的なデータ分析やパターン認識に役立つ手法です。
アーリア人ガーグ B.Techです。 電気工学科の学生で、現在は学部の最終学年です。 彼の関心は、Web 開発と機械学習の分野にあります。 彼はこの興味を追求してきており、これらの方向でもっと働きたいと思っています.
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 自動車/EV、 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- ブロックオフセット。 環境オフセット所有権の近代化。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/07/clustering-unleashed-understanding-kmeans-clustering.html?utm_source=rss&utm_medium=rss&utm_campaign=clustering-unleashed-understanding-k-means-clustering
- :持っている
- :は
- :not
- :どこ
- 1
- 10
- 11
- 13
- 16
- 25
- 28
- 7
- 8
- 9
- a
- 上記の.
- 広告運用
- 後
- アルゴリズム
- アルゴリズム
- すべて
- 既に
- am
- an
- 分析する
- 分析
- 分析します
- 分析する
- および
- 適用された
- アプローチ
- です
- 配列
- 記事
- AS
- At
- 軸
- b
- バンキング
- ベース
- BE
- になる
- 背後に
- 以下
- の間に
- 青
- 建物
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 缶
- 場合
- 例
- カテゴリー
- チェック
- 選択する
- class
- クラブ
- クラスタ
- クラスタリング
- コード
- コラム
- comes
- 注釈
- 一般に
- 比較します
- コンプリート
- 完了
- 結論
- 対応する
- 作ります
- 重大な
- 現在
- 顧客
- Customers
- データ
- データ分析
- データマイニング
- データサイエンス
- データセット
- 深いです
- ディープダイブ
- 開発
- 異なります
- ディップ
- 方向
- 議論する
- 議論
- 距離
- 明確な
- do
- ドキュメント
- ドキュメント
- 行われ
- ダウンロード
- ドロー
- e
- eコマース
- 各
- 熱心な
- 簡単に
- 電気工学
- エンジニアリング
- エンジン
- 入力します
- 等
- 最終的に
- 例
- 探索的データ分析
- 探る
- 表現します
- エキス
- 特徴
- 特徴
- フィールド
- フィールズ
- イチジク
- ファイナル
- 最後に
- もう完成させ、ワークスペースに掲示しましたか?
- 発見
- 名
- フィット
- フォロー中
- 形成
- 友達
- から
- 与える
- 与える
- グローバル
- 行く
- 良い
- でログイン
- グリーン
- グループ
- ハンドリング
- ハーネス
- 持ってる
- 持って
- he
- 助けます
- 役立つ
- こちら
- 隠されました
- 彼の
- 認定条件
- HTTPS
- i
- if
- 画像
- 実装する
- 実装
- 実装
- import
- in
- 含めて
- を示し
- インダストリアル
- 慣性
- 洞察
- を取得する必要がある者
- 関心
- 利益
- 内部で
- に
- 直観的な
- IT
- ITS
- 旅
- JPG
- KDナゲット
- ラベル
- 学習
- ライブラリ
- ある
- 制限
- LINK
- リスト
- 負荷
- ローカル
- 見て
- 機械
- 機械学習
- メイン
- 主に
- make
- 多くの
- 一致
- matplotlib
- 意味のある
- 手段
- メトリック
- マインド
- 最小
- 鉱業
- モデリング
- モジュール
- 他には?
- 最も
- の試合に
- しなければなりません
- 必要
- 必要
- 新作
- いいえ
- 今
- 数
- numpy
- オブジェクト
- 観察する
- 入手する
- of
- on
- ONE
- もの
- 最適な
- or
- その他
- 私たちの
- パンダ
- パス
- パターン
- パターン
- パフォーマンス
- 人
- パイプライン
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポイント
- 可能
- 潜在的な
- 強力な
- 前
- 原則
- 印刷物
- 多分
- 問題
- 問題
- プロセス
- プロジェクト
- プロジェクト(実績作品)
- プロトタイプ
- 提供
- は、大阪で
- Python
- ランダム
- 認識
- 推奨する
- おすすめ
- レッド
- 研究
- 結果として
- 結果
- 革命を起こす
- s
- セールス
- 同じ
- 科学
- 海生まれ
- 秘密
- セクション
- セグメント
- セグメンテーション
- 選択
- 選択
- 選択
- 別
- セッションに
- セット
- 形状
- シェアする
- 示す
- 側
- 意味する
- 同様の
- 簡単な拡張で
- So
- 解決する
- 解決
- 一部
- スポーツ
- 正方形
- 標準
- start
- 手順
- ステップ
- 店舗
- 店舗
- 戦略
- 力
- 学生
- 確か
- 合成
- システム
- ターゲット
- タスク
- テク
- 電気通信
- それ
- アプリ環境に合わせて
- それら
- その後
- そこ。
- したがって、
- ボーマン
- もの
- この
- 考え
- 介して
- 〜へ
- 試します
- 理解する
- 解き放たれました
- アンロック
- 教師なし学習
- us
- つかいます
- 中古
- ユーザー
- 使用されます
- 活用する
- 値
- 価値観
- さまざまな
- 可視化
- vs
- 欲しいです
- we
- ウェブ
- ウェブ開発
- which
- while
- 誰
- 広く
- 意志
- 仕事
- ワーキング
- 仕組み
- 作品
- X
- 年
- 黄
- 貴社
- あなたの
- ゼファーネット








