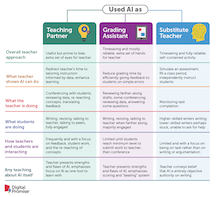
多くの人は 2020 年を忘れたがりますが、データサイエンティストは、パンデミックの影響が 2020 年のデータを異常なものにするのか、それとも高等教育におけるより永続的な変化の兆候を示すのかを判断する上で、この年を最優先に考えているでしょう。 新しい予測モデルを開発し、昨年収集したデータで既存の予測モデルを更新する際には、その影響を分析し、次に何が起こるかを予測する際にそのデータをどの程度重視するかを決定する必要があります。
越えて 昨年志願して入学した学生の数の劇的な変化、出願書類からのよく知られたデータですら利用できなくなっており、大学が志願者や帰国生がどのように行動する可能性があるかを予測することがますます困難になっています。 パンデミック中、学生が SAT または ACT を受けることが困難だったため、 多くの教育機関が検査を任意にしている。 試験データが不足し、申請や登録の数、種類、時期が大きく変動するため、高等教育業務のおなじみの年間サイクルが予測しにくくなっています。
入学担当官と登録管理者は、いくつかの疑問を自問しています。 今年は物事が新型コロナウイルス感染症以前の「通常の」パターンに戻ると期待すべきでしょうか、それともその期待を永久に変えるべきでしょうか? 入学や奨学金の基準を変更すべきでしょうか? 前例のない年が続いた後、過去のデータに基づいてトレーニングした予測モデルを捨てるべきでしょうか? また、既存のプロセスやツールを使い続ける場合、データ サイエンティストと協力してそれらを再調整して有用性を維持するにはどうすればよいでしょうか?
私は、予測モデルは依然として大学に多くの価値を提供すると信じています。 まず、過去のデータに基づいてトレーニングされたモデルは、現実が期待とどのように異なるかを理解するのに特に役立ちます。 しかし昨年は、これらのツールが「誰」が登録する可能性が最も高いか、または彼らが成功するために追加のサービスを必要とする可能性があるかについて、これらのツールが予測する「方法」と「理由」を完全に理解することがいかに重要であるかを明らかにしました。機関。
どのモデルが間違っていて、どのモデルが正しかったのか
新型コロナウイルス感染症流行前に構築したモデルを評価したところ、モデルが過去のデータで特定していた傾向と相関関係がパンデミックによって促進されたことがわかりました。 基本的に、それは正しい予測を立てましたが、レートと規模は予測していませんでした。
一例として、満たされていない経済的ニーズと学生定着率の関係が挙げられます。 経済的支援が受けられない必要がある学生は、より低い料金で再入学する傾向があります。 このパターンはパンデミック中も続いているようで、モデルは経済的な問題により次の学期に入学しないリスクが最も高い学生を多くの場合正確に特定しました。
しかし、危機の状況において、モデルは他の学生が戻ってくる可能性について過度に楽観的だった可能性もあります。 より多くの家庭の経済的将来が不確実になるにつれ、ローン、奨学金、助成金では対応できない経済的ニーズが、再入学しないという学生の決断に通常よりも大きな影響を与えた可能性があります。 これは、2020 年に全体的な定着率が多くの教育機関で予想されていたモデルよりも急激に低下した理由を説明するのに役立つ可能性があります。
より「ブラックボックス」(説明が難しい)アプローチで、どの変数を最も重視するかについて追加のコンテキストを持たずに保持可能性スコアを生成するモデルでは、現在増幅されている保持リスクに金融機関が対処するのに役立つ貴重な洞察がほとんど得られません。 このタイプのモデルに依存している機関は、パンデミックが予測の出力にどのような影響を与えたかについてあまり理解していません。 そのため、それらを使用し続けるかどうか、またどのような状況であれば使用し続けるかを判断することがより困難になります。
もちろん、予測モデルが適切に機能し、説明可能だからといって、そのモデルとそれが表すシステムが詳細な調査から免除されるわけではありません。 モデルの出力をより厳密に検討し、新しい状況下でどのモデルが適切にパフォーマンスを発揮し、どのモデルが適切にパフォーマンスを発揮していないかを判断する必要があるのは、おそらく良いことでしょう。
裕福な家庭がパンデミックをうまく「乗り切る」ことができれば、その家庭の学生はパンデミック前の料金に近い入学率になる可能性がある。 さらに、モデルは登録者数を適切に予測します。 しかし、ウイルスがより高い健康リスクや経済的リスクをもたらす家族は、たとえ「机上」やモデルが使用するデータセットで現在の状況が変わっていなくても、パンデミック中に子どもを大学に行かせることについて異なる決定を下す可能性がある。 困難な時期にモデルの予測の精度が低くなるグループを特定すると、モデルにとって未知の要因が浮き彫りになり、現実世界の生徒に影響を及ぼします。
課題となるアルゴリズムのバイアス
社会的不平等が特に目に見えて有害である現在、モデルが見落としたり誤って特徴づけたりする人々を特定することはさらに重要です。 疎外されたコミュニティは、新型コロナウイルス感染症による健康と経済への影響の矢面に立たされています。 がある 私たちのデータに「組み込まれた」歴史的な社会的偏見 既存のプロセスを加速および拡張するモデリング システムやマシンでは、こうしたバイアスが永続化することがよくあります。 予測モデルとヒューマンデータサイエンティストは連携して、社会的状況やその他の重要な要素がアルゴリズムの出力に確実に反映されるようにする必要があります。
たとえば、昨年、英国の大学入学試験に代わって、学生が試験を受けた場合の成績を予測するアルゴリズムが導入されました。 このアルゴリズムは非常に物議を醸す結果を生み出しました。
教師は生徒の試験での成績を推定し、アルゴリズムが各学校の生徒の過去の成績に基づいて人間による予測を調整しました。 として Axios報告, 「最大の被害者は、恵まれない学校の成績の良い生徒であり、成績が引き下げられる可能性が高く、一方、より裕福な学校の生徒は点数が引き上げられる可能性が高い。」
この記事は、「不適切に設計されたアルゴリズムは、大学の配置をはるかに超えた影響を与える可能性のある新たな形の偏見を固定化する危険性がある」と結論付けています。 その後、アルゴリズムで生成された結果の予測よりも模擬試験ではるかに良い成績を収めた学生などからの大規模な国民の抗議を受けて、英国政府はこのアルゴリズムを放棄した。
学生の人生の軌跡に影響を与える不公平なシナリオを避けるために、各分野の専門知識を持ち、すべての結果を検討し、その結果に異議を申し立てたり無効にしたりする権限を持たない人がいない限り、予測モデルを使用して影響の大きい意思決定を下すべきではありません。 これらのモデルは可能な限り透明性があり説明可能である必要があり、そのデータと手法は完全に文書化され、レビューに利用できる必要があります。 自動予測は人間の意思決定者に情報を提供できますが、人間の意思決定者に取って代わるべきではありません。 さらに、予測は常に実際の結果と比較する必要があり、変化する現実を考慮してモデルをいつ再トレーニングする必要があるかを判断するためにモデルを監視する必要があります。
結局のところ、2020 年は既存のシステムやモデルに関する厳然たる真実が暴露された一方で、2021 年は各機関が欠陥を認識し、バイアスに取り組み、アプローチをリセットする機会となります。 モデルの次の反復ではそれがより強力になり、より良い情報と洞察がすべての人に利益をもたらします。
出典: https://www.edsurge.com/news/2021-04-16-can-college-predictive-models-survive-the-pandemic
- NEW
- アルゴリズム
- アルゴリズム
- 申し込み
- 記事
- 自動化
- Axios
- 最大の
- 英国の
- 挑戦する
- 変化する
- 子供達
- クローザー
- カレッジ
- コミュニティ
- 続ける
- コロナ
- 危機
- 電流プローブ
- データ
- 開発する
- 経済
- 家族
- ファイナンシャル
- 財政援助
- 欠陥
- フォーム
- 先物
- 良い
- 政府・公共機関
- 助成
- 健康
- ハイ
- 認定条件
- HTTPS
- 識別する
- 影響
- 含めて
- 情報
- 洞察
- 機関
- 機関
- 問題
- IT
- 保管
- ローン
- マシン
- 作成
- 材料
- モデリング
- 提供
- 業務執行統括
- 機会
- その他
- パンデミック
- パターン
- のワークプ
- パフォーマンス
- 電力
- 予測
- 生産された
- 公共
- 価格表
- 現実
- 結果
- レビュー
- リスク
- 規模
- 学校
- 学校
- 科学者たち
- サービス
- 社会
- Status:
- 学生
- システム
- 時間
- top
- トレンド
- イギリス
- 大学
- 大学
- アップデイト
- 値
- ウイルス
- 体重を計る
- 重さ
- 誰
- 仕事
- 年