で類似の列を見つける データレイク データのクリーニングと注釈、スキーマ マッチング、データ検出、および複数のデータ ソースにわたる分析において重要な用途があります。 さまざまなソースからのデータを正確に見つけて分析できないことは、データ サイエンティスト、医学研究者、学者から金融アナリスト、政府アナリストまで、あらゆる人にとって効率を損なう可能性があることを表しています。
従来のソリューションには、語彙キーワード検索または正規表現マッチングが含まれますが、列名が存在しない、またはさまざまなデータセット間で列の命名規則が異なるなどのデータ品質の問題の影響を受けやすくなっています (たとえば、 zip_code, zcode, postalcode).
この投稿では、列名、列の内容、またはその両方に基づいて類似の列を検索するソリューションを示します。 ソリューションは使用します 最近隣アルゴリズムの概算 で利用可能 AmazonOpenSearchサービス 意味的に類似した列を検索します。 検索を容易にするために、事前にトレーニングされた Transformer モデルを使用して、データ レイク内の個々の列の機能表現 (埋め込み) を作成します。 文変換ライブラリ in アマゾンセージメーカー. 最後に、ソリューションを操作して結果を視覚化するために、インタラクティブな ストリームライト で実行されている Web アプリケーション AWSファーゲート.
私たちは含まれています コードチュートリアル サンプル データまたは独自のデータでソリューションを実行するためのリソースをデプロイします。
ソリューションの概要
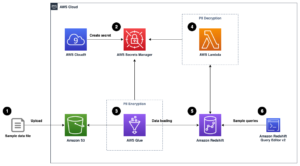
次のアーキテクチャ図は、意味的に類似した列を見つけるための XNUMX 段階のワークフローを示しています。 最初のステージでは、 AWSステップ関数 表形式の列から埋め込みを作成し、OpenSearch Service 検索インデックスを構築するワークフロー。 第 XNUMX ステージ (オンライン推論ステージ) では、Fargate を介して Streamlit アプリケーションを実行します。 Web アプリケーションは、入力検索クエリを収集し、OpenSearch Service インデックスから、クエリに最も近い k 個の近似列を取得します。

図 1. ソリューション アーキテクチャ
自動化されたワークフローは、次の手順で進みます。
- ユーザーは、表形式のデータセットを Amazon シンプル ストレージ サービス (Amazon S3) バケット。 AWSラムダ Step Functions ワークフローを開始する関数。
- ワークフローは AWSグルー CSVファイルをに変換するジョブ アパッチパーケット データ形式。
- SageMaker Processing ジョブは、事前トレーニング済みモデルまたはカスタム列埋め込みモデルを使用して、各列の埋め込みを作成します。 SageMaker Processing ジョブは、各テーブルの列埋め込みを Amazon S3 に保存します。
- Lambda 関数は、OpenSearch Service ドメインとクラスターを作成して、前のステップで生成された列の埋め込みにインデックスを付けます。
- 最後に、Fargate を使用してインタラクティブな Streamlit Web アプリケーションをデプロイします。 Web アプリケーションは、ユーザーが照会を入力して OpenSearch Service ドメインで類似の列を検索するためのインターフェースを提供します。
コード チュートリアルは次の場所からダウンロードできます。 GitHubの サンプル データまたは独自のデータでこのソリューションを試してください。 このチュートリアルに必要なリソースをデプロイする方法については、次の Web サイトで入手できます。 githubの.
前提条件
このソリューションを実装するには、次のものが必要です。
- An AWSアカウント.
- などの AWS サービスに関する基本的な知識 AWSクラウド開発キット (AWS CDK)、Lambda、OpenSearch サービス、および SageMaker 処理。
- 検索インデックスを作成するための表形式のデータセット。 独自の表形式データを持ち込むか、サンプル データセットをダウンロードできます。 GitHubの.
検索インデックスを構築する
最初の段階では、列検索エンジンのインデックスを作成します。 次の図は、このステージを実行する Step Functions ワークフローを示しています。

図 2 – ステップ関数ワークフロー – 複数の埋め込みモデル
データセット
この投稿では、400 を超える表形式のデータセットから 25 を超える列を含める検索インデックスを作成します。 データセットは、次の公開ソースに由来します。
インデックスに含まれるテーブルの完全なリストについては、次のコード チュートリアルを参照してください。 GitHubの.
独自の表形式のデータセットを使用して、サンプル データを補強したり、独自の検索インデックスを構築したりできます。 Step Functions ワークフローを開始して個々の CSV ファイルまたは CSV ファイルのバッチの検索インデックスをそれぞれ作成する XNUMX つの Lambda 関数が含まれています。
CSV を Parquet に変換する
生の CSV ファイルは、AWS Glue を使用して Parquet データ形式に変換されます。 Parquet は、効率的な圧縮とエンコードを提供するビッグ データ分析で好まれる列指向の形式のファイル形式です。 私たちの実験では、未加工の CSV ファイルと比較して、Parquet データ形式はストレージ サイズを大幅に削減しました。 また、Parquet は高度なネストされたデータ構造をサポートしているため、他のデータ形式 (JSON や NDJSON など) を変換するための一般的なデータ形式としても使用しました。
表形式の列の埋め込みを作成する
この投稿のサンプル表形式データセットの個々のテーブル列の埋め込みを抽出するために、次の事前トレーニング済みモデルを使用します sentence-transformers 図書館。 その他のモデルについては、 事前トレーニング済みモデル.
SageMaker Processing ジョブが実行されます create_embeddings.py(コード) 単一モデルの場合。 複数のモデルから埋め込みを抽出するために、ワークフローは、Step Functions ワークフローに示されているように、並列の SageMaker 処理ジョブを実行します。 このモデルを使用して、XNUMX セットの埋め込みを作成します。
- 列名_埋め込み – 列名 (ヘッダー) の埋め込み
- 列コンテンツの埋め込み – 列内のすべての行の平均埋め込み
列の埋め込みプロセスの詳細については、次のコード チュートリアルを参照してください。 GitHubの.
SageMaker の処理ステップに代わる方法は、SageMaker バッチ変換を作成して、大規模なデータセットで列の埋め込みを取得することです。 これには、モデルを SageMaker エンドポイントにデプロイする必要があります。 詳細については、次を参照してください。 バッチ変換を使用する.
OpenSearch Service を使用したインデックス埋め込み
この段階の最後のステップで、Lambda 関数は列の埋め込みを OpenSearch Service 近似 k-Nearest-Neighbor (kNN) 検索インデックス. 各モデルには、独自の検索インデックスが割り当てられます。 近似 kNN 検索インデックス パラメーターの詳細については、次を参照してください。 k 最近傍法.
Web アプリを使用したオンライン推論とセマンティック検索
ワークフローの第 XNUMX 段階では、 ストリームライト 入力を提供し、OpenSearch Service で索引付けされた意味的に類似した列を検索できる Web アプリケーション。 アプリケーション層は アプリケーションロードバランサー、Fargate、およびラムダ。 アプリケーション インフラストラクチャは、ソリューションの一部として自動的にデプロイされます。
このアプリケーションでは、意味的に類似した列名、列の内容、またはその両方を入力して検索できます。 さらに、埋め込みモデルと最近傍の数を選択して、検索から返すことができます。 アプリケーションは入力を受け取り、入力を指定されたモデルに埋め込み、 OpenSearch サービスでの kNN 検索 インデックス付き列の埋め込みを検索し、指定された入力に最も類似した列を見つけます。 表示される検索結果には、テーブル名、列名、識別された列の類似性スコア、およびさらに探索するための Amazon S3 内のデータの場所が含まれます。
Web アプリケーションの例を次の図に示します。 この例では、類似したデータ レイク内の列を検索しました。 Column Names (ペイロードタイプ)へ district (ペイロード)。 使用したアプリケーション all-MiniLM-L6-v2 として 埋め込みモデル そして戻ってきた 10 (k) OpenSearch Service インデックスからの最近傍。
アプリケーションが返されました transit_district, city, borough, location OpenSearch Service でインデックス化されたデータに基づいて、最も類似した XNUMX つの列として。 この例は、データセット全体で意味的に類似した列を識別する検索アプローチの機能を示しています。

図 3: Web アプリケーションのユーザー インターフェイス
クリーンアップ
このチュートリアルで AWS CDK によって作成されたリソースを削除するには、次のコマンドを実行します。
cdk destroy --allまとめ
この投稿では、表形式の列のセマンティック検索エンジンを構築するためのエンド ツー エンドのワークフローを紹介しました。
で利用できるコード チュートリアルを使用して、独自のデータで今すぐ始めましょう GitHubの. 製品やプロセスでの ML の使用を促進するための支援が必要な場合は、 Amazon 機械学習ソリューション ラボ.
著者について
![]() カチオドエメネ AWS AI の応用科学者です。 AWS のお客様のビジネス上の問題を解決する AI/ML ソリューションを構築しています。
カチオドエメネ AWS AI の応用科学者です。 AWS のお客様のビジネス上の問題を解決する AI/ML ソリューションを構築しています。
![]() テイラー・マクナリー Amazon Machine Learning Solutions Lab の深層学習アーキテクトです。 彼は、さまざまな業界のお客様が AWS で AI/ML を活用したソリューションを構築するのを支援しています。 おいしいコーヒーとアウトドア、そして家族や元気な犬との時間を楽しんでいます。
テイラー・マクナリー Amazon Machine Learning Solutions Lab の深層学習アーキテクトです。 彼は、さまざまな業界のお客様が AWS で AI/ML を活用したソリューションを構築するのを支援しています。 おいしいコーヒーとアウトドア、そして家族や元気な犬との時間を楽しんでいます。
![]() オースティンウェルチ Amazon ML Solutions Lab のデータサイエンティストです。 彼はカスタムの深層学習モデルを開発して、AWS 公共部門の顧客が AI とクラウドの採用を加速できるよう支援しています。 余暇には、読書、旅行、柔術を楽しんでいます。
オースティンウェルチ Amazon ML Solutions Lab のデータサイエンティストです。 彼はカスタムの深層学習モデルを開発して、AWS 公共部門の顧客が AI とクラウドの採用を加速できるよう支援しています。 余暇には、読書、旅行、柔術を楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- 能力
- 私たちについて
- 不在の
- 加速する
- 加速している
- 正確にデジタル化
- 越えて
- NEW
- さらに
- 追加
- 養子縁組
- 高度な
- AI
- AI / ML
- すべて
- ことができます
- 代替案
- Amazon
- アマゾン機械学習
- Amazon MLソリューションラボ
- アナリスト
- 分析論
- 分析します
- および
- アパッチ
- 申し込み
- 適用された
- アプローチ
- 建築
- 割り当てられた
- 自動化
- 自動的に
- 利用できます
- 平均
- AWS
- AWSグルー
- ベース
- なぜなら
- ビッグ
- ビッグデータ
- 持って来る
- ビルド
- 建物
- 構築します
- ビジネス
- クリーニング
- クラウド
- クラウドの採用
- クラスタ
- コード
- コーヒー
- 集める
- コラム
- コラム
- コマンドと
- 比べ
- 接触
- コンテンツ
- 表記
- 変換
- 変換
- 作ります
- 作成した
- 作成します。
- カップ
- カスタム
- Customers
- データ
- データ分析
- データレイク
- データ品質
- データサイエンティスト
- データセット
- 深いです
- 深い学習
- 実証します
- 実証
- 展開します
- 展開
- 展開する
- 破壊する
- 開発
- 開発
- 異なります
- 発見
- 異なる
- 異なる
- 犬
- ドメイン
- ダウンロード
- 各
- 効率
- 効率的な
- 端から端まで
- エンドポイント
- エンジン
- エーテル(ETH)
- 誰も
- 例
- 探査
- エキス
- 容易にする
- 親しみ
- 家族
- 特徴
- フィギュア
- File
- ファイナル
- 最後に
- ファイナンシャル
- もう完成させ、ワークスペースに掲示しましたか?
- 発見
- 名
- フォロー中
- 形式でアーカイブしたプロジェクトを保存します.
- から
- フル
- function
- 機能
- さらに
- 取得する
- 与えられた
- 良い
- 政府・公共機関
- ヘッダーの
- 助けます
- ことができます
- 認定条件
- How To
- HTML
- HTTPS
- 特定され
- 識別する
- 実装する
- 重要
- in
- できないこと
- include
- 含まれました
- index
- 個人
- 産業
- 情報
- インフラ関連事業
- 開始する
- 開始する
- 説明書
- 対話
- 相互作用的
- インタフェース
- 呼び出す
- 巻き込む
- 問題
- IT
- ジョブ
- Jobs > Create New Job
- JSON
- ラボ
- 湖
- 大
- 層
- 学習
- 活用
- 図書館
- リスト
- 負荷
- 場所
- 機械
- 機械学習
- マッチング
- 医療の
- ML
- モデル
- 他には?
- 最も
- の試合に
- 名
- 名
- 命名
- 必要
- 隣人
- 数
- 提供
- オンライン
- その他
- 屋外で
- 自分の
- 並列シミュレーションの設定
- パラメータ
- 部
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- お願いします
- ポスト
- 潜在的な
- 優先
- PLM platform.
- 前
- 問題
- 進む
- プロセス
- ラボレーション
- 処理
- 生産された
- 製品
- 提供します
- は、大阪で
- 公共
- 品質
- Raw
- リーディング
- 受け取り
- レギュラー
- 表し
- 必要とする
- の提出が必要です
- 研究者
- リソース
- それぞれ
- 結果
- return
- ラン
- ランニング
- セージメーカー
- 科学者
- 科学者たち
- を検索
- 検索エンジン
- 検索
- 二番
- セクター
- サービス
- サービス
- セット
- 示す
- 作品
- 重要
- 同様の
- 簡単な拡張で
- サイズ
- 溶液
- ソリューション
- 解決する
- ソース
- 指定の
- ステージ
- 開始
- 手順
- ステップ
- ストレージ利用料
- そのような
- サポート
- がち
- テーブル
- アプリ環境に合わせて
- 介して
- 時間
- 〜へ
- 今日
- 最適化の適用
- トランスフォーマー
- 旅行
- チュートリアル
- つかいます
- ユーザー
- ユーザーインターフェース
- さまざまな
- ウェブ
- ウェブアプリケーション
- which
- ワークフロー
- でしょう
- あなたの
- ゼファーネット