סטודיו דבק AWS הוא ממשק גרפי המקל על יצירה, הפעלה וניטור של חילוץ, שינוי וטעינה (ETL) בעבודות דבק AWS. זה מאפשר לך להרכיב באופן ויזואלי זרימות עבודה של טרנספורמציה של נתונים באמצעות צמתים המייצגים שלבי טיפול בנתונים שונים, אשר לאחר מכן מומרים אוטומטית לקוד להפעלה.
סטודיו דבק AWS שפורסמו לאחרונה 10 טרנספורמציות ויזואליות נוספות כדי לאפשר יצירת עבודות מתקדמות יותר בצורה ויזואלית ללא כישורי קידוד. בפוסט זה, אנו דנים במקרים של שימושים פוטנציאליים המשקפים צרכי ETL נפוצים.
התמורות החדשות שיוצגו בפוסט זה הן: שרשור, פיצול מחרוזת, מערך לעמודות, הוסף חותמת זמן נוכחית, סיבוב שורות לעמודות, ביטול ציר עמודות לשורות, חיפוש, פיצוץ מערך או מיפוי לעמודות, עמודה נגזרת ועיבוד איזון אוטומטי .
סקירת פתרונות
במקרה השימוש הזה, יש לנו כמה קבצי JSON עם פעולות אופציות. אנחנו רוצים לבצע כמה טרנספורמציות לפני אחסון הנתונים כדי להקל על הניתוח, ואנחנו גם רוצים לייצר סיכום מערך נתונים נפרד.
במערך נתונים זה, כל שורה מייצגת סחר של חוזי אופציות. אופציות הן מכשירים פיננסיים המספקים את הזכות - אך לא את החובה - לקנות או למכור מניות במחיר קבוע (נקרא מחיר המימוש) לפני תאריך תפוגה מוגדר.
נתוני קלט
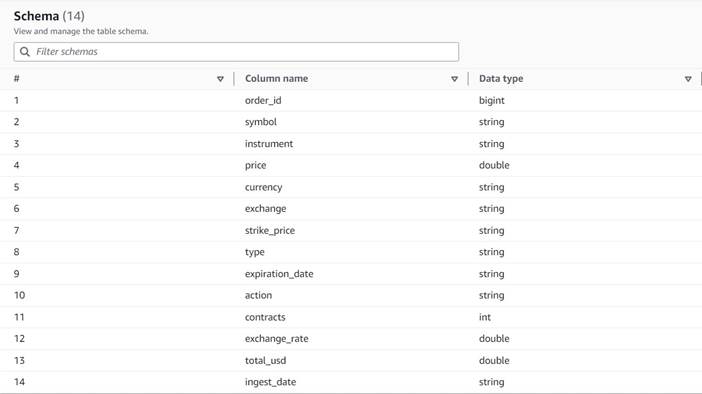
הנתונים עוקבים אחר הסכמה הבאה:
- מספר הזמנה - תעודה מזהה ייחודית
- סמל - קוד המבוסס בדרך כלל על כמה אותיות לזיהוי התאגיד שפולט את מניות המניות הבסיסיות
- מכשיר – השם שמזהה את האפשרות הספציפית הנרכשת או הנמכרת
- מטבע – קוד המטבע ISO בו מתבטא המחיר
- מחיר - הסכום ששולם עבור רכישת כל חוזה אופציה (ברוב הבורסות, חוזה אחד מאפשר לך לקנות או למכור 100 מניות)
- חליפין – הקוד של מרכז הבורסה או המקום בו נסחרה האופציה
- נמכרים – רשימה של מספר החוזים שהוקצו למילוי הזמנת המכירה כאשר מדובר בעסקת מכירה
- קנה – רשימה של מספר החוזים שהוקצו למילוי הזמנת הקנייה כאשר מדובר במסחר קנייה
להלן דוגמה של הנתונים הסינתטיים שנוצרו עבור פוסט זה:
דרישות ETL
לנתונים אלו מספר מאפיינים ייחודיים, כפי שנמצאים לעתים קרובות במערכות ישנות יותר, המקשים על השימוש בנתונים.
להלן דרישות ה-ETL:
- לשם המכשיר יש מידע רב ערך שנועד לבני אדם להבין; אנו רוצים לנרמל אותו לעמודות נפרדות לניתוח קל יותר.
- התכונות
boughtוsoldסותרים זה את זה; אנו יכולים לאחד אותם לעמודה אחת עם מספרי החוזים וליצור עמודה נוספת המציינת אם החוזים נרכשו או נמכרו בסדר הזה. - אנחנו רוצים לשמור את המידע על הקצאות החוזים הבודדים אבל כשורות בודדות במקום לאלץ את המשתמשים להתמודד עם מערך של מספרים. נוכל לחבר את המספרים, אבל נאבד מידע על אופן מילוי ההזמנה (המציין נזילות בשוק). במקום זאת, אנו בוחרים לבטל את הנורמליזציה של הטבלה כך שלכל שורה יש מספר יחיד של חוזים, תוך פיצול הזמנות עם מספרים מרובים לשורות נפרדות. בפורמט עמודות דחוס, גודל מערך הנתונים הנוסף של חזרה זו הוא לעתים קרובות קטן כאשר מוחלת דחיסה, ולכן מקובל להקל על השאילתה של מערך הנתונים.
- ברצוננו ליצור טבלת סיכום של נפח עבור כל סוג אופציה (התקשרות והוצאה) עבור כל מניה. זה מספק אינדיקציה לסנטימנט השוק עבור כל מניה והשוק בכלל (חמדנות מול פחד).
- כדי לאפשר סיכומי סחר כלליים, אנו רוצים לספק עבור כל פעולה את הסכום הכולל ולתקן את המטבע לדולר ארה"ב, באמצעות התייחסות להמרה משוערת.
- אנו רוצים להוסיף את התאריך שבו התרחשו התמורות הללו. זה יכול להיות שימושי, למשל, כדי לקבל התייחסות לגבי מתי בוצעה המרת המטבע.
בהתבסס על הדרישות הללו, המשרה תפיק שתי תפוקות:
- קובץ CSV עם סיכום של מספר החוזים לכל סמל וסוג
- טבלת קטלוג לשמירה על היסטוריה של ההזמנה, לאחר ביצוע השינויים המצוינים
תנאים מוקדמים
תזדקק לדלי S3 משלך כדי לעקוב עם מקרה השימוש הזה. ליצירת דלי חדש, עיין ב יצירת דלי.
הפקת נתונים סינתטיים
כדי לעקוב אחר הפוסט הזה (או להתנסות בסוג זה של נתונים בעצמך), אתה יכול ליצור מערך נתונים זה באופן סינתטי. ניתן להפעיל את הסקריפט הבא של Python על סביבת Python עם Boto3 מותקן וגישה אליו שירות אחסון פשוט של אמזון (אמזון S3).
כדי להפיק את הנתונים, בצע את השלבים הבאים:
- ב-AWS Glue Studio, צור עבודה חדשה עם האפשרות עורך סקריפטים של פייתון.
- תן שם לתפקיד ועל ה פרטי עבודה לשונית, בחר א תפקיד מתאים ושם לסקריפט Python.
- ב פרטי עבודה סעיף, הרחב מאפיינים מתקדמים וגלול מטה אל פרמטרים לעבודה.
- הזן פרמטר בשם
--bucketוהקצה כערך את שם הדלי שבו ברצונך להשתמש כדי לאחסן את הנתונים לדוגמה. - הזן את הסקריפט הבא לעורך ה-AWS Glue shell:
- הפעל את העבודה והמתן עד שהיא תראה כמושלמה בהצלחה בלשונית ריצות (זה אמור להימשך מספר שניות בלבד).
כל הפעלה תייצר קובץ JSON עם 1,000 שורות מתחת לדלי שצוינו ולקידומת transformsblog/inputdata/. אתה יכול להריץ את העבודה מספר פעמים אם אתה רוצה לבדוק עם קבצי קלט נוספים.
כל שורה בנתונים הסינתטיים היא שורת נתונים המייצגת אובייקט JSON כמו הבא:
צור את העבודה החזותית של AWS Glue
כדי ליצור את העבודה החזותית של AWS Glue, בצע את השלבים הבאים:
- עבור אל AWS Glue Studio וצור עבודה באמצעות האפשרות ויזואלי עם קנבס ריק.
- ערוך
Untitled jobלתת לו שם ולהקצות תפקיד המתאים ל-AWS Glue על פרטי עבודה TAB. - הוסף מקור נתונים S3 (תוכל לתת לו שם
JSON files source) והזן את כתובת האתר של S3 שמתחתיה מאוחסנים הקבצים (לדוגמה,s3://<your bucket name>/transformsblog/inputdata/), ולאחר מכן בחר JSON כפורמט הנתונים. - בחר להסיק סכמה כך שהוא מגדיר את סכימת הפלט בהתבסס על הנתונים.
מצומת מקור זה, תמשיך לשרשר טרנספורמציות. בעת הוספת כל טרנספורמציה, ודא שהצומת שנבחר הוא האחרון שנוסף כך שהוא יוקצה כהורה, אלא אם צוין אחרת בהוראות.
אם לא בחרת את ההורה הנכון, תמיד תוכל לערוך את ההורה על ידי בחירתו ובחירה בהורה אחר בחלונית התצורה.
עבור כל צומת שנוסף, תיתן לו שם ספציפי (כך שמטרת הצומת מופיעה בגרף) ותצורה ב- לשנות TAB.
בכל פעם שהטרנספורמציה משנה את הסכימה (לדוגמה, הוסף עמודה חדשה), יש לעדכן את סכימת הפלט כך שהיא תהיה גלויה לטרנספורמציות במורד הזרם. אתה יכול לערוך באופן ידני את סכימת הפלט, אבל זה מעשי ובטוח יותר לעשות זאת באמצעות התצוגה המקדימה של הנתונים.
בנוסף, כך תוכל לוודא שהשינוי פועל עד כה כמצופה. כדי לעשות זאת, פתח את ה תצוגה מקדימה של נתונים הכרטיסייה עם הטרנספורמציה שנבחרה והתחל הפעלת תצוגה מקדימה. לאחר שווידאתם שהנתונים שעברו שינוי נראים כצפוי, עבור אל סכימת פלט לחץ על הכרטיסייה ובחר השתמש בסכימת תצוגה מקדימה של נתונים כדי לעדכן את הסכימה באופן אוטומטי.
כאשר אתה מוסיף סוגים חדשים של טרנספורמציות, התצוגה המקדימה עשויה להציג הודעה על תלות חסרה. כשזה קורה, בחר סיום סשן ולהתחיל אחד חדש, כך שהתצוגה המקדימה קולטת את הסוג החדש של צומת.
חלץ מידע על המכשיר
נתחיל בטיפול במידע על שם המכשיר כדי לנרמל אותו לעמודות שקל יותר לגשת אליהן בטבלת הפלט המתקבלת.
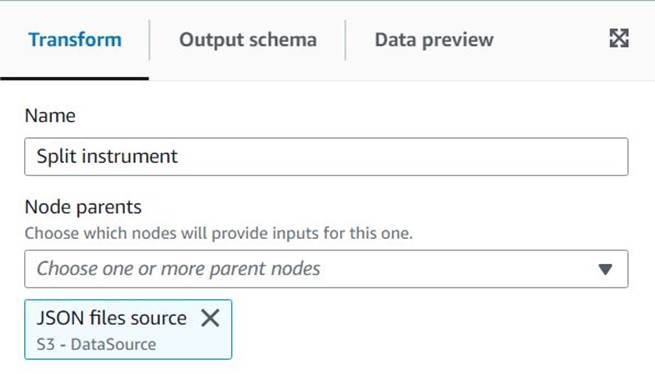
- הוסף מיתר מפוצל צומת ושמות לו
Split instrument, אשר יסמל את עמודת המכשיר באמצעות רווח ריגול:s+(חלל בודד יתאים במקרה הזה, אבל הדרך הזו גמישה יותר וברורה יותר מבחינה ויזואלית). - אנו רוצים לשמור את המידע המקורי של המכשיר כפי שהוא, אז הזן שם עמודה חדש עבור המערך המפוצל:
instrument_arr.
- הוסף מערך לעמודות צומת ושמות לו
Instrument columnsכדי להמיר את עמודת המערך שנוצרה זה עתה לשדות חדשים, למעטsymbol, שעבורו כבר יש לנו טור. - בחר את העמודה
instrument_arr, דלג על האסימון הראשון ותגיד לו לחלץ את עמודות הפלטmonth, day, year, strike_price, typeשימוש באינדקסים2, 3, 4, 5, 6(הרווחים שאחרי הפסקים מיועדים לקריאה, הם לא משפיעים על התצורה).
השנה שחולצה מבוטאת בשתי ספרות בלבד; בוא נניח שזה במאה הזו אם הם רק משתמשים בשתי ספרות.
- הוסף עמודה נגזרת צומת ושמות לו
Four digits year. - זן
yearבתור העמודה הנגזרת אז היא עוקפת אותה, והזן את הביטוי SQL הבא:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
מטעמי נוחות, אנו בונים א expiration_date שדה שיכול להיות למשתמש כהתייחסות לתאריך האחרון שניתן לממש את האופציה.
- הוסף שרשור עמודות צומת ושמות לו
Build expiration date. - תן שם לעמודה החדשה
expiration_date, בחר את העמודותyear,month, וday(בסדר הזה), ומקף כמרווח.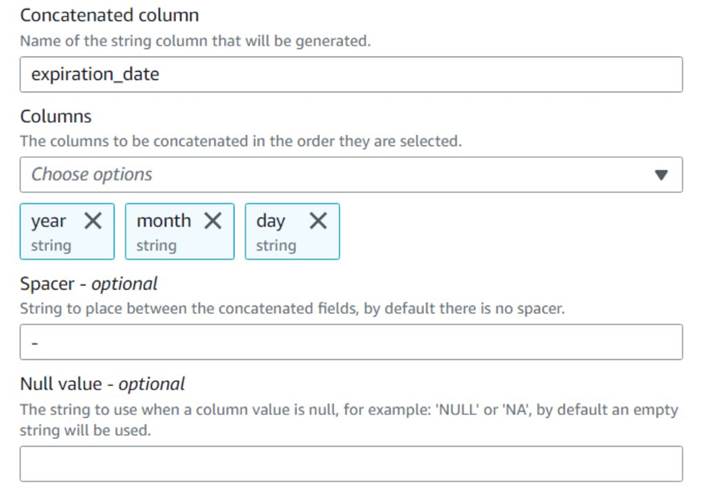
התרשים עד כה אמור להיראות כמו הדוגמה הבאה.
![]()
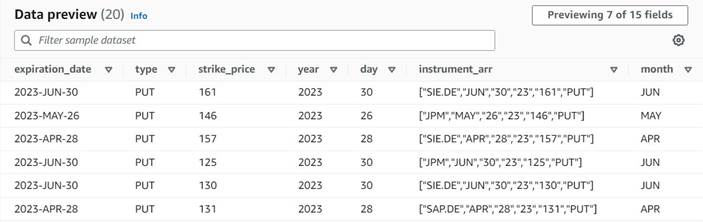
התצוגה המקדימה של הנתונים של העמודות החדשות עד כה צריכה להיראות כמו צילום המסך הבא.
נרמל את מספר החוזים
כל אחת מהשורות בנתונים מציינת את מספר החוזים של כל אופציה שנרכשו או נמכרו ואת המנות שבהן בוצעו ההזמנות. מבלי לאבד את המידע על האצוות הבודדות, אנו רוצים שכל כמות תהיה בשורה בודדת עם ערך כמות בודד, בעוד ששאר המידע משוכפל בכל שורה.
ראשית, בואו נמזג את הסכומים לעמודה אחת.
- הוסף ביטול ציר עמודות לשורות צומת ושמות לו
Unpivot actions. - בחר את העמודות
boughtוsoldכדי לבטל את הציר ולאחסן את השמות והערכים בעמודות עם שםactionוcontracts, בהתאמה.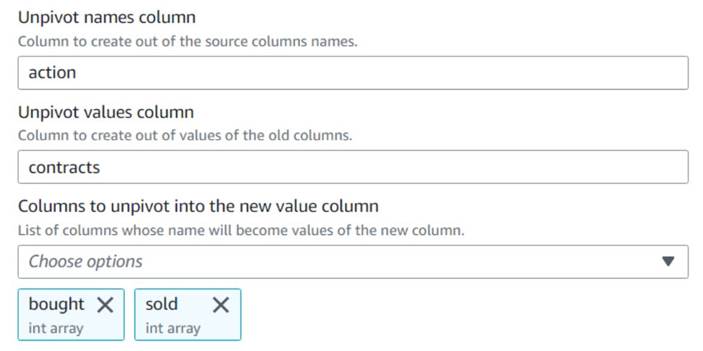
שימו לב בתצוגה המקדימה שהעמודה החדשהcontractsהוא עדיין מערך של מספרים לאחר השינוי הזה.
- הוסף פוצץ מערך או מפה לשורות שורה בשם
Explode contracts. - בחר את
contractsעמודה והזןcontractsבתור העמודה החדשה כדי לעקוף אותה (איננו צריכים לשמור את המערך המקורי).
התצוגה המקדימה כעת מראה שלכל שורה יש יחיד contracts כמות, ושאר השדות זהים.
זה גם אומר את זה order_id אינו עוד מפתח ייחודי. למקרי השימוש שלך, אתה צריך להחליט כיצד לעצב את הנתונים שלך ואם אתה רוצה לבטל את הנורמליזציה או לא.
צילום המסך הבא הוא דוגמה כיצד נראות העמודות החדשות לאחר השינויים עד כה.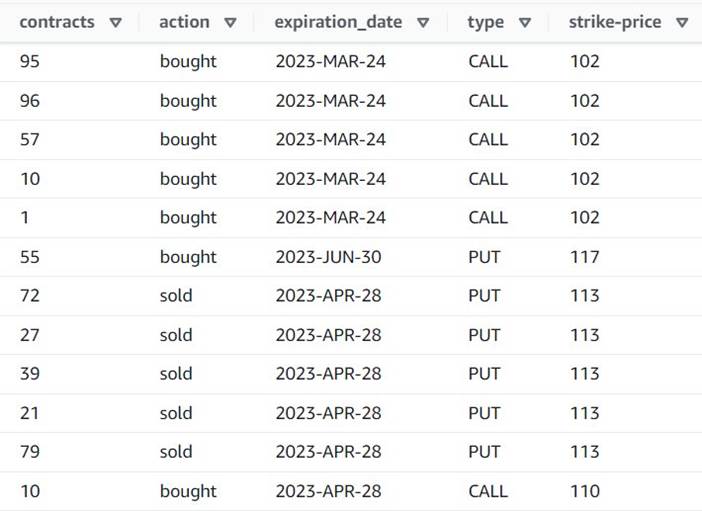
צור טבלת סיכום
כעת אתה יוצר טבלת סיכום עם מספר החוזים הנסחרים עבור כל סוג וכל סמל מניה.
נניח לצורך המחשה שהקבצים המעובדים שייכים ליום בודד, ולכן סיכום זה נותן למשתמשים העסקיים מידע על העניין והסנטימנט בשוק באותו יום.
- הוסף בחר שדות צומת ובחר את העמודות הבאות כדי לשמור עבור הסיכום:
symbol,type, וcontracts.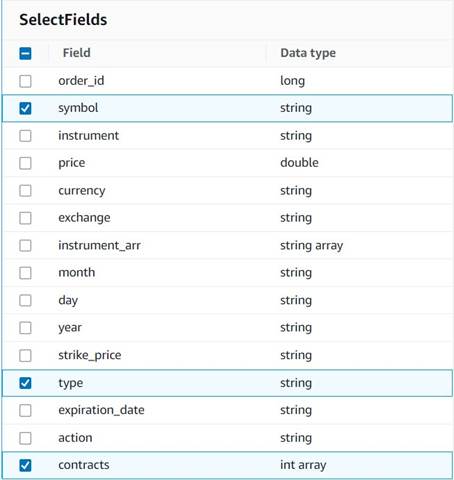
- הוסף סובב שורות לעמודות צומת ושמות לו
Pivot summary. - לצבור על
contractsעמודה באמצעותsumובחר להמיר אתtypeעמודה.
בדרך כלל, היית מאחסן אותו במסד נתונים או קובץ חיצוני כלשהו לעיון; בדוגמה זו, אנו שומרים אותו כקובץ CSV ב-Amazon S3.
- הוסף עיבוד איזון אוטומטי צומת ושמות לו
Single output file. - למרות שסוג הטרנספורמציה הזה משמש בדרך כלל כדי לייעל את המקביליות, כאן אנו משתמשים בו כדי לצמצם את הפלט לקובץ בודד. לכן, הכנס
1בתצורת מספר המחיצות.
- הוסף יעד S3 ותן לו שם
CSV Contract summary. - בחר CSV כפורמט הנתונים והזן נתיב S3 שבו מותר לתפקיד העבודה לאחסן קבצים.
החלק האחרון של העבודה אמור כעת להיראות כמו הדוגמה הבאה.![]()
- שמור והפעל את העבודה. להשתמש ב ריצות לשונית כדי לבדוק מתי זה הסתיים בהצלחה.
תמצא קובץ תחת הנתיב הזה שהוא CSV, למרות שאין לו סיומת זו. ככל הנראה תצטרך להוסיף את התוסף לאחר הורדתו כדי לפתוח אותו.
בכלי שיכול לקרוא את ה-CSV, הסיכום צריך להיראות בערך כמו הדוגמה הבאה.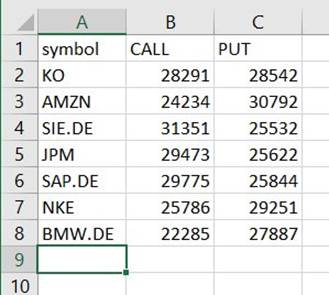
נקה עמודות זמניות
כהכנה לשמירת ההזמנות לטבלה היסטורית לניתוח עתידי, בואו ננקה כמה עמודות זמניות שנוצרו לאורך הדרך.
- הוסף זרוק שדות צומת עם ה
Explode contractsצומת שנבחר כהורה שלו (אנחנו מסיעים את צינור הנתונים כדי ליצור פלט נפרד). - בחר את השדות לביטול:
instrument_arr,month,day, וyear.
את השאר אנחנו רוצים לשמור כדי שהם יישמרו בטבלה ההיסטורית שניצור מאוחר יותר.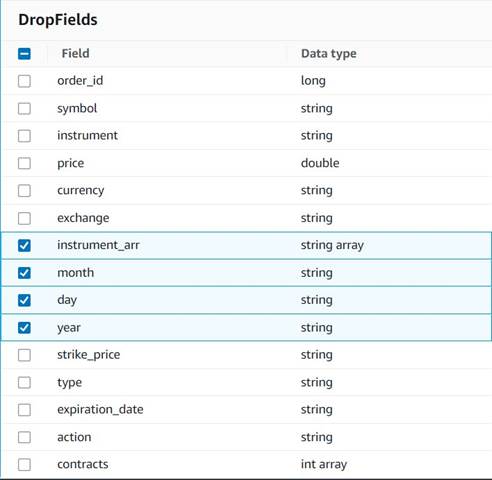
סטנדרטיזציה של מטבעות
הנתונים הסינטטיים האלה מכילים פעולות בדיוניות על שני מטבעות, אבל במערכת אמיתית אפשר היה להשיג מטבעות משווקים בכל רחבי העולם. כדאי לבצע סטנדרטיזציה של המטבעות המטופלים למטבע ייחוס יחיד כך שניתן יהיה להשוות אותם בקלות ולצבור אותם לצורך דיווח וניתוח.
אנו משתמשים אמזונה אתנה לדמות טבלה עם המרות מטבעות משוערות שמתעדכנת מעת לעת (כאן אנו מניחים שאנו מעבדים את ההזמנות בזמן מספיק כדי שההמרה היא נציג סביר למטרות השוואה).
- פתח את קונסולת Athena באותו אזור שבו אתה משתמש ב-AWS Glue.
- הפעל את השאילתה הבאה כדי ליצור את הטבלה על ידי הגדרת מיקום S3 שבו גם תפקידי Athena וגם התפקידים שלך AWS Glue יכולים לקרוא ולכתוב. כמו כן, ייתכן שתרצה לאחסן את הטבלה במסד נתונים אחר מאשר
default(אם תעשה זאת, עדכן את השם המתאים בטבלה בהתאם בדוגמאות המצורפות). - הזן כמה המרות לדוגמה לטבלה:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - כעת אתה אמור להיות מסוגל להציג את הטבלה עם השאילתה הבאה:
SELECT * FROM default.exchange_rates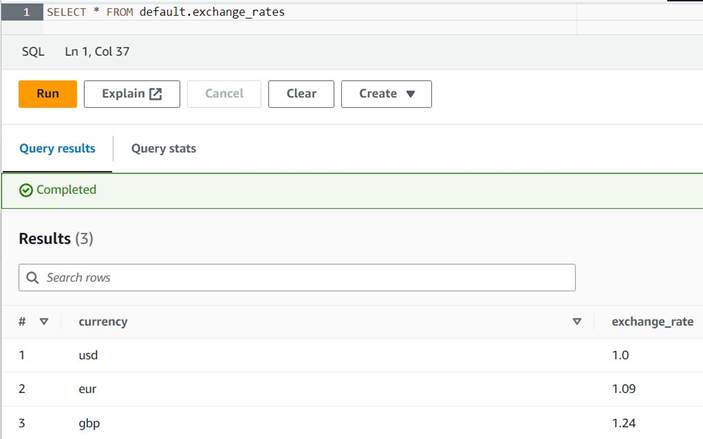
- בחזרה לעבודה החזותית של AWS Glue, הוסף א בדיקה צומת (כילד של
Drop Fields) ותן שםExchange rate. - הזן את השם האיכותי של הטבלה שזה עתה יצרת, באמצעות
currencyבתור המקש ובחר אתexchange_rateשדה לשימוש.
מכיוון שהשדה נקרא זהה גם בנתונים וגם בטבלת החיפוש, אנחנו יכולים פשוט להזין את השםcurrencyולא צריך להגדיר מיפוי.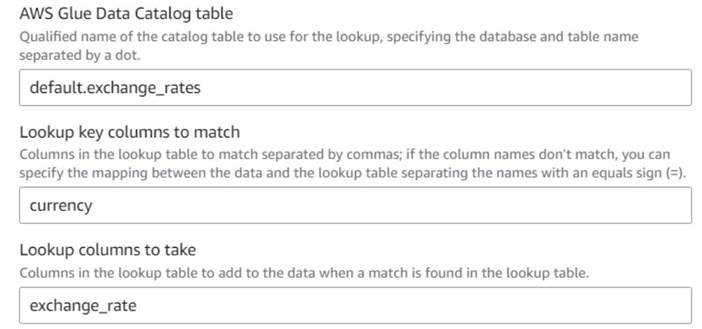
בזמן כתיבת שורות אלה, טרנספורמציה של Lookup אינה נתמכת בתצוגה המקדימה של הנתונים והיא תציג שגיאה שהטבלה לא קיימת. זה מיועד רק לתצוגה מקדימה של הנתונים ואינו מונע מהעבודה לפעול כהלכה. השלבים הספורים שנותרו בפוסט אינם מחייבים אותך לעדכן את הסכימה. אם אתה צריך להפעיל תצוגה מקדימה של נתונים בצמתים אחרים, אתה יכול להסיר את צומת הבדיקה באופן זמני ולאחר מכן להחזיר אותו. - הוסף עמודה נגזרת צומת ושמות לו
Total in usd. - תן שם לעמודה הנגזרת
total_usdוהשתמש בביטוי SQL הבא:round(contracts * price * exchange_rate, 2)
- הוסף הוסף חותמת זמן נוכחית צומת ושם לעמודה
ingest_date. - השתמש בפורמט
%Y-%m-%dעבור חותמת הזמן שלך (למטרות הדגמה, אנחנו רק משתמשים בתאריך; אתה יכול לדייק אותו אם תרצה).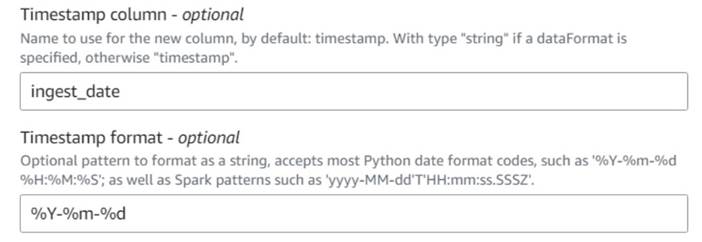
שמור את טבלת ההזמנות ההיסטוריות
כדי לשמור את טבלת ההזמנות ההיסטוריות, בצע את השלבים הבאים:
- הוסף צומת יעד S3 ושם לו
Orders table. - הגדר פורמט פרקט עם דחיסה מהירה, וספק נתיב יעד S3 שמתחתיו לאחסן את התוצאות (בנפרד מהסיכום).
- בחר צור טבלה בקטלוג הנתונים ובריצות עוקבות, עדכן את הסכימה והוסף מחיצות חדשות.
- הזן מסד נתונים יעד ושם לטבלה החדשה, למשל:
option_orders.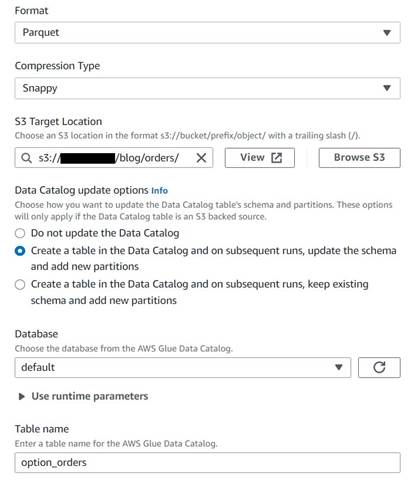
החלק האחרון של התרשים אמור כעת להיראות דומה לחלק הבא, עם שני ענפים עבור שני הפלטים הנפרדים.![]()
לאחר שתפעיל את העבודה בהצלחה, תוכל להשתמש בכלי כמו Athena כדי לסקור את הנתונים שהעבודה הפיקה על ידי שאילתה בטבלה החדשה. אתה יכול למצוא את הטבלה ברשימת אתנה ולבחור תצוגה מקדימה של טבלה או פשוט הפעל שאילתת SELECT (עדכון שם הטבלה לשם ולקטלוג שהשתמשת בהם):
SELECT * FROM default.option_orders limit 10
תוכן הטבלה שלך אמור להיראות דומה לצילום המסך הבא.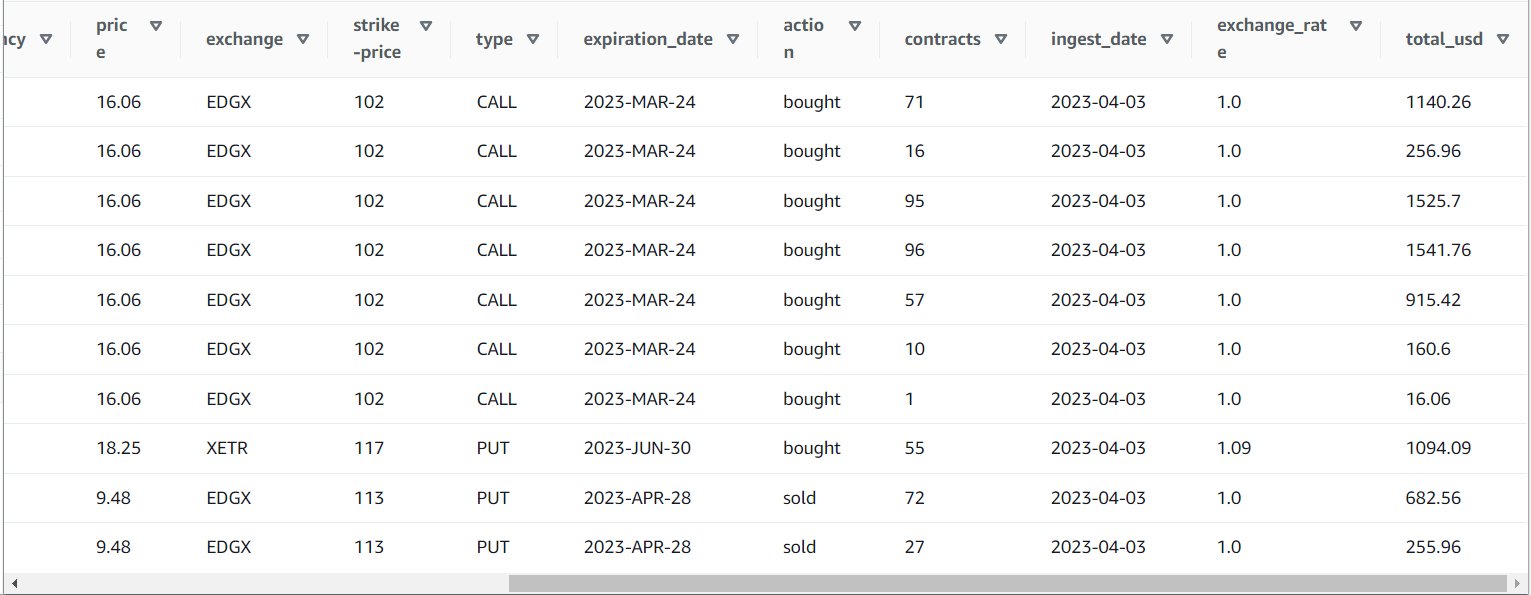
לנקות את
אם אינך רוצה לשמור את הדוגמה הזו, מחק את שתי המשימות שיצרת, את שתי הטבלאות ב- Athena ואת הנתיבים של S3 שבהם אוחסנו קבצי הקלט והפלט.
סיכום
בפוסט זה, הראינו כיצד ההמרה החדשה ב-AWS Glue Studio יכולה לעזור לך לבצע טרנספורמציה מתקדמת יותר עם מינימום תצורה. זה אומר שאתה יכול ליישם יותר מקרי שימוש ב-ETL מבלי שתצטרך לכתוב ולתחזק קוד כלשהו. הטרנספורמציות החדשות כבר זמינות ב-AWS Glue Studio, כך שתוכל להשתמש בטרנספורמציות החדשות היום בעבודות החזותיות שלך.
על הסופר
![]() גונזלו הררוס הוא ארכיטקט ביג דאטה בכיר בצוות AWS Glue.
גונזלו הררוס הוא ארכיטקט ביג דאטה בכיר בצוות AWS Glue.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoAiStream. Web3 Data Intelligence. הידע מוגבר. גישה כאן.
- הטבעת העתיד עם אדריאן אשלי. גישה כאן.
- קנה ומכירה של מניות בחברות PRE-IPO עם PREIPO®. גישה כאן.
- מקור: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- :יש ל
- :הוא
- :לֹא
- :איפה
- $ למעלה
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 15%
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- יכול
- אודות
- קביל
- גישה
- לפיכך
- להוסיף
- הוסיף
- מוסיף
- מתקדם
- לאחר
- תעשיות
- מוּקצֶה
- הקצאות
- להתיר
- מאפשר
- לאורך
- כְּבָר
- גם
- תמיד
- אמזון בעברית
- כמות
- כמויות
- an
- אנליזה
- לנתח
- ו
- אחר
- כל
- יישומית
- לְהִתְקַרֵב
- אפריל
- ARE
- טענה
- מערך
- AS
- שהוקצה
- At
- תכונות
- באופן אוטומטי
- זמין
- AWS
- דבק AWS
- בחזרה
- מבוסס
- BE
- לפני
- להיות
- גָדוֹל
- נתונים גדולים
- ריק
- ב.מ. וו
- שניהם
- קנה
- ענפים
- לִבנוֹת
- עסקים
- אבל
- לִקְנוֹת
- by
- שיחה
- CAN
- מקרה
- מקרים
- קטלוג
- מרכז
- מאה
- שינויים
- מאפיינים
- לבדוק
- ילד
- בחרו
- בחירה
- יותר ברור
- קוד
- סִמוּל
- טור
- עמודות
- Common
- לעומת
- השוואה
- להשלים
- השלמת
- תְצוּרָה
- קונסול
- לְגַבֵּשׁ
- מכיל
- תוכן
- חוזה
- חוזים
- נוחות
- המרה
- המרות
- להמיר
- הומר
- תַאֲגִיד
- יכול
- לִיצוֹר
- נוצר
- יוצרים
- מטבעות
- מַטְבֵּעַ
- נוֹכְחִי
- DAG
- נתונים
- מסד נתונים
- תַאֲרִיך
- תאריכים
- datetime
- יְוֹם
- עסקה
- התמודדות
- להחליט
- בְּרִירַת מֶחדָל
- מוגדר
- מופגן
- תלות
- נגזר
- למרות
- פרטים
- אחר
- ספרות
- לדון
- do
- לא
- עושה
- דולר
- לא
- לְהַכפִּיל
- מטה
- ירידה
- ירד
- כל אחד
- קל יותר
- בקלות
- קל
- עורך
- לאפשר
- מספיק
- זן
- סביבה
- שגיאה
- Ether (ETH)
- יורו
- דוגמה
- דוגמאות
- אלא
- חליפין
- בורסות
- בלעדי
- להתקיים
- לְהַרְחִיב
- צפוי
- לְנַסוֹת
- תפוגה
- ביטא
- הארכה
- חיצוני
- נוסף
- תמצית
- רחוק
- פחד
- מעטים
- בִּדְיוֹנִי
- שדה
- שדות
- שלח
- קבצים
- למלא
- ממולא
- כספי
- כלים פיננסיים
- ראשון
- קבוע
- גמיש
- לעקוב
- הבא
- כדלקמן
- בעד
- פוּרמָט
- מצא
- החל מ-
- עתיד
- ליש"ט
- כללי
- בדרך כלל
- ליצור
- נוצר
- לקבל
- לתת
- נותן
- Go
- גרף
- חמדנות
- טיפול
- קורה
- יש
- יש
- לעזור
- כאן
- היסטורי
- היסטוריה
- איך
- איך
- HTML
- http
- HTTPS
- בני אדם
- i
- מזהה
- לזהות
- if
- פְּגִיעָה
- ליישם
- לייבא
- in
- אינדקסים
- הצביע
- מצביע על
- המציין
- סִימָן
- בנפרד
- מידע
- קלט
- למשל
- במקום
- הוראות
- מכשיר
- מכשירים
- אינטרס
- מִמְשָׁק
- אל תוך
- ISO
- IT
- שֶׁלָה
- עבודה
- מקומות תעסוקה
- jpg
- ג'סון
- רק
- שמור
- מפתח
- סוג
- אחרון
- מאוחר יותר
- כמו
- להגביל
- קו
- נְזִילוּת
- רשימה
- לִטעוֹן
- מיקום
- עוד
- נראה
- נראה כמו
- נראה
- בדיקה
- להפסיד
- לאבד
- עשוי
- לתחזק
- לעשות
- עושה
- באופן ידני
- מַפָּה
- מיפוי
- שוק
- סנטימנט שוק
- שוקי
- מאי..
- אומר
- למזג
- הודעה
- יכול
- מינימום
- חסר
- מודל
- צג
- יותר
- רוב
- מספר
- הֲדָדִית
- שם
- שם
- שמות
- צורך
- צרכי
- חדש
- לא
- צומת
- צמתים
- בדרך כלל
- עַכשָׁיו
- מספר
- מספרים
- אובייקט
- of
- לעתים קרובות
- on
- ONE
- רק
- לפתוח
- מבצע
- תפעול
- מטב
- אפשרות
- אפשרויות
- or
- להזמין
- הזמנות
- מְקוֹרִי
- אחר
- אַחֶרֶת
- תפוקה
- יותר
- מקיף
- לעקוף
- שֶׁלוֹ
- נפרע
- זגוגית
- פרמטר
- חלק
- נתיב
- מבחר
- צינור
- Pivot
- מקום
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- הודעה
- פוטנציאל
- מעשי
- צורך
- למנוע
- תצוגה מקדימה
- מחיר
- כנראה
- תהליך
- תהליך
- לייצר
- מיוצר
- לספק
- ובלבד
- מספק
- לִרְכּוֹשׁ
- מטרה
- למטרות
- גם
- פיתון
- מוסמך
- להעלות
- אקראי
- חומר עיוני
- ממשי
- סביר
- להפחית
- לשקף
- באזור
- נותר
- להסיר
- משוכפל
- דווח
- לייצג
- נציג
- המייצג
- מייצג
- לדרוש
- דרישות
- דורש
- בהתאמה
- REST
- וכתוצאה מכך
- תוצאות
- סקירה
- תפקיד
- תפקידים
- שׁוּרָה
- הפעלה
- ריצה
- בטוח יותר
- אותו
- מוהל
- שמור
- חסכת
- לגלול
- שניות
- נבחר
- בחירה
- למכור
- לחצני מצוקה לפנסיונרים
- רגש
- נפרד
- מושב
- סטים
- הצבה
- שיתופים
- פָּגָז
- צריך
- לְהַצִיג
- הופעות
- דומה
- פָּשׁוּט
- יחיד
- מידה
- מיומנויות
- קטן
- So
- עד כה
- נמכרים
- כמה
- משהו
- מָקוֹר
- מֶרחָב
- רווחים
- ספציפי
- מפורט
- לפצל
- גיליון אלקטרוני
- SQL
- התחלה
- צעדים
- עוד
- מניות
- אחסון
- חנות
- מאוחסן
- מחרוזת
- סטודיו
- לאחר מכן
- בהצלחה
- מַתְאִים
- סיכום
- נתמך
- סמל
- סינטטי
- נתונים סינתטיים
- באופן סינתטי
- מערכת
- מערכות
- שולחן
- לקחת
- יעד
- נבחרת
- לספר
- זמני
- עשר
- מבחן
- מֵאֲשֶׁר
- זֶה
- השמיים
- הגרף
- המידע
- העולם
- אותם
- אז
- לכן
- אלה
- הֵם
- זֶה
- אלה
- זמן
- פִּי
- חותם
- ל
- היום
- אסימון
- tokenize
- לקח
- כלי
- סה"כ
- סחר
- נסחר
- לשנות
- טרנספורמציה
- טרנספורמציות
- טרנספורמציה
- שתיים
- סוג
- תחת
- בְּסִיסִי
- להבין
- ייחודי
- עד
- עדכון
- מְעוּדכָּן
- עדכון
- כתובת האתר
- us
- דולר אמריקני
- ש״ח
- להשתמש
- במקרה להשתמש
- מְשׁוּמָשׁ
- משתמש
- משתמשים
- באמצעות
- בעל ערך
- מידע בעל ערך
- ערך
- ערכים
- מָקוֹם מִפגָשׁ
- מְאוּמָת
- לאמת
- לצפיה
- נראה
- כֶּרֶך
- vs
- לחכות
- רוצה
- היה
- דֶרֶך..
- we
- היו
- מה
- מתי
- אשר
- בזמן
- יצטרך
- עם
- לְלֹא
- זרימות עבודה
- עובד
- עוֹלָם
- היה
- לכתוב
- כתיבה
- שנה
- אתה
- זפירנט











