מבוא
Retrieval Augmented Generation, או RAG, הוא מנגנון שעוזר למודלים של שפות גדולות (LLMs) כמו GPT להיות שימושיים ובעלי ידע רב יותר על ידי שליפת מידע ממאגר של נתונים שימושיים, בדומה להבאת ספר מספריה. הנה איך RAG עושה קסם עם זרימות עבודה פשוטות של AI:
- מאגר ידע (קלט): תחשוב על זה כעל ספרייה גדולה מלאה בדברים שימושיים - שאלות נפוצות, מדריכים, מסמכים וכו'. כאשר צצה שאלה, זה המקום שבו המערכת מחפשת תשובות.
- טריגר/שאילתה (קלט): זו נקודת ההתחלה. בדרך כלל, זו שאלה או בקשה ממשתמש שאומר למערכת, "היי, אני צריך שתעשה משהו!"
- משימה/פעולה (פלט): ברגע שהמערכת מקבלת את ההדק, היא נכנסת לפעולה. אם זו שאלה, זה חופר תשובה. אם זו בקשה לעשות משהו, זה יעשה את הדבר הזה.
כעת, בואו נפרק את מנגנון RAG לשלבים פשוטים:
- אחזור: ראשית, כאשר מגיעה שאלה או בקשה, RAG סורקת את מאגר הידע כדי למצוא מידע רלוונטי.
- הגדלה: בשלב הבא, הוא לוקח את המידע הזה ומערבב אותו עם השאלה או הבקשה המקורית. זה כמו להוסיף פרטים נוספים לבקשה הבסיסית כדי לוודא שהמערכת מבינה אותה במלואה.
- דור: לבסוף, עם כל המידע העשיר הזה בהישג יד, הוא מזין אותו למודל שפה גדול שלאחר מכן יוצר תגובה מושכלת או מבצע את הפעולה הנדרשת.
אז בקצרה, RAG הוא כמו שיש לו עוזר חכם שמחפש קודם מידע שימושי, משלב אותו עם השאלה הנידונה, ואז נותן תשובה מעוגלת היטב או מבצע משימה לפי הצורך. בדרך זו, עם RAG, מערכת הבינה המלאכותית שלך לא יורה רק בחושך; יש לו בסיס מוצק של מידע לעבוד ממנו, מה שהופך אותו לאמין ומועיל יותר.
איזו בעיה הם פותרים?
גישור על פער הידע
בינה מלאכותית גנרטיבית, המופעלת על ידי LLMs, בקיאה בהשראת תגובות טקסט המבוססות על כמות עצומה של נתונים שעליהן הוכשרה. בעוד שהכשרה זו מאפשרת יצירת טקסט קריא ומפורט, האופי הסטטי של נתוני האימון מהווה מגבלה קריטית. המידע בתוך המודל הופך מיושן עם הזמן, ובתרחיש דינמי כמו צ'אט בוט ארגוני, היעדר נתונים בזמן אמת או ספציפיים לארגון עלול להוביל לתגובות שגויות או מטעות. תרחיש זה מזיק מכיוון שהוא מערער את אמון המשתמש בטכנולוגיה, מה שמציב אתגר משמעותי במיוחד ביישומים ממוקדי לקוח או אפליקציות קריטיות.
פתרון RAG
RAG מגיעה להצלה על ידי מיזוג היכולות היצירתיות של LLMs עם אחזור מידע ממוקד בזמן אמת, מבלי לשנות את המודל הבסיסי. היתוך זה מאפשר למערכת הבינה המלאכותית לספק תגובות שמתאימות לא רק מבחינה הקשר אלא גם מבוססות על הנתונים העדכניים ביותר. לדוגמה, בתרחיש של ליגת ספורט, בעוד ש-LLM יכול לספק מידע כללי על הספורט או הקבוצות, RAG מסמיכה את הבינה המלאכותית לספק עדכונים בזמן אמת לגבי משחקים אחרונים או פציעות שחקנים על ידי גישה למקורות נתונים חיצוניים כמו מסדי נתונים, עדכוני חדשות, או אפילו מאגרי הנתונים של הליגה עצמה.
נתונים שנשארים מעודכנים
המהות של RAG טמונה ביכולתו להגדיל את ה-LLM עם נתונים טריים, ספציפיים לתחום. העדכון המתמיד של מאגר הידע ב-RAG הוא דרך חסכונית להבטיח שה-AI הגנרטיבי יישאר עדכני. יתר על כן, הוא מספק רובד של הקשר שחסר ל-LLM כללי, ובכך משפר את איכות התגובות. היכולת לזהות, לתקן או למחוק מידע שגוי בתוך מאגר הידע של ה- RAG מוסיפה עוד יותר למשיכה שלו, ומבטיחה מנגנון תיקון עצמי לאחזור מידע מדויק יותר.
דוגמאות לזרימות עבודה של RAG
בתחום המתפתח של בינה מלאכותית, Generation-Augmented Retrieval-Augmented (RAG) יוצר השפעה מהותית על פני מגזרים עסקיים שונים על ידי שיפור משמעותי של היכולות של מודלים של שפה גדולה (LLMs). הבה נסתכל על כמה דוגמאות כדי לקבל תחושה כיצד זרימות עבודה של RAG הופכות משימות לאוטומטיות -
- אחזור ושיתוף ידע פנימי בצוות:
- תרחיש: תאגיד רב לאומי עם פורטפוליו מגוון של פרויקטים מתמודד לעתים קרובות עם אתגרים בשיתוף יעיל של ידע ותובנות בין הצוותים שלו. כדי להקל על כך, החברה מיישמת פלטפורמה מוגברת של RAG לייעול אחזור ושיתוף ידע פנימי.
- זרימת עבודה:
- אחזור:
- שאילתה לדוגמה: מנהל פרויקט שואל, "האם עבדנו על פרויקטים כלשהם הקשורים לאנרגיה מתחדשת בשלוש השנים האחרונות?"
- מנגנון RAG מחפש באופן מיידי במאגרי המידע הפנימיים, דוחות פרויקטים קודמים וכל מאגר רלוונטי אחר כדי לאחזר מידע לגבי מעורבות החברה בפרויקטים של אנרגיה מתחדשת לאורך התקופה שצוינה.
- הגדלה:
- הנתונים שאוחזרו כוללים כותרות פרויקטים, אנשי מפתח, תוצרים סופיים ותוצאות של כל פרויקט.
- הוא עשוי גם להביא קישורים לכל תקשורת, מצגות או מסמכים רלוונטיים ששותפו באופן פנימי במהלך הפרויקטים הללו.
- דור:
- תשובה לדוגמה: המערכת מייצרת תגובה מקיפה:
"כן, במהלך שלוש השנים האחרונות, עסקנו בשלושה פרויקטים גדולים של אנרגיה מתחדשת. פרויקט 'חידושים סולאריים' הובל על ידי שרה ג'ונסון מצוות הקיימות והסתיים בדצמבר 2021 בפיתוח אב טיפוס של תחנת טעינה סולרית. פרויקט 'יעילות אנרגית רוח' בראשותו של מארק ד'סוזה, שמטרתו לשפר את יעילות טורבינות הרוח והושלם ביוני 2022. לבסוף, 'תמיכה במדיניות אנרגיה מתחדשת' הייתה יוזמה חוצת מחלקתים שהסתיימה בספטמבר 2022, ויצרה הצעת מדיניות לקידום אימוץ אנרגיה מתחדשת בקהילות מקומיות. ניתן לגשת למסמכים, דוחות ומצגות רלוונטיים דרך הקישורים המסופקים."
- תשובה לדוגמה: המערכת מייצרת תגובה מקיפה:
- אחזור:
- מסעות פרסום אוטומטיים:
- תַרחִישׁ: סוכנות שיווק דיגיטלית מיישמת RAG כדי להפוך את היצירה והפריסה של קמפיינים שיווקיים לאוטומטיים המבוססים על מגמות שוק בזמן אמת והתנהגות צרכנים.
- זרימת עבודה:
- אחזור: בכל פעם שליד חדש נכנס למערכת, מנגנון RAG מביא פרטים רלוונטיים של הליד והארגון שלהם ומפעיל את תחילת זרימת העבודה.
- הגדלה: הוא משלב את הנתונים האלה עם יעדי השיווק של הלקוח, הנחיות המותג ונתוני היעד הדמוגרפיים.
- ביצוע משימה: המערכת מעצבת ופורסת באופן אוטונומי קמפיין שיווקי מותאם בערוצים דיגיטליים שונים כדי לנצל את המגמה שזוהתה, תוך מעקב אחר ביצועי הקמפיין בזמן אמת לצורך התאמות אפשריות.
- מחקר משפטי והכנת תיקים:
- תַרחִישׁ: משרד עורכי דין משלב את RAG כדי לזרז את המחקר המשפטי והכנת התיקים.
- זרימת עבודה:
- אחזור: עם קלט לגבי מקרה חדש, הוא מעלה תקדימים משפטיים רלוונטיים, חוקים ופסקי דין אחרונים.
- הגדלה: זה מתאם את הנתונים האלה עם פרטי המקרה.
- דור: המערכת מנסחת תקציר תיק ראשוני, ומצמצמת משמעותית את הזמן שעורכי הדין מקדישים למחקר ראשוני.
- שיפור שירות לקוחות:
- תַרחִישׁ: חברת טלקומוניקציה מיישמת צ'אט בוט מתוגבר RAG לטיפול בשאלות לקוחות בנוגע לפרטי תוכנית, חיוב ופתרון בעיות נפוצות.
- זרימת עבודה:
- אחזור: עם קבלת שאילתה לגבי קצבת הנתונים של תוכנית מסוימת, המערכת מתייחסת לתוכניות ולהצעות העדכניות ביותר ממסד הנתונים שלה.
- הגדלה: הוא משלב את המידע שאוחזר עם פרטי התוכנית הנוכחיים של הלקוח (מפרופיל הלקוח) והשאילתה המקורית.
- דור: המערכת מייצרת מענה מותאם, המסביר את ההבדלים בקצבאות הנתונים בין התוכנית הנוכחית של הלקוח לתוכנית השאילתה.
- ניהול מלאי וסידור מחדש:
- תרחיש: חברת מסחר אלקטרוני משתמשת במערכת מוגברת של RAG כדי לנהל את המלאי ולבצע הזמנה מחדש אוטומטית של מוצרים כאשר רמות המלאי יורדות מתחת לסף שנקבע מראש.
- זרימת עבודה:
- שְׁלִיפָה: כאשר מלאי המוצר מגיע לרמה נמוכה, המערכת בודקת את היסטוריית המכירות, תנודות ביקוש עונתיות ומגמות שוק עדכניות ממסד הנתונים שלה.
- הגדלה: בשילוב הנתונים המאוחזרים עם תדירות ההזמנה מחדש של המוצר, זמני ההובלה ופרטי הספק, הוא קובע את הכמות האופטימלית להזמנה מחדש.
- ביצוע משימה: לאחר מכן המערכת מתממשקת לתוכנת הרכש של החברה כדי לבצע הזמנת רכש אוטומטית עם הספק, מה שמבטיח שפלטפורמת המסחר האלקטרוני לעולם לא ייגמרו מהמוצרים הפופולריים.
- הכשרת עובדים והגדרת IT:
- תרחיש: תאגיד רב לאומי משתמש במערכת המונעת על ידי RAG כדי לייעל את תהליך ההצטרפות לעובדים חדשים, תוך הבטחה שכל דרישות ה-IT יוגדרו לפני יומו הראשון של העובד.
- זרימת עבודה:
- שְׁלִיפָה: עם קבלת פרטים על גיוס חדש, המערכת מתייעצת במאגר משאבי אנוש כדי לקבוע את תפקידו, המחלקה והמיקום של העובד.
- הגדלה: הוא מתאם מידע זה עם מדיניות ה-IT של החברה, וקובע את התוכנה, החומרה והרשאות הגישה שהעובד החדש יזדקק להם.
- ביצוע משימה: לאחר מכן, המערכת מתקשרת עם מערכת הכרטוס של מחלקת ה-IT, מייצרת כרטיסים אוטומטית להקמת תחנת עבודה חדשה, התקנת תוכנה נחוצה והענקת גישה מתאימה למערכת. זה מבטיח שכאשר העובד החדש מתחיל, תחנת העבודה שלו מוכנה, והם יכולים לצלול מיד לאחריות שלהם.
דוגמאות אלו מדגישות את הרבגוניות והיתרונות המעשיים של שימוש בזרימות עבודה של RAG בטיפול באתגרים עסקיים מורכבים בזמן אמת על פני מספר עצום של תחומים.
חבר את הנתונים והאפליקציות שלך עם Nanonets AI Assistant כדי לשוחח עם נתונים, לפרוס צ'אטבוטים וסוכנים מותאמים אישית וליצור זרימות עבודה של RAG.
כיצד לבנות זרימות עבודה של RAG משלך?
תהליך בניית זרימת עבודה RAG
ניתן לחלק את תהליך בניית זרימת העבודה של Generation Augmented Retrieval (RAG) למספר שלבים מרכזיים. ניתן לחלק את השלבים הללו לשלושה תהליכים עיקריים: בליעה, שליפה, ו דור, כמו גם הכנה נוספת:
1. אופן ההכנה:
- הכנת מאגר הידע: הכן מאגר נתונים או בסיס ידע על ידי הכנסת נתונים ממקורות שונים - אפליקציות, מסמכים, מסדי נתונים. יש לעצב את הנתונים הללו כדי לאפשר יכולת חיפוש יעילה, מה שאומר שבעצם יש לעצב את הנתונים הללו לייצוג אובייקט מאוחד של 'מסמך'.
2. תהליך בליעה:
- הגדרת מסד נתונים וקטור: השתמש בבסיסי נתונים וקטוריים כבסיסי ידע, תוך שימוש באלגוריתמים שונים לאינדקס לארגון וקטורים בעלי מימדים גבוהים, המאפשרים יכולת שאילתה מהירה וחזקה.
- חילוץ מידע: חלץ נתונים ממסמכים אלה.
- חיתוך נתונים: חלק את המסמכים לחלקי נתונים.
- הטבעת נתונים: הפוך את הנתחים האלה להטבעות באמצעות מודל הטמעות כמו זה שמספק OpenAI.
- פתח מנגנון להטמעת שאילתת המשתמש שלך. זה יכול להיות ממשק משתמש או זרימת עבודה מבוססת API.
3. תהליך שליפה:
- הטמעת שאילתה: קבל את הטבעת הנתונים עבור שאילתת המשתמש.
- אחזור נתחים: בצע חיפוש היברידי כדי למצוא את הנתחים המאוחסנים הרלוונטיים ביותר ב-Vector Database בהתבסס על הטבעת השאילתה.
- משיכת תוכן: משוך את התוכן הרלוונטי ביותר ממאגר הידע שלך אל ההנחיה שלך כהקשר.
4. תהליך הדור:
- יצירת מהירה: שלב את המידע שאוחזר עם השאילתה המקורית כדי ליצור הנחיה. עכשיו, אתה יכול לבצע -
- יצירת תגובות: שלח את טקסט ההנחיה המשולב ל-LLM (מודל שפה גדול) כדי ליצור תגובה מושכלת.
- ביצוע משימה: שלח את טקסט ההנחיה המשולב לסוכן הנתונים LLM שלך, אשר יסיק את המשימה הנכונה לביצוע בהתבסס על השאילתה שלך ולבצע אותה. לדוגמה, אתה יכול ליצור סוכן נתונים של Gmail ולאחר מכן לבקש ממנו "לשלוח הודעות דוא"ל פרסומיות ללידים אחרונים של Hubspot" וסוכן הנתונים יבצע -
- להביא לידים אחרונים מהאבספוט.
- השתמש במאגר הידע שלך כדי לקבל מידע רלוונטי לגבי לידים. בסיס הידע שלך יכול להטמיע נתונים ממקורות נתונים מרובים - LinkedIn, APIs של העשרת לידים וכן הלאה.
- אצור אימיילים פרסומיים מותאמים אישית עבור כל ליד.
- שלח הודעות דוא"ל אלה באמצעות ספק הדוא"ל / מנהל מסעות הפרסום שלך.
5. תצורה ואופטימיזציה:
- התאמה אישית: התאם אישית את זרימת העבודה כך שתתאים לדרישות ספציפיות, שעשויות לכלול התאמת זרימת ההטמעה, כגון עיבוד מקדים, קטעים ובחירה במודל ההטמעה.
- אופטימיזציה: הטמעת אסטרטגיות אופטימיזציה כדי לשפר את איכות השליפה ולהפחית את ספירת האסימונים לעיבוד, מה שעלול להוביל למיטוב ביצועים ועלויות בקנה מידה.
יישום אחד בעצמך
הטמעת זרימת עבודה של אחזור מאוחדת (RAG) היא משימה מורכבת הכוללת שלבים רבים והבנה טובה של האלגוריתמים והמערכות הבסיסיות. להלן האתגרים והשלבים המודגשים כדי להתגבר עליהם עבור אלה המעוניינים ליישם זרימת עבודה של RAG:
אתגרים בבניית זרימת עבודה RAG משלך:
- חידוש וחוסר שיטות עבודה מבוססות: RAG היא טכנולוגיה חדשה יחסית, שהוצעה לראשונה בשנת 2020, והמפתחים עדיין מבינים את השיטות הטובות ביותר ליישום מנגנוני אחזור המידע שלה ב-AI גנרטיבי.
- עלות: יישום RAG יהיה יקר יותר מאשר שימוש במודל שפה גדול (LLM) בלבד. עם זאת, זה פחות יקר מאשר אימון מחדש של ה-LLM לעתים קרובות.
- מבנה נתונים: קביעת אופן המודל הטוב ביותר של נתונים מובנים ובלתי מובנים בתוך ספריית הידע ומסד הנתונים הווקטוריים היא אתגר מרכזי.
- הזנת נתונים מצטברת: פיתוח תהליכים להזנה הדרגתית של נתונים למערכת RAG הוא חיוני.
- טיפול באי דיוקים: יש צורך בהצבת תהליכים לטיפול בדיווחים על אי דיוקים ולתיקון או מחיקה של אותם מקורות מידע במערכת RAG.
חבר את הנתונים והאפליקציות שלך עם Nanonets AI Assistant כדי לשוחח עם נתונים, לפרוס צ'אטבוטים וסוכנים מותאמים אישית וליצור זרימות עבודה של RAG.
כיצד להתחיל ביצירת זרימת עבודה RAG משלך:
הטמעת זרימת עבודה של RAG דורשת שילוב של ידע טכני, הכלים הנכונים ולמידה מתמשכת ואופטימיזציה כדי להבטיח את האפקטיביות והיעילות שלו בעמידה ביעדים שלך. עבור אלה המחפשים ליישם זרימות עבודה של RAG בעצמם, אספנו רשימה של מדריכים מעשיים מקיפים המדריכים אותך בפירוט על תהליכי ההטמעה -
כל אחת מההדרכות מגיעה עם גישה או פלטפורמה ייחודית להשגת היישום הרצוי בנושאים שצוינו.
אם אתה מחפש להתעמק בבניית זרימות עבודה משלך של RAG, אנו ממליצים לבדוק את כל המאמרים המפורטים למעלה כדי לקבל תחושה הוליסטית הנדרשת כדי להתחיל במסע שלך.
הטמעת זרימות עבודה של RAG באמצעות פלטפורמות ML
בעוד שהפיתוי של בניית זרימת עבודה של Generation Augmented Retrieval (RAG) מהיסוד מציע תחושה מסוימת של הישג והתאמה אישית, אין ספק שזהו מאמץ מורכב. מתוך זיהוי המורכבות והאתגרים, כמה עסקים צעדו קדימה, והציעו פלטפורמות ושירותים מיוחדים כדי לפשט את התהליך הזה. מינוף הפלטפורמות הללו יכול לא רק לחסוך זמן ומשאבים יקרים, אלא גם להבטיח שהיישום מבוסס על שיטות עבודה מומלצות בתעשייה ומותאם לביצועים.
עבור ארגונים או יחידים שאולי אין להם את רוחב הפס או המומחיות לבנות מערכת RAG מאפס, פלטפורמות ML אלו מציגות פתרון בר-קיימא. על ידי בחירה בפלטפורמות אלה, ניתן:
- לעקוף את המורכבויות הטכניות: הימנע מהשלבים המורכבים של מבנה נתונים, הטמעה ושליפה. פלטפורמות אלו מגיעות לרוב עם פתרונות ומסגרות מוכנות מראש המותאמות לזרימות עבודה של RAG.
- למנף מומחיות: תיהנו מהמומחיות של אנשי מקצוע בעלי הבנה עמוקה של מערכות RAG וכבר התמודדו עם רבים מהאתגרים הקשורים ביישום שלה.
- בקרת מערכות ותקשורת: פלטפורמות אלה מתוכננות לעתים קרובות תוך מחשבה על מדרגיות, מה שמבטיח שככל שהנתונים שלך גדלים או שהדרישות שלך משתנות, המערכת יכולה להסתגל ללא שיפוץ מלא.
- עלות תועלת: אמנם ישנה עלות כרוכה בשימוש בפלטפורמה, אך היא עשויה להתגלות כמשתלמת יותר בטווח הארוך, במיוחד כאשר בוחנים את העלויות של פתרון בעיות, אופטימיזציה והטמעות פוטנציאליות מחדש.
הבה נסתכל על פלטפורמות המציעות יכולות יצירת זרימת עבודה של RAG.
ננונטים
Nanonets מציעה עוזרי בינה מלאכותית מאובטחת, צ'אטבוטים וזרימות עבודה RAG המופעלות על ידי הנתונים של החברה שלך. זה מאפשר סנכרון נתונים בזמן אמת בין מקורות נתונים שונים, ומאפשר אחזור מידע מקיף לצוותים. הפלטפורמה מאפשרת יצירת צ'אטבוטים יחד עם פריסה של זרימות עבודה מורכבות באמצעות שפה טבעית, המופעלת על ידי מודלים של שפה גדולה (LLMs). זה גם מספק מחברי נתונים לקריאה ולכתיבה של נתונים באפליקציות שלך, ויכולת להשתמש בסוכני LLM כדי לבצע פעולות ישירות באפליקציות חיצוניות.
Nanonets AI Assistant דף המוצר
AWS Generative AI
AWS מציעה מגוון שירותים וכלים תחת מטריית הבינה המלאכותית הגנרטיבית שלה כדי לתת מענה לצרכים עסקיים שונים. הוא מספק גישה למגוון רחב של דגמי יסודות מובילים בתעשייה מספקים שונים דרך Amazon Bedrock. משתמשים יכולים להתאים אישית את דגמי היסוד האלה עם הנתונים שלהם כדי לבנות חוויות מותאמות אישית ומובחנות יותר. AWS מדגישה אבטחה ופרטיות, ומבטיחה הגנה על נתונים בעת התאמה אישית של מודלים של בסיס. זה גם מדגיש תשתית חסכונית להרחבת AI מחולל, עם אפשרויות כגון AWS Trainium, AWS Inferentia ו-NVIDIA GPUs כדי להשיג את ביצועי המחיר הטובים ביותר. יתרה מכך, AWS מאפשרת בנייה, הדרכה ופריסה של מודלים של בסיס ב-Amazon SageMaker, ומרחיבה את הכוח של מודלים של בסיס למקרי שימוש ספציפיים של המשתמש.
AI גנרטיבי ב-Google Cloud
ה-Generative AI של Google Cloud מספק חבילה חזקה של כלים לפיתוח מודלים של AI, שיפור החיפוש והפעלת שיחות מונעות בינה מלאכותית. הוא מצטיין בניתוח סנטימנטים, עיבוד שפה, טכנולוגיות דיבור וניהול מסמכים אוטומטי. בנוסף, הוא יכול ליצור זרימות עבודה של RAG וסוכני LLM, לתת מענה לדרישות עסקיות מגוונות עם גישה רב לשונית, מה שהופך אותו לפתרון מקיף לצרכים ארגוניים שונים.
Oracle Generative AI
ה- Generative AI (OCI Generative AI) של אורקל מותאם לארגונים, ומציע מודלים מעולים בשילוב עם ניהול נתונים מעולה, תשתית AI ויישומים עסקיים. הוא מאפשר לשפר מודלים תוך שימוש בנתונים של המשתמש עצמו מבלי לשתף אותם עם ספקי מודלים גדולים של שפה או לקוחות אחרים, ובכך להבטיח אבטחה ופרטיות. הפלטפורמה מאפשרת פריסה של מודלים על אשכולות AI ייעודיים לביצועים ותמחור צפויים. OCI Generative AI מספק מקרי שימוש שונים כמו סיכום טקסט, יצירת העתקות, יצירת צ'אטבוטים, המרה סגנונית, סיווג טקסט וחיפוש נתונים, תוך מענה לקשת של צרכים ארגוניים. הוא מעבד את הקלט של המשתמש, שיכול לכלול שפה טבעית, דוגמאות קלט/פלט והוראות, כדי ליצור, לסכם, לשנות, לחלץ מידע, או לסווג טקסט על סמך בקשות המשתמש, לשלוח תגובה בפורמט שצוין.
קלודרה
בתחום הבינה המלאכותית הגנרטיבית, Cloudera מתגלה כבעלת ברית אמינה עבור ארגונים. בית אגם הנתונים הפתוח שלהם, הנגיש בעננים ציבוריים ופרטיים כאחד, הוא אבן יסוד. הם מציעים מגוון של שירותי נתונים המסייעים לכל מסע מחזור החיים של הנתונים, מהקצה ועד ל-AI. היכולות שלהם מתרחבות להזרמת נתונים בזמן אמת, אחסון וניתוח נתונים בבתי אגם פתוחים, ופריסה וניטור של מודלים של למידת מכונה באמצעות פלטפורמת הנתונים Cloudera. באופן משמעותי, Cloudera מאפשרת יצירת זרימות עבודה מדור אחזור משופר, הממזגת שילוב רב עוצמה של יכולות אחזור ויצירת יישומי AI משופרים.
ללקט
Glean משתמש בבינה מלאכותית כדי לשפר את החיפוש במקום העבודה ואת גילוי הידע. הוא ממנף מודלים של שפות גדולות מבוססי חיפוש וקטור ולמידה עמוקה להבנה סמנטית של שאילתות, תוך שיפור מתמיד של רלוונטיות החיפוש. הוא מציע גם עוזר בינה מלאכותית גנרטיבית למענה על שאילתות וסיכום מידע על פני מסמכים, כרטיסים ועוד. הפלטפורמה מספקת תוצאות חיפוש מותאמות אישית ומציעה מידע המבוסס על פעילות משתמשים ומגמות, מלבד הגדרה קלה ואינטגרציה עם למעלה מ-100 מחברים לאפליקציות שונות.
לנדבוט
Landbot מציעה חבילת כלים ליצירת חוויות שיחה. זה מקל על יצירת לידים, מעורבות לקוחות ותמיכה באמצעות צ'טבוטים באתרי אינטרנט או WhatsApp. משתמשים יכולים לעצב, לפרוס ולהגדיל צ'אטבוטים עם בונה ללא קוד, ולשלב אותם עם פלטפורמות פופולריות כמו Slack ו-Messenger. זה גם מספק תבניות שונות למקרי שימוש שונים כמו יצירת לידים, תמיכת לקוחות וקידום מוצרים
בסיס צ'אט
Chatbase מספקת פלטפורמה להתאמה אישית של ChatGPT כך שתתאים לאישיות המותג ולמראה האתר. זה מאפשר איסוף לידים, סיכומי שיחה יומיומיים ושילוב עם כלים אחרים כמו Zapier, Slack ומסנג'ר. הפלטפורמה נועדה להציע חוויית צ'טבוט מותאמת אישית לעסקים.
סולם AI
Scale AI מטפל בצוואר הבקבוק של הנתונים בפיתוח יישומי AI על ידי הצעת כוונון עדין ו-RLHF להתאמת מודלים של בסיס לצרכים עסקיים ספציפיים. היא משתלבת או שותפה למודלים מובילים של AI, מה שמאפשר לארגונים לשלב את הנתונים שלהם לצורך בידול אסטרטגי. יחד עם היכולת ליצור זרימות עבודה של RAG וסוכני LLM, Scale AI מספקת פלטפורמת בינה מלאכותית מחוללת בינה מלאכותית לפיתוח מואץ של יישומי בינה מלאכותית.
שאקודו - פתרונות LLM
Shakudo מציעה פתרון מאוחד לפריסת מודלים של שפה גדולה (LLM), ניהול מסדי נתונים וקטוריים והקמת צינורות נתונים חזקים. זה מייעל את המעבר מהדגמות מקומיות לשירותי LLM בדרגת ייצור עם ניטור בזמן אמת ותזמור אוטומטי. הפלטפורמה תומכת בפעולות גמישות של AI Generative, מסדי נתונים וקטוריים בעלי תפוקה גבוהה, ומספקת מגוון כלים מיוחדים של LLMOPS, מה שמשפר את העושר הפונקציונלי של ערימות טכנולוגיה קיימות.
דף המוצר של Shakundo RAG Workflows
לכל פלטפורמה/עסק שהוזכרו יש סט משלו של תכונות ויכולות ייחודיות, וניתן לחקור אותם עוד יותר כדי להבין כיצד ניתן למנף אותם לחיבור נתונים ארגוניים והטמעת זרימות עבודה של RAG.
חבר את הנתונים והאפליקציות שלך עם Nanonets AI Assistant כדי לשוחח עם נתונים, לפרוס צ'אטבוטים וסוכנים מותאמים אישית וליצור זרימות עבודה של RAG.
RAG Workflows עם Nanonets
בתחום של הגדלת מודלים של שפה כדי לספק תגובות מדויקות יותר ומלאות תובנות, Retrieval Augmented Generation (RAG) עומד כמנגנון מרכזי. התהליך המורכב הזה מעלה את המהימנות והתועלת של מערכות AI, ומבטיח שהן לא רק פועלות בוואקום מידע.
בליבה של זה, Nanonets AI Assistant מתגלה כשותף בטוח ורב תפקודי של AI שנועד לגשר על הפער בין הידע הארגוני שלך לבין מודלים של שפה גדולה (LLMs), והכל בתוך ממשק ידידותי למשתמש.
הנה הצצה לאינטגרציה חלקה ושיפור זרימת העבודה המוצעים על ידי יכולות RAG של Nanonets:
קישוריות נתונים:
Nanonets מאפשרת חיבורים חלקים ליותר מ-100 יישומי סביבת עבודה פופולריים כולל Slack, Notion, Google Suite, Salesforce ו-Zendesk, בין היתר. הוא מיומן בטיפול במגוון רחב של סוגי נתונים, בין אם זה לא מובנה כמו קובצי PDF, TXT, תמונות, קבצי אודיו ווידאו, או נתונים מובנים כגון CSVs, גיליונות אלקטרוניים, MongoDB ו-SQL מסדי נתונים. קישוריות נתונים רחבת-ספקטרום זו מבטיחה בסיס ידע חזק עבור מנגנון ה-RAG.
סוכני טריגר ואקשן:
עם Nanonets, הגדרת סוכני טריגר/פעולה היא משב רוח. סוכנים אלה ערניים לאירועים בכל אפליקציות סביבת העבודה שלך, ויזמים פעולות כנדרש. לדוגמה, צור זרימת עבודה למעקב אחר הודעות דוא"ל חדשות support@your_company.com, נצל את התיעוד שלך ואת שיחות הדוא"ל הקודמות שלך כבסיס ידע, נסח תגובת דוא"ל בעלת תובנות ושלח אותה החוצה, והכל מתוזמר בצורה חלקה.
קליטת נתונים ויצירת אינדקס יעילים:
קליטת נתונים ואינדקס אופטימלית הם חלק מהחבילה, מה שמבטיח עיבוד נתונים חלק אשר מטופל ברקע על ידי עוזר AI Nanonets. אופטימיזציה זו חיונית לסנכרון בזמן אמת עם מקורות נתונים, מה שמבטיח שלמנגנון RAG יש את המידע העדכני ביותר לעבוד איתו.
כדי להתחיל, אתה יכול להתקשר עם אחד ממומחי הבינה המלאכותית שלנו ונוכל לתת לך הדגמה וניסיון מותאם אישית של עוזר הבינה המלאכותי של Nanonets בהתבסס על מקרה השימוש שלך.
לאחר ההגדרה, תוכל להשתמש ב-Nanonets AI Assistant שלך כדי -
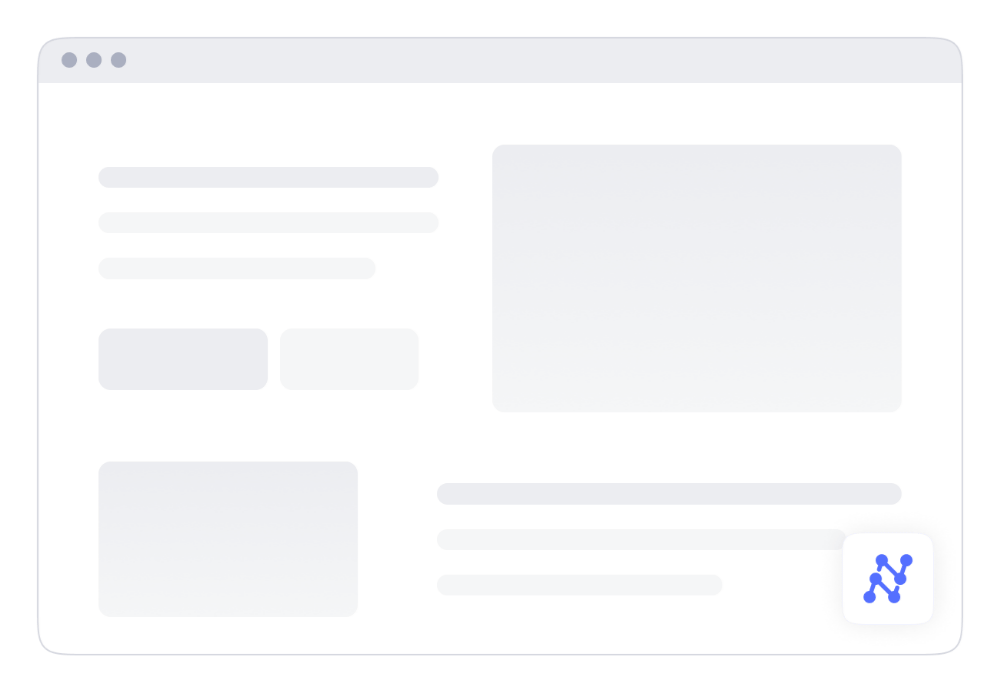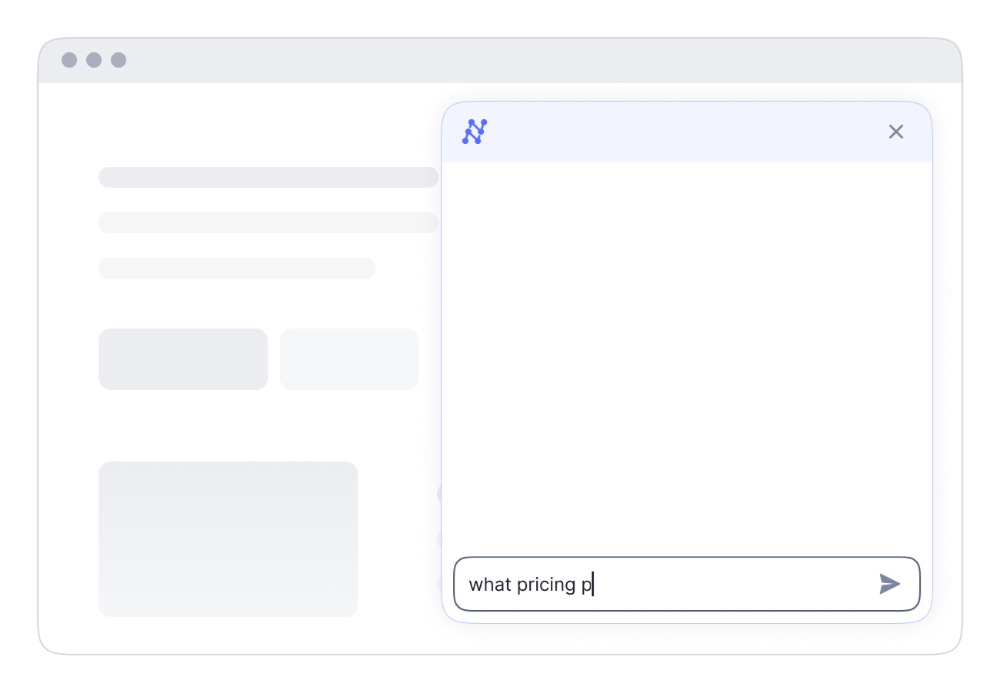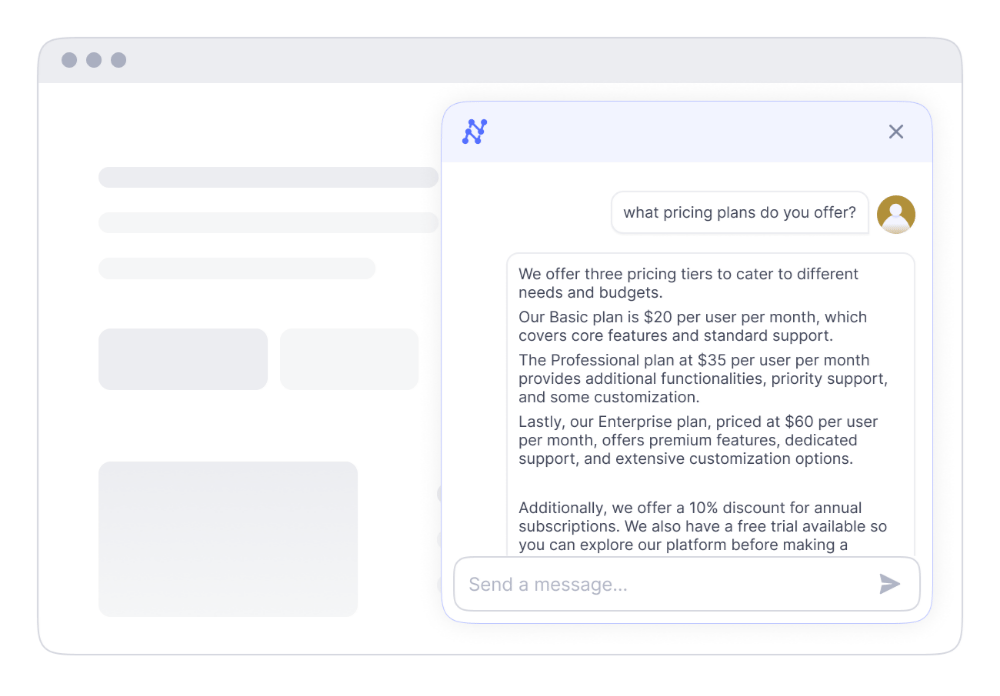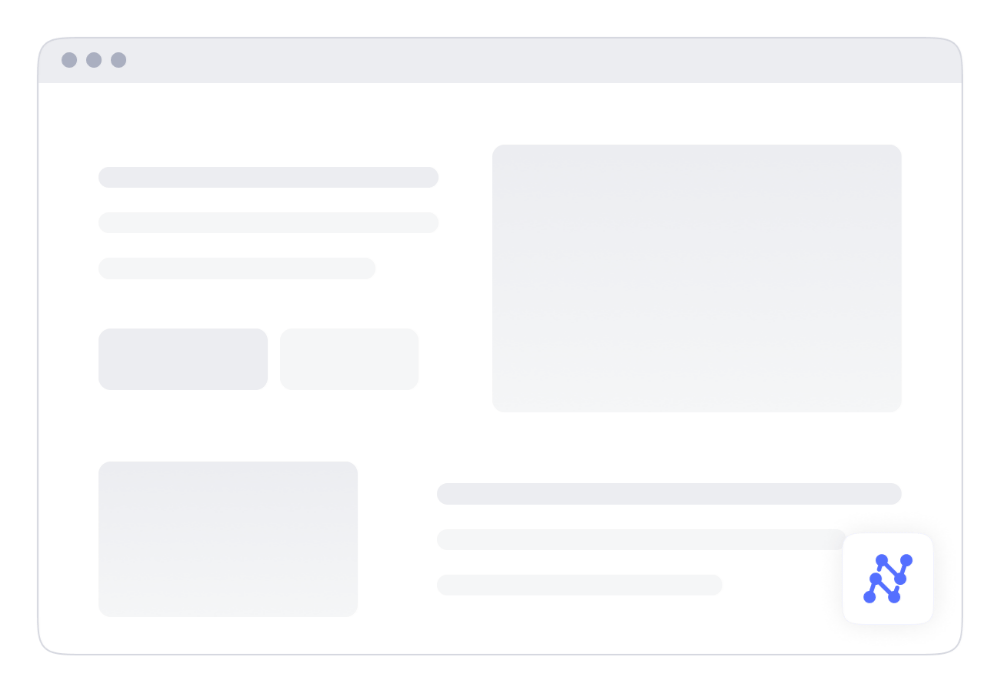
צור זרימות עבודה של RAG Chat
העצים את הצוותים שלך עם מידע מקיף בזמן אמת מכל מקורות הנתונים שלך.

צור זרימות עבודה של סוכן RAG
השתמש בשפה טבעית כדי ליצור ולהפעיל זרימות עבודה מורכבות המופעלות על ידי LLMs המקיימות אינטראקציה עם כל האפליקציות והנתונים שלך.

פרוס צ'אטבוטים מבוססי RAG
בנה ופריסה מוכנים לשימוש בצ'אטבוטים מותאמים אישית של AI שמכירים אותך תוך דקות.
הניע את היעילות של הצוות שלך
עם Nanonets AI, אתה לא רק משלב נתונים; אתה מטעין את היכולות של הצוות שלך. על ידי אוטומציה של משימות שגרתיות ומתן תגובות מלאות תובנות, הצוותים שלך יכולים להקצות מחדש את המיקוד שלהם ביוזמות אסטרטגיות.
עוזר AI המונע RAG של Nanonets הוא יותר מסתם כלי; זהו זרז שמייעל את התפעול, משפר את נגישות הנתונים ומניע את הארגון שלך לעבר עתיד של קבלת החלטות מושכלות ואוטומציה.
חבר את הנתונים והאפליקציות שלך עם Nanonets AI Assistant כדי לשוחח עם נתונים, לפרוס צ'אטבוטים וסוכנים מותאמים אישית וליצור זרימות עבודה של RAG.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://nanonets.com/blog/retrieval-augmented-generation/
- :יש ל
- :הוא
- :לֹא
- :איפה
- $ למעלה
- 100
- 2020
- 2021
- 2022
- a
- יכולת
- אודות
- מֵעַל
- מוּאָץ
- גישה
- נצפה
- נגישות
- נגיש
- גישה
- מדויק
- להשיג
- לרוחב
- פעולה
- פעולות
- פעילות
- להסתגל
- מוסיף
- נוסף
- בנוסף
- ממוען
- כתובות
- פְּנִיָה
- מוסיף
- התאמה
- התאמות
- אימוץ
- סנגור
- סוכנות
- סוֹכֵן
- סוכנים
- AI
- עוזר בינה מלאכותית
- דגמי AI
- פלטפורמת AI
- מערכות AI
- מכוון
- אלגוריתמים
- ליישר
- תעשיות
- להקל
- להתיר
- מאפשר
- קֶסֶם
- בן ברית
- לבד
- לאורך
- כְּבָר
- גם
- אמזון בעברית
- אמזון SageMaker
- בין
- כמות
- an
- אנליזה
- ו
- לענות
- תשובות
- כל
- ממשקי API
- לערער
- בקשה
- פיתוח אפליקציות
- יישומים
- גישה
- מתאים
- אפליקציות
- APT
- ARE
- מאמרים
- מלאכותי
- בינה מלאכותית
- AS
- עוזר
- עוזרים
- המשויך
- At
- אודיו
- לְהַגדִיל
- מוגבר
- אוטומטי
- אוטומטי
- באופן אוטומטי
- אוטומציה
- אוטומציה
- באופן אוטונומי
- לְהִמָנַע
- AWS
- Afer Inferentia
- בחזרה
- רקע
- רוחב פס
- בסיס
- מבוסס
- בסיסי
- בעיקרון
- BE
- להיות
- הופך להיות
- לפני
- התנהגות
- להלן
- תועלת
- הטבות
- מלבד
- הטוב ביותר
- שיטות עבודה מומלצות
- בֵּין
- גָדוֹל
- חיוב
- להתמזג
- תערובות
- בלוג
- ספר
- שניהם
- מותג
- לשבור
- לְגַשֵׁר
- שבור
- לִבנוֹת
- בונה
- בִּניָן
- עסקים
- יישומים עסקיים
- עסקים
- אבל
- by
- שיחה
- מבצע
- קמפיינים
- CAN
- יכול לקבל
- יכולות
- לְנַצֵל
- מקרה
- מקרים
- זרז
- לספק
- מסוים
- לאתגר
- האתגרים
- שינוי
- ערוצים
- טְעִינָה
- chatbot
- chatbots
- ChatGPT
- בדיקה
- בדיקות
- מיון
- לסווג
- ענן
- קלודרה
- אוסף
- COM
- שילוב
- לשלב
- משולב
- משלב
- שילוב
- איך
- מגיע
- Common
- תקשורת
- הקהילות
- חבר
- חברה
- להשלים
- השלמת
- מורכב
- מַקִיף
- הגיע למסקנה
- מקשר
- חיבורי
- קישוריות
- בהתחשב
- בנייה
- צרכן
- התנהגות צרכנית
- תוכן
- הקשר
- רציף
- ברציפות
- שיחה
- שיחה
- שיחות
- המרה
- אבן פינה
- משותף
- תַאֲגִיד
- לתקן
- עלות
- עלות תועלת
- יקר
- עלויות
- יכול
- יחד
- קורס
- לִיצוֹר
- יוצרים
- יצירה
- קריטי
- מכריע
- אוצר
- נוֹכְחִי
- מנהג
- לקוח
- מעורבות לקוחות
- שירות לקוחות
- לקוחות
- התאמה אישית
- אישית
- יומי
- כהה
- נתונים
- ניהול נתונים
- פלטפורמת נתונים
- עיבוד נתונים
- הגנה על נתונים
- אחסון נתונים
- מסד נתונים
- מאגרי מידע
- יְוֹם
- דֵצֶמבֶּר
- דצמבר 2021
- קבלת החלטות
- מוקדש
- עמוק
- למסור
- להתעמק
- דרישה
- הַדגָמָה
- דמוגרפיה
- הדגמות
- מַחלָקָה
- לפרוס
- פריסה
- פריסה
- פורס
- עיצוב
- מעוצב
- עיצובים
- רצוי
- פרט
- מְפוֹרָט
- פרטים
- לקבוע
- קובע
- קביעה
- מזיק
- מפתחים
- מתפתח
- צעצועי התפתחות
- ההבדלים
- אחר
- מובחנים
- דיגיטלי
- שיווק דיגיטלי
- ישירות
- תגלית
- צלילה
- שונה
- מְגוּוָן
- תיק מגוון
- do
- מסמך
- ניהול מסמכים
- תיעוד
- מסמכים
- תחומים
- עשה
- מטה
- טיוטה
- בְּמַהֲלָך
- דינמי
- מסחר אלקטרוני
- כל אחד
- קל
- אדג '
- יְעִילוּת
- יְעִילוּת
- יעיל
- יעילות
- או
- מעלה
- אמייל
- מיילים
- הטבעה
- מתגלה
- מדגיש
- עובד
- עובדים
- העסקת
- מעסיקה
- מעצים
- מאפשר
- מה שמאפשר
- מאמץ
- אנרגיה
- יעילויות אנרגיה
- פרויקטים בתחום האנרגיה
- מאורס
- התעסקות
- להגביר את
- משופר
- הגברה
- משפר
- שיפור
- לְהַבטִיחַ
- מבטיח
- הבטחתי
- מִפְעָל
- חברות
- שלם
- במיוחד
- מַהוּת
- להקים
- נוסד
- מקימים
- וכו '
- Ether (ETH)
- אֲפִילוּ
- אירועים
- מתפתח
- דוגמה
- דוגמאות
- מצוין
- הוצאת להורג
- קיימים
- לְזַרֵז
- יקר
- ניסיון
- חוויות
- מומחיות
- מומחים
- המסביר
- חקר
- להאריך
- מאריך
- חיצוני
- תמצית
- הוֹצָאָה
- פנים
- מקל
- הקלה
- ליפול
- מהר
- תכונות
- האכלה
- מעטים
- קבצים
- סופי
- פירמה
- ראשון
- מתאים
- גמיש
- תזרים
- תנודות
- להתמקד
- בעד
- טופס
- פוּרמָט
- קדימה
- קרן
- מסגרות
- תדר
- בתדירות גבוהה
- טרי
- החל מ-
- מלא
- לגמרי
- פונקציונלי
- נוסף
- היתוך
- עתיד
- משחקים
- פער
- ליצור
- מייצר
- יצירת
- דור
- גנרטטיבית
- AI Generative
- לקבל
- gif
- לתת
- נותן
- הצצה
- gmail
- טוב
- GPUs
- להעניק
- קרקע
- גדל
- הנחיות
- מדריך
- יד
- לטפל
- טיפול
- ידות על
- חומרה
- יש
- יש
- בראשותו
- לֵב
- מועיל
- עוזר
- מודגש
- פסים
- לִשְׂכּוֹר
- היסטוריה
- הוליסטית
- איך
- איך
- אולם
- hr
- HTTPS
- HubSpot
- היברידי
- i
- מזוהה
- לזהות
- if
- תמונות
- מיד
- פְּגִיעָה
- ליישם
- הפעלה
- יישום
- מיישמים
- לשפר
- שיפור
- in
- לכלול
- כולל
- כולל
- בע"מ
- אנשים
- תעשייה
- מובילים בתעשייה
- מידע
- מידע
- הודעה
- תשתית
- ייזום
- יוזמה
- יוזמות
- חידושים
- קלט
- תובנה
- תובנות
- להתקין
- למשל
- מייד
- הוראות
- לשלב
- משלב
- שילוב
- השתלבות
- מוֹדִיעִין
- אינטראקציה
- מִמְשָׁק
- ממשקים
- פנימי
- כלפי פנים
- אל תוך
- מורכבויות
- מוּרכָּב
- מבוא
- מלאי
- מעורבות
- כרוך
- בעיות
- IT
- שֶׁלָה
- ג'ונסון
- מסע
- יוני
- רק
- מפתח
- לדעת
- ידע
- חוסר
- שפה
- גָדוֹל
- לבסוף
- האחרון
- חוק
- משרד עורכי דין
- שכבה
- עוֹפֶרֶת
- מוביל
- מוביל
- ליגה
- למידה
- הוביל
- משפטי
- פחות
- לתת
- רמה
- רמות
- ממונפות
- מנופים
- מינוף
- סִפְרִיָה
- שקרים
- מעגל החיים
- כמו
- הגבלה
- לינקדין
- קישורים
- רשימה
- ברשימה
- מקומי
- מיקום
- ארוך
- נראה
- הסתכלות
- נראה
- נמוך
- מכונה
- למידת מכונה
- קסם
- ראשי
- גדול
- לעשות
- עושה
- עשייה
- לנהל
- ניהול
- מנהל
- ניהול
- רב
- סימן
- שוק
- טרנדים בשוק
- שיווק
- סוכנות שיווק
- קמפיינים שיווקיים
- מאי..
- אומר
- מנגנון
- מנגנוני
- מפגש
- מוּזְכָּר
- רק
- Messenger
- יכול
- אכפת לי
- דקות
- מַטעֶה
- מתערבב
- ML
- מודל
- מודלים
- MongoDB
- צג
- ניטור
- יותר
- יתר על כן
- רוב
- הרבה
- רב לאומי
- מספר
- מספר עצום
- טבעי
- שפה טבעית
- טבע
- הכרחי
- צורך
- נחוץ
- צרכי
- לעולם לא
- חדש
- חדשות
- הבא
- רעיון
- עַכשָׁיו
- רב
- קמצוץ
- Nvidia
- אובייקט
- יעדים
- of
- כבוי
- הַצָעָה
- מוצע
- הצעה
- המיוחדות שלנו
- לעתים קרובות
- on
- Onboarding
- פעם
- ONE
- רק
- לפתוח
- נתונים פתוחים
- OpenAI
- פועל
- תפעול
- אופטימלי
- אופטימיזציה
- אופטימיזציה
- אפשרויות
- or
- אורקל
- מתוזמר
- תזמור
- להזמין
- ארגון
- אִרְגוּנִי
- ארגונים
- מְקוֹרִי
- אחר
- אחרים
- שלנו
- הַחוּצָה
- תוצאות
- תפוקה
- יותר
- להתגבר על
- לְשַׁפֵּץ
- שֶׁלוֹ
- חבילה
- חלק
- שותפים
- עבר
- לבצע
- ביצועים
- מבצע
- תקופה
- הרשאות
- אישיות
- אישית
- כוח אדם
- מכריע
- מקום
- תכנית
- תוכניות
- פלטפורמה
- פלטפורמות
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- שחקן
- נקודה
- מדיניות
- מדיניות
- פופס
- פופולרי
- תיק עבודות
- אפשרי
- פוטנציאל
- כּוֹחַ
- מופעל
- חזק
- מעשי
- פרקטיקות
- צורך
- צפוי
- מקדים
- הכנה
- להכין
- להציג
- מצגות
- מחיר
- תמחור
- פְּרָטִיוּת
- פְּרָטִי
- בעיה
- תהליך
- תהליכים
- תהליך
- רכש
- המוצר
- מוצרים
- אנשי מקצוע
- פּרוֹפִיל
- פּרוֹיֶקט
- פרויקטים
- קידום
- קידום מכירות
- הצעה
- מוּצָע
- .
- אב טיפוס
- להוכיח
- לספק
- ובלבד
- ספק
- ספקים
- מספק
- מתן
- ציבורי
- מושך
- מושך
- לִרְכּוֹשׁ
- הזמנת רכש
- מכניס
- איכות
- כמות
- שאילתות
- שאלה
- רכס
- RE
- מגיע
- חומר עיוני
- מוכן
- זמן אמת
- נתונים בזמן אמת
- תחום
- קבלה
- לאחרונה
- זיהוי
- להמליץ
- להפחית
- הפחתה
- אזכור
- זיקוק
- בדבר
- קָשׁוּר
- יחסית
- הרלוונטיות
- רלוונטי
- אמינות
- אָמִין
- שְׂרִידִים
- מתחדשים
- אנרגיה מתחדשת
- דוחות לדוגמא
- מאגר
- נציגות
- לבקש
- בקשות
- נדרש
- דרישות
- דורש
- להציל
- מחקר
- משאבים
- תגובה
- תגובות
- אחריות
- תוצאות
- הסבה מקצועית
- עשיר
- תקין
- חָסוֹן
- תפקיד
- הפעלה
- פועל
- s
- בעל חכמים
- מכירות
- כוח מכירות
- שמור
- בקרת מערכות ותקשורת
- סולם
- סולם ai
- דרוג
- תרחיש
- לגרד
- בצורה חלקה
- בצורה חלקה
- חיפוש
- חיפושים
- חיפוש
- עונתי
- סעיפים
- מגזרים
- לבטח
- אבטחה
- בחירה
- לשלוח
- שליחה
- תחושה
- רגש
- סֶפּטֶמבֶּר
- שרות
- שירותים
- סט
- הצבה
- התקנה
- כמה
- משותף
- שיתוף
- יְרִי
- צריך
- משמעותי
- באופן משמעותי
- פָּשׁוּט
- לפשט
- רָפוּי
- חכם
- להחליק
- So
- תוכנה
- סולרי
- מופעל באנרגית השמש
- מוצק
- פִּתָרוֹן
- פתרונות
- לפתור
- כמה
- משהו
- מקורות
- מיוחד
- ספציפי
- מפורט
- ספֵּקטרוּם
- נאום
- לבלות
- ספורט
- ספורט
- SQL
- ערימות
- עומד
- התחלה
- החל
- החל
- התחלות
- תחנה
- צעדים
- עוד
- מניות
- אחסון
- חנות
- מאוחסן
- אסטרטגי
- אסטרטגיות
- נהירה
- לייעל
- מובנה
- נתונים מובנים ולא מובנים
- הַבנָיָה
- ניכר
- כזה
- מציע
- מערכת
- לסכם
- טעינת על
- מעולה
- להתחנן
- תמיכה
- תומך
- בטוח
- קיימות
- נדנדה
- סִנכְּרוּן
- מערכת
- מערכות
- מותאם
- לקחת
- לוקח
- יעד
- ממוקד
- המשימות
- משימות
- נבחרת
- צוותי
- טק
- טכני
- טכנולוגיות
- טכנולוגיה
- התקשורת
- אומר
- תבניות
- טֶקסט
- סיווג טקסט
- מֵאֲשֶׁר
- זֶה
- השמיים
- המידע
- שֶׁלָהֶם
- אותם
- עצמם
- אז
- שם.
- בכך
- אלה
- הֵם
- דבר
- לחשוב
- זֶה
- אלה
- שְׁלוֹשָׁה
- סף
- דרך
- כָּך
- הכרטיסים
- כרטיסים
- זמן
- פִּי
- כותרות
- ל
- אסימון
- כלי
- כלים
- נושאים
- לקראת
- מעקב
- מְאוּמָן
- הדרכה
- לשנות
- מַעֲבָר
- מְגַמָה
- מגמות
- מִשׁפָּט
- להפעיל
- סומך
- אמין
- טורבינה
- הדרכות
- סוגים
- מטריה
- ללא עוררין
- תחת
- בְּסִיסִי
- מדגיש
- להבין
- הבנה
- מבין
- מאוחד
- ייחודי
- תכונות ייחודיות
- עדכונים
- עדכון
- על
- us
- להשתמש
- במקרה להשתמש
- משתמש
- ממשק משתמש
- ידידותי למשתמש
- משתמשים
- שימושים
- באמצעות
- בְּדֶרֶך כְּלַל
- לנצל
- חלל
- בעל ערך
- מגוון
- שונים
- צדדיות
- באמצעות
- בַּר חַיִים
- וִידֵאוֹ
- ללכת
- היה
- דֶרֶך..
- we
- אתר
- אתרים
- טוֹב
- היו
- וואטסאפ
- מתי
- בכל פעם
- אשר
- בזמן
- מי
- רָחָב
- טווח רחב
- יצטרך
- רוח
- אנרגית רוח
- טורבינת רוח
- עם
- בתוך
- לְלֹא
- תיק עבודות
- עבד
- זרימת עבודה
- זרימות עבודה
- מקום עבודה
- תחנת עבודה
- לכתוב
- שנים
- כן
- אתה
- Zendesk
- זפירנט