בשנים האחרונות מודלים של שפה גדולה (LLM) עלו לגדולה ככלים יוצאי דופן המסוגלים להבין, ליצור ולתפעל טקסט במיומנות חסרת תקדים. היישומים הפוטנציאליים שלהם משתרעים בין סוכני שיחה ליצירת תוכן ואחזור מידע, תוך הבטחה לחולל מהפכה בכל התעשיות. עם זאת, רתימת הפוטנציאל הזה תוך הבטחת השימוש האחראי והיעיל במודלים אלה תלויה בתהליך הקריטי של הערכת LLM. הערכה היא משימה המשמשת למדידת איכות ואחריות התפוקה של שירות LLM או AI מחולל. הערכת LLMs מונעת רק מהרצון להבין ביצועים של מודל אלא גם מהצורך ליישם AI אחראי ומהצורך לצמצם את הסיכון של אספקת מידע שגוי או תוכן מוטה ולמזער את היווצרותם של מזיקים, לא בטוחים, זדוניים ולא אתיים. תוֹכֶן. יתר על כן, הערכת LLMs יכולה גם לסייע בהפחתת סיכוני אבטחה, במיוחד בהקשר של שיבוש מהיר בנתונים. עבור יישומים מבוססי LLM, חיוני לזהות נקודות תורפה וליישם אמצעי הגנה המגנים מפני הפרות פוטנציאליות ומניפולציות לא מורשות של נתונים.
על ידי מתן כלים חיוניים להערכת LLMs עם תצורה פשוטה וגישה בלחיצה אחת, אמזון סייג מייקר להבהיר יכולות הערכת LLM מעניקות ללקוחות גישה לרוב ההטבות הנ"ל. עם הכלים הללו ביד, האתגר הבא הוא לשלב הערכת LLM במחזור החיים של Machine Learning and Operation (MLOps) כדי להשיג אוטומציה ומדרגיות בתהליך. בפוסט זה, אנו מראים לכם כיצד לשלב את הערכת Amazon SageMaker Clarify LLM עם Amazon SageMaker Pipelines כדי לאפשר הערכת LLM בקנה מידה. בנוסף, אנו מספקים דוגמה לקוד בזה GitHub מאגר כדי לאפשר למשתמשים לבצע הערכת ריבוי מודלים מקבילה בקנה מידה, תוך שימוש בדוגמאות כגון Llama2-7b-f, Falcon-7b ומודלים מכוונים של Llama2-7b.
מי צריך לבצע הערכת LLM?
כל מי שמתאמן, מכוון או פשוט משתמש ב-LLM מיומן מראש צריך להעריך אותו במדויק כדי להעריך את התנהגות האפליקציה המופעלת על ידי אותו LLM. בהתבסס על עיקרון זה, אנו יכולים לסווג משתמשי בינה מלאכותית גנרטיבית הזקוקים ליכולות הערכת LLM ל-3 קבוצות כפי שמוצג באיור הבא: ספקי מודל, מכווננים וצרכנים.
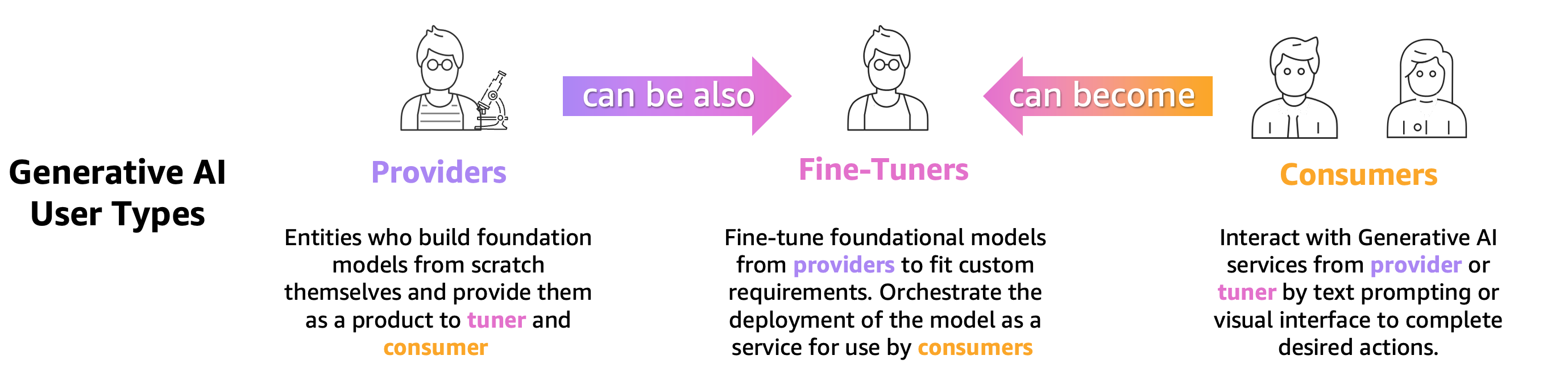
- ספקי מודל יסודי (FM). רכבת מודלים למטרות כלליות. מודלים אלה יכולים לשמש עבור משימות רבות במורד הזרם, כגון מיצוי תכונות או ליצירת תוכן. כל מודל מאומן צריך להיות מודד מול משימות רבות לא רק כדי להעריך את הביצועים שלו אלא גם כדי להשוות אותו עם מודלים קיימים אחרים, לזהות תחומים שזקוקים לשיפורים ולבסוף, לעקוב אחר ההתקדמות בתחום. ספקי מודלים צריכים גם לבדוק את נוכחותן של הטיות כלשהן כדי להבטיח את איכות מערך הנתונים ההתחלתי ואת ההתנהגות הנכונה של המודל שלהם. איסוף נתוני הערכה חיוני עבור ספקי מודל. יתר על כן, יש לאסוף נתונים ומדדים אלה כדי לעמוד בתקנות הקרובות. ISO 42001, ה צו ביצוע של מינהל ביידן, ו חוק AI של האיחוד האירופי לפתח תקנים, כלים ובדיקות כדי להבטיח שמערכות AI בטוחות, מאובטחות ומהימנות. לדוגמה, על חוק הבינה המלאכותית של האיחוד האירופי מוטלת המשימה לספק מידע באילו מערכי נתונים משמשים להדרכה, איזה כוח חישוב נדרש כדי להפעיל את המודל, לדווח על תוצאות מודל מול מדדים ציבוריים/סטנדרטיים בתעשייה ולשתף תוצאות של בדיקות פנימיות וחיצוניות.
- מספר סימוכין מכוונים עדינים רוצה לפתור משימות ספציפיות (כגון סיווג רגשות, סיכום, מענה על שאלות) וכן מודלים מאומנים מראש לאימוץ משימות ספציפיות לתחום. הם זקוקים למדדי הערכה שנוצרו על ידי ספקי מודלים כדי לבחור את המודל שהוכשר מראש הנכון כנקודת התחלה.
הם צריכים להעריך את המודלים המכוונים שלהם מול מקרה השימוש הרצוי שלהם עם מערכי נתונים ספציפיים למשימה או לתחום. לעתים קרובות, הם חייבים לאצור וליצור את מערכי הנתונים הפרטיים שלהם, שכן מערכי נתונים זמינים לציבור, אפילו אלה המיועדים למשימה מסוימת, עשויים שלא ללכוד כראוי את הניואנסים הנדרשים למקרה השימוש הספציפי שלהם.
כוונון עדין מהיר יותר וזול יותר מהכשרה מלאה ודורש איטרציה אופרטיבית מהירה יותר לפריסה ובדיקה מכיוון שבדרך כלל נוצרים מודלים מועמדים רבים. הערכת מודלים אלו מאפשרת שיפור מתמיד של המודל, כיול וניפוי באגים. שימו לב שמכווננים עדינים יכולים להפוך לצרכנים של הדגמים שלהם כאשר הם מפתחים יישומים בעולם האמיתי. - מספר סימוכין צרכנים או מפסי דגמים משרתים ומנטרים מודלים למטרות כלליות או מכוונות עדינות בייצור, במטרה לשפר את היישומים או השירותים שלהם באמצעות אימוץ של LLMs. האתגר הראשון שעומד בפניהם הוא להבטיח שה-LLM הנבחר תואם את הצרכים הספציפיים, העלות והביצועים שלהם. פרשנות והבנת תפוקות המודל היא דאגה מתמשכת, במיוחד כאשר מדובר בפרטיות ואבטחת מידע (למשל לביקורת סיכונים ותאימות בתעשיות מוסדרות, כגון המגזר הפיננסי). הערכת מודל רציפה היא קריטית כדי למנוע הפצה של הטיה או תוכן מזיק. על ידי הטמעת מסגרת ניטור והערכה חזקה, צרכני מודל יכולים לזהות באופן יזום ולטפל ברגרסיה ב-LLMs, ולהבטיח שהמודלים הללו ישמרו על יעילותם ומהימנותם לאורך זמן.
כיצד לבצע הערכת LLM
הערכת מודל יעילה כוללת שלושה מרכיבים בסיסיים: FM אחד או יותר או מודלים מכוונים עדינים להערכת מערכי הנתונים של הקלט (הנחיות, שיחות או קלט רגיל) והיגיון ההערכה.
כדי לבחור את המודלים להערכה, יש לקחת בחשבון גורמים שונים, כולל מאפייני נתונים, מורכבות הבעיה, משאבי חישוב זמינים והתוצאה הרצויה. מאגר הנתונים של הקלט מספק את הנתונים הדרושים לאימון, כוונון עדין ובדיקת הדגם הנבחר. זה חיוני שמאגר הנתונים הזה יהיה מובנה היטב, מייצג ואיכותי, שכן ביצועי המודל תלויים במידה רבה בנתונים שהוא לומד מהם. לבסוף, לוגיקה של הערכה מגדירה את הקריטריונים והמדדים המשמשים להערכת ביצועי המודל.
יחד, שלושת המרכיבים הללו יוצרים מסגרת מגובשת המבטיחה הערכה קפדנית ושיטתית של מודלים של למידת מכונה, שמובילה בסופו של דבר להחלטות מושכלות ולשיפורים ביעילות המודל.
טכניקות להערכת מודלים הן עדיין תחום מחקר פעיל. אמות מידה ומסגרות ציבוריות רבות נוצרו על ידי קהילת החוקרים בשנים האחרונות כדי לכסות מגוון רחב של משימות ותרחישים כגון דבק, דבק מגע, הֶגֶה, MMLU ו ספסל BIG. לממדים אלה יש לוחות הישגים שניתן להשתמש בהם כדי להשוות ולהבדיל בין מודלים מוערכים. אמות מידה, כמו HELM, שואפות גם להעריך על מדדים מעבר למדדי דיוק, כמו דיוק או ציון F1. מדד HELM כולל מדדים להוגנות, הטיה ורעילות שיש להם חשיבות לא פחות משמעותית בציון הערכת המודל הכולל.
כל המדדים הללו כוללים קבוצה של מדדים המודדים כיצד המודל מתפקד במשימה מסוימת. המדדים המפורסמים והנפוצים ביותר הם אדום (מחקר מכוון להיזכרות להערכה מתמשכת), BLUE (לימודי הערכה דו-לשונית), או מטאור (מדד להערכת תרגום עם הזמנה מפורשת). מדדים אלה משמשים כלי שימושי להערכה אוטומטית, ומספקים מדדים כמותיים של דמיון מילוני בין טקסט שנוצר לטקסט ייחוס. עם זאת, הם אינם תופסים את מלוא הרוחב של יצירת שפה דמוית אדם, הכוללת הבנה סמנטית, הקשר או ניואנסים סגנוניים. לדוגמה, HELM אינו מספק פרטי הערכה הרלוונטיים למקרי שימוש ספציפיים, פתרונות לבדיקת הנחיות מותאמות אישית ותוצאות המפורשות בקלות על ידי לא מומחים, מכיוון שהתהליך יכול להיות יקר, לא קל להרחבה, ורק למשימות ספציפיות.
יתרה מזאת, השגת יצירת שפה דמוית אדם דורשת לעתים קרובות שילוב של אדם-בלולאה כדי להביא הערכות איכותיות ושיקול דעת אנושי כדי להשלים את מדדי הדיוק האוטומטיים. הערכה אנושית היא שיטה חשובה להערכת תפוקות LLM אך היא יכולה להיות גם סובייקטיבית ונוטה להטיה מכיוון שלמעריכים אנושיים שונים עשויים להיות דעות ופרשנויות מגוונות של איכות הטקסט. יתר על כן, הערכה אנושית יכולה להיות עתירת משאבים ויקרה והיא עלולה לדרוש זמן ומאמץ משמעותיים.
בואו נצלול עמוק לתוך האופן שבו Amazon SageMaker Clarify מחבר בצורה חלקה את הנקודות, ומסייע ללקוחות לבצע הערכה ובחירה יסודית של מודלים.
הערכת LLM עם Amazon SageMaker Clarify
Amazon SageMaker Clarify עוזרת ללקוחות להפוך את המדדים לאוטומטיים, כולל אך לא רק דיוק, חוסן, רעילות, סטריאוטיפים וידע עובדתי עבור אוטומטיות, וסגנון, קוהרנטיות, רלוונטיות להערכה מבוססת אדם ושיטות הערכה על ידי מתן מסגרת להערכת LLMs ושירותים מבוססי LLM כגון Amazon Bedrock. כשירות מנוהל במלואו, SageMaker Clarify מפשטת את השימוש במסגרות הערכה בקוד פתוח בתוך Amazon SageMaker. לקוחות יכולים לבחור מערכי נתונים ומדדי הערכה רלוונטיים עבור התרחישים שלהם ולהרחיב אותם עם מערכי נתונים מהירים ואלגוריתמי הערכה משלהם. SageMaker Clarify מספק תוצאות הערכה במספר פורמטים כדי לתמוך בתפקידים שונים בזרימת העבודה של LLM. מדעני נתונים יכולים לנתח תוצאות מפורטות עם הדמיות של SageMaker Clarify במחברות, כרטיסי מודל של SageMaker ודוחות PDF. בינתיים, צוותי תפעול יכולים להשתמש ב-Amazon SageMaker GroundTruth כדי לסקור ולהעיר פריטים בסיכון גבוה ש-SageMaker Clarify מזהה. לדוגמה, על ידי סטריאוטיפים, רעילות, PII בריחה או דיוק נמוך.
הערות ולמידת חיזוק משמשים לאחר מכן כדי להפחית סיכונים פוטנציאליים. הסברים ידידותיים לאדם על הסיכונים שזוהו מזרזים את תהליך הבדיקה הידנית, ובכך מפחיתים עלויות. דוחות סיכום מציעים לבעלי עניין עסקיים אמות מידה השוואתיות בין מודלים וגרסאות שונות, ומקלים על קבלת החלטות מושכלת.
האיור הבא מציג את המסגרת להערכת LLMs ושירותים מבוססי LLM:

Amazon SageMaker Clarify LLM evaluation היא ספריית קוד פתוח של Foundation Model Evaluation (FMEval) שפותחה על ידי AWS כדי לעזור ללקוחות להעריך בקלות LLMs. כל הפונקציונליות שולבו גם באמזון SageMaker Studio כדי לאפשר הערכת LLM עבור המשתמשים שלה. בסעיפים הבאים, אנו מציגים את השילוב של יכולות הערכת LLM של Amazon SageMaker Clarify עם צינורות SageMaker כדי לאפשר הערכת LLM בקנה מידה על ידי שימוש בעקרונות MLOps.
מחזור החיים של Amazon SageMaker MLOps
בתור הפוסט"מפת הדרכים של בסיס MLOps לארגונים עם Amazon SageMaker" מתאר, MLOps הוא השילוב של תהליכים, אנשים וטכנולוגיה כדי לייצר מקרי שימוש ב-ML ביעילות.
האיור הבא מציג את מחזור החיים של MLOps מקצה לקצה:

מסע טיפוסי מתחיל עם מדען נתונים שיוצר מחברת הוכחת מושג (PoC) כדי להוכיח ש-ML יכול לפתור בעיה עסקית. במהלך הפיתוח של הוכחת קונספט (PoC), זה נופל על מדען הנתונים להמיר את מדדי הביצועים העיקריים העסקיים (KPIs) למדדי מודל למידת מכונה, כגון דיוק או שיעור חיובי שגוי, ולהשתמש במערך נתונים מוגבל כדי להעריך את אלה. מדדים. מדעני נתונים משתפים פעולה עם מהנדסי ML למעבר קוד ממחברות למאגרים, יצירת צינורות ML באמצעות Amazon SageMaker Pipelines, המחברים שלבי עיבוד ומשימות שונות, כולל עיבוד מקדים, הדרכה, הערכה ועיבוד לאחר, והכל תוך שילוב מתמיד של ייצור חדש נתונים. הפריסה של Amazon SageMaker Pipelines מסתמכת על אינטראקציות של מאגר והפעלת צינור CI/CD. צינור ML שומר על מודלים בעלי ביצועים גבוהים, תמונות מיכל, תוצאות הערכה ומידע סטטוס ברישום מודל, שבו בעלי עניין במודל מעריכים ביצועים ומחליטים על התקדמות לייצור על סמך תוצאות ביצועים ואמות מידה, ולאחר מכן הפעלה של צינור CI/CD נוסף לפריסת הבמה והפקה. לאחר הייצור, צרכני ML מנצלים את המודל באמצעות הסקה מופעלת על ידי יישומים באמצעות קריאות ישירות או קריאות API, עם לולאות משוב לבעלי המודל לצורך הערכת ביצועים מתמשכת.
Amazon SageMaker Clarify ושילוב MLOps
בעקבות מחזור החיים של MLOps, מכווננים או משתמשים בדגמי קוד פתוח מייצרים מודלים מכוונים או FM באמצעות Amazon SageMaker Jumpstart ושירותי MLOps, כמתואר ב- יישום שיטות MLOps עם מודלים מאומנים מראש של Amazon SageMaker JumpStart. זה הוביל לתחום חדש עבור פעולות מודל יסוד (FMOps) ו-LLM Operations (LLMOps) FMOps/LLMOps: תפעול AI גנרטיבי והבדלים עם MLOps.
האיור הבא מציג את מחזור החיים של LLMOps מקצה לקצה:
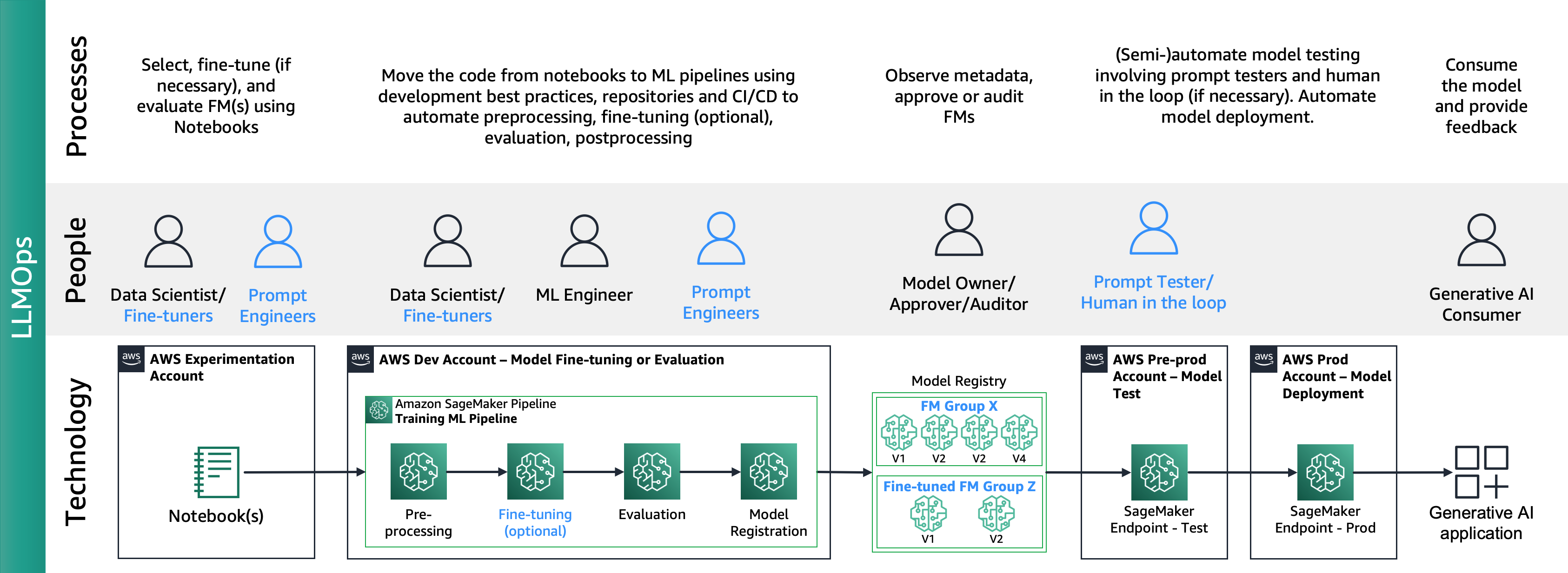
ב-LLMOps ההבדלים העיקריים בהשוואה ל-MLOps הם בחירת מודל והערכת מודל הכוללת תהליכים ומדדים שונים. בשלב הניסויים הראשוניים, מדעני הנתונים (או המכוונים העדינים) בוחרים את ה-FM שישמש למקרה שימוש ספציפי של AI Generative.
זה גורם לעתים קרובות לבדיקה וכיוונון עדין של מספר FMs, שחלקם עשויים להניב תוצאות דומות. לאחר בחירת המודל/ים, המהנדסים המהירים אחראים להכין את נתוני הקלט הדרושים ואת הפלט הצפוי להערכה (למשל הנחיות קלט הכוללות נתוני קלט ושאילתה) ולהגדיר מדדים כמו דמיון ורעילות. בנוסף למדדים אלה, מדעני נתונים או מכוונים עדינים חייבים לאמת את התוצאות ולבחור את ה-FM המתאים לא רק על מדדי דיוק, אלא על יכולות אחרות כמו חביון ועלות. לאחר מכן, הם יכולים לפרוס מודל לנקודת קצה של SageMaker ולבדוק את הביצועים שלו בקנה מידה קטן. בעוד ששלב הניסויים עשוי לכלול תהליך פשוט, המעבר לייצור דורש מהלקוחות להפוך את התהליך לאוטומטי ולשפר את חוסנו של הפתרון. לכן, עלינו לצלול לעומק כיצד להפוך הערכה לאוטומטית, לאפשר לבודקים לבצע הערכה יעילה בקנה מידה וליישם ניטור בזמן אמת של קלט ופלט של מודל.
אוטומציה של הערכת FM
Amazon SageMaker Pipelines אוטומציה את כל השלבים של עיבוד מקדים, כוונון עדין FM (אופציונלי) והערכה בקנה מידה. בהתחשב במודלים שנבחרו במהלך הניסוי, מהנדסים מהירים צריכים לכסות קבוצה גדולה יותר של מקרים על ידי הכנת הנחיות רבות ואחסוןם במאגר אחסון ייעודי הנקרא קטלוג הנחיות. למידע נוסף, עיין ב FMOps/LLMOps: תפעול AI גנרטיבי והבדלים עם MLOps. לאחר מכן, ניתן לבנות את הצינורות של Amazon SageMaker באופן הבא:
תרחיש 1 - הערכת FM מרובים: בתרחיש זה, ה-FM יכולים לכסות את מקרה השימוש העסקי ללא כוונון עדין. ה-Amazon SageMaker Pipeline מורכב מהשלבים הבאים: עיבוד מקדים של נתונים, הערכה מקבילה של מספר FMs, השוואת מודלים ובחירה על סמך דיוק ומאפיינים אחרים כמו עלות או חביון, רישום של חפצי מודל נבחרים ומטא נתונים.
התרשים הבא ממחיש ארכיטקטורה זו.

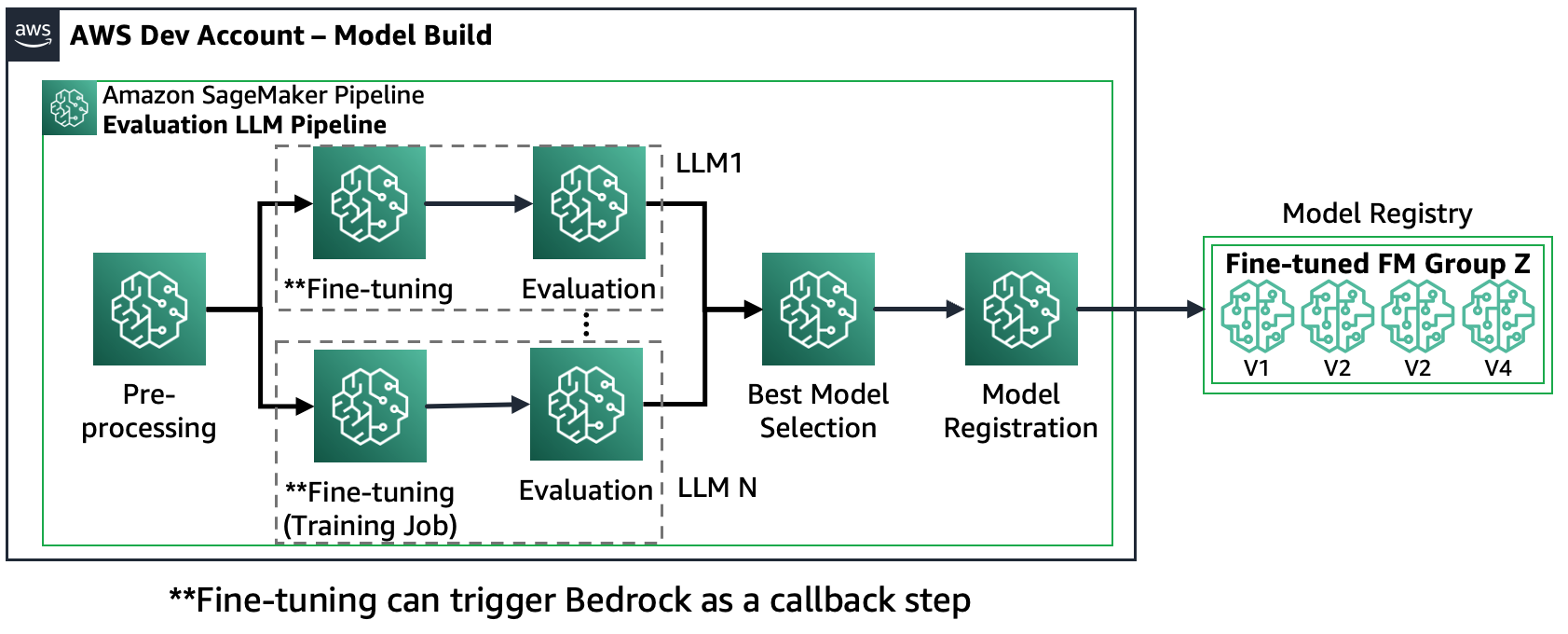
תרחיש 2 - כוונן והעריך מספר FMs: בתרחיש זה, ה-Amazon SageMaker Pipeline בנוי בדומה לתרחיש 1, אך הוא פועל במקביל גם שלבי כוונון והערכה עבור כל FM. הדגם המכוונן הטוב ביותר יירשם במרשם הדגמים.
התרשים הבא ממחיש ארכיטקטורה זו.
תרחיש 3 - הערכת FM מרובים ו-FM מכוונים עדינים: תרחיש זה הוא שילוב של הערכת FMs למטרות כלליות ו-FM מכוונים עדין. במקרה זה, הלקוחות רוצים לבדוק אם דגם מכוון יכול לבצע טוב יותר מאשר FM למטרות כלליות.
האיור הבא מציג את השלבים של SageMaker Pipeline שהתקבלו.
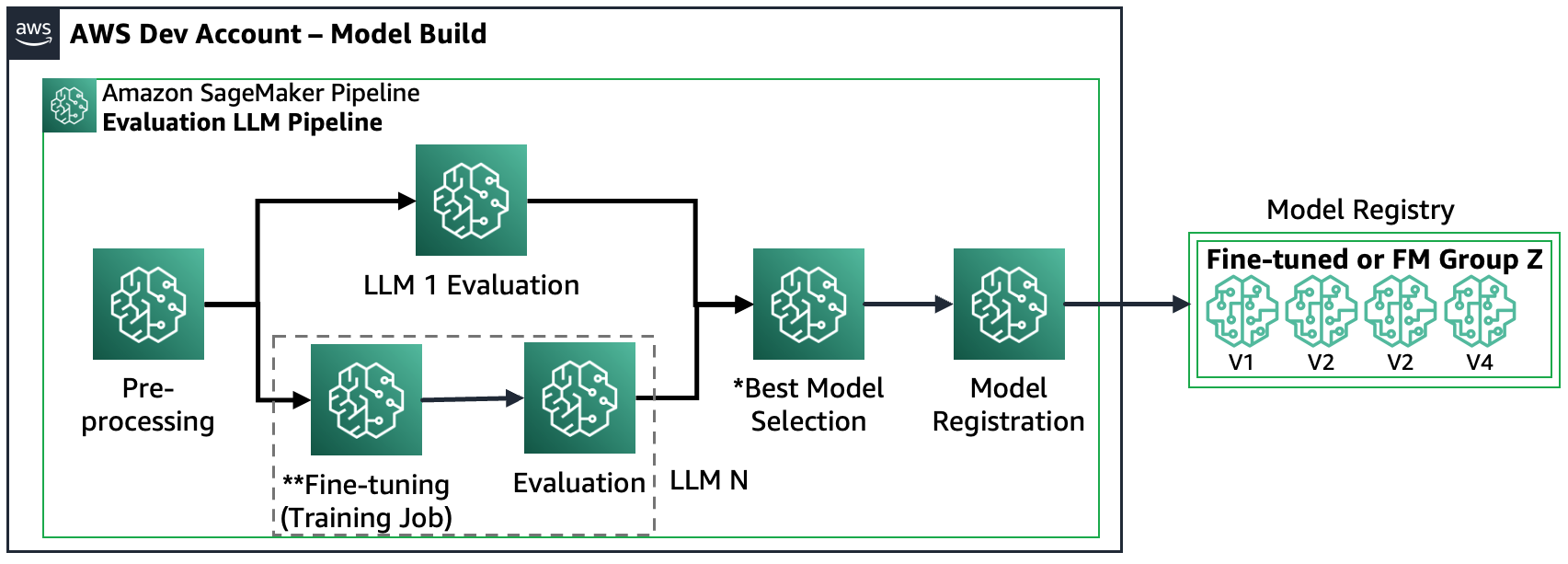
שים לב שהרישום של המודל פועל לפי שני דפוסים: (א) אחסן מודל וחפצי קוד פתוח או (ב) אחסן הפניה ל-FM קנייני. למידע נוסף, עיין ב FMOps/LLMOps: תפעול AI גנרטיבי והבדלים עם MLOps.
סקירת פתרונות
כדי להאיץ את המסע שלך להערכת LLM בקנה מידה, יצרנו פתרון שמיישם את התרחישים באמצעות Amazon SageMaker Clarify וגם ב-SDK החדש של Amazon SageMaker Pipelines. דוגמה לקוד, כולל מערכי נתונים, מחברות מקור ו-SageMaker Pipelines (צעדים וצינור ML), זמינה ב- GitHub. כדי לפתח פתרון לדוגמה זה, השתמשנו בשני FMs: Llama2 ו- Falcon-7B. בפוסט זה, ההתמקדות העיקרית שלנו היא במרכיבי המפתח של פתרון SageMaker Pipeline הנוגעים לתהליך ההערכה.
תצורת הערכה: לצורך סטנדרטיזציה של הליך ההערכה, יצרנו קובץ תצורה של YAML, (evaluation_config.yaml), המכיל את הפרטים הדרושים לתהליך ההערכה כולל מערך הנתונים, המודל/ים והאלגוריתמים שיופעלו במהלך שלב הערכה של צינור SageMaker. הדוגמה הבאה ממחישה את קובץ התצורה:
pipeline:
name: "llm-evaluation-multi-models-hybrid"
dataset:
dataset_name: "trivia_qa_sampled"
input_data_location: "evaluation_dataset_trivia.jsonl"
dataset_mime_type: "jsonlines"
model_input_key: "question"
target_output_key: "answer"
models:
- name: "llama2-7b-f"
model_id: "meta-textgeneration-llama-2-7b-f"
model_version: "*"
endpoint_name: "llm-eval-meta-textgeneration-llama-2-7b-f"
deployment_config:
instance_type: "ml.g5.2xlarge"
num_instances: 1
evaluation_config:
output: '[0].generation.content'
content_template: [[{"role":"user", "content": "PROMPT_PLACEHOLDER"}]]
inference_parameters:
max_new_tokens: 100
top_p: 0.9
temperature: 0.6
custom_attributes:
accept_eula: True
prompt_template: "$feature"
cleanup_endpoint: True
- name: "falcon-7b"
...
- name: "llama2-7b-finetuned"
...
finetuning:
train_data_path: "train_dataset"
validation_data_path: "val_dataset"
parameters:
instance_type: "ml.g5.12xlarge"
num_instances: 1
epoch: 1
max_input_length: 100
instruction_tuned: True
chat_dataset: False
...
algorithms:
- algorithm: "FactualKnowledge"
module: "fmeval.eval_algorithms.factual_knowledge"
config: "FactualKnowledgeConfig"
target_output_delimiter: "<OR>"שלב הערכה: ה-SDK החדש של SageMaker Pipeline מספק למשתמשים את הגמישות להגדיר שלבים מותאמים אישית בזרימת העבודה של ML באמצעות עיצוב ה-'@step' Python. לכן, המשתמשים צריכים ליצור סקריפט Python בסיסי שעורך את ההערכה, באופן הבא:
def evaluation(data_s3_path, endpoint_name, data_config, model_config, algorithm_config, output_data_path,):
from fmeval.data_loaders.data_config import DataConfig
from fmeval.model_runners.sm_jumpstart_model_runner import JumpStartModelRunner
from fmeval.reporting.eval_output_cells import EvalOutputCell
from fmeval.constants import MIME_TYPE_JSONLINES
s3 = boto3.client("s3")
bucket, object_key = parse_s3_url(data_s3_path)
s3.download_file(bucket, object_key, "dataset.jsonl")
config = DataConfig(
dataset_name=data_config["dataset_name"],
dataset_uri="dataset.jsonl",
dataset_mime_type=MIME_TYPE_JSONLINES,
model_input_location=data_config["model_input_key"],
target_output_location=data_config["target_output_key"],
)
evaluation_config = model_config["evaluation_config"]
content_dict = {
"inputs": evaluation_config["content_template"],
"parameters": evaluation_config["inference_parameters"],
}
serializer = JSONSerializer()
serialized_data = serializer.serialize(content_dict)
content_template = serialized_data.replace('"PROMPT_PLACEHOLDER"', "$prompt")
print(content_template)
js_model_runner = JumpStartModelRunner(
endpoint_name=endpoint_name,
model_id=model_config["model_id"],
model_version=model_config["model_version"],
output=evaluation_config["output"],
content_template=content_template,
custom_attributes="accept_eula=true",
)
eval_output_all = []
s3 = boto3.resource("s3")
output_bucket, output_index = parse_s3_url(output_data_path)
for algorithm in algorithm_config:
algorithm_name = algorithm["algorithm"]
module = importlib.import_module(algorithm["module"])
algorithm_class = getattr(module, algorithm_name)
algorithm_config_class = getattr(module, algorithm["config"])
eval_algo = algorithm_class(algorithm_config_class(target_output_delimiter=algorithm["target_output_delimiter"]))
eval_output = eval_algo.evaluate(model=js_model_runner, dataset_config=config, prompt_template=evaluation_config["prompt_template"], save=True,)
print(f"eval_output: {eval_output}")
eval_output_all.append(eval_output)
html = markdown.markdown(str(EvalOutputCell(eval_output[0])))
file_index = (output_index + "/" + model_config["name"] + "_" + eval_algo.eval_name + ".html")
s3_object = s3.Object(bucket_name=output_bucket, key=file_index)
s3_object.put(Body=html)
eval_result = {"model_config": model_config, "eval_output": eval_output_all}
print(f"eval_result: {eval_result}")
return eval_resultSageMaker Pipeline: לאחר יצירת השלבים הדרושים, כגון עיבוד מוקדם של נתונים, פריסת מודלים והערכת מודלים, המשתמש צריך לקשר את השלבים יחדיו באמצעות SageMaker Pipeline SDK. ה-SDK החדש מייצר אוטומטית את זרימת העבודה על ידי פירוש התלות בין שלבים שונים כאשר ממשק API ליצירת SageMaker Pipeline מופעל כפי שמוצג בדוגמה הבאה:
import os
import argparse
from datetime import datetime
import sagemaker
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.function_step import step
from sagemaker.workflow.step_outputs import get_step
# Import the necessary steps
from steps.preprocess import preprocess
from steps.evaluation import evaluation
from steps.cleanup import cleanup
from steps.deploy import deploy
from lib.utils import ConfigParser
from lib.utils import find_model_by_name
if __name__ == "__main__":
os.environ["SAGEMAKER_USER_CONFIG_OVERRIDE"] = os.getcwd()
sagemaker_session = sagemaker.session.Session()
# Define data location either by providing it as an argument or by using the default bucket
default_bucket = sagemaker.Session().default_bucket()
parser = argparse.ArgumentParser()
parser.add_argument("-input-data-path", "--input-data-path", dest="input_data_path", default=f"s3://{default_bucket}/llm-evaluation-at-scale-example", help="The S3 path of the input data",)
parser.add_argument("-config", "--config", dest="config", default="", help="The path to .yaml config file",)
args = parser.parse_args()
# Initialize configuration for data, model, and algorithm
if args.config:
config = ConfigParser(args.config).get_config()
else:
config = ConfigParser("pipeline_config.yaml").get_config()
evalaution_exec_id = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
pipeline_name = config["pipeline"]["name"]
dataset_config = config["dataset"] # Get dataset configuration
input_data_path = args.input_data_path + "/" + dataset_config["input_data_location"]
output_data_path = (args.input_data_path + "/output_" + pipeline_name + "_" + evalaution_exec_id)
print("Data input location:", input_data_path)
print("Data output location:", output_data_path)
algorithms_config = config["algorithms"] # Get algorithms configuration
model_config = find_model_by_name(config["models"], "llama2-7b")
model_id = model_config["model_id"]
model_version = model_config["model_version"]
evaluation_config = model_config["evaluation_config"]
endpoint_name = model_config["endpoint_name"]
model_deploy_config = model_config["deployment_config"]
deploy_instance_type = model_deploy_config["instance_type"]
deploy_num_instances = model_deploy_config["num_instances"]
# Construct the steps
processed_data_path = step(preprocess, name="preprocess")(input_data_path, output_data_path)
endpoint_name = step(deploy, name=f"deploy_{model_id}")(model_id, model_version, endpoint_name, deploy_instance_type, deploy_num_instances,)
evaluation_results = step(evaluation, name=f"evaluation_{model_id}", keep_alive_period_in_seconds=1200)(processed_data_path, endpoint_name, dataset_config, model_config, algorithms_config, output_data_path,)
last_pipeline_step = evaluation_results
if model_config["cleanup_endpoint"]:
cleanup = step(cleanup, name=f"cleanup_{model_id}")(model_id, endpoint_name)
get_step(cleanup).add_depends_on([evaluation_results])
last_pipeline_step = cleanup
# Define the SageMaker Pipeline
pipeline = Pipeline(
name=pipeline_name,
steps=[last_pipeline_step],
)
# Build and run the Sagemaker Pipeline
pipeline.upsert(role_arn=sagemaker.get_execution_role())
# pipeline.upsert(role_arn="arn:aws:iam::<...>:role/service-role/AmazonSageMaker-ExecutionRole-<...>")
pipeline.start()הדוגמה מיישמת את ההערכה של FM יחיד על ידי עיבוד מקדים של מערך הנתונים הראשוני, פריסת המודל והפעלת ההערכה. הגרף האציקלי המכוון לצינור שנוצר (DAG) מוצג באיור הבא.
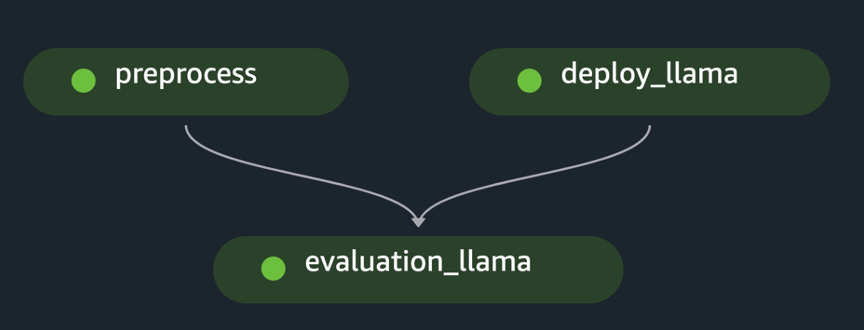
בעקבות גישה דומה ועל ידי שימוש והתאמת הדוגמה כוונן את דגמי LLaMA 2 ב- SageMaker JumpStart, יצרנו את הצינור כדי להעריך מודל מכוונן, כפי שמוצג באיור הבא.

על ידי שימוש בשלבים הקודמים של SageMaker Pipeline כקוביות "לגו", פיתחנו את הפתרון עבור תרחיש 1 ותרחיש 3, כפי שמוצג באיורים הבאים. ספציפית, ה GitHub המאגר מאפשר למשתמש להעריך מספר FMs במקביל או לבצע הערכה מורכבת יותר המשלבת הערכה של מודלים בסיסיים ומכווננים כאחד.

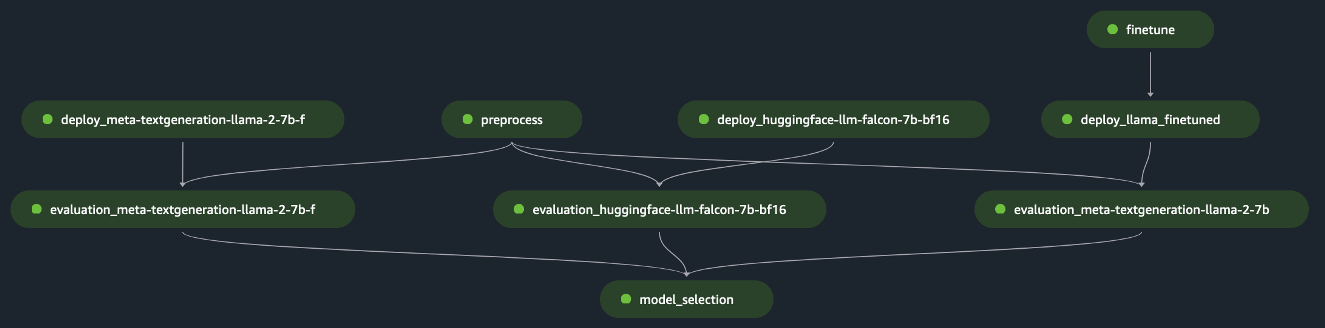
פונקציות נוספות הזמינות במאגר כוללות את הדברים הבאים:
- יצירת צעדי הערכה דינמית: הפתרון שלנו מייצר את כל שלבי ההערכה הדרושים באופן דינמי על סמך קובץ התצורה כדי לאפשר למשתמשים להעריך כל מספר של דגמים. הרחבנו את הפתרון כדי לתמוך באינטגרציה קלה של סוגים חדשים של דגמים, כגון Hugging Face או Amazon Bedrock.
- מנע פריסה מחדש של נקודות קצה: אם כבר קיימת נקודת קצה, אנו מדלגים על תהליך הפריסה. זה מאפשר למשתמש לעשות שימוש חוזר בנקודות קצה עם FMs לצורך הערכה, וכתוצאה מכך חיסכון בעלויות וזמן פריסה מופחת.
- ניקוי נקודת קצה: לאחר השלמת ההערכה, ה- SageMaker Pipeline מבטל את נקודות הקצה שנפרסו. ניתן להרחיב את הפונקציונליות הזו כדי לשמור על נקודת הקצה הטובה ביותר של הדגם בחיים.
- שלב בחירת הדגם: הוספנו מציין מיקום של שלב בחירת דגם הדורש את ההיגיון העסקי של בחירת הדגם הסופי, כולל קריטריונים כגון עלות או זמן השהייה.
- שלב רישום הדגם: ניתן לרשום את הדגם הטוב ביותר ב- Amazon SageMaker Model Registry כגרסה חדשה של קבוצת דגמים ספציפית.
- בריכה חמה: בריכות חמות מנוהלות של SageMaker מאפשרות לך לשמור ולעשות שימוש חוזר בתשתית המסופקת לאחר השלמת עבודה כדי להפחית את זמן האחזור לעומסי עבודה חוזרים
האיור הבא ממחיש את היכולות הללו ודוגמה להערכה מרובת מודלים שהמשתמשים יכולים ליצור בקלות ובאופן דינמי באמצעות הפתרון שלנו. GitHub מאגר.

שמרנו בכוונה על הכנת הנתונים מחוץ לתחום כפי שהוא יתואר בפוסט אחר לעומק, כולל עיצובי קטלוגים מהירים, תבניות הנחיות, אופטימיזציה מהירה. למידע נוסף והגדרות רכיבים קשורות, עיין ב FMOps/LLMOps: תפעול AI גנרטיבי והבדלים עם MLOps.
סיכום
בפוסט זה, התמקדנו כיצד לבצע אוטומציה ותפעולית של הערכת LLMs בקנה מידה באמצעות יכולות הערכת LLM של Amazon SageMaker Clarify ו-Amazon SageMaker Pipelines. בנוסף לעיצובי ארכיטקטורה תיאורטיים, יש לנו קוד לדוגמה בזה GitHub מאגר (הכולל מכשירי FM Llama2 ו-Falcon-7B) כדי לאפשר ללקוחות לפתח מנגנוני הערכה ניתנים להרחבה משלהם.
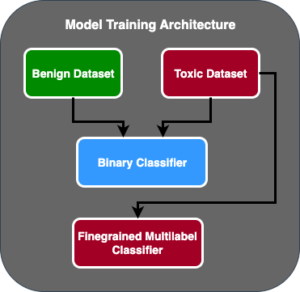
האיור הבא מציג את ארכיטקטורת הערכת המודל.
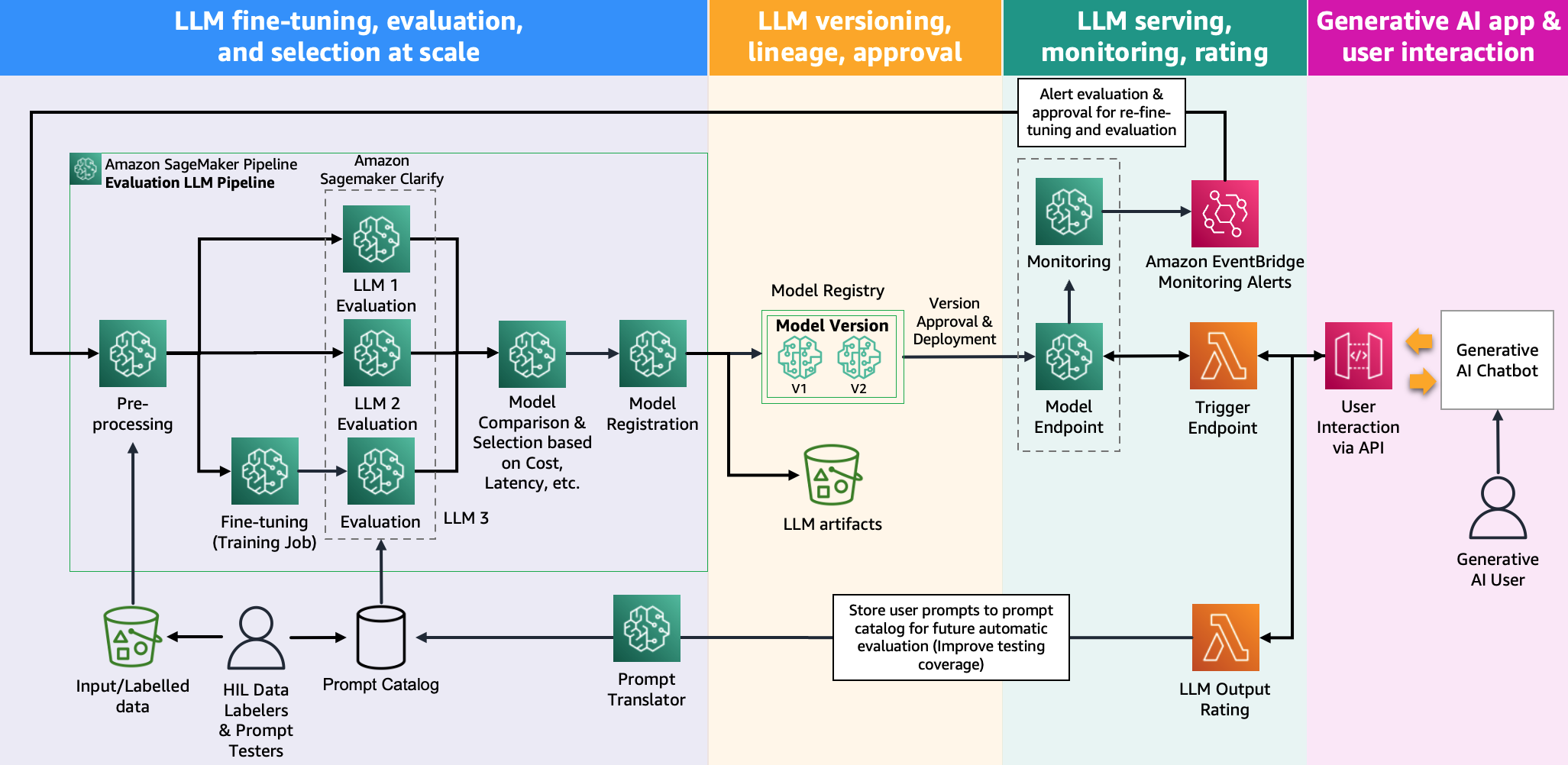
בפוסט זה, התמקדנו בהפעלת הערכת LLM בקנה מידה כפי שמוצג בצד שמאל של האיור. בעתיד, נתמקד בפיתוח דוגמאות הממלאות את מחזור החיים מקצה לקצה של FM עד ייצור על ידי ביצוע ההנחיה המתוארת ב FMOps/LLMOps: תפעול AI גנרטיבי והבדלים עם MLOps. זה כולל הגשה של LLM, ניטור, אחסון של דירוג פלט שיפעיל בסופו של דבר הערכה מחדש אוטומטית וכוונון עדין, ולבסוף, שימוש ב-human-in-the-loop כדי לעבוד על נתונים מסומנים או קטלוג הנחיות.
על המחברים
 ד"ר סוקראטיס קרטקיס הוא ארכיטקט פתרונות מומחה ללימוד מכונה ותפעול ראשי עבור שירותי האינטרנט של אמזון. Sokratis מתמקדת במתן אפשרות ללקוחות ארגוניים לתעש את פתרונות ה-Machine Learning (ML) ואת פתרונות הבינה המלאכותית הגנרטיבית שלהם על ידי ניצול שירותי AWS ועיצוב מודל התפעול שלהם, כלומר יסודות MLOps/FMOps/LLMOps, ומפת דרכים לשינוי הממנף את שיטות הפיתוח הטובות ביותר. הוא השקיע 15+ שנים על המצאה, עיצוב, הובלה והטמעה של פתרונות ML ו-AI חדשניים מקצה לקצה ברמת האנרגיה, הקמעונאות, הבריאות, הפיננסים, ספורט מוטורי וכו'.
ד"ר סוקראטיס קרטקיס הוא ארכיטקט פתרונות מומחה ללימוד מכונה ותפעול ראשי עבור שירותי האינטרנט של אמזון. Sokratis מתמקדת במתן אפשרות ללקוחות ארגוניים לתעש את פתרונות ה-Machine Learning (ML) ואת פתרונות הבינה המלאכותית הגנרטיבית שלהם על ידי ניצול שירותי AWS ועיצוב מודל התפעול שלהם, כלומר יסודות MLOps/FMOps/LLMOps, ומפת דרכים לשינוי הממנף את שיטות הפיתוח הטובות ביותר. הוא השקיע 15+ שנים על המצאה, עיצוב, הובלה והטמעה של פתרונות ML ו-AI חדשניים מקצה לקצה ברמת האנרגיה, הקמעונאות, הבריאות, הפיננסים, ספורט מוטורי וכו'.
 ג'אגדיפ סינג סוני הוא אדריכל פתרונות שותפים בכיר ב-AWS המבוסס בהולנד. הוא משתמש בתשוקה שלו ל-DevOps, GenAI וכלי Builder כדי לעזור גם למשלבי מערכות וגם לשותפים טכנולוגיים. Jagdeep מיישם את הרקע של פיתוח האפליקציות והארכיטקטורה שלו כדי להניע חדשנות בתוך הצוות שלו ולקדם טכנולוגיות חדשות.
ג'אגדיפ סינג סוני הוא אדריכל פתרונות שותפים בכיר ב-AWS המבוסס בהולנד. הוא משתמש בתשוקה שלו ל-DevOps, GenAI וכלי Builder כדי לעזור גם למשלבי מערכות וגם לשותפים טכנולוגיים. Jagdeep מיישם את הרקע של פיתוח האפליקציות והארכיטקטורה שלו כדי להניע חדשנות בתוך הצוות שלו ולקדם טכנולוגיות חדשות.
 ד"ר ריקרדו גאטי הוא ארכיטקט פתרונות סטארט-אפ בכיר שבסיסו באיטליה. הוא יועץ טכני ללקוחות, שעוזר להם להצמיח את העסק שלהם על ידי בחירת הכלים והטכנולוגיות הנכונות לחדש, להרחיב במהירות ולהפוך גלובלי תוך דקות. הוא תמיד היה נלהב ללמידת מכונה ובינה מלאכותית מחוללת, לאחר שלמד ויישם את הטכנולוגיות הללו בתחומים שונים לאורך קריירת העבודה שלו. הוא מנחה ועורך של הפודקאסט האיטלקי של AWS "Casa Startup", המוקדש לסיפורים של מייסדי סטארטאפים ומגמות טכנולוגיות חדשות.
ד"ר ריקרדו גאטי הוא ארכיטקט פתרונות סטארט-אפ בכיר שבסיסו באיטליה. הוא יועץ טכני ללקוחות, שעוזר להם להצמיח את העסק שלהם על ידי בחירת הכלים והטכנולוגיות הנכונות לחדש, להרחיב במהירות ולהפוך גלובלי תוך דקות. הוא תמיד היה נלהב ללמידת מכונה ובינה מלאכותית מחוללת, לאחר שלמד ויישם את הטכנולוגיות הללו בתחומים שונים לאורך קריירת העבודה שלו. הוא מנחה ועורך של הפודקאסט האיטלקי של AWS "Casa Startup", המוקדש לסיפורים של מייסדי סטארטאפים ומגמות טכנולוגיות חדשות.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/operationalize-llm-evaluation-at-scale-using-amazon-sagemaker-clarify-and-mlops-services/
- :יש ל
- :הוא
- :לֹא
- :איפה
- $ למעלה
- 1
- 100
- 9
- a
- אודות
- להאיץ
- גישה
- דיוק
- במדויק
- להשיג
- השגתי
- לרוחב
- לפעול
- הפעלה
- פעיל
- מחזורי
- הוסיף
- תוספת
- בנוסף
- כתובת
- כראוי
- מנהל
- אימוץ
- אימוץ
- התקדמות
- יועץ
- לאחר
- נגד
- סוכנים
- AI
- חוק AI
- מערכות AI
- המטרה
- מכוון
- אַלגוֹרִיתְם
- אלגוריתמים
- מיישר
- חי
- תעשיות
- מאפשר
- כְּבָר
- גם
- תמיד
- אמזון בעברית
- אמזון SageMaker
- אמזון SageMaker JumpStart
- צינורות SageMaker של אמזון
- סטודיו SageMaker של אמזון
- אמזון שירותי אינטרנט
- an
- לנתח
- ו
- אחר
- לענות
- כל
- API
- בקשה
- פיתוח אפליקציות
- יישומים
- יישומית
- חל
- גישה
- מתאים
- ארכיטקטורה
- ARE
- אזורים
- טענה
- AS
- לְהַעֲרִיך
- הערכה
- הערכה
- הערכות
- At
- ביקורת
- אוטומטי
- אוטומטי
- מכני עם סלילה אוטומטית
- באופן אוטומטי
- אוטומציה
- זמין
- AWS
- b
- רקע
- מבוסס
- בסיסי
- BE
- כי
- להיות
- היה
- התנהגות
- בנצ 'מרק
- מדוד
- מבחני ביצועים
- הטבות
- הטוב ביותר
- מוטב
- בֵּין
- מעבר
- הטיה
- מְשׁוּחָד
- הטיות
- אבני
- שניהם
- פרות
- רוחב
- להביא
- לִבנוֹת
- בונה
- עסקים
- אבל
- by
- נקרא
- שיחות
- CAN
- מועמד
- יכולות
- מסוגל
- ללכוד
- כרטיסים
- קריירה
- מקרה
- מקרים
- קטלוג
- מסוים
- לאתגר
- מאפיינים
- זול יותר
- לבדוק
- בחרו
- נבחר
- מיון
- לסווג
- לְנַקוֹת
- קוד
- מגובש
- לשתף פעולה
- שילוב
- שילוב
- Common
- קהילה
- השוואה
- לְהַשְׁווֹת
- לעומת
- השוואה
- השלמה
- השלמה
- מורכב
- מורכבות
- הענות
- להיענות
- רְכִיב
- רכיבים
- מכיל
- חישובית
- לחשב
- מושג
- דְאָגָה
- לנהל
- מוליך
- מנצח
- תְצוּרָה
- לְחַבֵּר
- מתחבר
- נחשב
- מורכב
- לבנות
- צרכנים
- מכולה
- מכיל
- תוכן
- הקשר
- תמיד
- רציף
- לעומת זאת
- שיחה
- שיחות
- להמיר
- לתקן
- עלות
- חיסכון עלויות
- יקר
- עלויות
- לכסות
- לִיצוֹר
- נוצר
- יוצרים
- יצירה
- הקריטריונים
- קריטי
- מכריע
- מנהג
- לקוחות
- DAG
- נתונים
- הכנת נתונים
- מדען נתונים
- אבטחת מידע
- מערך נתונים
- שיבוש נתונים
- מערכי נתונים
- datetime
- להחליט
- קבלת החלטות
- החלטות
- מוקדש
- עמוק
- צלילה לעומק
- בְּרִירַת מֶחדָל
- לְהַגדִיר
- הגדרות
- מספק
- דרישה
- תלות
- תלוי
- לפרוס
- פרס
- פריסה
- פריסה
- עומק
- מְתוּאָר
- יעוד
- מעוצב
- תכנון
- עיצובים
- רצון עז
- רצוי
- מְפוֹרָט
- פרטים
- לפתח
- מפותח
- מתפתח
- צעצועי התפתחות
- דופים
- ההבדלים
- אחר
- ישיר
- מְכוּוָן
- צלילה
- שונה
- do
- לא
- תחום
- תחומים
- נהיגה
- בְּמַהֲלָך
- באופן דינמי
- e
- כל אחד
- בקלות
- קל
- עורך
- אפקטיבי
- יְעִילוּת
- יעיל
- יעילות
- מאמץ
- או
- אלמנטים
- אחר
- מוּעֳסָק
- לאפשר
- מאפשר
- מה שמאפשר
- מקצה לקצה
- נקודת קצה
- נקודות קצה
- אנרגיה
- מהנדסים
- להגביר את
- לְהַבטִיחַ
- מבטיח
- הבטחתי
- מִפְעָל
- לקוחות ארגוניים
- חברות
- תקופה
- באותה מידה
- במיוחד
- חיוני
- וכו '
- Ether (ETH)
- EU
- להעריך
- העריך
- הערכה
- הערכה
- אֲפִילוּ
- בסופו של דבר
- דוגמה
- דוגמאות
- מנהלים
- קיימים
- הציפיות
- צפוי
- לְזַרֵז
- להאריך
- מוּרחָב
- חיצוני
- הוֹצָאָה
- f1
- פָּנִים
- הקלה
- גורמים
- עובד
- הגינות
- פולס
- שקר
- מפורסם
- מהר
- מהר יותר
- מאפיין
- משתתפים
- מָשׁוֹב
- מעטים
- שדה
- תרשים
- דמויות
- שלח
- סופי
- בסופו של דבר
- לממן
- כספי
- מגזר פיננסי
- ראשון
- גמישות
- להתמקד
- מרוכז
- מתמקד
- בעקבות
- הבא
- כדלקמן
- בעד
- טופס
- קרן
- יסודות
- המייסדים
- מסגרת
- מסגרות
- בתדירות גבוהה
- החל מ-
- להגשמה
- מלא
- פונקציות
- פונקציונלי
- יסודי
- יתר על כן
- עתיד
- איסוף
- כללי
- מטרה כללית
- ליצור
- נוצר
- מייצר
- יצירת
- דור
- גנרטטיבית
- AI Generative
- לקבל
- נתן
- גלוֹבָּלִי
- Go
- להעניק
- גרף
- קְבוּצָה
- קבוצה
- גדל
- יד
- מזיק
- רתימה
- יש
- יש
- he
- בְּרִיאוּת
- בִּכְבֵדוּת
- לעזור
- עזרה
- עוזר
- גָבוֹהַ
- סיכון גבוה
- צירי
- שֶׁלוֹ
- מחזיק
- המארח
- איך
- איך
- אולם
- HTML
- HTTPS
- בן אנוש
- i
- IAM
- מזוהה
- מזהה
- לזהות
- if
- מדגים
- תמונות
- ליישם
- יישום
- מיישמים
- לייבא
- חשיבות
- השבחה
- שיפורים
- in
- לכלול
- כולל
- כולל
- התאגדה
- שילוב
- אינדיקטורים
- תעשיות
- מידע
- הודעה
- תשתית
- בתחילה
- לחדש
- חדשנות
- חדשני
- קלט
- תשומות
- לשלב
- השתלבות
- בכוונה
- יחסי גומלין
- פנימי
- אל תוך
- מבוא
- הופעל
- לערב
- מעורב
- כרוך
- מעורב
- ISO
- IT
- איטלקי
- איטליה
- פריטים
- איטרציה
- שֶׁלָה
- עבודה
- מסע
- jpg
- שמור
- שמר
- מפתח
- ידע
- שפה
- גָדוֹל
- גדול יותר
- אחרון
- לבסוף
- חֶבִיוֹן
- עוֹפֶרֶת
- צור קשר
- מוביל
- למידה
- עזבו
- לתת
- מינוף
- סִפְרִיָה
- מעגל החיים
- כמו
- מוגבל
- קשר
- לאמה
- מיקום
- הגיון
- נמוך
- מכונה
- למידת מכונה
- ראשי
- לתחזק
- שומר
- הצליח
- מניפולציה
- מניפולציות
- מדריך ל
- רב
- מאי..
- בינתיים
- למדוד
- אמצעים
- מנגנוני
- מידע נוסף
- שיטה
- שיטות
- מטרי
- מדדים
- לצמצם
- דקות
- מידע שגוי
- להקל
- מקלה
- ML
- MLOps
- מודל
- מודלים
- מודול
- צג
- ניטור
- יותר
- רוב
- מוטיבציה
- Motorsports
- הרבה
- מספר
- צריך
- שם
- הכרחי
- צורך
- צרכי
- הולנד
- חדש
- טכנולוגיות חדשות
- הבא
- לא מומחים
- הערות
- מחברה
- מחשבים ניידים
- ניואנסים
- מספר
- of
- הַצָעָה
- לעתים קרובות
- on
- פעם
- ONE
- מתמשך
- רק
- קוד פתוח
- פועל
- מבצע
- תפעול
- דעות
- אופטימיזציה
- or
- OS
- אחר
- שלנו
- הַחוּצָה
- תוֹצָאָה
- תוצאות
- תפוקה
- פלטים
- בולט
- יותר
- מקיף
- שֶׁלוֹ
- בעלי
- מקביל
- פרמטרים
- מסוים
- במיוחד
- שותף
- שותפים
- תשוקה
- לוהט
- נתיב
- דפוסי
- אֲנָשִׁים
- לבצע
- ביצועים
- הופעות
- מבצע
- שלב
- pii
- צינור
- מקום
- מציין מיקום
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- PoC
- פודקאסט
- נקודה
- בריכה
- ברכות
- הודעה
- לאחר עיבוד
- פוטנציאל
- כּוֹחַ
- מופעל
- פרקטיקות
- דיוק
- הכנה
- העריכה
- נוכחות
- למנוע
- קודם
- יְסוֹדִי
- מנהל
- עקרונות
- פְּרָטִיוּת
- פְּרָטִי
- בעיה
- הליך
- תהליך
- תהליכים
- תהליך
- הפקה
- התקדמות
- בולטות
- הבטחה
- לקדם
- הנחיות
- הוכחה
- הוכחה של רעיון או תאוריה
- התפשטות
- נכסים
- קניינית
- להגן
- להוכיח
- לספק
- ספקים
- מספק
- מתן
- ציבורי
- בפומבי
- מטרה
- פיתון
- אֵיכוּתִי
- איכות
- כמותי
- שאלה
- רכס
- ציון
- דירוג
- ממשי
- עולם אמיתי
- זמן אמת
- להפחית
- מופחת
- הפחתה
- להתייחס
- הפניה
- רשום
- הַרשָׁמָה
- רישום
- נסיגה
- רגיל
- מוסדר
- תעשיות מוסדרות
- תקנון
- למידה חיזוק
- קָשׁוּר
- הרלוונטיות
- רלוונטי
- אמינות
- חוזר על עצמו
- לדווח
- דווח
- דוחות לדוגמא
- מאגר
- נציג
- נדרש
- דורש
- מחקר
- חוקרים
- עתירת משאבים
- משאבים
- אחריות
- אחראי
- וכתוצאה מכך
- תוצאות
- קמעוני
- לִשְׁמוֹר
- לַחֲזוֹר
- שימוש חוזר
- סקירה
- מהפכה
- תקין
- קַפְּדָנִי
- רייזן
- הסיכון
- סיכונים
- מפת דרכים
- חָסוֹן
- איתנות
- תפקיד
- תפקידים
- הפעלה
- ריצה
- פועל
- s
- בטוח
- אמצעי הגנה
- בעל חכמים
- צינורות SageMaker
- חיסכון
- בקרת מערכות ותקשורת
- להרחבה
- סולם
- תרחיש
- תרחישים
- מַדְעָן
- מדענים
- היקף
- ציון
- תסריט
- Sdk
- בצורה חלקה
- סעיפים
- מגזר
- לבטח
- אבטחה
- סיכוני אבטחה
- בחר
- נבחר
- בחירה
- מבחר
- לחצני מצוקה לפנסיונרים
- רגש
- לשרת
- שרות
- שירותים
- הגשה
- מושב
- סט
- מעצבים
- שיתוף
- לְהַצִיג
- הראה
- הופעות
- צד
- משמעותי
- דומה
- מפשט
- בפשטות
- since
- יחיד
- קטן
- פִּתָרוֹן
- פתרונות
- לפתור
- כמה
- מָקוֹר
- משך
- מומחה
- ספציפי
- במיוחד
- בילה
- בימוי
- בעלי עניין
- תקינה
- תקנים
- סטנפורד
- החל
- התחלות
- סטארט - אפ
- מצב
- שלב
- צעדים
- עוד
- אחסון
- חנות
- סיפורים
- פשוט
- מובנה
- מְחוֹשָׁב
- סטודיו
- סגנון
- כתוצאה מכך
- כזה
- סיכום
- תמיכה
- מערכת
- מערכות
- תפירה
- המשימות
- משימות
- נבחרת
- צוותי
- טכני
- טכניקות
- טכנולוגי
- טכנולוגיות
- טכנולוגיה
- תבניות
- מבחן
- בודקי
- בדיקות
- בדיקות
- טֶקסט
- מֵאֲשֶׁר
- זֶה
- השמיים
- העתיד
- שֶׁלָהֶם
- אותם
- אז
- תיאורטי
- בכך
- לכן
- אלה
- הֵם
- זֶה
- אלה
- שְׁלוֹשָׁה
- דרך
- בכל
- זמן
- ל
- יַחַד
- כלי
- כלים
- לעקוב
- רכבת
- מְאוּמָן
- הדרכה
- רכבות
- טרנספורמציה
- מַעֲבָר
- המעבר
- תרגום
- מגמות
- להפעיל
- נָכוֹן
- אמין
- שתיים
- סוגים
- טיפוסי
- בסופו של דבר
- לא מורשה
- להבין
- הבנה
- חסר תקדים
- בקרוב ב
- להשתמש
- במקרה להשתמש
- מְשׁוּמָשׁ
- משתמש
- משתמשים
- שימושים
- באמצעות
- בְּדֶרֶך כְּלַל
- לנצל
- לְאַמֵת
- בעל ערך
- שונים
- גרסה
- באמצעות
- חיוני
- פגיעויות
- רוצה
- חם
- we
- אינטרנט
- שירותי אינטרנט
- טוֹב
- היו
- מה
- מתי
- אשר
- בזמן
- מי
- רָחָב
- טווח רחב
- ויקיפדיה
- יצטרך
- עם
- בתוך
- לְלֹא
- תיק עבודות
- זרימת עבודה
- עובד
- עוֹלָם
- יאמל
- שנים
- תְשׁוּאָה
- אתה
- זפירנט