By דיוויד וונדט ו גרגורי קימבל
עיבוד יעיל של נתוני מחרוזת חיוני עבור יישומים רבים של מדעי הנתונים. כדי לחלץ מידע בעל ערך מנתוני מחרוזת, RAPIDS libcudf מספק כלים רבי עוצמה להאצת טרנספורמציות של נתוני מחרוזות. libcudf היא ספריית C++ GPU DataFrame המשמשת לטעינה, הצטרפות, צבירה וסינון נתונים.
במדעי הנתונים, נתוני מחרוזת מייצגים דיבור, טקסט, רצפים גנטיים, רישום וסוגים רבים אחרים של מידע. כאשר עובדים עם נתוני מחרוזת עבור למידת מכונה והנדסת תכונות, יש לנרמל ולשנות את הנתונים לעתים קרובות לפני שניתן יהיה ליישם אותם על מקרי שימוש ספציפיים. libcudf מספק גם ממשקי API למטרות כלליות וגם כלי עזר בצד המכשיר כדי לאפשר מגוון רחב של פעולות מחרוזות מותאמות אישית.
פוסט זה מדגים כיצד להפוך במיומנות עמודות מחרוזות עם ה-API למטרות כלליות של libcudf. תקבל ידע חדש כיצד לפתוח ביצועים שיא באמצעות גרעינים מותאמים אישית וכלי עזר בצד המכשיר libcudf. פוסט זה גם מנחה אותך בדוגמאות כיצד לנהל בצורה הטובה ביותר זיכרון GPU ולבנות ביעילות עמודות libcudf כדי להאיץ את טרנספורמציות המחרוזות שלך.
libcudf מאחסן נתוני מחרוזת בזיכרון המכשיר באמצעות פורמט חץ, המייצג עמודות מחרוזות כשתי עמודות צאצא: chars and offsets (איור 1).
השמיים chars העמודה מכילה את נתוני המחרוזת בתור בתים מקודדים של UTF-8 המאוחסנים ברציפות בזיכרון.
השמיים offsets העמודה מכילה רצף הולך וגדל של מספרים שלמים שהם מיקומי בתים המזהים את ההתחלה של כל מחרוזת בודדת בתוך מערך הנתונים של התווים. אלמנט ההיסט הסופי הוא המספר הכולל של בתים בעמודת התווים. המשמעות היא גודל של מחרוזת בודדת בשורה i זה מוגדר כ (offsets[i+1]-offsets[i]).
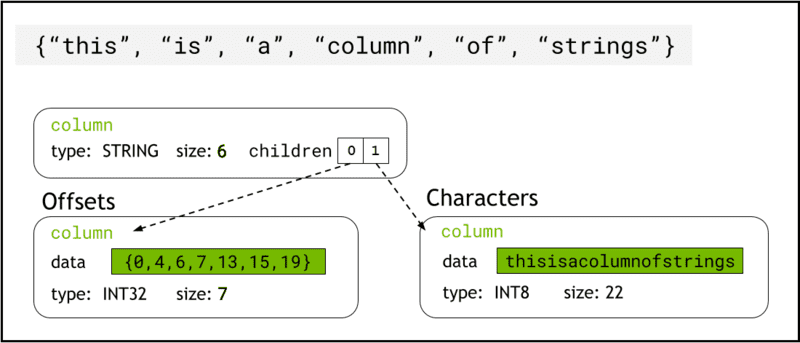 איור 1. סכמטי המראה כיצד פורמט החץ מייצג עמודות מחרוזות עם
איור 1. סכמטי המראה כיצד פורמט החץ מייצג עמודות מחרוזות עם chars ו offsets עמודות ילד
כדי להמחיש טרנספורמציה של מחרוזת לדוגמה, שקול פונקציה שמקבלת שתי עמודות מחרוזות קלט ומייצרת עמודת מחרוזות פלט אחת.
לנתוני הקלט יש את הצורה הבאה: עמודת "שמות" המכילה שמות פרטיים ושמות משפחה מופרדים ברווח ועמודת "ראות" המכילה את הסטטוס של "ציבורי" או "פרטי".
אנו מציעים את הפונקציה "redact" הפועלת על נתוני הקלט כדי לייצר נתוני פלט המורכבים מהאות הראשון של שם המשפחה ואחריו רווח והשם הפרטי כולו. עם זאת, אם עמודת הנראות המתאימה היא "פרטית", יש לתקן את מחרוזת הפלט במלואה כ-"X X".
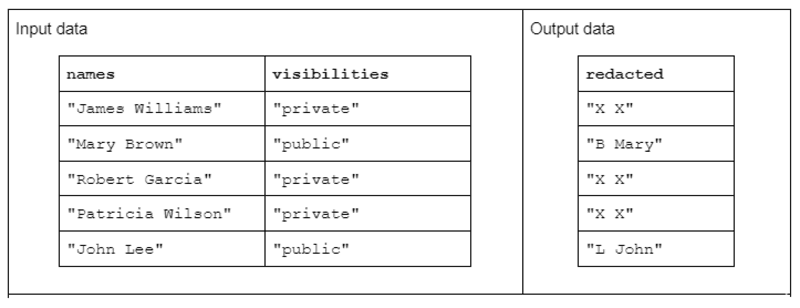 טבלה 1. דוגמה לטרנספורמציה של מחרוזת "עריכת" המקבלת עמודות מחרוזות שמות וראות כקלט ונתונים שנמחקו באופן חלקי או מלא כפלט
טבלה 1. דוגמה לטרנספורמציה של מחרוזת "עריכת" המקבלת עמודות מחרוזות שמות וראות כקלט ונתונים שנמחקו באופן חלקי או מלא כפלט
ראשית, ניתן לבצע טרנספורמציה של מחרוזת באמצעות ה- libcudf strings API. ה-API למטרות כלליות הוא נקודת התחלה מצוינת וקו בסיס טוב להשוואת ביצועים.
פונקציות ה-API פועלות על עמודת מחרוזות שלמה, משיקות לפחות ליבה אחת לכל פונקציה ומקצות חוט אחד לכל מחרוזת. כל שרשור מטפל בשורה אחת של נתונים במקביל על פני ה-GPU ומוציא שורה בודדת כחלק מעמודת פלט חדשה.
כדי להשלים את פונקציית העריכה לדוגמה באמצעות ממשק API למטרות כלליות, בצע את השלבים הבאים:
- המר את עמודת המחרוזות "חזותיות" לעמודה בוליאנית באמצעות
contains - צור עמודת מחרוזות חדשה מעמודת השמות על ידי העתקת "XX" בכל פעם שהכניסה השורה המתאימה בעמודה הבוליאנית היא "false"
- פצל את העמודה "שנוקפת" לעמודות שם פרטי ושם משפחה
- פרוס את התו הראשון של שמות המשפחה בתור ראשי התיבות של שם המשפחה
- בנה את עמודת הפלט על ידי שרשור עמודת ראשי התיבות האחרונה ועמודת השמות הפרטיים עם מפריד רווח (" ").
// convert the visibility label into a boolean
auto const visible = cudf::string_scalar(std::string("public"));
auto const allowed = cudf::strings::contains(visibilities, visible); // redact names auto const redaction = cudf::string_scalar(std::string("X X"));
auto const redacted = cudf::copy_if_else(names, redaction, allowed->view()); // split the first name and last initial into two columns
auto const sv = cudf::strings_column_view(redacted->view())
auto const first_last = cudf::strings::split(sv);
auto const first = first_last->view().column(0);
auto const last = first_last->view().column(1);
auto const last_initial = cudf::strings::slice_strings(last, 0, 1); // assemble a result column
auto const tv = cudf::table_view({last_initial->view(), first});
auto result = cudf::strings::concatenate(tv, std::string(" "));
גישה זו נמשכת כ-3.5 אלפיות השנייה ב-A6000 עם 600K שורות של נתונים. דוגמה זו משתמשת contains, copy_if_else, split, slice_strings ו concatenate כדי לבצע טרנספורמציה של מחרוזת מותאמת אישית. ניתוח פרופילים עם Nsight Systems מראה כי split הפונקציה לוקחת את פרק הזמן הארוך ביותר, ואחריה slice_strings ו concatenate.
איור 2 מציג נתוני פרופילים מ-Nsight Systems של הדוגמה של redact, המציגים עיבוד מחרוזות מקצה לקצה בקצב של עד ~600 מיליון אלמנטים בשנייה. האזורים תואמים לטווחי NVTX המשויכים לכל פונקציה. טווחי כחול בהיר תואמים לתקופות בהן פועלים גרעיני CUDA.
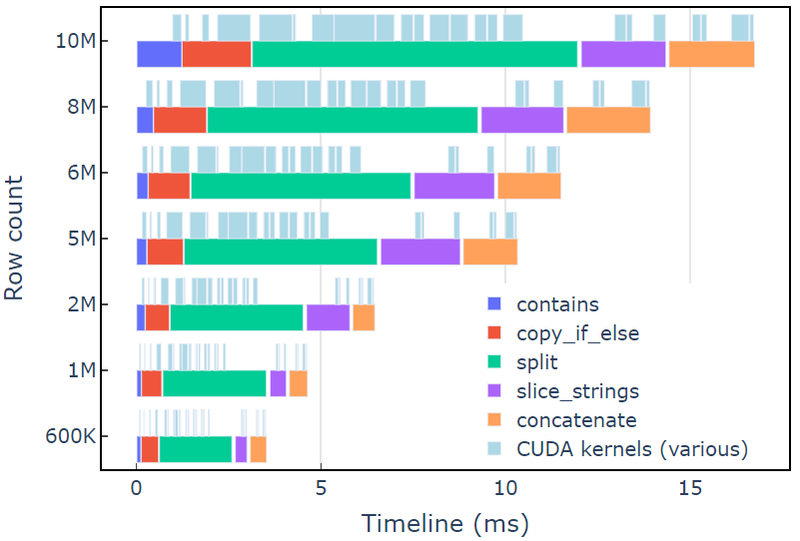 איור 2. נתוני פרופילים מ-Nsight Systems של דוגמה לעיבוד
איור 2. נתוני פרופילים מ-Nsight Systems של דוגמה לעיבוד
libcudf strings API הוא ערכת כלים מהירה ויעילה לשינוי מחרוזות, אך לפעמים פונקציות קריטיות לביצועים צריכות לפעול אפילו מהר יותר. מקור מפתח לעבודה נוספת ב-libcudf strings API הוא יצירת עמודת מחרוזות חדשה אחת לפחות בזיכרון ההתקן הגלובלי עבור כל קריאת API, מה שפותח את ההזדמנות לשלב קריאות API מרובות לגרעין מותאם אישית.
מגבלות ביצועים בקריאות malloc של ליבה
ראשית, נבנה ליבה מותאמת אישית כדי ליישם את שינוי הדוגמה של redact. בעת תכנון ליבה זו, עלינו לזכור שעמודות מחרוזות libcudf אינן ניתנות לשינוי.
לא ניתן לשנות את עמודות המחרוזות במקום מכיוון שבתי התווים מאוחסנים ברציפות, וכל שינוי באורך של מחרוזת יבטל את תוקף נתוני ההיסט. לכן ה redact_kernel קרנל מותאם אישית יוצר עמודת מחרוזות חדשה על ידי שימוש במפעל עמודות libcudf לבניית שניהם offsets ו chars עמודות ילד.
בגישה הראשונה הזו, מחרוזת הפלט עבור כל שורה נוצרת ב זיכרון מכשיר דינמי באמצעות קריאת malloc בתוך הקרנל. פלט הליבה המותאם אישית הוא וקטור של מצביעי התקן לכל פלט שורה, וקטור זה משמש כקלט למפעל עמודות מחרוזות.
הקרנל המותאם אישית מקבל א cudf::column_device_view כדי לגשת לנתוני עמודת המחרוזות ומשתמש ב- element שיטה להחזרת א cudf::string_view מייצג את נתוני המחרוזת באינדקס השורה שצוין. פלט הליבה הוא וקטור מסוג cudf::string_view שמחזיק מצביעים לזיכרון ההתקן המכיל את מחרוזת הפלט ואת גודל המחרוזת בבתים.
השמיים cudf::string_view המחלקה דומה למחלקה std::string_view אך מיושמת במיוחד עבור libcudf ועוטפת אורך קבוע של נתוני תווים בזיכרון המכשיר המקודד כ-UTF-8. יש לו הרבה מאותן תכונות (find ו substr פונקציות, למשל) ומגבלות (ללא terminator null) כ- std עָמִית. א cudf::string_view מייצג רצף תווים המאוחסן בזיכרון המכשיר ולכן נוכל להשתמש בו כאן כדי להקליט את הזיכרון malloc'd עבור וקטור פלט.
גרעין מאלוק
// note the column_device_view inputs to the kernel __global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, cudf::string_view* d_output)
{ // get index for this thread auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; char* output_ptr = static_cast(malloc(output_size)); // build output string d_output[index] = cudf::string_view{output_ptr, output_size}; memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
} __global__ void free_kernel(cudf::string_view redaction, cudf::string_view* d_output, int count)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= count) return; auto ptr = const_cast(d_output[index].data()); if (ptr != redaction.data()) free(ptr); // free everything that does match the redaction string
}
זו עשויה להיראות כמו גישה סבירה, עד שביצועי הליבה יימדדו. גישה זו נמשכת כ-108 אלפיות השנייה ב-A6000 עם 600K שורות של נתונים - יותר מפי 30 יותר איטי מהפתרון שסופק לעיל באמצעות ה-API של libcudf strings.
redact_kernel 60.3ms
free_kernel 45.5ms
make_strings_column 0.5ms
צוואר הבקבוק העיקרי הוא malloc/free שיחות בתוך שני הגרעינים כאן. זיכרון המכשיר הדינמי של CUDA דורש malloc/free קורא לגרעין לסנכרון, מה שגורם לביצוע מקביל להידרדר לביצוע רציף.
הקצאת זיכרון עבודה מראש לביטול צווארי בקבוק
לחסל את malloc/free צוואר בקבוק על ידי החלפת malloc/free קורא לליבה עם זיכרון עבודה שהוקצה מראש לפני הפעלת הליבה.
עבור הדוגמה של redact, גודל הפלט של כל מחרוזת בדוגמה זו לא צריך להיות גדול יותר ממחרוזת הקלט עצמה, מכיוון שהלוגיקה רק מסירה תווים. לכן, ניתן להשתמש במאגר זיכרון של התקן בודד באותו גודל כמו מאגר הקלט. השתמש בקיזוז הקלט כדי לאתר כל מיקום שורה.
גישה לקיזוזים של עמודת המיתרים כרוכה לעטוף את cudf::column_view עם cudf::strings_column_view וקורא לזה offsets_begin שיטה. הגודל של chars ניתן לגשת לעמודת הילד גם באמצעות chars_size שיטה. ואז א rmm::device_uvector מוקצה מראש לפני קריאת הליבה לאחסון נתוני פלט התווים.
auto const scv = cudf::strings_column_view(names);
auto const offsets = scv.offsets_begin();
auto working_memory = rmm::device_uvector(scv.chars_size(), stream);גרעין שהוקצה מראש
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, char* working_memory, cudf::offset_type const* d_offsets, cudf::string_view* d_output)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // resolve output string location char* output_ptr = working_memory + d_offsets[index]; d_output[index] = cudf::string_view{output_ptr, output_size}; // build output string into output_ptr memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
}
הקרנל מוציא וקטור של cudf::string_view חפצים אשר מועברים ל cudf::make_strings_column פונקציית המפעל. הפרמטר השני לפונקציה זו משמש לזיהוי ערכי null בעמודת הפלט. לדוגמאות בפוסט זה אין ערכים null, אז מציין מיקום nullptr cudf::string_view{nullptr,0} משמש.
auto str_ptrs = rmm::device_uvector(names.size(), stream); redact_kernel>>(*d_names, *d_visibilities, d_redaction.value(), working_memory.data(), offsets, str_ptrs.data()); auto result = cudf::make_strings_column(str_ptrs, cudf::string_view{nullptr,0}, stream);
גישה זו נמשכת כ-1.1 אלפיות השנייה ב-A6000 עם 600K שורות של נתונים ולכן מנצחת את קו הבסיס ביותר מפי 2. הפירוט המשוער מוצג להלן:
redact_kernel 66us make_strings_column 400us
את הזמן הנותר מבלים ב cudaMalloc, cudaFree, cudaMemcpy, מה שאופייני לתקורה לניהול מקרים זמניים של rmm::device_uvector. שיטה זו פועלת היטב אם מובטח שכל מחרוזות הפלט יהיו באותו גודל או קטנות יותר כמו מחרוזות הקלט.
בסך הכל, מעבר להקצאת זיכרון עבודה בכמות גדולה עם RAPIDS RMM הוא שיפור משמעותי ופתרון טוב לפונקציית מחרוזות מותאמות אישית.
אופטימיזציה של יצירת עמודות לזמני חישוב מהירים יותר
האם יש דרך לשפר את זה עוד יותר? צוואר הבקבוק הוא כעת cudf::make_strings_column פונקציית המפעל שבונה את שני מרכיבי עמודת המיתרים, offsets ו chars, מהווקטור של cudf::string_view חפצים.
ב-libcudf, פונקציות מפעל רבות כלולות לבניית עמודות מחרוזות. פונקציית היצרן שבה נעשה שימוש בדוגמאות הקודמות לוקחת א cudf::device_span of cudf::string_view אובייקט ולאחר מכן בונה את העמודה על ידי ביצוע א gather על נתוני התווים הבסיסיים כדי לבנות את ההסטות ועמודות הצאצא של התווים. א rmm::device_uvector ניתן להמרה אוטומטית ל-a cudf::device_span מבלי להעתיק נתונים.
עם זאת, אם וקטור התווים ווקטור ההיסטים בנויים ישירות, ניתן להשתמש בפונקציית יצרן אחרת, שפשוט יוצרת את עמודת המחרוזות מבלי לדרוש איסוף כדי להעתיק את הנתונים.
השמיים sizes_kernel מבצע מעבר ראשון על נתוני הקלט כדי לחשב את גודל הפלט המדויק של כל שורת פלט:
ליבה מותאמת: חלק 1
__global__ void sizes_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type* d_sizes)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); cudf::size_type result = redaction.size_bytes(); // init to redaction size if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); result = first.size_bytes() + last_initial.size_bytes() + 1; } d_sizes[index] = result;
}
גדלי הפלט מומרים לאחר מכן לקיזוזים על ידי ביצוע במקום exclusive_scan. שים לב כי offsets וקטור נוצר עם names.size()+1 אלמנטים. הערך האחרון יהיה המספר הכולל של בתים (כל הגדלים מתווספים יחד) ואילו הערך הראשון יהיה 0. שניהם מטופלים על ידי exclusive_scan שִׂיחָה. הגודל של chars העמודה מאוחזרת מהערך האחרון של offsets עמודה לבניית וקטור התווים.
// create offsets vector
auto offsets = rmm::device_uvector(names.size() + 1, stream); // compute output sizes
sizes_kernel>>( *d_names, *d_visibilities, offsets.data()); thrust::exclusive_scan(rmm::exec_policy(stream), offsets.begin(), offsets.end(), offsets.begin());
השמיים redact_kernel ההיגיון עדיין מאוד זהה חוץ מזה שהוא מקבל את הפלט d_offsets וקטור כדי לקבוע את מיקום הפלט של כל שורה:
ליבה מותאמת: חלק 2
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type const* d_offsets, char* d_chars)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); // resolve output_ptr using the offsets vector char* output_ptr = d_chars + d_offsets[index]; auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // build output string memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { memcpy(output_ptr, redaction.data(), redaction.size_bytes()); }
}
גודל הפלט d_chars העמודה מאוחזרת מהערך האחרון של d_offsets עמודה כדי להקצות את וקטור התווים. הליבה מופעלת עם וקטור ההיסטים המחושבים מראש ומחזירה את וקטור התווים המאוכלס. לבסוף, מפעל עמודות המחרוזות של libcudf יוצר את עמודות מחרוזות הפלט.
זֶה cudf::make_strings_column פונקציית factory בונה את עמודת המחרוזות מבלי ליצור עותק של הנתונים. ה offsets נתונים ו chars הנתונים כבר בפורמט הנכון והמצופה והמפעל הזה פשוט מעביר את הנתונים מכל וקטור ויוצר את מבנה העמודות סביבו. לאחר השלמתו, ה rmm::device_uvectors ל offsets ו chars ריקים, הנתונים שלהם הועברו לעמודת הפלט.
cudf::size_type output_size = offsets.back_element(stream);
auto chars = rmm::device_uvector(output_size, stream); redact_kernel>>( *d_names, *d_visibilities, offsets.data(), chars.data()); // from pre-assembled offsets and character buffers
auto result = cudf::make_strings_column(names.size(), std::move(offsets), std::move(chars));
גישה זו לוקחת בערך 300 לנו (0.3 אלפיות השנייה) ב-A6000 עם 600K שורות של נתונים ומשתפרת בהשוואה לגישה הקודמת ביותר מפי 2. אולי תשים לב לזה sizes_kernel ו redact_kernel חולקים הרבה מאותו היגיון: פעם אחת כדי למדוד את גודל הפלט ואז שוב כדי לאכלס את הפלט.
מנקודת מבט של איכות קוד, זה מועיל לשחזר את הטרנספורמציה כפונקציית התקן שנקראת הן על ידי הגדלים והן על ידי עיבוד הגרעינים. מנקודת מבט של ביצועים, אתה עשוי להיות מופתע לראות את העלות החישובית של השינוי משולמת פעמיים.
היתרונות לניהול זיכרון ויצירת עמודות יעילה יותר עולים לרוב על עלות החישוב של ביצוע השינוי פעמיים.
טבלה 2 מציגה את זמן החישוב, ספירת הליבה והבתים שעובדו עבור ארבעת הפתרונות שנדונו בפוסט זה. "סה"כ השקות ליבה" משקף את המספר הכולל של ליבות שהושקו, כולל גרעיני מחשוב ועזר. "סה"כ בתים מעובדים" הוא תפוקת הקריאה פלוס הכתיבה המצטברת של DRAM ו"מינימום בתים מעובדים" הוא ממוצע של 37.9 בתים לשורה עבור כניסות ויציאות הבדיקה שלנו. המארז האידיאלי "מוגבל ברוחב פס זיכרון" מניח רוחב פס של 768 GB/s, שיא התפוקה התיאורטי של ה-A6000.
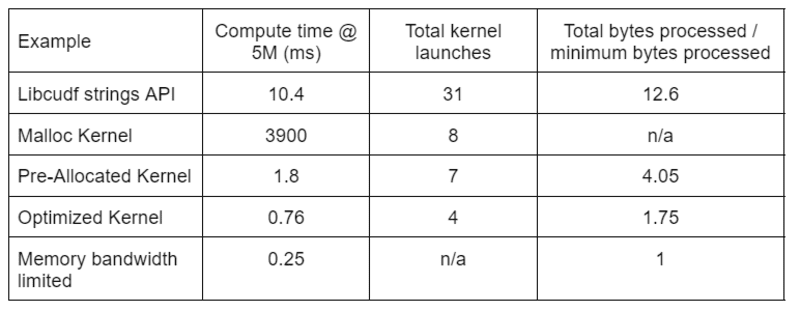 טבלה 2. זמן חישוב, ספירת ליבות ובייטים מעובדים עבור ארבעת הפתרונות שנדונו בפוסט זה
טבלה 2. זמן חישוב, ספירת ליבות ובייטים מעובדים עבור ארבעת הפתרונות שנדונו בפוסט זה
"קרנל אופטימיזציה" מספק את התפוקה הגבוהה ביותר בשל המספר המופחת של השקות הליבה ומספר הפחות בתים שעובדו. עם גרעינים מותאמים אישית יעילים, סך ההשקות של הליבה יורד מ-31 ל-4 וסך הבתים מעובד מ-12.6x ל-1.75x מגודל הקלט פלוס הפלט.
כתוצאה מכך, הליבה המותאמת אישית משיגה תפוקה גבוהה פי 10 מה-API של מחרוזות למטרות כלליות עבור השינוי.
משאב זיכרון הבריכה ב מנהל זיכרון RAPIDS (RMM) הוא כלי נוסף שאתה יכול להשתמש בו כדי להגביר את הביצועים. הדוגמאות לעיל משתמשות ברירת המחדל של "משאב זיכרון CUDA" להקצאה ושחרור זיכרון מכשיר גלובלי. עם זאת, הזמן הדרוש להקצאת זיכרון עבודה מוסיף חביון משמעותי בין השלבים של טרנספורמציות המחרוזות. "משאב זיכרון המאגר" ב-RMM מקטין את זמן ההשהיה על ידי הקצאת מאגר גדול של זיכרון מראש, והקצאת משנה לפי הצורך במהלך העיבוד.
עם משאב הזיכרון CUDA, "קרנל אופטימיזציה" מציג מהירות של 10x-15x שמתחילה לרדת בספירת שורות גבוהות יותר בגלל גודל ההקצאה הגובר (איור 3). השימוש במשאב זיכרון המאגר מפחית את האפקט הזה ושומר על העלאות מהירות של 15x-25x ביחס לגישת ה-API של libcudf strings.
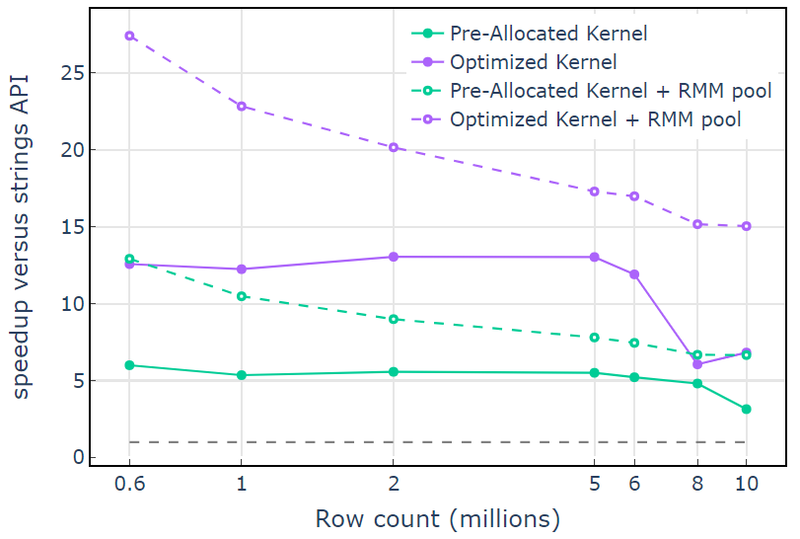 איור 3. הגברת מהירות מהגרעין המותאמים אישית "Pre-Allocated Kernel" ו-"Optimized Kernel" עם משאב זיכרון CUDA ברירת המחדל (מוצק) ומשאב זיכרון המאגר (מקווקו), לעומת libcudf string API באמצעות משאב זיכרון CUDA ברירת המחדל
איור 3. הגברת מהירות מהגרעין המותאמים אישית "Pre-Allocated Kernel" ו-"Optimized Kernel" עם משאב זיכרון CUDA ברירת המחדל (מוצק) ומשאב זיכרון המאגר (מקווקו), לעומת libcudf string API באמצעות משאב זיכרון CUDA ברירת המחדל
עם משאב זיכרון המאגר, מודגם תפוקת זיכרון מקצה לקצה המתקרבת לגבול התיאורטי עבור אלגוריתם שני מעברים. "קרנל אופטימלי" מגיע לתפוקה של 320-340 GB/s, הנמדד באמצעות גודל הכניסות בתוספת גודל היציאות וזמן החישוב (איור 4).
גישת שני המעבר מודדת תחילה את הגדלים של רכיבי הפלט, מקצה זיכרון, ולאחר מכן מגדירה את הזיכרון עם הפלטים. בהינתן אלגוריתם עיבוד שני מעברים, ההטמעה ב-"Optimized Kernel" מבצעת קרוב למגבלת רוחב הפס של הזיכרון. "תפוקת זיכרון מקצה לקצה" מוגדרת כגודל הקלט פלוס הפלט ב-GB חלקי זמן החישוב. *רוחב פס זיכרון RTX A6000 (768 GB/s).
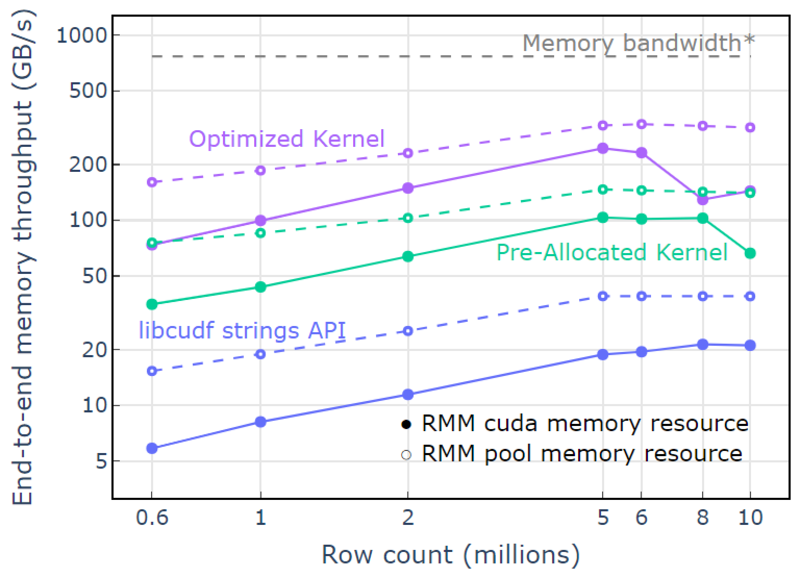 איור 4. תפוקת זיכרון עבור "קרנל אופטימיזציה", "קרנל מוקצה מראש" ו-"libcudf strings API" כפונקציה של ספירת שורות קלט/פלט
איור 4. תפוקת זיכרון עבור "קרנל אופטימיזציה", "קרנל מוקצה מראש" ו-"libcudf strings API" כפונקציה של ספירת שורות קלט/פלט
פוסט זה מדגים שתי גישות לכתיבת טרנספורמציות יעילות של נתוני מחרוזות ב-libcudf. ה-API למטרות כלליות של libcudf הוא מהיר ופשוט עבור מפתחים, ומספק ביצועים טובים. libcudf מספקת גם כלי עזר בצד המכשיר המיועדים לשימוש עם גרעינים מותאמים אישית, בדוגמה זו פותחת ביצועים מהירים יותר של פי 10.
יישם את הידע שלך
כדי להתחיל עם RAPIDS cuDF, בקר באתר rapidsai/cudf ריפו של GitHub. אם עדיין לא ניסית cuDF ו-libcudf עבור עומסי העבודה של עיבוד מחרוזות, אנו ממליצים לך לבדוק את המהדורה האחרונה. מכולות דוקר מסופקים עבור מהדורות כמו גם לבנות לילי. חבילות קונדה זמינים גם כדי להקל על הבדיקות והפריסה. אם אתה כבר משתמש ב-cuDF, אנו ממליצים לך להפעיל את הדוגמה החדשה לשינוי מחרוזות על ידי ביקור rapidsai/cudf/tree/HEAD/cpp/examples/strings ב- GitHub.
דיוויד וונדט הוא מהנדס תוכנת מערכות בכיר ב-NVIDIA המפתח קוד C++/CUDA עבור RAPIDS. דוד הוא בעל תואר שני בהנדסת חשמל מאוניברסיטת ג'ונס הופקינס.
גרגורי קימבל הוא מנהל הנדסת תוכנה ב-NVIDIA שעובד בצוות RAPIDS. גרגורי מוביל את הפיתוח עבור libcudf, ספריית CUDA/C++ לעיבוד נתונים עמודים המניעה את RAPIDS cuDF. גרגורי הוא בעל תואר דוקטור בפיזיקה יישומית מהמכון הטכנולוגי של קליפורניה.
מְקוֹרִי. פורסם מחדש באישור.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://www.kdnuggets.com/2023/01/mastering-string-transformations-rapids-libcudf.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-string-transformations-in-rapids-libcudf
- 1
- 7
- 9
- a
- אודות
- מֵעַל
- מאיצה
- מקבל
- גישה
- נצפה
- מושלם
- לרוחב
- הוסיף
- מוסיף
- אַלגוֹרִיתְם
- תעשיות
- מקצה
- הַקצָאָה
- כְּבָר
- כמות
- אנליזה
- ו
- אחר
- אַפָּשׁ
- API
- ממשקי API
- יישומים
- יישומית
- גישה
- גישות
- מתקרב
- סביב
- מערך
- המשויך
- המכונית
- באופן אוטומטי
- זמין
- מְמוּצָע
- רוחב פס
- Baseline
- כי
- לפני
- להיות
- להלן
- מועיל
- הטבות
- הטוב ביותר
- בֵּין
- כָּחוֹל
- התמוטטות
- חיץ
- לִבנוֹת
- בִּניָן
- בונה
- נבנה
- C + +
- קליפורניה
- שיחה
- נקרא
- קוראים
- שיחות
- לא יכול
- מקרה
- מקרים
- גורם
- שינויים
- אופי
- תווים
- ילד
- בכיתה
- סְגוֹר
- קוד
- טור
- עמודות
- לשלב
- השוואה
- להשלים
- השלמת
- רכיבים
- חישוב
- לחשב
- לשקול
- מורכב
- לבנות
- מכיל
- להמיר
- הומר
- הַעתָקָה
- תוֹאֵם
- עלות
- לִיצוֹר
- נוצר
- יוצר
- יצירה
- מנהג
- נתונים
- עיבוד נתונים
- מדע נתונים
- דוד
- בְּרִירַת מֶחדָל
- תואר
- מספק
- מופגן
- פריסה
- מעוצב
- תכנון
- מפתחים
- מתפתח
- צעצועי התפתחות
- מכשיר
- אחר
- ישירות
- נָדוֹן
- מחולק
- סַוָר
- ירידה
- בְּמַהֲלָך
- דינמי
- כל אחד
- קל יותר
- השפעה
- יעיל
- יעילות
- הנדסת חשמל
- אלמנטים
- בוטל
- לאפשר
- לעודד
- מקצה לקצה
- מהנדס
- הנדסה
- שלם
- כניסה
- Ether (ETH)
- אֲפִילוּ
- הכל
- דוגמה
- דוגמאות
- מצוין
- אלא
- הוצאת להורג
- צפוי
- חיצוני
- נוסף
- תמצית
- מפעל
- מהר
- מהר יותר
- מאפיין
- תכונות
- תרשים
- סינון
- סופי
- בסופו של דבר
- ראשון
- קבוע
- לעקוב
- בעקבות
- הבא
- טופס
- פוּרמָט
- חופשי
- בתדירות גבוהה
- החל מ-
- חזית
- לגמרי
- פונקציה
- פונקציות
- נוסף
- לְהַשִׂיג
- כללי
- מייצר
- לקבל
- GitHub
- נתן
- גלוֹבָּלִי
- טוב
- GPU
- מובטח
- מטפל
- יש
- כאן
- גבוה יותר
- הגבוה ביותר
- מחזיק
- איך
- איך
- אולם
- HTML
- HTTPS
- אידאל
- זיהוי
- בלתי ניתן לשינוי
- ליישם
- הפעלה
- יושם
- לשפר
- השבחה
- משפר
- in
- כלול
- כולל
- להגדיל
- גדל
- מדד
- בנפרד
- מידע
- בתחילה
- קלט
- מכון
- פנימי
- IT
- עצמו
- ג'ונס הופקינס
- אוניברסיטת ג'ונס הופקינס
- הצטרפות
- KDnuggets
- שמור
- מפתח
- ידע
- תווית
- גָדוֹל
- גדול יותר
- אחרון
- חֶבִיוֹן
- האחרון
- המהדורה האחרונה
- הושק
- השקות
- השקה
- מוביל
- למידה
- אורך
- סִפְרִיָה
- אוֹר
- להגביל
- מגבלות
- טוען
- מיקום
- מכונה
- למידת מכונה
- ראשי
- שומר
- לעשות
- עושה
- עשייה
- לנהל
- ניהול
- מנהל
- ניהול
- רב
- אב
- מאסטרינג
- להתאים
- אומר
- למדוד
- אמצעים
- זכרון
- שיטה
- יכול
- מִילִיוֹן
- אכפת לי
- יותר
- יותר יעיל
- מהלכים
- MS
- מספר
- שם
- שמות
- צורך
- נחוץ
- חדש
- מספר
- Nvidia
- אובייקטים
- לקזז
- ONE
- פתיחה
- להפעיל
- פועל
- תפעול
- הזדמנות
- אחר
- נפרע
- מקביל
- פרמטר
- חלק
- עבר
- שִׂיא
- ביצועים
- ביצוע
- מבצע
- תקופות
- רשות
- פרספקטיבה
- פיסיקה
- מקום
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- ועוד
- נקודה
- בריכה
- מְאוּכלָס
- עמדה
- עמדות
- הודעה
- חזק
- כוחות
- קודם
- תהליך
- לייצר
- פרופיל
- להציע
- ובלבד
- מספק
- ציבורי
- מטרה
- איכות
- רכס
- מגיע
- חומר עיוני
- סביר
- מקבל
- שיא
- מופחת
- מפחית
- רפקטור
- משקף
- אזורים
- לשחרר
- עיתונות
- נותר
- המייצג
- מייצג
- משאב
- תוצאה
- לַחֲזוֹר
- החזרות
- שׁוּרָה
- הפעלה
- ריצה
- אותו
- מדע
- שְׁנִיָה
- לחצני מצוקה לפנסיונרים
- רצף
- משמש
- סטים
- שיתוף
- צריך
- הראה
- הופעות
- משמעותי
- דומה
- בפשטות
- since
- יחיד
- מידה
- גדל
- קטן יותר
- So
- תוכנה
- מהנדס תוכנה
- הנדסת תוכנה
- מוצק
- פִּתָרוֹן
- פתרונות
- מָקוֹר
- מֶרחָב
- ספציפי
- במיוחד
- מפורט
- נאום
- מְהִירוּת
- בילה
- לפצל
- התחלה
- החל
- החל
- מצב
- צעדים
- עוד
- חנות
- מאוחסן
- חנויות
- פשוט
- זרם
- מִבְנֶה
- הופתע
- מערכות
- לוקח
- נבחרת
- טכנולוגיה
- זמני
- מבחן
- בדיקות
- השמיים
- שֶׁלָהֶם
- תיאורטי
- לכן
- דרך
- תפוקה
- זמן
- ל
- יַחַד
- כלי
- ארגז כלים
- כלים
- סה"כ
- לשנות
- טרנספורמציה
- טרנספורמציות
- טרנספורמציה
- הפיכה
- tv
- סוגים
- טיפוסי
- בְּסִיסִי
- אוניברסיטה
- לפתוח
- נעילה
- us
- להשתמש
- כלי עזר
- בעל ערך
- מידע בעל ערך
- נגד
- ראות
- נראה
- חיוני
- אשר
- בזמן
- רָחָב
- טווח רחב
- יצטרך
- בתוך
- לְלֹא
- תיק עבודות
- עובד
- עובד
- היה
- לכתוב
- כתיבה
- X
- זפירנט










