
תמונה מ-Adobe Firefly
"היינו יותר מדי מאיתנו. הייתה לנו גישה ליותר מדי כסף, יותר מדי ציוד, ולאט לאט השתגענו".
פרנסיס פורד קופולה לא עשה מטאפורה לחברות בינה מלאכותית שמוציאות יותר מדי ומאבדות את דרכן, אבל הוא יכול היה לעשות זאת. אפוקליפסה עכשיו היה אפי אבל גם פרויקט ארוך, קשה ויקר לביצוע, בדומה ל-GPT-4. אני מציע שהפיתוח של LLMs נמשך ליותר מדי כסף ויותר מדי ציוד. וחלק מההייפ של "הרגע המצאנו אינטליגנציה כללית" הוא קצת מטורף. אבל עכשיו הגיע תורן של קהילות קוד פתוח לעשות את מה שהן יודעות הכי טוב: אספקת תוכנות מתחרות בחינם תוך שימוש בהרבה פחות כסף וציוד.
OpenAI השתלטה על מימון של 11 מיליארד דולר וההערכה היא ש-GPT-3.5 עולה 5-6 מיליון דולר לריצת אימון. אנחנו יודעים מעט מאוד על GPT-4 מכיוון ש-OpenAI לא אומר, אבל אני חושב שבטוח להניח שהוא לא קטן מ-GPT-3.5. יש כרגע מחסור ב-GPU ברחבי העולם, ולשם שינוי זה לא בגלל ה-cryptocoin האחרון. סטארט-אפים של בינה מלאכותית גנרטיבית זוכים בסבבים של 100 מיליון דולר+ מסדרה A בהערכות שווי ענקיות, כאשר אין להם בבעלותם אף אחד מה-IP עבור ה-LLM שהם משתמשים בהם כדי להפעיל את המוצר שלהם. עגלת ה-LLM נמצאת בהילוך גבוה והכסף זורם.
זה היה נראה כאילו הקוביה הוכתרה: רק חברות עם כיסים עמוקים כמו Microsoft/OpenAI, אמזון וגוגל יכלו להרשות לעצמן להכשיר מודלים של מאה מיליארד פרמטרים. ההנחה הייתה שדגמים גדולים יותר הם דגמים טובים יותר. משהו לא בסדר ב-GPT-3? פשוט חכו עד שתהיה גרסה גדולה יותר והכל יהיה בסדר! חברות קטנות יותר שרצו להתחרות נאלצו לגייס הרבה יותר הון או להישאר בבניית שילובי סחורות בשוק ChatGPT. האקדמיה, עם תקציבי מחקר מוגבלים עוד יותר, נדחקה לשוליים.
למרבה המזל, חבורה של אנשים חכמים ופרויקטים של קוד פתוח לקחו את זה כאתגר ולא כמגבלה. חוקרים בסטנפורד פרסמו את Alpaca, מודל של 7 מיליארד פרמטרים שביצועיו מתקרבים למודל של 3.5 מיליארד פרמטרים של GPT-175. בהיעדר המשאבים לבנות מערך הדרכה בגודל שבו השתמש OpenAI, הם בחרו בחוכמה לקחת LLM מיומן בקוד פתוח, LLaMA, ולכוונן אותו בסדרה של הנחיות ופלטים של GPT-3.5 במקום זאת. בעיקרו של דבר, המודל למד מה עושה GPT-3.5, מה שמתברר כאסטרטגיה יעילה מאוד לשכפול ההתנהגות שלו.
ל-Alpaca יש רישיון לשימוש לא מסחרי רק הן בקוד והן בנתונים, שכן היא משתמשת במודל ה-LAMA הלא מסחרי בקוד פתוח, ו-OpenAI אוסרת במפורש כל שימוש בממשקי ה-API שלה ליצירת מוצרים מתחרים. זה אכן יוצר את הסיכוי המפתה של כוונון עדין של LLM אחר בקוד פתוח לפי ההנחיות והפלט של Alpaca... יצירת דגם שלישי דמוי GPT-3.5 עם אפשרויות רישוי שונות.
יש כאן שכבה נוספת של אירוניה, בכך שכל ה-LLMs הגדולים הוכשרו על טקסט ותמונות המוגנים בזכויות יוצרים הזמינים באינטרנט והם לא שילמו אגורה לבעלי הזכויות. החברות טוענות לפטור "שימוש הוגן" על פי חוק זכויות היוצרים האמריקאי בטענה שהשימוש הוא "טרנספורמטיבי". עם זאת, כשזה מגיע לתפוקה של המודלים שהם בונים עם נתונים חופשיים, הם ממש לא רוצים שמישהו יעשה להם את אותו הדבר. אני מצפה שזה ישתנה ככל שבעלי הזכויות יתחכמו, ואולי יסתיים בבית המשפט בשלב מסוים.
זוהי נקודה נפרדת ומובחנת מזו שהועלתה על ידי מחברים של קוד פתוח בעל רישיון מגביל, אשר עבור AI יצירתי עבור מוצרי קוד כמו CoPilot, מתנגדים לשימוש בקוד שלהם להדרכה בטענה שלא עוקבים אחר הרישיון. הבעיה של מחברי קוד פתוח בודדים היא שהם צריכים להראות מעמד - העתקה מהותית - ושגרמו להם נזקים. ומכיוון שהמודלים מקשים על קישור קוד פלט לקלט (שורות קוד המקור של המחבר) ואין הפסד כלכלי (זה אמור להיות בחינם), זה הרבה יותר קשה להגיש תיק. זה בניגוד ליוצרים למטרות רווח (למשל, צלמים) שכל המודל העסקי שלהם הוא ברישוי/מכירת יצירותיהם, ושמיוצגים על ידי אגרגטורים כמו Getty Images שיכולים להראות העתקה מהותית.
דבר מעניין נוסף ב-LAMA הוא שזה יצא מ-Meta. זה שוחרר במקור רק לחוקרים ולאחר מכן דלף דרך BitTorrent לעולם. Meta נמצאת בעסק שונה מהותית מ-OpenAI, מיקרוסופט, גוגל ואמזון בכך שהיא לא מנסה למכור לך שירותי ענן או תוכנות, ולכן יש לה תמריצים שונים מאוד. היא עשתה קוד פתוח לעיצובי המחשוב שלה בעבר (OpenCompute) וראתה את הקהילה משתפרת בהם - היא מבינה את הערך של קוד פתוח.
Meta יכול להתברר כאחד התורמים החשובים ביותר ל-AI בקוד פתוח. לא רק שיש לו משאבים עצומים, אלא שהוא מועיל אם יש התפשטות של טכנולוגיית AI יצירתית נהדרת: יהיה לו יותר תוכן להפיק רווחים במדיה החברתית. Meta פרסמה שלושה מודלים אחרים של AI בקוד פתוח: ImageBind (אינדקס נתונים רב מימדי), DINOv2 (ראייה ממוחשבת) ו- Segment Anything. האחרון מזהה אובייקטים ייחודיים בתמונות ומשוחרר תחת רישיון Apache המתירני ביותר.
לבסוף הייתה לנו גם הדלפה לכאורה של מסמך פנימי של גוגל "אין לנו חצץ, וגם לא ל-OpenAI", המציג מבט עמום של מודלים סגורים לעומת החדשנות של קהילות שמייצרות דגמים קטנים וזולים בהרבה עם ביצועים קרובים או טובים יותר. עמיתיהם במקור סגור. אני אומר לכאורה כי אין דרך לאמת את מקור המאמר כפנימי של גוגל. עם זאת, הוא מכיל את הגרף המשכנע הזה:
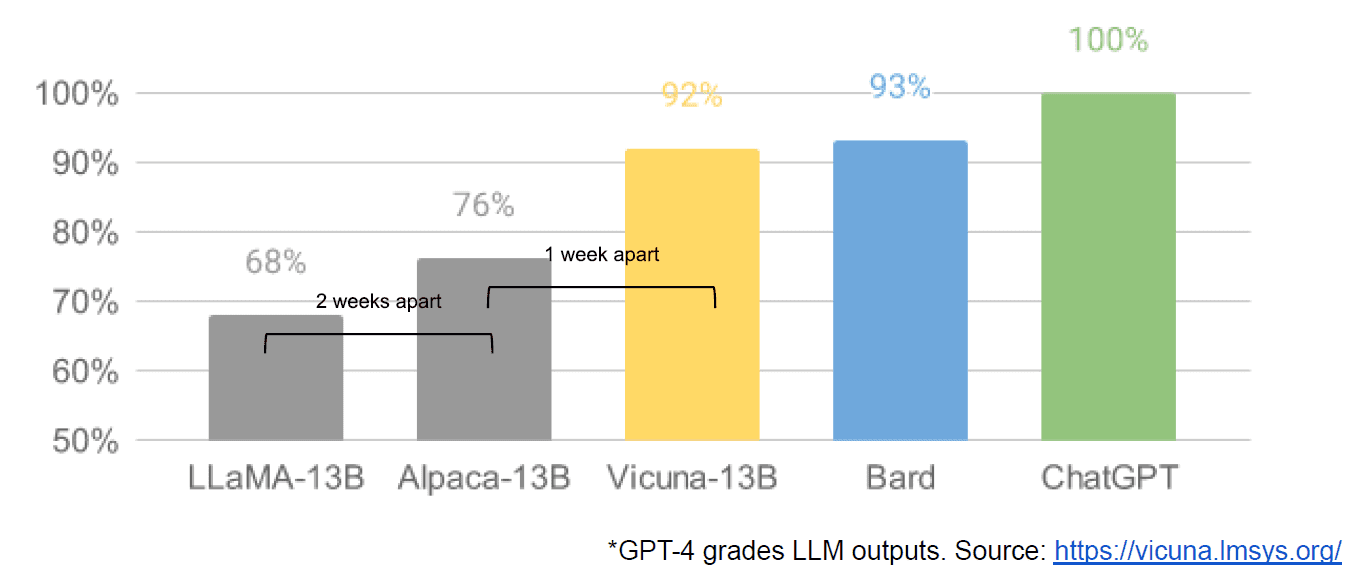
הציר האנכי הוא הדירוג של יציאות ה-LLM על ידי GPT-4, שיהיה ברור.
Stable Diffusion, המסנתז תמונות מטקסט, היא דוגמה נוספת למקום שבו AI מחולל קוד פתוח הצליח להתקדם מהר יותר ממודלים קנייניים. איטרציה עדכנית של הפרויקט הזה (ControlNet) שיפרה אותו כך שהוא עבר את היכולות של Dall-E2. זה נבע מהרבה התעסקות בכל העולם, וכתוצאה מכך קצב התקדמות שקשה לכל מוסד בודד להשתוות אליו. כמה מאותם מתעסקים הבינו איך להפוך את Stable Diffusion למהיר יותר להתאמן ולהפעיל על חומרה זולה יותר, מה שמאפשר מחזורי איטרציה קצרים יותר על ידי יותר אנשים.
וכך הגענו למעגל. היעדר יותר מדי כסף ויותר מדי ציוד העניק השראה לרמה ערמומית של חדשנות על ידי קהילה שלמה של אנשים רגילים. איזה זמן להיות מפתח AI.
מתיאו לודג' הוא מנכ"ל Diffblue, סטארט-אפ AI For Code. יש לו ניסיון מגוון של 25+ שנים בהובלת מוצר בחברות כמו Anaconda ו-VMware. לודג' מכהן כיום במועצת המנהלים של פרויקט חוק טוב וסגן יו"ר מועצת הנאמנים של האגודה המלכותית לצילום.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoAiStream. Web3 Data Intelligence. הידע מוגבר. גישה כאן.
- הטבעת העתיד עם אדריאן אשלי. גישה כאן.
- קנה ומכירה של מניות בחברות PRE-IPO עם PREIPO®. גישה כאן.
- מקור: https://www.kdnuggets.com/2023/05/llm-apocalypse-revenge-open-source-clones.html?utm_source=rss&utm_medium=rss&utm_campaign=llm-apocalypse-now-revenge-of-the-open-source-clones
- :יש ל
- :הוא
- :לֹא
- :איפה
- $ למעלה
- 9
- a
- יכול
- אודות
- אקדמיה
- גישה
- Adobe
- לקדם
- צוברים
- AI
- תעשיות
- כביכול
- לִכאוֹרָה
- גם
- אמזון בעברית
- an
- ו
- אחר
- כל
- כל אחד
- דבר
- אַפָּשׁ
- ממשקי API
- ARE
- טענה
- מאמר
- AS
- להניח
- At
- מחבר
- מחברים
- זמין
- צִיר
- BE
- כי
- היה
- להיות
- הטבות
- הטוב ביותר
- מוטב
- גדול
- ביטורנט
- לוּחַ
- שניהם
- תקציבים
- לִבנוֹת
- בִּניָן
- צרור
- עסקים
- מודל עסקי
- אבל
- by
- הגיע
- CAN
- יכולות
- הון
- מקרה
- מנכ"ל
- כִּסֵא
- לאתגר
- שינוי
- ChatGPT
- זול יותר
- בחר
- מעגל
- לטעון
- ברור
- סְגוֹר
- סגור
- ענן
- שירותי ענן
- קוד
- איך
- מגיע
- מצרך
- הקהילות
- קהילה
- חברות
- משכנע
- להתחרות
- מתחרה
- לחשב
- המחשב
- ראייה ממוחשבת
- תוכן
- תורמים
- הַעתָקָה
- זכויות יוצרים
- עלויות
- יכול
- בית דין
- לִיצוֹר
- יוצרים
- יוצרים
- קריפטוקוין
- כיום
- מחזורי
- נתונים
- אספקה
- סגן
- עיצובים
- מפתח
- צעצועי התפתחות
- למות
- אחר
- קשה
- שידור
- מובהק
- שונה
- do
- מסמך
- עושה
- לא
- e
- כַּלְכָּלִי
- אפקטיבי
- מה שמאפשר
- סוף
- שלם
- אפוס
- ציוד
- למעשה
- מוערך
- אֲפִילוּ
- דוגמה
- לצפות
- יקר
- ניסיון
- רחוק
- מהר יותר
- חשבתי
- זורם
- בעקבות
- בעד
- מַעבָּרָה
- חופשי
- החל מ-
- מלא
- ביסודו
- מימון
- ציוד
- כללי
- גנרטטיבית
- AI Generative
- טוב
- GPU
- גרף
- גדול
- היה
- קשה
- חומרה
- יש
- יש
- he
- כאן
- גָבוֹהַ
- מאוד
- מחזיקים
- איך
- איך
- אולם
- HTTPS
- עצום
- התלהבות
- i
- מזהה
- if
- תמונות
- חשוב
- לשפר
- משופר
- in
- תמריצים
- בנפרד
- חדשנות
- קלט
- מטורף
- השראה
- במקום
- מוסד
- ואינטגרציות
- מעניין
- פנימי
- אינטרנט
- בדוי
- IP
- אירוניה
- IT
- איטרציה
- שֶׁלָה
- רק
- KDnuggets
- לדעת
- נחיתה
- האחרון
- חוק
- שכבה
- מנהיגות
- למד
- עזבו
- פחות
- רמה
- רישיון
- מורשה
- רישוי
- כמו
- קווים
- קשר
- לינקדין
- קְצָת
- לאמה
- ארוך
- נראה
- הסתכלות
- להפסיד
- את
- מגרש
- גדול
- לעשות
- עשייה
- רב
- שוק
- מסיבי
- להתאים
- מאי..
- מדיה
- meta
- מיקרוסופט
- מודל
- מודלים
- מונטיזציה
- כסף
- יותר
- רוב
- הרבה
- צורך
- לא זה ולא זה
- לא
- לא מסחרי
- עַכשָׁיו
- אובייקט
- אובייקטים
- of
- on
- ONE
- רק
- לפתוח
- קוד פתוח
- פרויקטים של קוד פתוח
- OpenAI
- or
- רגיל
- בְּמָקוֹר
- אחר
- הַחוּצָה
- תפוקה
- יותר
- שֶׁלוֹ
- שלום
- פרמטר
- עבר
- תשלום
- אֲנָשִׁים
- לבצע
- ביצועים
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- נקודה
- אפשרויות
- כּוֹחַ
- בעיה
- המוצר
- מוצרים
- פּרוֹיֶקט
- פרויקטים
- קניינית
- נוף
- להעלות
- מורם
- במקום
- בֶּאֱמֶת
- לאחרונה
- שוחרר
- מיוצג
- מחקר
- חוקרים
- משאבים
- הגבלה
- וכתוצאה מכך
- זכויות
- סיבובים
- מלכותי
- הפעלה
- s
- בטוח
- אותו
- לומר
- לראות
- קטע
- למכור
- נפרד
- סדרה
- סדרה א '
- משמש
- שירותים
- סט
- מחסור
- לְהַצִיג
- since
- יחיד
- מידה
- קטן יותר
- חכם
- So
- חֶברָתִי
- מדיה חברתית
- חֶברָה
- תוכנה
- כמה
- משהו
- מָקוֹר
- קוד מקור
- לבלות
- יציב
- סטנפורד
- חברות סטארט-אפ
- סטארט - אפ
- אִסטרָטֶגִיָה
- כזה
- להציע
- אמור
- עלתה על
- לקחת
- משימות
- לוקח
- טכנולוגיה
- מֵאֲשֶׁר
- זֶה
- אל האני
- המקור
- העולם
- שֶׁלָהֶם
- אותם
- אז
- שם.
- הֵם
- דבר
- לחשוב
- שְׁלִישִׁי
- זֶה
- אלה
- שְׁלוֹשָׁה
- זמן
- ל
- גַם
- לקח
- רכבת
- מְאוּמָן
- הדרכה
- תור
- פונה
- תחת
- מבין
- ייחודי
- בניגוד
- עד
- us
- להשתמש
- מְשׁוּמָשׁ
- שימושים
- באמצעות
- הערכות שווי
- ערך
- לאמת
- גרסה
- אנכי
- מאוד
- באמצעות
- לצפיה
- חזון
- VMware
- vs
- לחכות
- רוצה
- היה
- דֶרֶך..
- we
- הלכתי
- היו
- מה
- מתי
- אשר
- מי
- כל
- של מי
- יצטרך
- חכם
- עם
- תיק עבודות
- עוֹלָם
- טעות
- אתה
- זפירנט









