אפאצ'י הודי הוא פורמט טבלה פתוח שמביא יכולות של מסד נתונים ומחסני נתונים לאגמי נתונים. Apache Hudi מסייע למהנדסי נתונים לנהל אתגרים מורכבים, כגון ניהול מערכי נתונים המתפתחים ללא הרף עם עסקאות תוך שמירה על ביצועי שאילתות. מהנדסי נתונים משתמשים ב- Apache Hudi לצורך הזרמת עומסי עבודה וכן ליצירת צינורות נתונים מצטברים יעילים. חודי מספק שולחנות, עסקות, העלאות ומחיקות יעילים, אינדקסים מתקדמים, שירותי הזרמת סטרימינג, נתונים קיבוץ ו דחיסה אופטימיזציות, ו בקרת מקביליות, כל זאת תוך שמירה על הנתונים שלך בפורמטים של קובץ קוד פתוח. אופטימיזציות הביצועים המתקדמות של Hudi הופכות עומסי עבודה אנליטיים למהירים יותר עם כל אחד ממנועי השאילתות הפופולריים, כולל Apache Spark, Presto, Trino, Hive וכו'.
לקוחות AWS רבים אימצו את Apache Hudi על אגמי הנתונים שלהם שנבנו על גבי Amazon S3 באמצעות דבק AWS, שירות שילוב נתונים ללא שרת המקל על גילוי, הכנה, העברה ושילוב של נתונים ממקורות מרובים לניתוח, למידת מכונה (ML) ופיתוח יישומים. סורק דבק AWS הוא רכיב של AWS Glue, המאפשר לך ליצור מטא נתונים של טבלה מתוכן נתונים באופן אוטומטי מבלי לדרוש הגדרה ידנית של המטא נתונים.
סורקי AWS Glue תומכים כעת בטבלאות Apache Hudi, מפשט את האימוץ של קטלוג נתוני דבק של AWS כקטלוג לשולחנות הודי. מקרה שימוש טיפוסי אחד הוא רישום טבלאות Hudi, שאין להן הגדרה של טבלת קטלוג. מקרה שימוש טיפוסי נוסף הוא הגירה מקטלוגים אחרים של Hudi, כגון Hive metastore. בעת הגירה מקטלוגים אחרים של Hudi, אתה יכול ליצור ולתזמן סורק AWS Glue ולספק נתיב אחד או יותר של Amazon S3 שבו ממוקמים קבצי הטבלה של Hudi. יש לך אפשרות לספק את העומק המרבי של נתיבי Amazon S3 שסורק הדבק של AWS יכול לעבור. עם כל הפעלה, סורקי AWS Glue יחלצו מידע על סכימה ומחיצות ויעדכנו את קטלוג הנתונים של AWS Glue עם שינויים בסכימה ובמחיצות. סורקי AWS Glue מעדכנים את מיקום קובץ המטא-נתונים העדכני ביותר בקטלוג הנתונים של AWS Glue Data שבו מנועים אנליטיים של AWS יכולים להשתמש ישירות.
עם השקה זו, אתה יכול ליצור ולתזמן סורק AWS Glue לרישום טבלאות Hudi בקטלוג הנתונים של AWS Glue Data. לאחר מכן תוכל לספק נתיב אחד או יותר של Amazon S3 שבו ממוקמים טבלאות Hudi. יש לך אפשרות לספק את העומק המרבי של נתיבים של Amazon S3 שסורקים יכולים לעבור. עם כל הפעלת סורק, הסורק בודק כל אחד מנתיבי S3 ומקטלג את מידע הסכימה, כגון טבלאות חדשות, מחיקות ועדכונים לסכמות בקטלוג הנתונים של AWS Glue Data. הסורקים בודקים מידע מחיצות ומוסיפים מחיצות חדשות שנוספו לקטלוג הנתונים של דבק של AWS. הסורקים גם מעדכנים את מיקום קובץ המטא-נתונים העדכני ביותר בקטלוג נתוני הדבק של AWS שבו מנועים אנליטיים של AWS יכולים להשתמש ישירות.
פוסט זה מדגים כיצד היכולת החדשה הזו לסרוק טבלאות Hudi עובדת.
איך AWS Glue Crawler עובד עם טבלאות Hudi
לטבלאות הודי יש שתי קטגוריות, עם השלכות ספציפיות לכל אחת מהן:
- העתק בכתיבה (CoW) – הנתונים מאוחסנים בפורמט עמודי (Parquet), וכל עדכון יוצר גרסה חדשה של קבצים במהלך הכתיבה.
- מיזוג בקריאה (MoR) – הנתונים מאוחסנים באמצעות שילוב של פורמטים עמודים (פרקט) ופורמטים מבוססי שורות (Avro). עדכונים מתועדים לפי שורות
deltaקבצים ונדחסים לפי הצורך כדי ליצור גרסאות חדשות של הקבצים העמודות.
עם מערכי נתונים של CoW, בכל פעם שיש עדכון לרשומה, הקובץ המכיל את הרשומה נכתב מחדש עם הערכים המעודכנים. עם מערך נתונים של MoR, בכל פעם שיש עדכון, Hudi כותב רק את השורה עבור הרשומה שהשתנתה. MoR מתאים יותר לעומסי עבודה כבדים בכתיבה או בשינוי עם פחות קריאות. CoW מתאימה יותר לעומסי עבודה כבדים בקריאה על נתונים המשתנים בתדירות נמוכה יותר.
Hudi מספק שלושה סוגי שאילתות לגישה לנתונים:
- שאילתות תמונת מצב – שאילתות שרואות את תמונת המצב העדכנית ביותר של הטבלה כמו התחייבות או פעולת דחיסה נתונה. עבור טבלאות MoR, שאילתות תמונת מצב חושפות את המצב העדכני ביותר של הטבלה על ידי מיזוג קבצי הבסיס והדלתא של פרוסת הקובץ האחרונה בזמן השאילתה.
- שאילתות מצטברות – שאילתות רואות רק נתונים חדשים שנכתבו לטבלה, מאז התחייבות או דחיסה נתונה. זה מספק למעשה זרמי שינוי כדי לאפשר צינורות נתונים מצטברים.
- קרא שאילתות מותאמות - עבור טבלאות MoR, שאילתות רואות את הנתונים העדכניים ביותר שנדחסו. עבור טבלאות CoW, שאילתות ראו את הנתונים העדכניים ביותר שבוצעו.
עבור טבלאות העתק-על-כתיבה, הסורקים יוצרים טבלה בודדת בקטלוג הנתונים של דבק AWS עם ה-ReadOptimized Serde org.apache.hudi.hadoop.HoodieParquetInputFormat.
עבור טבלאות מיזוג-על-קריאה, הסורקים יוצרים שתי טבלאות ב-AWS Glue Data Catalog עבור אותו מיקום טבלה:
- טבלה עם סיומת
_ro, שמשתמש ב-ReadOptimized Serdeorg.apache.hudi.hadoop.HoodieParquetInputFormat - טבלה עם סיומת
_rt, שמשתמש ב-RealTime Serde המאפשר שאילתות Snapshot:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
במהלך כל סריקה, עבור כל נתיב Hudi שסופק, הסורקים מבצעים קריאה ל-Amazon S3 list API, מסנן על סמך .hoodie תיקיות, ומצא את קובץ המטא-נתונים העדכני ביותר מתחת לתיקיית המטא-נתונים של טבלת Hudi.
סרוק שולחן Hudi CoW באמצעות סורק AWS Glue
בסעיף זה, בואו נעבור על איך לזרוק Hudi CoW באמצעות סורקי AWS Glue.
תנאים מוקדמים
להלן התנאים המוקדמים להדרכה זו:
- התקנה והגדרה ממשק שורת הפקודה AWS (AWS CLI).
- צור את דלי ה-S3 שלך אם אין לך אותו.
- צור את תפקיד IAM שלך עבור AWS Glue אם אין לך את זה. אתה צריך
s3:GetObjectלs3://your_s3_bucket/data/sample_hudi_cow_table/. - הפעל את הפקודה הבאה כדי להעתיק את טבלת Hudi לדוגמה לדלי S3 שלך. (החלף
your_s3_bucketעם שם דלי S3 שלך.)
הוראה זו מנחה אותך להעתיק נתונים לדוגמה, אבל אתה יכול ליצור כל טבלאות Hudi בקלות באמצעות AWS Glue. למידע נוסף ב הצגת תמיכה מקורית עבור Apache Hudi, Delta Lake ו- Apache Iceberg ב-AWS Glue for Apache Spark, חלק 2: עורך חזותי של AWS Glue Studio.
צור סורק Hudi
בהוראה זו, צור את הסורק דרך הקונסולה. השלם את השלבים הבאים כדי ליצור סורק Hudi:
- במסוף הדבק של AWS בחר סורקים.
- בחרו צור סורק.
- בעד שם, להיכנס
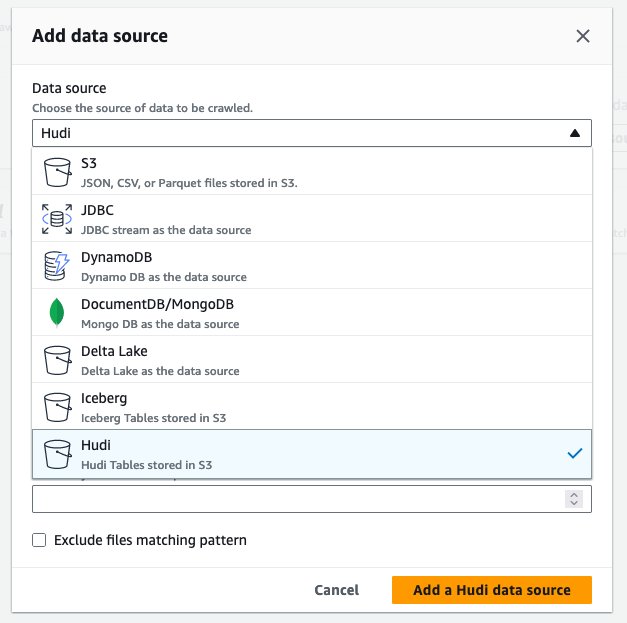
hudi_cow_crawler. בחר הַבָּא. - תַחַת תצורת מקור נתונים, בחר הוסף מקור נתונים.
- בעד מקור נתונים, בחר חודי.
- בעד כלול נתיבים של טבלת הודי, להיכנס
s3://your_s3_bucket/data/sample_hudi_cow_table/. (החלףyour_s3_bucketעם שם דלי S3 שלך.) - בחרו הוסף מקור נתונים של Hudi.
- בחרו הַבָּא.
- בעד תפקיד IAM קיים, בחר את תפקיד IAM שלך ולאחר מכן בחר הַבָּא.
- בעד מסד נתונים יעד, בחר הוסף מסד נתונים, אז ה הוסף מסד נתונים מופיעה תיבת דו-שיח. ל שם בסיס הנתונים, להיכנס
hudi_crawler_blog, ואז לבחור צור. בחר הַבָּא. - בחרו צור סורק.
כעת נוצר בהצלחה סורק חדש של Hudi. ניתן להפעיל את הסורק לרוץ דרך הקונסולה או דרך SDK או AWS CLI באמצעות StartCrawl ממשק API. זה יכול גם להיות מתוזמן דרך המסוף כדי להפעיל את הסורקים בזמנים ספציפיים. בהוראה זו, הפעל את הסורק דרך הקונסולה.
- בחרו הפעל סורק.
- המתן עד שהסורק יסתיים.
לאחר הפעלת הסורק, תוכל לראות את הגדרת טבלת Hudi במסוף הדבק של AWS:
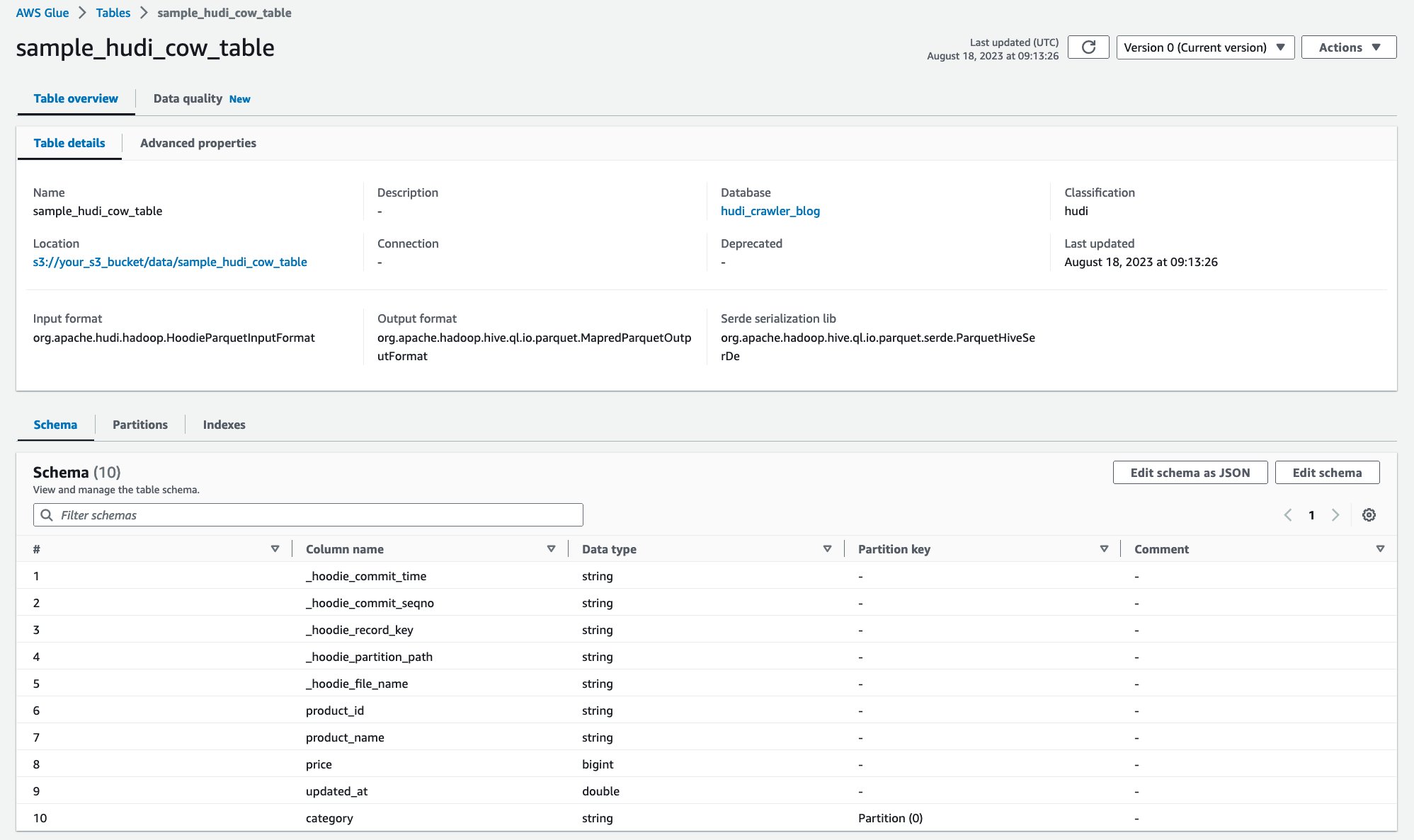
סרקתם בהצלחה את טבלת Hudi CoR עם נתונים ב-Amazon S3 ויצרתם טבלת קטלוג נתונים של AWS Glue עם הסכימה מאוכלסת. לאחר יצירת הגדרת הטבלה בקטלוג הנתונים של AWS Glue Data, שירותי ניתוח של AWS כגון Amazon Athena יכולים לבצע שאילתות בטבלת Hudi.
השלם את השלבים הבאים כדי להתחיל שאילתות על Athena:
- פתח את קונסולת אמזון אתנה.
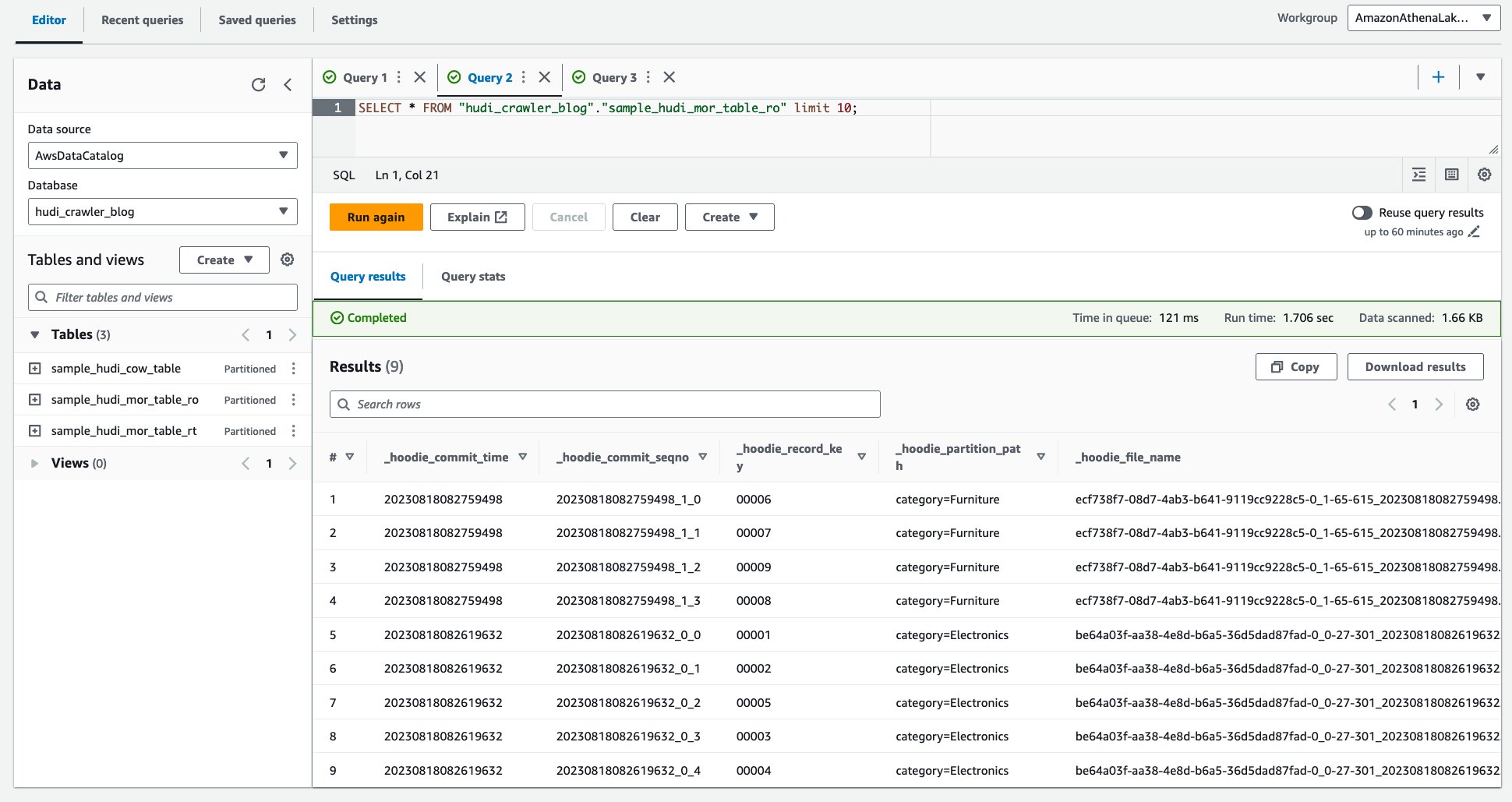
- הפעל את השאילתה הבאה.
צילום המסך הבא מציג את הפלט שלנו:
סרוק טבלת Hudi MoR באמצעות סורק AWS Glue עם הרשאות נתונים של AWS Lake Formation
בסעיף זה, בואו נעבור על איך לסרוק טבלת Hudi MoR באמצעות דבק AWS. הפעם, אתה משתמש בהרשאת הנתונים של AWS Lake Formation לסריקת מקורות נתונים של Amazon S3 במקום הרשאות IAM ו-Amazon S3. זה אופציונלי, אבל זה מפשט את תצורות ההרשאות כאשר אגם הנתונים שלך מנוהל על ידי הרשאות AWS Lake Formation.
תנאים מוקדמים
להלן התנאים המוקדמים להדרכה זו:
- התקנה והגדרה ממשק שורת הפקודה AWS (AWS CLI).
- צור את דלי ה-S3 שלך אם אין לך אותו.
- צור את תפקיד IAM שלך עבור AWS Glue אם אין לך את זה. אתה צריך
lakeformation:GetDataAccess. אבל אתה לא צריךs3:GetObjectלs3://your_s3_bucket/data/sample_hudi_mor_table/מכיוון שאנו משתמשים בהרשאת נתונים של Lake Formation כדי לגשת לקבצים. - הפעל את הפקודה הבאה כדי להעתיק את טבלת Hudi לדוגמה לדלי S3 שלך. (החלף
your_s3_bucketעם שם דלי S3 שלך.)
בנוסף לשלבי העיבוד, השלם את השלבים הבאים כדי לעדכן את הגדרות ה-AWS Glue Data Catalog לשימוש בהרשאות Lake Formation כדי לשלוט במשאבי קטלוג במקום בקרת גישה מבוססת IAM:
- היכנס למסוף של Lake Formation כמנהל אגם נתונים.
- אם זו הפעם הראשונה שניגשת לקונסולת Lake Formation, הוסף את עצמך כמנהל אגם הנתונים.
- תַחַת אדמינסטרציה, בחר הגדרות קטלוג נתונים.
- בעד הרשאות ברירת מחדל עבור מסדי נתונים וטבלאות שנוצרו לאחרונה, בטל את הבחירה השתמש רק בקרת גישה של IAM עבור מסדי נתונים חדשים ו השתמש רק בבקרת גישה של IAM לטבלאות חדשות בבסיסי נתונים חדשים.
- בעד הגדרת גרסה חוצה חשבון, בחר גרסת 3.
- בחרו שמור.
השלב הבא הוא לרשום את דלי ה-S3 שלך במיקומי אגם הנתונים של Lake Formation:
- בקונסולת Lake Lake, בחר מיקומי אגם נתונים, ולבחור רשום מיקום.
- בעד נתיב S3 של אמזון, להיכנס
s3://your_s3_bucket/. (החלףyour_s3_bucketעם שם דלי S3 שלך.) - בחרו רשום מיקום.
לאחר מכן, הענק לגשת לתפקיד הסורק של Glue למיקום הנתונים כך שהסורק יוכל להשתמש בהרשאת Lake Formation כדי לגשת לנתונים וליצור טבלאות במיקום:
- בקונסולת Lake Lake, בחר מיקומי נתונים ולבחור להעניק.
- בעד משתמשים ותפקידי IAM, בחר את תפקיד IAM שבו השתמשת עבור הסורק.
- בעד מקום איחסון, להיכנס
s3://your_s3_bucket/data/. (החלףyour_s3_bucketעם שם דלי S3 שלך.) - בחרו להעניק.
לאחר מכן, הענק תפקיד סורק ליצירת טבלאות תחת מסד הנתונים hudi_crawler_blog:
- בקונסולת Lake Lake, בחר הרשאות אגם נתונים.
- בחרו להעניק.
- בעד מנהלים, בחר משתמשים ותפקידי IAM, ובחר את תפקיד הסורק.
- בעד תגי LF או משאבי קטלוג, בחר משאבי קטלוג נתונים בעלי שם.
- בעד מסד נתונים, בחר את מסד הנתונים
hudi_crawler_blog. - תַחַת הרשאות מסד נתונים, בחר צור טבלה.
- בחרו להעניק.
צור סורק Hudi עם הרשאות נתונים של Lake Formation
השלם את השלבים הבאים כדי ליצור סורק Hudi:
- במסוף הדבק של AWS בחר סורקים.
- בחרו צור סורק.
- בעד שם, להיכנס
hudi_mor_crawler. בחר הַבָּא. - תַחַת תצורת מקור נתונים, בחר הוסף מקור נתונים.
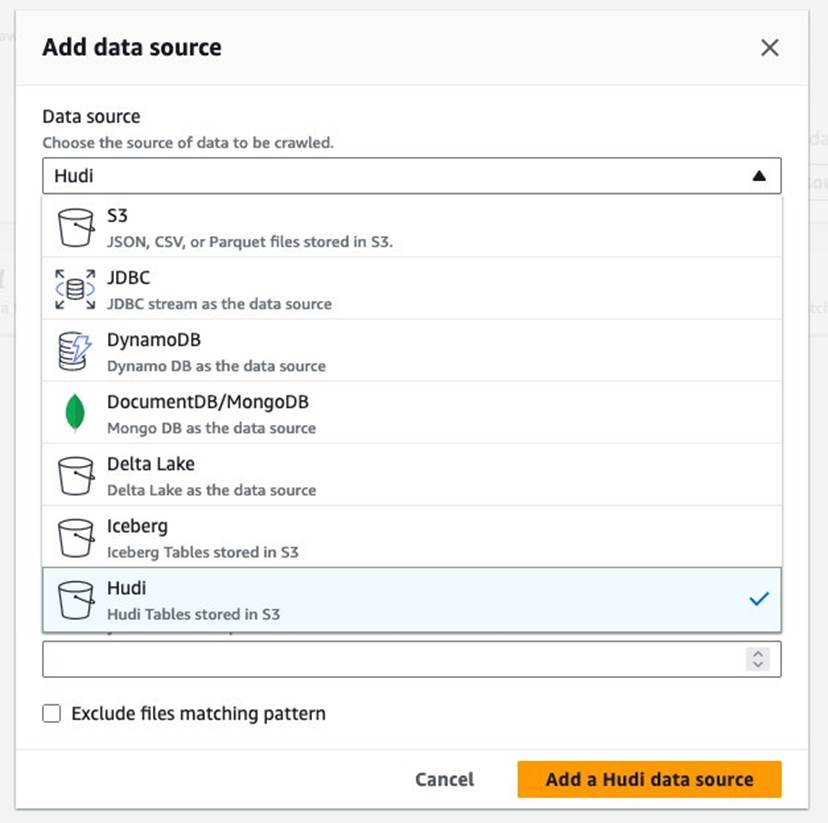
- בעד מקור נתונים, בחר חודי.
- בעד כלול נתיבים של טבלת הודי, להיכנס
s3://your_s3_bucket/data/sample_hudi_mor_table/. (החלףyour_s3_bucketעם שם דלי S3 שלך.) - בחרו הוסף מקור נתונים של Hudi.
- בחרו הַבָּא.
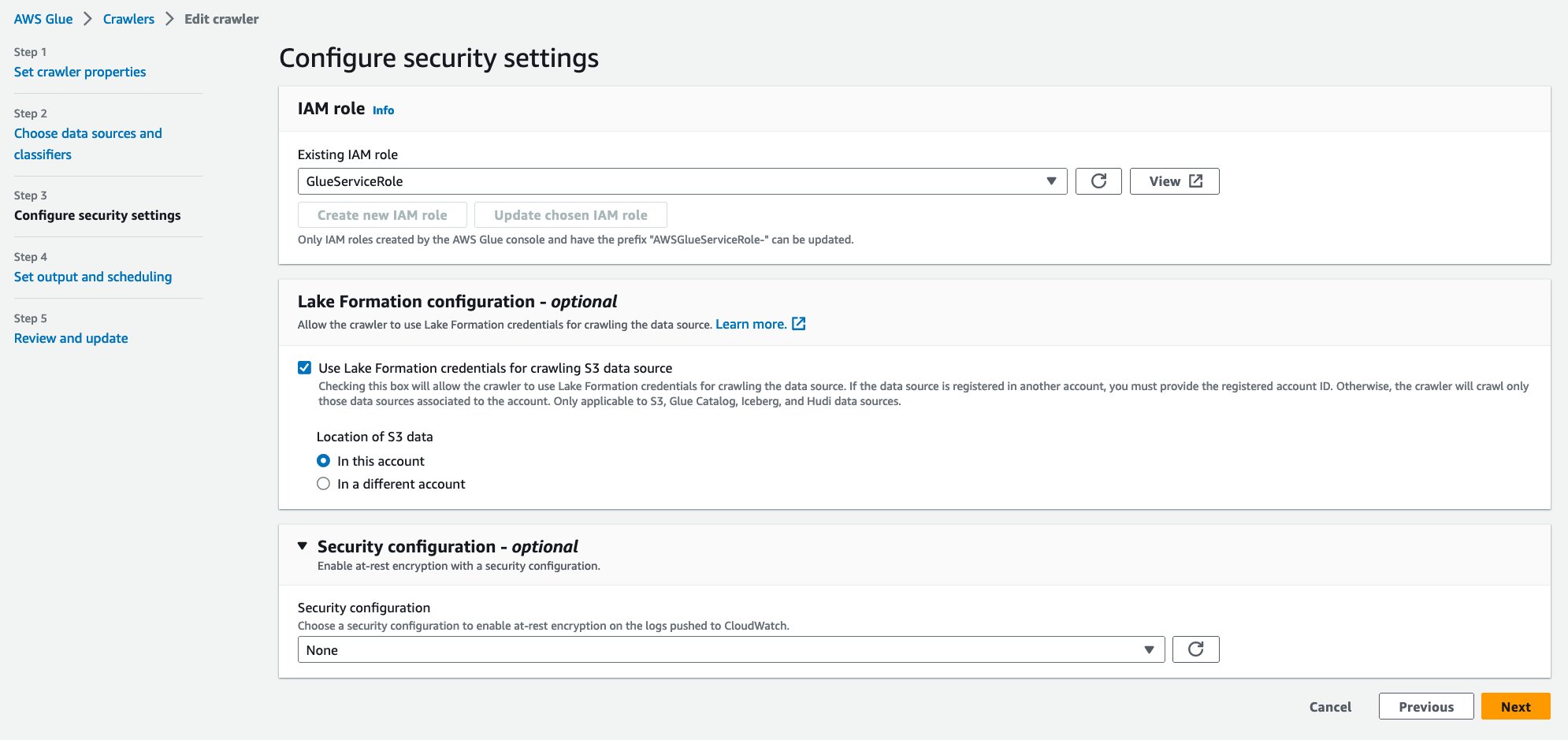
- בעד תפקיד IAM קיים, בחר את תפקיד IAM שלך.
- תַחַת תצורת Lake Formation - אופציונלי, בחר השתמש באישורים של Lake Formation לסריקת מקור נתונים S3.
- בחרו הַבָּא.
- בעד מסד נתונים יעד, בחר
hudi_crawler_blog. בחר הַבָּא. - בחרו צור סורק.
כעת נוצר בהצלחה סורק חדש של Hudi. הסורק משתמש באישורים של Lake Formation לסריקת קבצי Amazon S3. בואו נריץ את הסורק החדש:
- בחרו הפעל סורק.
- המתן עד שהסורק יסתיים.
לאחר הפעלת הסורק, תוכל לראות שתי טבלאות של הגדרת טבלת Hudi במסוף הדבק של AWS:
sample_hudi_mor_table_ro(קרא טבלה מותאמת)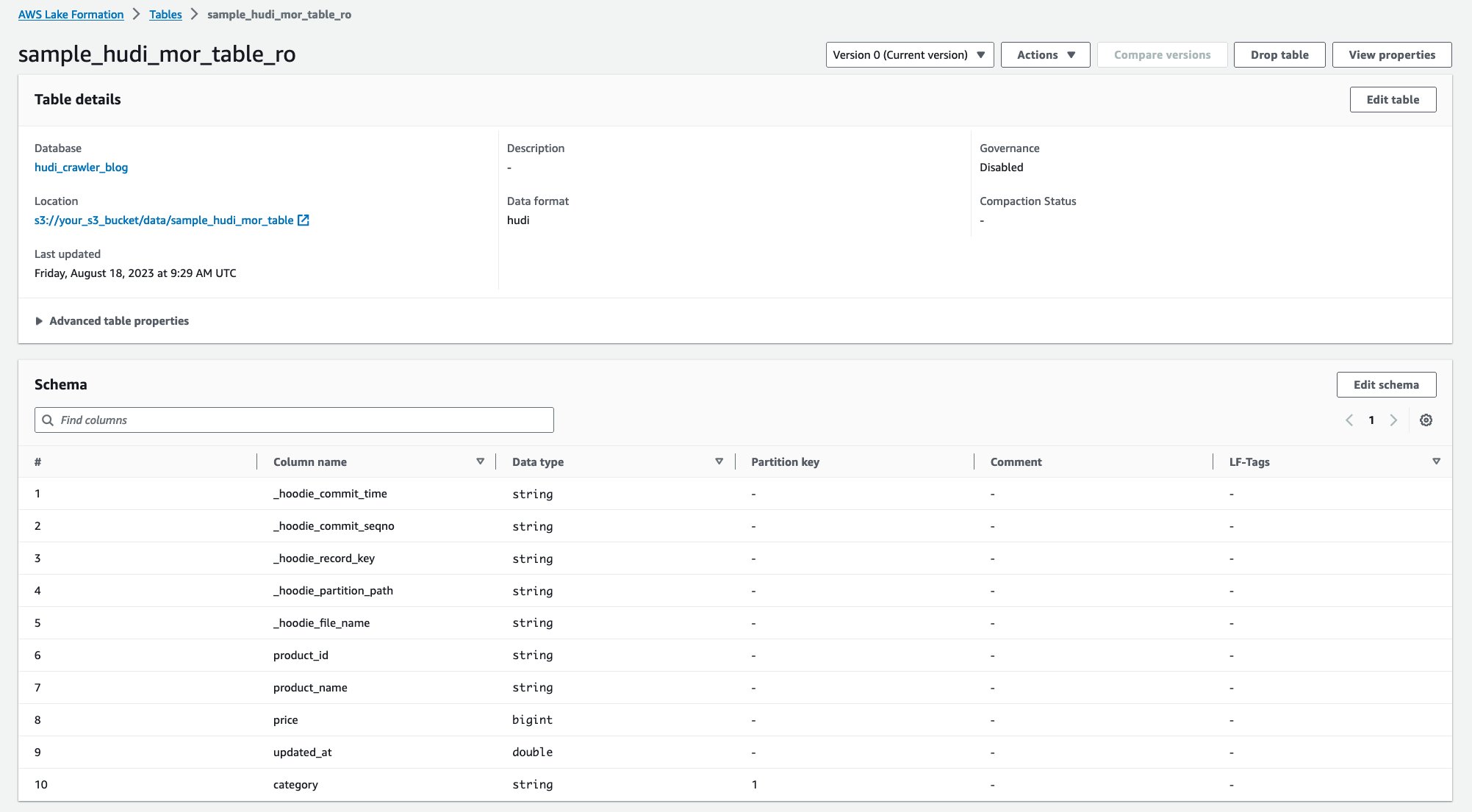
sample_hudi_mor_table_rt(לוח זמנים אמיתי)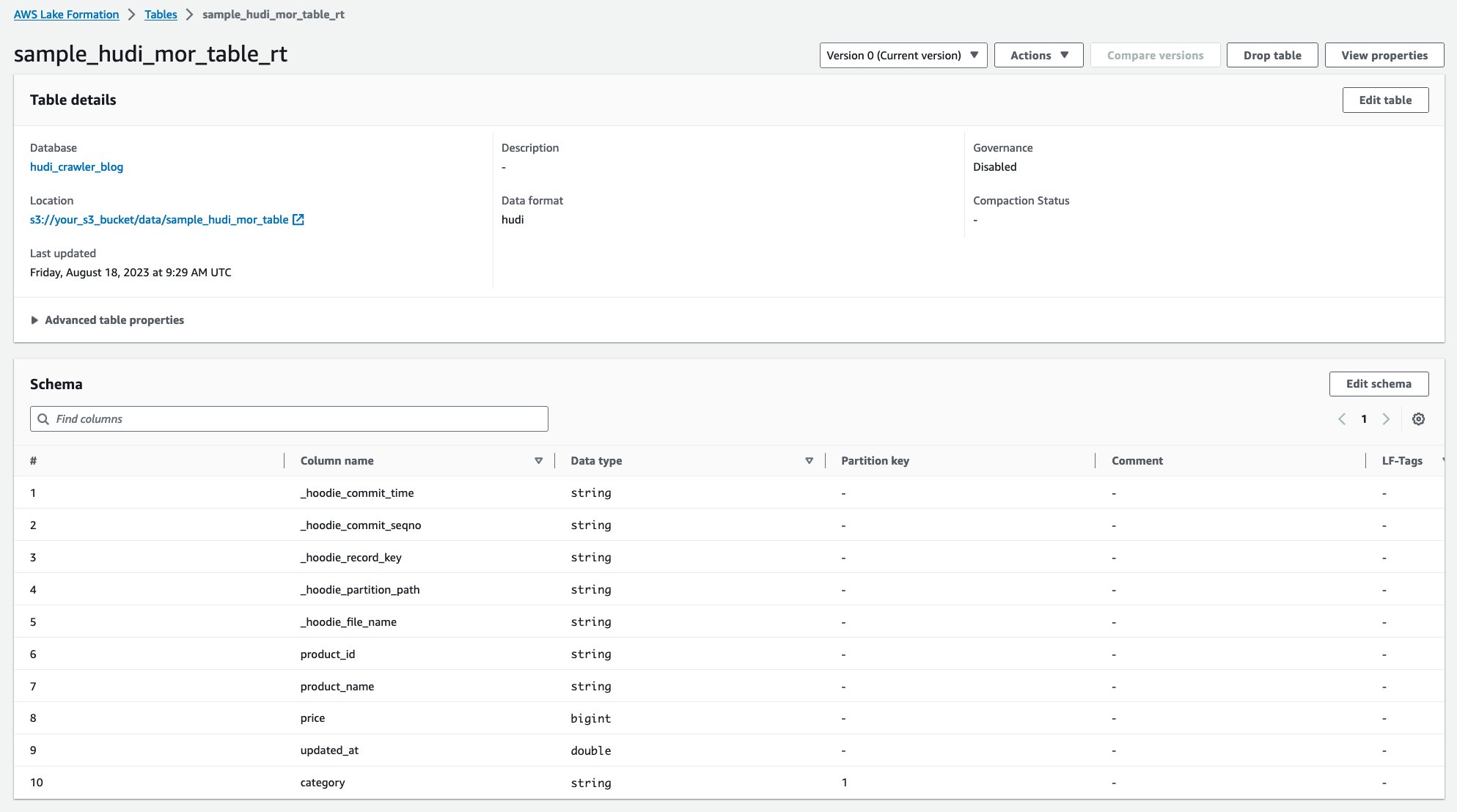
רשמת את דלי אגם הנתונים עם Lake Formation ואפשרת גישת סריקה לאגם הנתונים באמצעות הרשאות Lake Formation. סרקתם בהצלחה את טבלת Hudi MoR עם נתונים על Amazon S3 ויצרתם טבלת קטלוג נתונים של AWS Glue עם הסכימה מאוכלסת. לאחר יצירת הגדרות הטבלה בקטלוג נתוני הדבק של AWS, שירותי ניתוח של AWS כגון Amazon Athena יכולים לבצע שאילתות בטבלת Hudi.
השלם את השלבים הבאים כדי להתחיל שאילתות על Athena:
- פתח את קונסולת אמזון אתנה.
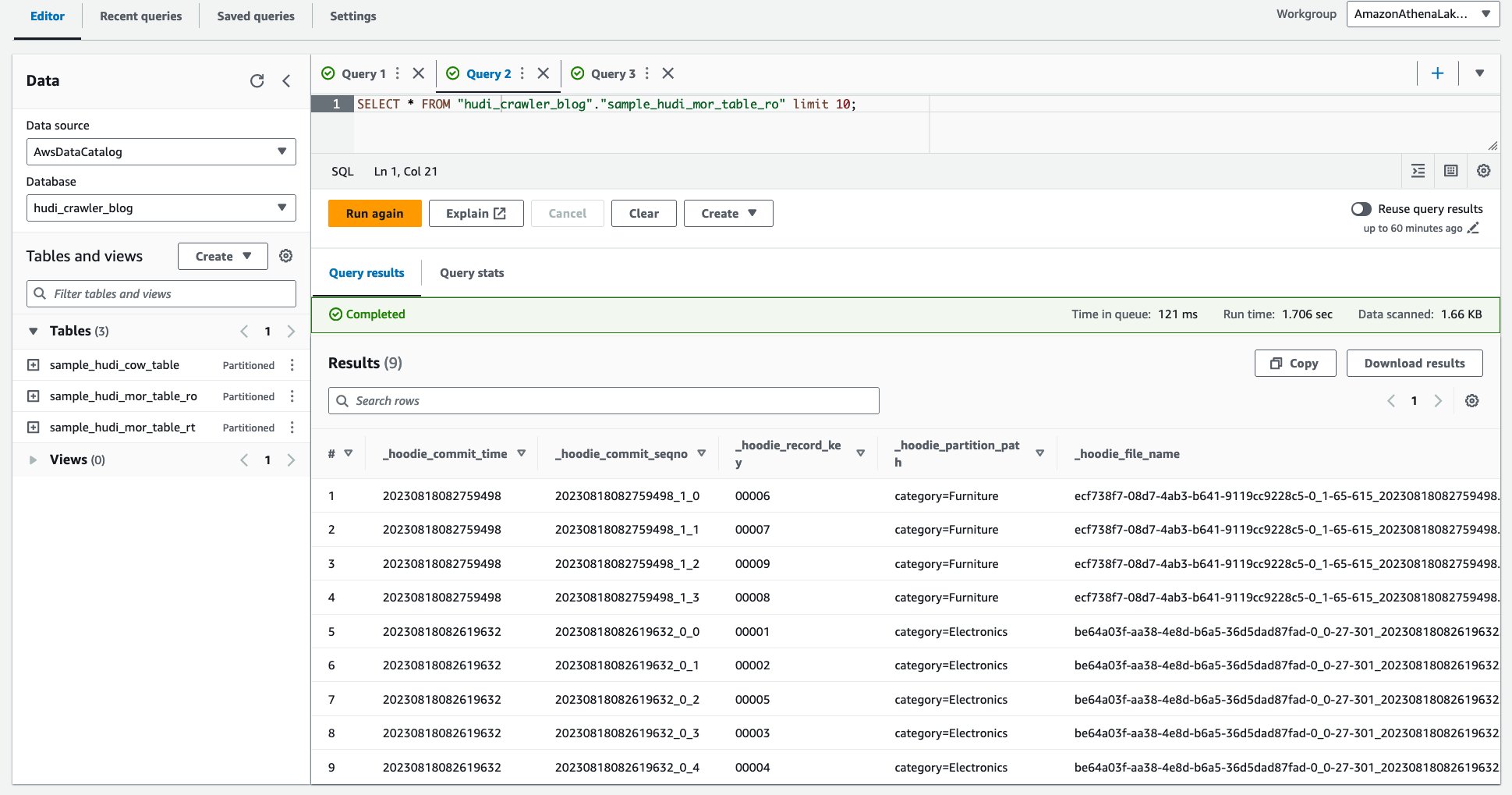
- הפעל את השאילתה הבאה.
צילום המסך הבא מציג את הפלט שלנו:
- הפעל את השאילתה הבאה.
צילום המסך הבא מציג את הפלט שלנו:
בקרת גישה עדינה באמצעות הרשאות AWS Lake Formation
כדי להחיל בקרת גישה עדינה על טבלת Hudi, אתה יכול ליהנות מהרשאות AWS Lake Formation. הרשאות Lake Formation מאפשרות לך להגביל גישה לטבלאות, עמודות או שורות ספציפיות ולאחר מכן לבצע שאילתות לטבלאות Hudi דרך Amazon Athena עם בקרת גישה עדינה. בואו נגדיר את הרשאת Lake Formation עבור טבלת Hudi MoR.
תנאים מוקדמים
להלן התנאים המוקדמים להדרכה זו:
- השלם את הסעיף הקודם סרוק טבלת Hudi MoR באמצעות סורק AWS Glue עם הרשאות נתונים של AWS Lake Formation.
- צור משתמש IAM DataAnalyst, שיש לו מדיניות מנוהלת AWS AmazonAthenaFullAccess.
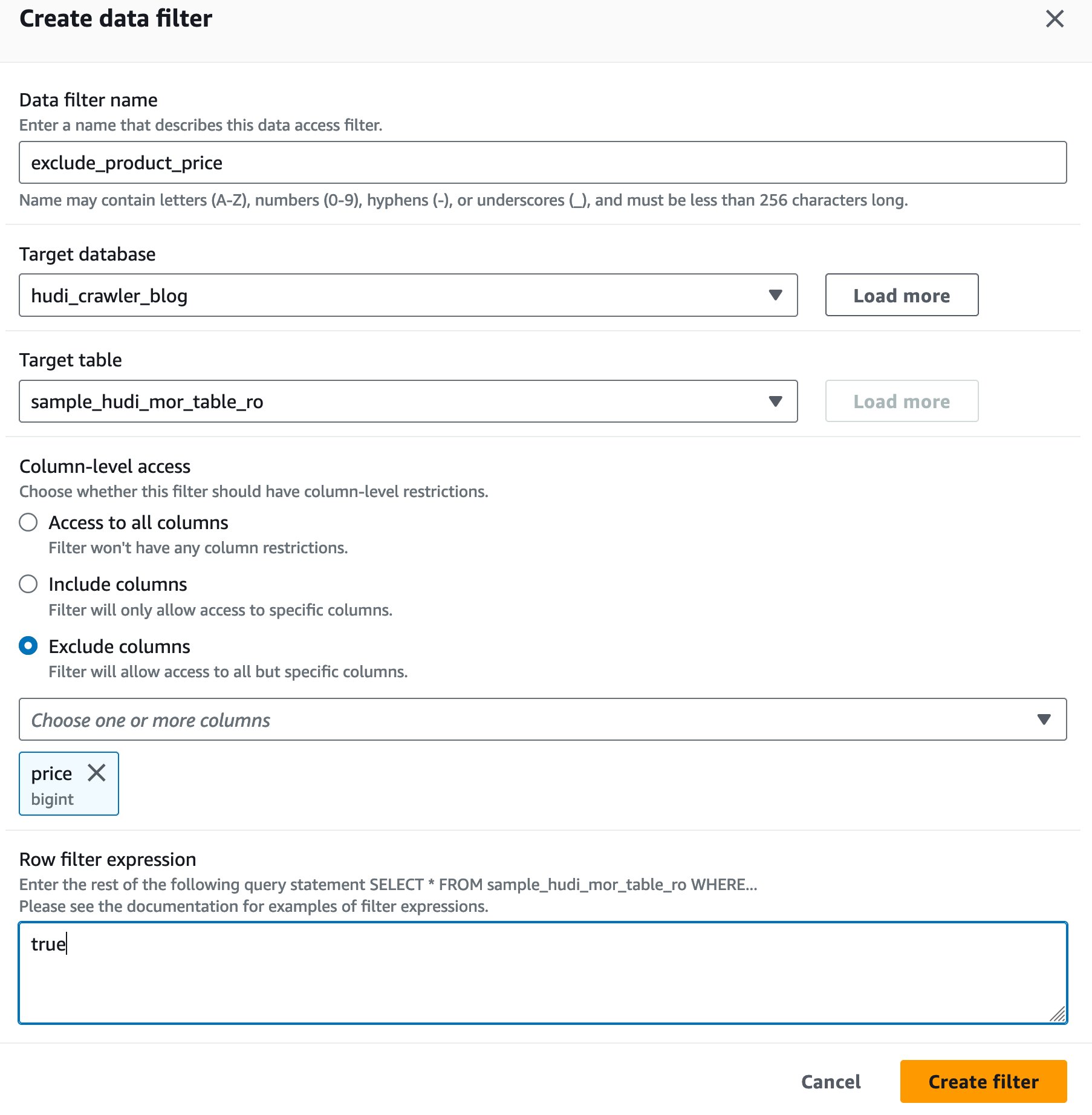
צור מסנן תא נתונים של Lake Formation
בואו נגדיר תחילה מסנן לטבלה המותאמת לקריאה של MoR.
- היכנס למסוף של Lake Formation כמנהל אגם נתונים.
- בחרו מסנני נתונים.
- בחרו צור מסנן חדש.
- בעד שם מסנן נתונים, להיכנס
exclude_product_price. - בעד מסד נתונים יעד, בחר את מסד הנתונים
hudi_crawler_blog. - בעד טבלת יעד, בחר את הטבלה
sample_hudi_mor_table_ro. - בעד ברמת העמודה גישה, בחר אל תכלול עמודות, ובחר את מחיר העמודה.
- בעד ביטוי מסנן שורה, להיכנס
true. - בחרו צור מסנן.
הענק הרשאות Lake Formation למשתמש DataAnalyst
השלם את השלבים הבאים כדי להעניק הרשאה של Lake Formation ל- DataAnalyst המשתמש
- בקונסולת Lake Lake, בחר הרשאות אגם נתונים.
- בחרו להעניק.
- בעד מנהלים, בחר משתמשים ותפקידי IAM, ובחר את המשתמש
DataAnalyst. - בעד תגי LF או משאבי קטלוג, בחר משאבי קטלוג נתונים בעלי שם.
- בעד מסד נתונים, בחר את מסד הנתונים
hudi_crawler_blog. - בעד שולחן - אופציונלי, בחר את הטבלה
sample_hudi_mor_table_ro. - בעד מסנני נתונים - אופציונלי, בחר
exclude_product_price. - בעד הרשאות סינון נתונים, בחר בחר.
- בחרו להעניק.
הענקת הרשאה ל-Lake Formation במסד הנתונים hudi_crawler_blog והשולחן sample_hudi_mor_table_ro, לא כולל העמודה price למשתמש DataAnalyst. כעת בואו נאמת את גישת המשתמש לנתונים באמצעות Athena.
- היכנס למסוף Athena כמשתמש DataAnalyst.
- בעורך השאילתות, הפעל את השאילתה הבאה:
צילום המסך הבא מציג את הפלט שלנו:
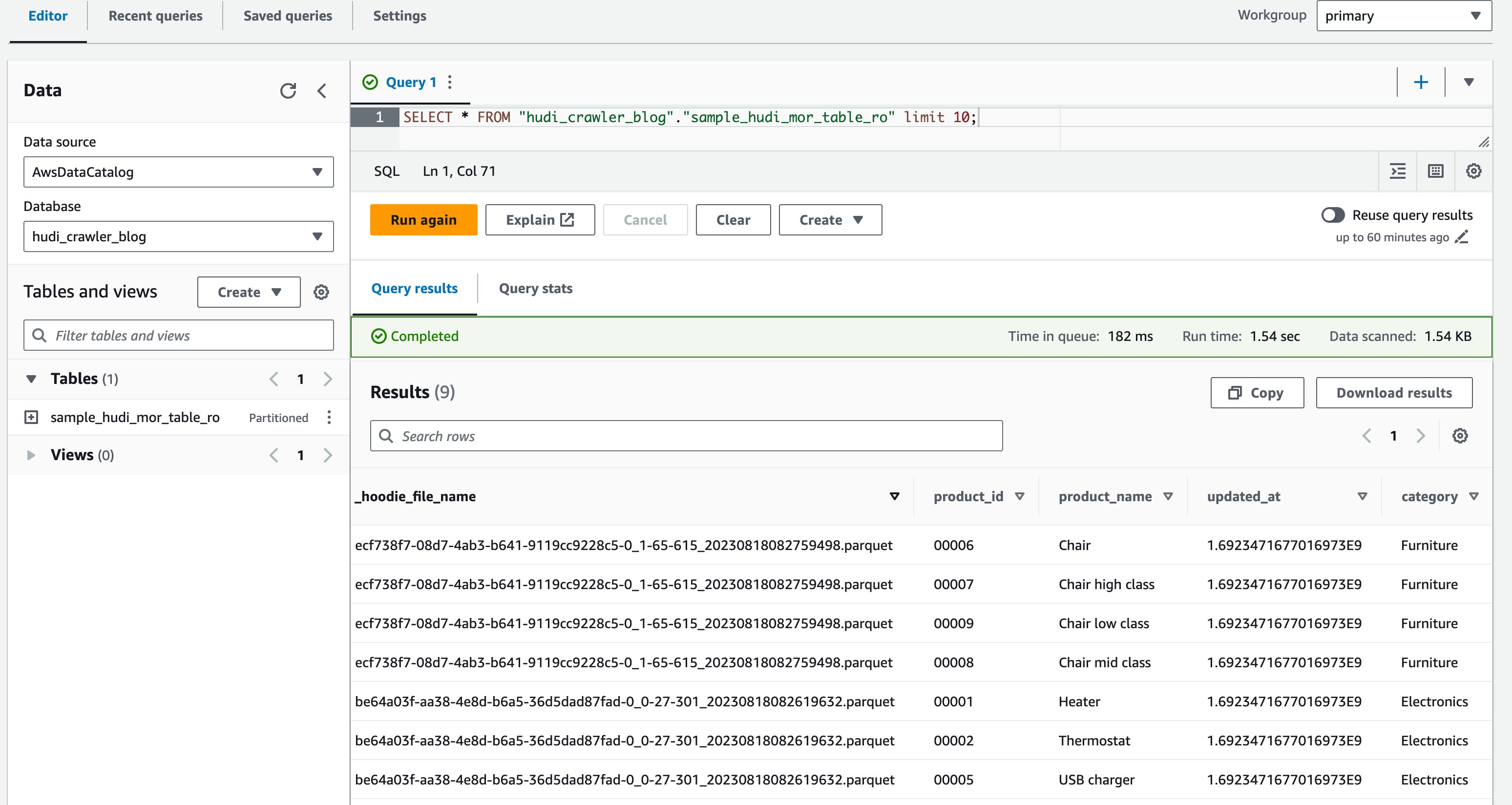
עכשיו אימתת את העמודה price לא מוצג, אלא העמודות האחרות product_id, product_name, update_at, ו category מוצגים.
לנקות את
כדי למנוע חיובים לא רצויים בחשבון AWS שלך, מחק את משאבי AWS הבאים:
- מחק את מסד הנתונים של AWS Glue
hudi_crawler_blog. - מחק סורקי AWS Glue
hudi_cow_crawlerוhudi_mor_crawler. - מחק קבצי Amazon S3 תחת
s3://your_s3_bucket/data/sample_hudi_cow_table/וs3://your_s3_bucket/data/sample_hudi_mor_table/.
סיכום
פוסט זה הדגים כיצד סורקי AWS Glue פועלים עבור שולחנות Hudi. עם התמיכה בסורק Hudi, אתה יכול לעבור במהירות לשימוש בקטלוג הנתונים של דבק של AWS כקטלוג טבלאות Hudi הראשי שלך. אתה יכול להתחיל לבנות את אגם הנתונים העסקאות ללא שרת שלך באמצעות Hudi ב-AWS באמצעות AWS Glue, AWS Glue Data Catalog ו-Lake Formation בקרות גישה עדינות לטבלאות ופורמטים הנתמכים על ידי מנועים אנליטיים של AWS.
על המחברים
 נוריטקה סקיאמה הוא אדריכל ביג דאטה ראשי בצוות AWS Glue. הוא עובד בטוקיו, יפן. הוא אחראי על בניית חפצי תוכנה כדי לעזור ללקוחות. בזמנו הפנוי הוא נהנה לרכוב עם אופני הכביש שלו.
נוריטקה סקיאמה הוא אדריכל ביג דאטה ראשי בצוות AWS Glue. הוא עובד בטוקיו, יפן. הוא אחראי על בניית חפצי תוכנה כדי לעזור ללקוחות. בזמנו הפנוי הוא נהנה לרכוב עם אופני הכביש שלו.
 קייל דוונג הוא מהנדס פיתוח תוכנה בצוות AWS Glue and Lake Formation. הוא נלהב מבניית טכנולוגיות ביג דאטה ומערכות מבוזרות.
קייל דוונג הוא מהנדס פיתוח תוכנה בצוות AWS Glue and Lake Formation. הוא נלהב מבניית טכנולוגיות ביג דאטה ומערכות מבוזרות.
 סנדיפ אדוואנקר הוא מנהל מוצר טכני בכיר ב-AWS. מבוסס באזור מפרץ קליפורניה, הוא עובד עם לקוחות ברחבי העולם כדי לתרגם דרישות עסקיות וטכניות למוצרים המאפשרים ללקוחות לשפר את אופן הניהול, האבטחה והגישה לנתונים.
סנדיפ אדוואנקר הוא מנהל מוצר טכני בכיר ב-AWS. מבוסס באזור מפרץ קליפורניה, הוא עובד עם לקוחות ברחבי העולם כדי לתרגם דרישות עסקיות וטכניות למוצרים המאפשרים ללקוחות לשפר את אופן הניהול, האבטחה והגישה לנתונים.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- :יש ל
- :הוא
- :לֹא
- :איפה
- $ למעלה
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- יכול
- אודות
- גישה
- גישה לנתונים
- גישה
- חֶשְׁבּוֹן
- פעולה
- להוסיף
- הוסיף
- תוספת
- מאומץ
- אימוץ
- מתקדם
- לאחר
- תעשיות
- להתיר
- מאפשר
- מאפשר
- גם
- אמזון בעברית
- אמזונה אתנה
- אמזון שירותי אינטרנט
- an
- אנליטית
- ניתוח
- ו
- אחר
- כל
- אַפָּשׁ
- אפאצ 'י ספארק
- API
- מופיע
- בקשה
- פיתוח אפליקציות
- החל
- ARE
- AREA
- סביב
- AS
- At
- באופן אוטומטי
- לְהִמָנַע
- AWS
- דבק AWS
- תצורת אגם AWS
- בסיס
- מבוסס
- מִפרָץ
- BE
- כי
- היה
- תועלת
- מוטב
- גָדוֹל
- נתונים גדולים
- מביא
- בִּניָן
- נבנה
- עסקים
- אבל
- by
- קליפורניה
- שיחה
- CAN
- יכולות
- יכולת
- מקרה
- קטלוג
- קטלוגים
- קטגוריות
- תא
- האתגרים
- שינוי
- השתנה
- שינויים
- חיובים
- בחרו
- טור
- עמודות
- שילוב
- לבצע
- מְחוּיָב
- להשלים
- מורכב
- רְכִיב
- תְצוּרָה
- קונסול
- מכיל
- תוכן
- ברציפות
- לִשְׁלוֹט
- בקרות
- יכול
- הסורק
- לִיצוֹר
- נוצר
- יוצר
- אישורים
- לקוחות
- נתונים
- שילוב נתונים
- אגם דאטה
- מחסן נתונים
- מסד נתונים
- מאגרי מידע
- מערכי נתונים
- הגדרה
- הגדרות
- דלתא
- מופגן
- מדגים
- עומק
- צעצועי התפתחות
- ישירות
- לגלות
- מופץ
- מערכות מבוזרות
- do
- עושה
- בְּמַהֲלָך
- כל אחד
- קל יותר
- בקלות
- עורך
- יעילות
- יעיל
- לאפשר
- מופעל
- מהנדס
- מהנדסים
- מנועים
- זן
- Ether (ETH)
- מתפתח
- לְמַעֵט
- תמצית
- מהר יותר
- פחות
- שלח
- קבצים
- לסנן
- מסננים
- ראשון
- firsttime
- הבא
- בעד
- פוּרמָט
- התהוות
- בתדירות גבוהה
- החל מ-
- נתן
- כדור הארץ
- Go
- להעניק
- כמובן מאליו
- מדריך
- Hadoop
- יש
- he
- לעזור
- עוזר
- שֶׁלוֹ
- כוורת
- איך
- איך
- HTML
- HTTPS
- IAM
- if
- השלכות
- לשפר
- in
- כולל
- מצטבר
- מידע
- במקום
- לשלב
- השתלבות
- מִמְשָׁק
- אל תוך
- החדרה
- IT
- יפן
- jpg
- שמירה
- אגם
- אגמים
- האחרון
- לשגר
- לִלמוֹד
- למידה
- פחות
- להגביל
- קו
- רשימה
- ממוקם
- מיקום
- מקומות
- מחובר
- מכונה
- למידת מכונה
- שמירה
- לעשות
- עושה
- לנהל
- הצליח
- מנהל
- ניהול
- מדריך ל
- מקסימום
- מיזוג
- מידע נוסף
- נודד
- הֲגִירָה
- ML
- יותר
- רוב
- המהלך
- מספר
- שם
- יליד
- צורך
- נחוץ
- חדש
- חדש
- הבא
- עַכשָׁיו
- of
- on
- ONE
- רק
- לפתוח
- קוד פתוח
- אופטימיזציה
- אפשרות
- or
- אחר
- שלנו
- תפוקה
- חלק
- לוהט
- נתיב
- שבילים
- ביצועים
- רשות
- הרשאות
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- פופולרי
- מְאוּכלָס
- הודעה
- להכין
- תנאים מוקדמים
- קודם
- מחיר
- יְסוֹדִי
- מנהל
- תהליך
- המוצר
- מנהל מוצר
- מוצרים
- לספק
- ובלבד
- מספק
- שאילתות
- מהירות
- חומר עיוני
- ממשי
- זמן אמת
- זמן אמת
- לאחרונה
- שיא
- הירשם
- רשום
- להחליף
- דרישות
- משאבים
- אחראי
- לְהַגבִּיל
- כביש
- תפקיד
- שׁוּרָה
- הפעלה
- אותו
- לוח זמנים
- מתוכנן
- Sdk
- סעיף
- לבטח
- לִרְאוֹת
- בחר
- לחצני מצוקה לפנסיונרים
- ללא שרת
- שרות
- שירותים
- סט
- הגדרות
- הראה
- הופעות
- מפשט
- since
- יחיד
- פרוסה
- תמונת בזק
- So
- תוכנה
- פיתוח תוכנה
- מָקוֹר
- מקורות
- לעורר
- ספציפי
- התחלה
- מדינה
- שלב
- צעדים
- מאוחסן
- נהירה
- זרמים
- סטודיו
- בהצלחה
- כזה
- תמיכה
- נתמך
- סינכרון.
- מערכות
- שולחן
- נבחרת
- טכני
- טכנולוגיות
- זֶה
- השמיים
- שֶׁלָהֶם
- אז
- שם.
- הֵם
- זֶה
- שְׁלוֹשָׁה
- דרך
- זמן
- פִּי
- ל
- טוקיו
- חלק עליון
- טרנזקציות
- עסקות
- לתרגם
- לַחֲצוֹת
- להפעיל
- מופעל
- הדרכה
- שתיים
- סוגים
- טיפוסי
- תחת
- לא רצוי
- עדכון
- מְעוּדכָּן
- עדכונים
- להשתמש
- במקרה להשתמש
- מְשׁוּמָשׁ
- משתמש
- משתמשים
- שימושים
- באמצעות
- לְאַמֵת
- תוקף
- ערכים
- גרסה
- חזותי
- מחסן
- we
- אינטרנט
- שירותי אינטרנט
- טוֹב
- מתי
- אשר
- בזמן
- מי
- יצטרך
- עם
- לְלֹא
- תיק עבודות
- עובד
- לכתוב
- כתוב
- אתה
- עצמך
- זפירנט