מבוא
האיחוד של בינה מלאכותית (AI) ואמנות חושפות אפיקים חדשים באמנות דיגיטלית יצירתית, באופן בולט באמצעות מודלים של דיפוזיה. מודלים אלה בולטים בדור אמנות הבינה המלאכותית היצירתית, ומציעים גישה שונה מרשתות עצביות קונבנציונליות. מאמר זה לוקח אותך למסע חקרני אל עומקם של דגמי דיפוזיה, ומבהיר את המנגנון הייחודי שלהם ביצירת יצירות אמנות מדהימות ויזואלית ועשירות יצירתית. הבן את הניואנסים של מודלים של דיפוזיה וקבל תובנה לגבי תפקידם בהגדרה מחדש של ביטוי אמנותי דרך העדשה של טכנולוגיות AI מתקדמות.

מטרות למידה
- להבין את המושגים הבסיסיים של מודלים של דיפוזיה ב-AI.
- חקור את ההבחנה בין מודלים של דיפוזיה ורשתות עצביות מסורתיות ביצירת אמנות.
- נתח את תהליך יצירת האמנות באמצעות מודלים של דיפוזיה.
- הערך את ההשלכות היצירתיות והאסתטיות של AI באמנות דיגיטלית.
- דון בשיקולים האתיים ביצירות אמנות שנוצרו בינה מלאכותית.
מאמר זה פורסם כחלק מה- בלוגתון מדעי הנתונים.
תוכן העניינים
הבנת מודלים של דיפוזיה

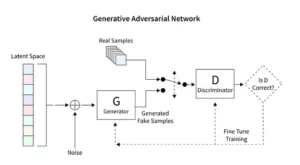
מודלים של דיפוזיה מחוללים מהפכה בינה מלאכותית גנרטיבית, ומציגים שיטת יצירת תמונה ייחודית הנבדלת מטכניקות קונבנציונליות כמו רשתות יריבות (GANs Generative Adversarial Networks). החל מרעש אקראי, מודלים אלה משכללים אותו בהדרגה, מזכירים אמן שמכוון ציור עדין, וכתוצאה מכך תמונות מורכבות וקוהרנטיות.
תהליך חידוד מצטבר זה משקף את האופי השיטתי של הדיפוזיה. כאן כל איטרציה משנה בעדינות את הרעש, מקרבת אותו לחזון האמנותי הסופי. הפלט הוא לא רק תוצר של אקראיות אלא יצירת אמנות מתפתחת, נבדלת בהתקדמותה ובגימור שלה.
קידוד עבור מודלים של דיפוזיה דורש הבנה עמוקה של רשתות עצביות ומסגרות למידת מכונה כגון TensorFlow או PyTorch. הקוד המתקבל מורכב, ודורש הכשרה מקיפה על מערכי נתונים רחבים כדי להשיג את ההשפעות הניואנסיות שנצפו באמנות שנוצרת בינה מלאכותית.
יישום של דיפוזיה יציבה באמנות
הופעתם של מחוללי אמנות בינה מלאכותית כמו דגמי דיפוזיה יציבים דורשת קידוד מתוחכם בתוך פלטפורמות כגון TensorFlow או PyTorch. מודלים אלה בולטים ביכולתם להפוך באופן שיטתי את האקראיות למבנה, בדומה לאמן שמחדד סקיצה ראשונית ליצירת מופת חיה.
מודלים של דיפוזיה יציבים מעצבים מחדש את סצנת האמנות בינה מלאכותית על ידי פיסול תמונות מסודרות מאקראיות, תוך הימנעות מהדינמיקה התחרותית האופיינית ל-GANs. הם מצטיינים בפירוש הנחיה רעיונית לאמנות חזותית, ומטפחים ריקוד סינרגטי בין יכולות AI וכושר ההמצאה האנושי. על ידי רתימת PyTorch, אנו מתבוננים כיצד המודלים הללו משכללים את הכאוס באופן איטרטיבי לבהירות, תוך שיקוף של מסעו של האמן מרעיון בהתהוות ליצירה מלוטשת.
ניסוי באמנות שנוצרת בינה מלאכותית
הדגמה זו מתעמקת בעולם המרתק של אמנות שנוצרת בינה מלאכותית באמצעות רשת נוירונים מפותלת הנקראת ConvDiffusionModel. דגם זה מאומן על דימויים אמנותיים מגוונים, הכוללים רישומים, ציורים, פסלים ותחריטים, כפי שמקורם ב מערך הנתונים של Kaggle הזה. המטרה שלנו היא לחקור את יכולתו של הדגם ללכוד ולשחזר את האסתטיקה המורכבת של יצירות אמנות אלו.
ארכיטקטורת מודל והדרכה
אדריכלות עיצוב
ConvDiffusionModel, בבסיסו, הוא פלא של הנדסה עצבית, הכולל ארכיטקטורת מקודדים-מפענחים מתוחכמת המותאמת לדרישות של יצירת אמנות. מבנה המודל הוא רשת עצבית מורכבת, המשלבת מנגנוני מקודד-מפענח מעודנים שחודזו במיוחד עבור ייצור אמנות. עם שכבות קונבולוציוניות נוספות וחיבורי דילוג המחקים אינטואיציה אמנותית, המודל יכול לנתח ולהרכיב מחדש אמנות עם הבנה משובחת של קומפוזיציה וסגנון.
- מקודד: המקודד הוא העין האנליטית של הדגם, הבוחנת את הפרטים הקטנים של כל תמונת קלט. כאשר תמונות עוברות דרך שכבות הפיתול של המקודד, הן נדחסות בהדרגה לחלל סמוי - ייצוג קומפקטי ומקודד של הגרפיקה המקורית. המקודד שלנו לא רק בודק תמונות קלט, אלא כעת עושה זאת עם עומק תפיסה מוגבר, באדיבות שכבות נוספות וטכניקות נורמליזציה של אצווה. בחינה מורחבת זו מאפשרת ייצוג עשיר ודחוס יותר בתוך המרחב הסמוי, המשקף את התבוננותו העמוקה של אמן בנושא.
- מפענח: לעומת זאת, המפענח משמש כיד יוצרת של הדוגמנית, לוקח את הסקיצות המופשטות מהמקודד ומפיח בהן חיים. הוא משחזר את יצירות האמנות מהחלל הסמוי, שכבה אחר שכבה, פרט אחר פרט, עד שמתגלה תמונה שלמה. המפענח שלנו מרוויח מחיבורי דילוג ויכול לשחזר יצירות אמנות בדיוק רב יותר. הוא בוחן מחדש את המהות המופשטת של הקלט ומייפה אותה בהדרגה, ומשיג ביצוע נאמן יותר לחומר המקור. השכבות המשופרות פועלות יחד כדי להבטיח שהתמונה הסופית תהיה יצירה חיה ומורכבת המשקפת את האומנות של הקלט.
תהליך הדרכה
ההכשרה של ConvDiffusionModel היא מסע בנוף אמנותי המשתרע על פני 150 תקופות. כל תקופה מייצגת מעבר שלם במערך הנתונים כולו, כאשר המודל שואף לחדד את הבנתו ולשפר את הנאמנות של התמונות שנוצרו.
- פונקציית אובדן היברידי: בלב האימון טמונה פונקציית אובדן השגיאה הממוצעת בריבוע (MSE). פונקציה זו מכמתת את ההבדל בין יצירת המופת המקורית לבין הבילוי של הדגם, ומספקת מדד ברור למזער. נציג רכיב אובדן תפיסתי הנגזר מרשת VGG מאומנת מראש המשלימה את מדד השגיאה הממוצעת בריבוע (MSE). אסטרטגיית אובדן כפול זו דוחפת את הדגם לכבד את היושרה האמנותית של המקור תוך שכלול השעתוק הטכני של הפרטים שלהם.
- מיטוב: עם קצב הלמידה שלו מותאם באופן דינמי על ידי מתזמן, האופטימיזציה של Adam מנחה את הלמידה של המודל בצורה מוגברת. גישה אדפטיבית זו מבטיחה שההתקדמות של המודל בלימוד לשכפל ולחדש אמנות היא יציבה וחזקה כאחד.
- איטרציה וחידוד: איטרציות ההכשרה הן ריקוד בין שימור המהות האמנותית לבין חתירה לשכפול טכני. עם כל מחזור, הדגם מתקרב יותר לסינתזה של נאמנות ויצירתיות.
- הדמיה של התקדמות: תמונות נשמרות במרווחי זמן קבועים במהלך האימון כדי לדמיין את התקדמות המודל. צילומי מצב אלה מציעים צוהר לעקומת הלמידה של המודל, ומציגות כיצד האמנות שנוצרה שלו מתפתחת, הופכת ברורה יותר, מפורטת יותר וקוהרנטית יותר מבחינה אמנותית עם כל תקופה.



האמור לעיל מודגם באמצעות קטע הקוד הבא:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')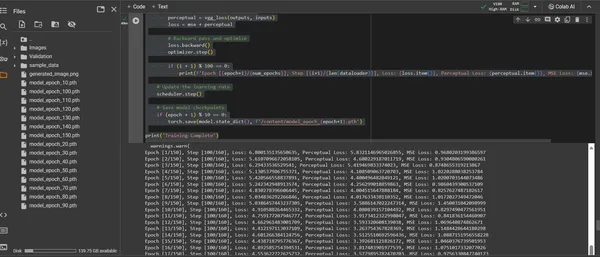
הדמיה של יצירות האמנות שנוצרו
מפגין אמנות בינה מלאכותית
עם ה-ConvDiffusionModel שעבר הכשרה מלאה, הפוקוס עובר מהמופשט לקונקרטי - מהפוטנציאל למימוש אמנות שנוצרה בינה מלאכותית. קטע הקוד שלאחר מכן מממש את היכולות האמנותיות הנלמדות של המודל, והופך את נתוני הקלט לקנבס דיגיטלי של ביטוי.
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()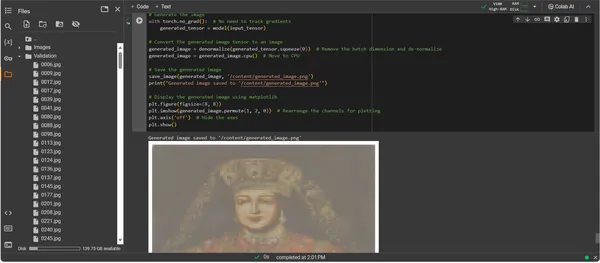

הדרכה על קוד דור יצירות אמנות
- דגם תחיית המתים: הצעד הראשון ביצירת יצירות האמנות הוא להחיות את ConvDiffusionModel המיומן שלנו. המשקולות הנלמדות של המודל נטענות ומובאות למצב הערכה, מה שמציב את הבמה ליצירה מבלי לשנות עוד את הפרמטרים שלו.
- שינוי תמונה: כדי להבטיח עקביות עם משטר האימון, תמונות קלט מעובדות באמצעות אותו רצף של טרנספורמציות. זה כולל שינוי גודל כדי להתאים לממדי הקלט של המודל, המרת טנזור עבור תאימות PyTorch ונורמליזציה על סמך הפרופיל הסטטיסטי של נתוני האימון.
- כלי עזר לדה-נורמליזציה: פונקציה מותאמת אישית הופכת את אפקטי העיבוד המקדים, ומרחיבה מחדש את הטנזור לטווח הצבעים של התמונה המקורית. שלב זה חיוני לעיבוד הפלט שנוצר לייצוג מדויק מבחינה ויזואלית.
- הכנת קלט: תמונה נטענת ונתונה לתמורות האמורות. חשוב לציין שהתמונה הזו משמשת כמוזה שממנה ה-AI ישאב השראה - הלחישה השקטה מציתה את הדמיון הסינתטי של הדוגמנית.
- סינתזת יצירות אמנות: בריקוד עדין של התפשטות קדימה, המודל מפרש את טנזור הקלט, ומאפשר לשכבות שלו לשתף פעולה בהפקת חזון אמנותי חדש. בצע את התהליך הזה מבלי לעקוב אחר שיפועים, מכיוון שאנו נמצאים כעת בתחום היישום, לא ההדרכה.
- המרת תמונה: פלט הטנזור של המודל, שמחזיק כעת את יצירות האמנות שנולדו באופן דיגיטלי, מנותק, ומתרגם את יצירת המודל בחזרה למרחב המוכר של צבע ואור שעינינו יכולות להעריך.
- התגלות יצירות אמנות: הטנזור שעבר טרנספורמציה מונח על קנבס דיגיטלי, ומגיע לשיאו בקובץ תמונה שמור. הקובץ הזה הוא צוהר לנשמה היצירתית של הבינה המלאכותית, הד סטטי של התהליך הדינמי שהעניק לו חיים.
- אחזור יצירות אמנות: התסריט מסתיים בשמירת התמונה שנוצרה בנתיב ייעודי והכרזה על השלמתו. התמונה שנשמרה, סינתזה של עקרונות אמנותיים נלמדים ויצירתיות מתהווה, מוכנה לתצוגה ולהתבוננות.
ניתוח הפלט
הפלט של ConvDiffusionModel מציג דמות עם קריצה ברורה לאמנות היסטורית. עטופה בלבוש משוכלל, התמונה המעובדת בינה מלאכותית מהדהדת את הפאר של הפורטרטים הקלאסיים אך עם מגע מודרני ומודרני. הלבוש של הנושא עשיר במרקם, המשלב את הדפוסים הנלמדים של הדגם עם פרשנות חדשה. תווי פנים עדינים ומשחק גומלין עדין של אור וצל מציגים את ההבנה הניואנסית של הבינה המלאכותית של טכניקות אמנות מסורתיות. יצירות אמנות זו היא עדות להכשרה המתוחכמת של הדגם, המשקפת סינתזה אלגנטית של אמנות היסטורית דרך הפריזמה של למידת מכונה מתקדמת. במהותו, זהו הומאז' דיגיטלי לעבר, מעוצב עם האלגוריתמים של ההווה.
אתגרים ושיקולים אתיים
יישום מודלים של דיפוזיה ליצירת אמנות מביא איתו מספר אתגרים ושיקולים אתיים שכדאי לשקול:
- מקור נתונים: יש לאסוף את מערכי הנתונים של ההדרכה בצורה אחראית. חשוב לוודא שהנתונים המשמשים לאימון מודלים של דיפוזיה אינם מכילים יצירות המוגנות בזכויות יוצרים או מוגנות ללא אישור מתאים.
- הטיה וייצוג: מודלים של AI יכולים להנציח הטיות בנתוני האימון שלהם. הבטחת מערכי נתונים מגוונים ומכילים חשובה כדי להימנע מחיזוק סטריאוטיפים באמנות שנוצרת בינה מלאכותית.
- שליטה על הפלט: מכיוון שמודלים של דיפוזיה יכולים לייצר מגוון רחב של תפוקות, יש צורך בהצבת גבולות למניעת יצירת תוכן לא הולם או פוגעני.
- מסגרת משפטית: היעדר מסגרת משפטית איתנה לטיפול בניואנסים של AI בתהליך היצירתי מהווה אתגר. החקיקה צריכה להתפתח כדי להגן על הזכויות של כל הצדדים המעורבים.
סיכום
עלייתם של מודלים של דיפוזיה ב-AI ובאמנות מסמנת עידן טרנספורמטיבי, הממזג דיוק חישובי עם חקר אסתטי. המסע שלהם בעולם האמנות מדגיש פוטנציאל חדשנות משמעותי אבל מגיע עם מורכבויות. איזון בין מקוריות, השפעה, יצירה אתית וכבוד ליצירות קיימות הוא חלק בלתי נפרד מהתהליך האמנותי.
המנות העיקריות
- מודלים של דיפוזיה נמצאים בחזית של שינוי טרנספורמטיבי ביצירת אמנות. הם מציעים כלים דיגיטליים חדשים המרחיבים את היריעה של הביטוי האמנותי מעבר לגבולות המסורתיים.
- באמנות המשופרת בינה מלאכותית, מתן עדיפות לאיסוף אתי של נתוני הכשרה וכיבוד הקניין הרוחני של היוצרים הוא הכרחי כדי לשמור על שלמות באמנות דיגיטלית.
- ההתכנסות של חזון אמנותי וחדשנות טכנולוגית פותחת דלתות ליחסים סימביוטיים בין אמנים ומפתחי בינה מלאכותית. לטפח סביבה שיתופית שיכולה להוליד אמנות פורצת דרך.
- הבטחה שאמנות שנוצרת בינה מלאכותית מייצגת קשת רחבה של פרספקטיבות היא חיונית. שלבו מגוון רחב של נתונים המשקפים את העושר של תרבויות ונקודות מבט שונות, ובכך לקדם את ההכללה.
- העניין הגובר באמנות שיוצרה בינה מלאכותית מחייב הקמת מסגרות משפטיות חזקות. מסגרות אלה צריכות להבהיר סוגיות של זכויות יוצרים, להכיר בתרומות ולשלוט בשימוש המסחרי ביצירות אמנות שנוצרו בינה מלאכותית.
השחר של האבולוציה האמנותית הזו מציע נתיב שופע פוטנציאל יצירתי אך מצריך אפוטרופסות מודעת. מוטלת עלינו החובה לטפח נוף שבו השילוב של בינה מלאכותית ואמנות משגשגת, מונחית על ידי פרקטיקות אחראיות ורגישות תרבותית.
שאלות נפוצות
א. מודלים של דיפוזיה הם אלגוריתמי ML גנרטיביים היוצרים תמונות על ידי התחלה עם דפוס של רעש אקראי ועיצוב הדרגתי לתמונה קוהרנטית. תהליך זה דומה לאמן שמתחיל עם קנבס ריק ומוסיף לאט לאט שכבות של פרטים.
ת. GANs, מודלים של דיפוזיה אינם דורשים רשת נפרדת כדי לשפוט את הפלט. הם פועלים על ידי הוספה והסרה של רעשים באופן איטרטיבי, ולעתים קרובות מביאים לתמונות מפורטות וניואנסיות יותר.
ת. כן, מודלים של דיפוזיה יכולים ליצור יצירות אמנות מקוריות על ידי למידה ממערך נתונים של תמונות. עם זאת, המקוריות מושפעת מהמגוון ומההיקף של נתוני ההכשרה. קיים ויכוח מתמשך לגבי האתיקה של שימוש ביצירות אמנות קיימות כדי להכשיר את המודלים הללו.
א. דאגות אתיות כוללות הימנעות מהפרת זכויות יוצרים של אמנות שנוצרה על ידי בינה מלאכותית. כיבוד מקוריותם של אמנים אנושיים, מניעת הנצחה של הטיה והבטחת שקיפות בתהליך היצירה של AI.
ת. העתיד של אמנות שנוצרת בינה מלאכותית נראה מבטיח, עם מודלים של דיפוזיה המציעים כלים חדשים לאמנים וליוצרים. אנו יכולים לצפות לראות יצירות אמנות מתוחכמות ומורכבות יותר ככל שהטכנולוגיה מתקדמת. עם זאת, הקהילה היצירתית חייבת לנווט שיקולים אתיים ולפעול להנחיות ברורות ושיטות עבודה מומלצות.
המדיה המוצגת במאמר זה אינה בבעלות Analytics Vidhya והיא משמשת לפי שיקול דעתו של המחבר.
מוצרים מקושרים
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- :הוא
- :לֹא
- :איפה
- 001
- 1
- 10
- 100
- 11
- 12
- 15%
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- יכולת
- אודות
- מֵעַל
- תקציר
- מדויק
- להשיג
- השגתי
- אדם
- הסתגלות
- מוסיף
- נוסף
- כתובת
- מותאם
- מתקדם
- התקדמות
- הִתגַלוּת
- -
- AI
- איי אמנות
- דומה
- אלגוריתמים
- תעשיות
- מאפשר
- מאפשר
- an
- אנליטית
- ניתוח
- אנליטיקה וידיה
- ו
- מכריז
- בקשה
- להעריך
- גישה
- ארכיטקטורה
- ARE
- אמנות
- מאמר
- אמן
- אמנותי
- בְּאֹפֶן אָמָנוּתִי
- אמנות
- אמנים
- יצירות אמנות
- יצירות אמנות
- AS
- At
- מוגבר
- אישור
- זמין
- שדרות
- לְהִמָנַע
- הימנעות
- AXES
- בחזרה
- רע
- איזון
- מבוסס
- BE
- התהוות
- הטבות
- הטוב ביותר
- שיטות עבודה מומלצות
- בֵּין
- מעבר
- הטיה
- הטיות
- ריק
- הִתמַזְגוּת
- בלוגתון
- נולד
- שניהם
- גבולות
- נשימה
- שופע
- מביא
- רחב
- מובא
- מתפתחת
- אבל
- by
- לחשב
- נקרא
- CAN
- בד
- יכולות
- יכולת
- ללכוד
- לאתגר
- האתגרים
- ערוצים
- תוהו ובוהו
- מאפיין
- לבדוק
- בדיקה
- מַהְדֵק
- בהירות
- בכיתה
- ברור
- יותר ברור
- קרוב יותר
- קוד
- סִמוּל
- קוהרנטי
- לשתף פעולה
- שיתוף פעולה
- צֶבַע
- מגיע
- מסחרי
- קהילה
- קומפקטי
- תאימות
- תחרותי
- להשלים
- השלמה
- מורכב
- מורכבות
- רְכִיב
- הרכב
- חישובית
- לחשב
- מושגים
- רעיוני
- דאגות
- קונצרט
- מסכם
- חיבורי
- לשקול
- שיקולים
- להכיל
- תוכן
- לעומת זאת
- תרומות
- מקובל
- התכנסות
- המרה
- המרת
- רשת עצבית convolutional
- זכויות יוצרים
- הפרת זכויות יוצרים
- ליבה
- מושחת
- CPU
- מעוצב
- לִיצוֹר
- יוצרים
- יצירה
- יְצִירָתִי
- באופן יצירתי
- יצירתיות
- יוצרים
- מכריע
- בשיאה
- לטפח
- מבחינה תרבותית
- אוצר
- זונה
- מנהג
- מחזור
- לִרְקוֹד
- נתונים
- מערכי נתונים
- דיון
- עמוק
- הגדרה
- דרישות
- מופגן
- עומק
- עומקים
- נגזר
- יעוד
- פרט
- מְפוֹרָט
- פרטים
- מפתחים
- מכשיר
- נבדלים
- הבדל
- אחר
- שידור
- דיגיטלי
- אמנות דיגיטלית
- באופן דיגיטלי
- מֵמַד
- ממדים
- שיקול דעת
- לְהַצִיג
- מציג
- מובהק
- הבחנה
- שונה
- גיוון
- do
- עושה
- דלתות
- לצייר
- ציורים
- בְּמַהֲלָך
- דינמי
- באופן דינמי
- דינמיקה
- e
- כל אחד
- הד
- הדים
- תופעות
- משוכלל
- אחר
- מתגלה
- מוצפן
- להקיף
- מקיף
- הנדסה
- משופר
- לְהַבטִיחַ
- מבטיח
- הבטחתי
- שלם
- סביבה
- תקופה
- תקופות
- תקופה
- שגיאה
- מַהוּת
- חיוני
- הקמה
- Ether (ETH)
- אֶתִי
- אתיקה
- הערכה
- כל
- אבולוציה
- להתפתח
- התפתח
- מתפתח
- בדיקה
- Excel
- אלא
- קיימים
- לְהַרְחִיב
- נרחב
- לצפות
- חקירה
- לחקור
- ביטוי
- מוּרחָב
- נרחב
- עין
- עיניים
- פנים
- נאמן
- שקר
- מוכר
- מקסים
- תכונות
- משתתפים
- דיוק
- תרשים
- שלח
- קבצים
- סופי
- גימור
- ראשון
- להתמקד
- הבא
- בעד
- בחזית
- קדימה
- לטפח
- טיפוח
- מסגרת
- מסגרות
- החל מ-
- לגמרי
- פונקציה
- פונקציונלי
- יסודי
- נוסף
- היתוך
- עתיד
- לְהַשִׂיג
- GANs
- איסוף
- נתן
- ליצור
- נוצר
- יצירת
- דור
- גנרטטיבית
- רשתות אדפרסיביות גנרטיביות
- AI Generative
- גנרטורים
- לתת
- מטרה
- GPU
- שיפועים
- בהדרגה
- פְּאֵר
- לתפוס
- יותר
- פורץ דרך
- מוּדרָך
- הנחיות
- מדריך
- יד
- רתימה
- לֵב
- כאן
- הסתר
- פסים
- היסטורי
- מחזיק
- מחווה
- כבוד
- איך
- אולם
- HTTPS
- בן אנוש
- i
- רעיון
- if
- מתלקח
- תמונה
- תמונות
- דִמיוֹן
- הֶכְרֵחִי
- יישום
- השלכות
- לייבא
- חשוב
- לשפר
- in
- כולל
- כולל
- הכלילות
- בע"מ
- גדל
- מצטבר
- מוּטָל
- להשפיע
- מוּשׁפָע
- הפרה
- שְׁנִינוּת
- לחדש
- חדשנות
- קלט
- תשומות
- תובנה
- אינטגרלי
- שילוב
- שלמות
- אִינטֶלֶקְטוּאַלִי
- קניין רוחני
- אינטרס
- פענוח
- אל תוך
- מוּרכָּב
- מבוא
- אינטואיציה
- מעורב
- בעיות
- IT
- איטרציה
- איטרציות
- שֶׁלָה
- מסע
- jpg
- שופט
- חוסר
- נוף
- שכבה
- שכבות
- למד
- למידה
- משפטי
- מסגרת משפטית
- חֲקִיקָה
- Lens
- שקרים
- החיים
- אוֹר
- כמו
- טוען
- נראה
- את
- אבדות
- מכונה
- למידת מכונה
- לתחזק
- פֶּלֶא
- יצירת מופת
- להתאים
- חוֹמֶר
- matplotlib
- אומר
- מנגנון
- מנגנוני
- מדיה
- רק
- מיזוג
- שיטה
- שיטתית
- מטרי
- לצמצם
- דקה
- שיקוף
- ML
- אלגוריתמים של ML
- מצב
- מודל
- מודלים
- מודרני
- מודול
- יותר
- המהלך
- הרבה
- מוזה
- צריך
- שמות
- המתהווה
- טבע
- נווט
- הכרחי
- צרכי
- רשת
- רשתות
- עצביים
- הנדסה עצבית
- רשת עצבית
- רשתות עצביות
- חדש
- רעש
- הערות
- רומן
- עַכשָׁיו
- ניואנסים
- להתבונן
- שנצפה
- of
- כבוי
- מתקפה
- הַצָעָה
- הצעה
- המיוחדות שלנו
- לעתים קרובות
- on
- מתמשך
- רק
- נפתח
- מטב
- or
- מְקוֹרִי
- מְקוֹרִיוּת
- מקוריים
- OS
- אחר
- שלנו
- הַחוּצָה
- תפוקה
- פלטים
- יותר
- בבעלות
- ציור
- ציורים
- פרמטר
- פרמטרים
- חלק
- צדדים
- לעבור
- עבר
- נתיב
- תבנית
- דפוסי
- תפיסה
- מושלם
- לבצע
- נקודות מבט
- תמונה
- לְחַבֵּר
- חתיכות
- פלטפורמות
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- פורטרטים
- פוטנציאל
- פרקטיקות
- דיוק
- מקדים
- להציג
- מתנות
- מִשׁמֶרֶת
- למנוע
- מניעה
- עקרונות
- הדפסה
- סדר עדיפויות
- תהליך
- מעובד
- הפקת
- המוצר
- פּרוֹפִיל
- עמוק
- התקדמות
- התקדמות
- בהדרגה
- מבטיח
- קידום
- הנחיות
- התפשטות
- תָקִין
- רכוש
- להגן
- מוּגָן
- מוֹצָא
- מתן
- לאור
- רודף
- פיטורך
- מכמת
- אקראי
- אקראי
- רכס
- ציון
- מוכן
- תחום
- להכיר
- הגדרה מחודשת
- לחדד
- מעודן
- משקף
- משקף
- משטר
- רגיל
- קשר
- הסרת
- טיוח
- שכפול
- נציגות
- מייצג
- שעתוק
- לדרוש
- דורש
- דומה
- לעצב מחדש
- כבוד
- כיבוד
- אחראי
- באחריות
- וכתוצאה מכך
- לַחֲזוֹר
- הִתגַלוּת
- להחיות
- לְחוֹלֵל מַהְפֵּכָה
- RGB
- עשיר
- זכויות
- לעלות
- חָסוֹן
- תפקיד
- אותו
- הציל
- חסכת
- סצינה
- מדע
- היקף
- תסריט
- לִרְאוֹת
- עצמי
- רגיש
- נפרד
- רצף
- משמש
- סט
- הצבה
- התקנה
- כמה
- Shadow
- מעצבים
- משמרת
- משמרות
- צריך
- ראווה
- לראווה
- הראה
- משמעותי
- since
- לאט
- קטע
- So
- מתוחכם
- נֶפֶשׁ
- מָקוֹר
- מקור
- מֶרחָב
- מתח
- במיוחד
- ספֵּקטרוּם
- מרובע
- יציב
- התמחות
- לעמוד
- החל
- סטטיסטי
- יציב
- שלב
- אִסטרָטֶגִיָה
- שאיפה
- מִבְנֶה
- מדהים
- סגנון
- נושא
- לאחר מכן
- כזה
- סימביוטי
- סינרגיסטית
- סינתזה
- סינטטי
- מותאם
- לוקח
- נטילת
- יעד
- טכני
- טכניקות
- טכנולוגי
- טכנולוגיות
- טכנולוגיה
- tensorflow
- ברית
- זֶה
- השמיים
- העתיד
- המקור
- שֶׁלָהֶם
- אותם
- שם.
- אלה
- הֵם
- זֶה
- משגשג
- דרך
- כָּך
- ל
- כלים
- לפיד
- חזון לפיד
- לגעת
- לקראת
- מעקב
- מסורתי
- רכבת
- מְאוּמָן
- הדרכה
- לשנות
- טרנספורמציה
- טרנספורמציות
- טרנספורמטיבית
- טרנספורמציה
- הפיכה
- התמרות
- שקיפות
- נָכוֹן
- לנסות
- להבין
- הבנה
- ייחודי
- עד
- חושף
- עדכון
- על
- us
- להשתמש
- מְשׁוּמָשׁ
- באמצעות
- תועלת
- תקף
- אימות
- באמצעות
- צפייה
- נקודות מבט
- חזון
- חזותי
- אמנות ויזואלית
- ראיה
- לחזות
- מבחינה ויזואלית
- חיוני
- היה
- we
- webp
- מה
- מה
- אשר
- בזמן
- Whisper
- מי
- רָחָב
- טווח רחב
- יצטרך
- חלון
- עם
- בתוך
- לְלֹא
- תיק עבודות
- עובד
- עוֹלָם
- X
- כן
- עוד
- אתה
- זפירנט
- אפס