במאמר זה נלמד כיצד לפרוס ולהשתמש במודל GPT4All במחשב המעבד בלבד (אני משתמש ב-a Macbook Pro ללא GPU!)

השתמש ב-GPT4All במחשב שלך - תמונה מאת המחבר
במאמר זה אנו הולכים להתקין במחשב המקומי שלנו GPT4All (LLM רב עוצמה) ונגלה כיצד לקיים אינטראקציה עם המסמכים שלנו עם python. אוסף של קובצי PDF או מאמרים מקוונים יהווה בסיס הידע לשאלות/תשובות שלנו.
מ האתר הרשמי GPT4All זה מתואר כ צ'אטבוט חינמי לשימוש הפועל באופן מקומי ומודע לפרטיות. אין צורך במעבד גרפי או אינטרנט.
GTP4All היא מערכת אקולוגית לאימון ופריסה חזק ו אישית מודלים שפה גדולים שפועלים באופן מקומי על מעבדים בדרגת צרכנים.
דגם ה-GPT4All שלנו הוא קובץ בנפח 4GB שתוכל להוריד ולחבר לתוכנת הקוד הפתוח של GPT4All. בינה מלאכותית נומית מאפשרת מערכות אקולוגיות איכותיות ומאובטחות של תוכנה, ומניעה את המאמץ לאפשר לאנשים וארגונים להכשיר וליישם ללא מאמץ מודלים שפה גדולים משלהם באופן מקומי.
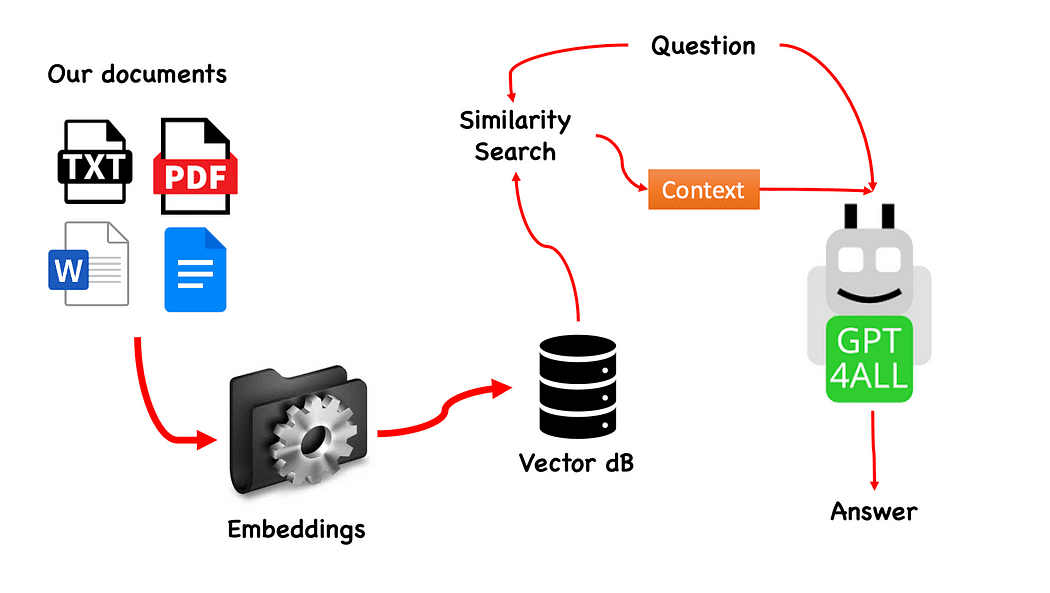
זרימת עבודה של ה-QnA עם GPT4All - נוצר על ידי המחבר
התהליך הוא ממש פשוט (כשאתה יודע את זה) וניתן לחזור עליו גם עם דגמים אחרים. השלבים הם כדלקמן:
- טען את דגם GPT4All
- להשתמש לנגצ'יין כדי לאחזר את המסמכים שלנו ולטעון אותם
- לפצל את המסמכים לנתחים קטנים הניתנים לעיכול על ידי Embeddings
- השתמש ב-FAISS כדי ליצור את מסד הנתונים הווקטוריים שלנו עם ההטמעות
- בצע חיפוש דמיון (חיפוש סמנטי) במסד הנתונים הווקטוריים שלנו בהתבסס על השאלה שאנו רוצים להעביר ל-GPT4All: זה ישמש בתור הקשר לשאלתנו
- הזן את השאלה ואת ההקשר ל-GPT4All עם לנגצ'יין ומחכה לתשובה.
אז מה שאנחנו צריכים זה Embeddings. הטבעה היא ייצוג מספרי של פיסת מידע, למשל, טקסט, מסמכים, תמונות, אודיו וכו'. הייצוג לוכד את המשמעות הסמנטית של מה שמוטבע, וזה בדיוק מה שאנחנו צריכים. עבור פרויקט זה איננו יכולים להסתמך על דגמי GPU כבדים: אז נוריד את המודל המקורי של Alpaca ונשתמש ב- לנגצ'יין מה היא LlamaCppEmbeddings. אל תדאג! הכל מוסבר שלב אחר שלב
צור סביבה וירטואלית
צור תיקיה חדשה עבור פרויקט Python החדש שלך, למשל GPT4ALL_Fabio (שים את שמך...):
mkdir GPT4ALL_Fabio
cd GPT4ALL_Fabioלאחר מכן, צור סביבה וירטואלית חדשה של Python. אם מותקנת אצלך יותר מגרסת פיתון אחת, ציין את הגירסה הרצויה לך: במקרה זה אשתמש בהתקנה הראשית שלי, המשויכת לפייתון 3.10.
python3 -m venv .venvהפקודה python3 -m venv .venv יוצר סביבה וירטואלית חדשה בשם .venv (הנקודה תיצור ספרייה נסתרת בשם venv).
סביבה וירטואלית מספקת התקנת Python מבודדת, המאפשרת לך להתקין חבילות ותלות רק עבור פרויקט ספציפי מבלי להשפיע על התקנת Python כלל המערכת או פרויקטים אחרים. בידוד זה עוזר לשמור על עקביות ולמנוע התנגשויות פוטנציאליות בין דרישות פרויקט שונות.
לאחר יצירת הסביבה הוירטואלית, תוכל להפעיל אותה באמצעות הפקודה הבאה:
source .venv/bin/activate 
סביבה וירטואלית מופעלת
הספריות להתקנה
בשביל הפרויקט שאנחנו בונים אנחנו לא צריכים יותר מדי חבילות. אנחנו צריכים רק:
- כריכות פיתון עבור GPT4All
- Langchain לאינטראקציה עם המסמכים שלנו
LangChain היא מסגרת לפיתוח יישומים המופעלים על ידי מודלים של שפה. זה מאפשר לך לא רק לקרוא למודל שפה באמצעות API, אלא גם לחבר מודל שפה למקורות נתונים אחרים ולאפשר למודל שפה ליצור אינטראקציה עם הסביבה שלו.
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4עבור LangChain אתה רואה שציינו גם את הגרסה. הספרייה הזו מקבלת הרבה עדכונים לאחרונה, אז כדי להיות בטוח שההגדרה שלנו תעבוד גם מחר, עדיף לציין גרסה שאנחנו יודעים שהיא עובדת בסדר. לא מובנה היא תלות נדרשת עבור טוען PDF ו pytesseract ו pdf2 תמונה גם כן.
הערה: במאגר GitHub יש קובץ requirements.txt (מוצע על ידי jl adcr) עם כל הגרסאות המשויכות לפרויקט זה. אתה יכול לבצע את ההתקנה במכה אחת, לאחר הורדתה לספריית קבצי הפרויקט הראשית עם הפקודה הבאה:
pip install -r requirements.txtבסוף המאמר יצרתי א סעיף לפתרון הבעיות. לריפו של GitHub יש גם READ.ME מעודכן עם כל המידע הזה.
זכור כי חלק לספריות יש גרסאות זמינות בהתאם לגרסת הפיתון אתה פועל על הסביבה הוירטואלית שלך.
הורד למחשב שלך את הדגמים
זה שלב ממש חשוב.
עבור הפרויקט אנחנו בהחלט צריכים GPT4All. התהליך המתואר ב-Nomic AI הוא ממש מסובך ודורש חומרה שלא לכולנו יש (כמוני). כך הנה הקישור לדגם כבר הומר ומוכן לשימוש. פשוט לחץ על הורדה.
הורד את דגם GPT4All
כפי שתואר בקצרה בהקדמה אנחנו צריכים גם את המודל של ההטמעות, מודל שנוכל להריץ על המעבד שלנו בלי לרסק. לחץ על קישור כאן להורדת ה-alpaca-native-7B-ggml כבר הומר ל-4 סיביות ומוכן לשימוש כדי לשמש כמודל שלנו להטמעה.

לחץ על חץ ההורדה שליד ggml-model-q4_0.bin
למה אנחנו צריכים הטמעות? אם אתה זוכר מתרשים הזרימה, השלב הראשון הנדרש, לאחר שנאסף את המסמכים למאגר הידע שלנו, הוא לעשות שבץ אוֹתָם. הטבעות LLamaCPP מדגם Alpaca זה מתאימות לעבודה בצורה מושלמת וגם הדגם הזה די קטן (4 ג'יגה-בייט). אגב אתה יכול להשתמש גם בדגם Alpaca עבור ה-QnA שלך!
עדכון 2023.05.25: משתמשי Mani Windows מתמודדים עם בעיות בשימוש בהטמעות llamaCPP. זה קורה בעיקר בגלל שבמהלך ההתקנה של חבילת python llama-cpp-python עם:
pip install llama-cpp-pythonחבילת pip הולכת לקמפל מהמקור את הספרייה. ב-Windows בדרך כלל אין CMake או מהדר C מותקן כברירת מחדל במחשב. אבל אל תיזהרו יש פתרון
הפעלת ההתקנה של llama-cpp-python, הנדרשת על ידי LangChain עם llamaEmbeddings, ב-Windows CMake C complier אינה מותקנת כברירת מחדל, כך שלא ניתן לבנות ממקור.
במשתמשי Mac עם Xtools וב-Linux, בדרך כלל תואם C כבר זמין במערכת ההפעלה.
כדי להימנע מהבעיה אתה חייב להשתמש בגלגל מותאם מראש.
עבור כאן https://github.com/abetlen/llama-cpp-python/releases
וחפש את הגלגל המתאים עבור גרסת הארכיטקטורה והפיתון שלך - אתה חייב לקחת את ווילס גרסה 0.1.49 כי גרסאות גבוהות יותר אינן תואמות.
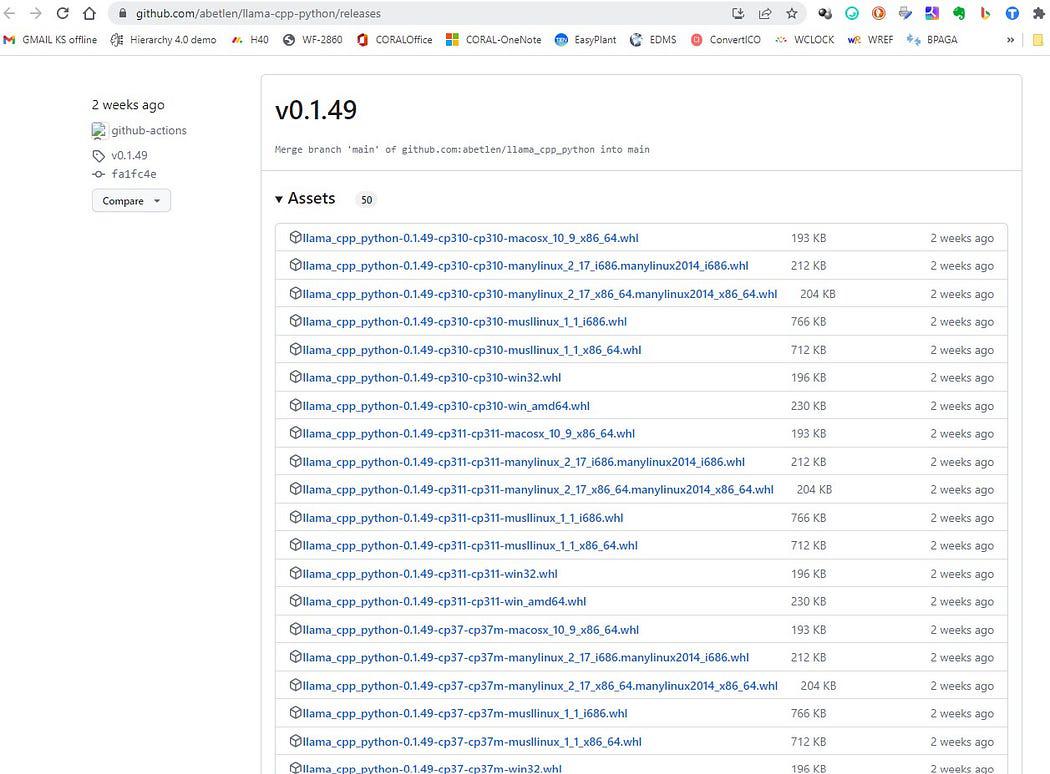
צילום מסך מ https://github.com/abetlen/llama-cpp-python/releases
במקרה שלי יש לי ווינדוס 10, 64 סיביות, פיתון 3.10
אז הקובץ שלי הוא llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
זֶה הבעיה נמצאת במעקב במאגר GitHub
לאחר ההורדה עליך לשים את שני הדגמים בספריית הדגמים, כפי שמוצג להלן.

מבנה ספריות והיכן לשים את קבצי הדגם
מכיוון שאנו רוצים לקבל שליטה על האינטראקציה שלנו במודל ה-GPT, עלינו ליצור קובץ פיתון (בואו נקרא לזה pygpt4all_test.py), לייבא את התלות ולתת את ההוראה למודל. אתה תראה שזה די קל.
from pygpt4all.models.gpt4all import GPT4Allזהו כריכת הפיתון עבור הדגם שלנו. עכשיו אנחנו יכולים להתקשר אליו ולהתחיל לשאול. בואו ננסה אחד יצירתי.
אנו יוצרים פונקציה שקוראת את ההתקשרות חזרה מהמודל, ואנו מבקשים מ-GPT4All להשלים את המשפט שלנו.
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)ההצהרה הראשונה אומרת לתוכנית שלנו היכן למצוא את הדגם (זכור מה עשינו בסעיף למעלה)
ההצהרה השנייה היא מבקשת מהמודל ליצור תגובה ולהשלים את ההנחיה שלנו "היה פעם".
כדי להפעיל אותו, ודא שהסביבה הוירטואלית עדיין מופעלת ופשוט הפעל:
python3 pygpt4all_test.pyאתה צריך לראות טקסט טעינה של הדגם ואת השלמת המשפט. בהתאם למשאבי החומרה שלך זה עשוי לקחת מעט זמן.
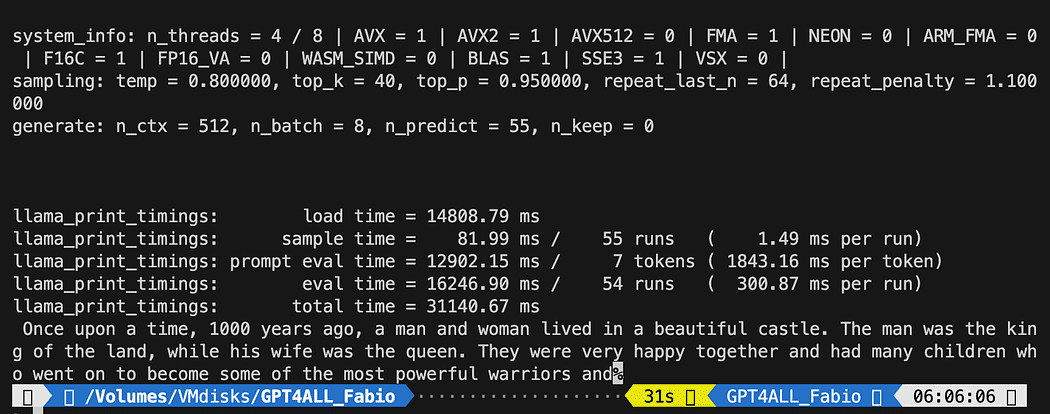
התוצאה עשויה להיות שונה משלך... אבל עבורנו החשוב הוא שזה עובד ונוכל להמשיך עם LangChain כדי ליצור כמה דברים מתקדמים.
הערה (עודכן ב-2023.05.23): אם אתה נתקל בשגיאה הקשורה ל-pygpt4all, בדוק את סעיף פתרון הבעיות בנושא זה עם הפתרון שניתן על ידי ראג'ניש אגרוואל or מאת אוסקר ג'ונג.
מסגרת LangChain היא ספרייה מדהימה באמת. זה מספק רכיבי לעבוד עם מודלים של שפה בצורה קלה לשימוש, וזה גם מספק רשתות. ניתן לחשוב על שרשראות כמרכיבות את הרכיבים הללו בדרכים מסוימות על מנת להגשים בצורה הטובה ביותר מקרה שימוש מסוים. אלה נועדו להיות ממשק ברמה גבוהה יותר שדרכו אנשים יכולים להתחיל בקלות עם מקרה שימוש ספציפי. רשתות אלו נועדו גם להתאמה אישית.
במבחן הפיתון הבא שלנו נשתמש ב- a תבנית בקשה. מודלים של שפה לוקחים טקסט כקלט - טקסט זה מכונה בדרך כלל הנחיה. בדרך כלל זו אינה רק מחרוזת מקודדת קשה אלא שילוב של תבנית, כמה דוגמאות וקלט משתמש. LangChain מספקת מספר מחלקות ופונקציות כדי להקל על בנייה ועבודה עם הנחיות. בואו נראה איך גם אנחנו יכולים לעשות את זה.
צור קובץ פיתון חדש וקרא לו my_langchain.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])ייבאנו מ-LangChain את ה-Prompt Template and Chain ו-GPT4All lm class כדי להיות מסוגל ליצור אינטראקציה ישירה עם מודל ה-GPT שלנו.
לאחר מכן, לאחר הגדרת נתיב ה-llm שלנו (כפי שעשינו קודם), אנו מייצרים את מנהלי ההתקשרות חזרה כך שנוכל לתפוס את התגובות לשאילתה שלנו.
ליצור תבנית זה ממש קל: בצע את הדרכה לתיעוד אנחנו יכולים להשתמש במשהו כזה…
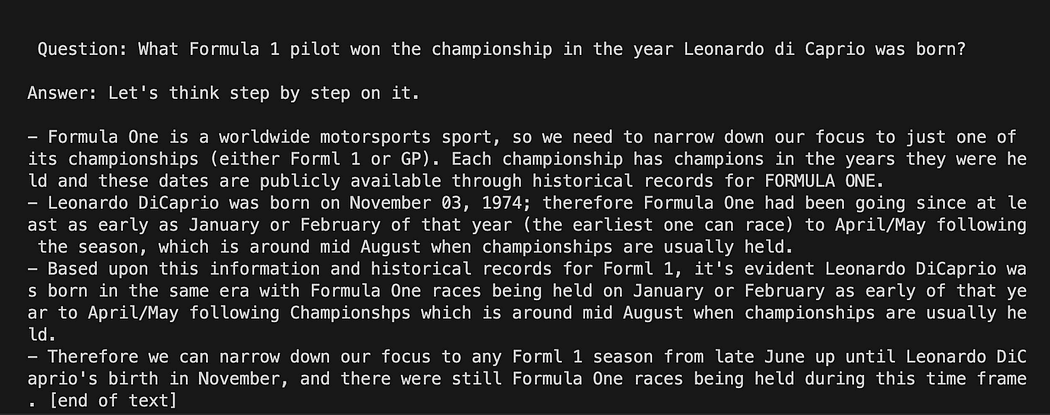
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])השמיים תבנית משתנה הוא מחרוזת מרובת שורות המכילה את מבנה האינטראקציה שלנו עם המודל: בסוגרים מסולסלים אנו מכניסים את המשתנים החיצוניים לתבנית, בתרחיש שלנו הוא שלנו שאלה.
מכיוון שזה משתנה אתה יכול להחליט אם זו שאלה מקודדת או שאלת קלט משתמש: הנה שתי הדוגמאות.
# Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")עבור הפעלת המבחן שלנו נגיב למשתמש קלט אחד. כעת נותר רק לקשר את התבנית שלנו, השאלה ומודל השפה.
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)זכור לוודא שהסביבה הוירטואלית שלך עדיין מופעלת והפעל את הפקודה:
python3 my_langchain.pyייתכן שתקבל תוצאות שונות משלי. מה שמדהים הוא שאתה יכול לראות את כל ההיגיון ואחריו GPT4All מנסה לקבל תשובה עבורך. התאמת השאלה עשויה לתת לך גם תוצאות טובות יותר.
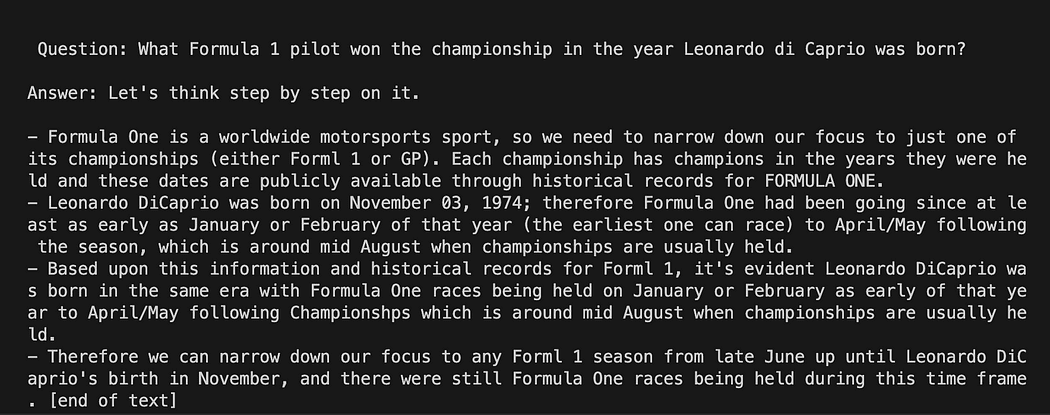
Langchain עם תבנית הנחיה ב-GPT4All
כאן אנחנו מתחילים את החלק המדהים, כי אנחנו הולכים לדבר עם המסמכים שלנו באמצעות GPT4All כצ'אט בוט שמשיב לשאלות שלנו.
רצף השלבים, בהתייחסו זרימת עבודה של ה-QnA עם GPT4All, הוא לטעון את קבצי ה-PDF שלנו, להפוך אותם לגושים. לאחר מכן נצטרך חנות וקטור להטמעות שלנו. אנחנו צריכים להזין את המסמכים החתוכים שלנו בחנות וקטורית לצורך אחזור מידע ואז נטמיע אותם יחד עם חיפוש הדמיון במסד הנתונים הזה כהקשר לשאילתת ה-LLM שלנו.
למטרות אלו אנו הולכים להשתמש ב-FAISS ישירות מ- לנגצ'יין סִפְרִיָה. FAISS היא ספריית קוד פתוח של Facebook AI Research, שנועדה למצוא במהירות פריטים דומים באוספים גדולים של נתונים במידות גבוהות. הוא מציע שיטות אינדקס וחיפוש כדי להקל ומהיר יותר לזהות את הפריטים הדומים ביותר בתוך מערך נתונים. זה נוח לנו במיוחד כי זה מפשט אִחזוּר מֵידַע ולאפשר לנו לשמור באופן מקומי את מסד הנתונים שנוצר: זה אומר שלאחר היצירה הראשונה הוא ייטען מהר מאוד לכל שימוש נוסף.
יצירת אינדקס וקטור db
צור קובץ חדש וקרא לו my_knowledge_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetimeהספריות הראשונות הן אותן הספריות בהן השתמשנו בעבר: בנוסף אנו משתמשים לנגצ'יין עבור יצירת אינדקס מאגר וקטור, ה LlamaCppEmbeddings לקיים אינטראקציה עם מודל האלפקה שלנו (מכומת ל-4 סיביות והידור עם ספריית ה-cpp) ועם טוען ה-PDF.
בואו נטען גם את ה-LLMs שלנו עם נתיבים משלהם: אחד להטמעות ואחד ליצירת טקסט.
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)לבדיקה בואו נראה אם הצלחנו לקרוא את כל קבצי ה-pfd: הצעד הראשון הוא להכריז על 3 פונקציות לשימוש בכל מסמך בודד. הראשון הוא לפצל את הטקסט שחולץ לנתחים, השני הוא ליצור את האינדקס הווקטורי עם המטא נתונים (כמו מספרי עמודים וכו'...) והאחרון מיועד לבדיקת חיפוש הדמיון (אני אסביר יותר טוב בהמשך).
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sourcesכעת נוכל לבדוק את יצירת האינדקס עבור המסמכים ב- Docs ספרייה: אנחנו צריכים לשים שם את כל קובצי ה-PDF שלנו. לנגצ'יין יש גם שיטה לטעינת התיקיה כולה, ללא קשר לסוג הקובץ: מכיוון שזה מסובך בתהליך הפוסט, אעסוק בזה במאמר הבא על דגמי LaMini.

ספריית המסמכים שלי מכילה 4 קבצי pdf
נחיל את הפונקציות שלנו על המסמך הראשון ברשימה
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)בשורות הראשונות אנו משתמשים בספריית OS כדי לקבל את רשימה של קבצי pdf בתוך ספריית המסמכים. לאחר מכן נטען את המסמך הראשון (doc_list[0]) מתיקיית המסמכים עם לנגצ'יין, מחלקים לחלקים ואז אנו יוצרים את מסד הנתונים הווקטוריים עם ה- לָאמָה הטבעות.
כפי שראית אנו משתמשים ב- שיטת pyPDF. זה קצת יותר ארוך לשימוש, מכיוון שאתה צריך לטעון את הקבצים אחד אחד, אבל לטעון PDF באמצעות pypdf לתוך מערך מסמכים מאפשר לך לקבל מערך שבו כל מסמך מכיל את תוכן העמוד ומטא נתונים עם page מספר. זה ממש נוח כשאתה רוצה לדעת את מקורות ההקשר שאנו ניתן ל-GPT4All עם השאילתה שלנו. הנה הדוגמה מה-readthedocs:
צילום מסך מ תיעוד לנגצ'יין
נוכל להריץ את קובץ python עם הפקודה מהמסוף:
python3 my_knowledge_qna.pyלאחר טעינת הדגם להטמעות תראה את האסימונים בעבודה לאינדקס: אל תתחרפן כי זה ייקח זמן, במיוחד אם אתה רץ רק על CPU, כמוני (זה לקח 8 דקות).
השלמת ה-db הווקטור הראשון
כפי שהסברתי, שיטת pyPDF איטית יותר אך נותנת לנו נתונים נוספים לחיפוש הדמיון. כדי לחזור על כל הקבצים שלנו נשתמש בשיטה נוחה של FAISS המאפשרת לנו למזג מסדי נתונים שונים יחד. מה שאנחנו עושים עכשיו זה שאנחנו משתמשים בקוד שלמעלה כדי ליצור את ה-db הראשון (נקרא לו db0) ואת עם לולאת for אנו יוצרים את האינדקס של הקובץ הבא ברשימה וממזגים אותו מיד db0.
הנה הקוד: שימו לב שהוספתי כמה יומנים כדי לתת לכם את מצב ההתקדמות באמצעות datetime.datetime.now() והדפסת הדלתא של זמן סיום ושעת התחלה כדי לחשב כמה זמן לקח הפעולה (אפשר להסיר אותה אם זה לא מוצא חן בעיניך).
הוראות המיזוג הן כאלה
# merge dbi with the existing db0
db0.merge_from(dbi)אחת ההנחיות האחרונות היא לשמור את מסד הנתונים שלנו באופן מקומי: כל הדור יכול לקחת אפילו שעות (תלוי בכמה מסמכים יש לך) אז זה ממש טוב שאנחנו צריכים לעשות את זה רק פעם אחת!
# Save the databasae locally
db0.save_local("my_faiss_index")הנה כל הקוד. אנו נגיב על חלקים רבים ממנו כאשר אנו מקיימים אינטראקציה עם GPT4All בטעינת האינדקס ישירות מהתיקייה שלנו.
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  הפעלת קובץ python ארכה 22 דקות
הפעלת קובץ python ארכה 22 דקות
שאל שאלות ל-GPT4All על המסמכים שלך
עכשיו אנחנו כאן. יש לנו את האינדקס שלנו, אנחנו יכולים לטעון אותו ועם תבנית הנחיה נוכל לבקש מ-GPT4All לענות על השאלות שלנו. נתחיל עם שאלה מקודדת ואז נעבור בלולאה דרך שאלות הקלט שלנו.
שים את הקוד הבא בתוך קובץ python db_loading.py והפעל אותו עם הפקודה מהמסוף python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])הטקסט המודפס הוא רשימת 3 המקורות המתאימים ביותר לשאילתה, ומספק לנו גם את שם המסמך ומספר העמוד.
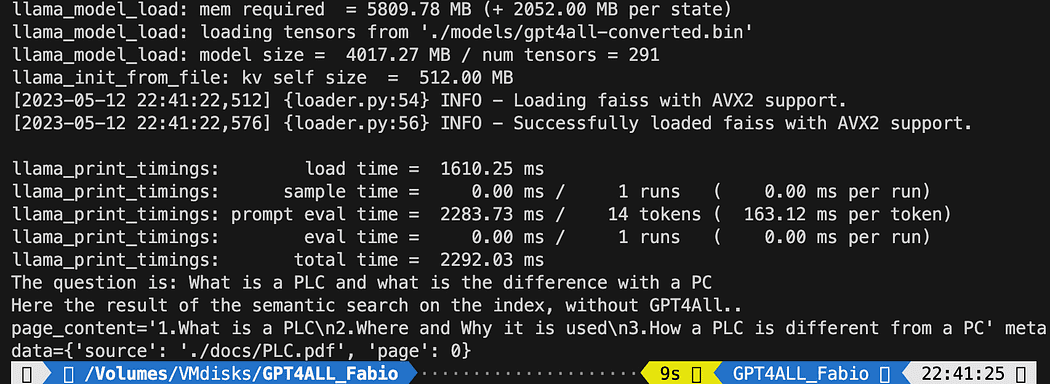
תוצאות החיפוש הסמנטי המריץ את הקובץ db_loading.py
כעת נוכל להשתמש בחיפוש הדמיון כהקשר לשאילתה שלנו באמצעות תבנית ההנחיה. לאחר 3 הפונקציות פשוט החליפו את כל הקוד עם הקוד הבא:
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))לאחר הריצה תקבל תוצאה כזו (אך עשויה להשתנות). מדהים לא!?!?
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.אם אתה רוצה שאלת קלט משתמש תחליף את השורה
question = "What is a PLC and what is the difference with a PC"עם משהו כזה:
question = input("Your question: ")הגיע הזמן שתתנסו. שאל שאלות שונות על כל הנושאים הקשורים למסמכים שלך, וראה את התוצאות. יש מקום גדול לשיפור, בוודאי בהנחיה ובתבנית: אתה יכול להסתכל כאן לכמה השראה. אבל לנגצ'יין התיעוד באמת מדהים (יכולתי לעקוב אחריו!!).
אתה יכול לעקוב אחר הקוד מהמאמר או לבדוק אותו ריפו ה-github שלי.
פאביו מטריקרדי מחנך, מורה, מהנדס וחובב למידה. הוא מלמד כבר 15 שנה לסטודנטים צעירים, וכעת הוא מכשיר עובדים חדשים ב-Key Solution Srl. הוא התחיל את הקריירה שלי כמהנדס אוטומציה תעשייתית בשנת 2010. נלהב לתכנות מאז שהיה נער, הוא גילה את היופי שבבניית תוכנות וממשקי מכונה אנושיים כדי להביא משהו לחיים. הוראה ואימון הם חלק מהשגרה היומיומית שלי, כמו גם ללמוד וללמוד כיצד להיות מנהיג נלהב עם כישורי ניהול עדכניים. הצטרפו אליי במסע לעבר עיצוב טוב יותר, שילוב מערכת חזוי באמצעות למידת מכונה ובינה מלאכותית לאורך כל מחזור החיים ההנדסי.
מְקוֹרִי. פורסם מחדש באישור.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- EVM Finance. ממשק מאוחד למימון מבוזר. גישה כאן.
- Quantum Media Group. IR/PR מוגבר. גישה כאן.
- PlatoAiStream. Web3 Data Intelligence. הידע מוגבר. גישה כאן.
- מקור: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free
- :יש ל
- :הוא
- :לֹא
- :איפה
- $ למעלה
- 1
- 10
- 11
- 12
- 13
- 14
- שנים 15
- 15%
- 16
- 2023
- 22
- 23
- 25
- 420
- 7
- 8
- 9
- a
- יכולת
- יכול
- אודות
- מֵעַל
- להשיג
- לפעול
- מופעל
- הוסיף
- תוספת
- נוסף
- מתקדם
- משפיע
- לאחר
- AI
- ai מחקר
- תעשיות
- להתיר
- מאפשר
- כְּבָר
- גם
- am
- מדהים
- an
- אנליזה
- ו
- לענות
- כל
- API
- יישומים
- החל
- ארכיטקטורה
- ARE
- מערך
- מאמר
- מאמרים
- מלאכותי
- בינה מלאכותית
- AS
- המשויך
- At
- אודיו
- אוטומטי
- באופן אוטומטי
- אוטומציה
- זמין
- לְהִמָנַע
- בסיס
- מבוסס
- BE
- יופי
- כי
- היה
- לפני
- להיות
- להלן
- הטוב ביותר
- מוטב
- בֵּין
- מעבר
- גָדוֹל
- BIN
- כריכה
- קצת
- נולד
- בקצרה
- להביא
- לִבנוֹת
- בִּניָן
- מובנה
- אוטובוסים
- אבל
- by
- לחשב
- שיחה
- נקרא
- שיחות
- CAN
- לא יכול
- קיבולת
- לוכדת
- קריירה
- לשאת
- מקרה
- היאבקות
- CD
- מסוים
- בהחלט
- שרשרת
- שרשראות
- אליפות
- chatbot
- ChatGPT
- לבדוק
- כימי
- בכיתה
- כיתות
- קליק
- עגלונות
- קוד
- קודים
- לגבות
- אוסף
- אוספים
- שילוב
- הערה
- בדרך כלל
- להעביר
- תקשורת
- תואם
- להשלים
- השלמת
- השלמה
- מורכב
- מסובך
- רכיבים
- המחשב
- מחשבים
- לְחַבֵּר
- מחובר
- בנייה
- צרכן
- מכיל
- תוכן
- הקשר
- לִשְׁלוֹט
- בקר
- בקרות
- נוֹחַ
- הומר
- יכול
- לכסות
- CPU
- לִיצוֹר
- נוצר
- יוצר
- יוצרים
- יצירה
- יְצִירָתִי
- קריטי
- להתאמה אישית
- יומי
- נתונים
- מסד נתונים
- מאגרי מידע
- תַאֲרִיך
- datetime
- להחליט
- בְּרִירַת מֶחדָל
- מוגדר
- דלתא
- תלות
- תלוי
- תלוי
- לפרוס
- מְתוּאָר
- עיצוב
- מעוצב
- רצוי
- מתפתח
- מכשיר
- התקנים
- DID
- הבדל
- אחר
- לעיכול
- דיגיטלי
- ישירות
- לגלות
- גילה
- do
- מסמך
- תיעוד
- מסמכים
- עושה
- לא איכפת
- עשה
- לא
- נקודה
- להורדה
- נהיגה
- בְּמַהֲלָך
- כל אחד
- קל יותר
- בקלות
- קל
- המערכת האקולוגית
- מערכות אקולוגיות
- מאמץ
- שבץ
- מוטבע
- הטבעה
- עובדים
- לאפשר
- סוף
- מהנדס
- הנדסה
- זן
- נלהב
- שלם
- סביבה
- שגיאה
- במיוחד
- וכו '
- Ether (ETH)
- אֲפִילוּ
- הכל
- בדיוק
- דוגמה
- דוגמאות
- הוצאת להורג
- קיימים
- לְנַסוֹת
- להסביר
- מוסבר
- המסביר
- חיצוני
- פָּנִים
- פייסבוק
- מקל
- מול
- מהר
- מהר יותר
- שלח
- קבצים
- סוף
- ראשון
- מתאים
- תזרים
- לעקוב
- בעקבות
- הבא
- כדלקמן
- בעד
- טופס
- פוּרמָט
- נוסחה
- פורמולה 1
- מסגרת
- החל מ-
- פונקציה
- פונקציות
- נוסף
- ליצור
- יצירת
- דור
- לקבל
- GitHub
- לתת
- נתן
- נותן
- נתינה
- הולך
- טוב
- GPU
- ציון
- טיפול
- קורה
- קשה
- חומרה
- יש
- he
- כבד
- עוזר
- כאן
- מוּסתָר
- גָבוֹהַ
- גבוה יותר
- שעות
- איך
- איך
- HTML
- http
- HTTPS
- בן אנוש
- i
- ICS
- if
- תמונות
- מיד
- ליישם
- לייבא
- חשוב
- השבחה
- in
- לכלול
- מדד
- אינדקסים
- אנשים
- התעשייה
- אוטומציה תעשייתית
- תעשיות
- מידע
- קלט
- פלט קלט
- תשומות
- להתקין
- התקנה
- למשל
- הוראות
- השתלבות
- מוֹדִיעִין
- התכוון
- אינטראקציה
- אינטראקציה
- מִמְשָׁק
- ממשקים
- אינטרנט
- אל תוך
- מבוא
- מְבוּדָד
- בדידות
- IT
- פריטים
- איטרציה
- שֶׁלָה
- עבודה
- להצטרף
- מסע
- רק
- KDnuggets
- מפתח
- לדעת
- ידע
- שפה
- גָדוֹל
- אחרון
- מאוחר יותר
- מנהיג
- למידה
- רמה
- ספריות
- סִפְרִיָה
- החיים
- מעגל החיים
- כמו
- קווים
- קשר
- לינקדין
- לינוקס
- רשימה
- קְצָת
- לִטעוֹן
- מטעין
- טוען
- מקומי
- באופן מקומי
- הגיון
- ארוך
- עוד
- נראה
- מגרש
- מק
- מכונה
- למידת מכונה
- מכונות
- ראשי
- בעיקר
- לתחזק
- לעשות
- הצליח
- ניהול
- מנהל
- מנהלים
- ייצור
- רב
- מאי..
- משמעות
- אומר
- זכרון
- למזג
- מיזוג
- מידע נוסף
- שיטה
- שיטות
- אכפת לי
- דקות
- מודל
- מודלים
- יותר
- רוב
- מספר
- צריך
- my
- שם
- יליד
- צורך
- רשתות
- חדש
- הבא
- עַכשָׁיו
- מספר
- מספרים
- אובייקט
- of
- המיוחדות שלנו
- on
- פעם
- ONE
- באינטרנט
- רק
- קוד פתוח
- מבצע
- תפעול
- or
- להזמין
- ארגונים
- OS
- אחר
- שלנו
- הַחוּצָה
- תפוקה
- יותר
- שֶׁלוֹ
- חבילה
- חבילות
- עמוד
- מקביל
- חלק
- מסוים
- במיוחד
- לעבור
- לוהט
- נתיב
- PC
- אֲנָשִׁים
- לבצע
- רשות
- אישי
- תמונה
- לְחַבֵּר
- טַיָס
- צמחים
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- PLC
- אנא
- תקע
- יציאות
- עמדה
- הודעה
- פוטנציאל
- כּוֹחַ
- תחנות כוח
- מופעל
- חזק
- מראש
- למנוע
- קופונים להדפסה
- הדפסה
- בעיות
- תהליך
- מעובד
- תהליכים
- תָכְנִית
- מתוכנה
- תכנות
- התקדמות
- פּרוֹיֶקט
- פרויקטים
- פרוטוקולים
- מספק
- למטרות
- גם
- פיתון
- איכות
- שאלה
- שאלות
- מהירות
- במקום
- חומר עיוני
- מוכן
- בֶּאֱמֶת
- קבלה
- לאחרונה
- מכונה
- מתייחס
- ללא קשר
- רושמים
- קָשׁוּר
- אמינות
- לסמוך
- לזכור
- להסיר
- חזר
- להחליף
- לדווח
- מאגר
- נציגות
- נדרש
- דרישות
- דורש
- מחקר
- משאבים
- תגובה
- תגובות
- תוצאה
- תוצאות
- לַחֲזוֹר
- חֶדֶר
- הפעלה
- ריצה
- s
- בְּטִיחוּת
- אותו
- שמור
- חסכת
- תרחיש
- חיפוש
- חיפוש
- שְׁנִיָה
- סעיף
- לבטח
- לִרְאוֹת
- חיישנים
- משפט
- רצף
- סידורי
- הצבה
- התקנה
- כמה
- בְּעִיטָה
- צריך
- הראה
- דומה
- פָּשׁוּט
- בפשטות
- since
- יחיד
- מיומנויות
- קטן
- So
- תוכנה
- פִּתָרוֹן
- כמה
- משהו
- מָקוֹר
- מקורות
- מיוחד
- במיוחד
- ספציפי
- מפורט
- לפצל
- מסחרי
- התחלה
- החל
- החל
- הצהרה
- מצב
- שלב
- צעדים
- עוד
- חנות
- מחרוזת
- מִבְנֶה
- סטודנטים
- לומד
- כזה
- מערכת
- לקחת
- לדבר
- משימות
- מורה
- הוראה
- מִתבַּגֵר
- תבנית
- מסוף
- מבחן
- מבחן ריצה
- בדיקות
- דור טקסט
- מֵאֲשֶׁר
- זֶה
- השמיים
- שֶׁלָהֶם
- אותם
- אז
- שם.
- אלה
- הֵם
- לחשוב
- זֶה
- מחשבה
- דרך
- בכל
- זמן
- ל
- יַחַד
- מטבעות
- מחר
- גַם
- לקח
- נושא
- נושאים
- לקראת
- רכבת
- לנסות
- שתיים
- סוג
- טיפוסי
- בדרך כלל
- מְעוּדכָּן
- עדכונים
- על
- us
- נוֹהָג
- USB
- להשתמש
- במקרה להשתמש
- מְשׁוּמָשׁ
- משתמש
- משתמשים
- באמצעות
- בְּדֶרֶך כְּלַל
- מנוצל
- שונים
- לאמת
- גרסה
- מאוד
- באמצעות
- וירטואלי
- W3
- לחכות
- רוצה
- היה
- דֶרֶך..
- דרכים
- we
- אתר
- טוֹב
- מה
- מה
- גַלגַל
- מתי
- אשר
- מי
- למה
- באופן נרחב
- יצטרך
- חלונות
- משתמשי Windows
- עם
- בתוך
- לְלֹא
- נצחנות
- תיק עבודות
- עובד
- שנה
- שנים
- אתה
- צעיר
- זפירנט










