היום, אנו נרגשים להכריז על זמינותם של מסקנות Llama 2 ותמיכה בכוונון עדין ב- AWS Trainium ו Afer Inferentia מקרים ב אמזון SageMaker JumpStart. שימוש במופעים מבוססי AWS Trainium ו-Inferentia, דרך SageMaker, יכול לעזור למשתמשים להוריד את עלויות הכוונון העדין בעד 50%, ולהוזיל את עלויות הפריסה פי 4.7, תוך הפחתת זמן האחזור לכל אסימון. Llama 2 הוא מודל שפת טקסט גנרטיבי אוטומטי רגרסיבי המשתמש בארכיטקטורת שנאי אופטימלית. כמודל זמין לציבור, Llama 2 מיועד למשימות NLP רבות כגון סיווג טקסט, ניתוח סנטימנטים, תרגום שפות, מודלים לשפות, יצירת טקסט ומערכות דיאלוג. כוונון ופריסה של LLMs, כמו Llama 2, עלולים להיות יקרים או מאתגרים כדי לעמוד בביצועים בזמן אמת כדי לספק חווית לקוח טובה. Trainium ו-AWS Inferentia, מופעל על ידי AWS נוירון ערכת פיתוח תוכנה (SDK), מציעה אפשרות יעילה וחסכונית להדרכה והסקת דגמי Llama 2.
בפוסט זה, אנו מדגימים כיצד לפרוס ולכוונן את Llama 2 במופעי Trainium ו-AWS Inferentia ב- SageMaker JumpStart.
סקירת פתרונות
בבלוג זה נעבור על התרחישים הבאים:
- פרוס את Llama 2 במופעי AWS Inferentia בשני ה סטודיו SageMaker של אמזון ממשק משתמש, עם חווית פריסה בלחיצה אחת, ו-SageMaker Python SDK.
- כוונן את Llama 2 במופעי Trainium הן בממשק המשתמש של SageMaker Studio והן ב- SageMaker Python SDK.
- השווה את הביצועים של דגם ה-Llama 2 המכוונן עדין לאלו של הדגם המאומן מראש כדי להראות את היעילות של כוונון עדין.
כדי לקבל יד על, ראה את מחברת לדוגמה של GitHub.
פרוס את Llama 2 במופעי AWS Inferentia באמצעות ממשק המשתמש של SageMaker Studio ו- Python SDK
בחלק זה, אנו מדגימים כיצד לפרוס את Llama 2 במופעי AWS Inferentia באמצעות ממשק המשתמש של SageMaker Studio לפריסה בלחיצה אחת ו- Python SDK.
גלה את דגם Llama 2 בממשק המשתמש של SageMaker Studio
SageMaker JumpStart מספק גישה הן לציבור והן לקנייניות דגמי יסוד. מודלים של קרן מוכללים ומתוחזקים מספקי צד שלישי וקנייניים. ככאלה, הם משוחררים תחת רישיונות שונים כפי שצוין על ידי מקור הדגם. הקפד לעיין ברישיון עבור כל דגם יסוד שבו אתה משתמש. אתה אחראי לעיין ולציית לכל תנאי הרישיון הרלוונטיים ולוודא שהם מקובלים במקרה השימוש שלך לפני ההורדה או השימוש בתוכן.
אתה יכול לגשת לדגמי הבסיס של Llama 2 דרך SageMaker JumpStart בממשק המשתמש של SageMaker Studio ו- SageMaker Python SDK. בחלק זה נעבור על איך לגלות את הדגמים בסטודיו SageMaker.
SageMaker Studio הוא סביבת פיתוח משולבת (IDE) המספקת ממשק חזותי אחד מבוסס אינטרנט שבו אתה יכול לגשת לכלים ייעודיים לביצוע כל שלבי הפיתוח של למידת מכונה (ML), מהכנת נתונים ועד לבנייה, הדרכה ופריסה של ה-ML שלך. דגמים. לפרטים נוספים כיצד להתחיל ולהגדיר את SageMaker Studio, עיין ב אמזון SageMaker Studio.
לאחר שתהיה ב-SageMaker Studio, תוכל לגשת ל- SageMaker JumpStart, המכיל דגמים מאומנים מראש, מחברות ופתרונות מובנים מראש, תחת פתרונות מובנים ואוטומטיים מראש. למידע מפורט יותר על איך לגשת לדגמים קנייניים, עיין ב השתמש בדגמי יסוד קנייניים של Amazon SageMaker JumpStart ב-Amazon SageMaker Studio.
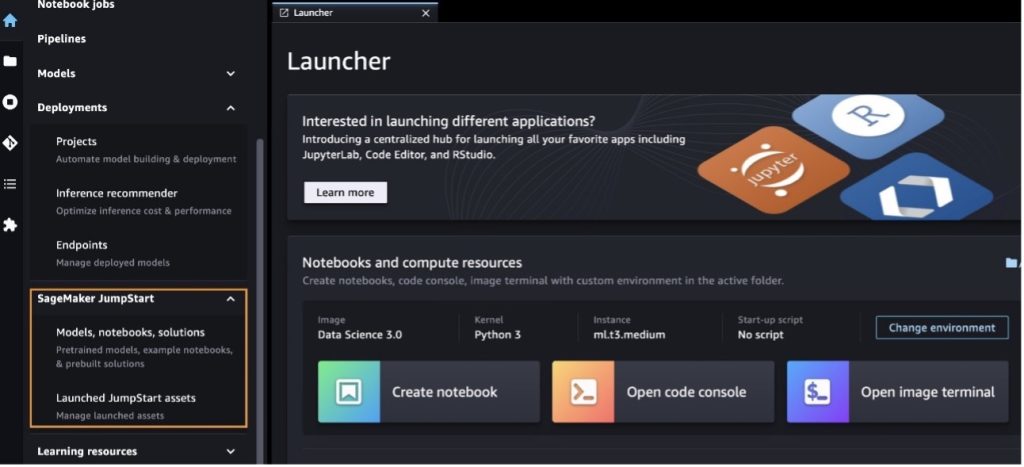
מדף הנחיתה של SageMaker JumpStart, אתה יכול לחפש פתרונות, דגמים, מחברות ומשאבים אחרים.
אם אינך רואה את דגמי Llama 2, עדכן את גרסת SageMaker Studio שלך על ידי כיבוי והפעלה מחדש. למידע נוסף על עדכוני גרסה, עיין ב כבה ועדכן את אפליקציות Studio Classic.

אתה יכול גם למצוא גרסאות דגמים אחרות על ידי בחירה חקור את כל המודלים ליצירת טקסט או מחפש llama or neuron בתיבת החיפוש. תוכל לצפות בדגמי Llama 2 Neuron בעמוד זה.
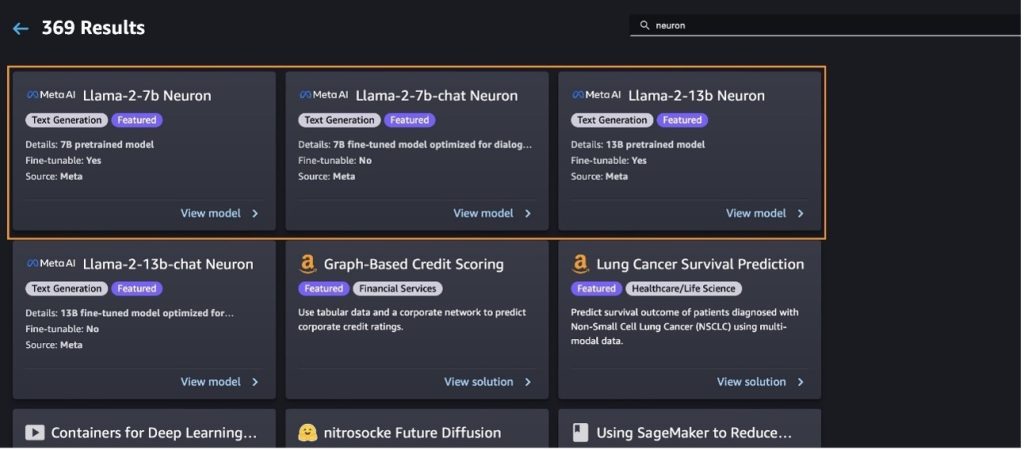
פרוס את מודל Llama-2-13b עם SageMaker Jumpstart
אתה יכול לבחור את כרטיס הדגם כדי להציג פרטים על הדגם כגון רישיון, נתונים המשמשים לאימון וכיצד להשתמש בו. אתה יכול למצוא גם שני כפתורים, לפרוס ו פתח את המחברת, שעוזר לך להשתמש במודל באמצעות דוגמה זו ללא קוד.
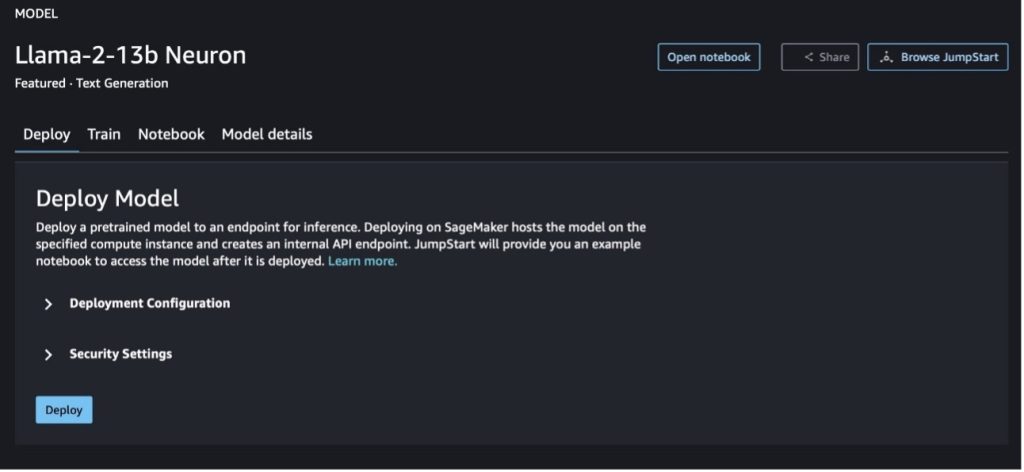
כאשר תבחר באחד מהלחצנים, חלון קופץ יציג את הסכם הרישיון למשתמש הקצה ואת מדיניות השימוש המקובל (AUP) כדי שתוכל לאשר.
לאחר שתאשר את המדיניות, תוכל לפרוס את נקודת הקצה של המודל ולהשתמש בה באמצעות השלבים בסעיף הבא.
פרוס את מודל Llama 2 Neuron דרך Python SDK
כשאתה בוחר לפרוס ואשר את התנאים, פריסת המודל תתחיל. לחלופין, תוכל לפרוס דרך המחברת לדוגמה על ידי בחירה פתח את המחברת. המחברת לדוגמה מספקת הדרכה מקצה לקצה כיצד לפרוס את המודל להסקת מסקנות וניקוי משאבים.
כדי לפרוס או לכוונן מודל במופעי Trainium או AWS Inferentia, תחילה עליך להתקשר ל- PyTorch Neuron (לפיד-נוירון) כדי להרכיב את המודל לגרף ספציפי ל- Neuron, שימטב אותו עבור NeuronCores של Inferentia. משתמשים יכולים להנחות את המהדר לבצע אופטימיזציה עבור השהיה הנמוכה ביותר או התפוקה הגבוהה ביותר, בהתאם למטרות היישום. ב-JumpStart, ערכנו מראש את גרפי ה- Neuron עבור מגוון תצורות, כדי לאפשר למשתמשים ללגום שלבי קומפילציה, מה שמאפשר כוונון עדין ופריסה מהירים יותר של מודלים.
שים לב שהגרף המהודר מראש של Neuron נוצר על סמך גרסה ספציפית של גרסת Neuron Compiler.
ישנן שתי דרכים לפרוס את LIama 2 במופעים מבוססי AWS Inferentia. השיטה הראשונה מנצלת את התצורה הבנויה מראש, ומאפשרת לך לפרוס את המודל בשתי שורות קוד בלבד. בשנייה, יש לך שליטה רבה יותר על התצורה. נתחיל בשיטה הראשונה, עם התצורה הבנויה מראש, ונשתמש במודל ה-Llama 2 13B Neuron המאומן מראש, כדוגמה. הקוד הבא מראה כיצד לפרוס את Llama 13B עם שתי שורות בלבד:
כדי לבצע הסקה על מודלים אלה, עליך לציין את הטיעון accept_eula להיות True כחלק מ model.deploy() שִׂיחָה. הגדרת טיעון זה להיות נכון, מאשרת שקראת וקיבלת את ה-EULA של המודל. ניתן למצוא את ה-EULA בתיאור כרטיס הדגם או מה- אתר מטא.
סוג המופע המוגדר כברירת מחדל עבור Llama 2 13B הוא ml.inf2.8xlarge. אתה יכול גם לנסות מזהי דגמים נתמכים אחרים:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(דגם צ'אט)meta-textgenerationneuron-llama-2-13b-f(דגם צ'אט)
לחלופין, אם ברצונך לקבל שליטה רבה יותר על תצורות הפריסה, כגון אורך הקשר, דרגת טנזור מקבילה וגודל אצווה מתגלגלת מקסימלית, תוכל לשנות אותן באמצעות משתנים סביבתיים, כפי שהודגם בסעיף זה. ה-Deep Learning Container (DLC) הבסיסי של הפריסה הוא Large Model Inference (LMI) NeuronX DLC. המשתנים הסביבתיים הם כדלקמן:
- OPTION_N_POSITIONS - המספר המרבי של אסימוני קלט ופלט. לדוגמה, אם אתה מקמפל את המודל עם
OPTION_N_POSITIONSבתור 512, אז אתה יכול להשתמש באסימוני קלט של 128 (גודל הודעת קלט) עם אסימון פלט מקסימלי של 384 (סך הכל של אסימוני הקלט והפלט צריך להיות 512). עבור אסימון הפלט המקסימלי, כל ערך מתחת ל-384 הוא בסדר, אבל אתה לא יכול ללכת מעבר לו (לדוגמה, קלט 256 ופלט 512). - OPTION_TENSOR_PARALLEL_DEGREE - מספר NeuronCores לטעינת המודל במופעי AWS Inferentia.
- OPTION_MAX_ROLLING_BATCH_SIZE - גודל האצווה המרבי עבור בקשות במקביל.
- OPTION_DTYPE – סוג התאריך לטעינת הדגם.
הידור של גרף Neuron תלוי באורך ההקשר (OPTION_N_POSITIONS), תואר מקביל טנזור (OPTION_TENSOR_PARALLEL_DEGREE), גודל אצווה מקסימלי (OPTION_MAX_ROLLING_BATCH_SIZE), וסוג נתונים (OPTION_DTYPE) כדי לטעון את הדגם. SageMaker JumpStart הרכיב מראש גרפי Neuron עבור מגוון תצורות עבור הפרמטרים הקודמים כדי להימנע מהידור בזמן ריצה. התצורות של גרפים שהורכבו מראש מפורטות בטבלה הבאה. כל עוד המשתנים הסביבתיים נכנסים לאחת מהקטגוריות הבאות, תדלג על הידור של גרפים של נוירון.
| LIama-2 7B ו-LIama-2 7B Chat | ||||
| סוג מופע | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B ו-LIama-2 13B Chat | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
להלן דוגמה לפריסת Llama 2 13B והגדרת כל התצורות הזמינות.
כעת, לאחר שפרסנו את מודל ה-Llama-2-13b, אנו יכולים להסיק איתו על ידי הפעלת נקודת הקצה. קטע הקוד הבא מדגים את השימוש בפרמטרי ההסקה הנתמכים כדי לשלוט ביצירת טקסט:
- אורך מקסימלי – המודל יוצר טקסט עד שאורך הפלט (הכולל את אורך ההקשר של הקלט) מגיע
max_length. אם צוין, זה חייב להיות מספר שלם חיובי. - max_new_tokens – המודל יוצר טקסט עד שאורך הפלט (לא כולל אורך ההקשר של הקלט) מגיע
max_new_tokens. אם צוין, זה חייב להיות מספר שלם חיובי. - num_beams - זה מציין את מספר הקורות המשמשות בחיפוש החמדני. אם צוין, הוא חייב להיות מספר שלם הגדול או שווה ל
num_return_sequences. - no_repeat_ngram_size – המודל מבטיח שרצף מילים של
no_repeat_ngram_sizeאינו חוזר על עצמו ברצף הפלט. אם צוין, זה חייב להיות מספר שלם חיובי הגדול מ-1. - טמפרטורה - זה שולט באקראיות בפלט. טמפרטורה גבוהה יותר מביאה לרצף פלט עם מילים בסבירות נמוכה; טמפרטורה נמוכה יותר מביאה לרצף פלט עם מילים בסבירות גבוהה. אם
temperatureשווה ל-0, זה גורם לפענוח חמדני. אם צוין, זה חייב להיות ציפה חיובית. - עצירה מוקדמת - אם
True, יצירת טקסט מסתיימת כאשר כל השערות האלומה מגיעות לסוף אסימון המשפט. אם צוין, זה חייב להיות בוליאני. - do_sample - אם
True, המודל דוגם את המילה הבאה לפי הסבירות. אם צוין, זה חייב להיות בוליאני. - top_k – בכל שלב של יצירת טקסט, המודל דוגם רק מה-
top_kסביר להניח מילים. אם צוין, זה חייב להיות מספר שלם חיובי. - top_p – בכל שלב של יצירת טקסט, המודל דוגם מקבוצת המילים הקטנה ביותר האפשרית עם הסתברות מצטברת של
top_p. אם צוין, זה חייב להיות צף בין 0-1. - להפסיק – אם צוין, זה חייב להיות רשימה של מחרוזות. יצירת טקסט נעצרת אם אחת מהמחרוזות שצוינו נוצרת.
הקוד הבא מציג דוגמה:
תְפוּקָה:
למידע נוסף על הפרמטרים במטען, עיין ב פרמטרים מפורטים.
אתה יכול גם לחקור את יישום הפרמטרים ב- מחברה כדי להוסיף מידע נוסף על הקישור של המחברת.
כוונן את דגמי Llama 2 במופעי Trainium באמצעות ממשק המשתמש של SageMaker Studio ו- SageMaker Python SDK
מודלים של יסודות בינה מלאכותית הפכו למוקד עיקרי ב-ML ובינה מלאכותית, עם זאת, ההכללה הרחבה שלהם עלולה להיכשל בתחומים ספציפיים כמו שירותי בריאות או שירותים פיננסיים, שבהם מעורבים מערכי נתונים ייחודיים. מגבלה זו מדגישה את הצורך לכוונן את דגמי הבינה המלאכותית הגנרטיבית הללו עם נתונים ספציפיים לתחום כדי לשפר את הביצועים שלהם בתחומים מיוחדים אלה.
כעת, לאחר שפרסנו את הגרסה המאומנת מראש של דגם ה-Llama 2, בואו נסתכל כיצד נוכל לכוונן זאת לנתונים ספציפיים לתחום כדי להגביר את הדיוק, לשפר את המודל מבחינת השלמות מיידיות ולהתאים את המודל ל מקרה השימוש העסקי והנתונים הספציפיים שלך. אתה יכול לכוונן את הדגמים באמצעות ממשק המשתמש של SageMaker Studio או SageMaker Python SDK. אנו דנים בשתי השיטות בחלק זה.
כוונן את דגם Llama-2-13b Neuron עם SageMaker Studio
ב-SageMaker Studio, נווט לדגם Llama-2-13b Neuron. על לפרוס לשונית, אתה יכול להצביע על שירות אחסון פשוט של אמזון (Amazon S3) דלי המכיל את מערכי ההדרכה והאימות לכוונון עדין. בנוסף, תוכל להגדיר תצורת פריסה, היפרפרמטרים והגדרות אבטחה לכוונון עדין. אז תבחר רכבת כדי להתחיל את עבודת ההדרכה במופע SageMaker ML.

כדי להשתמש בדגמי Llama 2, עליך לאשר את ה-EULA ואת AUP. זה יופיע כשאתה בוחר רכבת. בחר קראתי ואני מקבל את EULA ו-AUP כדי להתחיל את עבודת הכוונון העדין.
אתה יכול לראות את מצב עבודת ההדרכה שלך עבור הדגם המכוונן תחת בקונסולת SageMaker על ידי בחירה משרות הדרכה בחלונית הניווט.
אתה יכול לכוונן עדין את דגם ה-Llama 2 Neuron שלך באמצעות דוגמה זו ללא קוד, או לכוונן עדין באמצעות ה- Python SDK, כפי שהודגם בסעיף הבא.
כוונון עדין של דגם Llama-2-13b Neuron באמצעות SageMaker Python SDK
אתה יכול לכוונן את מערך הנתונים עם פורמט התאמת הדומיין או ה- כוונון עדין מבוסס הוראות פוּרמָט. להלן ההוראות כיצד יש לעצב את נתוני האימון לפני שליחתם לכוונון עדין:
- קֶלֶט -
trainספרייה המכילה קובץ בפורמט של שורות JSON (.jsonl) או טקסט (.txt).- עבור קובץ JSON lines (.jsonl), כל שורה היא אובייקט JSON נפרד. כל אובייקט JSON צריך להיות מובנה כזוג מפתח-ערך, היכן שהמפתח צריך להיות
text, והערך הוא התוכן של דוגמה אחת לאימון. - מספר הקבצים תחת ספריית הרכבת צריך להיות שווה ל-1.
- עבור קובץ JSON lines (.jsonl), כל שורה היא אובייקט JSON נפרד. כל אובייקט JSON צריך להיות מובנה כזוג מפתח-ערך, היכן שהמפתח צריך להיות
- תְפוּקָה – מודל מאומן שניתן לפרוס להסקת מסקנות.
בדוגמה זו, אנו משתמשים בתת-קבוצה של מערך הנתונים של דולי בפורמט כוונון הוראות. מערך הנתונים של דולי מכיל כ-15,000 רשומות העוקבות אחר הוראות עבור קטגוריות שונות, כגון מענה לשאלות, סיכום והפקת מידע. זה זמין תחת רישיון Apache 2.0. אנו משתמשים ב- information_extraction דוגמאות לכוונון עדין.
- טען את מערך הנתונים של דולי ופצל אותו ל
train(עבור כוונון עדין) וtest(להערכה):
- השתמש בתבנית הנחיה לעיבוד מוקדם של הנתונים בתבנית הוראות עבור עבודת ההדרכה:
- בדוק את הפרמטרים ההיפר ודרוס אותם למקרה השימוש שלך:
- כוונן את הדגם והתחל בעבודת הכשרה של SageMaker. התסריטים לכוונון העדין מבוססים על neuronx-nemo-megatron מאגר, שהן גרסאות מתוקנות של החבילות נמו ו שיא שהותאמו לשימוש עם מופעי Neuron ו-EC2 Trn1. ה neuronx-nemo-megatron למאגר יש מקביליות תלת-ממדית (נתונים, טנזור וצינור) כדי לאפשר לך לכוונן עדין LLMs בקנה מידה. המופעים הנתמכים של Trainium הם ml.trn3xlarge ו-ml.trn1.32n.1xlarge.
- לבסוף, פרוס את המודל המכוונן בנקודת קצה של SageMaker:
השווה תגובות בין דגמי ה-Llama 2 Neuron המאומנים מראש ובין הדגמים המכוונים היטב
כעת, לאחר שפרסנו את הגרסה המאומנת מראש של דגם ה-Llama-2-13b וכינונו אותה עדין, אנו יכולים לראות כמה מהשוואות הביצועים של ההשלמות המיידיות משני הדגמים, כפי שמוצג בטבלה הבאה. אנו מציעים גם דוגמה לכוונון עדין של Llama 2 במערך נתונים של תיוק SEC בפורמט txt. לפרטים, ראה את מחברת לדוגמה של GitHub.
| פריט | תשומות | אמת קרקעית | תגובה מדגם לא מעודן | תגובה מדגם מכוון |
| 1 | להלן הוראה המתארת משימה, בשילוב עם קלט המספק הקשר נוסף. כתוב תגובה שמשלימה כראוי את הבקשה.nn### הוראה: nחלץ מכל אחת מהאוניברסיטאות שבהן למד מורט ושנת סיום הלימודים שלו, והכנס אותם לרשימת תבליטים.nn### קלט:nמורט נולד ב-1953 בוויווי בשוויץ , ועשה את לימודי התואר הראשון שלו ב-École Polytechnique Fédérale de Lausanne (EPFL), סיים את לימודיו בשנת 1975. הוא המשיך ללימודי תואר שני באוניברסיטת טנסי, וקיבל תואר Ph.D. בשנת 1980. לאחר מכן הצטרף לפקולטה של אוניברסיטת ניו מקסיקו, שם נשאר עד 2006, אז עבר ל-EPFL. הוא פרש מ-EPFL בדצמבר 2016. nnבשנת 1996, ייסד מורט את ACM Journal of Experimental Algorithmics, והוא נשאר העורך הראשי של כתב העת עד 2003. בשנת 2001, ייסד מורט את הסדנה באלגוריתמים לביואינפורמטיקה (WABI) ונשאר ב- ועדת היגוי לכנס.nnבשנת 2018, נבחר מורת כעמית של האגודה הבינלאומית לביולוגיה חישובית, על תרומתו הבולטת לתחומי הביולוגיה החישובית והביואינפורמטיקה.nn### תגובה:n | * École Polytechnique Fédérale de Lausanne (EPFL) (בוגר 1975)n* אוניברסיטת טנסי (בוגר 1980) | מוראט למד באקול פוליטכניק פדראל דה לוזאן (EPFL) ובאוניברסיטת טנסי, וסיים את לימודיו ב-1975 וב-1980, בהתאמה.nn### רמז:nn- השתמש בפונקציית 'פיצול' כדי לפצל את הקלט לרשימת משפטים.n- השתמש בפונקציה `פיצול` כדי לפצל כל משפט לרשימת מילים. n- השתמש בפונקציית `פיצול` כדי לפצל | – École Polytechnique Fédérale de Lausanne (EPFL),1975n- University of Tennessee,1980n- University of New Mexico- École Polytechnique Fédérale de Lausanne (EPFL),2006nn להלן הוראה המתארת משימה, בשילוב עם קלט מספק הקשר נוסף. כתוב תגובה שמשלימה כראוי את הבקשה.נ |
| 2 | להלן הוראה המתארת משימה, בשילוב עם קלט המספק הקשר נוסף. כתוב תגובה שמשלימה כראוי את הבקשה.nn### הוראה:nמהקטע זהה את התכונות של דיוניסוס. הצג את התוצאות בתבנית מופרדת בפסיקים.nn### קלט:nDionysus (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnאלוהי היין, הפירות, המסיבות, הפסטיבלים, הטירוף, הכאוס, הצמחונות, השכרות והשיכרות, תיאטרון. הוא הבן שנולד פעמיים של זאוס וסמלה, בכך שזאוס חטף אותו מבטן אמו ותפר את דיוניסוס לתוך ירכו ונשא אותו עד שהיה מוכן להיוולד. באמנות הוא מתואר כאל מזוקן מבוגר יותר (במיוחד לפני 430 לפנה"ס) או כצעיר נשי וארוך שיער (במיוחד אחרי 430 לפנה"ס). התכונות שלו כוללות את התירסוס, כוס שתייה, גפן הענבים וכתר קיסוס. לעתים קרובות הוא נמצא בחברת התיאסוס שלו, קבוצת מלווים הכוללת סאטירים, מאנדות, והמורה הוותיק שלו סילנוס. בת זוגו של דיוניסוס הייתה אריאדנה. פעם נקבע כי דיוניסיוס היה תוספת מאוחרת יותר לפנתיאון היווני, אך גילוי לוחות B ליניארי מאשר את מעמדו כאל מתקופה מוקדמת. בכחוס היה שם נוסף עבורו ביוונית, ונכנס לשימוש נפוץ בקרב הרומאים. החיות הקדושות שלו כוללות דולפינים, נחשים, נמרים וחמורים.nn### תגובה:n | התירסוס, כוס שתייה, גפן הענבים, כתר קיסוס | דיוניסוס (Διόνυσος, Diónusos)nnאלוהי היין, הפוריות, המסיבות, הפסטיבלים, הטירוף, הכאוס, השכרות, הצמחייה, האקסטזה והתיאטרון. הוא הבן שנולד פעמיים של זאוס וסמלה, בכך שזאוס חטף אותו מרחם אמו ותפר את דיוניסוס לתוך ירכו. | תירסוס, כוס שתייה, גפן הענבים, כתר של ivynn להלן הוראה המתארת משימה, בשילוב עם קלט המספק הקשר נוסף. כתוב תגובה שמשלימה כראוי את הבקשה.nn### הוראה:nמה ההבדל בין האימפריה הפרתית והארסאקית?nn### קלט:nהאימפריה הפרתית, הידועה גם בשם האימפריה הארסאצית הייתה |
| 3 | להלן הוראה המתארת משימה, בשילוב עם קלט המספק הקשר נוסף. כתוב תגובה שמשלימה כראוי את הבקשה.nn### הוראה:nמדוע בירת אוזבקיסטן מכילה את הקהילה היוונית הגדולה ביותר?nn### קלט:nהיוונים באוזבקיסטן מונים כ-9,000. הקהילה מורכבת מיוונים מרוסיה שגורשו בכוח מאותה מדינה לאוזבקיסטן בשנות ה-1940, ופליטים פוליטיים מיוון. כ-30,000 יוונים חיו במדינה לפני מלחמת העולם השנייה ו-11,000 נוספים הגיעו לאחר מלחמת האזרחים היוונית ותבוסת הצבא הדמוקרטי של יוון. מספרם הצטמצם משיא של כ-40,000 בשנות ה-1960. הסיבה העיקרית היא הגירה ליוון לאחר תום המלחמה הקרה כאשר חוקים אפשרו את החזרתם של כל היוונים האתניים שהוגלו מסיבות פוליטיות לאחר מלחמת האזרחים היוונית. הקהילה היוונית הגדולה ביותר במדינה נמצאת בעיר הבירה טשקנט, שם הועברו רוב הפליטים הפוליטיים היוונים על ידי השלטונות הסובייטיים. בימי קדם היה דרום המדינה חלק מהממלכה הסלאוקית ההלניסטית אך הקהילות היווניות הבודדות שם נטמעו מאז. הארגון החשוב ביותר המייצג את היוונים האתניים הוא אגודת התרבות היוונית של טשקנט. הפעילויות של ארגון זה כוללות הוראת שפה יוונית (19 כיתות עם סך של 571 תלמידים, כיתות למבוגרים) והוראת ריקודים ומוזיקה יוונית.nn### תגובה:n | רוב הפליטים הפוליטיים היוונים באוזבקיסטן הועברו על ידי השלטונות הסובייטיים לעיר הבירה טשקנט. | n“`nבירת אוזבקיסטן מכילה את הקהילה היוונית הגדולה ביותר מכיוון שהיוונים באוזבקיסטן מונים כ-9,000 איש. הקהילה מורכבת מיוונים מרוסיה שגורשו בכוח מאותה מדינה לאוזבקיסטן בשנות הארבעים, ופליטים פוליטיים מיוון. כ-1940 יוונים חיו במדינה לפני מלחמת העולם השנייה ועוד 30,000 | בירת אוזבקיסטן מכילה את הקהילה היוונית הגדולה ביותר מכיוון ששם הועברו רוב הפליטים הפוליטיים היוונים על ידי השלטונות הסובייטיים לאחר שגורשו מיוון.nn להלן הוראה המתארת משימה, בשילוב עם קלט המספק הקשר נוסף. כתוב תגובה שמשלימה כראוי את הבקשה.nn### הוראה:nמה ההבדל בין האימפריה הפרתית והארסאצית?nn### קלט:n |
אנו יכולים לראות שהתגובות מהמודל המכוונן מדגימות שיפור משמעותי בדיוק, רלוונטיות ובהירות בהשוואה לאלו מהמודל שהוכשר מראש. במקרים מסוימים, השימוש במודל המיומן מראש עבור מקרה השימוש שלך עשוי שלא להספיק, ולכן כוונון עדין שלו באמצעות טכניקה זו יהפוך את הפתרון למותאם אישית יותר למערך הנתונים שלך.
לנקות את
לאחר שסיימת את עבודת ההכשרה שלך ואינך רוצה להשתמש יותר במשאבים הקיימים, מחק את המשאבים באמצעות הקוד הבא:
סיכום
הפריסה והכוונן העדין של דגמי Llama 2 Neuron ב- SageMaker מדגימים התקדמות משמעותית בניהול ואופטימיזציה של מודלים בינה מלאכותית בקנה מידה גדול. מודלים אלה, כולל גרסאות כמו Llama-2-7b ו-Llama-2-13b, משתמשים ב-Neuron לאימון יעיל והסקת מסקנות על מופעים מבוססי AWS Inferentia ו-Trainium, משפרים את הביצועים ואת יכולת ההרחבה שלהם.
היכולת לפרוס את הדגמים הללו דרך ממשק המשתמש של SageMaker JumpStart ו- Python SDK מציעה גמישות וקלות שימוש. ה- Neuron SDK, עם התמיכה שלו במסגרות ML פופולריות ויכולות ביצועים גבוהות, מאפשר טיפול יעיל בדגמים גדולים אלו.
כוונון עדין של מודלים אלה על נתונים ספציפיים לתחום הוא חיוני לשיפור הרלוונטיות והדיוק שלהם בתחומים מיוחדים. התהליך, אותו תוכלו לבצע באמצעות ממשק המשתמש של SageMaker Studio או Python SDK, מאפשר התאמה אישית לצרכים ספציפיים, מה שמוביל לשיפור ביצועי הדגם מבחינת השלמות מהירות ואיכות תגובה.
באופן השוואתי, הגרסאות המאומנות מראש של הדגמים הללו, למרות שהן חזקות, עשויות לספק תגובות כלליות יותר או חוזרות על עצמן. כוונון עדין מתאים את המודל להקשרים ספציפיים, וכתוצאה מכך תגובות מדויקות, רלוונטיות ומגוונות יותר. התאמה אישית זו בולטת במיוחד כאשר משווים תגובות מדגמים מאומנים ומכוונים מראש, כאשר האחרונים מדגימים שיפור ניכר באיכות ובספציפיות של הפלט. לסיכום, הפריסה והכוונן העדין של דגמי Neuron Llama 2 ב- SageMaker מייצגים מסגרת חזקה לניהול מודלים מתקדמים של AI, המציעה שיפורים משמעותיים בביצועים ובישימות, במיוחד כשהם מותאמים לתחומים או למשימות ספציפיות.
התחל היום על ידי התייחסות לדוגמה של SageMaker מחברה.
למידע נוסף על פריסה וכיוונון עדין של דגמי Llama 2 מאומנים מראש במופעים מבוססי GPU, עיין ב- כוונן את Llama 2 ליצירת טקסט ב- Amazon SageMaker JumpStart ו דגמי הבסיס של Llama 2 מבית Meta זמינים כעת באמזון SageMaker JumpStart.
המחברים היו רוצים להכיר בתרומותיהם הטכניות של אוון קרביץ, כריסטופר וויטן, אדם קוזדרוביץ', מנאן שאה, ג'ונתן גינייה ומייק ג'יימס.
על הכותבים
 שין הואנג הוא מדען יישומי בכיר עבור האלגוריתמים המובנים של Amazon SageMaker JumpStart ו-Amazon SageMaker. הוא מתמקד בפיתוח אלגוריתמים של למידת מכונה ניתנים להרחבה. תחומי העניין שלו במחקר הם בתחום של עיבוד שפה טבעית, למידה עמוקה הניתנת להסבר על נתונים טבלאיים וניתוח חזק של צבירת מרחב-זמן לא פרמטרית. הוא פרסם מאמרים רבים בכנסים של ACL, ICDM, KDD וב-Royal Statistic Society: Series A.
שין הואנג הוא מדען יישומי בכיר עבור האלגוריתמים המובנים של Amazon SageMaker JumpStart ו-Amazon SageMaker. הוא מתמקד בפיתוח אלגוריתמים של למידת מכונה ניתנים להרחבה. תחומי העניין שלו במחקר הם בתחום של עיבוד שפה טבעית, למידה עמוקה הניתנת להסבר על נתונים טבלאיים וניתוח חזק של צבירת מרחב-זמן לא פרמטרית. הוא פרסם מאמרים רבים בכנסים של ACL, ICDM, KDD וב-Royal Statistic Society: Series A.
 ניטין אוזביוס הוא Sr. Enterprise Solutions Architect ב-AWS, מנוסה בהנדסת תוכנה, ארכיטקטורה ארגונית ו-AI/ML. הוא נלהב מאוד לחקור את האפשרויות של AI גנרטיבי. הוא משתף פעולה עם לקוחות כדי לעזור להם לבנות יישומים מעוצבים היטב בפלטפורמת AWS, ומוקדש לפתרון אתגרים טכנולוגיים וסיוע במסע הענן שלהם.
ניטין אוזביוס הוא Sr. Enterprise Solutions Architect ב-AWS, מנוסה בהנדסת תוכנה, ארכיטקטורה ארגונית ו-AI/ML. הוא נלהב מאוד לחקור את האפשרויות של AI גנרטיבי. הוא משתף פעולה עם לקוחות כדי לעזור להם לבנות יישומים מעוצבים היטב בפלטפורמת AWS, ומוקדש לפתרון אתגרים טכנולוגיים וסיוע במסע הענן שלהם.
 מאדור פראשנט עובד בחלל ה-AI הגנרטיבי ב-AWS. הוא נלהב מההצטלבות בין החשיבה האנושית ובינה מלאכותית. תחומי העניין שלו טמונים בבינה מלאכותית גנרטיבית, במיוחד בבניית פתרונות מועילים ולא מזיקים, ובעיקר אופטימליים ללקוחות. מחוץ לעבודה, הוא אוהב לעשות יוגה, לטייל, לבלות עם התאום שלו ולנגן בגיטרה.
מאדור פראשנט עובד בחלל ה-AI הגנרטיבי ב-AWS. הוא נלהב מההצטלבות בין החשיבה האנושית ובינה מלאכותית. תחומי העניין שלו טמונים בבינה מלאכותית גנרטיבית, במיוחד בבניית פתרונות מועילים ולא מזיקים, ובעיקר אופטימליים ללקוחות. מחוץ לעבודה, הוא אוהב לעשות יוגה, לטייל, לבלות עם התאום שלו ולנגן בגיטרה.
 דיואן צ'ודהורי הוא מהנדס פיתוח תוכנה עם שירותי האינטרנט של אמזון. הוא עובד על האלגוריתמים של אמזון SageMaker ועל הצעות JumpStart. מלבד בניית תשתיות AI/ML, הוא גם נלהב מבניית מערכות מבוזרות ניתנות להרחבה.
דיואן צ'ודהורי הוא מהנדס פיתוח תוכנה עם שירותי האינטרנט של אמזון. הוא עובד על האלגוריתמים של אמזון SageMaker ועל הצעות JumpStart. מלבד בניית תשתיות AI/ML, הוא גם נלהב מבניית מערכות מבוזרות ניתנות להרחבה.
 האו ג'ו הוא מדען מחקר עם Amazon SageMaker. לפני כן, הוא עבד על פיתוח שיטות למידת מכונה לזיהוי הונאה עבור Amazon Fraud Detector. הוא נלהב ליישם למידת מכונה, אופטימיזציה וטכניקות בינה מלאכותית מחוללת לבעיות שונות בעולם האמיתי. הוא בעל תואר דוקטור בהנדסת חשמל מאוניברסיטת נורת'ווסטרן.
האו ג'ו הוא מדען מחקר עם Amazon SageMaker. לפני כן, הוא עבד על פיתוח שיטות למידת מכונה לזיהוי הונאה עבור Amazon Fraud Detector. הוא נלהב ליישם למידת מכונה, אופטימיזציה וטכניקות בינה מלאכותית מחוללת לבעיות שונות בעולם האמיתי. הוא בעל תואר דוקטור בהנדסת חשמל מאוניברסיטת נורת'ווסטרן.
 צ'ינג לאן הוא מהנדס פיתוח תוכנה ב-AWS. הוא עבד על כמה מוצרים מאתגרים באמזון, כולל פתרונות ML ביצועים גבוהים ומערכת רישום ביצועים גבוהים. הצוות של צ'ינג השיק בהצלחה את המודל הראשון של מיליארד פרמטרים בפרסום באמזון עם זמן אחזור נמוך מאוד. לצ'ינג יש ידע מעמיק באופטימיזציית התשתית והאצת הלמידה העמוקה.
צ'ינג לאן הוא מהנדס פיתוח תוכנה ב-AWS. הוא עבד על כמה מוצרים מאתגרים באמזון, כולל פתרונות ML ביצועים גבוהים ומערכת רישום ביצועים גבוהים. הצוות של צ'ינג השיק בהצלחה את המודל הראשון של מיליארד פרמטרים בפרסום באמזון עם זמן אחזור נמוך מאוד. לצ'ינג יש ידע מעמיק באופטימיזציית התשתית והאצת הלמידה העמוקה.
 ד"ר אשיש חתן הוא מדען יישומי בכיר עם אלגוריתמים מובנים של Amazon SageMaker ועוזר בפיתוח אלגוריתמים של למידת מכונה. הוא קיבל את הדוקטורט שלו מאוניברסיטת אילינוי אורבנה-שמפיין. הוא חוקר פעיל בלמידת מכונה והסקה סטטיסטית, ופרסם מאמרים רבים בכנסים NeurIPS, ICML, ICLR, JMLR, ACL ו-EMNLP.
ד"ר אשיש חתן הוא מדען יישומי בכיר עם אלגוריתמים מובנים של Amazon SageMaker ועוזר בפיתוח אלגוריתמים של למידת מכונה. הוא קיבל את הדוקטורט שלו מאוניברסיטת אילינוי אורבנה-שמפיין. הוא חוקר פעיל בלמידת מכונה והסקה סטטיסטית, ופרסם מאמרים רבים בכנסים NeurIPS, ICML, ICLR, JMLR, ACL ו-EMNLP.
 ד"ר לי ג'אנג הוא מנהל מוצר ראשי-טכני עבור אלגוריתמים מובנים של Amazon SageMaker JumpStart ו-Amazon SageMaker, שירות המסייע למדעני נתונים ומתרגלי למידת מכונה להתחיל בהדרכה ופריסה של המודלים שלהם, ומשתמש בלימוד חיזוק עם Amazon SageMaker. עבודתו בעבר כחבר צוות מחקר ראשי וממציא מאסטר ב-IBM Research זכתה בפרס מבחן הזמן ב-IEEE INFOCOM.
ד"ר לי ג'אנג הוא מנהל מוצר ראשי-טכני עבור אלגוריתמים מובנים של Amazon SageMaker JumpStart ו-Amazon SageMaker, שירות המסייע למדעני נתונים ומתרגלי למידת מכונה להתחיל בהדרכה ופריסה של המודלים שלהם, ומשתמש בלימוד חיזוק עם Amazon SageMaker. עבודתו בעבר כחבר צוות מחקר ראשי וממציא מאסטר ב-IBM Research זכתה בפרס מבחן הזמן ב-IEEE INFOCOM.
 קמרן חאן, ראש פיתוח עסקי טכני עבור AWS Inferentina/Trianium ב-AWS. יש לו למעלה מעשור של ניסיון בסיוע ללקוחות לפרוס ולייעל אימון למידה עמוקה ועומסי עבודה מסקנות באמצעות AWS Inferentia ו-AWS Trainium.
קמרן חאן, ראש פיתוח עסקי טכני עבור AWS Inferentina/Trianium ב-AWS. יש לו למעלה מעשור של ניסיון בסיוע ללקוחות לפרוס ולייעל אימון למידה עמוקה ועומסי עבודה מסקנות באמצעות AWS Inferentia ו-AWS Trainium.
 ג'ו סנרצ'יה הוא מנהל מוצר בכיר ב-AWS. הוא מגדיר ובונה מופעי אמזון EC2 ללמידה עמוקה, בינה מלאכותית ועומסי עבודה מחשוב בעלי ביצועים גבוהים.
ג'ו סנרצ'יה הוא מנהל מוצר בכיר ב-AWS. הוא מגדיר ובונה מופעי אמזון EC2 ללמידה עמוקה, בינה מלאכותית ועומסי עבודה מחשוב בעלי ביצועים גבוהים.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/
- :יש ל
- :הוא
- :לֹא
- :איפה
- $ למעלה
- 000
- 1
- 10
- 100
- 11
- 12
- 121
- 13
- 15%
- 16
- 19
- 1996
- 2001
- 2006
- 2016
- 2018
- 25
- 30
- 36
- 3d
- 40
- 60
- 610
- 65
- 7
- 8
- 9
- a
- יכולת
- יכול
- אודות
- האצה
- לְקַבֵּל
- קביל
- מקובל
- גישה
- דיוק
- מדויק
- הודה
- ACM
- פעיל
- פעילויות
- אדם
- להסתגל
- הסתגלות
- מותאם
- להוסיף
- תוספת
- מבוגרים
- מתקדם
- קידום
- פרסום
- לאחר
- הסכם
- AI
- דגמי AI
- AI / ML
- אלגוריתמים
- תעשיות
- להתיר
- מותר
- מאפשר
- גם
- אמזון בעברית
- אמזון
- גלאי הונאות של אמזון
- אמזון SageMaker
- אמזון SageMaker JumpStart
- אמזון שירותי אינטרנט
- בין
- an
- אנליזה
- עתיק
- ו
- בעלי חיים
- להכריז
- אחר
- כל
- יותר
- אַפָּשׁ
- בנפרד
- ישים
- בקשה
- יישומים
- יישומית
- מריחה
- כראוי
- בערך
- ארכיטקטורה
- ARE
- AREA
- אזורים
- טענה
- צָבָא
- הגיע
- אמנות
- מלאכותי
- בינה מלאכותית
- AS
- סיוע
- עמותה
- At
- דיילות
- תכונות
- רשויות
- מחברים
- אוטומטי
- זמינות
- זמין
- לְהִמָנַע
- AWS
- Afer Inferentia
- b
- מבוסס
- BE
- קרן
- כי
- להיות
- היה
- לפני
- להיות
- תאמינו
- להלן
- בֵּין
- מעבר
- הגדול ביותר
- ביולוגיה
- בלוג
- נולד
- שניהם
- אריזה מקורית
- רחב
- לִבנוֹת
- בִּניָן
- בונה
- מובנה
- עסקים
- פיתוח עסקי
- אבל
- לַחְצָן
- כפתורים
- by
- שיחה
- הגיע
- CAN
- יכולות
- הון
- כרטיס
- נשא
- מקרה
- מקרים
- קטגוריות
- קטגוריה
- האתגרים
- אתגר
- שינוי
- תוהו ובוהו
- צ'אט
- רֹאשׁ
- בחירה
- בחרו
- בחירה
- כריסטופר
- עִיר
- אזרחי
- בהירות
- כיתות
- קלאסי
- מיון
- לְנַקוֹת
- ענן
- קיבוץ
- קוד
- קר
- הוועדה
- Common
- הקהילות
- קהילה
- חברה
- לעומת
- השוואה
- השוואות
- השלמת
- הושלם
- חישובית
- מחשוב
- מסקנה
- במקביל
- לנהל
- כנס
- כנסים
- תְצוּרָה
- לאשר
- קונסול
- להכיל
- מכולה
- מכיל
- תוכן
- הקשר
- הקשרים
- תרומות
- לִשְׁלוֹט
- בקרות
- עלות
- יקר
- עלויות
- מדינה
- נוצר
- כתר
- מכריע
- תרבותי
- כוס
- לקוח
- חווית לקוח
- לקוחות
- התאמה אישית
- נתונים
- מערכי נתונים
- תַאֲרִיך
- de
- עָשׂוֹר
- דֵצֶמבֶּר
- פענוח
- מוקדש
- עמוק
- למידה עמוקה
- באופן מעמיק
- בְּרִירַת מֶחדָל
- מגדיר
- תואר
- למסור
- דֵמוֹקרָטִי
- להפגין
- מופגן
- מדגים
- תלוי
- תלוי
- לפרוס
- פרס
- פריסה
- פריסה
- מתאר
- תיאור
- יעוד
- מעוצב
- מְפוֹרָט
- פרטים
- איתור
- לפתח
- מתפתח
- צעצועי התפתחות
- דיאלוג
- DID
- הבדל
- אחר
- לגלות
- תגלית
- לדון
- לְהַצִיג
- מופץ
- מערכות מבוזרות
- שונה
- עושה
- עושה
- מַבחֵשׁ
- תחום
- תחומים
- לא
- מטה
- כל אחד
- מוקדם
- רווחים
- להקל
- קלות שימוש
- עורך
- אפקטיבי
- יְעִילוּת
- יעיל
- או
- נבחר
- הנדסת חשמל
- אימפריה
- מופעל
- מאפשר
- מה שמאפשר
- סוף
- מקצה לקצה
- נקודת קצה
- מהנדס
- הנדסה
- להגביר את
- שיפור
- מספיק
- מבטיח
- מִפְעָל
- פתרונות ארגוניים
- סביבה
- סביבתי
- שווה
- שווים
- במיוחד
- Ether (ETH)
- להעריך
- הערכה
- ברור
- דוגמה
- דוגמאות
- נרגש
- לְמַעֵט
- קיימים
- ניסיון
- מנוסה
- ניסיוני
- לחקור
- היכרות
- הוֹצָאָה
- ליפול
- שקר
- מהר יותר
- בחור
- פסטיבלים
- מעטים
- שדות
- שלח
- קבצים
- תיוק
- כספי
- שירותים פיננסיים
- סוף
- ראשון
- גמישות
- לָצוּף
- להתמקד
- מתמקד
- הבא
- כדלקמן
- בעד
- להכריח
- פוּרמָט
- מצא
- קרן
- נוסד
- מסגרת
- מסגרות
- הונאה
- גילוי הונאה
- החל מ-
- פונקציה
- נוסף
- נוצר
- מייצר
- דור
- גנרטטיבית
- AI Generative
- לקבל
- Go
- אל
- טוב
- קבל
- בוגר
- גרף
- גרפים
- יותר
- יון
- חמדן
- יוונית
- קְבוּצָה
- הדרכה
- גיטרה
- היה
- טיפול
- ידיים
- שמח
- יש
- he
- בריאות
- הוחזק
- לעזור
- מועיל
- עזרה
- עוזר
- גָבוֹהַ
- ביצועים גבוהים
- גבוה יותר
- הגבוה ביותר
- פסים
- טיולים
- לו
- שֶׁלוֹ
- מחזיק
- איך
- איך
- אולם
- HTML
- http
- HTTPS
- בן אנוש
- i
- יבמ
- כיל
- לזהות
- מזהה
- IEEE
- if
- ii
- אילינוי
- הפעלה
- לייבא
- חשוב
- לשפר
- משופר
- השבחה
- שיפורים
- in
- מעמיק
- לכלול
- כולל
- כולל
- להגדיל
- מצביע על
- מידע
- מיצוי מידע
- תשתית
- תשתית
- קלט
- תשומות
- למשל
- מקרים
- הוראות
- משולב
- מוֹדִיעִין
- אינטרסים
- מִמְשָׁק
- ברמה בינלאומית
- הִצטַלְבוּת
- אל תוך
- מעורב
- IT
- שֶׁלָה
- ג'יימס
- עבודה
- מקומות תעסוקה
- הצטרף
- יהונתן
- כתב עת
- מסע
- jpg
- ג'סון
- רק
- מפתח
- מלכות
- ערכה
- ערכה (SDK)
- ידע
- ידוע
- נחיתה
- דף נחיתה
- שפה
- גָדוֹל
- בקנה מידה גדול
- חֶבִיוֹן
- מאוחר יותר
- הושק
- חוקים
- מוביל
- למידה
- אורך
- li
- רישיון
- רישיונות
- שקר
- החיים
- כמו
- סְבִירוּת
- סביר
- הגבלה
- קו
- קווים
- קשר
- רשימה
- ברשימה
- לאמה
- לִטעוֹן
- מקומי
- רישום
- ארוך
- נראה
- אוהב
- נמוך
- להוריד
- הורדה
- הנמוך ביותר
- מכונה
- למידת מכונה
- עשוי
- ראשי
- לעשות
- עשייה
- מנהל
- ניהול
- מנאן שה
- רב
- אב
- מקסימום
- מאי..
- משמעות
- לִפְגוֹשׁ
- חבר
- meta
- שיטה
- שיטות
- MEXICO
- יכול
- מייק
- אכפת לי
- ML
- מודל
- דוגמנות
- מודלים
- שונים
- לשנות
- יותר
- רוב
- נִרגָשׁ
- כלי נגינה
- צריך
- שם
- טבעי
- שפה טבעית
- עיבוד שפה טבעית
- נווט
- ניווט
- צורך
- צרכי
- NeurIPS
- חדש
- הבא
- NLP
- אוניברסיטת נורת'ווסטרן
- מחברה
- מחשבים ניידים
- עַכשָׁיו
- מספר
- מספרים
- אובייקט
- יעדים
- of
- הַצָעָה
- הצעה
- הצעות
- המיוחדות שלנו
- לעתים קרובות
- זקן
- מבוגר
- on
- פעם
- ONE
- רק
- אופטימלי
- אופטימיזציה
- מטב
- אופטימיזציה
- מיטוב
- אפשרות
- or
- ארגון
- אחר
- תפוקה
- בחוץ
- בולט
- יותר
- שֶׁלוֹ
- חבילות
- עמוד
- זוג
- מְזוּוָג
- זגוגית
- מאמר
- ניירות
- מקביל
- פרמטרים
- חלק
- במיוחד
- צדדים
- מעבר
- לוהט
- עבר
- עבור
- לבצע
- ביצועים
- תקופה
- אישית
- דוקטורט
- צינור
- פלטפורמה
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- משחק
- אנא
- נקודה
- מדיניות
- מדיניות
- פוליטי
- מוקפץ
- פופולרי
- חיובי
- אפשרויות
- אפשרי
- הודעה
- חזק
- קודם
- דיוק
- העריכה
- יְסוֹדִי
- מנהל
- הסתברות
- בעיות
- תהליך
- תהליך
- המוצר
- מנהל מוצר
- מוצרים
- קניינית
- לספק
- ספקים
- מספק
- בפומבי
- לאור
- גם
- פיתון
- פיטורך
- איכות
- שאלה
- אקראי
- לְהַגִיעַ
- מגיע
- חומר עיוני
- מוכן
- ממשי
- עולם אמיתי
- זמן אמת
- טעם
- סיבות
- רשום
- להתייחס
- התייחסות
- פליטים
- שוחרר
- הרלוונטיות
- רלוונטי
- עבר דירה
- נשאר
- שְׂרִידִים
- חזר
- חוזר על עצמו
- להחליף
- מאגר
- לייצג
- המייצג
- לבקש
- בקשות
- נדרש
- מחקר
- חוקר
- משאבים
- בהתאמה
- תגובה
- תגובות
- אחראי
- וכתוצאה מכך
- תוצאות
- לַחֲזוֹר
- סקירה
- ביקורת
- חָסוֹן
- גִלגוּל
- מלכותי
- הפעלה
- רוסיה
- בעל חכמים
- בקרת מערכות ותקשורת
- להרחבה
- סולם
- תרחישים
- מַדְעָן
- מדענים
- סקריפטים
- Sdk
- חיפוש
- חיפוש
- ה-SEC
- הגשת SEC
- שְׁנִיָה
- סעיף
- אבטחה
- לִרְאוֹת
- לחצני מצוקה לפנסיונרים
- נשלח
- משפט
- רגש
- נפרד
- רצף
- סדרה
- סדרה א '
- שרות
- שירותים
- סט
- הצבה
- הגדרות
- כמה
- קצר
- צריך
- לְהַצִיג
- הראה
- הופעות
- משמעותי
- פָּשׁוּט
- since
- יחיד
- מידה
- קטע
- So
- חֶברָה
- תוכנה
- פיתוח תוכנה
- ערכת פיתוח תוכנה
- הנדסת תוכנה
- פִּתָרוֹן
- פתרונות
- פותר
- כמה
- שלה
- מָקוֹר
- דרום
- סובייטית
- מֶרחָב
- מיוחד
- ספציפי
- במיוחד
- ספֵּצִיפִיוּת
- מפורט
- הוצאה
- לפצל
- סגל
- התחלה
- החל
- מדינה
- סטטיסטי
- מצב
- היגוי
- שלב
- צעדים
- עוצר
- אחסון
- מובנה
- סטודנטים
- מְחוֹשָׁב
- מחקרים
- סטודיו
- בהצלחה
- כזה
- תמיכה
- נתמך
- בטוח
- שוויץ
- מערכת
- מערכות
- שולחן
- מותאם
- המשימות
- משימות
- הוראה
- נבחרת
- טכני
- טכניקה
- טכניקות
- טכנולוגיה
- תבנית
- טנסי
- מונחים
- מבחן
- טֶקסט
- סיווג טקסט
- דור טקסט
- מֵאֲשֶׁר
- זֶה
- השמיים
- האזור
- עיר הבירה
- תיאטרון
- שֶׁלָהֶם
- אותם
- אז
- שם.
- אלה
- הֵם
- חושב
- צד שלישי
- זֶה
- אלה
- דרך
- תפוקה
- נמרים
- זמן
- פִּי
- ל
- היום
- אסימון
- מטבעות
- כלים
- סה"כ
- רכבת
- מְאוּמָן
- הדרכה
- שנאי
- תרגום
- נָכוֹן
- לנסות
- תאום
- שתיים
- סוג
- ui
- תחת
- בְּסִיסִי
- ייחודי
- אוניברסיטאות
- אוניברסיטה
- עד
- עדכון
- עדכונים
- נוֹהָג
- להשתמש
- במקרה להשתמש
- מְשׁוּמָשׁ
- משתמש
- משתמשים
- שימושים
- באמצעות
- מנצל
- אוזבקיסטן
- אימות
- ערך
- מגוון
- שונים
- גרסה
- מאוד
- באמצעות
- לצפיה
- גפן
- חזותי
- ללכת
- רוצה
- מִלחָמָה
- היה
- דרכים
- we
- אינטרנט
- שירותי אינטרנט
- המבוסס על האינטרנט
- הלכתי
- היו
- מתי
- אשר
- בזמן
- מי
- יצטרך
- יַיִן
- עם
- נצחנות
- Word
- מילים
- תיק עבודות
- עבד
- עובד
- עובד
- סדנה
- עוֹלָם
- היה
- לכתוב
- שנה
- יוגה
- אתה
- נוֹעַר
- זפירנט
- זאוס