האדום של אמזון הוא מחסן נתונים בענן מנוהל במלואו ובקנה מידה פטה-בייט, המשמש עשרות אלפי לקוחות לעיבוד אקס-בייט של נתונים מדי יום כדי להפעיל את עומס העבודה הניתוחי שלהם. אתה יכול לבנות את הנתונים שלך, למדוד תהליכים עסקיים, ולקבל תובנות חשובות במהירות, ניתן לעשות באמצעות מודל ממדי. Amazon Redshift מספקת תכונות מובנות כדי להאיץ את תהליך המידול, התזמור והדיווח ממודל ממדי.
בפוסט זה, אנו דנים כיצד ליישם מודל ממדי, במיוחד את מתודולוגיה של קימבל. אנו דנים ביישום ממדים ועובדות בתוך אמזון Redshift. אנו מראים כיצד לבצע חילוץ, טרנספורמציה וטעינה (ELT), תהליך אינטגרציה המתמקד בהשגת הנתונים הגולמיים מאגם נתונים לשכבת היערכות לביצוע המודלים. בסך הכל, הפוסט ייתן לך הבנה ברורה כיצד להשתמש במודלים ממדיים באמזון Redshift.
סקירת פתרונות
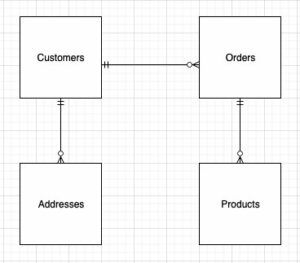
התרשים הבא ממחיש את ארכיטקטורת הפתרונות.

בסעיפים הבאים, תחילה נדון ומדגים את ההיבטים המרכזיים של המודל הממדיים. לאחר מכן, אנו יוצרים חנות נתונים באמצעות Amazon Redshift עם מודל נתונים ממדי הכולל טבלאות מימד ועובדות. הנתונים נטענים ומבויימים באמצעות ה COPY הפקודה, הנתונים בממדים נטענים באמצעות ה- מיזוג הצהרה, ועובדות יצטרפו לממדים שמהם נגזרות תובנות. אנו מתזמנים את טעינת המידות והעובדות באמצעות ה Amazon Redshift Query Editor V2. לבסוף, אנו משתמשים אמזון קוויקסייט כדי לקבל תובנות על הנתונים המודלים בצורה של לוח מחוונים של QuickSight.
עבור פתרון זה, אנו משתמשים במערך נתונים לדוגמה (מנורמל) שסופק על ידי Amazon Redshift למכירת כרטיסים לאירועים. עבור פוסט זה, צמצמנו את מערך הנתונים למטרות פשטות והדגמה. הטבלאות הבאות מציגות דוגמאות לנתונים עבור מכירת כרטיסים ומקומות.


על פי מתודולוגיית המודלים המימדיים של קימבל, ישנם ארבעה שלבים מרכזיים בתכנון מודל ממדי:
- זיהוי התהליך העסקי.
- הצהר על גרעין הנתונים שלך.
- זיהוי ויישום הממדים.
- זהה ויישם את העובדות.
בנוסף, אנו מוסיפים שלב חמישי למטרות הדגמה, שהוא דיווח וניתוח אירועים עסקיים.
תנאים מוקדמים
לפריצת דרך זו, יהיו עליכם התנאים המוקדמים הבאים:
זיהוי התהליך העסקי
במילים פשוטות, זיהוי התהליך העסקי הוא זיהוי אירוע מדיד שיוצר נתונים בתוך ארגון. בדרך כלל, לחברות יש איזושהי מערכת מקור תפעולית המייצרת את הנתונים שלהן בפורמט הגולמי שלה. זוהי נקודת התחלה טובה לזהות מקורות שונים לתהליך עסקי.
התהליך העסקי נמשך לאחר מכן כמו א נתונים מרט בצורה של מימדים ועובדות. בהסתכלות על מערך הנתונים לדוגמה שלנו שהוזכר קודם לכן, אנו יכולים לראות בבירור שהתהליך העסקי הוא המכירות שנעשו עבור אירוע נתון.
טעות נפוצה שנעשתה היא שימוש במחלקות של חברה כתהליך העסקי. הנתונים (תהליך עסקי) צריכים להיות משולבים על פני מחלקות שונות, במקרה זה, השיווק יכול לגשת לנתוני המכירות. זיהוי התהליך העסקי הנכון הוא קריטי - טעות בצעד זה עלולה להשפיע על כל שוק הנתונים (היא עלולה לגרום לשכפול הגרעין ולמדדים שגויים בדוחות הסופיים).
הצהר על גרעין הנתונים שלך
הכרזה על התבואה היא הפעולה של זיהוי ייחודי של רשומה במקור הנתונים שלך. הגרגר משמש בטבלת העובדות כדי למדוד במדויק את הנתונים ולאפשר לך להתגלגל הלאה. בדוגמה שלנו, זה יכול להיות פריט שורה בתהליך העסקי של המכירה.
במקרה השימוש שלנו, ניתן לזהות מכירה באופן ייחודי על ידי הסתכלות על זמן העסקה שבו התרחשה המכירה; זו תהיה הרמה האטומית ביותר.

זיהוי ויישום הממדים
טבלת הממדים שלך מתארת את טבלת העובדות שלך ואת התכונות שלה. כשאתה מזהה את ההקשר התיאורי של התהליך העסקי שלך, אתה מאחסן את הטקסט בטבלה נפרדת, תוך שמירה על גרעין טבלת העובדות. בעת צירוף טבלת הממדים לטבלת העובדות, צריכה להיות רק שורה אחת המשויכת לטבלת העובדות. בדוגמה שלנו, אנו משתמשים בטבלה הבאה כדי להפריד לטבלת מידות; שדות אלו מתארים את העובדות שאנו נמדוד.
בעת תכנון המבנה של המודל הממדיים (הסכמה), אתה יכול ליצור א כוכב or פְּתִית שֶׁלֶג סכֵימָה. המבנה צריך להתאים באופן הדוק לתהליך העסקי; לכן, סכימת כוכבים מתאימה ביותר לדוגמא שלנו. האיור הבא מציג את דיאגרמת יחסי הישות שלנו (ERD).

בסעיפים הבאים נפרט את השלבים ליישום הממדים.
שלב את נתוני המקור
לפני שנוכל ליצור ולטעון את טבלת המידות, אנו זקוקים לנתוני מקור. לכן, אנו משלבים את נתוני המקור לטבלה או טבלה זמנית. זה מכונה לעתים קרובות בשם שכבת הבמה, שהוא העותק הגולמי של נתוני המקור. כדי לעשות זאת ב- Amazon Redshift, אנו משתמשים ב- פקודת COPY כדי לטעון את הנתונים מהדלי הציבורי S3 הממוקם על us-east-1 אזור. שים לב שהפקודה COPY משתמשת ב- AWS זהות וניהול גישה (IAM) תפקיד עם גישה לאמזון S3. התפקיד צריך להיות הקשורים לאשכול. השלם את השלבים הבאים כדי לשלב את נתוני המקור:
- צור את
venueטבלת מקור:
- טען את נתוני המקום:
- צור את
salesטבלת מקור:
- טען את נתוני מקור המכירות:
- צור את
calendarשולחן:
- טען את נתוני היומן:
צור את טבלת המידות
עיצוב טבלת המידות יכול להיות תלוי בדרישה העסקית שלך - לדוגמה, האם עליך לעקוב אחר שינויים בנתונים לאורך זמן? יש שבעה סוגי מימדים שונים. עבור הדוגמה שלנו, אנו משתמשים הקלד 1 כי אנחנו לא צריכים לעקוב אחר שינויים היסטוריים. למידע נוסף על סוג 2, עיין ב פשט את טעינת הנתונים לממדים מסוג 2 המשתנים באיטיות באמזון Redshift. טבלת הממדים תבוטל עם מפתח ראשי, מפתח תחליף וכמה שדות נוספים כדי לציין שינויים בטבלה. ראה את הקוד הבא:
כמה הערות על יצירת טבלת מידות:
- שמות השדות הופכים לשמות ידידותיים לעסקים
- המפתח העיקרי שלנו הוא
VenueID, שבו אנו משתמשים כדי לזהות באופן ייחודי מקום בו התקיימה המכירה - יתווספו שתי שורות נוספות, המציינות מתי הוספה ועודכנה רשומה (כדי לעקוב אחר שינויים)
- אנו משתמשים ב-an סגנון הפצה אוטומטי לתת לאמזון Redshift את האחריות לבחור ולהתאים את סגנון ההפצה
גורם חשוב נוסף שיש לקחת בחשבון בדוגמנות ממדי הוא השימוש בו מפתחות פונדקאית. מפתחות סרוגייט הם מפתחות מלאכותיים המשמשים במודלים ממדיים כדי לזהות באופן ייחודי כל רשומה בטבלת ממדים. הם בדרך כלל נוצרים כמספר שלם רציף, ואין להם שום משמעות בתחום העסקי. הם מציעים מספר יתרונות, כמו הבטחת ייחודיות ושיפור ביצועים בחיבורים, מכיוון שהם בדרך כלל קטנים יותר ממפתחות טבעיים וכמפתחות פונדקאים הם לא משתנים עם הזמן. זה מאפשר לנו להיות עקביים ולהצטרף לעובדות וממדים ביתר קלות.
ב-Amazon Shift, מפתחות פונדקאים נוצרים בדרך כלל באמצעות מילת המפתח IDENTITY. לדוגמה, הצהרת CREATE הקודמת יוצרת טבלת מימדים עם a VenueSkey מפתח פונדקאות. ה VenueSkey העמודה מאוכלסת אוטומטית בערכים ייחודיים כאשר שורות חדשות מתווספות לטבלה. לאחר מכן ניתן להשתמש בעמודה זו כדי להצטרף לשולחן המקום ל- FactSaleTransactions השולחן.
כמה טיפים לעיצוב מפתחות פונדקאים:
- השתמש בסוג נתונים קטן ברוחב קבוע עבור מפתח הפונדקאי. זה ישפר את הביצועים ויפחית את שטח האחסון.
- השתמש במילת המפתח IDENTITY, או צור את מפתח הפונדקאי באמצעות ערך רציף או GUID. זה יבטיח שמפתח הפונדקאי יהיה ייחודי ולא ניתן לשינוי.
טען את הטבלה העמומה באמצעות MERGE
ישנן דרכים רבות לטעון את השולחן העמום שלך. יש לקחת בחשבון גורמים מסוימים - לדוגמה, ביצועים, נפח נתונים ואולי זמני טעינת SLA. עם ה מיזוג הצהרה, אנו מבצעים upsert ללא צורך לציין מספר פקודות הוספה ועדכון. אתה יכול להגדיר את מיזוג הצהרה א הליך מאוחסן כדי לאכלס את הנתונים. לאחר מכן, אתה מתזמן את ההליך המאוחסן לפעול באופן תוכנתי דרך עורך השאילתות, אותו אנו מדגימים בהמשך הפוסט. הקוד הבא יוצר פרוצדורה מאוחסנת בשם SalesMart.DimVenueLoad:
כמה הערות לגבי טעינת הממדים:
- כאשר רשומה הוכנסה בפעם הראשונה, התאריך שהוכנס והתאריך המעודכן יאוכלסו. כאשר ערכים משתנים, הנתונים מתעדכנים והתאריך המעודכן משקף את התאריך שבו הם שונו. התאריך שהוכנס נשאר.
- מכיוון שהנתונים ישמשו משתמשים עסקיים, עלינו להחליף ערכי NULL, אם קיימים, בערכים מתאימים יותר לעסק.
זהה ויישם את העובדות
כעת, לאחר שהכרזנו על התבואה שלנו כאירוע של מכירה שהתקיימה בזמן מסוים, טבלת העובדות שלנו תשמור את העובדות המספריות עבור התהליך העסקי שלנו.
זיהינו את העובדות המספריות הבאות למדידה:
- כמות הכרטיסים שנמכרה בכל מכירה
- עמלה על המכירה
יישום העובדה
יש שלושה סוגים של טבלאות עובדות (טבלת עובדות עסקאות, טבלת עובדות תקופתית של תמונת מצב וטבלת עובדות של תמונת מצב מצטברת). כל אחת מהן משרתת מבט שונה על התהליך העסקי. לדוגמא שלנו, אנו משתמשים בטבלת עובדות עסקאות. השלם את השלבים הבאים:
- צור את טבלת העובדות
נוסף תאריך מוכנס עם ערך ברירת מחדל, המציין אם ומתי נרשמה רשומה. אתה יכול להשתמש בזה בעת טעינה מחדש של טבלת העובדות כדי להסיר את הנתונים שכבר נטענו כדי למנוע כפילויות.
טעינת טבלת העובדות מורכבת מהצהרת הוספה פשוטה המצטרפת לממדים המשויכים שלך. אנחנו מצטרפים מה DimVenue טבלה שנוצרה, המתארת את העובדות שלנו. זה השיטה הטובה ביותר אבל אופציונלי תאריך לוח שנה ממדים, המאפשרים למשתמש הקצה לנווט בטבלת העובדות. ניתן לטעון נתונים כאשר יש מבצע חדש, או מדי יום; זה המקום שבו התאריך שהוכנס או תאריך הטעינה שימושיים.
אנו טוענים את טבלת העובדות באמצעות פרוצדורה מאוחסנת ומשתמשים בפרמטר תאריך.
- צור את ההליך המאוחסן עם הקוד הבא. כדי לשמור על אותה שלמות נתונים שהחלנו בעומס הממדים, אנו מחליפים ערכי NULL, אם קיימים, בערכים מתאימים יותר לעסקים:
- טען את הנתונים על ידי קריאה לפרוצדורה עם הפקודה הבאה:
תזמן את טעינת הנתונים
כעת אנו יכולים להפוך את תהליך הדוגמנות לאוטומטי על ידי תזמון ההליכים המאוחסנים ב-Amazon Redshift Query Editor V2. השלם את השלבים הבאים:
- אנו קוראים תחילה לעומס הממדים ולאחר שעומס הממדים פועל בהצלחה, עומס העובדה מתחיל:
אם עומס הממדים נכשל, עומס העובדות לא יפעל. זה מבטיח עקביות בנתונים מכיוון שאנחנו לא רוצים לטעון את טבלת העובדות עם ממדים מיושנים.
- כדי לתזמן את הטעינה, בחר לוח זמנים בעורך שאילתות V2.

- אנו מתזמנים את השאילתה לפעול כל יום בשעה 5:00 בבוקר.
- לחלופין, תוכל להוסיף התראות על כשל על ידי הפעלה שירות התראה פשוט של אמזון הודעות (Amazon SNS).

דווח וניתוח הנתונים באמזון קוויקסייט
QuickSight הוא שירות בינה עסקית המקל על מתן תובנות. כשירות מנוהל במלואו, QuickSight מאפשרת לך ליצור ולפרסם בקלות לוחות מחוונים אינטראקטיביים שניתן לגשת אליהם מכל מכשיר ולהטמיע אותם באפליקציות, בפורטלים ובאתרי האינטרנט שלך.
אנו משתמשים ב-Data Mart שלנו כדי להציג חזותית את העובדות בצורה של לוח מחוונים. כדי להתחיל ולהגדיר את QuickSight, עיין ב יצירת מערך נתונים באמצעות מסד נתונים שאינו מתגלה אוטומטית.
לאחר שתיצור את מקור הנתונים שלך ב-QuickSight, אנו מצטרפים את הנתונים המנוסחים (data mart) יחד על סמך מפתח הפונדקאי שלנו skey. אנו משתמשים במערך הנתונים הזה כדי להמחיש את שוק הנתונים.

לוח המחוונים הקצה שלנו יכיל את התובנות של שוק הנתונים ויענה על שאלות עסקיות קריטיות, כגון עמלה כוללת לכל מקום ותאריכים עם המכירות הגבוהות ביותר. צילום המסך הבא מציג את התוצר הסופי של שוק הנתונים.

לנקות את
כדי להימנע מחיובים עתידיים, מחק את כל המשאבים שיצרת כחלק מהפוסט הזה.
סיכום
כעת יישמנו בהצלחה חנות נתונים באמצעות שלנו DimVenue, DimCalendar, ו FactSaleTransactions שולחנות. המחסן שלנו אינו שלם; ככל שנוכל להרחיב את שוק הנתונים עם יותר עובדות וליישם יותר מרצים, וככל שהתהליך העסקי והדרישות יגדלו עם הזמן, כך גם מחסן הנתונים יגדל. בפוסט זה נתנו מבט מקצה לקצה על הבנה והטמעה של מודלים ממדיים באמזון Redshift.
התחל עם שלך האדום של אמזון מודל ממדי היום.
על הכותבים
 ברנרד ורסטר הוא מהנדס ענן מנוסה עם שנים של חשיפה ביצירת מודלים מדרגיים ויעילים של נתונים, הגדרת אסטרטגיות שילוב נתונים והבטחת ממשל ואבטחת נתונים. הוא נלהב להשתמש בנתונים כדי להעלות תובנות, תוך התאמה לדרישות וליעדים העסקיים.
ברנרד ורסטר הוא מהנדס ענן מנוסה עם שנים של חשיפה ביצירת מודלים מדרגיים ויעילים של נתונים, הגדרת אסטרטגיות שילוב נתונים והבטחת ממשל ואבטחת נתונים. הוא נלהב להשתמש בנתונים כדי להעלות תובנות, תוך התאמה לדרישות וליעדים העסקיים.
 אבישק פאן הוא WWSO מומחה SA-Analytics שעובד עם לקוחות במגזר הציבורי של AWS India. הוא מתקשר עם לקוחות כדי להגדיר אסטרטגיה מונעת נתונים, לספק מפגשי צלילה עמוקים על מקרי שימוש בניתוח, ולעצב יישומים אנליטיים ניתנים להרחבה וביצועים. יש לו 12 שנות ניסיון והוא נלהב ממאגרי מידע, אנליטיקה ו-AI/ML. הוא נוסע נלהב ומנסה ללכוד את העולם דרך עדשת המצלמה שלו.
אבישק פאן הוא WWSO מומחה SA-Analytics שעובד עם לקוחות במגזר הציבורי של AWS India. הוא מתקשר עם לקוחות כדי להגדיר אסטרטגיה מונעת נתונים, לספק מפגשי צלילה עמוקים על מקרי שימוש בניתוח, ולעצב יישומים אנליטיים ניתנים להרחבה וביצועים. יש לו 12 שנות ניסיון והוא נלהב ממאגרי מידע, אנליטיקה ו-AI/ML. הוא נוסע נלהב ומנסה ללכוד את העולם דרך עדשת המצלמה שלו.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. רכב / רכבים חשמליים, פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- BlockOffsets. מודרניזציה של בעלות על קיזוז סביבתי. גישה כאן.
- מקור: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :יש ל
- :הוא
- :לֹא
- :איפה
- $ למעלה
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- אודות
- להאיץ
- גישה
- נצפה
- במדויק
- לרוחב
- לפעול
- להוסיף
- הוסיף
- נוסף
- לאחר
- AI / ML
- ליישר
- יישור
- להתיר
- מאפשר
- כְּבָר
- am
- אמזון בעברית
- אמזון שירותי אינטרנט
- an
- אנליזה
- אנליטית
- ניתוח
- לנתח
- ו
- לענות
- כל
- יישומים
- יישומית
- מתאים
- ארכיטקטורה
- ARE
- מלאכותי
- AS
- היבטים
- המשויך
- At
- תכונות
- המכונית
- אוטומטי
- באופן אוטומטי
- לְהִמָנַע
- AWS
- b
- מבוסס
- BE
- כי
- להתחיל
- הטבות
- הטוב ביותר
- מובנה
- עסקים
- מודיעין עסקי
- תהליך עסקי
- תהליכים עסקיים
- אבל
- by
- יומן אירועים
- שיחה
- נקרא
- קוראים
- חדר
- CAN
- ללכוד
- מקרה
- מקרים
- לגרום
- מסוים
- שינוי
- השתנה
- שינויים
- משתנה
- אופי
- חיובים
- בחרו
- ברור
- בבירור
- מקרוב
- ענן
- קוד
- טור
- מגיע
- עמלה
- Common
- חברות
- חברה
- להשלים
- לשקול
- עִקבִי
- מורכב
- הקשר
- לתקן
- יכול
- לִיצוֹר
- נוצר
- יוצר
- יוצרים
- יצירה
- קריטי
- לקוחות
- יומי
- לוח מחוונים
- לוחות מחוונים
- נתונים
- שילוב נתונים
- אגם דאטה
- מחסן נתונים
- נתונים מונחים
- אסטרטגיה מונעת נתונים
- מסד נתונים
- מאגרי מידע
- תַאֲרִיך
- תאריכים
- datetime
- יְוֹם
- עמוק
- צלילה לעומק
- בְּרִירַת מֶחדָל
- הגדרה
- למסור
- להפגין
- מחלקות
- נגזר
- לתאר
- עיצוב
- תכנון
- פרט
- מכשיר
- אחר
- מֵמַד
- ממדים
- לדון
- מובהק
- הפצה
- do
- תחום
- עשה
- לא
- מטה
- נהיגה
- כפילויות
- כל אחד
- מוקדם יותר
- בקלות
- קל
- עורך
- יעיל
- או
- מוטבע
- לאפשר
- מה שמאפשר
- סוף
- מקצה לקצה
- עוסק
- מהנדס
- לְהַבטִיחַ
- מבטיח
- הבטחתי
- שלם
- ישות
- Ether (ETH)
- אירוע
- אירועים
- כל
- כל יום
- דוגמה
- דוגמאות
- לְהַרְחִיב
- ניסיון
- מנוסה
- חשיפה
- תמצית
- עובדה
- גורם
- גורמים
- עובדות
- נכשל
- כשלון
- תכונות
- מעטים
- שדה
- שדות
- ה
- תרשים
- לסנן
- סופי
- ראשון
- firsttime
- מתאים
- מרוכז
- הבא
- בעד
- טופס
- פוּרמָט
- ארבע
- החל מ-
- לגמרי
- נוסף
- עתיד
- לְהַשִׂיג
- ליצור
- נוצר
- מייצר
- לקבל
- מקבל
- לתת
- נתן
- טוב
- ממשל
- לגדול
- שימושי
- יש
- he
- הגבוה ביותר
- שֶׁלוֹ
- היסטורי
- חַג
- איך
- איך
- HTML
- http
- HTTPS
- IAM
- מזוהה
- לזהות
- זיהוי
- זהות
- if
- מדגים
- פְּגִיעָה
- ליישם
- יושם
- יישום
- חשוב
- לשפר
- שיפור
- in
- כולל
- הודו
- להצביע
- המציין
- מידע
- תובנות
- משולב
- השתלבות
- שלמות
- מוֹדִיעִין
- אינטראקטיבי
- אל תוך
- IT
- שֶׁלָה
- להצטרף
- הצטרף
- הצטרפות
- מצטרף
- jpg
- שמור
- שמירה
- מפתח
- מפתחות
- אגם
- שפה
- מאוחר יותר
- האחרון
- שכבה
- עזבו
- Lens
- מאפשר לי
- רמה
- קו
- לִטעוֹן
- טוען
- המון
- ממוקם
- הסתכלות
- עשוי
- עושה
- הצליח
- שיווק
- מתאים
- משמעות
- למדוד
- מוּזְכָּר
- למזג
- מדדים
- אכפת לי
- טעות
- מודל
- דוגמנות
- דוּגמָנוּת
- מודלים
- חוֹדֶשׁ
- יותר
- רוב
- מספר
- שמות
- טבעי
- נווט
- צורך
- צורך
- צרכי
- חדש
- הערות
- הודעה
- הודעות
- עַכשָׁיו
- רב
- יעדים
- of
- הַצָעָה
- לעתים קרובות
- on
- רק
- מבצעי
- or
- ארגון
- שלנו
- יותר
- מקיף
- פרמטר
- חלק
- לוהט
- עבור
- לבצע
- ביצועים
- אוּלַי
- תקופתי
- מקום
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- נקודה
- מְאוּכלָס
- הודעה
- כּוֹחַ
- תרגול
- תנאים מוקדמים
- להציג
- יְסוֹדִי
- הליך
- נהלים
- תהליך
- תהליכים
- המוצר
- לספק
- ובלבד
- מספק
- ציבורי
- לפרסם
- למטרות
- שאלות
- מהירות
- להעלות
- חי
- נתונים גולמיים
- שיא
- רשום
- להפחית
- מכונה
- משקף
- באזור
- קשר
- שְׂרִידִים
- להסיר
- להחליף
- לדווח
- דווח
- דוחות לדוגמא
- דרישות
- משאבים
- אחריות
- תפקיד
- גָלִיל
- שׁוּרָה
- הפעלה
- פועל
- SALE
- מכירות
- אותו
- מערך נתונים לדוגמה
- להרחבה
- לוח זמנים
- תזמון
- סעיפים
- מגזר
- אבטחה
- לִרְאוֹת
- נפרד
- משמש
- שרות
- שירותים
- הפעלות
- סט
- כמה
- צריך
- לְהַצִיג
- הופעות
- פָּשׁוּט
- פשטות
- יחיד
- לאט
- קטן
- קטן יותר
- תמונת בזק
- So
- נמכרים
- פִּתָרוֹן
- כמה
- מָקוֹר
- מקורות
- מֶרחָב
- מומחה
- ספציפי
- במיוחד
- התמחות
- בימוי
- כוכב
- החל
- החל
- הצהרה
- שלב
- צעדים
- אחסון
- חנות
- מאוחסן
- אסטרטגיות
- אִסטרָטֶגִיָה
- מִבְנֶה
- מוצלח
- בהצלחה
- כזה
- מערכת
- שולחן
- זמני
- עשרות
- מונחים
- מֵאֲשֶׁר
- זֶה
- השמיים
- המקור
- העולם
- שֶׁלָהֶם
- אז
- שם.
- לכן
- אלה
- הֵם
- זֶה
- אלפים
- דרך
- כרטיס
- מכירת כרטיסים
- כרטיסים
- זמן
- פִּי
- חותם
- טיפים
- ל
- היום
- יַחַד
- לקח
- סה"כ
- לעקוב
- עסקה
- לשנות
- טרנספורמציה
- נוסע
- סוג
- סוגים
- בדרך כלל
- הבנה
- ייחודי
- באופן ייחודי
- ייחוד
- לא ידוע
- עדכון
- מְעוּדכָּן
- us
- נוֹהָג
- להשתמש
- במקרה להשתמש
- מְשׁוּמָשׁ
- משתמשים
- שימושים
- באמצעות
- בְּדֶרֶך כְּלַל
- בעל ערך
- ערך
- ערכים
- שונים
- מָקוֹם מִפגָשׁ
- התרחשויות
- באמצעות
- לצפיה
- כֶּרֶך
- בהדרכה
- רוצה
- מחסן
- היה
- דרכים
- we
- אינטרנט
- שירותי אינטרנט
- אתרים
- שבוע
- מתי
- אשר
- בזמן
- יצטרך
- עם
- בתוך
- לְלֹא
- עובד
- עוֹלָם
- טעות
- שנה
- שנים
- אתה
- זפירנט