
תמונה מאת המחבר
תוך כדי ניתוח הנתונים, הדבר בראש שלנו הוא למצוא דפוסים נסתרים ולחלץ תובנות משמעותיות. הבה ניכנס לקטגוריה החדשה של למידה מבוססת ML, כלומר, למידה ללא פיקוח, שבה אחד האלגוריתמים החזקים לפתרון משימות האשכולות הוא אלגוריתם האשכולות K-Means שמחולל מהפכה בהבנת הנתונים.
K-Means has become a useful algorithm in machine learning and data mining applications. In this article, we will deep dive into the workings of K-Means, its implementation using Python, and exploring its principles, applications, etc. So, let’s start the journey to unlock the secret patterns and harness the potential of the K-Means clustering algorithm.
האלגוריתם של K-Means משמש לפתרון בעיות האשכולות השייכות לשיעור למידה ללא פיקוח. בעזרת אלגוריתם זה נוכל לקבץ את מספר התצפיות לאשכולות K.
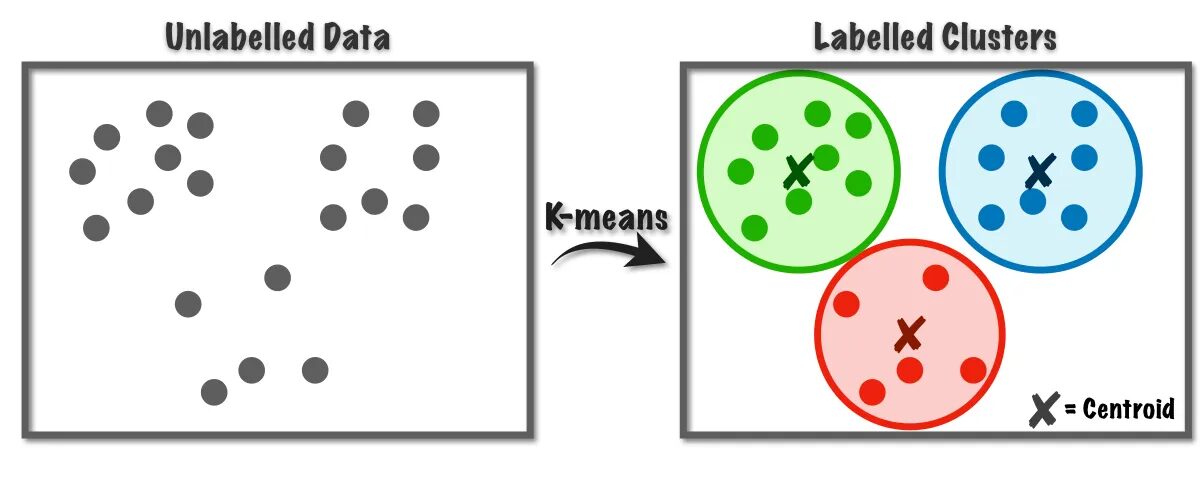
איור 1 K-Means אלגוריתם עובד | תמונה מ לקראת מדעי נתונים
אלגוריתם זה משתמש באופן פנימי בקוונטיזציה וקטורית, באמצעותה נוכל להקצות כל תצפית במערך הנתונים לאשכול עם המרחק המינימלי, שהוא אב הטיפוס של אלגוריתם האשכולות. אלגוריתם אשכולות זה משמש בדרך כלל בכריית נתונים ולמידת מכונה עבור חלוקת נתונים לאשכולות K בהתבסס על מדדי דמיון. לכן, באלגוריתם זה, עלינו למזער את המרחק של סכום הריבועים בין התצפיות והמרכזים התואמים להן, מה שבסופו של דבר מביא לאשכולות מובחנים והומוגניים.
יישומים של K-means Clustering
להלן כמה מהיישומים הסטנדרטיים של אלגוריתם זה. אלגוריתם K-means הוא טכניקה נפוצה במקרים של שימוש תעשייתי לפתרון בעיות הקשורות לאשכולות.
- פילוח לקוחות: K-means clustering יכול לפלח לקוחות שונים על סמך תחומי העניין שלהם. זה יכול להיות מיושם על בנקאות, טלקום, מסחר אלקטרוני, ספורט, פרסום, מכירות וכו '.
- אשכול מסמכים: בטכניקה זו, אנו מועדון מסמכים דומים מתוך סט של מסמכים, וכתוצאה מכך מסמכים דומים באותם אשכולות.
- מנועי המלצה: לפעמים, ניתן להשתמש באשכולות K-means ליצירת מערכות המלצות. לדוגמה, אתה רוצה להמליץ על שירים לחברים שלך. אתה יכול להסתכל על השירים שאוהבים על ידי אותו אדם ולאחר מכן להשתמש באשכולות כדי למצוא שירים דומים ולהמליץ על השירים הדומים ביותר.
יש עוד הרבה יישומים שאני בטוח שכבר חשבת עליהם, אותם אתה כנראה משתף בקטע התגובות מתחת למאמר זה.
בסעיף זה, נתחיל ליישם את האלגוריתם K-Means על אחד מערכי הנתונים באמצעות Python, המשמש בעיקר בפרויקטים של Data Science.
1. ייבוא ספריות ותלויות הכרחיות
ראשית, בואו לייבא את ספריות הפיתון שבהן אנו משתמשים כדי ליישם את אלגוריתם K-means, כולל NumPy, Pandas, Seaborn, Marplotlib וכו'.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb2. טען ונתח את ערכת הנתונים
בשלב זה, נטען את מערך הנתונים של התלמידים על ידי אחסון זה במסגרת הנתונים של Pandas. להורדת מערך הנתונים, אתה יכול לעיין בקישור כאן.
הצינור המלא של הבעיה מוצג להלן:

איור 2 פרויקט צינור | תמונה לפי מחבר
df = pd.read_csv('student_clustering.csv')
print("The shape of data is",df.shape)
df.head()3. עלילת פיזור של מערך הנתונים
עכשיו מגיע השלב של המודלים הוא להמחיש את הנתונים, אז אנחנו משתמשים ב-matplotlib כדי לצייר את עלילת הפיזור כדי לבדוק איך אלגוריתם האשכולות עובד וליצור אשכולות שונים.
# Scatter plot of the dataset
import matplotlib.pyplot as plt
plt.scatter(df['cgpa'],df['iq'])
פלט:
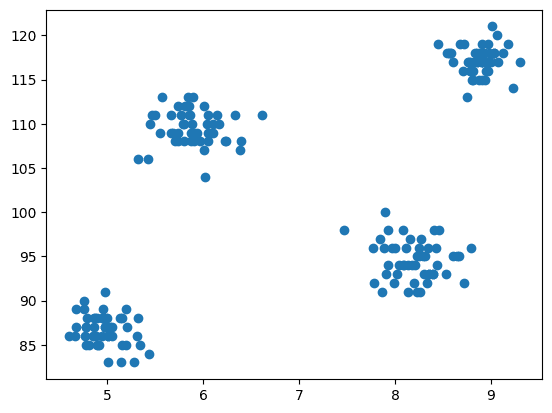
איור 3 עלילת פיזור | תמונה לפי מחבר
4. ייבא את ה-K-Means ממחלקת אשכולות של Scikit-lear
כעת, מכיוון שעלינו ליישם את אשכול K-Means, אנו מייבאים תחילה את מחלקת האשכולות, ולאחר מכן יש לנו את KMeans כמודול של המחלקה הזו.
from sklearn.cluster import KMeans5. מציאת הערך האופטימלי של K באמצעות שיטת המרפק
בשלב זה, נמצא את הערך האופטימלי של K, אחד מפרמטרי ההיפר, תוך יישום האלגוריתם. ערך K מציין כמה אשכולות עלינו ליצור עבור מערך הנתונים שלנו. מציאת ערך זה אינטואיטיבית אינה אפשרית, אז כדי למצוא את הערך האופטימלי, אנו הולכים ליצור עלילה בין WCSS(בתוך אשכול-סכום-ריבועים) לבין ערכי K שונים, ועלינו לבחור את ה-K הזה, אשר נותן לנו את הערך המינימלי של WCSS.
# create an empty list for store residuals
wcss = [] for i in range(1,11): # create an object of K-Means class km = KMeans(n_clusters=i) # pass the dataframe to fit the algorithm km.fit_predict(df) # append inertia value to wcss list wcss.append(km.inertia_)
כעת, בואו נתווה את חלקת המרפק כדי למצוא את הערך האופטימלי של K.
# Plot of WCSS vs. K to check the optimal value of K
plt.plot(range(1,11),wcss)
פלט:
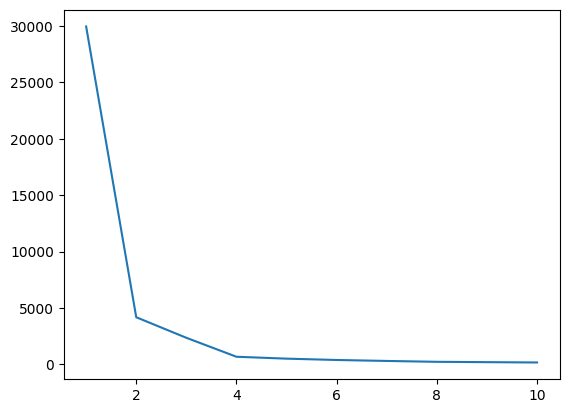
איור.4 חלקת מרפק | תמונה לפי מחבר
מחלקת המרפק לעיל, אנו יכולים לראות ב-K=4; יש ירידה בערך של WCSS, מה שאומר שאם נשתמש בערך האופטימלי כ-4, במקרה כזה, האשכולות תיתן לך ביצועים טובים.
6. התאימו לאלגוריתם K-Means את הערך האופטימלי של K
סיימנו למצוא את הערך האופטימלי של K. כעת, בואו נעשה את המודל שבו ניצור מערך X המאחסן את מערך הנתונים המלא הכולל את כל התכונות. אין צורך להפריד את וקטור המטרה והפיצ'ר כאן, מכיוון שזו בעיה ללא פיקוח. לאחר מכן, ניצור אובייקט של מחלקה KMeans עם ערך K נבחר ואז נתאים אותו למערך הנתונים שסופק. לבסוף, אנו מדפיסים את ה-y_means, המציין את האמצעים של אשכולות שונים שנוצרו.
X = df.iloc[:,:].values # complete data is used for model building
km = KMeans(n_clusters=4)
y_means = km.fit_predict(X)
y_means7. בדוק את הקצאת אשכול של כל קטגוריה
בואו נבדוק אילו כל הנקודות במערך הנתונים שייכות לאיזה אשכול.
X[y_means == 3,1]
עד עכשיו, לאתחול מרכז, השתמשנו באסטרטגיית K-Means++, כעת, בואו נאתחל את המוקדים האקראיים במקום K-Means++ ונשווה את התוצאות על ידי ביצוע אותו תהליך.
km_new = KMeans(n_clusters=4, init='random')
y_means_new = km_new.fit_predict(X)
y_means_new
בדוק כמה ערכים תואמים.
sum(y_means == y_means_new)8. הדמיית האשכולות
כדי לדמיין כל אשכול, אנו משרטטים אותם על הצירים ומקצים צבעים שונים דרכם נוכל לראות בקלות 4 אשכולות שנוצרו.
plt.scatter(X[y_means == 0,0],X[y_means == 0,1],color='blue')
plt.scatter(X[y_means == 1,0],X[y_means == 1,1],color='red') plt.scatter(X[y_means == 2,0],X[y_means == 2,1],color='green') plt.scatter(X[y_means == 3,0],X[y_means == 3,1],color='yellow')
פלט:
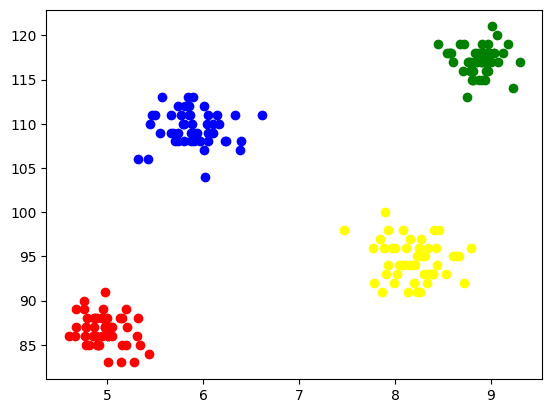
איור 5 הדמיה של אשכולות שנוצרו | תמונה לפי מחבר
9. K-Means על 3D-Data
מכיוון שלמערך הנתונים הקודם יש 2 עמודות, יש לנו בעיה דו-ממדית. כעת, נשתמש באותה מערכת שלבים עבור בעיה תלת-ממדית וננסה לנתח את יכולת השחזור של הקוד עבור נתונים נ-ממדיים.
# Create a synthetic dataset from sklearn
from sklearn.datasets import make_blobs # make synthetic dataset
centroids = [(-5,-5,5),(5,5,-5),(3.5,-2.5,4),(-2.5,2.5,-4)]
cluster_std = [1,1,1,1]
X,y = make_blobs(n_samples=200,cluster_std=cluster_std,centers=centroids,n_features=3,random_state=1)
# Scatter plot of the dataset
import plotly.express as px
fig = px.scatter_3d(x=X[:,0], y=X[:,1], z=X[:,2])
fig.show()
פלט:
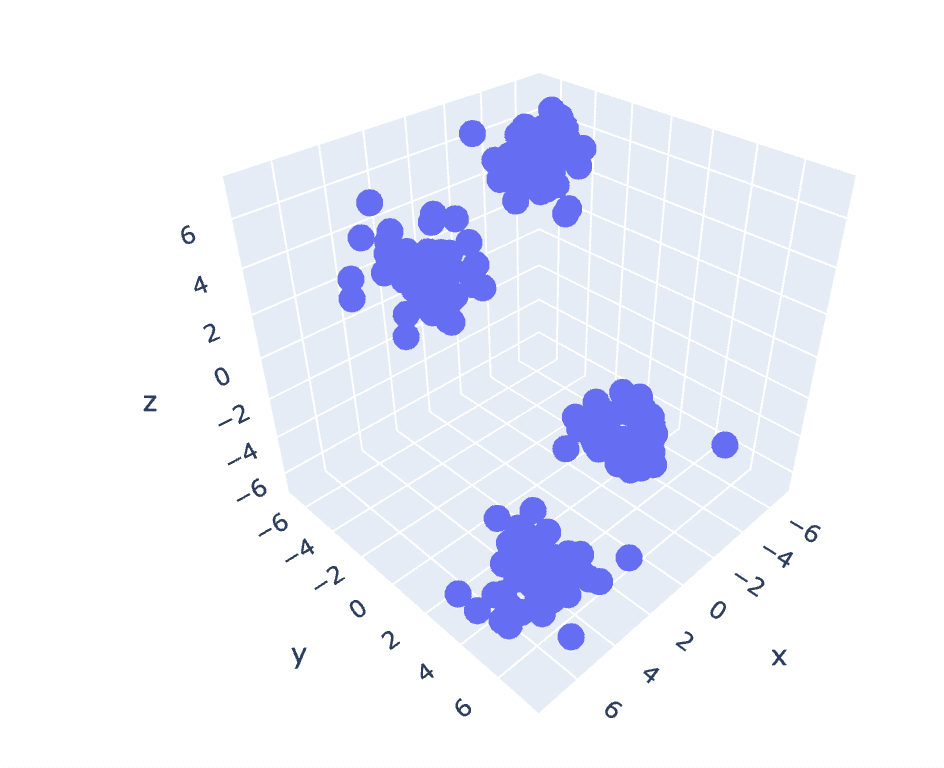
איור 6 עלילת פיזור של ערכת נתונים תלת-ממדית | תמונה לפי מחבר
wcss = []
for i in range(1,21): km = KMeans(n_clusters=i) km.fit_predict(X) wcss.append(km.inertia_) plt.plot(range(1,21),wcss)
פלט:

איור.7 חלקת מרפק | תמונה לפי מחבר
# Fit the K-Means algorithm with the optimal value of K
km = KMeans(n_clusters=4)
y_pred = km.fit_predict(X)
# Analyse the different clusters formed
df = pd.DataFrame()
df['col1'] = X[:,0]
df['col2'] = X[:,1]
df['col3'] = X[:,2]
df['label'] = y_pred fig = px.scatter_3d(df,x='col1', y='col2', z='col3',color='label')
fig.show()
פלט:
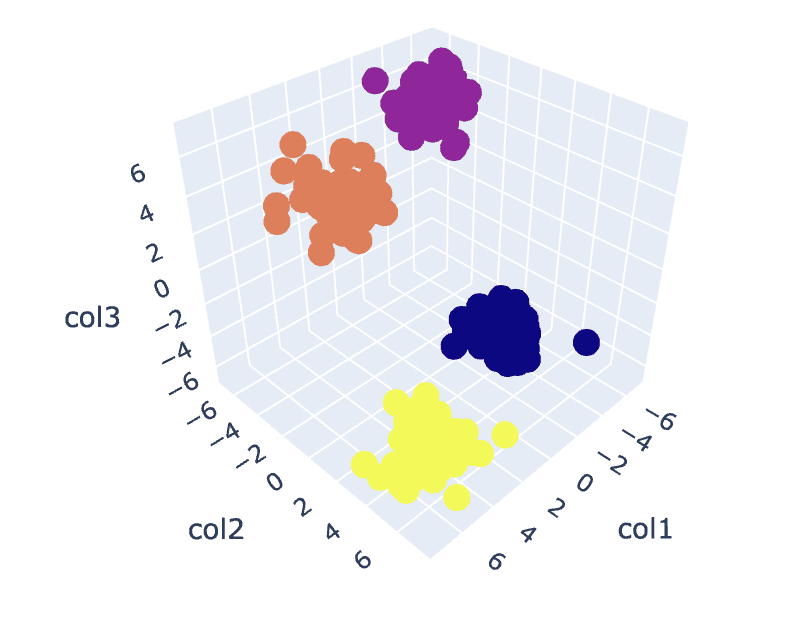
איור.8. ויזואליזציה של אשכולות | תמונה לפי מחבר
You can find the complete code here – מחברת קולאב
זה משלים את הדיון שלנו. דנו בעבודה, היישום והיישומים של K-Means. לסיכום, יישום משימות האשכולות הוא אלגוריתם בשימוש נרחב מהכיתה של למידה ללא פיקוח המספק גישה פשוטה ואינטואיטיבית לקיבוץ תצפיות של מערך נתונים. החוזק העיקרי של אלגוריתם זה הוא לחלק את התצפיות למספר סטים על סמך מדדי הדמיון שנבחרו בעזרת המשתמש שמיישם את האלגוריתם.
עם זאת, בהתבסס על בחירת הסנטרואידים בשלב הראשון, האלגוריתם שלנו מתנהג אחרת ומתכנס לאופטימיות מקומית או גלובלית. לכן, בחירת מספר האשכולות למימוש האלגוריתם, עיבוד מקדים של הנתונים, טיפול בחריגים וכו', היא חיונית להשגת תוצאות טובות. אבל אם נתבונן בצד השני של האלגוריתם הזה מאחורי המגבלות, K-Means היא טכניקה מועילה לניתוח נתונים חקרני וזיהוי דפוסים בתחומים שונים.
אריאן גארג הוא B.Tech. סטודנט להנדסת חשמל, כיום בשנה האחרונה לתואר ראשון. העניין שלו הוא בתחום בניית אתרים ולמידת מכונה. הוא רדף עניין זה והוא להוט לעבוד יותר בכיוונים אלה.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. רכב / רכבים חשמליים, פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- BlockOffsets. מודרניזציה של בעלות על קיזוז סביבתי. גישה כאן.
- מקור: https://www.kdnuggets.com/2023/07/clustering-unleashed-understanding-kmeans-clustering.html?utm_source=rss&utm_medium=rss&utm_campaign=clustering-unleashed-understanding-k-means-clustering
- :יש ל
- :הוא
- :לֹא
- :איפה
- 1
- 10
- 11
- 13
- 16
- 25
- 28
- 7
- 8
- 9
- a
- מֵעַל
- פרסום
- לאחר
- אַלגוֹרִיתְם
- אלגוריתמים
- תעשיות
- כְּבָר
- am
- an
- לנתח
- אנליזה
- לנתח
- ניתוח
- ו
- יישומים
- יישומית
- גישה
- ARE
- מערך
- מאמר
- AS
- At
- AXES
- b
- בנקאות
- מבוסס
- BE
- להיות
- מאחור
- להלן
- בֵּין
- כָּחוֹל
- בִּניָן
- אבל
- by
- CAN
- מקרה
- מקרים
- קטגוריה
- לבדוק
- בחרו
- בכיתה
- מועדון
- אשכול
- קיבוץ
- קוד
- עמודות
- מגיע
- הערות
- בדרך כלל
- לְהַשְׁווֹת
- להשלים
- הושלם
- מסקנה
- תוֹאֵם
- לִיצוֹר
- מכריע
- כיום
- לקוח
- לקוחות
- נתונים
- ניתוח נתונים
- כריית נתונים
- מדע נתונים
- מערכי נתונים
- עמוק
- צלילה לעומק
- צעצועי התפתחות
- אחר
- לטבול
- כיוונים
- נָדוֹן
- דיון
- מרחק
- מובהק
- do
- מסמך
- מסמכים
- עשה
- להורדה
- לצייר
- e
- מסחר אלקטרוני
- כל אחד
- לָהוּט
- בקלות
- הנדסת חשמל
- הנדסה
- מנועים
- זן
- וכו '
- בסופו של דבר
- דוגמה
- ניתוח נתונים חקרני
- היכרות
- אקספרס
- תמצית
- מאפיין
- תכונות
- שדה
- שדות
- תאנה
- סופי
- בסופו של דבר
- מציאת
- ראשון
- מתאים
- הבא
- בעד
- נוצר
- חברים
- החל מ-
- לתת
- נותן
- גלוֹבָּלִי
- הולך
- טוב
- ירוק
- קְבוּצָה
- טיפול
- רתמת
- יש
- יש
- he
- לעזור
- מועיל
- כאן
- מוּסתָר
- שֶׁלוֹ
- איך
- HTTPS
- i
- if
- תמונה
- ליישם
- הפעלה
- יישום
- לייבא
- in
- כולל
- מצביע על
- התעשייה
- אינרציה
- תובנות
- במקום
- אינטרס
- אינטרסים
- כלפי פנים
- אל תוך
- אינטואיטיבי
- IT
- שֶׁלָה
- מסע
- jpg
- KDnuggets
- תווית
- למידה
- ספריות
- שקרים
- מגבלות
- קשר
- לינקדין
- רשימה
- לִטעוֹן
- מקומי
- נראה
- מכונה
- למידת מכונה
- ראשי
- בעיקר
- לעשות
- רב
- להתאים
- matplotlib
- משמעותי
- אומר
- מדדים
- אכפת לי
- מינימום
- כרייה
- מודל
- דוגמנות
- מודול
- יותר
- רוב
- מספר
- צריך
- הכרחי
- צורך
- חדש
- לא
- עַכשָׁיו
- מספר
- קהות
- אובייקט
- להתבונן
- להשיג
- of
- on
- ONE
- יחידות
- אופטימלי
- or
- אחר
- שלנו
- דובי פנדה
- לעבור
- תבנית
- דפוסי
- ביצועים
- אדם
- צינור
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- נקודות
- אפשרי
- פוטנציאל
- חזק
- קודם
- עקרונות
- קופונים להדפסה
- כנראה
- בעיה
- בעיות
- תהליך
- פּרוֹיֶקט
- פרויקטים
- אב טיפוס
- ובלבד
- מספק
- פיתון
- אקראי
- הכרה
- להמליץ
- המלצה
- Red
- מחקר
- וכתוצאה מכך
- תוצאות
- עושה מהפכה
- s
- מכירות
- אותו
- מדע
- ים ים
- סוד
- סעיף
- לִרְאוֹת
- קטע
- פילוח
- נבחר
- בחירה
- מבחר
- נפרד
- סט
- סטים
- צוּרָה
- שיתוף
- הראה
- צד
- מסמל
- דומה
- פָּשׁוּט
- So
- לפתור
- פותר
- כמה
- ספורט
- ריבועים
- תֶקֶן
- התחלה
- שלב
- צעדים
- חנות
- חנויות
- אִסטרָטֶגִיָה
- כוח
- סטודנט
- בטוח
- סינטטי
- מערכות
- יעד
- משימות
- טק
- טלקום
- זֶה
- השמיים
- שֶׁלָהֶם
- אותם
- אז
- שם.
- לכן
- אלה
- דבר
- זֶה
- מחשבה
- דרך
- ל
- לנסות
- הבנה
- שוחרר
- לפתוח
- למידה ללא פיקוח
- us
- להשתמש
- מְשׁוּמָשׁ
- משתמש
- שימושים
- באמצעות
- לנצל
- ערך
- ערכים
- שונים
- ראיה
- vs
- רוצה
- we
- אינטרנט
- בניית אתרים
- אשר
- בזמן
- מי
- באופן נרחב
- יצטרך
- עם
- תיק עבודות
- עובד
- עובד
- עובד
- X
- שנה
- צהוב
- אתה
- זפירנט








