מציאת עמודות דומות בא אגם נתונים יש יישומים חשובים בניקוי והערות נתונים, התאמת סכמות, גילוי נתונים וניתוח על פני מספר מקורות נתונים. חוסר היכולת למצוא ולנתח במדויק נתונים ממקורות שונים מייצגת יעילות פוטנציאלית עבור כולם, החל מדעני נתונים, חוקרים רפואיים, אקדמאים וכלה באנליסטים פיננסיים וממשלתיים.
פתרונות קונבנציונליים כוללים חיפוש מילות מפתח לקסיקלי או התאמת ביטויים רגולריים, אשר רגישים לבעיות איכות נתונים כגון שמות עמודות נעדרים או מוסכמות שונות של שמות עמודות על פני מערכי נתונים מגוונים (לדוגמה, zip_code, zcode, postalcode).
בפוסט זה, אנו מדגימים פתרון לחיפוש עמודות דומות על סמך שם העמודה, תוכן העמודה או שניהם. הפתרון משתמש משוער אלגוריתמים של השכנים הקרובים ביותר אפשר להשיג ב שירות חיפוש פתוח של אמזון כדי לחפש עמודות דומות מבחינה סמנטית. כדי להקל על החיפוש, אנו יוצרים ייצוגי תכונות (הטמעות) עבור עמודות בודדות באגם הנתונים באמצעות מודלים של רובוטריקים מאומנים מראש מה- ספריית שנאי משפטים in אמזון SageMaker. לבסוף, כדי ליצור אינטראקציה עם תוצאות מהפתרון שלנו ולדמיין אותן, אנו בונים אינטראקטיבי מוארת יישום אינטרנט פועל על AWS פרגייט.
אנו כוללים א הדרכה בקוד כדי שתוכל לפרוס את המשאבים להפעלת הפתרון על נתונים לדוגמה או על נתונים משלך.
סקירת פתרונות
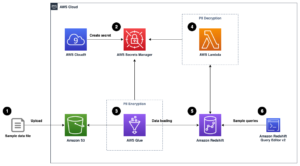
דיאגרמת הארכיטקטורה הבאה ממחישה את זרימת העבודה הדו-שלבית למציאת עמודות דומות מבחינה סמנטית. השלב הראשון מפעיל א פונקציות שלב AWS זרימת עבודה שיוצרת הטמעות מעמודות טבלאות ובונה את אינדקס החיפוש של OpenSearch Service. השלב השני, או שלב ההסקה המקוון, מריץ אפליקציית Streamlit דרך פארגייט. אפליקציית האינטרנט אוספת שאילתות חיפוש קלט ומחזירה מאינדקס OpenSearch Service את ה-k-העמודות הדומות ביותר לשאילתה.

איור 1. ארכיטקטורת פתרון
זרימת העבודה האוטומטית ממשיכה בשלבים הבאים:
- המשתמש מעלה מערכי נתונים טבלאיים ל-an שירות אחסון פשוט של אמזון (Amazon S3) דלי, אשר מפעיל an AWS למבדה פונקציה שמתחילה את זרימת העבודה של Step Functions.
- זרימת העבודה מתחילה בא דבק AWS עבודה הממירה את קבצי ה-CSV ל אפאצ'י פרקט פורמט נתונים.
- עבודת SageMaker Processing יוצרת הטבעות עבור כל עמודה באמצעות מודלים מאומנים מראש או מודלים של הטבעת עמודות מותאמות אישית. עבודת SageMaker Processing שומרת את הטבעות העמודות עבור כל טבלה באמזון S3.
- פונקציית Lambda יוצרת את הדומיין והאשכול של OpenSearch Service כדי להוסיף לאינדקס את הטבעות העמודות שנוצרו בשלב הקודם.
- לבסוף, יישום אינטרנט אינטראקטיבי Streamlit נפרס עם Fargate. אפליקציית האינטרנט מספקת ממשק למשתמש להזין שאילתות לחיפוש בדומיין OpenSearch Service עבור עמודות דומות.
אתה יכול להוריד את מדריך הקוד מ GitHub כדי לנסות את הפתרון הזה על נתונים לדוגמה או על הנתונים שלך. הוראות כיצד לפרוס את המשאבים הנדרשים עבור הדרכה זו זמינות ב- GitHub.
דרישות מוקדמות
כדי ליישם פתרון זה, אתה צריך את הדברים הבאים:
- An חשבון AWS.
- היכרות בסיסית עם שירותי AWS כגון ערכת פיתוח ענן AWS (AWS CDK), Lambda, OpenSearch Service ו- SageMaker Processing.
- מערך נתונים טבלאי ליצירת אינדקס החיפוש. אתה יכול להביא נתונים טבלאיים משלך או להוריד את מערכי הנתונים לדוגמה GitHub.
בניית אינדקס חיפוש
השלב הראשון בונה את אינדקס מנוע החיפוש העמודה. האיור הבא ממחיש את זרימת העבודה של Step Functions המריץ שלב זה.

איור 2 - זרימת עבודה של פונקציות שלב - דגמי הטמעה מרובים
מערכי נתונים
בפוסט זה, אנו בונים אינדקס חיפוש שיכלול למעלה מ-400 עמודות מתוך למעלה מ-25 מערכי נתונים טבלאיים. מערכי הנתונים מקורם במקורות הציבוריים הבאים:
לרשימה המלאה של הטבלאות הכלולות באינדקס, עיין במדריך הקוד בנושא GitHub.
אתה יכול להביא מערך נתונים טבלאי משלך כדי להגדיל את הנתונים לדוגמה או לבנות אינדקס חיפוש משלך. אנו כוללים שתי פונקציות Lambda שמתניעות את זרימת העבודה של Step Functions לבניית אינדקס החיפוש עבור קבצי CSV בודדים או אצווה של קבצי CSV, בהתאמה.
הפיכת CSV לפרקט
קבצי CSV גולמיים מומרים לפורמט נתוני פרקט עם AWS Glue. פרקט הוא פורמט קובץ בפורמט מונחה עמודות המועדף בניתוח ביג דאטה המספק דחיסה וקידוד יעילים. בניסויים שלנו, פורמט הנתונים של Parquet הציע הפחתה משמעותית בגודל האחסון בהשוואה לקבצי CSV גולמיים. השתמשנו ב-Parquet גם כפורמט נתונים נפוץ להמרת פורמטים אחרים של נתונים (למשל JSON ו-NDJSON) מכיוון שהוא תומך במבני נתונים מקוננים מתקדמים.
צור הטמעות עמודות בטבלה
כדי לחלץ הטבעות עבור עמודות טבלה בודדות במערך הנתונים הטבלאי לדוגמה בפוסט זה, אנו משתמשים במודלים הבאים שהוכשרו מראש מה- sentence-transformers סִפְרִיָה. לדגמים נוספים, ראה מודלים מאומנים מראש.
משימת SageMaker Processing פועלת create_embeddings.py(קוד) עבור דגם בודד. לחילוץ הטמעות ממספר דגמים, זרימת העבודה מריץ משימות עיבוד מקבילות של SageMaker כפי שמוצג בזרימת העבודה של Step Functions. אנו משתמשים במודל כדי ליצור שתי קבוצות של הטבעות:
- column_name_embeddings - הטמעות של שמות עמודות (כותרות)
- העמודות_תוכן – הטבעה ממוצעת של כל השורות בעמודה
למידע נוסף על תהליך הטבעת העמודות, עיין במדריך הקוד בנושא GitHub.
חלופה לשלב SageMaker Processing היא ליצור טרנספורמציה של SageMaker אצווה כדי לקבל הטבעת עמודות על מערכי נתונים גדולים. זה ידרוש פריסת המודל לנקודת קצה של SageMaker. למידע נוסף, ראה השתמש ב-Bach Transform.
הטמעות אינדקס עם OpenSearch Service
בשלב האחרון של שלב זה, פונקציית Lambda מוסיפה את הטבעות העמודות לשירות OpenSearch משוער k-Nearest-Neighbor (kNN) אינדקס חיפוש. לכל דגם מוקצה אינדקס חיפוש משלו. למידע נוסף על הפרמטרים המשוערים של אינדקס החיפוש של kNN, ראה k-NN.
הסקה מקוונת וחיפוש סמנטי עם אפליקציית אינטרנט
השלב השני של זרימת העבודה פועל א מוארת יישום אינטרנט שבו אתה יכול לספק קלט ולחפש עמודות דומות מבחינה סמנטית באינדקס ב-OpenSearch Service. שכבת היישום משתמשת ב-an איזון עומס יישומים, פארגייט ולמבדה. תשתית האפליקציה נפרסת אוטומטית כחלק מהפתרון.
האפליקציה מאפשרת לך לספק קלט ולחפש שמות עמודות דומים מבחינה סמנטית, תוכן עמודות או שניהם. בנוסף, תוכל לבחור את דגם ההטמעה ומספר השכנים הקרובים ביותר שיחזרו מהחיפוש. האפליקציה מקבלת תשומות, מטמיעה את הקלט עם הדגם שצוין ומשתמשת חיפוש kNN בשירות OpenSearch כדי לחפש הטמעות עמודות באינדקס ולמצוא את העמודות הדומות ביותר לקלט הנתון. תוצאות החיפוש המוצגות כוללות את שמות הטבלאות, שמות העמודות וציוני הדמיון עבור העמודות שזוהו, כמו גם את מיקומי הנתונים באמזון S3 לחקירה נוספת.
האיור הבא מציג דוגמה של יישום האינטרנט. בדוגמה זו, חיפשנו עמודות באגם הנתונים שלנו שיש להם דומים Column Names (סוג מטען) כדי district (מטען). האפליקציה שבה נעשה שימוש all-MiniLM-L6-v2 כמו דגם הטבעה וחזר 10 (k) השכנים הקרובים ביותר מאינדקס שירות OpenSearch שלנו.
הבקשה חזרה transit_district, city, borough, ו location כארבע העמודות הדומות ביותר המבוססות על הנתונים שנוספו לאינדקס ב-OpenSearch Service. דוגמה זו מדגימה את היכולת של גישת החיפוש לזהות עמודות דומות מבחינה סמנטית על פני מערכי נתונים.

איור 3: ממשק משתמש של יישום אינטרנט
לנקות את
כדי למחוק את המשאבים שנוצרו על ידי AWS CDK במדריך זה, הפעל את הפקודה הבאה:
cdk destroy --allסיכום
בפוסט זה הצגנו זרימת עבודה מקצה לקצה לבניית מנוע חיפוש סמנטי עבור עמודות טבלאות.
התחל היום עם הנתונים שלך עם ערכת הקוד שלנו זמינה ב- GitHub. אם תרצה עזרה בהאצת השימוש שלך ב-ML במוצרים ובתהליכים שלך, אנא צור קשר עם מעבדת פתרונות למידת מכונות של אמזון.
על הכותבים
![]() Kachi Odoemene הוא מדען יישומי ב-AWS AI. הוא בונה פתרונות AI/ML לפתרון בעיות עסקיות עבור לקוחות AWS.
Kachi Odoemene הוא מדען יישומי ב-AWS AI. הוא בונה פתרונות AI/ML לפתרון בעיות עסקיות עבור לקוחות AWS.
![]() טיילור מקנלי הוא אדריכל למידה עמוקה במעבדת פתרונות למידת מכונה של אמזון. הוא עוזר ללקוחות מתעשיות שונות לבנות פתרונות הממנפים AI/ML ב-AWS. הוא נהנה מכוס קפה טובה, מהחוץ, ומזמן עם המשפחה והכלב הנמרץ שלו.
טיילור מקנלי הוא אדריכל למידה עמוקה במעבדת פתרונות למידת מכונה של אמזון. הוא עוזר ללקוחות מתעשיות שונות לבנות פתרונות הממנפים AI/ML ב-AWS. הוא נהנה מכוס קפה טובה, מהחוץ, ומזמן עם המשפחה והכלב הנמרץ שלו.
![]() אוסטין וולש הוא מדען נתונים במעבדת פתרונות ML של אמזון. הוא מפתח מודלים מותאמים אישית של למידה עמוקה כדי לעזור ללקוחות במגזר הציבורי של AWS להאיץ את אימוץ הבינה המלאכותית והענן שלהם. בזמנו הפנוי, הוא נהנה לקרוא, לטייל ולג'ו-ג'יטסו.
אוסטין וולש הוא מדען נתונים במעבדת פתרונות ML של אמזון. הוא מפתח מודלים מותאמים אישית של למידה עמוקה כדי לעזור ללקוחות במגזר הציבורי של AWS להאיץ את אימוץ הבינה המלאכותית והענן שלהם. בזמנו הפנוי, הוא נהנה לקרוא, לטייל ולג'ו-ג'יטסו.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- יכולת
- אודות
- נעדר
- להאיץ
- מאיצה
- במדויק
- לרוחב
- נוסף
- בנוסף
- מוסיף
- אימוץ
- מתקדם
- AI
- AI / ML
- תעשיות
- מאפשר
- חלופה
- אמזון בעברית
- למידת מכונת אמזון
- מעבדת פתרונות אמזון ML
- אנליסטים
- ניתוח
- לנתח
- ו
- אַפָּשׁ
- בקשה
- יישומים
- יישומית
- גישה
- ארכיטקטורה
- שהוקצה
- אוטומטי
- באופן אוטומטי
- זמין
- מְמוּצָע
- AWS
- דבק AWS
- מבוסס
- כי
- גָדוֹל
- נתונים גדולים
- להביא
- לִבנוֹת
- בִּניָן
- בונה
- עסקים
- ניקוי
- ענן
- אימוץ ענן
- אשכול
- קוד
- קָפֶה
- אוסף
- טור
- עמודות
- Common
- לעומת
- צור קשר
- תוכן
- אמנות
- להמיר
- הומר
- לִיצוֹר
- נוצר
- יוצר
- כוס
- מנהג
- לקוחות
- נתונים
- ניתוח נתונים
- אגם דאטה
- איכות נתונים
- מדען נתונים
- מערכי נתונים
- עמוק
- למידה עמוקה
- להפגין
- מדגים
- לפרוס
- פרס
- פריסה
- להרוס
- צעצועי התפתחות
- מפתחת
- אחר
- תגלית
- שונה
- שונה
- כֶּלֶב
- תחום
- להורדה
- כל אחד
- יְעִילוּת
- יעיל
- מקצה לקצה
- נקודת קצה
- מנוע
- Ether (ETH)
- כולם
- דוגמה
- חקירה
- תמצית
- לְהַקֵל
- בְּקִיאוּת
- משפחה
- תכונות
- תרשים
- שלח
- קבצים
- סופי
- בסופו של דבר
- כספי
- מציאת
- ראשון
- הבא
- פוּרמָט
- החל מ-
- מלא
- פונקציה
- פונקציות
- נוסף
- לקבל
- נתן
- טוב
- ממשלה
- כותרות
- לעזור
- עוזר
- איך
- איך
- HTML
- HTTPS
- מזוהה
- לזהות
- ליישם
- חשוב
- in
- חוסר יכולת
- לכלול
- כלול
- מדד
- בנפרד
- תעשיות
- מידע
- תשתית
- ליזום
- יוזם
- קלט
- הוראות
- אינטראקציה
- אינטראקטיבי
- מִמְשָׁק
- מעורר
- לערב
- בעיות
- IT
- עבודה
- מקומות תעסוקה
- ג'סון
- מעבדה
- אגם
- גָדוֹל
- שכבה
- למידה
- מינוף
- סִפְרִיָה
- רשימה
- לִטעוֹן
- מקומות
- מכונה
- למידת מכונה
- תואם
- רפואי
- ML
- מודל
- מודלים
- יותר
- רוב
- מספר
- שם
- שמות
- שמות
- צורך
- השכנים
- מספר
- מוצע
- באינטרנט
- אחר
- בחוץ
- שֶׁלוֹ
- מקביל
- פרמטרים
- חלק
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- אנא
- הודעה
- פוטנציאל
- מועדף
- מוצג
- קודם
- בעיות
- ההכנסות
- תהליך
- תהליכים
- תהליך
- מיוצר
- מוצרים
- לספק
- מספק
- ציבורי
- איכות
- חי
- קריאה
- מקבל
- רגיל
- מייצג
- לדרוש
- נדרש
- חוקרים
- משאבים
- בהתאמה
- תוצאות
- לַחֲזוֹר
- הפעלה
- ריצה
- בעל חכמים
- מַדְעָן
- מדענים
- חיפוש
- מנוע חיפוש
- חיפוש
- שְׁנִיָה
- מגזר
- שרות
- שירותים
- סטים
- הראה
- הופעות
- משמעותי
- דומה
- פָּשׁוּט
- יחיד
- מידה
- פִּתָרוֹן
- פתרונות
- לפתור
- מקורות
- מפורט
- התמחות
- החל
- שלב
- צעדים
- אחסון
- כזה
- תומך
- apt
- שולחן
- השמיים
- שֶׁלָהֶם
- דרך
- זמן
- ל
- היום
- לשנות
- רוֹבּוֹטרִיקִים
- נסיעה
- הדרכה
- להשתמש
- משתמש
- ממשק משתמש
- שונים
- אינטרנט
- אפליקציית רשת
- אשר
- זרימת עבודה
- היה
- זפירנט