זהו פוסט אורח מאת AK Roy מ-Qualcomm AI.
ענן מחשוב אלסטי של אמזון (אמזון EC2) מופעי DL2q, המופעלים על ידי מאיצים סטנדרטיים של Qualcomm AI 100, יכולים לשמש לפריסה יעילה של עומסי עבודה של למידה עמוקה (DL) בענן. הם יכולים לשמש גם לפיתוח ולאמת ביצועים ודיוק של עומסי עבודה של DL שייפרסו במכשירי קוואלקום. מופעי DL2q הם המופעים הראשונים שהביאו את הטכנולוגיה החכמה המלאכותית (AI) של קוואלקום לענן.
עם שמונה מאיצים של Qualcomm AI 100 Standard ו-128 GiB של זיכרון מאיץ כולל, לקוחות יכולים גם להשתמש במופעי DL2q כדי להריץ יישומי AI גנרטיביים פופולריים, כגון יצירת תוכן, סיכום טקסט ועוזרים וירטואליים, כמו גם יישומי AI קלאסיים לעיבוד שפה טבעית וראייה ממוחשבת. בנוסף, מאיצי קוואלקום AI 100 כוללים את אותה טכנולוגיית בינה מלאכותית המשמשת בסמארטפונים, נהיגה אוטונומית, מחשבים אישיים ואוזניות מציאות מורחבת, כך שניתן להשתמש במופעי DL2q לפיתוח ולאמת עומסי עבודה של בינה מלאכותית לפני הפריסה.
דגשים חדשים של מופע DL2q
כל מופע DL2q משלב שמונה מאיצים של Qualcomm Cloud AI100, עם ביצועים מצטברים של למעלה מ-2.8 PetaOps של ביצועי הסקת Int8 ו-1.4 PetaFlops של ביצועי הסקת FP16. למופע יש 112 ליבות AI מצטבר, קיבולת זיכרון מאיץ של 128 GB ורוחב פס זיכרון של 1.1 TB לשנייה.
לכל מופע DL2q 96 vCPUs, קיבולת זיכרון מערכת של 768 GB ותומך ברוחב פס רשת של 100 Gbps וכן Amazon Elastic Block Store (Amazon EBS) אחסון של 19 Gbps.
| שם מופע | מעבדי vCPU | מאיצי ענן AI100 | זיכרון מאיץ | זיכרון מאיץ BW (מצטבר) | זיכרון מופע | רשת מופעים | רוחב פס אחסון (Amazon EBS). |
| DL2q.24xlarge | 96 | 8 | 128 GB | 1.088 TB / s | 768 GB | XNXX Gbps | XNXX Gbps |
חדשנות מאיץ Qualcomm Cloud AI100
מאיץ ה-Cloud AI100 מערכת-על-שבב (SoC) הוא ארכיטקטורה מרובת ליבות ניתנת להרחבה נבנית במיוחד, התומכת במגוון רחב של מקרי שימוש ללמידה עמוקה החל ממרכז הנתונים ועד לקצה. ה-SoC משתמש בליבות מחשוב סקלריות, וקטוריות וטנזוריות עם קיבולת SRAM מובילה בתעשייה של 126 MB. הליבות מחוברות זו לזו עם רשת רשת-על-שבב (NoC) ברוחב פס גבוה עם חביון נמוך.
מאיץ ה-AI100 תומך במגוון רחב ומקיף של דגמים ומקרי שימוש. הטבלה שלהלן מדגישה את טווח התמיכה בדגם.
| קטגוריית דגמים | מספר מודלים | דוגמאות |
| NLP | 157 | BERT, BART, FasterTransformer, T5, Z-code MOE |
| AI גנרטיבי - NLP | 40 | LLaMA, CodeGen, GPT, OPT, BLOOM, Jais, Luminous, StarCoder, XGen |
| AI גנרטיבי - תמונה | 3 | דיפוזיה יציבה v1.5 ו-v2.1, OpenAI CLIP |
| קורות חיים – סיווג תמונה | 45 | ViT, ResNet, ResNext, MobileNet, EfficientNet |
| קורות חיים - זיהוי אובייקטים | 23 | YOLO v2, v3, v4, v5 ו-v7, SSD-ResNet, RetinaNet |
| קורות חיים - אחר | 15 | LPRNet, רזולוציה-על/SRGAN, ByteTrack |
| רשתות רכב* | 53 | תפיסה וזיהוי LIDAR, הולכי רגל, נתיבים ורמזורים |
| סה"כ | > 300 | |
* רוב רשתות הרכב הן רשתות מורכבות המורכבות ממיזוג של רשתות בודדות.
ה-SRAM הגדול על גבי המאיץ DL2q מאפשר הטמעה יעילה של טכניקות ביצועים מתקדמות כגון דיוק מיקרו-אקספונט MX6 לאחסון המשקולות ודיוק מיקרו-מעריך MX9 לתקשורת מאיץ-מאיץ. טכנולוגיית המיקרו-אקספוננט מתוארת בהודעת התעשייה הבאה של Open Compute Project (OCP): AMD, Arm, Intel, Meta, Microsoft, NVIDIA, ו-Qualcomm מייצרות את הדור הבא של פורמטי נתונים צרים מדויקים עבור AI » Open Compute Project.
משתמש המופע יכול להשתמש באסטרטגיה הבאה כדי למקסם את הביצועים לעלות:
- אחסן משקלים באמצעות דיוק המיקרו-אקספוננט MX6 בזיכרון ה-DDR המופעל על המאיץ. השימוש בדייקנות MX6 ממקסם את ניצול קיבולת הזיכרון הזמינה ואת רוחב הפס של הזיכרון כדי לספק תפוקה והשהייה מהטובים מסוגו.
- חישוב ב-FP16 כדי לספק את דיוק מקרה השימוש הנדרש, תוך שימוש ב-SRAM המשובח על-שבב ו-TOPs רזרביים בכרטיס, כדי ליישם ביצועים גבוהים של גרעיני MX6 עד FP16.
- השתמש באסטרטגיית אצווה אופטימלית ובגודל אצווה גבוה יותר על ידי שימוש ב-SRAM הגדול על-שבב הזמין כדי למקסם את השימוש החוזר במשקלים, תוך שמירה על ההפעלה על-שבב למקסימום האפשרי.
DL2q AI מחסנית ושרשרת כלים
מופע DL2q מלווה ב-Qualcomm AI Stack המספק חווית מפתח עקבית בכל קוואלקום AI בענן ובמוצרים אחרים של Qualcomm. אותה טכנולוגיית AI מחסנית ובסיס AI של Qualcomm פועלת על מופעי DL2q ומכשירי קוואלקום קצה, ומספקת ללקוחות חווית מפתח עקבית, עם API מאוחד על פני ענן, רכב, מחשב אישי, מציאות מורחבת וסביבות פיתוח סמארטפונים.
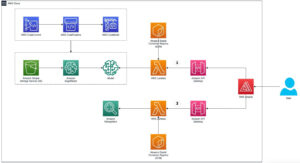
שרשרת הכלים מאפשרת למשתמש המופע להרכיב במהירות מודל שהוכשר בעבר, לקמפל ולבצע אופטימיזציה של המודל עבור יכולות המופע, ולאחר מכן לפרוס את המודלים שנערכו עבור מקרי שימוש בהסקת ייצור בשלושה שלבים המוצגים באיור הבא.

למידע נוסף על כוונון הביצועים של דגם, עיין ב- Cloud AI 100 פרמטרי ביצועים מרכזיים תיעוד.
התחל עם מופעי DL2q
בדוגמה זו, אתה קומפלט ופורס קובץ מאומן מראש דגם BERT החל מ- פנים מחבקות על מופע EC2 DL2q באמצעות DL2q AMI זמין בנוי מראש, בארבעה שלבים.
אתה יכול להשתמש באחד מראש קוואלקום DLAMI על המופע או התחל עם Amazon Linux2 AMI ובנה DL2q AMI משלך עם Cloud AI 100 Platform ו- Apps SDK הזמינים ב- שירות אחסון פשוט של אמזון (Amazon S3) דְלִי: s3://ec2-linux-qualcomm-ai100-sdks/latest/.
השלבים הבאים משתמשים ב-DL2q AMI המובנה מראש, Qualcomm Base AL2 DLAMI.
השתמש ב-SSH כדי לגשת למופע DL2q שלך עם Qualcomm Base AL2 DLAMI AMI ובצע את השלבים 1 עד 4.
שלב 1. הגדר את הסביבה והתקן את החבילות הנדרשות
- התקן את Python 3.8.
- הגדר את הסביבה הווירטואלית Python 3.8.
- הפעל את הסביבה הוירטואלית Python 3.8.
- התקן את החבילות הנדרשות, המוצגות ב- מסמך requirements.txt זמין באתר Github הציבורי של קוואלקום.
- ייבא את הספריות הדרושות.
שלב 2. ייבא את הדגם
- ייבא וסמל את הדגם.
- הגדר קלט לדוגמה וחלץ את
inputIdsוattentionMask. - המר את המודל ל-ONNX, אשר לאחר מכן ניתן להעביר אותו למהדר.
- אתה תפעיל את הדגם בדייקנות FP16. לכן, עליך לבדוק אם המודל מכיל קבועים כלשהם מעבר לטווח FP16. העבירו את הדגם ל-
fix_onnx_fp16פונקציה ליצירת קובץ ONNX החדש עם התיקונים הנדרשים.
שלב 3. הרכיב את המודל
השמיים qaic-exec כלי המהדר של ממשק שורת הפקודה (CLI) משמש להידור המודל. הקלט למהדר זה הוא קובץ ONNX שנוצר בשלב 2. המהדר מייצר קובץ בינארי (נקרא QPC, עבור מיכל תוכנית קוואלקום) בנתיב שהוגדר על ידי -aic-binary-dir ויכוח.
בפקודת ההידור למטה, אתה משתמש בארבע ליבות מחשוב בינה מלאכותית ובגודל אצווה של אחת כדי להרכיב את המודל.
ה-QPC נוצר ב- bert-base-cased/generatedModels/bert-base-cased_fix_outofrange_fp16_qpc תיקייה.
שלב 4. הפעל את המודל
הגדר הפעלה כדי להפעיל את ההסקה על מאיץ Cloud AI100 Qualcomm במופע DL2q.
ספריית Qualcomm qaic Python היא קבוצה של ממשקי API המספקים תמיכה להרצת הסקת מסקנות על מאיץ Cloud AI100.
- השתמש בקריאה ל-Session API כדי ליצור מופע של הפעלה. הקריאה ל-Session API היא נקודת הכניסה לשימוש בספריית ה-qaic Python.
- מבנה מחדש את הנתונים ממאגר פלט עם
output_shapeוoutput_type. - פענח את הפלט שהופק.
להלן הפלטים עבור משפט הקלט "הכלב [מסכה] על המחצלת."
זהו זה. עם כמה שלבים בלבד, הידור והרצת מודל PyTorch על מופע של Amazon EC2 DL2q. למידע נוסף על שילוב וקומפילציה של מודלים במופע DL2q, עיין ב- תיעוד הדרכה של Cloud AI100.
למידע נוסף על אילו ארכיטקטורות מודל DL מתאימות למופעי AWS DL2q ומטריצת תמיכת המודל הנוכחית, עיין ב- תיעוד Qualcomm Cloud AI100.
זמין כעת
אתה יכול להשיק מופעי DL2q היום באזורי AWS במערב ארה"ב (אורגון) ואירופה (פרנקפורט). לפי דרישה, שמורות, ו מופעי ספוט, או במסגרת א תכנית חיסכון. כרגיל באמזון EC2, אתה משלם רק על מה שאתה משתמש בו. למידע נוסף, ראה תמחור אמזון EC2.
ניתן לפרוס מופעי DL2q באמצעות AWS למידה עמוקה AMI (DLAMI), ותמונות מיכל זמינות דרך שירותים מנוהלים כגון אמזון SageMaker, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), ו ParallelCluster של AWS.
למידע נוסף, בקר בכתובת מופע של Amazon EC2 DL2q עמוד, ושלח משוב אל AWS re:Post עבור EC2 או דרך אנשי הקשר הרגילים שלך לתמיכה של AWS.
על המחברים
 א.ק רוי הוא מנהל ניהול מוצר ב-Qualcomm, עבור מוצרים ופתרונות בינה מלאכותית של ענן ו-Datacenter. יש לו למעלה מ-20 שנות ניסיון באסטרטגיית ופיתוח מוצר, עם המוקד הנוכחי של ביצועים וביצועים מהטובים בכיתה/פתרונות מקצה לקצה עבור מסקנות AI בענן, עבור מגוון רחב של מקרי שימוש, כולל GenAI, LLMs, Auto ו-Hybrid AI.
א.ק רוי הוא מנהל ניהול מוצר ב-Qualcomm, עבור מוצרים ופתרונות בינה מלאכותית של ענן ו-Datacenter. יש לו למעלה מ-20 שנות ניסיון באסטרטגיית ופיתוח מוצר, עם המוקד הנוכחי של ביצועים וביצועים מהטובים בכיתה/פתרונות מקצה לקצה עבור מסקנות AI בענן, עבור מגוון רחב של מקרי שימוש, כולל GenAI, LLMs, Auto ו-Hybrid AI.
 ג'יאניינג לאנג הוא אדריכל פתרונות ראשי ב-AWS Worldwide Specialist Organization (WWSO). יש לה למעלה מ-15 שנות ניסיון בעבודה בתחום HPC ובינה מלאכותית. ב-AWS, היא מתמקדת בסיוע ללקוחות לפרוס, לייעל ולהרחיב את עומסי העבודה של AI/ML שלהם במופעי מחשוב מואצים. היא נלהבת משילוב הטכניקות בתחומי HPC ו-AI. ל-Jianying תואר דוקטור בפיזיקה חישובית מאוניברסיטת קולורדו בבולדר.
ג'יאניינג לאנג הוא אדריכל פתרונות ראשי ב-AWS Worldwide Specialist Organization (WWSO). יש לה למעלה מ-15 שנות ניסיון בעבודה בתחום HPC ובינה מלאכותית. ב-AWS, היא מתמקדת בסיוע ללקוחות לפרוס, לייעל ולהרחיב את עומסי העבודה של AI/ML שלהם במופעי מחשוב מואצים. היא נלהבת משילוב הטכניקות בתחומי HPC ו-AI. ל-Jianying תואר דוקטור בפיזיקה חישובית מאוניברסיטת קולורדו בבולדר.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/amazon-ec2-dl2q-instance-for-cost-efficient-high-performance-ai-inference-is-now-generally-available/
- :יש ל
- :הוא
- $ למעלה
- 1
- 1 TB
- 10
- 100
- 11
- 12
- 13
- שנים 15
- 15%
- 17
- 19
- 20
- שנים 20
- 22
- 23
- 46
- 7
- 75
- 8
- 84
- a
- אודות
- מֵעַל
- מוּאָץ
- מאיץ
- מאיצים
- גישה
- נלווה
- דיוק
- לרוחב
- הפעלות
- בנוסף
- מתקדם
- לְקַבֵּץ
- AI
- AI / ML
- תעשיות
- גם
- אמזון בעברית
- אמזון
- אמזון שירותי אינטרנט
- an
- ו
- הַכרָזָה
- כל
- API
- ממשקי API
- יישומים
- אפליקציות
- ארכיטקטורה
- ARE
- טענה
- זרוע
- מלאכותי
- AS
- עוזרים
- At
- המכונית
- רכב
- אוטונומי
- זמין
- AWS
- AXES
- רוחב פס
- בסיס
- אצווה
- BE
- לפני
- להלן
- מעבר
- BIN
- לחסום
- לִפְרוֹחַ
- להביא
- רחב
- חיץ
- לִבנוֹת
- by
- שיחה
- נקרא
- CAN
- יכולות
- קיבולת
- כרטיס
- מקרה
- לבדוק
- קלאסי
- ענן
- קולורדו
- שילוב
- תקשורת
- הידור
- מַקִיף
- חישובית
- לחשב
- המחשב
- ראייה ממוחשבת
- מחשבים
- מחשוב
- עִקבִי
- מורכב
- אנשי קשר
- מכולה
- מכיל
- תוכן
- לִיצוֹר
- נוֹכְחִי
- לקוחות
- נתונים
- Datacenter
- עמוק
- למידה עמוקה
- מוגדר
- תואר
- למסור
- מספק
- לפרוס
- פרס
- פריסה
- מְתוּאָר
- לפתח
- מפתח
- צעצועי התפתחות
- מכשיר
- התקנים
- שידור
- מְנַהֵל
- תיעוד
- כֶּלֶב
- נהיגה
- דינמי
- ebs
- אדג '
- יעיל
- או
- מעסיקה
- מאפשר
- מקצה לקצה
- כניסה
- סביבה
- סביבות
- Ether (ETH)
- אירופה
- דוגמה
- ניסיון
- המציאות המורחבת
- תמצית
- שקר
- מאפיין
- מָשׁוֹב
- מעטים
- שדה
- שדות
- תרשים
- שלח
- ראשון
- מתאים
- תיקוני
- להתמקד
- מתמקד
- לעקוב
- הבא
- בעד
- מצא
- ארבע
- פרנקפורט
- החל מ-
- פונקציה
- היתוך
- בדרך כלל
- ליצור
- נוצר
- דור
- גנרטטיבית
- AI Generative
- GitHub
- נתן
- טוב
- אוֹרֵחַ
- פוסט אורח
- he
- אוזניות
- עזרה
- כאן
- ביצועים גבוהים
- גבוה יותר
- פסים
- מחזיק
- hpc
- HTML
- HTTPS
- היברידי
- i
- IDX
- if
- תמונה
- תמונות
- ליישם
- הפעלה
- לייבא
- in
- כולל
- משלבת
- בנפרד
- תעשייה
- מובילים בתעשייה
- מידע
- קלט
- להתקין
- למשל
- מקרים
- אינטל
- אינטליגנטי
- מקושרים
- מִמְשָׁק
- IT
- jpg
- רק
- מפתח
- קוברנט
- נתיב
- שפה
- גָדוֹל
- חֶבִיוֹן
- לשגר
- לִלמוֹד
- למידה
- ספריות
- סִפְרִיָה
- עסקה
- אוֹר
- קו
- המון
- הצליח
- ניהול
- מסכה
- מַטרִיצָה
- מקסימום
- לְהַגדִיל
- מעלה
- מקסימום
- זכרון
- רשת
- meta
- מיקרוסופט
- דקות
- מודל
- מודלים
- שונים
- יותר
- רוב
- שם
- טבעי
- שפה טבעית
- עיבוד שפה טבעית
- הכרחי
- צורך
- רשת
- רשתות
- רשתות
- חדש
- הדור הבא
- עַכשָׁיו
- קהות
- Nvidia
- אובייקט
- of
- on
- על הסיפון
- Onboarding
- ONE
- רק
- לפתוח
- OpenAI
- מטב
- אופטימיזציה
- or
- אורגון
- ארגון
- OS
- אחר
- הַחוּצָה
- תפוקה
- פלטים
- יותר
- שֶׁלוֹ
- חבילות
- עמוד
- חלק
- לעבור
- עבר
- לוהט
- נתיב
- תשלום
- עבור
- ביצועים
- אישי
- מחשבים אישיים
- דוקטורט
- פיסיקה
- פלטפורמה
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- נקודה
- פופולרי
- אפשרי
- הודעה
- מופעל
- דיוק
- קוֹדֶם
- מנהל
- תהליך
- מיוצר
- ייצור
- המוצר
- ניהול מוצר
- הפקה
- מוצרים
- תָכְנִית
- פּרוֹיֶקט
- מספק
- מתן
- ציבורי
- פיתון
- פיטורך
- Qualcomm
- מהירות
- רכס
- RE
- קריאה
- מציאות
- אזורים
- נדרש
- דרישות
- שמירה
- לַחֲזוֹר
- שימוש חוזר
- רועי
- הפעלה
- ריצה
- פועל
- אותו
- שמור
- חסכת
- להרחבה
- סולם
- Sdk
- שְׁנִיָה
- לִרְאוֹת
- לשלוח
- משפט
- רצף
- שרות
- שירותים
- מושב
- סט
- היא
- הראה
- פָּשׁוּט
- לפשט
- אתר
- מידה
- טלפון חכם
- טלפונים חכמים
- So
- פתרונות
- מתח
- מומחה
- לערום
- תֶקֶן
- התחלה
- החל
- שלב
- צעדים
- אחסון
- חנות
- אִסטרָטֶגִיָה
- כתוצאה מכך
- כזה
- מעולה
- תמיכה
- מסייע
- תומך
- מערכת
- שולחן
- טכניקות
- טכנולוגיה
- טֶקסט
- זֶה
- השמיים
- שֶׁלָהֶם
- אז
- אלה
- הֵם
- זֶה
- שְׁלוֹשָׁה
- דרך
- תפוקה
- דרך
- ל
- היום
- tokenize
- כלי
- עליוניות
- לפיד
- סה"כ
- תְנוּעָה
- מְאוּמָן
- רוֹבּוֹטרִיקִים
- נָכוֹן
- הדרכה
- מאוחד
- אוניברסיטה
- us
- להשתמש
- במקרה להשתמש
- מקרים לשימוש
- מְשׁוּמָשׁ
- משתמש
- באמצעות
- כרגיל
- v1
- מדד
- לְאַמֵת
- ערך
- וירטואלי
- חזון
- לְבַקֵר
- we
- אינטרנט
- שירותי אינטרנט
- טוֹב
- מערב
- מה
- אשר
- בזמן
- רָחָב
- טווח רחב
- יצטרך
- עם
- Word
- עובד
- עולמי
- שנים
- אתה
- זפירנט