
תמונה מאת המחבר
למידת מכונה היא ללא ספק הכוכב הזוהר של העידן החדש. הוא מהווה את עמוד השדרה של טכנולוגיות מרכזיות שונות שהפכו לאינטגרליות בחיי היומיום שלנו, כגון זיהוי פנים (נתמך על ידי Convolutional Neural Networks או CNN), זיהוי דיבור (מינוף CNN ו-Recurrent Neural Networks או RNN), והצ'אטבוטים הפופולריים יותר ויותר כמו ChatGPT (מופעל על ידי Reinforcement Learning from Human Feedback, RLHF).
זמינות כיום שיטות רבות לשיפור הביצועים של מודל למידת מכונה. שיטות אלה יכולות לתת לפרויקט שלך יתרון תחרותי על ידי אספקת ביצועים מעולים.
בדיון זה, נתעמק בתחום הטכניקות לבחירת תכונות. אבל לפני שנמשיך, בואו נבהיר: מהי בעצם בחירת תכונות?
בחירת תכונה היא תהליך בחירת התכונות הטובות ביותר עבור הדגם שלך. תהליך זה עשוי להיות שונה מטכניקה אחת לאחרת, אך המטרה העיקרית היא לגלות אילו תכונות משפיעות יותר על הדגם שלך.
מכיוון שלפעמים, תכונות רבות מדי עלולות להזיק למודל למידת המכונה שלך. אֵיך?
יכול להיות שיש יותר מדי סיבות שונות. לדוגמה, תכונות אלה עשויות להיות קשורות זו לזו, מה שעלול לגרום למולקולינאריות, להרוס את הביצועים של המודל שלך.
בעיה פוטנציאלית נוספת קשורה לכוח חישוב. נוכחותם של תכונות רבות מדי מחייבת יותר כוח חישוב לביצוע המשימה במקביל, מה שעלול לדרוש יותר משאבים וכתוצאה מכך, עלויות מוגברות.
בהחלט, יכולות להיות גם סיבות אחרות. אבל הדוגמאות האלה אמורות לתת לך מושג כללי על הבעיות הפוטנציאליות. עם זאת, יש עוד היבט חשוב להבין לפני שנעמיק בנושא זה.
כן, זו שאלה מצוינת ויש לענות עליה לפני תחילת הפרויקט. אבל לא קל לתת תשובה כללית.
הבחירה במודל לבחירת תכונה מסתמכת על סוג הנתונים שיש לך ועל מטרת הפרויקט שלך.
לדוגמה, שיטות המבוססות על פילטרים כגון מבחן צ'י בריבוע או השגת מידע הדדי משמשות בדרך כלל לבחירת תכונה בנתונים קטגוריים. השיטות המבוססות על מעטפת כמו בחירה קדימה או אחורה מתאימות לנתונים מספריים.
עם זאת, טוב לדעת ששיטות רבות לבחירת תכונות יכולות להתמודד עם נתונים קטגוריים ומספריים כאחד.
לדוגמה, רגרסיית לאסו, עצי החלטה ויער אקראי יכולים להתמודד עם שני סוגי הנתונים בצורה טובה למדי.
במונחים של בחירת תכונה מפוקחת ובלתי מפוקחת, שיטות מפוקחות כמו חיסול תכונה רקורסיבית או עצי החלטה טובים לנתונים מסומנים. שיטות לא מפוקחות כמו ניתוח רכיבים עיקריים (PCA) או ניתוח רכיבים עצמאיים (ICA) משמשות לנתונים לא מסומנים.
בסופו של דבר, הבחירה בשיטת בחירת התכונות צריכה להתבסס על המאפיינים הספציפיים של הנתונים שלך ועל המטרות של הפרויקט שלך.
עיין בסקירה הכללית של הנושאים בהם נדון במאמר. הכר את עצמך, ובואו נתחיל עם טכניקות בחירת תכונות מפוקחות.
תמונה מאת המחבר
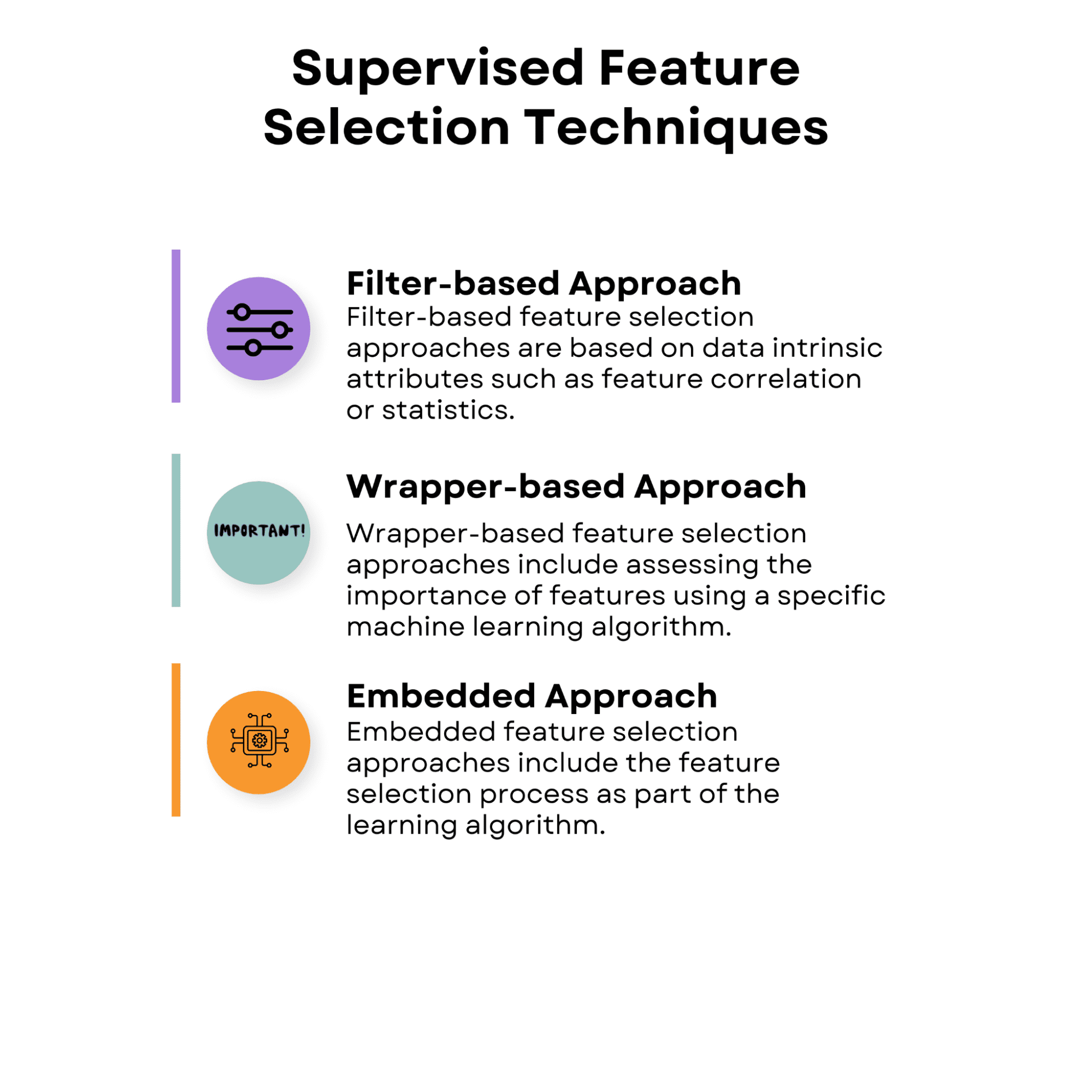
אסטרטגיות בחירת תכונות בלמידה מפוקחת מטרתן לגלות את התכונות הרלוונטיות ביותר לחיזוי משתנה היעד על ידי שימוש בקשר בין תכונות הקלט למשתנה היעד. אסטרטגיות אלו עשויות לעזור לשפר את ביצועי המודל, להפחית התאמה יתרה ולהוזיל את העלות החישובית של אימון המודל.
להלן הסקירה הכללית של טכניקות בחירת התכונות המפוקחות עליהן נדבר.
תמונה מאת המחבר
1.1 גישה מבוססת פילטרים
גישות לבחירת תכונות מבוססות-מסנן מבוססות על תכונות מהותיות של נתונים כגון מתאם תכונות או סטטיסטיקה. גישות אלו מעריכות את הערך של כל מאפיין לבד או בזוגות מבלי לקחת בחשבון את הביצועים של אלגוריתם למידה מסוים.
גישות מבוססות מסננים הן יעילות חישוביות וניתן להשתמש בהן עם מגוון אלגוריתמי למידה. עם זאת, מכיוון שהם אינם מביאים בחשבון את האינטראקציה בין התכונות לשיטת הלמידה, ייתכן שהם לא תמיד תופסים את תת-קבוצת התכונות האידיאלית עבור אלגוריתם מסוים.
עיין בסקירה הכללית של הגישות המבוססות על מסננים, ולאחר מכן נדון בכל אחת מהן.

תמונה מאת המחבר
רווח מידע
רווח מידע הוא נתון שמודד את הפחתת האנטרופיה (אי הוודאות) עבור תכונה ספציפית על ידי חלוקת הנתונים לפי מאפיין זה. הוא משמש לעתים קרובות באלגוריתמים של עצי החלטות ויש לו גם תכונות שימושיות. ככל שרווח המידע של תכונה גבוה יותר, כך הוא מועיל יותר לקבלת החלטות.
כעת, בואו ניישם רווח מידע על ידי שימוש במערך נתונים של סוכרת שנבנה מראש.
מערך הסוכרת מכיל מאפיינים פיזיולוגיים הקשורים לניבוי התקדמות הסוכרת.
- גיל: גיל בשנים
- מין: מגדר (1 = זכר, 0 = נקבה)
- BMI: מדד מסת הגוף, מחושב כמשקל בקילוגרמים חלקי ריבוע הגובה במטרים
- bp: לחץ דם ממוצע (מ"מ כספית)
- s1, s2, s3, s4, s5, s6: מדידות סרום בדם של שישה כימיקלים שונים בדם (כולל גלוקוז),
הקוד הבא מדגים כיצד ליישם את שיטת השגת מידע. קוד זה משתמש במערך הנתונים של סוכרת מספריית sklearn כדוגמה.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression # Load the diabetes dataset
data = load_diabetes() # Split the dataset into features and target
X = data.data
y = data.target
המטרה העיקרית של קוד זה היא לחשב ציוני חשיבות של תכונה על סמך רווח מידע, שעוזר לזהות את התכונות הרלוונטיות ביותר עבור המודל החזוי. על ידי קביעת ציונים אלה, אתה יכול לקבל החלטות מושכלות לגבי התכונות לכלול או לא לכלול מהניתוח שלך, מה שיוביל בסופו של דבר לשיפור ביצועי הדגם, צמצום התאמה יתר וזמני אימון מהירים יותר.
כדי להשיג זאת, קוד זה מחשב את ציוני רווחי המידע עבור כל תכונה במערך הנתונים ומאחסן אותם במילון.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression # Load the diabetes dataset
data = load_diabetes() # Split the dataset into features and target
X = data.data
y = data.target # Apply Information Gain
ig = mutual_info_regression(X, y) # Create a dictionary of feature importance scores
feature_scores = {}
for i in range(len(data.feature_names)): feature_scores[data.feature_names[i]] = ig[i]
לאחר מכן התכונות ממוינות בסדר יורד לפי הציונים שלהן.
# Sort the features by importance score in descending order
sorted_features = sorted(feature_scores.items(), key=lambda x: x[1], reverse=True) # Print the feature importance scores and the sorted features
for feature, score in sorted_features: print('Feature:', feature, 'Score:', score)
אנו נדמיין את ציוני חשיבות התכונה הממוינים כתרשים עמודות אופקי, המאפשר לך להשוות בקלות את הרלוונטיות של תכונות שונות עבור המשימה הנתונה.
הדמיה זו מועילה במיוחד כאשר מחליטים אילו תכונות לשמור או לבטל בזמן בניית מודל למידת מכונה.
# Plot a horizontal bar chart of the feature importance scores
fig, ax = plt.subplots()
y_pos = np.arange(len(sorted_features))
ax.barh(y_pos, [score for feature, score in sorted_features], align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels([feature for feature, score in sorted_features])
ax.invert_yaxis() # Labels read top-to-bottom
ax.set_xlabel("Importance Score")
ax.set_title("Feature Importance Scores (Information Gain)") # Add importance scores as labels on the horizontal bar chart
for i, v in enumerate([score for feature, score in sorted_features]): ax.text(v + 0.01, i, str(round(v, 3)), color="black", fontweight="bold")
plt.show()
בוא נראה את כל הקוד.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression # Load the diabetes dataset
data = load_diabetes() # Split the dataset into features and target
X = data.data
y = data.target # Apply Information Gain
ig = mutual_info_regression(X, y) # Create a dictionary of feature importance scores
feature_scores = {}
for i in range(len(data.feature_names)): feature_scores[data.feature_names[i]] = ig[i]
# Sort the features by importance score in descending order
sorted_features = sorted(feature_scores.items(), key=lambda x: x[1], reverse=True) # Print the feature importance scores and the sorted features
for feature, score in sorted_features: print("Feature:", feature, "Score:", score)
# Plot a horizontal bar chart of the feature importance scores
fig, ax = plt.subplots()
y_pos = np.arange(len(sorted_features))
ax.barh(y_pos, [score for feature, score in sorted_features], align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels([feature for feature, score in sorted_features])
ax.invert_yaxis() # Labels read top-to-bottom
ax.set_xlabel("Importance Score")
ax.set_title("Feature Importance Scores (Information Gain)") # Add importance scores as labels on the horizontal bar chart
for i, v in enumerate([score for feature, score in sorted_features]): ax.text(v + 0.01, i, str(round(v, 3)), color="black", fontweight="bold")
plt.show()
הנה הפלט.
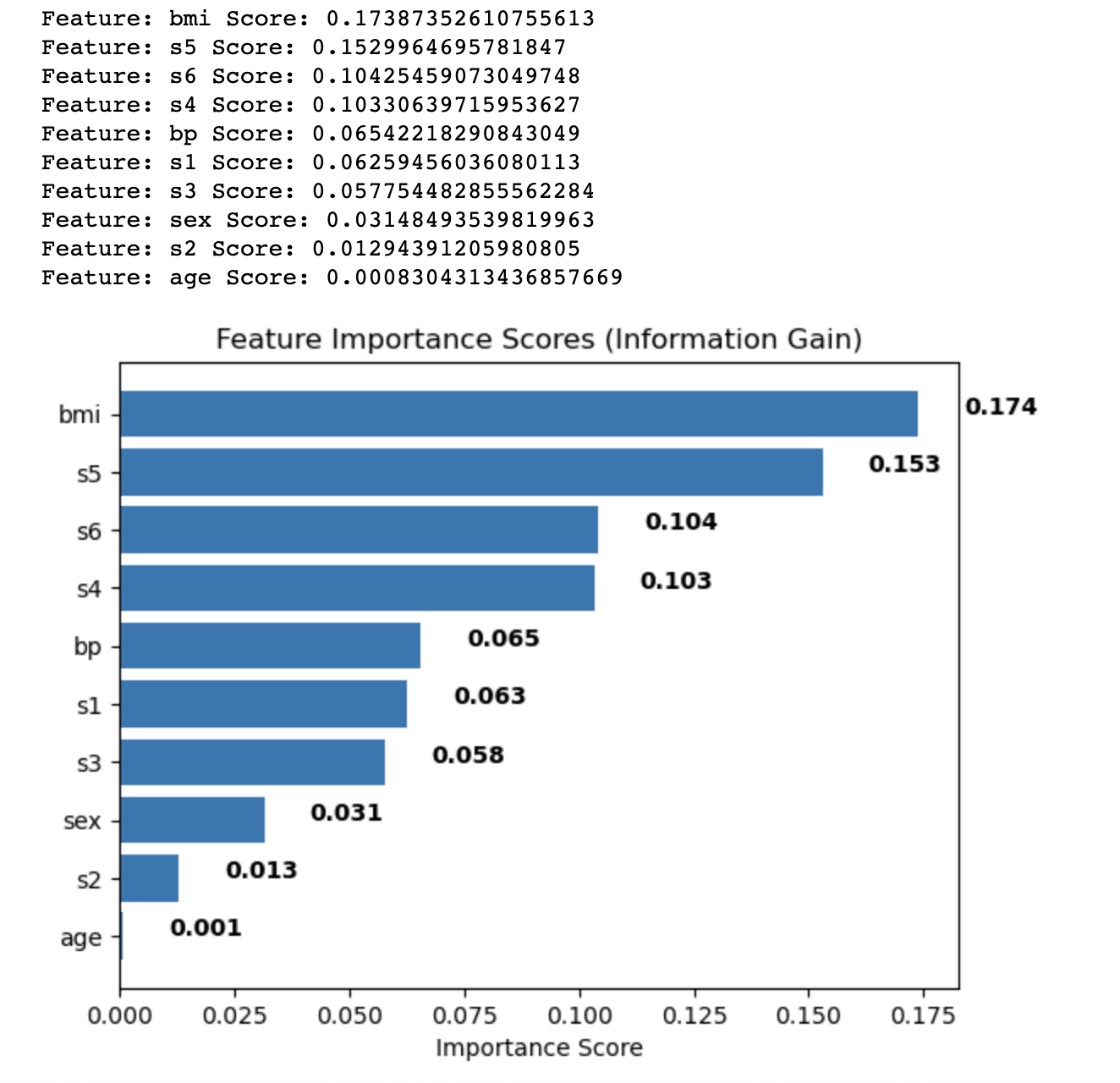
הפלט מציג את ציוני חשיבות התכונה המחושבים באמצעות שיטת מידע רווח עבור כל תכונה במערך הנתונים של סוכרת. התכונות ממוינות בסדר יורד על סמך הציונים שלהן, המעידים על חשיבותן היחסית בחיזוי משתנה היעד.
התוצאות הן כדלקמן:
- לאינדקס מסת הגוף (bmi) יש את ציון החשיבות הגבוה ביותר (0.174), המצביע על כך שיש לו את ההשפעה המשמעותית ביותר על משתנה היעד במערך הנתונים של סוכרת.
- מדידת סרום 5 (s5) לאחר מכן עם ציון של 0.153, מה שהופך אותה לתכונה השנייה בחשיבותה.
- למדידת סרום 6 (s6), מדידת סרום 4 (s4), ולחץ הדם (bp) יש ציוני חשיבות בינוניים, הנעים בין 0.104 ל-0.065.
- לשאר המאפיינים, כמו מדידות סרום 1, 2 ו-3 (s1, s2, s3), מין וגיל, יש ציוני חשיבות נמוכים יחסית, מה שמצביע על כך שהם תורמים פחות לכוח הניבוי של המודל.
על ידי ניתוח ציוני חשיבות התכונות הללו, תוכל להחליט אילו תכונות לכלול או לא לכלול מהניתוח שלך כדי לשפר את הביצועים של מודל למידת המכונה שלך. במקרה זה, תוכל לשקול לשמור על תכונות עם ציוני חשיבות גבוהים יותר, כגון bmi ו-s5, תוך הסרה או חקירה נוספת של תכונות עם ציונים נמוכים יותר, כגון גיל ו-s2.
מבחן צ'י מרובע
מבחן צ'י ריבוע הוא מבחן סטטיסטי המשמש להערכת הקשר בין שני משתנים קטגוריים. הוא משמש בבחירת תכונה כדי לנתח את הקשר בין תכונה קטגורית למשתנה היעד. ציון צ'י ריבוע גדול יותר מראה קשר חזק יותר בין התכונה למטרה, מראה שהתכונה חשובה יותר לעבודת הסיווג.
בעוד שמבחן צ'י ריבוע הוא שיטת בחירת תכונות נפוצה, היא משמשת בדרך כלל לנתונים קטגוריים, כאשר התכונות ומשתני היעד הם בדידים.
הציון של פישר
Fisher's Discriminant Ratio, הידוע בכינויו פישר's Score, היא גישת בחירת תכונות המדרגת תכונות על סמך יכולתן להבדיל בין מחלקות שונות במערך נתונים. זה עשוי לשמש עבור תכונות רציפות בבעיית סיווג.
ציון פישר מחושב כיחס בין השונות בין המחלקה לבין השונות בתוך המחלקה. ציון פישר גבוה יותר מרמז שהמאפיין הוא יותר מפלה ובעל ערך לסיווג.
כדי להשתמש בציון פישר לבחירת תכונה, חשב ניקוד עבור כל תכונה רציפה ודרג אותם לפי הציונים שלהם. המודל מחשיב תכונות עם ציון פישר גבוה יותר חשובות יותר.
יחס ערך חסר
יחס הערך החסר הוא שיטת בחירת תכונה פשוטה שמקבלת החלטות על סמך מספר הערכים החסרים בתכונה.
תכונות שיש בהן חלק ניכר מהערכים החסרים עלולות להיות לא אינפורמטיביות ועלולות לפגוע בביצועי המודל. אתה יכול לסנן תכונות עם יותר מדי ערכים חסרים על ידי ציון סף ליחס הערך החסר המקובל.
כדי להשתמש ביחס ערך חסר לבחירת תכונה, בצע את השלבים הבאים:
- חשב את יחס הערכים החסרים עבור כל תכונה על ידי חלוקת מספר הערכים החסרים במספר הכולל של מופעים במערך הנתונים.
- הגדר סף עבור יחס הערך החסר המקובל (לדוגמה, 0.8, כלומר, לתכונה צריכים להיות חסרים לכל היותר 80% מהערכים שלה כדי להיחשב).
- סנן תכונות שיש להן יחס ערך חסר מעל הסף.
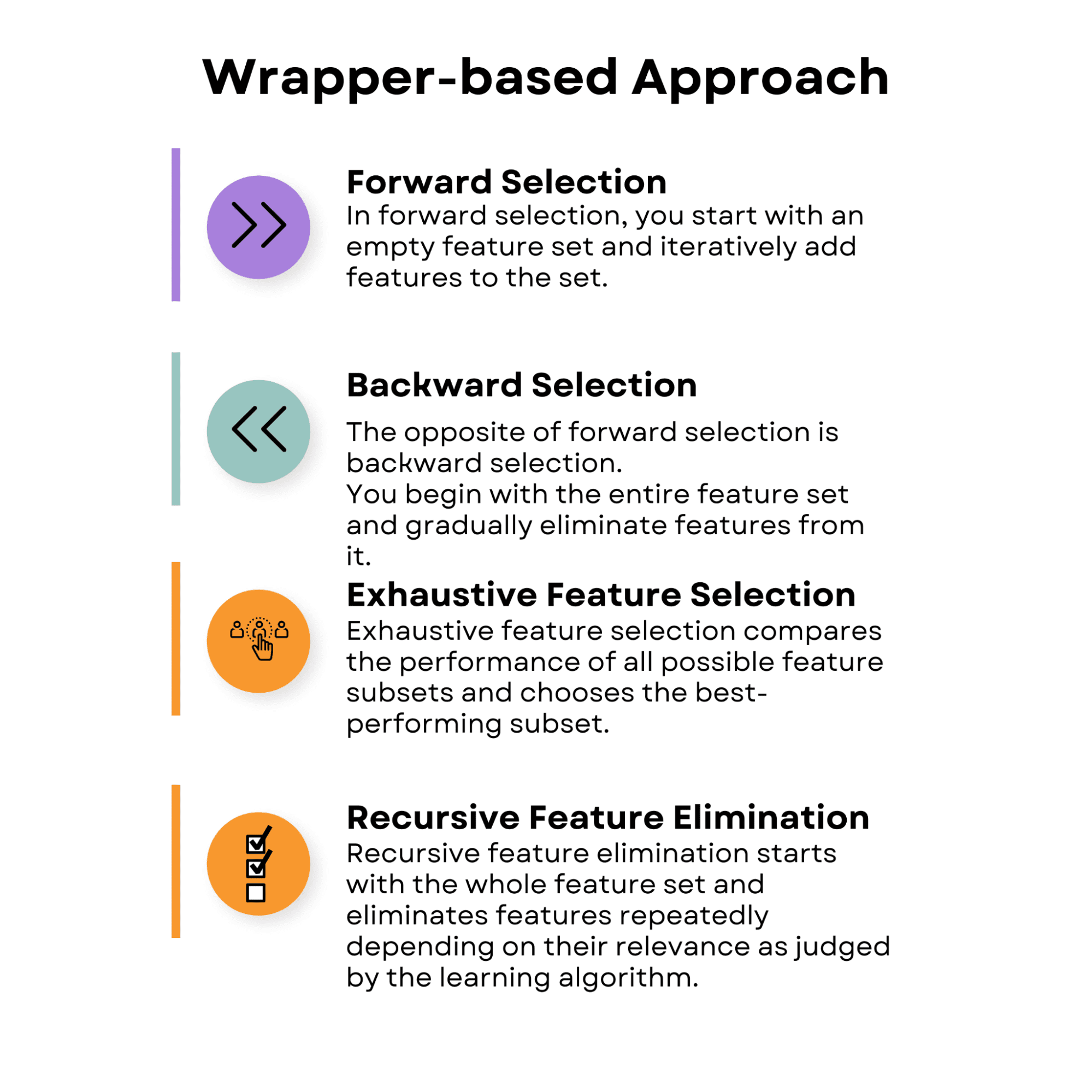
1.2 גישה מבוססת עטיפה
גישות לבחירת תכונות מבוססות-עטיפה כוללות הערכת חשיבותן של תכונות באמצעות אלגוריתם למידת מכונה ספציפי. הם מחפשים את המשנה הטובה ביותר של תכונות על ידי התנסות בשילובי תכונות שונים והערכת הביצועים שלהם בשיטה שנבחרה.
בגלל הכמות העצומה של תת-קבוצות של תכונות זמינות, גישות מבוססות-עטיפה יכולות להיות יקרות מבחינה חישובית, במיוחד כאשר עובדים עם מערכי נתונים בעלי ממדים גבוהים.
עם זאת, לעתים קרובות הם עולים על גישות המבוססות על מסננים מכיוון שהם רואים את הקשר בין תכונות לאלגוריתם הלמידה.
תמונה מאת המחבר
בחירה קדימה
בבחירה קדימה, אתה מתחיל עם ערכת תכונות ריקה ומוסיף באופן איטרטיבי תכונות לסט. בכל שלב, אתה מעריך את ביצועי המודל עם ערכת התכונות הנוכחית והתכונה הנוספת. התכונה שמביאה לשיפור הביצועים הטוב ביותר מתווספת לסט.
התהליך נמשך עד שלא נצפה שיפור משמעותי בביצועים, או שמגיעים למספר מוגדר מראש של תכונות.
הקוד הבא מדגים את היישום של בחירה קדימה, טכניקת בחירת תכונה מפוקחת המבוססת על מעטפת.
הדוגמה משתמשת במערך הנתונים של סרטן השד מספריית sklearn. מערך הנתונים של סרטן השד, המכונה גם מערך הנתונים של סרטן השד של ויסקונסין (WDBC), הוא מערך נתונים נפוץ שנבנה מראש לסיווג. וכאן, המטרה העיקרית היא בניית מודלים חזויים לאבחון סרטן השד כממאיר (סרטני) או שפיר (לא סרטני).
למען המודל שלנו, נבחר מספר שונה של תכונות כדי לראות כיצד הביצועים משתנים בהתאם, אך ראשית, בואו נטען את הספריות, מערך הנתונים והמשתנים.
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS # Load the breast cancer dataset
data = load_breast_cancer() # Split the dataset into features and target
X = data.data
y = data.target
מטרת הקוד היא לזהות תת-קבוצה אופטימלית של תכונות עבור מודל רגרסיה לוגיסטי באמצעות בחירה קדימה. טכניקה זו מתחילה עם קבוצה ריקה של תכונות ומוסיפה באופן איטרטיבי את התכונות המשפרות את ביצועי המודל בהתבסס על מדד הערכה מוגדר. במקרה זה, המדד המשמש הוא דיוק.
החלק הבא של הקוד משתמש ב-SequentialFeatureSelector מספריית mlxtend כדי לבצע בחירה קדימה. הוא מוגדר עם מודל רגרסיה לוגיסטי, מספר התכונות הרצוי ואימות צולב פי 5. אובייקט הבחירה קדימה מותאם לנתוני האימון, והתכונות שנבחרו מודפסות.
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS # Load the breast cancer dataset
data = load_breast_cancer() # Split the dataset into features and target
X = data.data
y = data.target # Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # Define the logistic regression model
model = LogisticRegression() # Define the forward selection object
sfs = SFS(model, k_features=5, forward=True, floating=False, scoring='accuracy', cv=5) # Perform forward selection on the training set
sfs.fit(X_train, y_train)
בנוסף, עלינו להעריך את הביצועים של התכונות שנבחרו בערכת הבדיקות ולדמיין את ביצועי המודל עם תת-קבוצות שונות בתרשים קווים.
התרשים יציג את הדיוק המאומת כפונקציה של מספר התכונות, ויספק תובנות לגבי הפשרה בין מורכבות המודל לביצועים חזויים.
על ידי ניתוח הפלט והתרשים, אתה יכול לקבוע את המספר האופטימלי של תכונות לכלול בדגם שלך, בסופו של דבר לשפר את הביצועים שלו ולהפחית התאמה יתר.
# Print the selected features
print('Selected Features:', sfs.k_feature_names_) # Evaluate the performance of the selected features on the testing set
accuracy = sfs.k_score_
print('Accuracy:', accuracy) # Plot the performance of the model with different feature subsets
sfs_df = pd.DataFrame.from_dict(sfs.get_metric_dict()).T
sfs_df['avg_score'] = sfs_df['avg_score'].astype(float)
fig, ax = plt.subplots()
sfs_df.plot(kind='line', y='avg_score', ax=ax)
ax.set_xlabel('Number of Features')
ax.set_ylabel('Accuracy')
ax.set_title('Forward Selection Performance')
plt.show()
הנה כל הקוד.
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS # Load the breast cancer dataset
data = load_breast_cancer() # Split the dataset into features and target
X = data.data
y = data.target # Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # Define the logistic regression model
model = LogisticRegression() # Define the forward selection object
sfs = SFS(model, k_features=5, forward=True, floating=False, scoring="accuracy", cv=5) # Perform forward selection on the training set
sfs.fit(X_train, y_train) # Print the selected features
print("Selected Features:", sfs.k_feature_names_) # Evaluate the performance of the selected features on the testing set
accuracy = sfs.k_score_
print("Accuracy:", accuracy) # Plot the performance of the model with different feature subsets
sfs_df = pd.DataFrame.from_dict(sfs.get_metric_dict()).T
sfs_df["avg_score"] = sfs_df["avg_score"].astype(float)
fig, ax = plt.subplots()
sfs_df.plot(kind="line", y="avg_score", ax=ax)
ax.set_xlabel("Number of Features")
ax.set_ylabel("Accuracy")
ax.set_title("Forward Selection Performance")
plt.show()
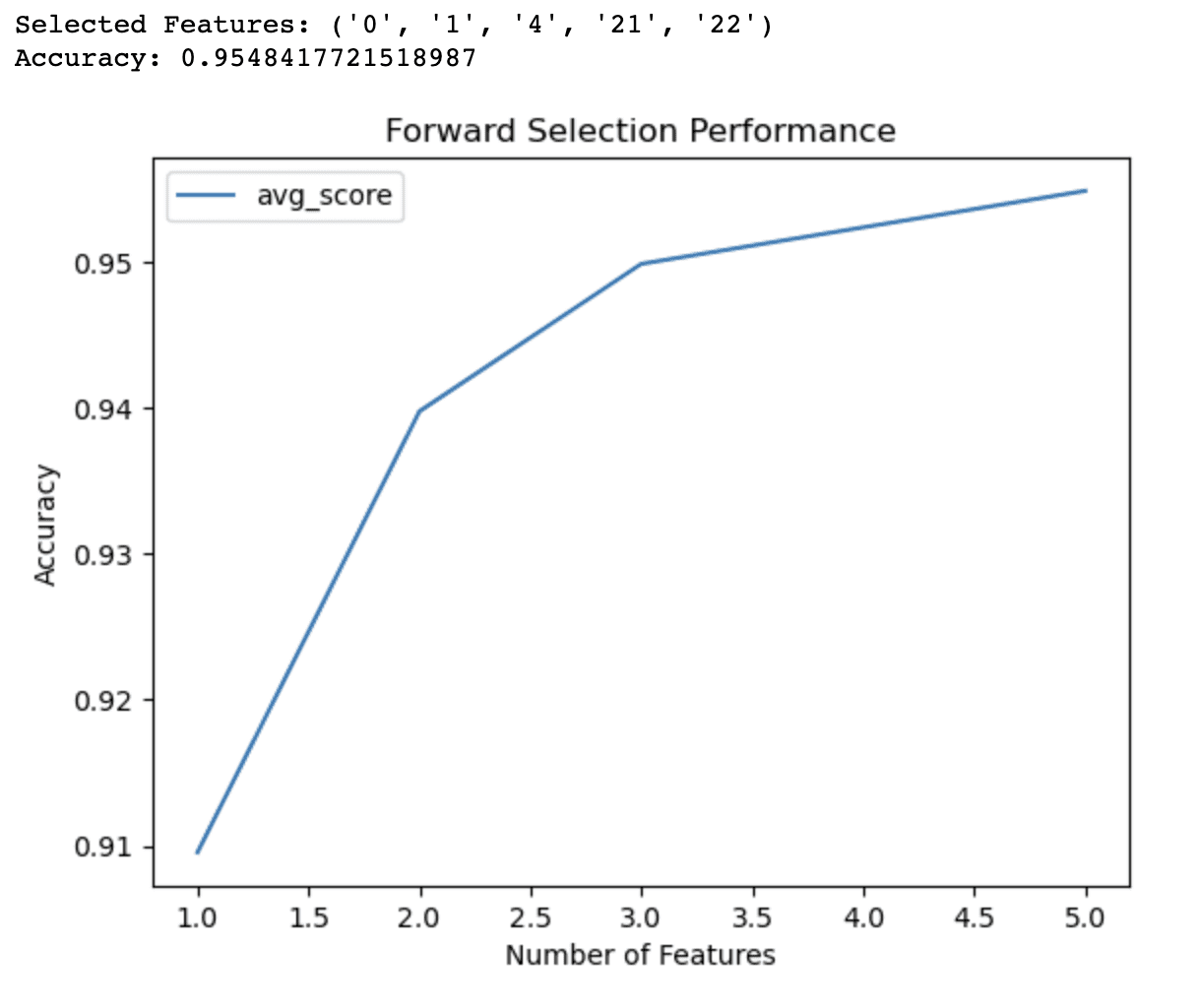
הפלט של קוד הבחירה קדימה מוכיח שהאלגוריתם זיהה תת-קבוצה של 5 תכונות המניבות את הדיוק הטוב ביותר (0.9548) עבור מודל הרגרסיה הלוגיסטי במערך הנתונים של סרטן השד. תכונות נבחרות אלו מזוהות לפי המדדים שלהן: 0, 1, 4, 21 ו-22.
גרף הקו מספק תובנות נוספות לגבי הביצועים של המודל עם מספרים שונים של תכונות. זה מראה ש:
- עם תכונה אחת בלבד, הדגם משיג דיוק של כ-1%.
- הוספת תכונה שנייה מגדילה את הדיוק ל-94%.
- עם 3 תכונות, הדיוק משתפר עוד יותר ל-95%.
- כולל 4 תכונות דוחף את הדיוק מעט מעל 95%.
מעבר ל-4 תכונות, השיפורים ברמת הדיוק הופכים פחות משמעותיים. מידע זה יכול לעזור לך לקבל החלטות מושכלות לגבי השינויים בין מורכבות המודל לביצועים חזויים. בהתבסס על תוצאות אלו, ייתכן שתחליט להשתמש רק ב-3 או 4 תכונות במודל שלך כדי לאזן בין דיוק לפשטות.
בחירה לאחור
ההפך מבחירה קדימה היא בחירה אחורה. אתה מתחיל עם מערך התכונות כולו ומבטל ממנו תכונות בהדרגה.
בכל שלב, אתה מודד את ביצועי המודל עם ערכת התכונות הנוכחית פחות הפיצ'ר שיש למחוק.
התכונה שגורמת לפחות הפחתת ביצועים נמחקת מהסט.
ההליך חוזר על עצמו עד שאין עליה משמעותית בביצועים או שמגיעים למספר מוגדר מראש של תכונות.
בחירות אחורה וקדימה מסווגות כבחירת תכונה רציפה; אתה יכול ללמוד יותר כאן.
מבחר תכונות ממצה
בחירת תכונות ממצה משווה את הביצועים של כל תת-קבוצות התכונות האפשריות ובוחרת את המשנה בעלת הביצועים הטובים ביותר. גישה זו תובענית מבחינה חישובית, במיוחד עבור מערכי נתונים גדולים, אך היא מבטיחה את תת-קבוצת התכונות הטובה ביותר.
חיסול תכונה רקורסיבית
ביטול תכונות רקורסיבי מתחיל עם כל מערך התכונות ומבטל תכונות שוב ושוב בהתאם לרלוונטיות שלהן כפי שנשפט על ידי אלגוריתם הלמידה. התכונה הפחות חשובה מוסרת בכל שלב, והמודל עובר הכשרה מחדש. השיטה חוזרת על עצמה עד להשגת מספר קבוע מראש של תכונות.
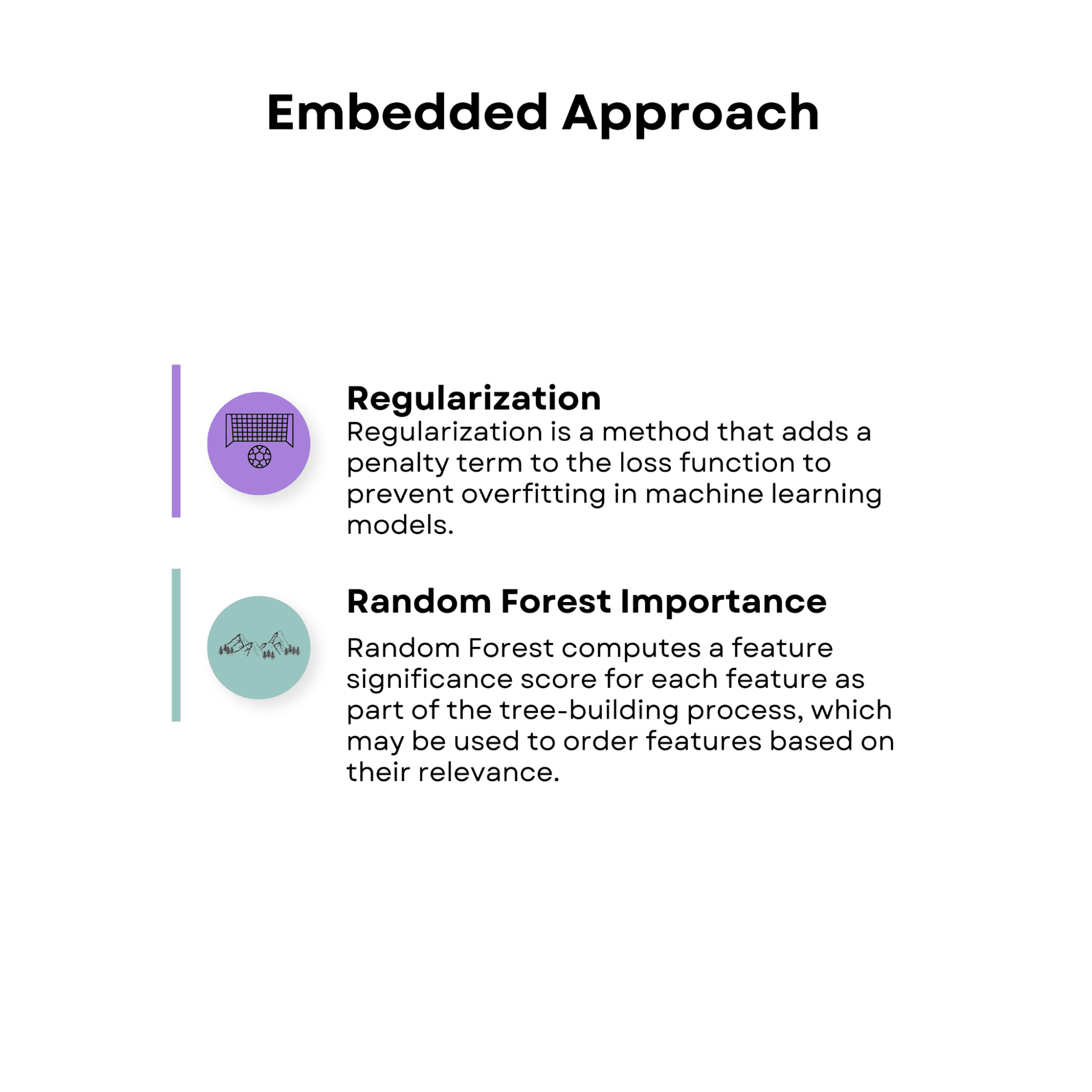
1.3 גישה משובצת
גישות לבחירת תכונות משובצות כוללות את תהליך בחירת התכונות כחלק מאלגוריתם הלמידה.
זה מרמז שלאורך שלב האימון, אלגוריתם הלמידה לא רק מייעל את פרמטרי המודל אלא גם בוחר את המאפיינים החשובים ביותר. שיטות משובצות יכולות להיות יעילות יותר משיטות עטיפה מכיוון שהן אינן דורשות הליך בחירת תכונה חיצונית.
תמונה מאת המחבר
ויסות
רגוליזציה היא שיטה שמוסיפה מונח עונש לפונקציית ההפסד כדי למנוע התאמה יתר במודלים של למידת מכונה.
ניתן להשתמש בשיטות רגוליזציה, כגון לאסו (רגוליזציה L1) ורכס (רגוליזציה L2), בשילוב עם בחירת תכונה כדי להקטין את המקדמים של תכונות פחות משמעותיות לכיוון אפס, ובכך לבחור תת-קבוצה של התכונות הרלוונטיות ביותר.
חשיבות יער אקראית
יער אקראי הוא גישת למידה אנסמבלית המשלבת תחזיות של מספר עצי החלטה. יער אקראי מחשב ציון מובהקות תכונה עבור כל תכונה כחלק מתהליך בניית העצים, שניתן להשתמש בו כדי לסדר תכונות על סמך הרלוונטיות שלהן. המודל מחשיב תכונות בעלות דירוג מובהקות גבוה יותר כמשמעותיות יותר.
אם אתה רוצה ללמוד עוד על היער האקראי, הנה המאמר "עץ החלטה ואלגוריתם יער אקראי", מה שמסביר גם את אלגוריתם עץ ההחלטות.
הדוגמה הבאה משתמשת במערך הנתונים Covertype, הכולל מידע על סוגים שונים של כיסוי יער.
מטרת מערך הנתונים של Covertype היא לחזות את סוג כיסוי היער (מיני העצים הדומיננטיים) בתוך היער הלאומי רוזוולט של צפון קולורדו.
המטרה העיקרית של הקוד שלהלן היא לקבוע את החשיבות של תכונות באמצעות מסווג יער אקראי. על ידי הערכת התרומה של כל תכונה לביצועי הסיווג הכוללים, שיטה זו עוזרת לזהות את התכונות הרלוונטיות ביותר לבניית מודל חזוי.
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt # Load the Covertype dataset
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz", header=None) # Assign column names
cols = ["Elevation", "Aspect", "Slope", "Horizontal_Distance_To_Hydrology", "Vertical_Distance_To_Hydrology", "Horizontal_Distance_To_Roadways", "Hillshade_9am", "Hillshade_Noon", "Hillshade_3pm", "Horizontal_Distance_To_Fire_Points"] + ["Wilderness_Area_"+str(i) for i in range(1,5)] + ["Soil_Type_"+str(i) for i in range(1,41)] + ["Cover_Type"] data.columns = cols
לאחר מכן, אנו יוצרים אובייקט RandomForestClassifier ומתאים אותו לנתוני האימון. לאחר מכן הוא מחלץ את חשיבות התכונה מהמודל המאומן וממיין אותם בסדר יורד. 10 התכונות המובילות נבחרות על סמך ציוני החשיבות שלהן ומוצגות בדירוג.
# Split the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # Create a random forest classifier object
rfc = RandomForestClassifier(n_estimators=100, random_state=42) # Fit the model to the training data
rfc.fit(X_train, y_train) # Get feature importances from the trained model
importances = rfc.feature_importances_ # Sort the feature importances in descending order
indices = np.argsort(importances)[::-1] # Select the top 10 features
num_features = 10
top_indices = indices[:num_features]
top_importances = importances[top_indices] # Print the top 10 feature rankings
print("Top 10 feature rankings:")
for f in range(num_features): # Use num_features instead of 10 print(f"{f+1}. {X_train.columns[indices[f]]}: {importances[indices[f]]}")
בנוסף, הקוד מדגים את 10 חשיבות התכונות המובילות באמצעות תרשים עמודות אופקי.
# Plot the top 10 feature importances in a horizontal bar chart
plt.barh(range(num_features), top_importances, align='center')
plt.yticks(range(num_features), X_train.columns[top_indices])
plt.xlabel("Feature Importance")
plt.ylabel("Feature")
plt.show()
הדמיה זו מאפשרת השוואה קלה של ציוני החשיבות ומסייעת בקבלת החלטות מושכלות לגבי אילו תכונות לכלול או לא לכלול מהניתוח שלך.
על ידי בחינת הפלט והתרשים, אתה יכול לבחור את התכונות הרלוונטיות ביותר עבור המודל החזוי שלך, מה שיכול לעזור לשפר את הביצועים שלו, להפחית התאמה יתר ולהאיץ את זמני האימון.
הנה כל הקוד.
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt # Load the Covertype dataset
data = pd.read_csv( "https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz", header=None,
) # Assign column names
cols = ( [ "Elevation", "Aspect", "Slope", "Horizontal_Distance_To_Hydrology", "Vertical_Distance_To_Hydrology", "Horizontal_Distance_To_Roadways", "Hillshade_9am", "Hillshade_Noon", "Hillshade_3pm", "Horizontal_Distance_To_Fire_Points", ] + ["Wilderness_Area_" + str(i) for i in range(1, 5)] + ["Soil_Type_" + str(i) for i in range(1, 41)] + ["Cover_Type"]
) data.columns = cols # Split the dataset into features and target
X = data.iloc[:, :-1]
y = data.iloc[:, -1] # Split the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=42
) # Create a random forest classifier object
rfc = RandomForestClassifier(n_estimators=100, random_state=42) # Fit the model to the training data
rfc.fit(X_train, y_train) # Get feature importances from the trained model
importances = rfc.feature_importances_ # Sort the feature importances in descending order
indices = np.argsort(importances)[::-1] # Select the top 10 features
num_features = 10
top_indices = indices[:num_features]
top_importances = importances[top_indices] # Print the top 10 feature rankings
print("Top 10 feature rankings:")
for f in range(num_features): # Use num_features instead of 10 print(f"{f+1}. {X_train.columns[indices[f]]}: {importances[indices[f]]}")
# Plot the top 10 feature importances in a horizontal bar chart
plt.barh(range(num_features), top_importances, align="center")
plt.yticks(range(num_features), X_train.columns[top_indices])
plt.xlabel("Feature Importance")
plt.ylabel("Feature")
plt.show()
הנה הפלט.
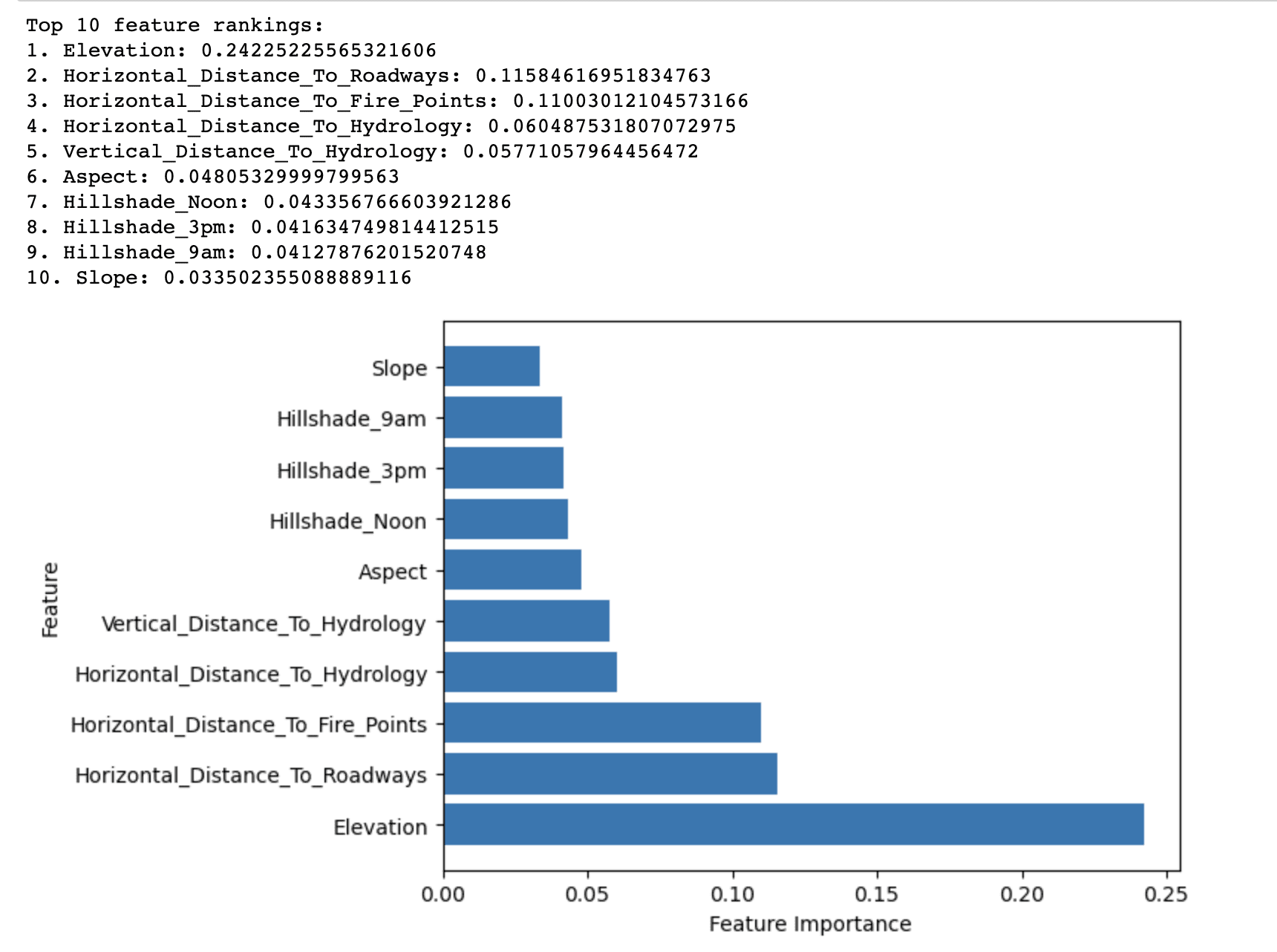
הפלט של שיטת חשיבות היער האקראי מציג את 10 התכונות המובילות המדורגות לפי חשיבותן בחיזוי סוג כיסוי היער במערך הנתונים של Covertype.
הוא מגלה שלגובה יש את ציון החשיבות הגבוה ביותר (0.2423) מבין כל המאפיינים בחיזוי סוג כיסוי היער. זה מצביע על כך שלגובה יש תפקיד קריטי בקביעת מיני העצים הדומיננטיים ביער הלאומי רוזוולט.
תכונות אחרות בעלות ציוני חשיבות גבוהים יחסית כוללות Horizontal_Distance_To_Roadways (0.1158) ו- Horizontal_Distance_To_Fire_Points (0.1100). אלה מצביעים על כך שהקרבה לכבישים ולנקודות הצתת אש משפיעה באופן משמעותי גם על סוגי כיסוי היער.
למאפיינים הנותרים ברשימת 10 המובילים יש ציוני חשיבות נמוכים יחסית, אך הם עדיין תורמים לביצועי הניבוי הכוללים של המודל. מאפיינים אלה מתייחסים בעיקר לגורמים הידרולוגיים, מדדי שיפוע, היבט וצל גבעות.
לסיכום, התוצאות מדגישות את הגורמים החשובים ביותר המשפיעים על התפלגות סוגי כיסוי היער ביער הלאומי רוזוולט, אשר ניתן להשתמש בהם כדי לבנות מודל חיזוי יעיל ויעיל יותר לסיווג סוגי כיסוי היער.
כאשר אין משתנה יעד זמין, ניתן להשתמש בגישות לבחירת תכונה ללא פיקוח על מנת לצמצם את הממדיות של מערך הנתונים תוך שמירה על המבנה הבסיסי שלו. שיטות אלה כוללות לעתים קרובות שינוי מרחב התכונה הראשוני למרחב חדש בממדים נמוכים יותר שבו התכונות המשתנות לוכדות את רוב השונות בנתונים.

תמונה מאת המחבר
2.1 ניתוח רכיבים עיקריים (PCA)
PCA היא שיטת הפחתת מימד ליניארית הממירה את מרחב התכונה המקורי למרחב אורתוגונלי חדש המוגדר על ידי רכיבים עיקריים. רכיבים אלו הם שילובים ליניאריים של התכונות המקוריות שנבחרו כדי ללכוד את רמת השונות הגבוהה ביותר בנתונים.
ניתן להשתמש ב-PCA כדי לבחור את ק הרכיבים העיקריים המובילים המייצגים את רוב הווריאציה, ובכך להפחית את הממדיות של מערך הנתונים.
כדי להראות לך איך זה עובד בפועל, נעבוד עם מערך הנתונים של Wine. זהו מערך נתונים בשימוש נרחב למשימות סיווג ובחירת תכונות בלמידת מכונה ומורכב מ-178 דוגמאות, שכל אחת מהן מייצגת יין שונה שמקורו בשלושה זנים שונים באותו אזור באיטליה.
המטרה של העבודה עם מערך הנתונים של Wine היא בדרך כלל לבנות מודל חיזוי שיכול לסווג במדויק דגימת יין לאחד משלושת הזנים בהתבסס על התכונות הכימיות שלו.
הקוד הבא מדגים את היישום של Principal Component Analysis (PCA), טכניקת בחירת תכונות ללא פיקוח, על מערך הנתונים של Wine.
רכיבים אלו (רכיבים עיקריים) לוכדים את השונות הגדולה ביותר בנתונים תוך מזעור אובדן המידע.
הקוד מתחיל בטעינת מערך הנתונים של Wine, המורכב מ-13 תכונות המתארות את התכונות הכימיות של דגימות יין שונות.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler # Load the Wine dataset
wine = load_wine()
X = wine.data
y = wine.target
feature_names = wine.feature_names
לאחר מכן, מאפיינים אלה מותקנים באמצעות StandardScaler כדי להבטיח ש-PCA לא יושפע מקשקשים משתנים של תכונות הקלט.
# Standardize the features
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
לאחר מכן, PCA מבוצע על הנתונים הסטנדרטיים באמצעות מחלקת PCA ממודול sklearn.decomposition.
# Perform PCA
pca = PCA()
X_pca = pca.fit_transform(X_scaled)
יחס השונות המוסבר עבור כל מרכיב עיקרי מחושב, המציין את היחס של השונות הכוללת בנתונים שכל רכיב מסביר.
# Calculate the explained variance ratio
explained_variance_ratio = pca.explained_variance_ratio_
לבסוף, נוצרות שתי עלילות כדי להמחיש את יחס השונות המוסבר ואת השונות המוסברת המצטברת על ידי המרכיבים העיקריים.
העלילה הראשונה מציגה את יחס השונות המוסבר עבור כל מרכיב עיקרי אינדיבידואלי, בעוד שהחלקה השנייה ממחישה כיצד השונות המוסברת המצטברת גדלה ככל שכלולים יותר רכיבים עיקריים.
עלילות אלו עוזרות לקבוע את המספר האופטימלי של רכיבים עיקריים לשימוש במודל, תוך איזון הפשרה בין הפחתת מימדים לשמירת מידע.
# Create a 2x1 grid of subplots
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16, 8)) # Plot the explained variance ratio in the first subplot
ax1.bar(range(1, len(explained_variance_ratio) + 1), explained_variance_ratio)
ax1.set_xlabel('Principal Component')
ax1.set_ylabel('Explained Variance Ratio')
ax1.set_title('Explained Variance Ratio by Principal Component') # Calculate the cumulative explained variance
cumulative_explained_variance = np.cumsum(explained_variance_ratio) # Plot the cumulative explained variance in the second subplot
ax2.plot(range(1, len(cumulative_explained_variance) + 1), cumulative_explained_variance, marker='o')
ax2.set_xlabel('Number of Principal Components')
ax2.set_ylabel('Cumulative Explained Variance')
ax2.set_title('Cumulative Explained Variance by Principal Components') # Display the figure
plt.tight_layout()
plt.show()
בוא נראה את כל הקוד.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler # Load the Wine dataset
wine = load_wine()
X = wine.data
y = wine.target
feature_names = wine.feature_names # Standardize the features
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # Perform PCA
pca = PCA()
X_pca = pca.fit_transform(X_scaled) # Calculate the explained variance ratio
explained_variance_ratio = pca.explained_variance_ratio_ # Create a 2x1 grid of subplots
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16, 8)) # Plot the explained variance ratio in the first subplot
ax1.bar(range(1, len(explained_variance_ratio) + 1), explained_variance_ratio)
ax1.set_xlabel("Principal Component")
ax1.set_ylabel("Explained Variance Ratio")
ax1.set_title("Explained Variance Ratio by Principal Component") # Calculate the cumulative explained variance
cumulative_explained_variance = np.cumsum(explained_variance_ratio) # Plot the cumulative explained variance in the second subplot
ax2.plot( range(1, len(cumulative_explained_variance) + 1), cumulative_explained_variance, marker="o",
)
ax2.set_xlabel("Number of Principal Components")
ax2.set_ylabel("Cumulative Explained Variance")
ax2.set_title("Cumulative Explained Variance by Principal Components") # Display the figure
plt.tight_layout()
plt.show()
הנה הפלט.
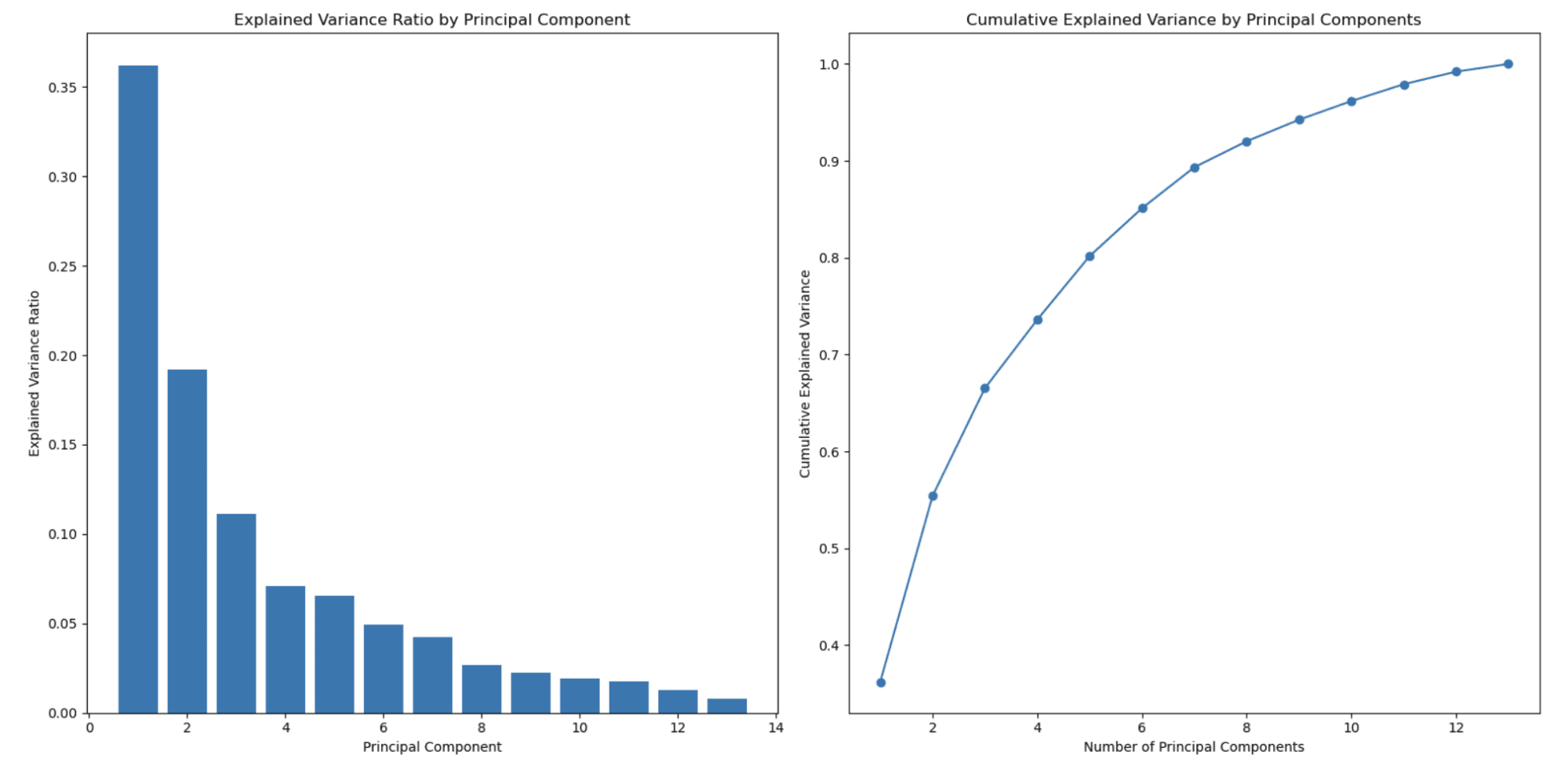
הגרף משמאל מראה שיחס השונות המוסבר יורד ככל שמספר המרכיבים העיקריים גדל. זוהי התנהגות אופיינית הנצפית ב-PCA מכיוון שהרכיבים העיקריים מסודרים לפי כמות השונות שהם מסבירים.
הרכיב הראשי הראשון (תכונה) לוכד את השונות הגבוהה ביותר, המרכיב העיקרי השני לוכד את הכמות השנייה הגבוהה ביותר, וכן הלאה. כתוצאה מכך, יחס השונות המוסבר יורד עם כל מרכיב עיקרי עוקב.
זו אחת הסיבות העיקריות שבגללן משתמשים ב-PCA להפחתת ממדי.
הגרף השני מימין מציג את השונות המוסברת המצטברת ועוזר לך לקבוע כמה רכיבים (תכונות) עיקריים לבחור כדי לייצג את אחוז הנתונים שלך. ציר ה-x מייצג את מספר הרכיבים העיקריים, וציר ה-y מציג את השונות המוסברת המצטברת. כאשר אתה נע לאורך ציר ה-x, אתה יכול לראות כמה מהשונות הכוללת נשמר כאשר אתה כולל כל כך הרבה רכיבים עיקריים.
בדוגמה זו, אתה יכול לראות שבחירה של כ-3 או 4 רכיבים עיקריים כבר תופסת יותר מ-80% מהשונות הכוללת, וכ-8 רכיבים עיקריים תופסים למעלה מ-90% מהשונות הכוללת.
אתה יכול לבחור את מספר הרכיבים העיקריים בהתבסס על ההחלפה הרצויה שלך בין הפחתת מימד לבין השונות שברצונך לשמור.
בדוגמה זו, השתמשנו ב-Sci-kit כדי ללמוד ליישם PCA, וכאן תוכלו למצוא את המסמך הרשמי.
2.2 ניתוח רכיבים עצמאיים (ICA)
ICA היא שיטה לחלוקת אות רב ממדי למרכיביו.
בהקשר של בחירת תכונה, ניתן להשתמש ב-ICA כדי להמיר את חלל התכונה המקורי למרחב חדש המאופיין ברכיבים בלתי תלויים סטטיסטית. אתה יכול להקטין את הממדיות של מערך הנתונים תוך שמירה על המבנה הבסיסי על ידי בחירת ק הרכיבים הבלתי תלויים העליונים.
2.3 פקטוריזציה של מטריקס לא שלילי (NMF)
מטריצת המטריצה הלא-שלילית (NMF) היא גישת הפחתת מימדיות המקרבת מטריצת נתונים לא-שלילית כמכפלה של שתי מטריצות לא-שליליות בממדים נמוכים יותר.
ניתן להשתמש ב-NMF בהקשר של בחירת תכונות כדי לחלץ קבוצה חדשה של תכונות בסיסיות הלוכדות את המבנה החשוב של הנתונים המקוריים. אתה יכול למזער את הממדיות של מערך הנתונים תוך שמירה על מגבלת אי השליליות על ידי בחירת תכונות הבסיס המובילות.
2.4 t-distributed Stochastic Neighbor Embedding (t-SNE)
t-SNE היא שיטת הפחתת מימד לא ליניארית המנסה לשמר את מבנה מערך הנתונים על ידי הפחתת ההבדל בין התפלגויות הסתברות זוגיות במיקומים במימד גבוה ונמוך.
ניתן ליישם t-SNE בבחירת תכונה כדי להקרין את חלל התכונה המקורי לתוך חלל בעל מימד נמוך יותר השומר על מבנה הנתונים, המאפשר הדמיה והערכה משופרים.
תוכל למצוא מידע נוסף על שני אלגוריתמים ללא פיקוח ועל t-SNE כאן "אלגוריתמי למידה ללא פיקוח".
2.5 מקודד אוטומטי
מקודד אוטומטי, מעין רשת עצבית מלאכותית, לומד לקודד נתוני קלט לייצוג ממד נמוך יותר ואז לפענח אותם בחזרה לגרסה המקורית. ניתן להשתמש בייצוג הממד הנמוך של המקודד האוטומטי כדי לייצר קבוצה נוספת של תכונות הלוכדות את המבנה הבסיסי של הנתונים המקוריים.
לסיכום, בחירת תכונות חיונית בלמידת מכונה. זה עוזר להפחית את הממדיות של הנתונים, למזער את הסיכון להתאמת יתר ולשפר את הביצועים הכוללים של הדגם. בחירת שיטת בחירת התכונה הנכונה תלויה בבעיה הספציפית, במערך הנתונים ובדרישות המידול.
מאמר זה כיסה מגוון רחב של טכניקות לבחירת תכונות, כולל שיטות מפוקחות ובלתי מפוקחות.
טכניקות מפוקחות, כגון גישות מבוססות פילטר, עטיפה וגישות מוטמעות, משתמשות בקשר בין תכונות למשתנה היעד כדי לזהות את התכונות החשובות ביותר.
טכניקות ללא פיקוח, כמו PCA, ICA, NMF, t-SNE ומקודדים אוטומטיים, מתמקדות במבנה הפנימי של הנתונים כדי להפחית את הממדיות מבלי להתחשב במשתנה היעד.
בעת בחירת שיטת בחירת התכונות המתאימה עבור המודל שלך, חיוני לקחת בחשבון את המאפיינים של הנתונים שלך, את ההנחות הבסיסיות של כל טכניקה, ואת המורכבות החישובית הכרוכה בכך.
על ידי בחירה קפדנית ויישום טכניקת בחירת התכונות הנכונה, תוכל לשפר משמעותית את הביצועים, ולהוביל לתובנות טובות יותר וקבלת החלטות.
נייט רוזידי הוא מדען נתונים ואסטרטגיית מוצר. הוא גם פרופסור עזר המלמד אנליטיקה, והוא המייסד של StrataScratch, פלטפורמה המסייעת למדעני נתונים להתכונן לראיונות שלהם עם שאלות ראיונות אמיתיות מחברות מובילות. התחבר אליו הלאה טוויטר: StrataScratch or לינקדין.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- EVM Finance. ממשק מאוחד למימון מבוזר. גישה כאן.
- Quantum Media Group. IR/PR מוגבר. גישה כאן.
- PlatoAiStream. Web3 Data Intelligence. הידע מוגבר. גישה כאן.
- מקור: https://www.kdnuggets.com/2023/06/advanced-feature-selection-techniques-machine-learning-models.html?utm_source=rss&utm_medium=rss&utm_campaign=advanced-feature-selection-techniques-for-machine-learning-models
- :יש ל
- :הוא
- :לֹא
- :איפה
- 1
- 10
- 11
- 12
- 13
- 15%
- 16
- 20
- 22
- 27
- 7
- 8
- 9
- 95%
- a
- יכולת
- אודות
- מֵעַל
- להאיץ
- קביל
- פי
- לפיכך
- חֶשְׁבּוֹן
- דיוק
- במדויק
- להשיג
- הושג
- משיגה
- להוסיף
- הוסיף
- נוסף
- מוסיף
- מתקדם
- משפיע
- גיל
- איידס
- המטרה
- אַלגוֹרִיתְם
- אלגוריתמים
- תעשיות
- מאפשר
- מאפשר
- לבד
- לאורך
- כְּבָר
- גם
- תמיד
- בין
- כמות
- an
- אנליזה
- ניתוח
- לנתח
- ניתוח
- ו
- אחר
- לענות
- בקשה
- יישומית
- החל
- מריחה
- גישה
- גישות
- מתאים
- ARE
- סביב
- מאמר
- מלאכותי
- AS
- אספקט
- לְהַעֲרִיך
- הערכה
- הנחות
- At
- תכונות
- זמין
- מְמוּצָע
- בחזרה
- עמוד שדרה
- איזון
- איזון
- בָּר
- מבוסס
- בסיסי
- בסיס
- BE
- כי
- להיות
- לפני
- להתחיל
- ההתחלה
- להלן
- הטוב ביותר
- מוטב
- בֵּין
- שחור
- דם
- לחץ דם
- Bmi
- גוּף
- סיכה
- שניהם
- BP
- סרטן השד
- לִבנוֹת
- בִּניָן
- אבל
- by
- לחשב
- מחושב
- מחשב
- CAN
- מחלת הסרטן
- ללכוד
- לוכדת
- בזהירות
- מקרה
- לגרום
- גורמים
- מרכז
- מסוים
- השתנה
- שינויים
- משתנה
- מאפיין
- מאפיינים
- מאופיין
- תרשים
- chatbots
- ChatGPT
- כימי
- כימיקלים
- בחירה
- בחרו
- בחירה
- נבחר
- בכיתה
- כיתות
- מיון
- לסווג
- CNN
- קוד
- קולורדו
- טור
- עמודות
- COM
- שילובים
- משלב
- בדרך כלל
- חברות
- לְהַשְׁווֹת
- השוואה
- תחרותי
- מורכבות
- רְכִיב
- רכיבים
- כוח חישובי
- לחשב
- מסקנה
- יחד
- לְחַבֵּר
- כתוצאה מכך
- לשקול
- נחשב
- בהתחשב
- רואה
- מורכב
- מכיל
- הקשר
- ממשיך
- רציף
- לתרום
- תרומה
- להמיר
- מתאם
- עלות
- יקר
- עלויות
- יכול
- לכסות
- מכוסה
- לִיצוֹר
- קריטי
- נוֹכְחִי
- יומי
- נתונים
- מדען נתונים
- מערכי נתונים
- להחליט
- מחליטים
- החלטה
- קבלת החלטות
- עץ החלטות
- החלטות
- להקטין
- ירידות
- מוגדר
- אספקה
- תובעני
- מדגים
- תלוי
- תלוי
- רצוי
- לקבוע
- קביעה
- סוכרת
- DID
- נבדלים
- הבדל
- אחר
- להבחין
- לגלות
- לדון
- דיון
- לְהַצִיג
- מציג
- הפצה
- הפצות
- מחולק
- do
- מסמך
- דומיננטי
- e
- כל אחד
- בקלות
- קל
- אדג '
- אפקטיבי
- יעיל
- או
- בוטל
- בוטלו
- מבטל
- מוטבע
- הטבעה
- מעסיקה
- להגביר את
- משופר
- לְהַבטִיחַ
- מבטיח
- שלם
- תקופה
- במיוחד
- Ether (ETH)
- להעריך
- הערכה
- הערכה
- בדיוק
- בוחן
- דוגמה
- דוגמאות
- לבצע
- להסביר
- מוסבר
- מסביר
- חיצוני
- תמצית
- תמציות
- פנים
- זיהוי פנים
- גורם
- גורמים
- מוכר
- מהר יותר
- מאפיין
- תכונות
- מָשׁוֹב
- נְקֵבָה
- תאנה
- תרשים
- לסנן
- אש
- ראשון
- מתאים
- לָצוּף
- להתמקד
- לעקוב
- הבא
- כדלקמן
- בעד
- יער
- צורות
- קדימה
- מייסד
- החל מ-
- פונקציה
- נוסף
- לְהַשִׂיג
- מין
- כללי
- נוצר
- לקבל
- לתת
- נתן
- מטרה
- שערים
- טוב
- בהדרגה
- גרף
- גדול
- יותר
- רֶשֶׁת
- לטפל
- לפגוע
- יש
- יש
- he
- גובה
- לעזור
- מועיל
- עזרה
- עוזר
- כאן
- גָבוֹהַ
- גבוה יותר
- הגבוה ביותר
- להבליט
- לו
- מאוזן
- איך
- איך
- אולם
- HTTPS
- עצום
- בן אנוש
- i
- ICS
- רעיון
- אידאל
- מזוהה
- לזהות
- הצתה
- מדגים
- פְּגִיעָה
- השפעות
- לייבא
- חשיבות
- חשוב
- היבט חשוב
- לשפר
- משופר
- השבחה
- שיפורים
- משפר
- שיפור
- in
- לכלול
- כלול
- כולל
- כולל
- להגדיל
- גדל
- עליות
- יותר ויותר
- עצמאי
- מדד
- להצביע
- המציין
- מדדים
- בנפרד
- להשפיע
- מידע
- הודעה
- בתחילה
- קלט
- תובנות
- במקום
- אינטגרלי
- אינטראקציה
- ראיון אישי
- שאלות בראיון
- ראיונות
- אל תוך
- מהותי
- מעורב
- סוגיה
- IT
- איטליה
- שֶׁלָה
- עבודה
- נשפט
- רק
- KDnuggets
- שמירה
- סוג
- לדעת
- ידוע
- l2
- תוויות
- גָדוֹל
- מוביל
- לִלמוֹד
- למידה
- הכי פחות
- עזבו
- פחות
- רמה
- מינוף
- ספריות
- סִפְרִיָה
- כמו
- הגבלה
- קו
- קשר
- לינקדין
- רשימה
- חי
- ll
- לִטעוֹן
- טוען
- מקומות
- נראה
- את
- להוריד
- הורדה
- מכונה
- למידת מכונה
- ראשי
- בעיקר
- שמירה
- שומר
- גדול
- הרוב
- לעשות
- עושה
- עשייה
- רב
- מסה
- matplotlib
- מַטרִיצָה
- מאי..
- משמעות
- למדוד
- מדידה
- מידות
- אמצעים
- שיטה
- שיטות
- מטרי
- יכול
- מזעור
- חסר
- מודל
- דוגמנות
- מודלים
- בינוני
- מודול
- יותר
- רוב
- המהלך
- הרבה
- הדדי
- שמות
- לאומי
- צורך
- רשת
- רשתות
- עצביים
- רשת עצבית
- רשתות עצביות
- חדש
- הבא
- לא
- מספר
- מספרים
- קהות
- אובייקט
- מטרה
- שנצפה
- of
- רשמי
- לעתים קרובות
- on
- ONE
- רק
- מול
- אופטימלי
- מייעל
- or
- להזמין
- מְקוֹרִי
- מקורו
- אחר
- שלנו
- הַחוּצָה
- ביצועים טובים יותר
- תפוקה
- יותר
- מקיף
- סקירה
- זוגות
- דובי פנדה
- פרמטרים
- חלק
- מסוים
- במיוחד
- אחוזים
- לבצע
- ביצועים
- ביצעתי
- שלב
- לבחור
- מבחר
- פלטפורמה
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- משחק
- נקודות
- פופולרי
- אפשרי
- פוטנציאל
- פוטנציאל
- כּוֹחַ
- מופעל
- תרגול
- לחזות
- ניבוי
- התחזיות
- להכין
- נוכחות
- לחץ
- למנוע
- יְסוֹדִי
- מנהל
- קופונים להדפסה
- הסתברות
- בעיה
- בעיות
- תהליך
- לייצר
- המוצר
- פרופסור
- התקדמות
- פּרוֹיֶקט
- פרויקט
- נכסים
- פרופורציה
- מספק
- מתן
- שאלה
- שאלות
- אקראי
- רכס
- טִוּוּחַ
- מדורג
- דירוג
- דרגות
- דירוגים
- יחס
- הגיע
- חומר עיוני
- ממשי
- תחום
- סיבות
- הכרה
- רקורסיבי
- להפחית
- מופחת
- הפחתה
- הפחתה
- באזור
- נסיגה
- למידה חיזוק
- קָשׁוּר
- קשר
- קרוב משפחה
- יחסית
- הרלוונטיות
- רלוונטי
- נותר
- הוסר
- הסרת
- חזר
- שוב ושוב
- לייצג
- נציגות
- המייצג
- מייצג
- לדרוש
- דרישות
- משאבים
- תוצאה
- תוצאות
- לִשְׁמוֹר
- שמירה
- שייר
- מגלה
- תקין
- הסיכון
- תפקיד
- s
- טוֹבָה
- אותו
- מאזניים
- מַדְעָן
- מדענים
- ציון
- ציונים
- שְׁנִיָה
- לִרְאוֹת
- לחפש
- נבחר
- בחירה
- מבחר
- נַסיוֹב
- סט
- סטים
- כמה
- מִין
- צריך
- לְהַצִיג
- הצגה
- הופעות
- לאותת
- משמעות
- משמעותי
- באופן משמעותי
- פשטות
- since
- שישה
- מדרון
- So
- מֶרחָב
- ספציפי
- מפורט
- נאום
- זיהוי דיבור
- לפצל
- מרובע
- כוכב
- התחלה
- התחלות
- סטטיסטי
- סטטיסטי
- סטטיסטיקה
- שלב
- צעדים
- עוד
- חנויות
- פשוט
- אסטרטגיות
- אִסטרָטֶגִיָה
- חזק יותר
- מִבְנֶה
- לאחר מכן
- ניכר
- כזה
- מציע
- מַתְאִים
- סיכום
- מעולה
- למידה מפוקחת
- נתמך
- נטילת
- לדבר
- יעד
- המשימות
- משימות
- הוראה
- טכניקות
- טכנולוגיות
- טווח
- מונחים
- מבחן
- בדיקות
- מֵאֲשֶׁר
- זֶה
- השמיים
- המידע
- שֶׁלָהֶם
- אותם
- אז
- שם.
- בכך
- אלה
- הֵם
- זֶה
- שְׁלוֹשָׁה
- סף
- בכל
- פִּי
- ל
- היום
- גַם
- חלק עליון
- 10 למעלה
- נושא
- נושאים
- סה"כ
- לקראת
- רכבת
- מְאוּמָן
- הדרכה
- עץ
- עצים
- שתיים
- סוג
- סוגים
- טיפוסי
- בדרך כלל
- בסופו של דבר
- אי ודאות
- בְּסִיסִי
- להבין
- עד
- להשתמש
- מְשׁוּמָשׁ
- שימושים
- באמצעות
- בְּדֶרֶך כְּלַל
- בעל ערך
- ערך
- ערכים
- מגוון
- שונים
- גרסה
- ראיה
- חיוני
- רוצה
- we
- מִשׁקָל
- טוֹב
- מה
- מתי
- אשר
- בזמן
- כל
- רָחָב
- טווח רחב
- באופן נרחב
- יצטרך
- יַיִן
- ויסקונסין
- עם
- בתוך
- לְלֹא
- תיק עבודות
- עובד
- עובד
- X
- שנים
- עוד
- תְשׁוּאָה
- אתה
- עצמך
- זפירנט
- אפס




