In 2021 ed 2020, vi abbiamo parlato delle nuove funzionalità in Amazon RedShift che rendono più facile, veloce e conveniente analizzare tutti i tuoi dati e trovare approfondimenti ricchi e potenti. Nel 2022, siamo lieti di annunciare che il team di Amazon Redshift ha lavorato sodo. Abbiamo lavorato a ritroso rispetto ai requisiti dei clienti e annunciato numerose nuove funzionalità per rendere più semplice, veloce ed economica l'analisi di tutti i dati. Questo post copre alcune di queste nuove funzionalità.
In AWS, per dati e analisi, la nostra strategia è darti un moderna architettura dei dati che ti aiuta a liberarti dai silos di dati; disporre di dati, analisi, machine learning (ML) e servizi di intelligenza artificiale appositamente progettati per utilizzare lo strumento giusto per il lavoro giusto; e disporre di servizi aperti, governati, sicuri e completamente gestiti per rendere l'analisi disponibile a tutti. All'interno della moderna architettura dei dati di AWS, Amazon Redshift come data warehouse nel cloud rimane un componente chiave, consentendoti di eseguire complesse analisi SQL su larga scala e prestazioni su terabyte o petabyte di dati strutturati e non strutturati e rendere le informazioni ampiamente disponibili attraverso la business intelligence ( BI) e strumenti di analisi. Continuiamo a lavorare a ritroso rispetto ai requisiti dei clienti e nel 2022 abbiamo lanciato oltre 40 funzionalità in Amazon Redshift per aiutare i clienti con i loro principali casi d'uso di data warehousing, tra cui:
- Analisi self-service
- Facile ingestione di dati
- Condivisione dei dati e collaborazione
- Scienza dei dati e apprendimento automatico
- Analisi sicure e affidabili
- Migliore analisi delle prestazioni dei prezzi
Approfondiamo e discutiamo delle nuove funzionalità di Amazon Redshift in queste aree.
Analisi self-service
I clienti continuano a dirci che i dati e l'analisi stanno diventando onnipresenti e tutti nella loro organizzazione hanno bisogno di analisi. Abbiamo annunciato Amazon Redshift senza server (in anteprima) nel 2021 per semplificare l'esecuzione e la scalabilità dell'analisi in pochi secondi senza dover eseguire il provisioning e gestire l'infrastruttura del data warehouse. Nel luglio 2022, abbiamo annunciato il disponibilità generale di Redshift Serverless, e da allora migliaia di clienti, tra cui Peloton, Broadridge Financials e NextGen Healthcare, lo hanno utilizzato per analizzare i propri dati in modo rapido e semplice. Amazon Redshift Serverless esegue automaticamente il provisioning e ridimensiona in modo intelligente la capacità del data warehouse per offrire prestazioni elevate per tutte le tue analisi e paghi solo per il calcolo utilizzato per la durata dei carichi di lavoro su base al secondo. Da GA, abbiamo aggiunto funzionalità come etichettatura delle risorse, monitoraggio semplificato e disponibilità in altre regioni AWS per semplificare ulteriormente la fatturazione ed espandere la copertura in più regioni in tutto il mondo.
Nel 2021, abbiamo lanciato Amazon Redshift Query Editor V2, uno strumento gratuito basato sul Web per analisti di dati, data scientist e sviluppatori per esplorare, analizzare e collaborare sui dati nei data warehouse e nei data lake di Amazon Redshift. Nel 2022, l'editor di query V2 ha ottenuto ulteriori miglioramenti come supporto per notebook per una migliore collaborazione per creare, organizzare e annotare le query; accesso utente tramite credenziali del provider di identità (IdP). per l'accesso singolo; e la possibilità di eseguire più query contemporaneamente per migliorare la produttività degli sviluppatori.
L'autonomia è un'altra area in cui stiamo lavorando attivamente per utilizzare le ottimizzazioni basate su ML e offrire ai clienti un data warehouse di autoapprendimento e auto-ottimizzazione. Nel 2022, abbiamo annunciato la disponibilità generale di Viste materializzate automatizzate (AutoMVs) per migliorare le prestazioni delle query (ridurre il runtime totale) senza alcuno sforzo da parte dell'utente, creando e mantenendo automaticamente viste materializzate. Gli AutoMV, combinati con l'aggiornamento automatico, l'aggiornamento incrementale e la riscrittura automatica delle query per le viste materializzate, hanno reso le viste materializzate esenti da manutenzione, offrendo automaticamente prestazioni più veloci. Inoltre, il ottimizzazione automatica della tabella (ATO) per l'ottimizzazione dello schema e gestione automatica del carico di lavoro (auto WLM) per l'ottimizzazione del carico di lavoro ha ottenuto ulteriori miglioramenti per migliorare le prestazioni delle query.
Facile ingestione di dati
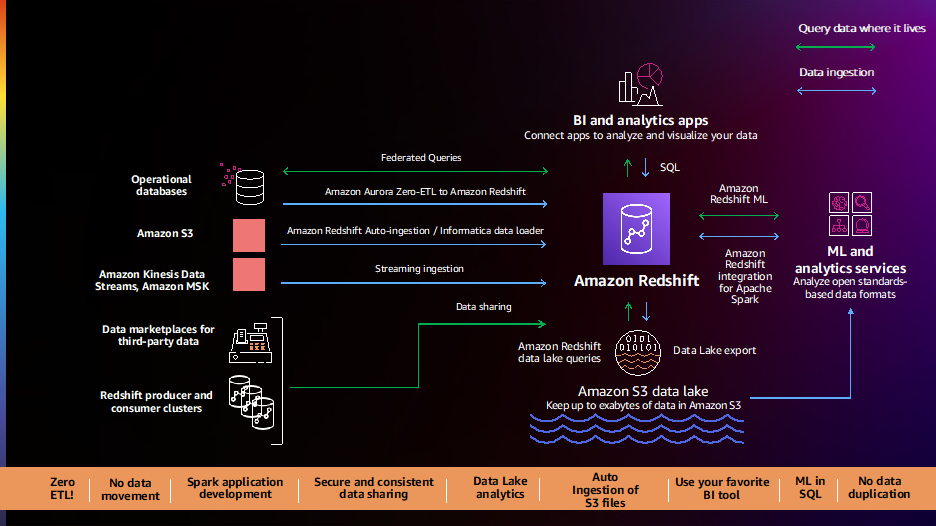
I clienti ci dicono che i loro dati sono distribuiti su più fonti di dati come database transazionali, data warehouse, data lake e sistemi di big data. Vogliono la flessibilità per integrare questi dati con pipeline di dati senza codice/basso codice, zero ETL o analizzare questi dati sul posto senza spostarli. I clienti ci dicono che le loro attuali pipeline di dati sono complesse, manuali, rigide e lente, con conseguenti visualizzazioni incomplete, incoerenti e non aggiornate dei dati, che limitano gli insight. I clienti ci hanno chiesto una soluzione migliore e siamo lieti di annunciare una serie di nuove funzionalità per semplificare e automatizzare le pipeline di dati.
Integrazione zero-ETL di Amazon Aurora con Amazon Redshift (anteprima) ti consente di eseguire analisi e ML quasi in tempo reale su petabyte di dati transazionali. Offre una soluzione senza codice per creare dati transazionali da più Amazon Aurora database disponibili nei data warehouse di Amazon Redshift entro pochi secondi dalla scrittura su Aurora, eliminando la necessità di creare e mantenere complesse pipeline di dati. Con questa funzionalità, i clienti Aurora possono anche accedere alle funzionalità di Amazon Redshift come analisi SQL complesse, ML integrato, condivisione dei dati e accesso federato a più datastore e data lake. Questa funzione è ora disponibile in anteprima per Edizione compatibile con Amazon Aurora MySQL versione 3 (con compatibilità MySQL 8.0) e puoi farlo richiedere l'accesso all'anteprima.
Amazon Redshift ora supporta copia automatica da Amazon S3 (anteprima) per semplificare il caricamento dei dati da Servizio di archiviazione semplice Amazon (Amazon S3) in Amazon Redshift. Ora puoi impostare regole di importazione continua dei file (processi di copia) per tenere traccia dei tuoi percorsi Amazon S3 e caricare automaticamente nuovi file senza la necessità di strumenti aggiuntivi o soluzioni personalizzate. I processi di copia possono essere monitorati tramite le tabelle di sistema e tengono automaticamente traccia dei file caricati in precedenza e li escludono dal processo di importazione per impedire la duplicazione dei dati. Questa funzione è ora disponibile in anteprima; puoi provare questa funzione creando un nuovo cluster utilizzando la traccia di anteprima.
I clienti continuano a dirci che hanno bisogno di analisi istantanee, immediate e in tempo reale e siamo lieti di annunciare il disponibilità generale del supporto per l'importazione di streaming in Amazon Redshift per Flussi di dati di Amazon Kinesis ed Streaming gestito da Amazon per Apache Kafka (Amazon MSK). Questa funzionalità elimina la necessità di mettere in scena i dati in streaming in Amazon S3 prima di inserirli in Amazon Redshift, consentendoti di ottenere una bassa latenza, misurata in secondi, durante l'acquisizione di centinaia di megabyte di dati in streaming al secondo nei tuoi data warehouse. Puoi utilizzare SQL all'interno di Amazon Redshift per connetterti e importare direttamente i dati da più flussi di dati Kinesis o argomenti MSK, creare viste materializzate in streaming con aggiornamento automatico con trasformazioni in cima ai flussi direttamente per accedere ai dati in streaming e combinare dati in tempo reale con dati storici dati per una migliore comprensione. Ad esempio, Adobe ha integrato l'importazione di streaming di Amazon Redshift come parte della propria Adobe Experience Platform per l'acquisizione e l'analisi, in tempo reale, del flusso di clic Web e delle applicazioni e dei dati di sessione per varie applicazioni come CRM e applicazioni di assistenza clienti.
I clienti ci hanno detto che desiderano un'integrazione semplice e pronta all'uso tra Amazon Redshift, strumenti BI ed ETL (estrazione, trasformazione e caricamento) e applicazioni aziendali come Salesforce e Marketo. Siamo lieti di annunciare la disponibilità generale di Informatica Data Loader per Amazon Redshift, che consente di utilizzare gratuitamente Informatica Data Loader per il caricamento di dati ad alta velocità e volumi elevati in Amazon Redshift. Puoi semplicemente selezionare l'opzione Informatica Data Loader sulla console Amazon Redshift. Una volta in Informatica Data Loader, puoi connetterti a origini come Salesforce o Marketo, scegliere Amazon Redshift come destinazione e iniziare a caricare i tuoi dati.
Condivisione dei dati e collaborazione
I clienti continuano a dirci che desiderano analizzare tutti i loro dati proprietari e di terze parti e mettere a disposizione di clienti, partner e fornitori le ricche informazioni dettagliate basate sui dati. Abbiamo lanciato nuove funzionalità nel 2021, come ad esempio Condivisione dei dati ed Integrazione dello scambio di dati AWS, per semplificare l'analisi di tutti i dati e condividerli all'interno e all'esterno delle organizzazioni.
Un ottimo esempio di cliente che utilizza la condivisione dei dati è Orion. Orion fornisce soluzioni Data as a Service (DaaS) in tempo reale per i clienti del settore dei servizi finanziari, come fornitori di gestione patrimoniale, gestione patrimoniale e gestione degli investimenti. Hanno oltre 2,500 origini dati che sono principalmente database SQL Server che si trovano sia in locale che in AWS. I dati vengono trasmessi in streaming utilizzando i connettori Kafka in Amazon Redshift. Hanno un cluster di produttori che riceve tutti questi dati e quindi utilizza la condivisione dei dati per condividere i dati in tempo reale per la collaborazione. Questa è un'architettura multi-tenant che serve più client. Data la sensibilità dei loro dati, la condivisione dei dati è un modo per fornire l'isolamento del carico di lavoro tra i cluster e condividere in modo sicuro tali dati con gli utenti finali.
Nel 2022, abbiamo continuato a investire in quest'area per migliorare le prestazioni, la governance e la produttività degli sviluppatori con nuove funzionalità per rendere più facile, semplice e veloce la condivisione e la collaborazione sui dati.
Poiché i clienti stanno creando configurazioni di condivisione dei dati su larga scala, hanno chiesto governance e sicurezza semplificate per i dati condivisi e stiamo aggiungendo controllo degli accessi centralizzato con AWS Lake Formation per le condivisioni di dati di Amazon Redshift per consentire la condivisione di dati in tempo reale tra più data warehouse di Amazon Redshift. Con questa funzionalità, Amazon Redshift ora supporta la governance semplificata delle condivisioni di dati di Amazon Redshift utilizzando Formazione AWS Lake come un unico pannello di vetro per gestire centralmente i dati o le autorizzazioni sulle condivisioni di dati. Puoi visualizzare, modificare e controllare le autorizzazioni, inclusa la sicurezza a livello di riga e di colonna sulle tabelle e le viste nelle condivisioni di dati di Amazon Redshift, utilizzando le API di Lake Formation e il Console di gestione AWSe consentire la scoperta e l'utilizzo delle condivisioni di dati di Amazon Redshift da parte di altri data warehouse di Amazon Redshift.
Scienza dei dati e apprendimento automatico
I clienti continuano a dirci che desiderano che i loro sistemi di dati e analisi li aiutino a rispondere a un'ampia gamma di domande, da ciò che sta accadendo nella loro azienda (analisi descrittiva) al perché sta accadendo (analisi diagnostica) e cosa accadrà in futuro (analisi predittiva). Amazon Redshift offre funzionalità come analisi SQL complesse, analisi di data lake e Amazon RedshiftML per consentire ai clienti di analizzare i propri dati e scoprire potenti intuizioni. Spostamento verso il rosso ML integra Amazon Redshift con Amazon Sage Maker, un servizio ML completamente gestito, che ti consente di creare, addestrare e distribuire modelli ML utilizzando comandi SQL familiari.
I clienti ci hanno anche chiesto una migliore integrazione tra Amazon Redshift e Apache Spark, quindi siamo lieti di annunciarlo Integrazione di Amazon Redshift per Apache Spark per rendere i data warehouse facilmente accessibili per le applicazioni basate su Spark. Ora, gli sviluppatori che utilizzano analisi AWS e servizi ML come Amazon EMR, Colla AWSe SageMaker può facilmente creare applicazioni Apache Spark che leggono e scrivono nei data warehouse di Amazon Redshift. Amazon EMR e AWS Glue impacchettano il connettore Redshift-Spark in modo che tu possa connetterti facilmente al tuo data warehouse dalle tue applicazioni basate su Spark. Puoi utilizzare diverse funzionalità pushdown per operazioni come funzioni di ordinamento, aggregazione, limitazione, join e scalari in modo che solo i dati rilevanti vengano spostati dal tuo data warehouse di Amazon Redshift all'applicazione Spark di consumo. Puoi anche rendere le tue applicazioni più sicure utilizzando Gestione dell'identità e dell'accesso di AWS (IAM) per connettersi ad Amazon Redshift.
Analisi sicure e affidabili
I clienti continuano a dirci che i loro data warehouse sono sistemi mission-critical che richiedono elevata disponibilità, affidabilità e sicurezza. Abbiamo lanciato una serie di nuove funzionalità nel 2022 in quest'area.
Amazon Redshift ora supporta Implementazioni Multi-AZ (in anteprima) per i cluster basati su istanze RA3, che consente l'esecuzione simultanea del data warehouse in più zone di disponibilità AWS e il funzionamento continuo in scenari di errore imprevisti a livello di zona di disponibilità. Il supporto Multi-AZ è già disponibile per Redshift Serverless. Un'implementazione Multi-AZ di Amazon Redshift ti consente di eseguire il ripristino in caso di errori nella zona di disponibilità senza alcun intervento da parte dell'utente. Un data warehouse Amazon Redshift Multi-AZ è accessibile come un singolo data warehouse con un endpoint e ti aiuta a massimizzare le prestazioni distribuendo automaticamente l'elaborazione del carico di lavoro su più zone di disponibilità. Non sono necessarie modifiche alle applicazioni per mantenere la continuità aziendale durante interruzioni impreviste.
Nel 2022, abbiamo lanciato funzionalità come il controllo degli accessi basato sui ruoli, la sicurezza a livello di riga e il mascheramento dei dati (in anteprima) per semplificare la gestione degli accessi e decidere chi ha accesso a quali dati, inclusa l'offuscamento delle informazioni di identificazione personale (PII ) come numeri di carte di credito.
Puoi usare controllo degli accessi basato sui ruoli (RBAC) per controllare l'accesso dell'utente finale ai dati a livello generale o granulare in base al ruolo lavorativo e alle autorizzazioni dell'utente finale. Con RBAC, puoi creare un ruolo utilizzando SQL, concedere una raccolta di autorizzazioni granulari al ruolo e quindi assegnare quel ruolo agli utenti finali. Ai ruoli possono essere concesse autorizzazioni a livello di oggetto, di colonna e di sistema. Inoltre, RBAC introduce ruoli di sistema predefiniti per DBA, operatori, amministratori della sicurezza o ruoli personalizzati.
Sicurezza a livello di riga (RLS) semplifica la progettazione e l'implementazione dell'accesso granulare alle righe nelle tabelle. Con la sicurezza a livello di riga, puoi limitare l'accesso a un sottoinsieme di righe all'interno di una tabella in base al ruolo professionale degli utenti o alle autorizzazioni con SQL.
Supporto di Amazon Redshift per mascheramento dinamico dei dati (DDM), che ora è disponibile in anteprima, ti consente di semplificare la protezione delle PII come numeri di previdenza sociale, numeri di carte di credito e numeri di telefono nel data warehouse di Amazon Redshift. Con il data masking dinamico, puoi controllare l'accesso ai tuoi dati tramite semplici policy di mascheramento basate su SQL che determinano il modo in cui Amazon Redshift restituisce i dati sensibili all'utente al momento della query. È possibile creare criteri di mascheramento per definire valori di dati mascherati coerenti, con conservazione del formato e irreversibili. È possibile applicare un criterio di mascheramento a una colonna specifica oa un elenco di colonne in una tabella. Inoltre, hai la flessibilità di scegliere come mostrare i dati mascherati. Ad esempio, puoi nascondere completamente i dati, sostituire valori reali parziali con caratteri jolly o definire il tuo modo di mascherare i dati utilizzando espressioni SQL, Python o AWS Lambda funzioni definite dall'utente. Inoltre, puoi applicare un criterio di mascheramento condizionale basato su altre colonne, che protegge in modo selettivo i dati della colonna in una tabella in base ai valori in una o più colonne diverse.
Abbiamo anche annunciato miglioramenti a registrazione di controllo, integrazione nativa con Active Directory di Microsoft Azuree supporto per ruoli IAM predefiniti in ulteriori Regioni per semplificare ulteriormente la gestione della sicurezza.
Migliore analisi delle prestazioni dei prezzi
I clienti continuano a dirci che hanno bisogno di data warehouse veloci ed economici che offrano prestazioni elevate su qualsiasi scala mantenendo bassi i costi. Dal giorno 1 da allora Il lancio di Amazon Redshift nel 2012, abbiamo adottato un approccio basato sui dati e utilizzato la telemetria della flotta per creare un servizio di data warehouse nel cloud che ti offra il miglior rapporto qualità-prezzo su qualsiasi scala. Negli anni ci siamo evoluti L'architettura di Amazon Redshift e funzionalità lanciate come Archiviazione gestita Redshift (RMS) per la separazione di storage e calcolo, Spettro Amazon Redshift per le query sul data lake, ottimizzazione automatica della tabella per l'ottimizzazione dello schema fisico, gestione automatica del carico di lavoro per dare la priorità ai carichi di lavoro e allocare il calcolo e la memoria corretti, ridimensionamento del cluster per ridimensionare il calcolo e l'archiviazione verticalmente e ridimensionamento della concorrenza per ridimensionare dinamicamente il calcolo in entrata o in uscita. Our benchmark delle prestazioni continuare a dimostrare la leadership in termini di prestazioni di prezzo di Amazon Redshift.
Nel 2022 abbiamo aggiunto nuove funzionalità come la disponibilità generale di ridimensionamento della concorrenza per le operazioni di scrittura come COPY, INSERT, UPDATE e DELETE per supportare utenti e query simultanei virtualmente illimitati. Abbiamo inoltre introdotto miglioramenti delle prestazioni per l'elaborazione dei dati basata su stringhe tramite scansioni vettoriali su colonne di stringhe leggere, efficienti per la CPU e codificate da dizionario, che consentono al motore di database di operare direttamente sui dati compressi.
Abbiamo anche aggiunto il supporto per operatori SQL come MERGE (unico operatore per inserti o aggiornamenti); CONNECY_BY (per query gerarchiche); SET DI RAGGRUPPAMENTO, ROLLUP e CUBE (per la reportistica multidimensionale); e aumentato la dimensione del tipo di dati SUPER a 16 MB per semplificare la migrazione dai data warehouse legacy ad Amazon Redshift.
Conclusione
I nostri clienti continuano a dirci che i dati e l'analisi rimangono una priorità assoluta per loro e la necessità di estrarre in modo conveniente più valore aziendale dai loro dati in questi periodi è più pronunciata che in qualsiasi altro momento del passato. Amazon Redshift come data warehouse nel cloud ti consente di eseguire analisi SQL complesse con scalabilità e prestazioni da terabyte a petabyte di dati strutturati e non strutturati e rendere le informazioni ampiamente disponibili attraverso i più diffusi strumenti di analisi e BI.
Sebbene abbiamo lanciato oltre 40 funzionalità nel 2022 e il ritmo dell'innovazione continua ad accelerare, rimane il giorno 1 e non vediamo l'ora di sentire da te come queste funzionalità ti aiutano a sbloccare più valore per le tue organizzazioni. Ti invitiamo a provare queste nuove funzionalità e a metterti in contatto con noi tramite il team del tuo account AWS se hai ulteriori commenti.
Circa l'autore
 Manan Goel è un prodotto Go-To-Market Leader per i servizi di analisi AWS, incluso Amazon Redshift in AWS. Ha più di 25 anni di esperienza ed è esperto di database, data warehousing, business intelligence e analisi. Manan ha conseguito un MBA presso la Duke University e una laurea in ingegneria elettronica e delle comunicazioni.
Manan Goel è un prodotto Go-To-Market Leader per i servizi di analisi AWS, incluso Amazon Redshift in AWS. Ha più di 25 anni di esperienza ed è esperto di database, data warehousing, business intelligence e analisi. Manan ha conseguito un MBA presso la Duke University e una laurea in ingegneria elettronica e delle comunicazioni.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/whats-new-in-amazon-redshift-2022-a-year-in-review/
- 1
- 100
- 2021
- 2022
- a
- capacità
- WRI
- accelerare
- accesso
- Accesso ai dati
- accessibile
- accessibile
- Il mio account
- Raggiungere
- operanti in
- attivo
- attivamente
- aggiunto
- aggiunta
- aggiuntivo
- Inoltre
- Adobe
- Tutti
- consente
- già
- Amazon
- Amazon EMR
- Gli analisti
- analitica
- analizzare
- l'analisi
- ed
- Annunciare
- ha annunciato
- Un altro
- rispondere
- Apache
- Apache Spark
- API
- Applicazioni
- applicazioni
- APPLICA
- approccio
- architettura
- RISERVATA
- aree
- artificiale
- intelligenza artificiale
- attività
- gestione delle risorse
- revisione
- Aurora
- autore
- auto
- automatizzare
- Automatico
- automaticamente
- disponibilità
- disponibile
- AWS
- Colla AWS
- azzurro
- basato
- base
- diventando
- prima
- essendo
- MIGLIORE
- Meglio
- fra
- Big
- Big Data
- fatturazione
- Rompere
- ampio
- Broadridge
- costruire
- Costruzione
- incassato
- affari
- Applicazioni aziendali
- business continuity
- business intelligence
- funzionalità
- Ultra-Grande
- carta
- Custodie
- casi
- Modifiche
- caratteri
- Scegli
- la scelta
- clienti
- Cloud
- Cluster
- collaboreranno
- collaborazione
- collezione
- Colonna
- colonne
- combinare
- combinato
- Commenti
- Comunicazioni
- compatibilità
- completamente
- complesso
- componente
- Calcolare
- concorrente
- Connettiti
- coerente
- consolle
- consumato
- continua
- continua
- continua
- continuo
- di controllo
- costo effettivo
- Costi
- copre
- creare
- Creazione
- Credenziali
- credito
- carta di credito
- Crediti
- CRM
- Corrente
- costume
- cliente
- Assistenza clienti
- Clienti
- personalizzate
- dati
- Scambio di dati
- Lago di dati
- elaborazione dati
- condivisione dei dati
- data warehouse
- data warehouse
- data-driven
- Banca Dati
- banche dati
- giorno
- più profondo
- consegnare
- dimostrare
- schierare
- deployment
- Design
- Determinare
- Costruttori
- sviluppatori
- diverso
- direttamente
- scopri
- scoperto
- discutere
- distribuito
- distribuzione
- Duca
- Università del Duca
- durante
- dinamico
- più facile
- facilmente
- editore
- sforzo
- Elettronica
- elimina
- eliminando
- enable
- Abilita
- consentendo
- endpoint
- motore
- Ingegneria
- Etere (ETH)
- tutti
- si è evoluta
- esempio
- exchange
- eccitato
- Espandere
- esperienza
- esplora
- espressioni
- estratto
- Fallimento
- familiare
- FAST
- più veloce
- caratteristica
- Caratteristiche
- Compila il
- File
- finanziario
- servizi finanziari
- dati finanziari
- Trovate
- FLOTTA
- Flessibilità
- formazione
- Avanti
- Gratis
- da
- completamente
- funzioni
- ulteriormente
- futuro
- Generale
- ottenere
- gif
- Dare
- dato
- dà
- Dare
- vetro.
- Andare al mercato
- la governance
- concedere
- concesso
- grande
- accadere
- contento
- Hard
- avendo
- assistenza sanitaria
- udito
- Aiuto
- aiuta
- nascondere
- Alta
- storico
- detiene
- Come
- Tutorial
- HTML
- HTTPS
- centinaia
- IAM
- Identità
- implementazione
- competenze
- migliorata
- miglioramenti
- in
- Compreso
- è aumentato
- industria
- informazioni
- Infrastruttura
- Innovazione
- Inserti
- intuizioni
- integrare
- integrato
- Integra
- integrazione
- Intelligence
- intervento
- introdotto
- Introduce
- Investire
- investimento
- invitare
- da solo
- IT
- Lavoro
- Offerte di lavoro
- join
- Luglio
- kafka
- mantenere
- conservazione
- Le
- Flussi di dati Kinesis
- lago
- larga scala
- Latenza
- lanciare
- lanciato
- leader
- Leadership
- apprendimento
- Eredità
- Livello
- leggero
- LIMITE
- Lista
- vivere
- dati in tempo reale
- caricare
- caricatore
- Caricamento in corso
- Guarda
- Basso
- macchina
- machine learning
- fatto
- mantenere
- manutenzione
- make
- Fare
- gestire
- gestito
- gestione
- Manuale
- Marketo
- mask
- Massimizzare
- Memorie
- migrare
- ML
- modelli
- moderno
- modificare
- monitorati
- monitoraggio
- Scopri di più
- in movimento
- multiplo
- MySQL
- nativo
- Bisogno
- di applicazione
- esigenze
- New
- Nuove funzionalità
- numero
- numeri
- Offerte
- ONE
- aprire
- operare
- operazione
- Operazioni
- operatore
- Operatori
- ottimizzazione
- Opzione
- organizzazione
- organizzazioni
- Altro
- interruzioni
- al di fuori
- proprio
- Pace
- pacchetto
- vetro
- parte
- partner
- passato
- Paga le
- peloton
- performance
- permessi
- Personalmente
- telefono
- Fisico
- pii
- posto
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- contento
- Termini e Condizioni
- politica
- Popolare
- Post
- potente
- Predictive Analytics
- prevenire
- Anteprima
- in precedenza
- prezzo
- principalmente
- Dare priorità
- priorità
- processi
- lavorazione
- produttore
- Prodotto
- della produttività
- proteggere
- fornire
- fornitore
- fornitori
- fornisce
- fornitura
- Python
- Domande
- rapidamente
- gamma
- raggiungere
- Leggi
- di rose
- tempo reale
- dati in tempo reale
- riceve
- Recuperare
- ridurre
- regioni
- pertinente
- problemi di
- affidabile
- resti
- sostituire
- rapporto
- Reportistica
- Requisiti
- limitare
- risultante
- problemi
- recensioni
- riscrittura
- Ricco
- rigido
- Ruolo
- ruoli
- rollup
- norme
- Correre
- running
- sagemaker
- forza di vendita
- Scala
- bilancia
- scala
- Scenari
- Scienze
- scienziati
- Secondo
- secondo
- sicuro
- in modo sicuro
- problemi di
- delicata
- Sensibilità
- serverless
- serve
- servizio
- Servizi
- Sessione
- set
- Set
- alcuni
- Condividi
- condiviso
- compartecipazione
- mostrare attraverso le sue creazioni
- Un'espansione
- semplificata
- semplificare
- semplicemente
- contemporaneamente
- da
- singolo
- Seduta
- Taglia
- rallentare
- So
- Social
- soluzione
- Soluzioni
- alcuni
- fonti
- Scintilla
- specifico
- SQL
- Stage
- conservazione
- negozi
- Strategia
- streaming
- Streaming
- flussi
- strutturato
- dati strutturati e non strutturati
- tale
- Super
- fornitori
- supporto
- supporti
- sistema
- SISTEMI DI TRATTAMENTO
- tavolo
- Target
- team
- Il
- Il futuro
- loro
- di parti terze standard
- migliaia
- Attraverso
- tempo
- volte
- a
- strumenti
- top
- Argomenti
- Totale
- toccare
- pista
- Treni
- transazionale
- Trasformare
- trasformazioni
- onnipresente
- imprevisto
- Università
- illimitato
- sbloccare
- Aggiornanento
- Aggiornamenti
- us
- uso
- Utente
- utenti
- Utilizzando
- APPREZZIAMO
- Valori
- vario
- versione
- Visualizza
- visualizzazioni
- potenzialmente
- Magazzino
- Magazzinaggio
- Ricchezza
- gestione patrimoniale
- sito web
- Web-basata
- Che
- Che cosa è l'
- quale
- while
- OMS
- largo
- Vasta gamma
- ampiamente
- volere
- entro
- senza
- Lavora
- lavorato
- lavoro
- In tutto il mondo
- scrivere
- scritto
- anno
- anni
- Trasferimento da aeroporto a Sharm
- zefiro
- zone