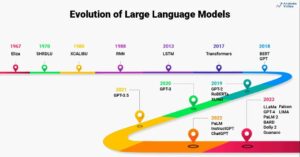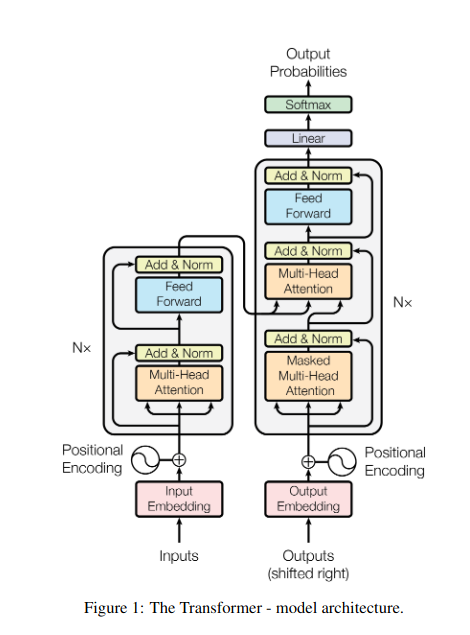
Introduzione
Immagina di trovarti in una biblioteca poco illuminata e di dover lottare per decifrare un documento complesso mentre ti destreggi tra dozzine di altri testi. Questo era il mondo di Transformers prima che il documento "L'attenzione è tutto ciò di cui hai bisogno" svelasse i suoi riflettori rivoluzionari: il meccanismo di attenzione.
Sommario
Limitazioni degli RNN
Modelli sequenziali tradizionali, come Reti neurali ricorrenti (RNN), ha elaborato il linguaggio parola per parola, portando a diverse limitazioni:
- Dipendenza a corto raggio: Gli RNN hanno faticato a cogliere le connessioni tra parole distanti, spesso interpretando erroneamente il significato di frasi come "l'uomo che ha visitato lo zoo ieri", dove soggetto e verbo sono distanti.
- Parallelismo limitato: L'elaborazione delle informazioni in sequenza è intrinsecamente lenta, impedendo un addestramento e un utilizzo efficienti delle risorse computazionali, soprattutto per sequenze lunghe.
- Focus sul contesto locale: Le RNN considerano principalmente i vicini immediati, potenzialmente perdendo informazioni cruciali da altre parti della frase.
Queste limitazioni hanno ostacolato la capacità dei Transformers di eseguire compiti complessi come la traduzione automatica e la comprensione del linguaggio naturale. Poi è arrivato il meccanismo di attenzione, un riflettore rivoluzionario che illumina le connessioni nascoste tra le parole, trasformando la nostra comprensione dell'elaborazione del linguaggio. Ma cosa ha risolto esattamente l’attenzione e come ha cambiato il gioco per Transformers?
Concentriamoci su tre aree chiave:
Dipendenza a lungo raggio
- Problema: I modelli tradizionali spesso si imbattono in frasi come “la donna che viveva sulla collina ieri sera ha visto una stella cadente”. Hanno faticato a collegare “donna” e “stella cadente” a causa della loro distanza, portando a interpretazioni errate.
- Meccanismo di attenzione: Immagina che il modello faccia brillare un raggio luminoso attraverso la frase, collegando "donna" direttamente a "stella cadente" e comprendendo la frase nel suo insieme. Questa capacità di catturare le relazioni indipendentemente dalla distanza è fondamentale per attività come la traduzione automatica e il riepilogo.
Leggi anche: Una panoramica sulla memoria a lungo termine (LSTM)
Potenza di elaborazione parallela
- Problema: I modelli tradizionali elaboravano le informazioni in sequenza, come leggere un libro pagina per pagina. Questo era lento e inefficiente, soprattutto per i testi lunghi.
- Meccanismo di attenzione: Immagina più riflettori che scansionano la biblioteca contemporaneamente, analizzando diverse parti del testo in parallelo. Ciò accelera notevolmente il lavoro del modello, consentendogli di gestire grandi quantità di dati in modo efficiente. Questa potenza di elaborazione parallela è essenziale per addestrare modelli complessi ed effettuare previsioni in tempo reale.
Consapevolezza del contesto globale
- Problema: I modelli tradizionali spesso si concentravano su singole parole, trascurando il contesto più ampio della frase. Ciò ha portato a malintesi in casi come sarcasmo o doppi significati.
- Meccanismo di attenzione: Immagina che i riflettori spensero l'intera biblioteca, accogliendo ogni libro e comprendendo come si relazionano tra loro. Questa consapevolezza del contesto globale consente al modello di considerare l'intero testo durante l'interpretazione di ciascuna parola, portando a una comprensione più ricca e sfumata.
Parole polisemiche disambiguanti
- Problema: Parole come “banca” o “mela” possono essere sostantivi, verbi o persino aziende, creando ambiguità che i modelli tradizionali hanno faticato a risolvere.
- Meccanismo di attenzione: Immagina che il modello punti i riflettori su tutte le occorrenze della parola "banca" in una frase, quindi analizzi il contesto circostante e le relazioni con altre parole. Considerando la struttura grammaticale, i nomi vicini e persino le frasi passate, il meccanismo dell'attenzione può dedurre il significato previsto. Questa capacità di chiarire le ambiguità delle parole polisemiche è cruciale per attività come la traduzione automatica, il riepilogo del testo e i sistemi di dialogo.
Questi quattro aspetti – dipendenza a lungo raggio, potenza di elaborazione parallela, consapevolezza del contesto globale e disambiguazione – mostrano il potere di trasformazione dei meccanismi di attenzione. Hanno portato i Transformers in prima linea nell'elaborazione del linguaggio naturale, consentendo loro di affrontare compiti complessi con notevole precisione ed efficienza.
Poiché la PNL e in particolare i LLM continuano ad evolversi, i meccanismi di attenzione giocheranno senza dubbio un ruolo ancora più critico. Sono il ponte tra la sequenza lineare delle parole e il ricco arazzo del linguaggio umano e, in definitiva, la chiave per sbloccare il vero potenziale di queste meraviglie linguistiche. Questo articolo approfondisce i vari tipi di meccanismi di attenzione e le loro funzionalità.
1. Autoattenzione: la stella guida del trasformatore
Immagina di destreggiarti tra più libri e di dover fare riferimento a passaggi specifici in ciascuno mentre scrivi un riassunto. L'attenzione al sé o all'attenzione al prodotto scalato agisce come un assistente intelligente, aiutando i modelli a fare lo stesso con dati sequenziali come frasi o serie temporali. Consente a ciascun elemento della sequenza di occuparsi di ogni altro elemento, catturando efficacemente dipendenze a lungo raggio e relazioni complesse.
Ecco uno sguardo più da vicino ai suoi aspetti tecnici principali:
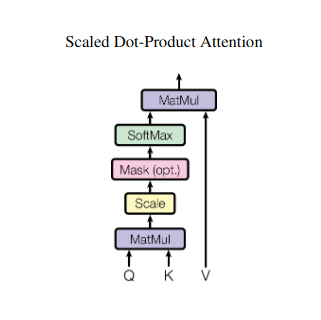
Rappresentazione vettoriale
Ogni elemento (parola, punto dati) viene trasformato in un vettore ad alta dimensione, codificandone il contenuto informativo. Questo spazio vettoriale funge da base per l'interazione tra gli elementi.
Trasformazione QKV
Sono definite tre matrici chiave:
- Domanda (Q): Rappresenta la “domanda” che ogni elemento pone agli altri. Q cattura le esigenze informative dell'elemento corrente e guida la sua ricerca di informazioni rilevanti all'interno della sequenza.
- Chiave (K): Contiene la "chiave" per le informazioni di ciascun elemento. K codifica l'essenza del contenuto di ciascun elemento, consentendo ad altri elementi di identificare la potenziale rilevanza in base alle proprie esigenze.
- Valore (V): Memorizza il contenuto effettivo che ciascun elemento desidera condividere. V contiene le informazioni dettagliate a cui altri elementi possono accedere e sfruttare in base ai loro punteggi di attenzione.
Calcolo del punteggio di attenzione
La compatibilità tra ciascuna coppia di elementi viene misurata attraverso un prodotto scalare tra i rispettivi vettori Q e K. Punteggi più alti indicano una potenziale rilevanza maggiore tra gli elementi.
Pesi di attenzione in scala
Per garantire l'importanza relativa, questi punteggi di compatibilità vengono normalizzati utilizzando una funzione softmax. Ciò si traduce in pesi di attenzione, compresi tra 0 e 1, che rappresentano l'importanza ponderata di ciascun elemento per il contesto dell'elemento corrente.
Aggregazione del contesto ponderato
I pesi dell'attenzione vengono applicati alla matrice V, evidenziando essenzialmente le informazioni importanti di ciascun elemento in base alla sua rilevanza per l'elemento corrente. Questa somma ponderata crea una rappresentazione contestualizzata per l'elemento corrente, incorporando le informazioni raccolte da tutti gli altri elementi nella sequenza.
Rappresentazione degli elementi migliorata
Con la sua rappresentazione arricchita, l'elemento possiede ora una comprensione più profonda del proprio contenuto e delle sue relazioni con gli altri elementi della sequenza. Questa rappresentazione trasformata costituisce la base per la successiva elaborazione all'interno del modello.
Questo processo in più fasi consente all’attenzione al sé di:
- Cattura dipendenze a lungo raggio: Le relazioni tra elementi distanti diventano subito evidenti, anche se separati da molteplici elementi intermedi.
- Modella interazioni complesse: Vengono portate alla luce sottili dipendenze e correlazioni all'interno della sequenza, portando a una comprensione più approfondita della struttura e delle dinamiche dei dati.
- Contestualizza ogni elemento: Il modello analizza ogni elemento non isolatamente ma nel quadro più ampio della sequenza, portando a previsioni o rappresentazioni più accurate e sfumate.
L’autoattenzione ha rivoluzionato il modo in cui i modelli elaborano i dati sequenziali, sbloccando nuove possibilità in diversi campi come la traduzione automatica, la generazione di linguaggio naturale, la previsione di serie temporali e altro ancora. La sua capacità di svelare le relazioni nascoste all'interno delle sequenze fornisce un potente strumento per scoprire informazioni approfondite e ottenere prestazioni superiori in un'ampia gamma di attività.
2. Attenzione multitesta: vedere attraverso obiettivi diversi
L’attenzione al sé fornisce una visione olistica, ma a volte è fondamentale concentrarsi su aspetti specifici dei dati. È qui che entra in gioco l'attenzione di più teste. Immagina di avere più assistenti, ciascuno dotato di un obiettivo diverso:
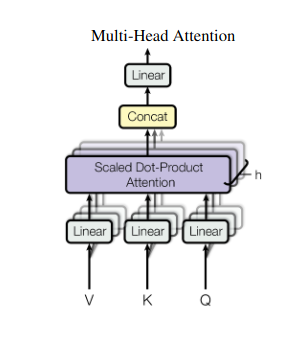
- Molteplici “teste” vengono creati, ciascuno dei quali si occupa della sequenza di input attraverso le proprie matrici Q, K e V.
- Ogni capo impara a concentrarsi su diversi aspetti dei dati, come dipendenze a lungo raggio, relazioni sintattiche o interazioni di parole locali.
- Gli output di ciascuna testa vengono quindi concatenati e proiettati in una rappresentazione finale, catturando la natura sfaccettata dell'input.
Ciò consente al modello di considerare simultaneamente diverse prospettive, portando a una comprensione dei dati più ricca e sfumata.
3. Attenzione incrociata: costruire ponti tra sequenze
La capacità di comprendere le connessioni tra diverse informazioni è cruciale per molte attività di PNL. Immagina di scrivere una recensione di un libro: non ti limiteresti a riassumere il testo parola per parola, ma piuttosto a tracciare approfondimenti e collegamenti tra i capitoli. accedere attenzione incrociata, un potente meccanismo che costruisce ponti tra sequenze, consentendo ai modelli di sfruttare le informazioni provenienti da due fonti distinte.
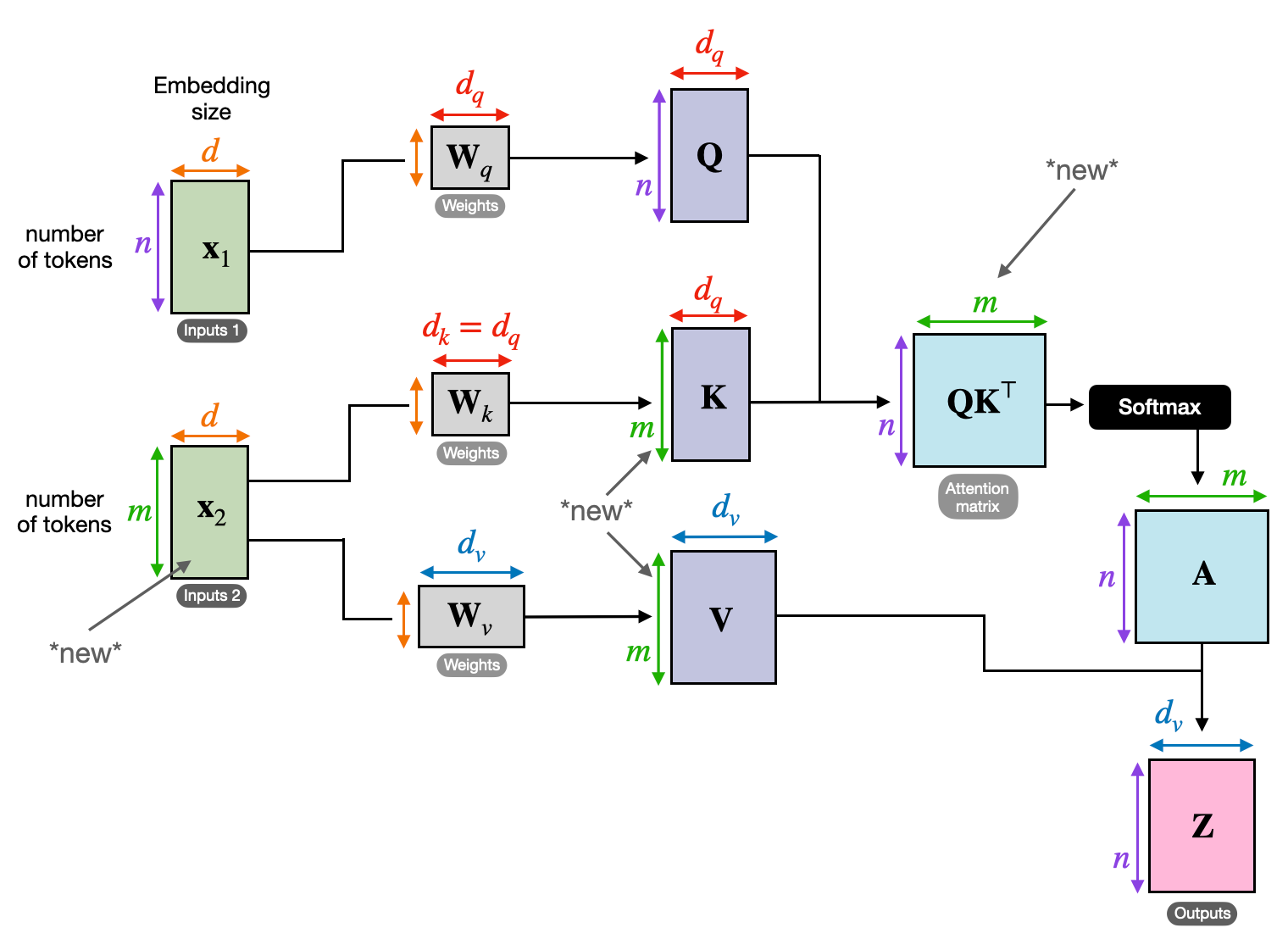
- Nelle architetture codificatore-decodificatore come Transformers, il codificatore elabora la sequenza di input (il libro) e genera una rappresentazione nascosta.
- I decoder utilizza l'attenzione incrociata per prestare attenzione alla rappresentazione nascosta del codificatore in ogni passaggio durante la generazione della sequenza di output (la revisione).
- La matrice Q del decodificatore interagisce con le matrici K e V del codificatore, permettendogli di concentrarsi sulle parti rilevanti del libro mentre scrive ogni frase della recensione.
Questo meccanismo è prezioso per attività come la traduzione automatica, il riepilogo e la risposta a domande, in cui è essenziale comprendere le relazioni tra le sequenze di input e output.
4. Attenzione causale: preservare il flusso del tempo
Immagina di prevedere la parola successiva in una frase senza sbirciare avanti. I meccanismi di attenzione tradizionali lottano con compiti che richiedono la preservazione dell’ordine temporale delle informazioni, come la generazione di testo e la previsione di serie temporali. Essi prontamente “sbirciano avanti” nella sequenza, portando a previsioni imprecise. L'attenzione causale risolve questa limitazione garantendo che le previsioni dipendano esclusivamente da informazioni precedentemente elaborate.
Ecco come funziona
- Meccanismo di mascheramento: Una maschera specifica viene applicata ai pesi dell'attenzione, bloccando di fatto l'accesso del modello agli elementi futuri della sequenza. Ad esempio, quando si prevede la seconda parola in “la donna che…”, il modello può considerare solo “il” e non “chi” o le parole successive.
- Elaborazione autoregressiva: Le informazioni fluiscono in modo lineare, con la rappresentazione di ciascun elemento costruita esclusivamente a partire dagli elementi che appaiono prima di esso. Il modello elabora la sequenza parola per parola, generando previsioni in base al contesto stabilito fino a quel momento.
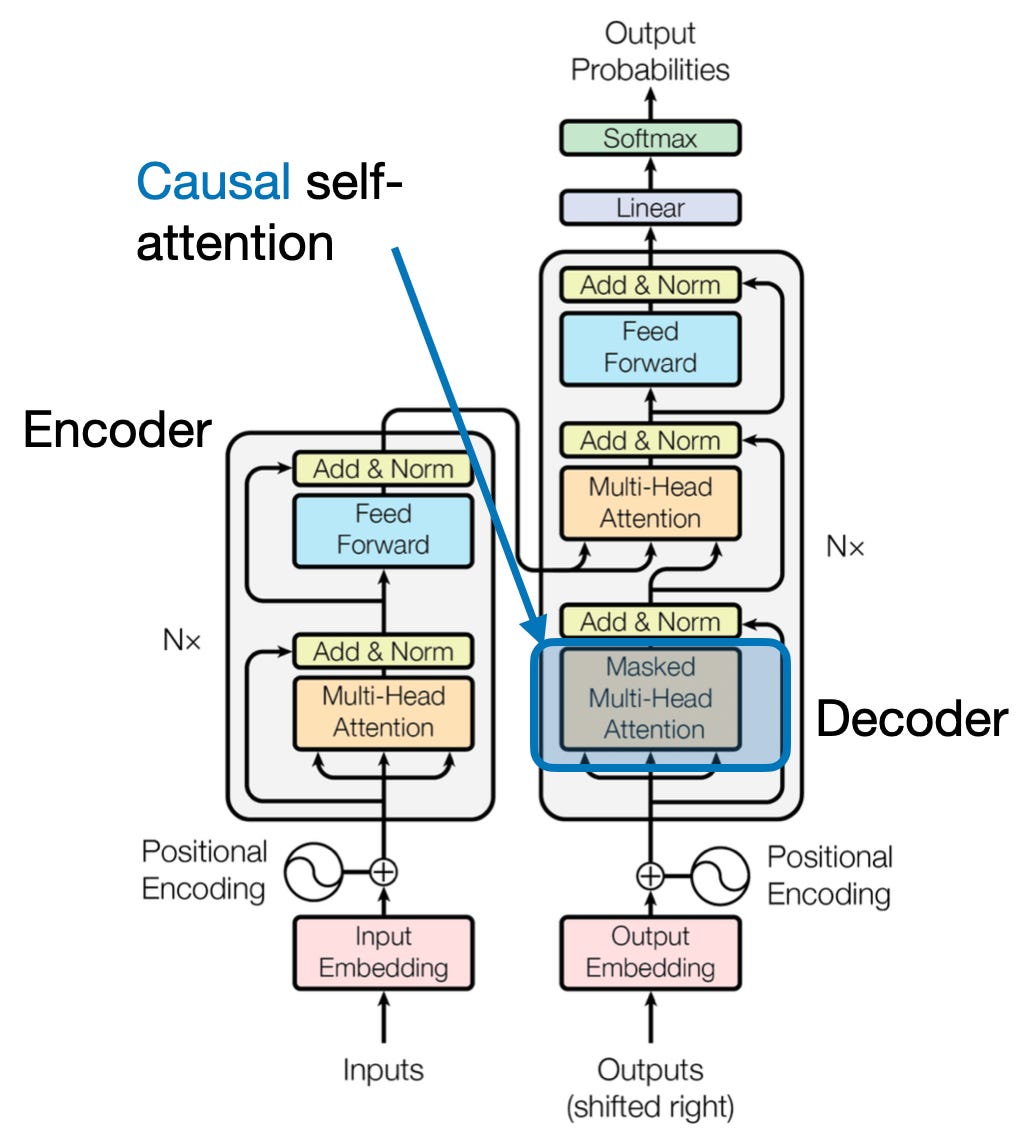
L'attenzione causale è fondamentale per attività come la generazione di testo e la previsione di serie temporali, dove il mantenimento dell'ordine temporale dei dati è vitale per previsioni accurate.
5. Attenzione globale e locale: trovare l’equilibrio
I meccanismi di attenzione devono affrontare un compromesso chiave: catturare dipendenze a lungo raggio rispetto a mantenere un calcolo efficiente. Ciò si manifesta in due approcci principali: attenzione globale ed attenzione locale. Immagina di leggere un intero libro invece di concentrarti su un capitolo specifico. L’attenzione globale elabora l’intera sequenza in una volta, mentre l’attenzione locale si concentra su una finestra più piccola:
- Attenzione globale cattura le dipendenze a lungo raggio e il contesto generale, ma può essere costoso dal punto di vista computazionale per sequenze lunghe.
- Attenzione locale è più efficiente ma potrebbe perdere le relazioni lontane.
La scelta tra attenzione globale e locale dipende da diversi fattori:
- Requisiti del compito: Compiti come la traduzione automatica richiedono di catturare relazioni distanti, favorendo l'attenzione globale, mentre l'analisi del sentiment potrebbe favorire il focus dell'attenzione locale.
- Lunghezza della sequenza: Sequenze più lunghe rendono l’attenzione globale computazionalmente costosa, rendendo necessari approcci locali o ibridi.
- Capacità del modello: I vincoli di risorse potrebbero richiedere attenzione locale anche per compiti che richiedono un contesto globale.
Per raggiungere l’equilibrio ottimale, i modelli possono utilizzare:
- Commutazione dinamica: utilizzare l'attenzione globale per gli elementi chiave e l'attenzione locale per gli altri, adattandosi in base all'importanza e alla distanza.
- Approcci ibridi: combinare entrambi i meccanismi all'interno dello stesso livello, sfruttando i rispettivi punti di forza.
Leggi anche: Analisi dei tipi di reti neurali nel deep learning
Conclusione
In definitiva, l’approccio ideale si colloca in uno spettro compreso tra attenzione globale e locale. Comprendere questi compromessi e adottare strategie adeguate consente ai modelli di sfruttare in modo efficiente le informazioni rilevanti su scale diverse, portando a una comprensione più ricca e accurata della sequenza.
Riferimenti
- Raschka, S. (2023). "Comprensione e codifica dell'attenzione personale, dell'attenzione multi-testa, dell'attenzione incrociata e dell'attenzione causale negli LLM."
- Vaswani, A., et al. (2017). "L'attenzione è tutto ciò di cui hai bisogno."
- Radford, A., et al. (2019). “I modelli linguistici sono studenti multitasking senza supervisione.”
Leggi Anche
Sono un amante dei dati e amo estrarre e comprendere gli schemi nascosti nei dati. Voglio imparare e crescere nel campo del Machine Learning e della Data Science.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.analyticsvidhya.com/blog/2024/01/different-types-of-attention-mechanisms/
- :ha
- :È
- :non
- :Dove
- $ SU
- 1
- 2017
- 2019
- 2023
- 302
- 320
- 321
- 7
- a
- capacità
- accesso
- precisione
- preciso
- Raggiungere
- il raggiungimento
- operanti in
- atti
- presenti
- indirizzi
- Adottando
- avanti
- AL
- Tutti
- Consentire
- consente
- am
- Ambiguità
- importi
- an
- .
- analisi
- l'analisi
- ed
- rispondere
- a parte
- apparente
- applicato
- approccio
- approcci
- SONO
- aree
- articolo
- AS
- aspetti
- Assistant
- assistenti
- At
- assistere
- frequentando
- attenzione
- consapevolezza
- Equilibrio
- basato
- base
- BE
- Larghezza
- diventare
- prima
- fra
- Al di là di
- blocco
- libro
- Libri
- entrambi
- BRIDGE
- ponti
- Brillants
- più ampia
- portato
- Costruzione
- costruisce
- costruito
- ma
- by
- è venuto
- Materiale
- catturare
- cattura
- Catturare
- casi
- il cambiamento
- Capitolo
- capitoli
- scegliere
- più vicino
- codifica
- combinare
- viene
- Aziende
- compatibilità
- complesso
- calcolo
- computazionale
- Connettiti
- Collegamento
- Connessioni
- Prendere in considerazione
- considerando
- vincoli
- contiene
- contenuto
- contesto
- continua
- Nucleo
- correlazioni
- creato
- crea
- Creazione
- critico
- cruciale
- Corrente
- dati
- scienza dei dati
- Decifrare
- deep
- più profondo
- definito
- scava
- dipendere
- dipendenza
- dipendenze
- Dipendenza
- dipende
- dettagliati
- Dialogo
- DID
- diverso
- direttamente
- distanza
- lontano
- distinto
- paesaggio differenziato
- do
- documento
- DOT
- doppio
- decine
- drammaticamente
- disegnare
- dovuto
- dinamica
- E&T
- ogni
- in maniera efficace
- efficienza
- efficiente
- in modo efficiente
- elemento
- elementi
- che abilita
- Abilita
- consentendo
- codifica
- arricchito
- garantire
- assicurando
- entrare
- Intero
- interezza
- attrezzato
- particolarmente
- essenza
- essential
- essenzialmente
- sviluppate
- Anche
- Ogni
- evolvere
- di preciso
- costoso
- Sfruttare
- estratto
- Faccia
- Fattori
- lontano
- favorire
- campo
- campi
- finale
- flusso
- flussi
- Focus
- concentrato
- si concentra
- messa a fuoco
- Nel
- prima linea
- forme
- Fondazione
- quattro
- Contesto
- da
- function
- funzionalità
- futuro
- gioco
- genera
- la generazione di
- ELETTRICA
- globali
- contesto globale
- afferrala
- Crescere
- Guide
- guidare
- maniglia
- Avere
- avendo
- capo
- aiutare
- nascosto
- Alta
- superiore
- mettendo in evidenza
- detiene
- olistica
- Come
- HTTPS
- umano
- IBRIDO
- i
- ideale
- identificare
- if
- immagine
- immediato
- importanza
- importante
- in
- impreciso
- incorporando
- indicare
- individuale
- inefficiente
- informazioni
- intrinsecamente
- ingresso
- intuizioni
- esempio
- Intelligente
- destinato
- interazione
- interazioni
- interagisce
- intervenendo
- ai miglioramenti
- inestimabile
- da solo
- IT
- SUO
- jpg
- ad appena
- Le
- Aree chiave
- Lingua
- Cognome
- strato
- principale
- IMPARARE
- Impara e cresci
- discenti
- apprendimento
- Guidato
- lente
- lenti
- Leva
- leveraging
- Biblioteca
- si trova
- leggera
- piace
- limitazione
- limiti
- locale
- Lunghi
- più a lungo
- Guarda
- amore
- macchina
- machine learning
- traduzione automatica
- mantenimento
- make
- Fare
- uomo
- molti
- mask
- Matrice
- max-width
- significato
- significati
- misurato
- meccanismo
- meccanismi di
- Memorie
- forza
- perdere
- mancante
- modello
- modelli
- Scopri di più
- più efficiente
- poliedrico
- multiplo
- Naturale
- Linguaggio naturale
- Generazione del linguaggio naturale
- Elaborazione del linguaggio naturale
- Comprensione del linguaggio naturale
- Natura
- Bisogno
- che necessitano di
- esigenze
- vicinato
- reti
- Neurale
- reti neurali
- New
- GENERAZIONE
- notte
- nlp
- sostantivi
- adesso
- sfumato
- of
- di frequente
- on
- una volta
- esclusivamente
- ottimale
- or
- minimo
- Altro
- Altri
- nostro
- su
- produzione
- uscite
- complessivo
- panoramica
- proprio
- pagina
- coppia
- Carta
- Parallel
- Ricambi
- passaggi
- passato
- modelli
- eseguire
- performance
- prospettive
- pezzi
- Platone
- Platone Data Intelligence
- PlatoneDati
- Giocare
- punto
- pone
- possiede
- possibilità
- potente
- potenziale
- potenzialmente
- energia
- potente
- previsione
- Previsioni
- preservare
- prevenzione
- in precedenza
- principalmente
- primario
- processi
- elaborati
- i processi
- lavorazione
- Potenza di calcolo
- Prodotto
- proiettato
- a propulsione
- fornisce
- domanda
- gamma
- che vanno
- piuttosto
- Leggi
- prontamente
- Lettura
- tempo reale
- riferimento
- Indipendentemente
- Relazioni
- parente
- rilevanza
- pertinente
- notevole
- rappresentazione
- che rappresenta
- rappresenta
- richiedere
- risolvere
- risorsa
- Risorse
- quelli
- Risultati
- recensioni
- rivoluzionario
- rivoluzionato
- Ricco
- Ruolo
- s
- stesso
- Sarcasmo
- sega
- bilancia
- scansione
- Scienze
- Punto
- punteggi
- Cerca
- Secondo
- vedendo
- condanna
- sentimento
- Sequenza
- Serie
- serve
- alcuni
- Condividi
- splendente
- Shooting
- Corti
- vetrina
- contemporaneamente
- rallentare
- inferiore
- unicamente
- RISOLVERE
- a volte
- fonti
- lo spazio
- specifico
- in particolare
- Spettro
- velocità
- Riflettore
- in piedi
- Stella
- step
- negozi
- strategie
- punti di forza
- più forte
- La struttura
- Lotta
- Lottando
- soggetto
- successivo
- tale
- adatto
- somma
- riassumere
- SOMMARIO
- superiore
- Circostante
- SISTEMI DI TRATTAMENTO
- attrezzatura
- presa
- arazzo
- task
- Consulenza
- termine
- testo
- generazione di testo
- che
- I
- il mondo
- loro
- Li
- poi
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- tre
- Attraverso
- tempo
- Serie storiche
- a
- tradizionale
- Training
- trasformativa
- trasformato
- trasformatore
- trasformatori
- trasformazione
- Traduzione
- vero
- seconda
- Tipi di
- in definitiva
- capire
- e una comprensione reciproca
- indubbiamente
- sblocco
- svelare
- svelato
- uso
- usa
- utilizzando
- vario
- Fisso
- contro
- Visualizza
- visitato
- importantissima
- vs
- volere
- vuole
- Prima
- WELL
- Che
- quando
- while
- OMS
- tutto
- largo
- Vasta gamma
- volere
- finestra
- con
- entro
- senza
- donna
- Word
- parole
- Lavora
- mondo
- scrittura
- ieri
- Tu
- zefiro
- ZOO