I dati geospaziali sono dati su posizioni specifiche sulla superficie terrestre. Può rappresentare un'area geografica nel suo complesso oppure può rappresentare un evento associato ad un'area geografica. L’analisi dei dati geospaziali è ricercata in alcuni settori. Implica capire dove si trovano i dati da una prospettiva spaziale e perché esistono lì.
Esistono due tipi di dati geospaziali: dati vettoriali e dati raster. I dati raster sono una matrice di celle rappresentate come una griglia, che rappresenta principalmente fotografie e immagini satellitari. In questo post, ci concentreremo sui dati vettoriali, che sono rappresentati come coordinate geografiche di latitudine e longitudine, nonché linee e poligoni (aree) che li collegano o li racchiudono. I dati vettoriali hanno una moltitudine di casi d'uso per ricavare informazioni sulla mobilità. I dati mobili degli utenti ne sono uno di questi componenti e derivano principalmente dalla posizione geografica dei dispositivi mobili che utilizzano il GPS o dagli editori di app che utilizzano SDK o integrazioni simili. Ai fini di questo post, ci riferiremo a questi dati come dati sulla mobilità.
Questa è una serie in due parti. In questo primo post presentiamo i dati sulla mobilità, le sue fonti e uno schema tipico di questi dati. Discutiamo quindi dei vari casi d'uso ed esploriamo come utilizzare i servizi AWS per pulire i dati, come il machine learning (ML) può aiutare in questo sforzo e come è possibile fare un uso etico dei dati nella generazione di immagini e approfondimenti. Il secondo post sarà di natura più tecnica e tratterà questi passaggi in dettaglio insieme al codice di esempio. Questo post non contiene un set di dati o un codice di esempio, ma illustra come utilizzare i dati dopo averli acquistati da un aggregatore di dati.
Puoi usare Funzionalità geospaziali di Amazon SageMaker per sovrapporre i dati sulla mobilità su una mappa di base e fornire una visualizzazione a più livelli per facilitare la collaborazione. Il visualizzatore interattivo basato su GPU e i notebook Python forniscono un modo semplice per esplorare milioni di punti dati in un'unica finestra e condividere approfondimenti e risultati.
Fonti e schemi
Esistono poche fonti di dati sulla mobilità. Oltre ai ping GPS e agli editori di app, vengono utilizzate altre fonti per aumentare il set di dati, come punti di accesso Wi-Fi, dati sul flusso di offerte ottenuti tramite la pubblicazione di annunci su dispositivi mobili e trasmettitori hardware specifici posizionati dalle aziende (ad esempio, nei negozi fisici ). Spesso è difficile per le aziende raccogliere questi dati da sole, quindi potrebbero acquistarli dagli aggregatori di dati. Gli aggregatori di dati raccolgono dati sulla mobilità da varie fonti, li puliscono, aggiungono rumore e rendono i dati disponibili quotidianamente per specifiche regioni geografiche. A causa della natura dei dati stessi e poiché sono difficili da ottenere, la precisione e la qualità di questi dati possono variare considerevolmente e spetta alle aziende valutarli e verificarli utilizzando parametri quali utenti attivi giornalieri, ping giornalieri totali, e ping giornalieri medi per dispositivo. La tabella seguente mostra come potrebbe apparire uno schema tipico di un feed di dati giornaliero inviato dagli aggregatori di dati.
| Attributo | Descrizione |
| Id o cameriera | ID pubblicità mobile (MAID) del dispositivo (hash) |
| lat | Latitudine del dispositivo |
| lng | Longitudine del dispositivo |
| geohash | Posizione Geohash del dispositivo |
| tipo di dispositivo | Sistema operativo del dispositivo = IDFA o GAID |
| precisione_orizzontale | Precisione delle coordinate GPS orizzontali (in metri) |
| timestamp | Timestamp dell'evento |
| ip | Indirizzo IP |
| alt | Altitudine del dispositivo (in metri) |
| velocità | Velocità del dispositivo (in metri/secondo) |
| nazione | Codice ISO a due cifre per il paese di origine |
| stato | Codici che rappresentano lo stato |
| città | Codici che rappresentano la città |
| codice postale | Codice postale di dove viene visualizzato l'ID dispositivo |
| vettore | Vettore del dispositivo |
| produttore_dispositivo | Produttore del dispositivo |
Utilizzo Tipico
I dati sulla mobilità hanno applicazioni diffuse in vari settori. Di seguito sono riportati alcuni dei casi d'uso più comuni:
- Metriche di densità – L’analisi del traffico pedonale può essere combinata con la densità di popolazione per osservare le attività e le visite ai punti di interesse (POI). Questi parametri presentano un quadro di quanti dispositivi o utenti si fermano e interagiscono attivamente con un'azienda, che può essere ulteriormente utilizzato per la selezione del sito o anche per analizzare i modelli di movimento attorno a un evento (ad esempio, le persone che viaggiano per una giornata di gioco). Per ottenere tali informazioni, i dati grezzi in entrata passano attraverso un processo di estrazione, trasformazione e caricamento (ETL) per identificare attività o impegni dal flusso continuo di ping di posizione del dispositivo. Possiamo analizzare le attività identificando le fermate effettuate dall'utente o dal dispositivo mobile raggruppando i ping utilizzando i modelli ML in Amazon Sage Maker.
- Viaggi e traiettorie – Il feed di posizione giornaliero di un dispositivo può essere espresso come una raccolta di attività (soste) e viaggi (movimento). Una coppia di attività può rappresentare un viaggio tra di loro, e tracciare il viaggio tramite il dispositivo in movimento nello spazio geografico può portare a mappare la traiettoria effettiva. I modelli di traiettoria dei movimenti degli utenti possono portare a informazioni interessanti come modelli di traffico, consumo di carburante, pianificazione urbana e altro ancora. Può anche fornire dati per analizzare il percorso intrapreso da punti pubblicitari come un cartellone pubblicitario, identificare i percorsi di consegna più efficienti per ottimizzare le operazioni della catena di fornitura o analizzare le rotte di evacuazione in caso di catastrofi naturali (ad esempio, evacuazione in caso di uragano).
- Analisi del bacino d'utenza - A bacino di utenza si riferisce ai luoghi da cui una determinata area attira i suoi visitatori, che possono essere clienti o potenziali clienti. Le aziende di vendita al dettaglio possono utilizzare queste informazioni per determinare la posizione ottimale per aprire un nuovo negozio o determinare se due punti vendita sono troppo vicini l'uno all'altro con bacini di utenza sovrapposti e ostacolano reciprocamente le attività. Possono anche scoprire da dove provengono i clienti effettivi, identificare i potenziali clienti che passano nella zona in viaggio per andare al lavoro o a casa, analizzare metriche di visita simili per i concorrenti e altro ancora. Le società di Marketing Tech (MarTech) e Advertisement Tech (AdTech) possono anche utilizzare questa analisi per ottimizzare le campagne di marketing identificando il pubblico vicino al negozio di un marchio o per classificare i negozi in base alle prestazioni per la pubblicità fuori casa.
Esistono molti altri casi d'uso, tra cui la generazione di informazioni sulla posizione per immobili commerciali, l'integrazione di dati di immagini satellitari con numeri di calpestio, l'identificazione di hub di consegna per ristoranti, la determinazione della probabilità di evacuazione dei quartieri, la scoperta di modelli di movimento delle persone durante una pandemia e altro ancora.
Sfide e uso etico
L’uso etico dei dati sulla mobilità può portare a molti spunti interessanti che possono aiutare le organizzazioni a migliorare le proprie operazioni, eseguire un marketing efficace o persino ottenere un vantaggio competitivo. Per utilizzare questi dati in modo etico, è necessario seguire diversi passaggi.
Si inizia con la raccolta dei dati stessi. Sebbene la maggior parte dei dati sulla mobilità rimanga priva di informazioni di identificazione personale (PII) come nome e indirizzo, i raccoglitori e gli aggregatori di dati devono avere il consenso dell'utente per raccogliere, utilizzare, archiviare e condividere i propri dati. È necessario rispettare le leggi sulla privacy dei dati come GDPR e CCPA perché consentono agli utenti di determinare come le aziende possono utilizzare i propri dati. Questo primo passo rappresenta un passo sostanziale verso un uso etico e responsabile dei dati sulla mobilità, ma si può fare di più.
A ogni dispositivo viene assegnato un Mobile Advertising ID (MAID) con hash, che viene utilizzato per ancorare i singoli ping. Questo può essere ulteriormente offuscato utilizzando Amazon Macie, Lambda oggetto Amazon S3, Amazon Comprehend, o anche il AWS Colla Studio Rileva la trasformazione PII. Per ulteriori informazioni, fare riferimento a Tecniche comuni per rilevare dati PHI e PII utilizzando i servizi AWS.
Oltre alle PII, è necessario prendere in considerazione l’opportunità di mascherare la posizione dell’utente e altri luoghi sensibili come basi militari o luoghi di culto.
Il passaggio finale per un utilizzo etico consiste nel derivare ed esportare solo parametri aggregati da Amazon SageMaker. Ciò significa ottenere parametri quali il numero medio o il numero totale di visitatori rispetto ai modelli di viaggio individuali; ottenere tendenze giornaliere, settimanali, mensili o annuali; o indicizzare i modelli di mobilità su dati disponibili al pubblico come i dati del censimento.
Panoramica della soluzione
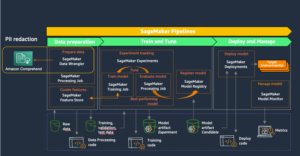
Come accennato in precedenza, i servizi AWS che puoi utilizzare per l'analisi dei dati sulla mobilità sono le funzionalità geospaziali Amazon S3, Amazon Macie, AWS Glue, S3 Object Lambda, Amazon Comprehend e Amazon SageMaker. Le funzionalità geospaziali di Amazon SageMaker semplificano la creazione, il training e la distribuzione di modelli da parte di data scientist e ingegneri ML utilizzando dati geospaziali. Puoi trasformare o arricchire in modo efficiente set di dati geospaziali su larga scala, accelerare la creazione di modelli con modelli ML preaddestrati ed esplorare previsioni di modelli e dati geospaziali su una mappa interattiva utilizzando grafica 3D accelerata e strumenti di visualizzazione integrati.
L'architettura di riferimento seguente illustra un flusso di lavoro che utilizza il machine learning con dati geospaziali.
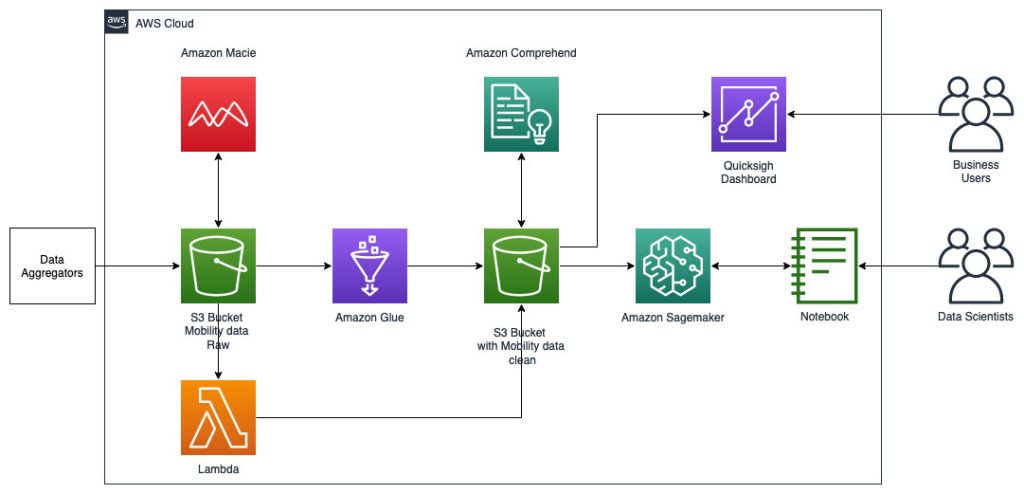
In questo flusso di lavoro, i dati grezzi vengono aggregati da varie origini dati e archiviati in un file Servizio di archiviazione semplice Amazon (S3) secchio. Amazon Macie viene utilizzato su questo bucket S3 per identificare e redigere informazioni personali. AWS Glue viene quindi utilizzato per pulire e trasformare i dati grezzi nel formato richiesto, quindi i dati modificati e puliti vengono archiviati in un bucket S3 separato. Per le trasformazioni di dati che non sono possibili tramite AWS Glue, utilizzi AWS Lambda per modificare e pulire i dati grezzi. Una volta puliti i dati, puoi utilizzare Amazon SageMaker per creare, addestrare e distribuire modelli ML sui dati geospaziali preparati. Puoi anche usare il Lavori di elaborazione geospaziale funzionalità delle funzionalità geospaziali di Amazon SageMaker per preelaborare i dati, ad esempio utilizzando una funzione Python e istruzioni SQL per identificare le attività dai dati grezzi sulla mobilità. I data scientist possono eseguire questo processo connettendosi tramite notebook Amazon SageMaker. Puoi anche usare Amazon QuickSight per visualizzare i risultati aziendali e altri parametri importanti dai dati.
Funzionalità geospaziali di Amazon SageMaker e processi di elaborazione geospaziale
Dopo che i dati sono stati ottenuti e inseriti in Amazon S3 con un feed giornaliero e ripuliti da eventuali dati sensibili, possono essere importati in Amazon SageMaker utilizzando un Amazon Sage Maker Studio taccuino con un'immagine geospaziale. Lo screenshot seguente mostra un esempio di ping giornalieri del dispositivo caricati in Amazon S3 come file CSV e quindi caricati in un frame di dati Pandas. Il notebook Amazon SageMaker Studio con immagine geospaziale è precaricato con librerie geospaziali come GDAL, GeoPandas, Fiona e Shapely e semplifica l'elaborazione e l'analisi di questi dati.
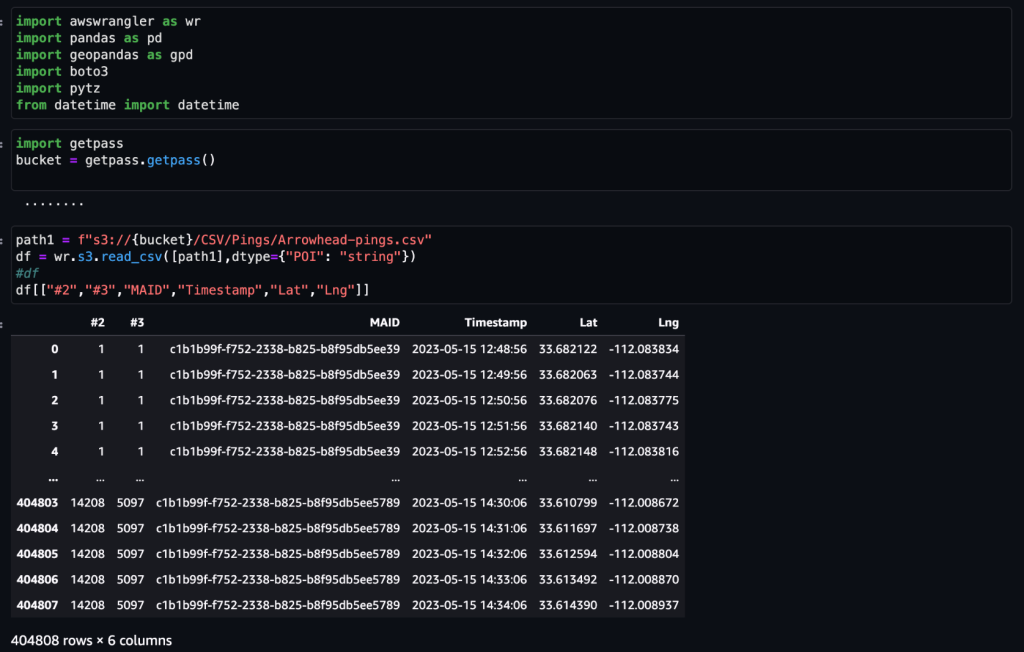
Questo set di dati di esempio contiene circa 400,000 ping giornalieri di 5,000 dispositivi provenienti da 14,000 luoghi univoci registrati da utenti che hanno visitato l'Arrowhead Mall, un famoso complesso di centri commerciali a Phoenix, in Arizona, il 15 maggio 2023. Lo screenshot precedente mostra un sottoinsieme di colonne nel schema dei dati. IL MAID rappresenta l'ID del dispositivo e ciascun MAID genera ping ogni minuto trasmettendo la latitudine e la longitudine del dispositivo, registrate nel file di esempio come Lat ed Lng colonne.
Di seguito sono riportati gli screenshot dello strumento di visualizzazione della mappa delle funzionalità geospaziali di Amazon SageMaker fornito da Foursquare Studio, che illustrano il layout dei ping dei dispositivi che visitano il centro commerciale tra le 7:00 e le 6:00.
Lo screenshot seguente mostra i ping dal centro commerciale e dalle aree circostanti.

Di seguito sono riportati i ping provenienti dall'interno di vari negozi del centro commerciale.
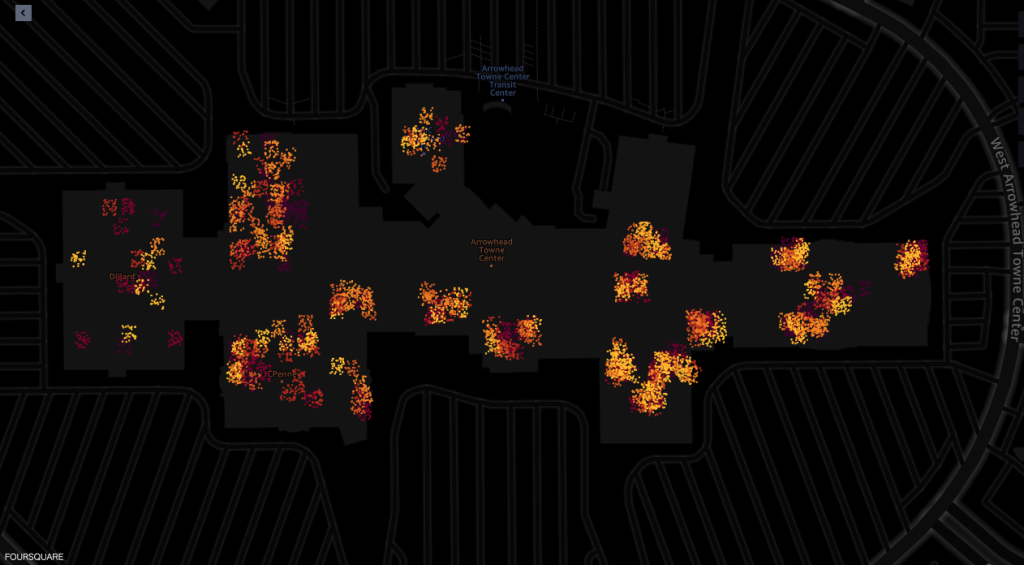
Ogni punto negli screenshot rappresenta un ping da un determinato dispositivo in un determinato momento. Un gruppo di ping rappresenta i luoghi popolari in cui i dispositivi si sono radunati o si sono fermati, come negozi o ristoranti.
Come parte dell'ETL iniziale, questi dati grezzi possono essere caricati su tabelle utilizzando AWS Glue. Puoi creare un crawler AWS Glue per identificare lo schema dei dati e formare tabelle indicando la posizione dei dati non elaborati in Amazon S3 come origine dati.

Come accennato in precedenza, i dati grezzi (i ping giornalieri del dispositivo), anche dopo l'ETL iniziale, rappresenteranno un flusso continuo di ping GPS che indicano le posizioni del dispositivo. Per estrarre informazioni utili da questi dati, dobbiamo identificare fermate e viaggi (traiettorie). Ciò può essere ottenuto utilizzando il Lavori di elaborazione geospaziale caratteristica delle funzionalità geospaziali di SageMaker. Elaborazione di Amazon SageMaker utilizza un'esperienza gestita e semplificata su SageMaker per eseguire carichi di lavoro di elaborazione dati con il contenitore geospaziale appositamente creato. L'infrastruttura sottostante per un lavoro di elaborazione SageMaker è completamente gestita da SageMaker. Questa funzionalità consente l'esecuzione di codice personalizzato su dati geospaziali archiviati su Amazon S3 eseguendo un contenitore ML geospaziale su un processo di elaborazione SageMaker. Puoi eseguire operazioni personalizzate su dati geospaziali aperti o privati scrivendo codice personalizzato con librerie open source ed eseguire l'operazione su larga scala utilizzando i processi di elaborazione SageMaker. L'approccio basato su contenitori risolve le esigenze di standardizzazione dell'ambiente di sviluppo con librerie open source di uso comune.
Per eseguire carichi di lavoro su così larga scala, è necessario un cluster di elaborazione flessibile in grado di scalare da decine di istanze per elaborare un isolato a migliaia di istanze per l'elaborazione su scala planetaria. La gestione manuale di un cluster di elaborazione fai-da-te è lenta e costosa. Questa funzionalità è particolarmente utile quando il set di dati sulla mobilità coinvolge più di poche città in più stati o addirittura paesi e può essere utilizzata per eseguire un approccio ML in due fasi.
Il primo passaggio consiste nell'utilizzare l'algoritmo DBSCAN (clustering spaziale delle applicazioni con rumore) basato sulla densità per raggruppare gli arresti dai ping. Il passo successivo consiste nell'utilizzare il metodo delle Support Vector Machines (SVM) per migliorare ulteriormente la precisione delle fermate identificate e anche per distinguere le fermate con impegni con un POI dalle fermate senza uno (come casa o lavoro). È inoltre possibile utilizzare il lavoro SageMaker Processing per generare viaggi e traiettorie dai ping giornalieri del dispositivo identificando fermate consecutive e mappando il percorso tra le fermate di origine e di destinazione.
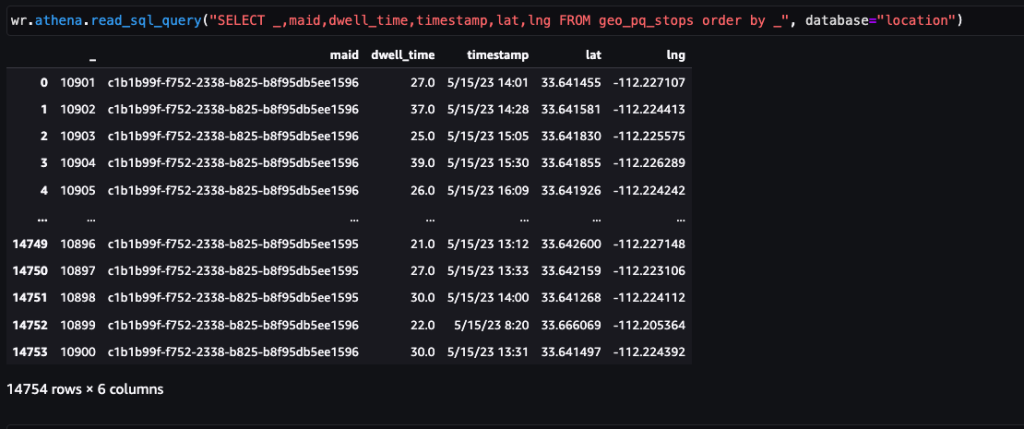
Dopo aver elaborato i dati grezzi (ping giornalieri del dispositivo) su larga scala con processi di elaborazione geospaziale, il nuovo set di dati denominato fermate dovrebbe avere lo schema seguente.
| Attributo | Descrizione |
| Id o cameriera | ID pubblicità mobile del dispositivo (hash) |
| lat | Latitudine del baricentro dell'ammasso di fermate |
| lng | Longitudine del baricentro del cluster di fermate |
| geohash | Posizione geohash del PDI |
| tipo di dispositivo | Sistema operativo del dispositivo (IDFA o GAID) |
| timestamp | Orario di inizio della sosta |
| dwell_time | Tempo di permanenza della fermata (in secondi) |
| ip | Indirizzo IP |
| alt | Altitudine del dispositivo (in metri) |
| nazione | Codice ISO a due cifre per il paese di origine |
| stato | Codici che rappresentano lo stato |
| città | Codici che rappresentano la città |
| codice postale | Codice postale di dove viene visualizzato l'ID del dispositivo |
| vettore | Vettore del dispositivo |
| produttore_dispositivo | Produttore del dispositivo |
Gli arresti vengono consolidati raggruppando i ping per dispositivo. Il clustering basato sulla densità è combinato con parametri come la soglia di fermata di 300 secondi e la distanza minima tra le fermate di 50 metri. Questi parametri possono essere regolati in base al caso d'uso.
La schermata seguente mostra circa 15,000 fermate identificate da 400,000 ping. È presente anche un sottoinsieme dello schema precedente, dove la colonna Dwell Time rappresenta la durata dell'arresto e il Lat ed Lng le colonne rappresentano la latitudine e la longitudine dei centroidi del cluster di fermate per dispositivo e per posizione.
Dopo l'ETL, i dati vengono archiviati nel formato file Parquet, ovvero un formato di archiviazione a colonne che semplifica l'elaborazione di grandi quantità di dati.
Lo screenshot seguente mostra le fermate consolidate dai ping per dispositivo all'interno del centro commerciale e delle aree circostanti.

Dopo aver identificato le fermate, questo set di dati può essere unito ai dati POI disponibili pubblicamente o ai dati POI personalizzati specifici per il caso d'uso per identificare attività, come il coinvolgimento con i marchi.
Lo screenshot seguente mostra le fermate identificate nei principali PDI (negozi e marchi) all'interno dell'Arrowhead Mall.
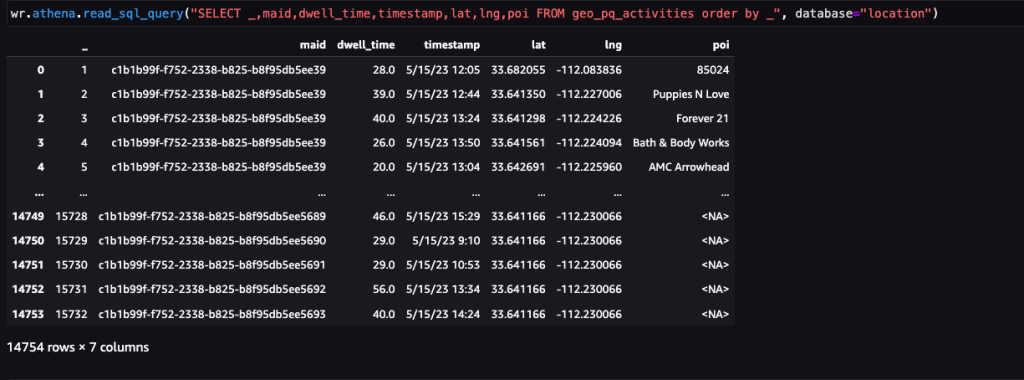
I codici postali di casa sono stati utilizzati per mascherare la posizione di casa di ciascun visitatore per mantenere la privacy nel caso in cui faccia parte del viaggio nel set di dati. La latitudine e la longitudine in questi casi sono le rispettive coordinate del baricentro del codice postale.
Lo screenshot seguente è una rappresentazione visiva di tali attività. L'immagine a sinistra mappa le fermate dei negozi, mentre l'immagine a destra dà un'idea della disposizione del centro commerciale stesso.

Il set di dati risultante può essere visualizzato in diversi modi, di cui parleremo nelle sezioni seguenti.
Metriche di densità
Possiamo calcolare e visualizzare la densità delle attività e delle visite.
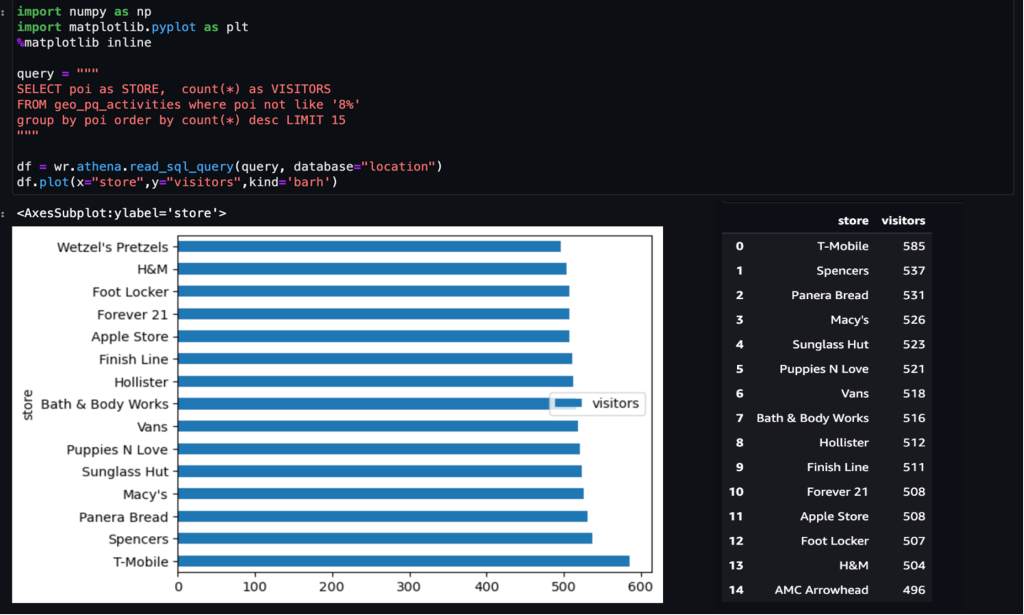
esempio 1 – Lo screenshot seguente mostra i 15 negozi più visitati nel centro commerciale.
esempio 2 – La schermata seguente mostra il numero di visite all'Apple Store ogni ora.

Viaggi e traiettorie
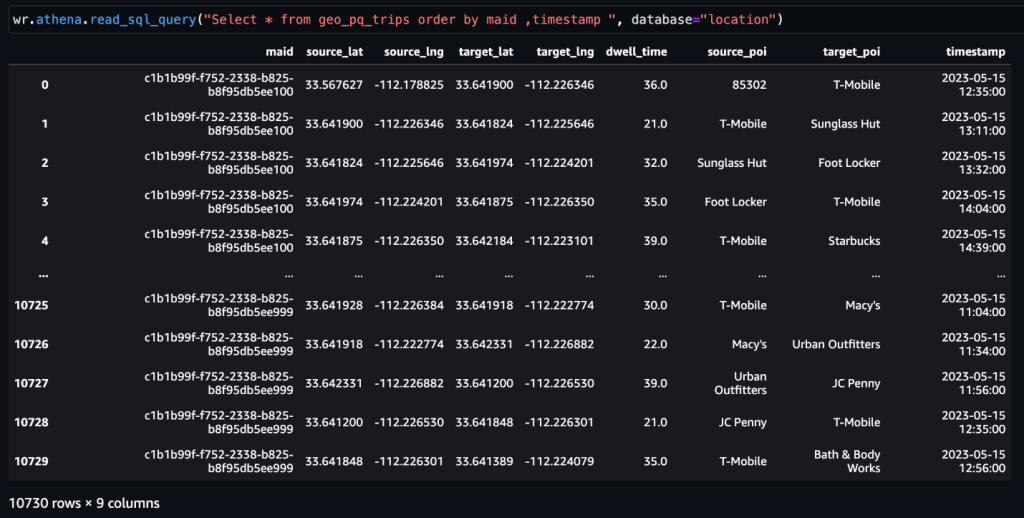
Come accennato in precedenza, una coppia di attività consecutive rappresenta un viaggio. Possiamo utilizzare il seguente approccio per derivare i viaggi dai dati delle attività. Qui, le funzioni finestra vengono utilizzate con SQL per generare il file trips tabella, come mostrato nello screenshot.

Dopo il trips viene generata una tabella, è possibile determinare i viaggi verso un POI.
Esempio 1 – Lo screenshot seguente mostra i primi 10 negozi che indirizzano il traffico pedonale verso l'Apple Store.

esempio 2 – Lo screenshot seguente mostra tutti i viaggi all'Arrowhead Mall.

esempio 3 – Il video seguente mostra gli schemi di movimento all’interno del centro commerciale.

esempio 4 – Il video seguente mostra gli schemi di movimento all’esterno del centro commerciale.
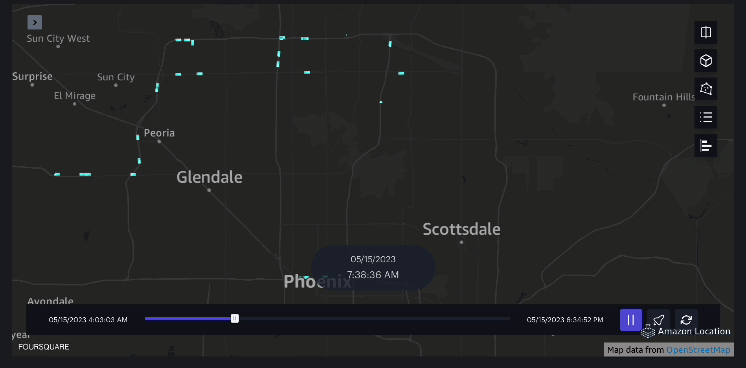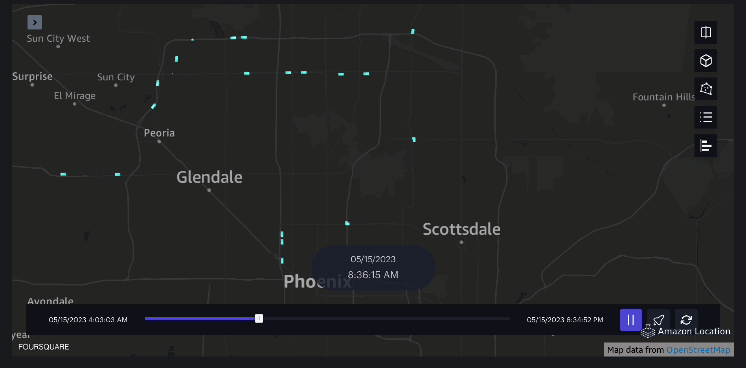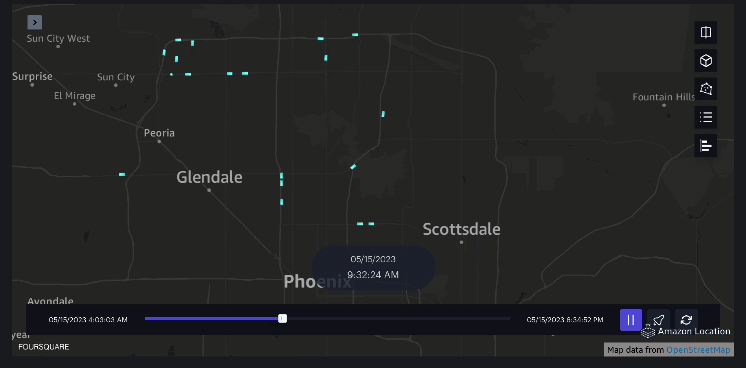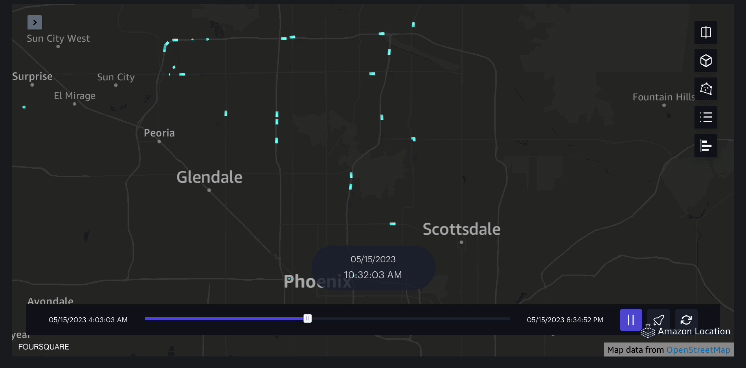
Analisi del bacino d'utenza
Possiamo analizzare tutte le visite a un POI e determinare il bacino di utenza.
Esempio 1 – Lo screenshot seguente mostra tutte le visite al negozio Macy's.

esempio 2 – La schermata seguente mostra i primi 10 codici postali dell'area di residenza (confini evidenziati) da cui si sono verificate le visite.

Controllo della qualità dei dati
Possiamo controllare la qualità del feed di dati in entrata giornaliero e rilevare anomalie utilizzando dashboard QuickSight e analisi dei dati. Lo screenshot seguente mostra un dashboard di esempio.

Conclusione
I dati sulla mobilità e la loro analisi per ottenere informazioni dettagliate sui clienti e ottenere un vantaggio competitivo rimangono un’area di nicchia perché è difficile ottenere un set di dati coerente e accurato. Tuttavia, questi dati possono aiutare le organizzazioni ad aggiungere contesto alle analisi esistenti e persino a produrre nuove informazioni sui modelli di movimento dei clienti. Le funzionalità geospaziali di Amazon SageMaker e i processi di elaborazione geospaziale possono aiutare a implementare questi casi d'uso e ricavare informazioni in modo intuitivo e accessibile.
In questo post, abbiamo dimostrato come utilizzare i servizi AWS per pulire i dati sulla mobilità e quindi utilizzare le capacità geospaziali di Amazon SageMaker per generare set di dati derivati come fermate, attività e viaggi utilizzando modelli ML. Quindi abbiamo utilizzato i set di dati derivati per visualizzare modelli di movimento e generare approfondimenti.
Puoi iniziare a utilizzare le funzionalità geospaziali di Amazon SageMaker in due modi:
Per ulteriori informazioni, visitare il sito Funzionalità geospaziali di Amazon SageMaker ed Nozioni di base sull'utilizzo geospaziale di Amazon SageMaker. Inoltre, visita il nostro Repository GitHub, che contiene diversi notebook di esempio sulle funzionalità geospaziali di Amazon SageMaker.
Informazioni sugli autori
 Jimy Matthews è un AWS Solutions Architect, con esperienza nella tecnologia AI/ML. Jimy ha sede a Boston e lavora con i clienti aziendali mentre trasformano la loro attività adottando il cloud e li aiuta a creare soluzioni efficienti e sostenibili. È appassionato della sua famiglia, delle auto e delle arti marziali miste.
Jimy Matthews è un AWS Solutions Architect, con esperienza nella tecnologia AI/ML. Jimy ha sede a Boston e lavora con i clienti aziendali mentre trasformano la loro attività adottando il cloud e li aiuta a creare soluzioni efficienti e sostenibili. È appassionato della sua famiglia, delle auto e delle arti marziali miste.
 Girish Keshav è un Solutions Architect presso AWS e aiuta i clienti nel loro percorso di migrazione al cloud per modernizzare ed eseguire carichi di lavoro in modo sicuro ed efficiente. Lavora con i leader dei team tecnologici per guidarli sulla sicurezza delle applicazioni, sull'apprendimento automatico, sull'ottimizzazione dei costi e sulla sostenibilità. Vive a San Francisco e ama viaggiare, fare escursioni, guardare sport ed esplorare birrifici artigianali.
Girish Keshav è un Solutions Architect presso AWS e aiuta i clienti nel loro percorso di migrazione al cloud per modernizzare ed eseguire carichi di lavoro in modo sicuro ed efficiente. Lavora con i leader dei team tecnologici per guidarli sulla sicurezza delle applicazioni, sull'apprendimento automatico, sull'ottimizzazione dei costi e sulla sostenibilità. Vive a San Francisco e ama viaggiare, fare escursioni, guardare sport ed esplorare birrifici artigianali.
 Molo di Ramesh è un leader senior di Solutions Architecture focalizzato sull'aiutare i clienti aziendali AWS a monetizzare le proprie risorse di dati. Fornisce consulenza a dirigenti e ingegneri nella progettazione e realizzazione di soluzioni cloud altamente scalabili, affidabili ed economicamente vantaggiose, con particolare attenzione all'apprendimento automatico, ai dati e all'analisi. Nel tempo libero ama stare all'aria aperta, andare in bicicletta e fare escursioni con la famiglia.
Molo di Ramesh è un leader senior di Solutions Architecture focalizzato sull'aiutare i clienti aziendali AWS a monetizzare le proprie risorse di dati. Fornisce consulenza a dirigenti e ingegneri nella progettazione e realizzazione di soluzioni cloud altamente scalabili, affidabili ed economicamente vantaggiose, con particolare attenzione all'apprendimento automatico, ai dati e all'analisi. Nel tempo libero ama stare all'aria aperta, andare in bicicletta e fare escursioni con la famiglia.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/use-mobility-data-to-derive-insights-using-amazon-sagemaker-geospatial-capabilities/
- :ha
- :È
- :non
- :Dove
- $ SU
- 000
- 1
- 10
- 100
- 14
- 15%
- 2023
- 300
- 361
- 3d
- 400
- 50
- 7
- 9
- a
- Chi siamo
- sopra
- accelerare
- accelerata
- accesso
- accessibile
- realizzare
- precisione
- preciso
- raggiunto
- attivo
- attivamente
- attività
- presenti
- aggiungere
- indirizzo
- aderito
- Rettificato
- Adottando
- Ads - Annunci
- Vantaggio
- pubblicità
- Pubblicità
- Dopo shavasana, sedersi in silenzio; saluti;
- Aggregator
- Aggregatori
- AI / ML
- aiuto
- algoritmo
- Tutti
- a fianco di
- anche
- Sebbene il
- am
- Amazon
- Amazon Comprehend
- Amazon Sage Maker
- Amazon SageMaker geospaziale
- Amazon Sage Maker Studio
- Amazon Web Services
- importi
- an
- analisi
- .
- analitica
- analizzare
- l'analisi
- Presentatrice
- ed
- in qualsiasi
- a parte
- App
- Apple
- Applicazioni
- sicurezza delle applicazioni
- applicazioni
- approccio
- circa
- architettura
- SONO
- RISERVATA
- aree
- Arizona
- in giro
- Arte
- AS
- Attività
- addetto
- associato
- At
- raggiungere
- pubblico
- aumentare
- disponibile
- media
- AWS
- Colla AWS
- base
- basato
- base
- BE
- perché
- stato
- essendo
- fra
- offerta
- Bloccare
- Boston
- confini
- marche
- costruire
- Costruzione
- incassato
- affari
- aziende
- ma
- by
- calcolare
- detto
- Responsabile Campagne
- Materiale
- Può ottenere
- funzionalità
- auto
- Custodie
- casi
- CCPA
- Celle
- Censimento
- dati del censimento
- catena
- dai un'occhiata
- Città
- Città
- cavedano
- Chiudi
- Cloud
- Cluster
- il clustering
- codice
- codici
- collaborazione
- raccogliere
- collezione
- collezionisti
- Colonna
- colonne
- combinato
- viene
- arrivo
- immobile commerciale
- Uncommon
- comunemente
- Aziende
- competitivo
- concorrenti
- complesso
- componente
- comprendere
- Calcolare
- Collegamento
- consecutivo
- consenso
- Considerazioni
- coerente
- consumo
- Contenitore
- contiene
- contesto
- continuo
- Costo
- paesi
- nazione
- coprire
- copre
- artigianali
- crawler
- creare
- costume
- cliente
- Clienti
- alle lezioni
- cruscotto
- cruscotti
- dati
- punti dati
- privacy dei dati
- elaborazione dati
- dataset
- giorno
- consegna
- dimostrato
- densità
- raffigurante
- schierare
- derivato
- derivare
- derivato
- Design
- Destinazioni
- dettaglio
- individuare
- Determinare
- determinato
- determinazione
- Mercato
- dispositivo
- dispositivi
- difficile
- dirette
- disastri
- scoprire
- discutere
- distanza
- distinguere
- fai da te
- effettua
- fatto
- DOT
- disegna
- dovuto
- durata
- durante
- ogni
- In precedenza
- più facile
- facile
- Efficace
- efficiente
- in modo efficiente
- sforzo
- e potenza
- Abilita
- che comprende
- Fidanzamento
- impegni
- impegnandosi
- Ingegneri
- arricchire
- Impresa
- clienti aziendali
- Ambiente
- particolarmente
- tenuta
- Etere (ETH)
- etico
- Anche
- Evento
- Ogni
- esempio
- dirigenti
- esistente
- esiste
- costoso
- esperienza
- competenza
- esplora
- Esplorare
- export
- espresso
- estratto
- famiglia
- caratteristica
- Federale
- pochi
- Compila il
- finale
- Trovare
- fiona
- Nome
- flessibile
- Focus
- concentrato
- seguito
- i seguenti
- Calcio
- Nel
- modulo
- formato
- foursquare
- TELAIO
- Francisco
- Gratis
- da
- Carburante
- completamente
- function
- funzioni
- ulteriormente
- guadagnando
- gioco
- raccolto
- GDPR
- generare
- generato
- genera
- la generazione di
- geografico
- geografico
- ML geospaziale
- ottenere
- ottenere
- gif
- dato
- dà
- va
- GPS
- grafiche
- grande
- Vasto spazio all'aperto
- Griglia
- guida
- Hardware
- hash
- Avere
- he
- Aiuto
- utile
- aiutare
- aiuta
- qui
- Evidenziato
- vivamente
- escursionismo
- il suo
- Casa
- Orizzontale
- ora
- Come
- Tutorial
- Tuttavia
- HTML
- http
- HTTPS
- Mozzi
- uragano
- ID
- idea
- identificato
- identificare
- identificazione
- IDFA
- if
- Immagine
- realizzare
- importante
- competenze
- in
- Compreso
- In arrivo
- indicando
- individuale
- industrie
- informazioni
- Infrastruttura
- inizialmente
- interno
- intuizioni
- istanze
- integrazioni
- Intelligence
- interattivo
- interesse
- interessante
- ai miglioramenti
- introdurre
- intuitivo
- comporta
- IT
- SUO
- stessa
- Lavoro
- Offerte di lavoro
- congiunto
- viaggio
- jpg
- grandi
- larga scala
- latitudine
- Legislazione
- stratificato
- disposizione
- portare
- leader
- capi
- IMPARARE
- apprendimento
- a sinistra
- biblioteche
- piace
- probabilità
- Linee
- caricare
- località
- posizioni
- Guarda
- una
- ama
- macchina
- machine learning
- macchine
- fatto
- mantenere
- maggiore
- make
- FA
- gestito
- gestione
- manualmente
- molti
- carta geografica
- mappatura
- Maps
- Marketing
- Campagne di marketing
- tecnologia di marketing
- Martech
- marziale
- mask
- Matrice
- Maggio..
- si intende
- menzionato
- metodo
- Metrica
- migrazione
- Militare
- milioni
- ordine
- minuto
- misto
- ML
- Mobile
- dispositivo mobile
- dispositivi mobili
- mobilità
- modello
- modelli
- modernizzare
- modificato
- modificare
- monetizzare
- mensile
- Scopri di più
- maggior parte
- soprattutto
- cambiano
- movimento
- movimenti
- in movimento
- multiplo
- moltitudine
- devono obbligatoriamente:
- Nome
- Naturale
- Natura
- Bisogno
- esigenze
- New
- GENERAZIONE
- nicchia
- Rumore
- taccuino
- computer portatili
- numero
- numeri
- oggetto
- osservare
- ottenere
- ottenuto
- ottenendo
- si è verificato
- of
- di frequente
- on
- ONE
- esclusivamente
- aprire
- open source
- operazione
- Operazioni
- opposto
- ottimale
- ottimizzazione
- OTTIMIZZA
- or
- organizzazioni
- Altro
- nostro
- su
- risultati
- all'aperto
- al di fuori
- ancora
- coppia
- panda
- pandemia
- parametri
- parte
- particolarmente
- passare
- appassionato
- sentiero
- modelli
- Persone
- per
- eseguire
- performance
- Personalmente
- prospettiva
- fenice
- fotografie
- Fisico
- immagine
- pii
- ping
- posto
- Partner
- pianificazione
- Platone
- Platone Data Intelligence
- PlatoneDati
- pm
- punto
- punti
- Popolare
- popolazione
- posizione
- possibile
- Post
- potenziale
- potenziali clienti
- alimentato
- precedente
- Previsioni
- presenti
- Privacy
- leggi sulla privacy
- un bagno
- processi
- lavorazione
- produrre
- fornire
- pubblicamente
- editori
- Acquista
- acquistati
- scopo
- Python
- qualità
- classifica
- piuttosto
- Crudo
- dati grezzi
- di rose
- beni immobili
- registrato
- riferimento
- riferimento
- si riferisce
- regioni
- affidabile
- resti
- rappresentare
- rappresentazione
- rappresentato
- che rappresenta
- rappresenta
- necessario
- quelli
- responsabile
- Ristoranti
- risultante
- Risultati
- nello specifico retail
- destra
- strada
- percorsi
- Correre
- running
- sagemaker
- Set di dati di esempio
- San
- San Francisco
- satellitare
- immagini satellitari
- scalabile
- Scala
- scienziati
- screenshot
- sdk
- senza soluzione di continuità
- Secondo
- secondo
- sezioni
- in modo sicuro
- problemi di
- prodotti
- anziano
- delicata
- inviato
- separato
- Serie
- Servizi
- servizio
- alcuni
- Condividi
- Shopping
- dovrebbero
- mostrato
- Spettacoli
- simile
- Un'espansione
- semplificata
- singolo
- site
- rallentare
- So
- Soluzioni
- risolve
- alcuni
- ricercato
- Fonte
- fonti
- lo spazio
- Spaziale
- specifico
- Sports
- spot
- SQL
- standardizzazione
- iniziato
- inizio
- dichiarazioni
- stati
- step
- Passi
- Fermare
- fermato
- sosta
- Interrompe
- conservazione
- Tornare al suo account
- memorizzati
- negozi
- lineare
- ruscello
- studio
- sostanziale
- tale
- fornire
- supply chain
- supporto
- superficie
- Circostante
- Sostenibilità
- sostenibile
- sistema
- tavolo
- preso
- le squadre
- Tech
- Consulenza
- tecniche
- Tecnologia
- decine
- di
- che
- I
- L'area
- L’ORIGINE
- loro
- Li
- si
- poi
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- quelli
- migliaia
- soglia
- Attraverso
- tempo
- a
- pure
- strumenti
- top
- Top 10
- Totale
- verso
- Tracciato
- traffico
- Treni
- traiettoria
- Trasformare
- trasformazioni
- trasmettitori
- viaggiare
- Di viaggio
- tendenze
- viaggio
- seconda
- Tipi di
- tipico
- sottostante
- e una comprensione reciproca
- unico
- caricato
- uso
- caso d'uso
- utilizzato
- Utente
- utenti
- usa
- utilizzando
- utilizzare
- vario
- verificare
- via
- Video
- Visita
- visitato
- visitatori
- Visite
- visivo
- visualizzazione
- visualizzare
- visivi
- vs
- guardare
- Modo..
- modi
- we
- sito web
- servizi web
- settimanale
- WELL
- Che
- quando
- quale
- OMS
- tutto
- perché
- Wi-fi
- molto diffuso
- volere
- finestra
- con
- senza
- Lavora
- flusso di lavoro
- lavori
- scrittura
- annuale
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro
- Codice postale