Immagine dell'autore
I tempi stanno cambiando. Se vuoi diventare un data scientist nel 2023, ci sono molte nuove abilità che dovresti aggiungere al tuo elenco, così come la sfilza di abilità esistenti che dovresti aver già imparato.
Perché un insieme così ampio di competenze? Parte del problema è lo scorrimento dell'ambito del lavoro. Nessuno sa cosa sia un data scientist o cosa dovrebbe fare, men che meno il tuo futuro datore di lavoro. Quindi tutto ciò che contiene dati rimane bloccato nella categoria della scienza dei dati che devi affrontare.
Ci si aspetta che tu sappia come pulire, trasformare, analizzare statisticamente, visualizzare, comunicare e prevedere i dati. Non solo, ma anche la nuova tecnologia (o la tecnologia che ha recentemente raggiunto il mainstream) potrebbe essere aggiunta alle tue responsabilità lavorative.
In questo articolo, analizzerò le 19 principali competenze che devi conoscere nel 2023 per essere un data scientist.
Ecco una panoramica dei dieci più importanti.
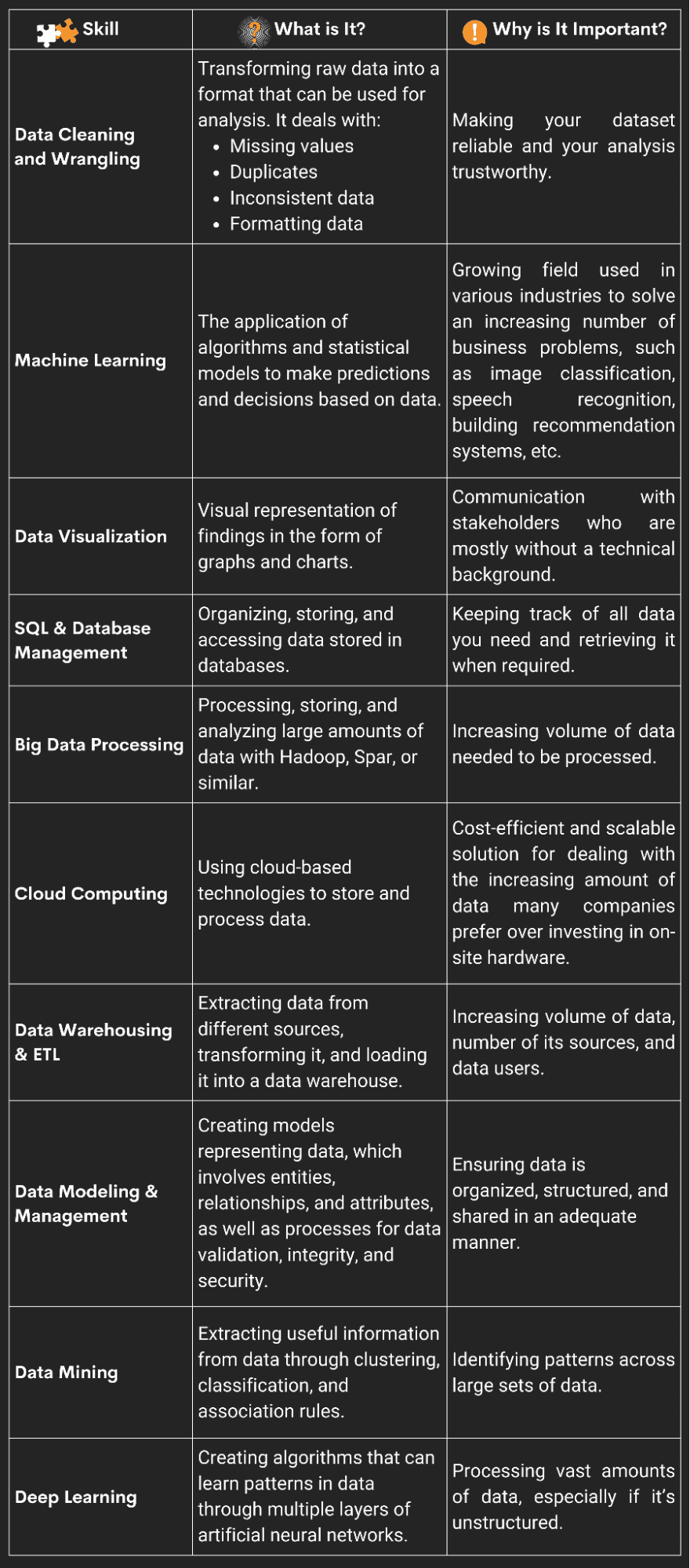
Immagine dell'autore
Queste abilità ti aiuteranno a ottenere un lavoro, superare un colloquio, stare al passo con i tempi e negoziare per quella promozione. In ogni sezione, riassumerò brevemente cos'è ciascuna abilità, perché è importante e offrirò alcuni luoghi per apprendere queste abilità.
Mentre è non L'80% del lavoro di un data scientist, la pulizia e la discussione dei dati sono ancora una delle competenze più importanti che un data scientist può padroneggiare nel 2023.
Che cos'è la pulizia e la discussione dei dati?
La pulizia e la disputa dei dati sono i processi di trasformazione dei dati grezzi in un formato che può essere utilizzato per l'analisi. Ciò comporta la gestione dei valori mancanti, la rimozione dei duplicati, la gestione dei dati incoerenti e la formattazione dei dati in modo da renderli pronti per l'analisi.
La pulizia dei dati di solito si riferisce all'eliminazione di valori errati/imprecisi, al riempimento di eventuali spazi vuoti, alla ricerca di duplicati e all'assicurarsi in altro modo che il set di dati sia impeccabile e affidabile come ci si può aspettare. Combatterlo (o mungerlo, massaggiarlo o qualsiasi altro strano verbo del genere) significa dargli una forma analizzabile. Lo converti o lo mappa in un altro formato più facile da guardare.
Perché è importante diventare un data scientist nel 2023?
Chiedi a qualsiasi data scientist cosa fa e una delle prime cose che menzioneranno sarà la pulizia e la discussione dei dati. I dati non arrivano mai nelle tue mani in una forma bella, pulita e analizzabile, quindi è estremamente importante sapere come metterli in ordine.
La capacità di pulire e classificare i dati assicura che i risultati dell'analisi siano affidabili e aiuta a evitare di trarre conclusioni errate.
Dove puoi imparare questa abilità chiave?
Ci sono molte ottime opzioni per imparare la pulizia e la discussione dei dati. Harvard offre a corso su EdX. Puoi anche esercitarti da solo pulendo e discutendo set di dati grezzi e gratuiti come Common Crawl, dati di scansione web composti da oltre 50 miliardi di pagine web (qui), o i dati meteorologici del Brasile (qui).
No, non è solo una parola d'ordine! L'apprendimento automatico è un'abilità molto importante che qualsiasi futuro scienziato di dati deve conoscere.
Cos'è l'apprendimento automatico?
L'apprendimento automatico è l'applicazione di algoritmi e modelli statistici per fare previsioni e decisioni basate sui dati.
È un sottocampo dell'intelligenza artificiale che consente ai computer di migliorare le proprie prestazioni su un'attività specifica imparando dai dati, senza essere esplicitamente programmati. Aiuta con l'automazione. Lo troverai in qualsiasi settore.
Perché è importante diventare un data scientist nel 2023?
Devi conoscere l'apprendimento automatico nel 2023 perché è un campo in rapida crescita che è diventato uno strumento cruciale per risolvere problemi complessi e fare previsioni in vari settori.
Gli algoritmi di apprendimento automatico possono essere utilizzati per classificare le immagini, riconoscere il parlato, eseguire l'elaborazione del linguaggio naturale e creare sistemi di raccomandazione. Ti sarà difficile trovare un settore che non fa (o non vuole) fare quelle attività assistite da ML.
Essere competenti nell'apprendimento automatico consente a uno scienziato di dati di estrarre informazioni preziose da set di dati ampi e complessi e di sviluppare modelli predittivi che possono guidare decisioni aziendali migliori.
Dove puoi imparare questa abilità chiave?
Abbiamo un archivio di oltre trenta progetti di machine learning su ScrataScratch per mostrare questa abilità sul tuo curriculum. TensorFlow ha anche una serie di fantastiche risorse gratuite per apprendere il machine learning.

Immagine dell'autore
Questa abilità è abbastanza autoesplicativa. Quando analizzi i numeri, le principali parti interessate vorranno comprendere i tuoi risultati con graziosi grafici e diagrammi.
Che cos'è la visualizzazione dei dati?
La visualizzazione dei dati è la creazione di diagrammi, grafici e altri elementi grafici per facilitare la comprensione dei dati. Prendi i numeri che hai appena ripulito, discusso o previsto e li metti in una sorta di formato visivo, per comunicare le tendenze con gli altri o per rendere le tendenze più facili da individuare.
Perché è importante diventare un data scientist nel 2023?
Nel 2023, essere in grado di visualizzare i dati è fondamentale per un data scientist. È come avere un superpotere segreto per scoprire schemi e tendenze nascosti nei dati che potrebbero non essere evidenti a prima vista. E la parte migliore? Puoi condividere le tue scoperte con gli altri in un modo coinvolgente e memorabile. In qualità di data scientist, lavorerai con gruppi di tutti i diversi livelli di esperienza, ma un'immagine è molto più facilmente comprensibile di una fila di numeri.
Quindi, se vuoi essere un data scientist in grado di comunicare efficacemente le tue intuizioni e scoperte, è importante padroneggiare l'arte della visualizzazione dei dati.
Dove puoi imparare questa abilità chiave?
Ecco un elenco di posti gratuiti per imparare i dati vale a dire.
SQL è un linguaggio di query strutturato. I data scientist utilizzano SQL per lavorare con i database SQL, nonché per gestire i database ed eseguire attività di archiviazione dei dati.
Cos'è SQL e la gestione dei database?
SQL è un linguaggio molto diffuso che consente di accedere e manipolare dati strutturati. Va di pari passo con la gestione del database, che viene comunemente eseguita in SQL. La gestione del database è fondamentalmente il modo in cui puoi organizzare, archiviare e recuperare i dati da un luogo. I database SQL sono uno dei migliori tecnologie di back-end da imparare nel 2023, quindi non è solo per la scienza dei dati.
Perché è importante diventare un data scientist nel 2023?
In qualità di data scientist, devi tenere traccia di tutti i dati, assicurarti che siano organizzati e recuperarli quando qualcuno ne ha bisogno. Questo è ciò che SQL e la gestione del database ti permettono di fare.
Dove puoi imparare questa abilità chiave?
Coursera ha una tonnellata di ottimi corsi di gestione/amministrazione di database a buon prezzo che puoi provare. Puoi anche ottenere un'anteprima di alcuni Domande di intervista SQL qui, che può essere utile per testare le tue conoscenze.
Big data è una parola d'ordine, sì, ma è anche un concetto reale: Oracle definisce come “dati che contengono una maggiore varietà, che arrivano in volumi crescenti e con maggiore velocità”, o dati con le tre V.
Cos'è l'elaborazione dei Big Data?
L'elaborazione dei big data è la capacità di elaborare, archiviare e analizzare grandi quantità di dati utilizzando tecnologie come Hadoop e Spark.
Perché è importante diventare un data scientist nel 2023?
Nel 2023, la capacità di elaborare i big data è fondamentale per i data scientist. Il volume di dati generati continua a crescere a un ritmo esponenziale ed essere in grado di gestire e analizzare questi dati in modo efficace è essenziale per prendere decisioni informate e ottenere informazioni preziose. I data scientist che hanno una profonda conoscenza delle tecniche di elaborazione dei big data saranno in grado di lavorare con facilità con grandi set di dati e ottenere il massimo dalle informazioni che contengono.
Inoltre, grazie alla sua verbosità, non fa mai male colpire "big data" sul tuo curriculum.
Dove puoi impararlo?
Adoro Simplilearn Serie di esercitazioni su YouTube su questo concetto.

Immagine dell'autore
È divertente: man mano che sempre più prodotti e servizi si spostano nel cloud, il cloud computing diventa un requisito di lavoro praticamente per ogni lavoro tecnico, che sia DevOps o un data scientist.
Che cos'è il cloud computing?
Il cloud computing è l'uso di tecnologie e piattaforme basate su cloud come AWS, Azure o Google Cloud per archiviare ed elaborare i dati. È un po' come avere un magazzino virtuale a cui puoi accedere da qualsiasi luogo e in qualsiasi momento. Invece di archiviare dati e risorse di elaborazione su macchine o server locali, il cloud computing consente alle organizzazioni e ai data scientist di accedere a queste risorse tramite Internet.
Perché è importante diventare un data scientist nel 2023?
Come continuo a sottolineare, la quantità di dati con cui dovresti lavorare come data scientist sta crescendo. Più aziende lo inseriranno nel cloud piuttosto che gestirlo on-premise. Sta diventando sempre più importante avere la possibilità di archiviare ed elaborare questi dati in modo scalabile ed efficiente.
Il cloud computing fornisce una soluzione efficace per questo, consentendo ai data scientist di accedere a grandi quantità di risorse di elaborazione e archiviazione dei dati senza bisogno di costosi hardware e infrastrutture.
Dove puoi impararlo?
La buona notizia è che le aziende possiedono vari cloud, molti di loro hanno interesse a insegnartelo gratuitamente, quindi impari a usare i loro. Google, Microsofte Amazon tutti hanno grandi risorse di cloud computing.
“Aspetta, non abbiamo appena coperto i database? Che cos'è un data warehouse?" Ti sento chiedere.
ti capisco. A volte sembra che l'abilità di data science più critica sia mantenere tutti gli acronimi e il gergo chiari.
Cosa sono il data warehousing e l'ETL?
Innanzitutto, distinguiamo i data warehouse dai database.
I magazzini memorizzano i dati correnti e storici per più sistemi, mentre i database memorizzano i dati correnti necessari per alimentare un progetto. Un database memorizza i dati correnti necessari per alimentare un'applicazione mentre un data warehouse memorizza i dati correnti e storici per uno o più sistemi in uno schema predefinito e fisso per analizzare i dati.
In breve, utilizzeresti un data warehouse per i dati di molti progetti diversi insieme, mentre un database memorizza principalmente i dati di un singolo progetto.
ETL è un processo che coinvolge il data warehousing, abbreviazione di estrarre, trasformare e caricare. Uno strumento ETL estrarrà i dati da qualsiasi sistema di origine dati desiderato, li trasformerà nell'area di staging (di solito pulendo, manipolando o "mungendoli") e quindi caricandoli in un data warehouse.
Perché è importante diventare un data scientist nel 2023?
Mi sembra di aver ripetuto questo punto in ogni abilità, ma i dati stanno crescendo. Le aziende ne sono affamate e si aspettano che tu lo gestisca. Sapere come gestire i dati in pipeline costruibili è fondamentale.
Dove puoi impararlo?
Consiglio di imparare come eseguire un ETL corretto con un linguaggio specifico, come SQL o Python. Datacamp ha un buona con Python. Microsoft esegue un altro tutorial di livello intermedio per passare attraverso un'opzione SQL.
Ogni data scientist è uno specialista di modelli. Non sto parlando di Giselle Bundchen. Intendo creare un modello di come i dati vengono archiviati e organizzati in un sistema.
Che cos'è la modellazione e la gestione dei dati?
La modellazione e la gestione dei dati è il processo di creazione di modelli matematici per rappresentare i dati, nonché la gestione dei dati per mantenerne la qualità, l'accuratezza e l'utilità.
Ciò comporta la definizione di entità di dati, relazioni e attributi, nonché l'implementazione di processi per la convalida, l'integrità e la sicurezza dei dati.
In termini più semplici, la modellazione dei dati significa fondamentalmente che stai creando un progetto per il modo in cui i dati sono organizzati e collegati nei sistemi del tuo datore di lavoro. Puoi pensarlo come disegnare un progetto di una casa. Proprio come un progetto mostra le diverse stanze e il modo in cui sono collegate, la modellazione dei dati mostra come le diverse informazioni sono correlate e collegate tra loro.
Ciò aiuta a garantire che i dati vengano archiviati e utilizzati in modo coerente ed efficace.
Perché è importante diventare un data scientist nel 2023?
In qualità di data scientist, sarai responsabile di assicurarti che i dati siano organizzati e strutturati in modo accessibile. La modellazione e la gestione dei dati ti aiutano a lavorare con i dati, condividerli, assicurarti che siano accurati e prendere decisioni basate su di essi.
Dove puoi impararlo?
Microsoft ha una buona intro sul loro blog, di appena mezz'ora e molto quotato. È un buon punto di partenza.

Immagine per Autore
Molti termini di scienza dei dati sono stati appena derubati da altre professioni, come la modellazione e il mining. Scopriamo cosa significa e perché è importante.
Cos'è il data mining?
Il data mining è il processo di estrazione di informazioni utili dai dati attraverso tecniche come clustering, classificazione e regole di associazione. Stai setacciando la vera marea di dati per trovare utili pepite d'oro. (Forse il panning dei dati sarebbe stato un nome migliore per questa abilità!)
Perché è importante diventare un data scientist nel 2023?
Immagina: sei un data scientist nel 2023. Hai dati che arrivano da diecimila fonti diverse. Quale abilità usi per identificare i modelli in tutte queste fontane di dati?
È il data mining.
Dove puoi impararlo?
Il data mining è in genere trattato nei corsi che trattano i big data o l'analisi dei dati poiché è una componente piuttosto critica di queste due abilità. EdX offre un paio di opzioni per apprendere il data mining.
Il deep learning è leggermente diverso dall'apprendimento automatico! Il deep learning è un sottocampo del machine learning.
Cos'è l'apprendimento profondo?
Il deep learning è un aspetto dell'apprendimento automatico che si concentra sulla creazione di algoritmi in grado di apprendere modelli nei dati attraverso più livelli di reti neurali artificiali. (Le reti neurali artificiali, tra l'altro, sono un tipo di algoritmo di apprendimento automatico modellato per essere simile alla struttura e alla funzione del cervello umano.)
Perché è importante diventare un data scientist nel 2023?
L'intelligenza artificiale sta diventando più sofisticata nel 2023. Non è sufficiente conoscere le basi di AI e ML: dovresti avere familiarità anche con l'avanguardia, perché domani non sarà all'avanguardia. Il deep learning era una novità qualche anno fa e ora è una necessità.
Ci si aspetta che i data scientist utilizzino il deep learning quando le aziende hanno accesso a una quantità veramente vasta di dati. Viene utilizzato per l'elaborazione di immagini e video o per applicazioni di visione artificiale.
Dove puoi impararlo?
Mi piace Tutorial di Simplilearn come punto di partenza.
Ci sono molte tecnologie e tecniche emergenti che è utile conoscere. Questi sono ancora più avanzati, come le reti antagoniste generative, o più basati su competenze trasversali, come la narrazione di dati, o specializzati in un campo come la previsione delle serie temporali. Li riassumo brevemente qui:
- Natural Language Processing (NLP): Un sottocampo dell'intelligenza artificiale che gestisce l'elaborazione e la comprensione del linguaggio umano. I chatbot lo usano.
- Analisi e previsione delle serie storiche: Lo studio dei dati nel tempo e l'uso di modelli statistici per fare previsioni su eventi futuri. Potresti usare questa abilità per fare analisi delle vendite o dei ricavi.
- Progettazione sperimentale e test A/B: Il processo di progettazione e conduzione di esperimenti controllati per testare ipotesi e prendere decisioni basate sui dati.
- Narrazione dei dati: La capacità di comunicare in modo efficace approfondimenti e risultati dei dati a parti interessate non tecniche. Sempre più parti interessate si stanno interessando al perché dietro decisioni basate sui dati, quindi questo è fondamentale.
- Generative Adversarial Networks (GAN): un tipo di architettura di deep learning in cui due reti neurali vengono addestrate a lavorare insieme per generare nuovi dati che assomigliano a un determinato set di dati.
- Trasferire l'apprendimento: Una tecnica di apprendimento automatico in cui un modello viene pre-addestrato su un'attività e perfezionato su un'attività correlata, migliorando le prestazioni e riducendo la quantità di dati di addestramento necessari. Le aziende più piccole che dispongono di risorse più limitate lo troveranno utile.
- Apprendimento automatico automatico (AutoML): Un metodo per automatizzare il processo di selezione, addestramento e distribuzione di modelli di machine learning.
- Sintonia iperparametro: Un'altra sottocategoria ML. Questo è il processo di ottimizzazione delle prestazioni di un modello di machine learning regolando i parametri che non vengono appresi dai dati, come il tasso di apprendimento o il numero di livelli nascosti.
- IA spiegabile (XAI): un ramo dell'intelligenza artificiale incentrato sulla creazione di algoritmi e modelli trasparenti e interpretabili, in modo che i loro processi decisionali possano essere compresi dagli esseri umani. Ancora una volta, aiutare le parti interessate a capire cosa sta succedendo.
Se vuoi diventare un data scientist nel 2023, queste 19 competenze sono assolutamente fondamentali. La vera grande notizia è che molte di queste abilità possono essere autodidatte, mentre altre puoi acquisirle mentre lavori in un ruolo di livello più basso come un analista di dati o di business.
Alcuni modi per imparare:
- Controlla sempre YouTube. Ci sono così tante risorse gratuite e complete. Ne ho elencati alcuni qui, ma ci sono praticamente infiniti video là fuori.
- Piattaforme come Coursera ed EdX hanno spesso serie di conferenze
- Abbiamo oltre un migliaio di vere domande di intervista su cui esercitarsi, entrambi basato sulla codifica ed non codificaa XNUMX e XNUMX stelle. È anche disponibile la esempi di progetti di dati.
Goditi il viaggio di apprendimento di queste abilità per diventare un data scientist nel 2023.
Nato Rosidi è un data scientist e nella strategia di prodotto. È anche un professore a contratto che insegna analisi ed è il fondatore di Strata Scratch, una piattaforma che aiuta i data scientist a prepararsi per le loro interviste con domande di interviste reali delle migliori aziende. Connettiti con lui su Twitter: Strata Scratch or LinkedIn.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://www.kdnuggets.com/2023/04/top-19-skills-need-know-2023-data-scientist.html?utm_source=rss&utm_medium=rss&utm_campaign=top-19-skills-you-need-to-know-in-2023-to-be-a-data-scientist
- :È
- $ SU
- 2023
- a
- capacità
- capace
- Chi siamo
- a proposito
- assolutamente
- accesso
- accessibile
- precisione
- preciso
- Acronimi
- operanti in
- aggiunto
- Avanzate
- contraddittorio
- avanti
- AI
- algoritmo
- Algoritmi
- Tutti
- Consentire
- consente
- già
- Amazon
- quantità
- importi
- .
- analitica
- analizzare
- ed
- e infrastruttura
- Un altro
- ovunque
- Applicazioni
- applicazioni
- architettura
- SONO
- RISERVATA
- in arrivo
- Arte
- articolo
- artificiale
- intelligenza artificiale
- reti neurali artificiali
- AS
- Associazione
- At
- gli attributi
- Automatizzare
- Automazione
- AutoML
- AWS
- azzurro
- BACKEND
- basato
- fondamentalmente
- Nozioni di base
- BE
- perché
- diventare
- diventa
- diventando
- dietro
- essendo
- MIGLIORE
- Meglio
- Big
- Big Data
- Miliardo
- Blog
- Cervello
- Branch di società
- Rompere
- brevemente
- affari
- by
- Materiale
- Categoria
- cambiando
- Grafici
- chatbots
- dai un'occhiata
- classificazione
- classificare
- Pulizia
- Cloud
- il cloud computing
- il clustering
- COM
- arrivo
- Uncommon
- comunemente
- comunicare
- Aziende
- complesso
- componente
- composto
- globale
- computer
- Visione computerizzata
- Applicazioni di visione artificiale
- computer
- informatica
- concetto
- conduzione
- Connettiti
- collegato
- coerente
- contiene
- continua
- controllata
- convertire
- potuto
- Coursera
- Corsi
- coprire
- coperto
- creare
- Creazione
- creazione
- critico
- cruciale
- Corrente
- curva
- taglio
- dati
- Dati Analytics
- data mining
- elaborazione dati
- scienza dei dati
- scienziato di dati
- set di dati
- set di dati
- memorizzazione dei dati
- visualizzazione dati
- data warehouse
- data warehouse
- Banca Dati
- banche dati
- dataset
- affare
- trattare
- Decision Making
- decisioni
- deep
- apprendimento profondo
- definizione
- distribuzione
- Design
- progettazione
- sviluppare
- diverso
- differenziare
- non
- giù
- disegnato
- guidare
- duplicati
- ogni
- più facile
- facilmente
- bordo
- edx
- Efficace
- in maniera efficace
- efficiente
- o
- Abilita
- impegnandosi
- abbastanza
- garantire
- assicura
- entità
- essential
- Etere (ETH)
- Anche
- eventi
- Ogni
- esistente
- attenderti
- previsto
- esperienza
- esponenziale
- estensivo
- estratto
- familiare
- pochi
- campo
- Trovare
- ricerca
- Nome
- fisso
- alluvione
- concentrato
- si concentra
- Nel
- formato
- fondatore
- Gratis
- da
- function
- divertente
- futuro
- guadagnando
- GANS
- generare
- generato
- generativo
- generative reti contraddittorie
- ottenere
- ottenere
- dato
- Sguardo
- Go
- va
- d'oro
- buono
- Google cloud
- grafiche
- grafici
- grande
- maggiore
- Gruppo
- Crescere
- Crescita
- Hadoop
- Metà
- cura
- maniglia
- Maniglie
- Manovrabilità
- Mani
- Happening
- Hardware
- harvard
- Avere
- avendo
- sentire
- Aiuto
- aiutare
- aiuta
- qui
- nascosto
- mettendo in evidenza
- vivamente
- storico
- Casa
- Come
- Tutorial
- HTTPS
- umano
- Gli esseri umani
- Affamato
- i
- MALATO
- identificare
- Immagine
- immagini
- Implementazione
- importante
- competenze
- miglioramento
- in
- crescente
- sempre più
- industrie
- industria
- informazioni
- informati
- Infrastruttura
- intuizioni
- invece
- interezza
- Intelligence
- interesse
- Internet
- Colloquio
- Domande di un'intervista
- interviste
- IT
- SUO
- gergo
- Lavoro
- viaggio
- KDnuggets
- mantenere
- conservazione
- Le
- Genere
- Sapere
- Conoscere
- conoscenze
- Paese
- Lingua
- grandi
- galline ovaiole
- IMPARARE
- imparato
- apprendimento
- lettura
- Consente di
- livelli
- piace
- elencati
- caricare
- locale
- Lunghi
- amore
- macchina
- machine learning
- macchine
- corrente principale
- mantenere
- make
- FA
- Fare
- gestire
- gestione
- manipolazione
- modo
- molti
- carta geografica
- Mastercard
- matematico
- Importanza
- Matters
- si intende
- metodo
- Microsoft
- forza
- Siti di estrazione mineraria
- mancante
- ML
- modello
- modellismo
- modelli
- Scopri di più
- maggior parte
- cambiano
- multiplo
- Nome
- Naturale
- Linguaggio naturale
- Elaborazione del linguaggio naturale
- Bisogno
- di applicazione
- che necessitano di
- esigenze
- reti
- Neurale
- reti neurali
- New
- notizie
- nlp
- non tecnico
- romanzo
- numero
- numeri
- ovvio
- of
- offrire
- Offerte
- on
- ONE
- ottimizzazione
- Opzione
- Opzioni
- oracolo
- organizzazioni
- Organizzato
- Altro
- Altri
- altrimenti
- panoramica
- proprio
- parametri
- parte
- modelli
- eseguire
- performance
- scegliere
- immagine
- pezzi
- posto
- Partner
- piattaforma
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- Abbondanza
- punto
- Popolare
- energia
- in pratica
- pratica
- predire
- previsto
- Previsioni
- Preparare
- piuttosto
- Anteprima
- Problema
- problemi
- processi
- i processi
- lavorazione
- Prodotto
- Prodotti
- Prodotti e Servizi
- Insegnante
- programmato
- progetto
- progetti
- promozione
- corretto
- fornisce
- metti
- Python
- qualità
- Domande
- rapidamente
- tasso
- piuttosto
- Crudo
- dati grezzi
- RE
- a raggiunto
- pronto
- di rose
- recentemente
- riconoscere
- raccomandare
- Consigli
- riducendo
- si riferisce
- relazionato
- Relazioni
- rimozione
- ripetuto
- deposito
- rappresentare
- necessario
- requisito
- assomiglia
- Risorse
- responsabilità
- responsabile
- Risultati
- curriculum vitae
- Le vendite
- Rid
- Ruolo
- Prenotazione sale
- Camere
- lista
- RIGA
- norme
- s
- vendite
- scalabile
- Scienze
- Scienziato
- scienziati
- portata
- Segreto
- Sezione
- problemi di
- Selezione
- Serie
- Servizi
- set
- Set
- alcuni
- Forma
- Condividi
- Corti
- dovrebbero
- mostrare attraverso le sue creazioni
- Spettacoli
- simile
- da
- singolo
- abilità
- abilità
- inferiore
- nascosto
- So
- soluzione
- Soluzione
- alcuni
- Qualcuno
- sofisticato
- Fonte
- fonti
- Scintilla
- specialista
- specializzata
- specifico
- discorso
- Spot
- SQL
- messa in scena
- stakeholder
- inizia a
- Di partenza
- statistiche
- soggiorno
- adesivo
- Ancora
- conservazione
- Tornare al suo account
- memorizzati
- negozi
- narrativa
- dritto
- Strategia
- La struttura
- strutturato
- Studio
- tale
- riassumere
- Super
- superpotenza
- sistema
- SISTEMI DI TRATTAMENTO
- Fai
- presa
- parlando
- Task
- task
- Insegnamento
- tecniche
- Tecnologie
- Tecnologia
- carnagione
- tensorflow
- condizioni
- test
- Testing
- che
- I
- Le nozioni di base
- le informazioni
- loro
- Li
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- cose
- tre
- Attraverso
- tempo
- Serie storiche
- a
- insieme
- domani
- pure
- top
- pista
- allenato
- Training
- Trasformare
- trasformazione
- trasparente
- tendenze
- affidabili sul mercato
- lezione
- tipicamente
- capire
- e una comprensione reciproca
- inteso
- uso
- informazioni utili
- generalmente
- convalida
- Prezioso
- Valori
- varietà
- vario
- Fisso
- Velocità
- Video
- Video
- virtuale
- visione
- visualizzazione
- volume
- volumi
- Magazzino
- Magazzinaggio
- Modo..
- modi
- Tempo
- sito web
- WELL
- Che
- se
- quale
- while
- OMS
- volere
- con
- senza
- Lavora
- lavorare insieme
- lavoro
- sarebbe
- anni
- Trasferimento da aeroporto a Sharm
- youtube
- zefiro