Immagine dell'autore
Sono disponibili molti corsi e risorse sull'apprendimento automatico e la scienza dei dati, ma pochissimi sull'ingegneria dei dati. Ciò solleva alcune domande. È un campo difficile? Offre una paga bassa? Non è considerato entusiasmante come altri ruoli tecnologici? Tuttavia, la realtà è che molte aziende cercano attivamente talenti nell’ingegneria dei dati e offrono stipendi sostanziali, a volte superiori a 200,000 dollari. Gli ingegneri dei dati svolgono un ruolo cruciale come architetti delle piattaforme dati, progettando e costruendo i sistemi fondamentali che consentono ai data scientist e agli esperti di machine learning di funzionare in modo efficace.
Affrontando questa lacuna del settore, DataTalkClub ha introdotto un bootcamp trasformativo e gratuito, "Zoomcamp di ingegneria dei dati“. Questo corso è progettato per potenziare i principianti o i professionisti che desiderano cambiare carriera, con competenze essenziali ed esperienza pratica nell'ingegneria dei dati.
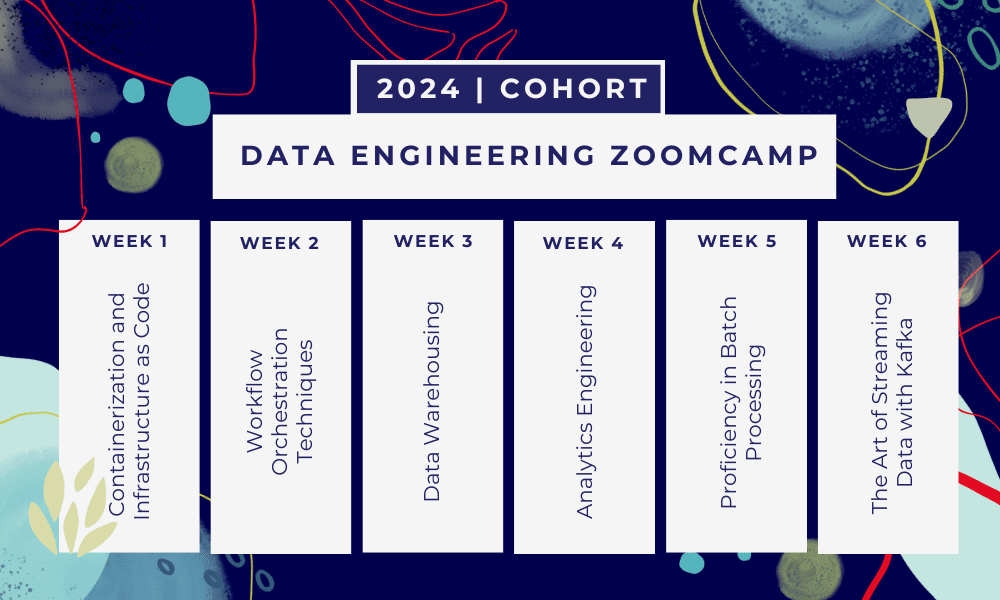
Questo è Campo di addestramento di 6 settimane dove imparerai attraverso più corsi, materiali di lettura, workshop e progetti. Alla fine di ogni modulo ti verranno assegnati dei compiti per mettere in pratica ciò che hai imparato.
- Settimana 1: Introduzione a GCP, Docker, Postgres, Terraform e configurazione dell'ambiente.
- Settimana 2: Orchestrazione del flusso di lavoro con Mage.
- Settimana 3: Data warehousing con BigQuery e machine learning con BigQuery.
- Settimana 4: Ingegnere analitico con dbt, Google Data Studio e Metabase.
- Settimana 5: Elaborazione batch con Spark.
- Settimana 6: In streaming con Kafka.
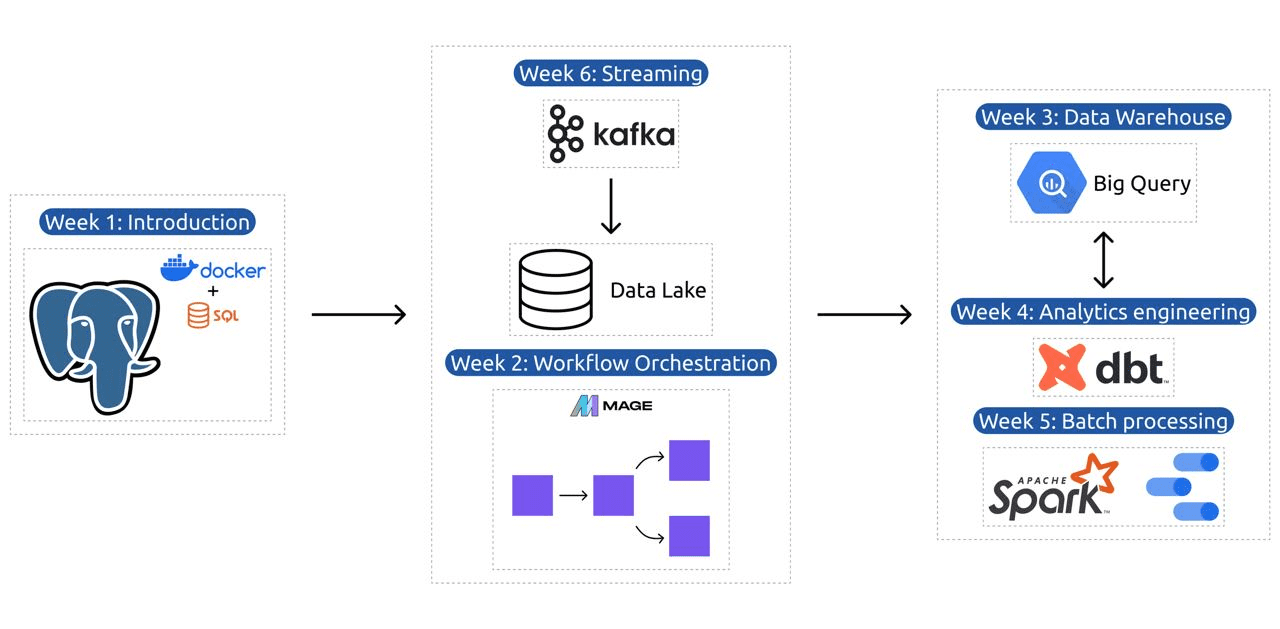
Immagine da DataTalksClub/data-engineering-zoomcamp
Il programma contiene 6 moduli, 2 workshop e un progetto che copre tutto il necessario per diventare un ingegnere dei dati professionista.
Modulo 1: Padroneggiare la containerizzazione e l'infrastruttura come codice
In questo modulo imparerai a conoscere Docker e Postgres, iniziando dalle nozioni di base e avanzando attraverso tutorial dettagliati sulla creazione di pipeline di dati, sull'esecuzione di Postgres con Docker e altro ancora.
Il modulo copre anche strumenti essenziali come pgAdmin, Docker-compose e argomenti di aggiornamento SQL, con contenuti opzionali sulla rete Docker e una procedura dettagliata speciale per gli utenti Linux del sottosistema Windows. Alla fine, il corso introduce GCP e Terraform, fornendo una comprensione olistica della containerizzazione e dell'infrastruttura come codice, essenziale per i moderni ambienti basati sul cloud.
Modulo 2: Tecniche di orchestrazione del flusso di lavoro
Il modulo offre un'esplorazione approfondita di Mage, un innovativo framework ibrido open source per la trasformazione e l'integrazione dei dati. Questo modulo inizia con le nozioni di base sull'orchestrazione del flusso di lavoro, proseguendo con esercizi pratici con Mage, inclusa la configurazione tramite Docker e la creazione di pipeline ETL dall'API a Postgres e Google Cloud Storage (GCS) e quindi a BigQuery.
La combinazione di video, risorse e attività pratiche del modulo garantisce un'esperienza di apprendimento completa, fornendo agli studenti le competenze per gestire sofisticati flussi di lavoro di dati utilizzando Mage.
Workshop 1: Strategie di acquisizione dei dati
Nel primo workshop imparerai a costruire pipeline efficienti di acquisizione dei dati. Il workshop si concentra su competenze essenziali come l'estrazione di dati da API e file, la normalizzazione e il caricamento dei dati e le tecniche di caricamento incrementale. Dopo aver completato questo workshop, sarai in grado di creare pipeline di dati efficienti come un ingegnere dati senior.
Modulo 3: Immagazzinamento di dati
Il modulo è un'esplorazione approfondita dell'archiviazione e dell'analisi dei dati, concentrandosi sul data warehousing utilizzando BigQuery. Copre concetti chiave come il partizionamento e il clustering e approfondisce le best practice di BigQuery. Il modulo prosegue con argomenti avanzati, in particolare l'integrazione di Machine Learning (ML) con BigQuery, evidenziando l'uso di SQL per ML e fornendo risorse sull'ottimizzazione degli iperparametri, sulla preelaborazione delle funzionalità e sulla distribuzione dei modelli.
Modulo 4: Ingegneria analitica
Il modulo di ingegneria analitica si concentra sulla creazione di un progetto utilizzando dbt (Data Build Tool) con un data warehouse esistente, BigQuery o PostgreSQL.
Il modulo copre la configurazione del dbt sia in ambienti cloud che locali, introducendo concetti di ingegneria analitica, ETL vs ELT e modellazione dei dati. Copre anche funzionalità DBT avanzate come modelli incrementali, tag, hook e istantanee.
Alla fine, il modulo introduce tecniche per visualizzare i dati trasformati utilizzando strumenti come Google Data Studio e Metabase e fornisce risorse per la risoluzione dei problemi e il caricamento efficiente dei dati.
Modulo 5: Competenza nell'elaborazione batch
Questo modulo copre l'elaborazione batch utilizzando Apache Spark, iniziando con le introduzioni all'elaborazione batch e a Spark, insieme alle istruzioni di installazione per Windows, Linux e MacOS.
Include l'esplorazione di Spark SQL e DataFrames, la preparazione dei dati, l'esecuzione di operazioni SQL e la comprensione degli aspetti interni di Spark. Infine, si conclude con l'esecuzione di Spark nel cloud e l'integrazione di Spark con BigQuery.
Modulo 6: L'arte dello streaming di dati con Kafka
Il modulo inizia con un'introduzione ai concetti di elaborazione del flusso, seguita da un'esplorazione approfondita di Kafka, compresi i suoi fondamenti, l'integrazione con Confluent Cloud e le applicazioni pratiche che coinvolgono produttori e consumatori.
Il modulo copre anche la configurazione e i flussi di Kafka, affrontando argomenti come join di flussi, test, finestre e l'uso di Kafka ksqldb e Connect. Inoltre, estende la sua attenzione agli ambienti Python e JVM, presentando Faust per l'elaborazione di flussi Python, Pyspark – Streaming strutturato ed esempi Scala per Kafka Streams.
Workshop 2: elaborazione del flusso con SQL
Imparerai a elaborare e gestire i dati in streaming con RisingWave, che fornisce una soluzione economicamente vantaggiosa con un'esperienza in stile PostgreSQL per potenziare le tue applicazioni di elaborazione dei flussi.
Progetto: Applicazione di ingegneria dei dati nel mondo reale
L'obiettivo di questo progetto è implementare tutti i concetti appresi in questo corso per costruire una pipeline di dati end-to-end. Creerai un dashboard composto da due riquadri selezionando un set di dati, costruendo una pipeline per l'elaborazione dei dati e archiviandoli in un data Lake, costruendo una pipeline per trasferire i dati elaborati dal data Lake a un data warehouse, trasformando i dati nel data warehouse e preparandoli per il dashboard, quindi costruendo un dashboard per presentare visivamente i dati.
Dettagli della coorte 2024
- Registrazione: Iscriviti ora
- Data di inizio: 15 gennaio 2024, alle 17:00 CET
- Apprendimento autonomo con supporto guidato
- Cartella della coorte con compiti e scadenze
- Interactive Comunità Slack per l’apprendimento tra pari
Prerequisiti
- Competenze di base di codifica e riga di comando
- Fondamenti in SQL
- Python: utile ma non obbligatorio
Istruttori esperti che guidano il tuo viaggio
- Ankush Khanna
- Vittoria Perez Mola
- Alexei Grigorev
- -- Matt Palmer
- Luis Oliveira
- Michele Calzolaio
Unisciti al nostro gruppo 2024 e inizia ad apprendere con una straordinaria community di ingegneria dei dati. Con una formazione guidata da esperti, un'esperienza pratica e un curriculum su misura per le esigenze del settore, questo bootcamp non solo ti fornisce le competenze necessarie, ma ti posiziona anche in prima linea in un percorso di carriera redditizio e molto richiesto. Iscriviti oggi e trasforma le tue aspirazioni in realtà!
Abid Ali Awan (@1abidaliawan) è un professionista di data scientist certificato che ama creare modelli di machine learning. Attualmente si sta concentrando sulla creazione di contenuti e sulla scrittura di blog tecnici sulle tecnologie di apprendimento automatico e scienza dei dati. Abid ha conseguito un Master in Technology Management e una laurea in Ingegneria delle Telecomunicazioni. La sua visione è quella di costruire un prodotto di intelligenza artificiale utilizzando una rete neurale grafica per studenti alle prese con malattie mentali.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer
- :ha
- :È
- :non
- :Dove
- $ SU
- 000
- 1
- 15%
- 17
- 2024
- a
- capace
- Chi siamo
- attivamente
- Inoltre
- indirizzamento
- Avanzate
- avanzando
- Dopo shavasana, sedersi in silenzio; saluti;
- AI
- Tutti
- lungo
- anche
- stupefacente
- an
- .
- Analitico
- analitica
- ed
- e infrastruttura
- Apache
- Apache Spark
- api
- API
- applicazioni
- architetti
- SONO
- Arte
- AS
- At
- disponibile
- Nozioni di base
- BE
- diventare
- diventando
- principianti
- benefico
- MIGLIORE
- best practice
- BigQuery
- Uvaggio:
- blog
- entrambi
- costruire
- Costruzione
- ma
- by
- Career
- carriere
- Certificato
- Cloud
- Cloud Storage
- il clustering
- codice
- codifica
- Coorte
- comunità
- Aziende
- completando
- globale
- concetti
- conclude
- Configurazione
- ConFluent™
- Connettiti
- considerato
- Consistente
- costruire
- Consumatori
- contiene
- contenuto
- creazione di contenuti
- corso
- Corsi
- copre
- creare
- Creazione
- creazione
- cruciale
- Attualmente
- Programma scolastico
- cruscotto
- dati
- ingegnere dei dati
- Lago di dati
- scienza dei dati
- scienziato di dati
- memorizzazione dei dati
- data warehouse
- Data
- Laurea
- deployment
- progettato
- progettazione
- dettagliati
- difficile
- docker
- ogni
- in maniera efficace
- efficiente
- o
- e potenza
- enable
- fine
- da un capo all'altro
- ingegnere
- Ingegneria
- Ingegneri
- iscriversi
- assicura
- Ambiente
- ambienti
- essential
- Etere (ETH)
- qualunque cosa
- Esempi
- coinvolgenti
- esistente
- esperienza
- esperti
- esplorazione
- Esplorare
- si estende
- caratteristica
- Caratteristiche
- Grazie
- pochi
- campo
- File
- Infine
- Nome
- Focus
- si concentra
- messa a fuoco
- seguito
- Nel
- prima linea
- Fondamentale
- Contesto
- Gratis
- da
- function
- Fondamenti
- divario
- GCP
- dato
- Google cloud
- grafico
- Grafico rete neurale
- guidata
- mani su
- Avere
- he
- mettendo in evidenza
- il suo
- detiene
- olistica
- compito
- ganci
- Tuttavia
- HTTPS
- IBRIDO
- Sintonia iperparametro
- malattia
- realizzare
- in
- Uno sguardo approfondito sui miglioramenti dei pneumatici da corsa di Bridgestone.
- inclusi
- Compreso
- incrementale
- industria
- Infrastruttura
- creativi e originali
- installazione
- istruzioni
- Integrazione
- integrazione
- ai miglioramenti
- introdotto
- Introduce
- l'introduzione di
- Introduzione
- introduzioni
- coinvolgendo
- IT
- SUO
- Gennaio
- Entra a far parte
- kafka
- KDnuggets
- Le
- lago
- principale
- IMPARARE
- imparato
- discenti
- apprendimento
- piace
- linea
- linux
- Caricamento in corso
- locale
- cerca
- ama
- Basso
- lucrativo
- macchina
- machine learning
- macos
- gestire
- gestione
- obbligatorio
- molti
- Mastercard
- La padronanza della
- Materiale
- mentale
- Malattia mentale
- ML
- modello
- modellismo
- modelli
- moderno
- modulo
- moduli
- Scopri di più
- multiplo
- necessaria
- Bisogno
- di applicazione
- esigenze
- Rete
- internazionale
- Neurale
- rete neurale
- obiettivo
- of
- offerta
- Offerte
- on
- esclusivamente
- open source
- Operazioni
- or
- orchestrazione
- Altro
- nostro
- Palmer
- particolarmente
- sentiero
- Paga le
- pera
- esecuzione
- conduttura
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- Giocare
- posizioni
- Postgresql
- Pratico
- Applicazioni pratiche
- pratica
- pratiche
- preparazione
- presenti
- processi
- elaborati
- lavorazione
- Produttori
- Prodotto
- professionale
- Scelto dai professionisti
- progredendo
- progetto
- progetti
- fornisce
- fornitura
- Python
- Domande
- solleva
- Lettura
- mondo reale
- Realtà
- Risorse
- Ruolo
- ruoli
- running
- s
- stipendi
- Scala
- Scienze
- Scienziato
- scienziati
- cerca
- Selezione
- anziano
- regolazione
- flessibile.
- abilità
- allentato
- soluzione
- alcuni
- a volte
- sofisticato
- Scintilla
- la nostra speciale
- SQL
- inizia a
- Di partenza
- conservazione
- ruscello
- Streaming
- flussi
- strutturato
- Lottando
- Gli studenti
- studio
- sostanziale
- tale
- supporto
- Interruttore
- SISTEMI DI TRATTAMENTO
- su misura
- Talento
- task
- Tech
- Consulenza
- tecniche
- Tecnologie
- Tecnologia
- telecomunicazione
- Terraform
- Testing
- che
- Il
- Le nozioni di base
- poi
- questo
- Attraverso
- a
- oggi
- strumenti
- Argomenti
- Training
- Trasferimento
- Trasformare
- Trasformazione
- trasformativa
- trasformato
- trasformazione
- esercitazioni
- seconda
- e una comprensione reciproca
- USD
- uso
- utenti
- utilizzando
- Ve
- molto
- via
- Video
- visione
- visivamente
- vs
- Magazzino
- Magazzinaggio
- we
- Che
- quale
- OMS
- volere
- finestre
- con
- flusso di lavoro
- flussi di lavoro
- laboratorio
- Corsi
- scrittura
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro










