AWS Colla Studio è un'interfaccia grafica che semplifica la creazione, l'esecuzione e il monitoraggio di processi di estrazione, trasformazione e caricamento (ETL) in Colla AWS. Consente di comporre visivamente flussi di lavoro di trasformazione dei dati utilizzando nodi che rappresentano diversi passaggi di gestione dei dati, che in seguito vengono convertiti automaticamente in codice da eseguire.
AWS Colla Studio Recentemente rilasciato Altre 10 trasformazioni visive per consentire la creazione di lavori più avanzati in modo visivo senza competenze di programmazione. In questo post, discutiamo potenziali casi d'uso che riflettono le esigenze ETL comuni.
Le nuove trasformazioni che verranno illustrate in questo post sono: Concatena, Dividi stringa, Matrice in colonne, Aggiungi timestamp corrente, Trasforma righe in colonne, Annulla colonne in righe, Ricerca, Esplodi matrice o mappa in colonne, Colonna derivata ed Elaborazione del bilanciamento automatico .
Panoramica della soluzione
In questo caso d'uso, abbiamo alcuni file JSON con operazioni di stock option. Vogliamo apportare alcune trasformazioni prima di archiviare i dati per semplificarne l'analisi e vogliamo anche produrre un riepilogo del set di dati separato.
In questo set di dati, ogni riga rappresenta uno scambio di contratti di opzione. Le opzioni sono strumenti finanziari che prevedono il diritto, ma non l'obbligo, di acquistare o vendere azioni a un prezzo fisso (cd prezzo di esercizio) prima di una data di scadenza definita.
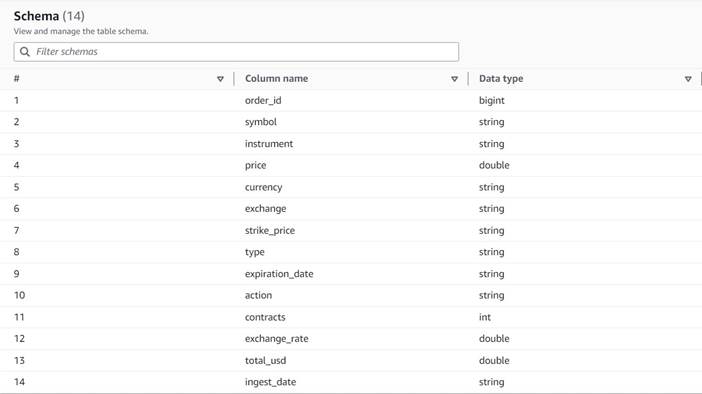
Dati in ingresso
I dati seguono il seguente schema:
- order_id – Un ID univoco
- simbolo – Un codice generalmente basato su poche lettere per identificare la società che emette le azioni sottostanti
- strumento – Il nome che identifica l'opzione specifica acquistata o venduta
- valuta – Il codice valuta ISO in cui è espresso il prezzo
- prezzo – L'importo pagato per l'acquisto di ciascun contratto di opzione (sulla maggior parte delle borse, un contratto consente di acquistare o vendere 100 azioni)
- exchange – Il codice del centro di scambio o della sede in cui è stata negoziata l'opzione
- venduto – Un elenco del numero di contratti che sono stati assegnati per riempire l'ordine di vendita quando si tratta di un'operazione di vendita
- comprato – Un elenco del numero di contratti che sono stati assegnati per riempire l'ordine di acquisto quando si tratta di un'operazione di acquisto
Di seguito è riportato un esempio dei dati sintetici generati per questo post:
Requisiti ETL
Questi dati hanno una serie di caratteristiche uniche, come spesso si trovano sui sistemi più vecchi, che rendono i dati più difficili da usare.
Di seguito sono riportati i requisiti ETL:
- Il nome dello strumento contiene informazioni preziose che devono essere comprese dagli esseri umani; vogliamo normalizzarlo in colonne separate per facilitare l'analisi.
- Gli attributi
boughtedsoldsi escludono a vicenda; possiamo consolidarli in un'unica colonna con i numeri di contratto e avere un'altra colonna che indichi se i contratti sono stati acquistati o venduti in questo ordine. - Vogliamo mantenere le informazioni sulle allocazioni dei singoli contratti ma come singole righe invece di costringere gli utenti a gestire una serie di numeri. Potremmo sommare i numeri, ma perderemmo informazioni su come è stato eseguito l'ordine (indicando la liquidità del mercato). Invece, scegliamo di denormalizzare la tabella in modo che ogni riga abbia un unico numero di contratti, suddividendo gli ordini con più numeri in righe separate. In un formato colonnare compresso, la dimensione extra del set di dati di questa ripetizione è spesso piccola quando viene applicata la compressione, quindi è accettabile rendere il set di dati più facile da interrogare.
- Vogliamo generare una tabella riassuntiva del volume per ogni tipo di opzione (call e put) per ogni azione. Ciò fornisce un'indicazione del sentimento del mercato per ogni titolo e del mercato in generale (avidità vs. paura).
- Per abilitare i riepiloghi complessivi degli scambi, vogliamo fornire per ciascuna operazione il totale generale e standardizzare la valuta in dollari USA, utilizzando un riferimento di conversione approssimativo.
- Vogliamo aggiungere la data in cui sono avvenute queste trasformazioni. Questo potrebbe essere utile, ad esempio, per avere un riferimento su quando è stata effettuata la conversione di valuta.
Sulla base di tali requisiti, il lavoro produrrà due output:
- Un file CSV con un riepilogo del numero di contratti per ogni simbolo e tipologia
- Una tabella catalogo per tenere uno storico dell'ordine, dopo aver effettuato le trasformazioni indicate
Prerequisiti
Avrai bisogno del tuo bucket S3 per seguire questo caso d'uso. Per creare un nuovo bucket, fare riferimento a Creare un secchio.
Genera dati sintetici
Per seguire questo post (o sperimentare questo tipo di dati da solo), puoi generare questo set di dati sinteticamente. Il seguente script Python può essere eseguito in un ambiente Python con Boto3 installato e accessibile Servizio di archiviazione semplice Amazon (Amazon S3).
Per generare i dati, completare i seguenti passaggi:
- Su AWS Glue Studio, crea un nuovo lavoro con l'opzione Editor di script della shell Python.
- Dai un nome al lavoro e sul Dettagli di lavoro scheda, selezionare a ruolo adatto e un nome per lo script Python.
- Nel Dettagli di lavoro sezione, espandere Proprietà avanzate e scorrere fino a Parametri del lavoro.
- Immettere un parametro denominato
--buckete assegna come valore il nome del bucket che desideri utilizzare per archiviare i dati di esempio. - Inserisci il seguente script nell'editor della shell di AWS Glue:
- Esegui il processo e attendi finché non viene visualizzato come completato correttamente nella scheda Esecuzioni (dovrebbero essere necessari solo pochi secondi).
Ogni esecuzione genererà un file JSON con 1,000 righe sotto il bucket e il prefisso specificati transformsblog/inputdata/. È possibile eseguire il processo più volte se si desidera testare con più file di input.
Ogni riga nei dati sintetici è una riga di dati che rappresenta un oggetto JSON come il seguente:
Crea il lavoro visivo di AWS Glue
Per creare il lavoro visivo di AWS Glue, completa i seguenti passaggi:
- Vai su AWS Glue Studio e crea un processo utilizzando l'opzione Visual con una tela bianca.
- Modifica
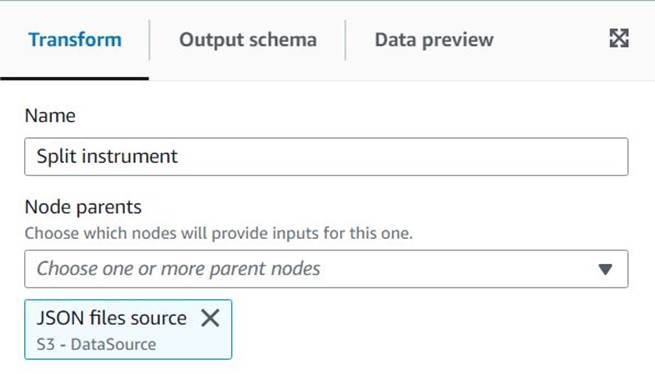
Untitled jobper dargli un nome e assegnare un ruolo adatto ad AWS Glue sul Dettagli di lavoro scheda. - Aggiungi un'origine dati S3 (puoi nominarla
JSON files source) e inserisci l'URL S3 in cui sono archiviati i file (ad esempio,s3://<your bucket name>/transformsblog/inputdata/), quindi selezionare JSON come formato dei dati. - Seleziona Deduci schema quindi imposta lo schema di output in base ai dati.
Da questo nodo di origine, continuerai a concatenare le trasformazioni. Quando aggiungi ogni trasformazione, assicurati che il nodo selezionato sia l'ultimo aggiunto in modo che venga assegnato come genitore, se non diversamente indicato nelle istruzioni.
Se non hai selezionato il genitore giusto, puoi sempre modificare il genitore selezionandolo e scegliendo un altro genitore nel pannello di configurazione.
Per ogni nodo aggiunto, gli assegnerai un nome specifico (quindi lo scopo del nodo viene mostrato nel grafico) e una configurazione sul file Trasformare scheda.
Ogni volta che una trasformazione modifica lo schema (ad esempio, aggiungi una nuova colonna), lo schema di output deve essere aggiornato in modo che sia visibile alle trasformazioni a valle. Puoi modificare manualmente lo schema di output, ma è più pratico e più sicuro farlo utilizzando l'anteprima dei dati.
Inoltre, in questo modo puoi verificare che la trasformazione funzioni come previsto. Per farlo, apri il file Anteprima dei dati scheda con la trasformazione selezionata e avviare una sessione di anteprima. Dopo aver verificato che i dati trasformati abbiano l'aspetto previsto, vai al file Schema di output scheda e scegliere Utilizza lo schema di anteprima dei dati per aggiornare automaticamente lo schema.
Man mano che aggiungi nuovi tipi di trasformazioni, l'anteprima potrebbe mostrare un messaggio relativo a una dipendenza mancante. Quando questo accade, scegli Fine sessione e ne inizia uno nuovo, quindi l'anteprima raccoglie il nuovo tipo di nodo.
Estrarre le informazioni sullo strumento
Iniziamo trattando le informazioni sul nome dello strumento per normalizzarle in colonne di più facile accesso nella tabella di output risultante.
- Aggiungere un Corda divisa nodo e nominarlo
Split instrument, che tokenizzerà la colonna dello strumento utilizzando una regex di spazi bianchi:s+(in questo caso andrebbe bene un unico spazio, ma in questo modo è più flessibile e visivamente più chiaro). - Vogliamo mantenere le informazioni sullo strumento originale così come sono, quindi inserisci un nuovo nome di colonna per l'array diviso:
instrument_arr.
- Aggiungi un Matrice a colonne nodo e nominarlo
Instrument columnsper convertire la colonna dell'array appena creata in nuovi campi, ad eccezione disymbol, per il quale abbiamo già una colonna. - Seleziona la colonna
instrument_arr, salta il primo token e digli di estrarre le colonne di outputmonth, day, year, strike_price, typeutilizzando gli indici2, 3, 4, 5, 6(gli spazi dopo le virgole sono per la leggibilità, non incidono sulla configurazione).
L'anno estratto è espresso con due sole cifre; mettiamo un tampone per supporre che sia in questo secolo se usano solo due cifre.
- Aggiungere un Colonna derivata nodo e nominarlo
Four digits year. - entrare
yearcome colonna derivata in modo che la sovrascriva e immetti la seguente espressione SQL:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
Per comodità, costruiamo un file expiration_date campo che un utente può avere come riferimento della data ultima in cui l'opzione può essere esercitata.
- Aggiungere un Concatena colonne nodo e nominarlo
Build expiration date. - Assegna un nome alla nuova colonna
expiration_date, seleziona le colonneyear,montheday(in quest'ordine) e un trattino come spaziatore.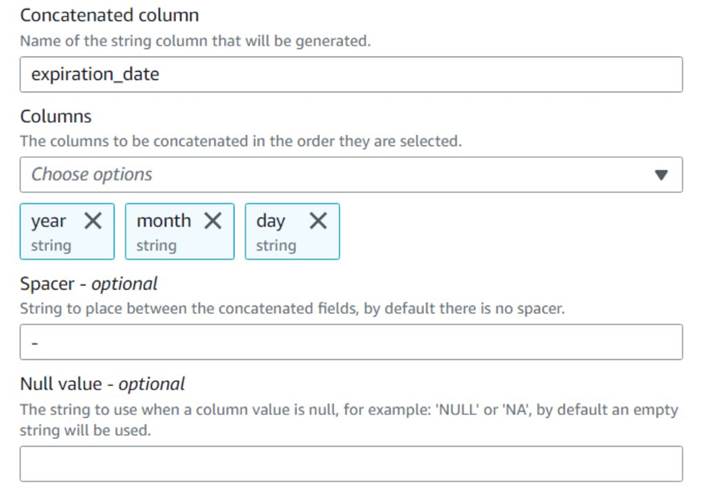
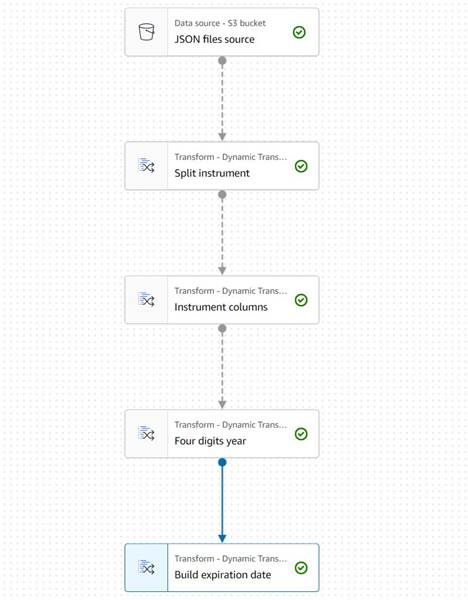
Il diagramma finora dovrebbe essere simile al seguente esempio.
L'anteprima dei dati delle nuove colonne finora dovrebbe essere simile allo screenshot seguente.
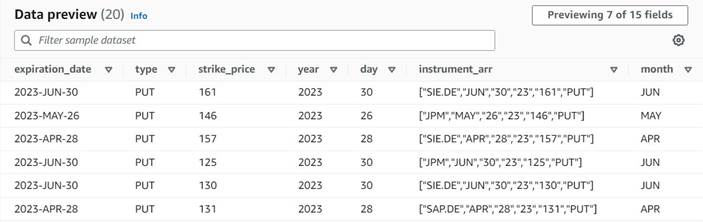
Normalizzare il numero di contratti
Ciascuna delle righe nei dati indica il numero di contratti di ciascuna opzione che sono stati acquistati o venduti e i lotti su cui sono stati eseguiti gli ordini. Senza perdere le informazioni sui singoli lotti, vogliamo avere ogni importo su una singola riga con un unico valore di importo, mentre il resto delle informazioni viene replicato in ogni riga prodotta.
Innanzitutto, uniamo gli importi in un'unica colonna.
- Aggiungi un Unpivot colonne in righe nodo e nominarlo
Unpivot actions. - Scegli le colonne
boughtedsoldper annullare il pivot e memorizzare i nomi e i valori nelle colonne denominateactionedcontracts, Rispettivamente.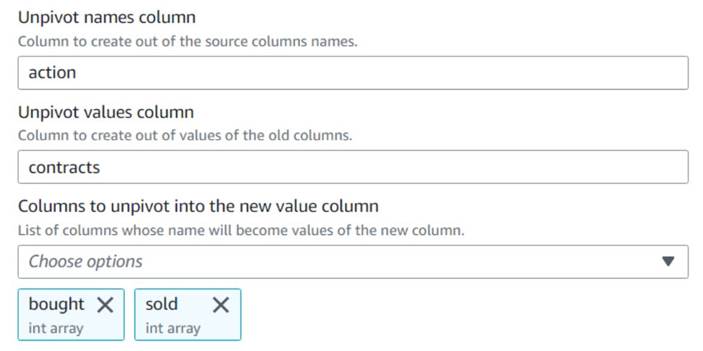
Si noti nell'anteprima che la nuova colonnacontractsè ancora un array di numeri dopo questa trasformazione.
- Aggiungi un Esplodi matrice o mappa in righe riga denominata
Explode contracts. - Scegliere il
contractscolonna e inseriscicontractscome nuova colonna per sovrascriverla (non è necessario mantenere l'array originale).
L'anteprima ora mostra che ogni riga ha un singolo contracts importo e il resto dei campi sono gli stessi.
Questo significa anche che order_id non è più una chiave univoca. Per i tuoi casi d'uso, devi decidere come modellare i tuoi dati e se vuoi denormalizzare o meno.
Lo screenshot seguente è un esempio dell'aspetto delle nuove colonne dopo le trasformazioni effettuate finora.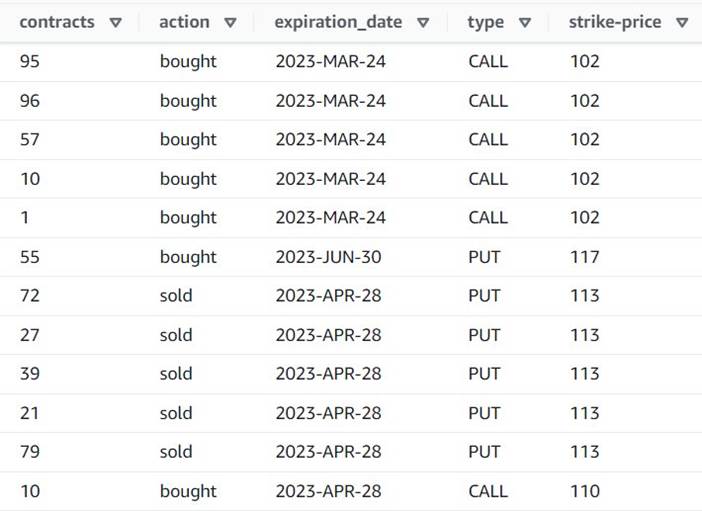
Crea una tabella riassuntiva
Ora crei una tabella riassuntiva con il numero di contratti scambiati per ogni tipo e ogni simbolo di borsa.
Supponiamo a scopo illustrativo che i file elaborati appartengano a un solo giorno, quindi questo riepilogo fornisce agli utenti aziendali informazioni su quali sono l'interesse e il sentiment del mercato quel giorno.
- Aggiungere un Seleziona Campi nodo e selezionare le seguenti colonne da conservare per il riepilogo:
symbol,typeecontracts.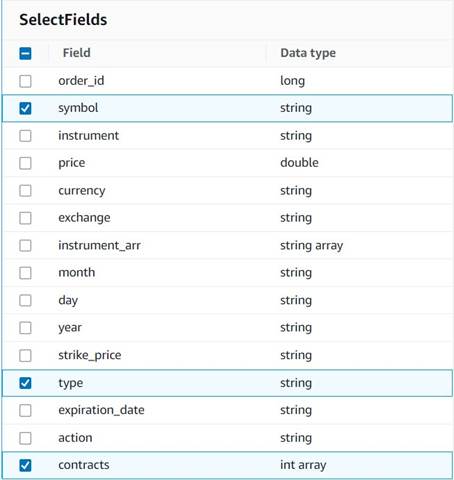
- Aggiungere un Trasforma le righe in colonne nodo e nominarlo
Pivot summary. - Aggregato sul
contractscolonna usandosume scegliere di convertire il filetypecolonna.
Normalmente, lo memorizzeresti su un database o file esterno per riferimento; in questo esempio, lo salviamo come file CSV su Amazon S3.
- Aggiungi un Elaborazione del bilanciamento automatico nodo e nominarlo
Single output file. - Sebbene quel tipo di trasformazione sia normalmente usato per ottimizzare il parallelismo, qui lo usiamo per ridurre l'output a un singolo file. Pertanto, entra
1nella configurazione del numero di partizioni.
- Aggiungi un target S3 e assegnagli un nome
CSV Contract summary. - Scegli CSV come formato dati e immetti un percorso S3 in cui il ruolo professionale è autorizzato a memorizzare i file.
L'ultima parte del lavoro dovrebbe ora essere simile all'esempio seguente.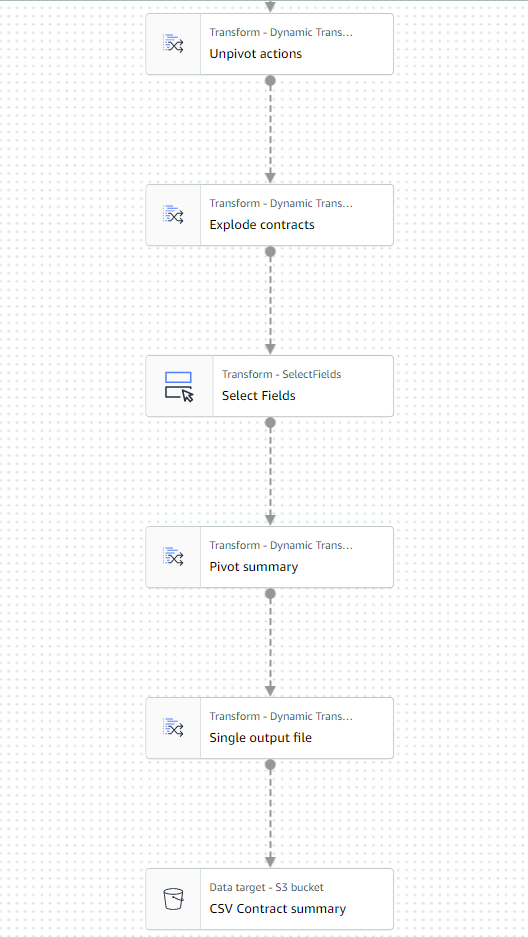
- Salva ed esegui il lavoro. Usa il Esegue scheda per verificare quando è terminato correttamente.
Troverai un file sotto quel percorso che è un CSV, nonostante non abbia quell'estensione. Probabilmente dovrai aggiungere l'estensione dopo averla scaricata per aprirla.
Su uno strumento in grado di leggere il CSV, il riepilogo dovrebbe essere simile all'esempio seguente.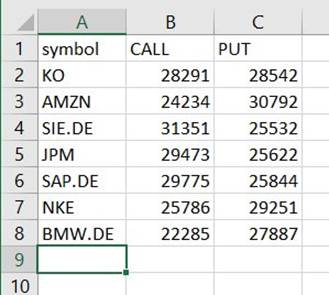
Pulisci le colonne temporanee
In preparazione al salvataggio degli ordini in una tabella storica per analisi future, puliamo alcune colonne temporanee create lungo il percorso.
- Aggiungere un Elimina campi nodo con il
Explode contractsnodo selezionato come genitore (stiamo ramificando la pipeline di dati per generare un output separato). - Seleziona i campi da eliminare:
instrument_arr,month,dayeyear.
Il resto vogliamo conservarlo in modo che venga salvato nella tabella storica che creeremo in seguito.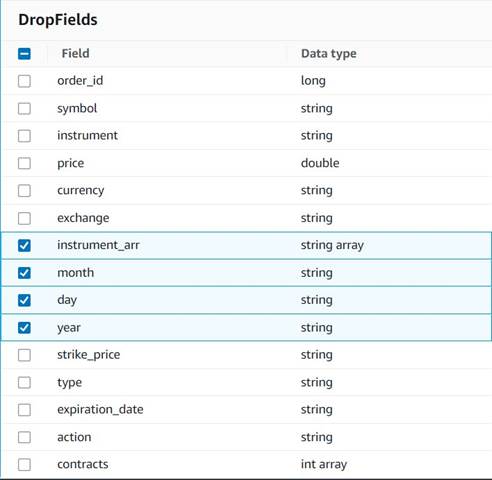
Standardizzazione valutaria
Questi dati sintetici contengono operazioni fittizie su due valute, ma in un sistema reale potresti ottenere valute dai mercati di tutto il mondo. È utile standardizzare le valute gestite in un'unica valuta di riferimento in modo che possano essere facilmente confrontate e aggregate per report e analisi.
Usiamo Amazzone Atena per simulare una tabella con conversioni valutarie approssimative che viene aggiornata periodicamente (qui presumiamo di elaborare gli ordini in modo sufficientemente tempestivo in modo che la conversione sia un rappresentante ragionevole ai fini del confronto).
- Apri la console Athena nella stessa regione in cui utilizzi AWS Glue.
- Esegui la query seguente per creare la tabella impostando una posizione S3 in cui i ruoli Athena e AWS Glue possono leggere e scrivere. Inoltre, potresti voler archiviare la tabella in un database diverso da
default(se lo fai, aggiorna il nome completo della tabella di conseguenza negli esempi forniti). - Inserisci alcune conversioni di esempio nella tabella:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - Ora dovresti essere in grado di visualizzare la tabella con la seguente query:
SELECT * FROM default.exchange_rates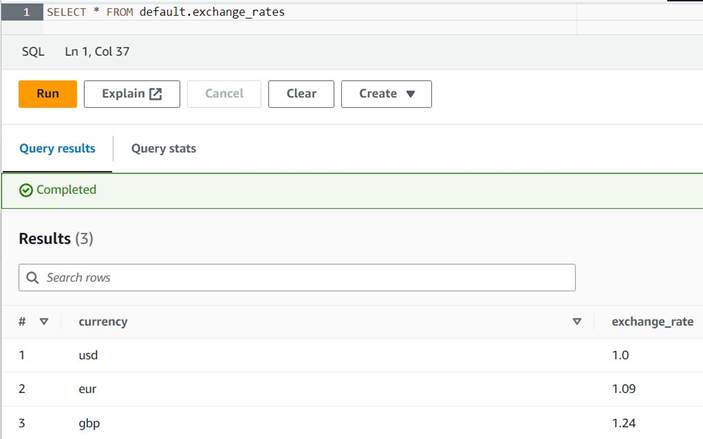
- Tornando al lavoro visivo di AWS Glue, aggiungi a Lookup nodo (come figlio di
Drop Fields) e nominaloExchange rate. - Inserisci il nome completo della tabella che hai appena creato, utilizzando
currencycome chiave e selezionare ilexchange_ratecampo da utilizzare.
Poiché il campo ha lo stesso nome sia nei dati che nella tabella di ricerca, possiamo semplicemente inserire il nomecurrencye non è necessario definire una mappatura.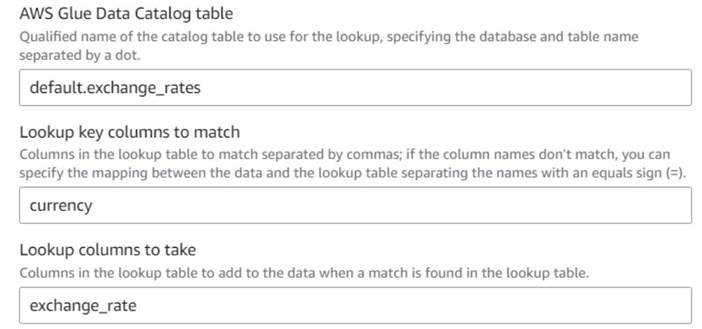
Al momento della stesura di questo documento, la trasformazione Lookup non è supportata nell'anteprima dei dati e mostrerà un errore che indica che la tabella non esiste. Questo è solo per l'anteprima dei dati e non impedisce l'esecuzione corretta del lavoro. I pochi passaggi rimanenti del post non richiedono l'aggiornamento dello schema. Se è necessario eseguire un'anteprima dei dati su altri nodi, è possibile rimuovere temporaneamente il nodo di ricerca e quindi ripristinarlo. - Aggiungere un Colonna derivata nodo e nominarlo
Total in usd. - Assegna un nome alla colonna derivata
total_usde utilizzare la seguente espressione SQL:round(contracts * price * exchange_rate, 2)
- Aggiungere un Aggiungi timestamp corrente nodo e assegna un nome alla colonna
ingest_date. - Usa il formato
%Y-%m-%dper il tuo timestamp (a scopo dimostrativo, stiamo solo usando la data; puoi renderla più precisa se vuoi).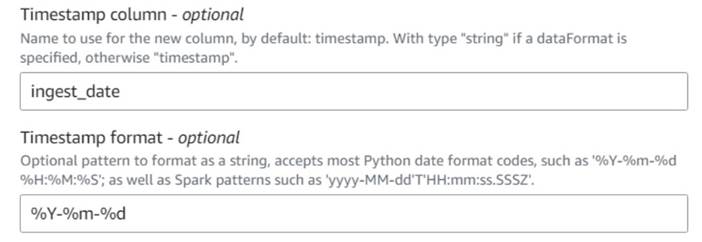
Salva la tabella degli ordini storici
Per salvare la tabella degli ordini storici, completare i seguenti passaggi:
- Aggiungi un nodo di destinazione S3 e assegnagli un nome
Orders table. - Configura il formato Parquet con la compressione scattante e fornisci un percorso di destinazione S3 in cui archiviare i risultati (separato dal riepilogo).
- Seleziona Creare una tabella nel Catalogo dati e nelle esecuzioni successive, aggiornare lo schema e aggiungere nuove partizioni.
- Immettere un database di destinazione e un nome per la nuova tabella, ad esempio:
option_orders.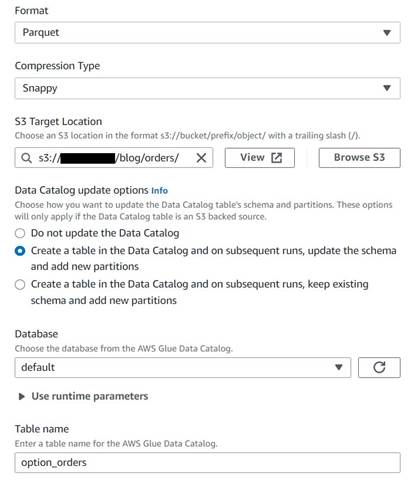
L'ultima parte del diagramma dovrebbe ora essere simile alla seguente, con due diramazioni per le due uscite separate.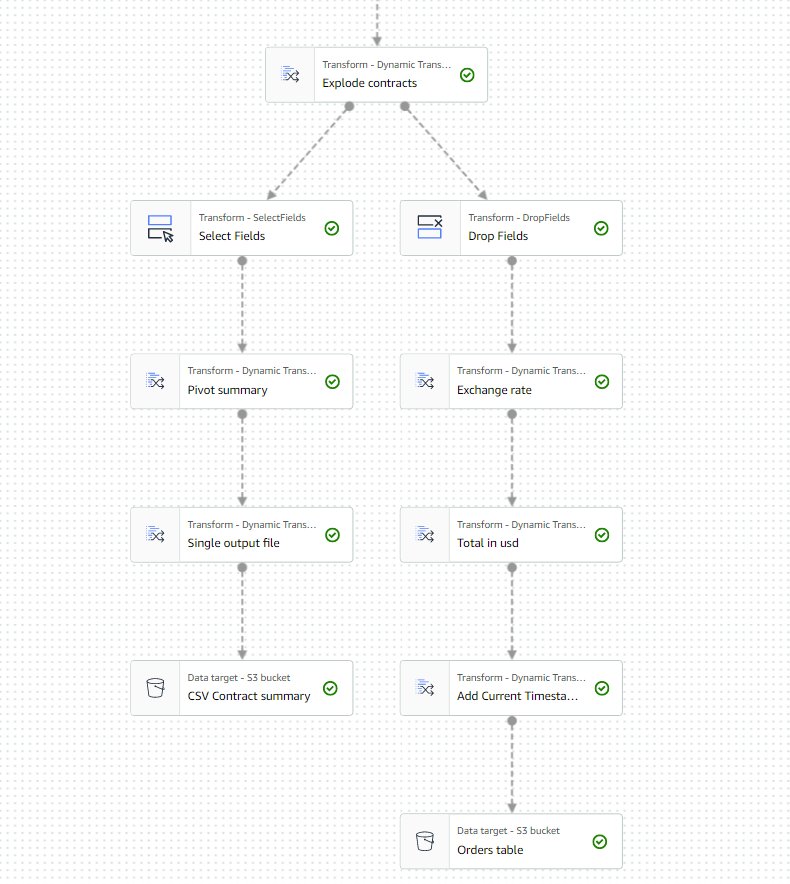
Dopo aver eseguito correttamente il lavoro, puoi utilizzare uno strumento come Athena per rivedere i dati prodotti dal lavoro interrogando la nuova tabella. Puoi trovare il tavolo nell'elenco Athena e scegliere Anteprima tabella o esegui semplicemente una query SELECT (aggiornando il nome della tabella con il nome e il catalogo che hai utilizzato):
SELECT * FROM default.option_orders limit 10
Il contenuto della tua tabella dovrebbe essere simile allo screenshot seguente.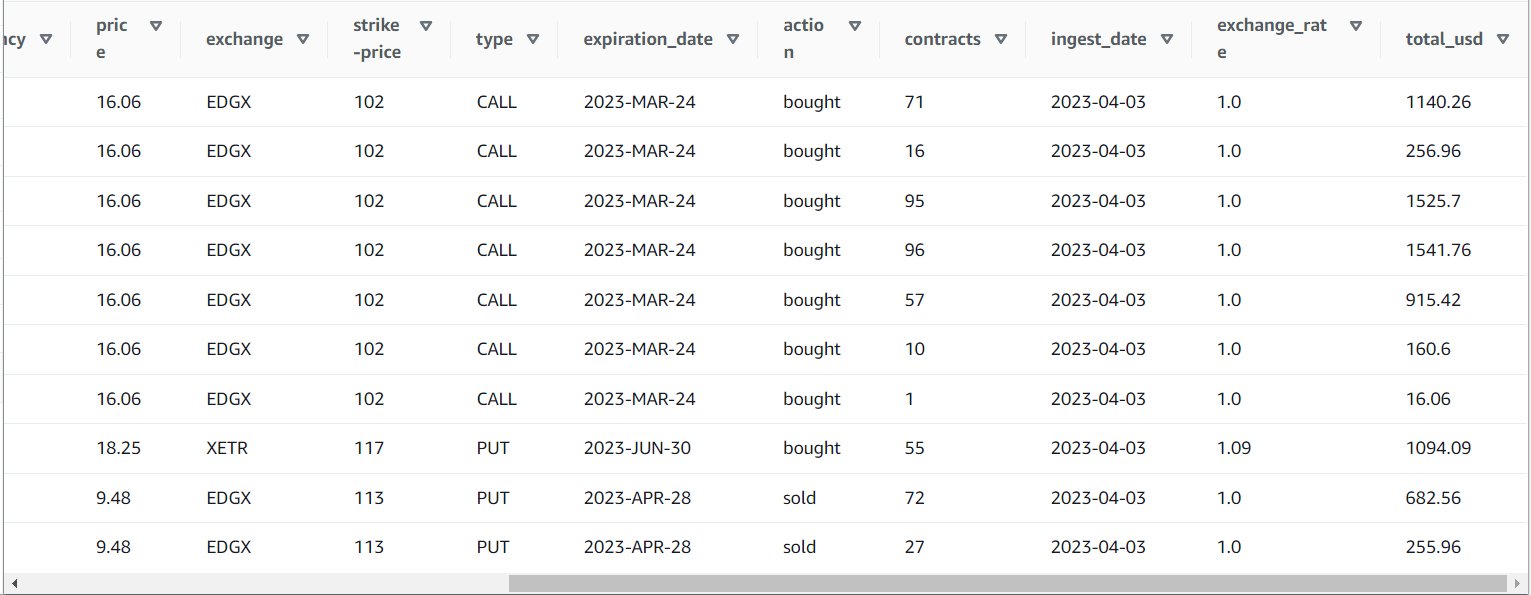
ripulire
Se non vuoi conservare questo esempio, elimina i due processi che hai creato, le due tabelle in Athena e i percorsi S3 in cui sono stati archiviati i file di input e output.
Conclusione
In questo post, abbiamo mostrato come le nuove trasformazioni in AWS Glue Studio possono aiutarti a eseguire trasformazioni più avanzate con una configurazione minima. Ciò significa che puoi implementare più casi d'uso ETL senza dover scrivere e mantenere alcun codice. Le nuove trasformazioni sono già disponibili su AWS Glue Studio, quindi puoi utilizzarle oggi stesso nei tuoi lavori visivi.
Circa l'autore
![]() Gonzalo herreros è un Senior Big Data Architect nel team di AWS Glue.
Gonzalo herreros è un Senior Big Data Architect nel team di AWS Glue.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoAiStream. Intelligenza dei dati Web3. Conoscenza amplificata. Accedi qui.
- Coniare il futuro con Adryenn Ashley. Accedi qui.
- Acquista e vendi azioni in società PRE-IPO con PREIPO®. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- :ha
- :È
- :non
- :Dove
- $ SU
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 15%
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- capace
- Chi siamo
- accettabile
- accesso
- di conseguenza
- aggiungere
- aggiunto
- l'aggiunta di
- Avanzate
- Dopo shavasana, sedersi in silenzio; saluti;
- Tutti
- allocato
- allocazioni
- consentire
- consente
- lungo
- già
- anche
- sempre
- Amazon
- quantità
- importi
- an
- .
- analizzare
- ed
- Un altro
- in qualsiasi
- applicato
- approssimativo
- aprile
- SONO
- argomento
- Italia
- AS
- addetto
- At
- gli attributi
- automaticamente
- disponibile
- AWS
- Colla AWS
- precedente
- basato
- BE
- prima
- essendo
- Big
- Big Data
- vuoto
- BMW
- entrambi
- comprato
- rami
- costruire
- affari
- ma
- Acquistare
- by
- chiamata
- Materiale
- Custodie
- casi
- catalogo
- centro
- Secolo
- Modifiche
- caratteristiche
- dai un'occhiata
- bambino
- Scegli
- la scelta
- più chiaro
- codice
- codifica
- Colonna
- colonne
- Uncommon
- rispetto
- confronto
- completamento di una
- Completato
- Configurazione
- consolle
- consolidare
- contiene
- contenuto
- contratto
- contratti
- comodità
- Conversione
- conversioni
- convertire
- convertito
- SOCIETÀ
- potuto
- creare
- creato
- Creazione
- valute
- Valuta
- Corrente
- GIORNO
- dati
- Banca Dati
- Data
- Date
- datetime
- giorno
- affare
- trattare
- decide
- Predefinito
- definito
- dimostrato
- Dipendenza
- derivato
- Nonostante
- dettagli
- diverso
- cifre
- discutere
- do
- non
- fare
- dollari
- Dont
- doppio
- giù
- Cadere
- caduto
- ogni
- più facile
- facilmente
- facile
- editore
- enable
- abbastanza
- entrare
- Ambiente
- errore
- Etere (ETH)
- EUR
- esempio
- Esempi
- Tranne
- exchange
- Cambi Merce
- Exclusive
- esistere
- Espandere
- previsto
- esperimento
- scadenza
- espresso
- estensione
- esterno
- extra
- estratto
- lontano
- paura
- pochi
- immaginario
- campo
- campi
- Compila il
- File
- riempire
- pieno
- finanziario
- Strumenti finanziari
- Trovare
- Nome
- fisso
- flessibile
- seguire
- i seguenti
- segue
- Nel
- formato
- essere trovato
- da
- futuro
- GBP
- Generale
- generalmente
- generare
- generato
- ottenere
- Dare
- dà
- Go
- grafico
- Avidità
- Manovrabilità
- accade
- Avere
- avendo
- Aiuto
- qui
- storico
- storia
- Come
- Tutorial
- HTML
- http
- HTTPS
- Gli esseri umani
- i
- identifica
- identificare
- if
- Impact
- realizzare
- importare
- in
- indici
- indicato
- indica
- indicando
- indicazione
- individuale
- informazioni
- ingresso
- esempio
- invece
- istruzioni
- strumento
- strumenti
- interesse
- Interfaccia
- ai miglioramenti
- ISO
- IT
- SUO
- Lavoro
- Offerte di lavoro
- jpg
- json
- ad appena
- mantenere
- Le
- Genere
- Cognome
- dopo
- piace
- LIMITE
- linea
- Liquidità
- Lista
- caricare
- località
- più a lungo
- Guarda
- una
- SEMBRA
- ricerca
- perdere
- a
- fatto
- mantenere
- make
- FA
- manualmente
- carta geografica
- mappatura
- Rappresentanza
- sentimento del mercato
- Mercati
- Maggio..
- si intende
- Unire
- messaggio
- forza
- ordine
- mancante
- modello
- Monitorare
- Scopri di più
- maggior parte
- multiplo
- reciprocamente
- Nome
- Detto
- nomi
- Bisogno
- esigenze
- New
- no
- nodo
- nodi
- normalmente
- adesso
- numero
- numeri
- oggetto
- of
- di frequente
- on
- ONE
- esclusivamente
- aprire
- operazione
- Operazioni
- OTTIMIZZA
- Opzione
- Opzioni
- or
- minimo
- ordini
- i
- Altro
- altrimenti
- produzione
- ancora
- complessivo
- Override
- proprio
- pagato
- vetro
- parametro
- parte
- sentiero
- Scelte
- conduttura
- Perno
- posto
- Platone
- Platone Data Intelligence
- PlatoneDati
- Post
- potenziale
- Pratico
- bisogno
- prevenire
- Anteprima
- prezzo
- probabilmente
- processi
- lavorazione
- produrre
- Prodotto
- fornire
- purché
- fornisce
- Acquista
- scopo
- fini
- metti
- Python
- qualificato
- aumentare
- casuale
- Leggi
- di rose
- ragionevole
- ridurre
- riflettere
- regione
- rimanente
- rimuovere
- replicato
- Reportistica
- rappresentare
- rappresentante
- che rappresenta
- rappresenta
- richiedere
- Requisiti
- richiede
- rispettivamente
- REST
- risultante
- Risultati
- recensioni
- Ruolo
- ruoli
- RIGA
- Correre
- running
- più sicuro
- stesso
- linfa
- Risparmi
- risparmio
- scorrere
- secondo
- selezionato
- Selezione
- venda
- anziano
- sentimento
- separato
- Sessione
- Set
- regolazione
- azioni
- Conchiglia
- dovrebbero
- mostrare attraverso le sue creazioni
- Spettacoli
- simile
- Un'espansione
- singolo
- Taglia
- abilità
- piccole
- So
- finora
- venduto
- alcuni
- qualcosa
- Fonte
- lo spazio
- spazi
- specifico
- specificato
- dividere
- Foglio di calcolo
- SQL
- inizia a
- Passi
- Ancora
- azione
- conservazione
- Tornare al suo account
- memorizzati
- Corda
- studio
- successivo
- Con successo
- adatto
- SOMMARIO
- supportato
- simbolo
- sintetico
- dati sintetici
- sinteticamente
- sistema
- SISTEMI DI TRATTAMENTO
- tavolo
- Fai
- Target
- team
- dire
- temporaneo
- carnagione
- test
- di
- che
- I
- Il grafo
- le informazioni
- il mondo
- Li
- poi
- perciò
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- quelli
- tempo
- volte
- timestamp
- a
- oggi
- token
- tokenize
- ha preso
- Totale
- commercio
- negoziate
- Trasformare
- Trasformazione
- trasformazioni
- trasformato
- seconda
- Digitare
- per
- sottostante
- capire
- unico
- fino a quando
- Aggiornanento
- aggiornato
- aggiornamento
- URL
- us
- US Dollars
- USD
- uso
- caso d'uso
- utilizzato
- Utente
- utenti
- utilizzando
- Prezioso
- Informazione preziosa
- APPREZZIAMO
- Valori
- LOCATION
- verificato
- verificare
- Visualizza
- visibile
- volume
- vs
- aspettare
- volere
- Prima
- Modo..
- we
- sono stati
- Che
- quando
- quale
- while
- volere
- con
- senza
- flussi di lavoro
- lavoro
- mondo
- sarebbe
- scrivere
- scrittura
- anno
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro











