
Immagine creata con DALL-E3
L’intelligenza artificiale ha rappresentato una rivoluzione completa nel mondo della tecnologia.
La sua capacità di imitare l’intelligenza umana e di svolgere compiti che un tempo erano considerati esclusivamente di dominio umano stupisce ancora la maggior parte di noi.
Tuttavia, non importa quanto siano stati positivi questi ultimi balzi in avanti dell’IA, c’è sempre spazio per miglioramenti.
Ed è proprio qui che entra in gioco la pronta ingegneria!
Entra in questo campo che può migliorare significativamente la produttività dei modelli di intelligenza artificiale.
Scopriamolo tutto insieme!
Il prompt engineering è un settore in rapida crescita all’interno dell’intelligenza artificiale che si concentra sul miglioramento dell’efficienza e dell’efficacia dei modelli linguistici. Si tratta di creare suggerimenti perfetti per guidare i modelli di intelligenza artificiale a produrre i risultati desiderati.
Consideralo come imparare a dare istruzioni migliori a qualcuno per assicurarti che comprenda ed esegua correttamente un'attività.
Perché l'ingegneria rapida è importante
- Produttività migliorata: Utilizzando suggerimenti di alta qualità, i modelli di intelligenza artificiale possono generare risposte più accurate e pertinenti. Ciò significa meno tempo dedicato alle correzioni e più tempo a sfruttare le capacità dell’intelligenza artificiale.
- Efficienza dei costi: L’addestramento dei modelli di intelligenza artificiale richiede molte risorse. Il prompt engineering può ridurre la necessità di riqualificazione ottimizzando le prestazioni del modello attraverso prompt migliori.
- Versatilità: Un suggerimento ben realizzato può rendere i modelli di intelligenza artificiale più versatili, consentendo loro di affrontare una gamma più ampia di compiti e sfide.
Prima di addentrarci nelle tecniche più avanzate, ricordiamo due delle tecniche di prompt engineering più utili (e basilari).
Pensiero Sequenziale con “Pensiamo passo dopo passo”
Oggi è noto che la precisione dei modelli LLM migliora notevolmente quando si aggiunge la sequenza di parole “Pensiamo passo dopo passo”.
Perché... potresti chiedere?
Bene, questo perché stiamo forzando il modello a suddividere qualsiasi attività in più passaggi, assicurandoci così che il modello abbia tempo sufficiente per elaborarli ciascuno.
Ad esempio, potrei sfidare GPT3.5 con il seguente messaggio:
Se Giovanni ha 5 pere, poi ne mangia 2, ne compra altre 5, poi ne dà 3 al suo amico, quante pere ha?
La modella mi darà subito una risposta. Tuttavia, se aggiungo la frase finale “Pensiamo passo dopo passo”, forzo il modello a generare un processo di pensiero con più passaggi.
Richiesta di pochi colpi
Mentre il suggerimento Zero-shot si riferisce al chiedere al modello di eseguire un'attività senza fornire alcun contesto o conoscenza precedente, la tecnica di suggerimento pochi-shot implica che presentiamo al LLM alcuni esempi dell'output desiderato insieme ad alcune domande specifiche.
Ad esempio, se vogliamo elaborare un modello che definisca qualsiasi termine utilizzando un tono poetico, potrebbe essere piuttosto difficile da spiegare. Giusto?
Tuttavia, potremmo utilizzare i seguenti suggerimenti per dirigere il modello nella direzione desiderata.
Il tuo compito è rispondere in uno stile coerente in linea con lo stile seguente.
: Insegnami la resilienza.
: La resilienza è come un albero che si piega al vento ma non si spezza mai.
È la capacità di riprendersi dalle avversità e andare avanti.
: Il tuo contributo qui.
Se non l'hai ancora provato, puoi sfidare GPT.
Tuttavia, poiché sono abbastanza sicuro che molti di voi conoscano già queste tecniche di base, cercherò di sfidarvi con alcune tecniche avanzate.
1. Promuovere la catena di pensiero (CoT).
Presentato da Google nel 2022, questo metodo prevede di istruire il modello a sottoporsi a diverse fasi di ragionamento prima di fornire la risposta definitiva.
Sembra familiare, vero? Se è così, hai assolutamente ragione.
È come fondere il pensiero sequenziale e il suggerimento a colpi brevi.
Come?
In sostanza, la richiesta CoT indirizza il LLM a elaborare le informazioni in sequenza. Ciò significa che esemplifichiamo come risolvere un primo problema con un ragionamento in più passaggi e quindi inviamo al modello il nostro compito reale, aspettandoci che emuli una catena di pensiero comparabile quando risponde alla domanda effettiva che vogliamo che risolva.
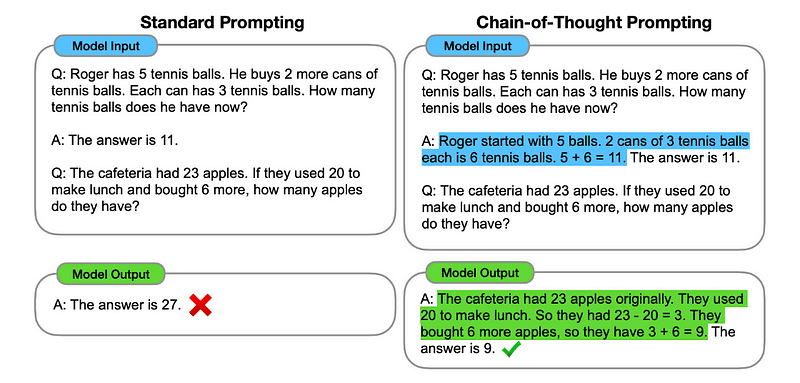
Immagine tratta da carta.
Quindi, seguendo il primo esempio, potremmo fornire un suggerimento con il primo problema e una spiegazione sequenziale di come risolverlo. Quindi, possiamo inviare il nostro contributo e vedere come avviene la magia!
Se Giovanni ha 5 pere, poi ne mangia 2, ne compra altre 5, poi ne dà 3 al suo amico, quante pere ha? Pensiamo passo dopo passo.
Andiamo per gradi. John inizia con 5 pere. Mangia 2 pere, quindi gli restano 5–2 = 3 pere. Poi compra altre 5 pere. Quindi ora ha 3 + 5 = 8 pere. Infine regala 3 pere al suo amico. Pertanto gli restano 8–3 = 5 pere. Quindi, dopo tutti questi passaggi, Giovanni ha 5 pere.
Il tuo contributo qui.
Tuttavia, la maggior parte di voi starà pensando... Devo pensare a un modo sequenziale per risolvere qualsiasi problema ogni volta che voglio chiedere qualcosa su ChatGPT?
Beh... non sei il primo! E questo ci porta a…
2. Catena di pensiero automatica (Auto-CoT)
Nel 2022, Zhang e colleghi hanno introdotto un metodo per evitare questo processo manuale. Esistono due ragioni principali per evitare qualsiasi attività manuale:
- Può essere noioso.
- Può produrre risultati negativi, ad esempio quando il nostro processo mentale è sbagliato.
Hanno suggerito di utilizzare LLM combinati con il suggerimento “Pensiamo passo dopo passo” per produrre in sequenza catene di ragionamento per ciascuna dimostrazione.
Ciò significa chiedere a ChatGPT come risolvere qualsiasi problema in sequenza e quindi utilizzare lo stesso esempio per addestrarlo a risolvere qualsiasi altro problema.
3. Autocoerenza
L’autocoerenza è un’altra interessante tecnica di suggerimento che mira a migliorare la catena di pensiero che suggerisce problemi di ragionamento più complessi.
Quindi... qual è la differenza principale?
L'idea principale di Self-Consistency è essere consapevoli che possiamo addestrare il modello con un esempio sbagliato. Immagina di risolvere il problema precedente con un processo mentale sbagliato:
Se Giovanni ha 5 pere, poi ne mangia 2, ne compra altre 5, poi ne dà 3 al suo amico, quante pere ha? Pensiamo passo dopo passo.
Inizia con 5 pere. John mangia 2 pere. Poi dà 3 pere al suo amico. Queste azioni possono essere combinate: 2 (mangiate) + 3 (date) = 5 pere in totale colpite. Ora sottrai il totale delle pere interessate dalle 5 pere iniziali: 5 (iniziali) – 5 (interessate) = 0 pere rimaste.
Quindi, qualsiasi altra attività che invio al modello risulterà errata.
Questo è il motivo per cui la Self-Consistency prevede il campionamento da vari percorsi di ragionamento, ciascuno contenente una catena di pensiero, e quindi lasciare che il LLM scelga il percorso migliore e più coerente per risolvere il problema.
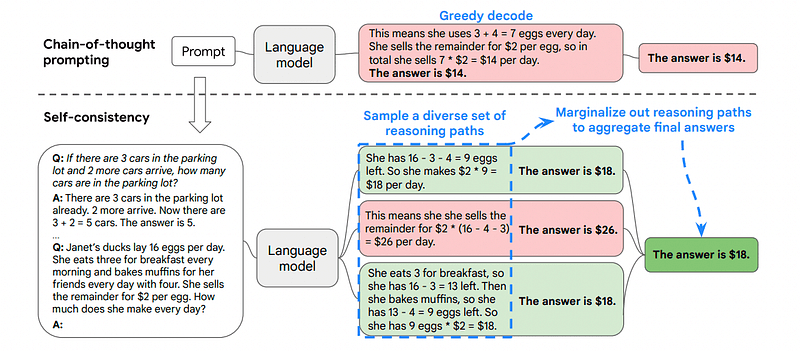
Immagine tratta da carta
In questo caso, e seguendo nuovamente il primo esempio, possiamo mostrare al modello diversi modi di risolvere il problema.
Se Giovanni ha 5 pere, poi ne mangia 2, ne compra altre 5, poi ne dà 3 al suo amico, quante pere ha?
Inizia con 5 pere. Giovanni mangia 2 pere, rimanendo con 5–2 = 3 pere. Acquista altre 5 pere, il che porta il totale a 3 + 5 = 8 pere. Alla fine dà 3 pere al suo amico, quindi gli restano 8–3 = 5 pere.
Se Giovanni ha 5 pere, poi ne mangia 2, ne compra altre 5, poi ne dà 3 al suo amico, quante pere ha?
Inizia con 5 pere. Poi compra altre 5 pere. John mangia 2 pere adesso. Queste azioni possono essere combinate: 2 (mangiate) + 5 (comprate) = 7 pere in totale. Sottrai la pera che Jon ha mangiato dalla quantità totale di pere 7 (importo totale) – 2 (mangiata) = 5 pere rimaste.
Il tuo contributo qui.
Ed ecco che arriva l'ultima tecnica.
4. Suggerimenti di conoscenze generali
Una pratica comune di prompt engineering è quella di arricchire una query con conoscenze aggiuntive prima di inviare la chiamata API finale a GPT-3 o GPT-4.
Secondo Jiacheng Liu e Co, possiamo sempre aggiungere alcune conoscenze a qualsiasi richiesta in modo che il LLM conosca meglio la domanda.
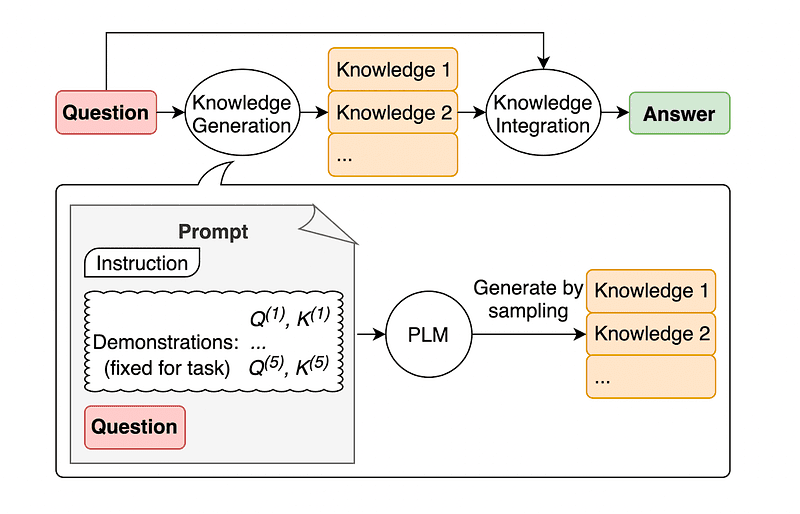
Immagine tratta da carta.
Quindi, ad esempio, quando chiediamo a ChatGPT se una parte del golf sta cercando di ottenere un punteggio totale più alto rispetto ad altri, ci confermerà. Ma l’obiettivo principale del golf è esattamente l’opposto. Per questo motivo possiamo aggiungere qualche conoscenza precedente dicendo “Vince il giocatore con il punteggio più basso”.

Quindi... qual è la parte divertente se stiamo dicendo al modello esattamente la risposta?
In questo caso, questa tecnica viene utilizzata per migliorare il modo in cui LLM interagisce con noi.
Quindi, invece di estrarre contesto supplementare da un database esterno, gli autori dell’articolo raccomandano che il LLM produca la propria conoscenza. Questa conoscenza autogenerata viene quindi integrata nel prompt per rafforzare il ragionamento basato sul buon senso e fornire risultati migliori.
Ecco quindi come è possibile migliorare i LLM senza aumentare il set di dati di formazione!
L'ingegneria rapida è emersa come una tecnica fondamentale per migliorare le capacità di LLM. Iterando e migliorando i prompt, possiamo comunicare in modo più diretto con i modelli di intelligenza artificiale e ottenere così risultati più accurati e contestualmente rilevanti, risparmiando tempo e risorse.
Per gli appassionati di tecnologia, i data scientist e i creatori di contenuti, comprendere e padroneggiare il prompt engineering può essere una risorsa preziosa per sfruttare tutto il potenziale dell’intelligenza artificiale.
Combinando prompt di input attentamente progettati con queste tecniche più avanzate, possedere le competenze di prompt engineering ti darà senza dubbio un vantaggio nei prossimi anni.
Giuseppe Ferrer è un ingegnere analitico di Barcellona. Laureato in ingegneria fisica, attualmente lavora nel campo della Data Science applicata alla mobilità umana. È un creatore di contenuti part-time focalizzato sulla scienza e la tecnologia dei dati. Puoi contattarlo su LinkedIn, Twitter or Medio.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.kdnuggets.com/some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models?utm_source=rss&utm_medium=rss&utm_campaign=some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models
- :ha
- :È
- :non
- :Dove
- $ SU
- 10
- 11
- 2022
- 29
- 7
- 8
- a
- capacità
- WRI
- precisione
- preciso
- azioni
- presenti
- aggiungere
- l'aggiunta di
- aggiuntivo
- Avanzate
- Dopo shavasana, sedersi in silenzio; saluti;
- ancora
- AI
- Modelli AI
- mira
- Allineati
- nello stesso modo
- Tutti
- Consentire
- lungo
- già
- sempre
- am
- quantità
- an
- analitica
- ed
- Un altro
- rispondere
- in qualsiasi
- api
- applicato
- SONO
- AS
- chiedere
- chiedendo
- attività
- gli autori
- Automatico
- evitare
- consapevole
- lontano
- precedente
- Vasca
- Barcellona
- basic
- BE
- perché
- stato
- prima
- essendo
- MIGLIORE
- Meglio
- sostenere
- Incremento
- Noioso
- entrambi
- comprato
- Rimbalzo
- Rompere
- pause
- Porta
- più ampia
- ma
- Acquista
- by
- chiamata
- Materiale
- funzionalità
- attentamente
- Custodie
- catena
- Catene
- Challenge
- sfide
- ChatGPT
- Scegli
- colleghi
- combinato
- combinando
- Venire
- viene
- arrivo
- Uncommon
- comunicare
- paragonabile
- completamento di una
- complesso
- considerato
- coerente
- contatti
- contenuto
- creatori di contenuti
- contesto
- Correzioni
- correttamente
- potuto
- creato
- Creatore
- creatori
- Attualmente
- dati
- scienza dei dati
- Banca Dati
- definisce
- consegna
- progettato
- desiderato
- differenza
- diverso
- dirette
- direzione
- scopri
- immersione
- do
- effettua
- dominio
- domini
- giù
- ogni
- bordo
- efficacia
- efficienza
- emerse
- ingegnere
- Ingegneria
- accrescere
- migliorando
- abbastanza
- garantire
- gli appassionati
- di preciso
- esempio
- Esempi
- eseguire
- aspetta
- Spiegare
- spiegazione
- familiare
- pochi
- campo
- finale
- Infine
- Nome
- concentrato
- si concentra
- i seguenti
- Nel
- forzatura
- Avanti
- Amico
- da
- pieno
- divertente
- Generale
- generare
- ottenere
- Dare
- dato
- dà
- Go
- scopo
- golf
- buono
- guida
- Hard
- Sfruttamento
- Avere
- avendo
- he
- qui
- alta qualità
- superiore
- lui
- il suo
- Come
- Tutorial
- Tuttavia
- HTTPS
- umano
- intelligenza umana
- i
- idea
- if
- immagine
- competenze
- migliorata
- miglioramento
- miglioramento
- in
- crescente
- informazioni
- inizialmente
- ingresso
- esempio
- istruzioni
- integrato
- Intelligence
- interagisce
- interessante
- ai miglioramenti
- introdotto
- comporta
- IT
- SUO
- John
- jon
- ad appena
- KDnuggets
- mantenere
- calcio
- Kicks
- Sapere
- conoscenze
- conosce
- Lingua
- Cognome
- In ritardo
- Leads
- Salto
- apprendimento
- partenza
- a sinistra
- meno
- lasciare
- locazione
- leveraging
- piace
- inferiore
- magia
- Principale
- make
- Fare
- modo
- Manuale
- molti
- La padronanza della
- Importanza
- me
- si intende
- mentale
- fusione
- metodo
- forza
- mobilità
- modello
- modelli
- Scopri di più
- maggior parte
- in movimento
- multiplo
- devono obbligatoriamente:
- Bisogno
- mai
- no
- adesso
- ottenere
- of
- on
- una volta
- di fronte
- ottimizzazione
- or
- Altro
- Altri
- nostro
- su
- produzione
- uscite
- al di fuori
- proprio
- Carta
- parte
- sentiero
- perfetta
- eseguire
- performance
- Fisica
- centrale
- Platone
- Platone Data Intelligence
- PlatoneDati
- giocatore
- punto
- potenziale
- pratica
- precisamente
- presenti
- piuttosto
- precedente
- Problema
- problemi
- processi
- produrre
- della produttività
- fornire
- fornitura
- traino
- domanda
- abbastanza
- gamma
- piuttosto
- di rose
- motivi
- raccomandare
- ridurre
- si riferisce
- pertinente
- richiesta
- elasticità
- risorsa intensiva
- Risorse
- risponde
- risposta
- risposte
- Risultati
- riqualificazione
- Rivoluzione
- destra
- Prenotazione sale
- s
- stesso
- risparmio
- Scienze
- Scienza e Tecnologia
- scienziati
- Punto
- vedere
- inviare
- invio
- Sequenza
- set
- alcuni
- mostrare attraverso le sue creazioni
- significativamente
- abilità
- So
- unicamente
- RISOLVERE
- Soluzione
- alcuni
- Qualcuno
- qualcosa
- specifico
- esaurito
- tappe
- inizia a
- inizio
- guidare
- step
- Passi
- Ancora
- style
- sicuro
- attrezzatura
- preso
- Task
- task
- Tech
- per l'esame
- tecniche
- Tecnologia
- raccontare
- termine
- di
- che
- Il
- Li
- poi
- Là.
- perciò
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- think
- Pensiero
- questo
- pensiero
- Attraverso
- così
- tempo
- a
- TONE
- Totale
- COMPLETAMENTE
- Treni
- Training
- albero
- provato
- prova
- cerca
- seconda
- ultimo
- per
- subire
- capire
- e una comprensione reciproca
- indubbiamente
- us
- uso
- utilizzato
- utilizzando
- CONVALIDARE
- Prezioso
- vario
- versatile
- molto
- volere
- Modo..
- modi
- we
- noto
- sono stati
- quando
- quale
- perché
- volere
- vento
- con
- entro
- senza
- Word
- lavoro
- mondo
- Wrong
- anni
- ancora
- dare la precedenza
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro







