Questo post è stato scritto in collaborazione con Preshen Goobiah e Johan Olivier di Capitec.
Apache Spark è un sistema di elaborazione distribuita open source ampiamente utilizzato, rinomato per la gestione di carichi di lavoro di dati su larga scala. Trova applicazione frequente tra gli sviluppatori Spark che lavorano con Amazon EMR, Amazon Sage Maker, Colla AWS e applicazioni Spark personalizzate.
Amazon RedShift offre un'integrazione perfetta con Apache Spark, consentendoti di accedere facilmente ai tuoi dati Redshift sia sui cluster forniti da Amazon Redshift che Amazon Redshift senza server. Questa integrazione espande le possibilità delle soluzioni di analisi e machine learning (ML) di AWS, rendendo il data warehouse accessibile a una gamma più ampia di applicazioni.
Grazie alla Integrazione di Amazon Redshift per Apache Spark, puoi iniziare rapidamente e sviluppare facilmente applicazioni Spark utilizzando linguaggi diffusi come Java, Scala, Python, SQL e R. Le tue applicazioni possono leggere e scrivere senza problemi nel tuo data warehouse Amazon Redshift mantenendo prestazioni ottimali e coerenza transazionale. Inoltre, trarrai vantaggio dai miglioramenti delle prestazioni attraverso le ottimizzazioni pushdown, migliorando ulteriormente l'efficienza delle tue operazioni.
Capitec, la più grande banca al dettaglio del Sud Africa con oltre 21 milioni di clienti bancari al dettaglio, mira a fornire servizi finanziari semplici, convenienti e accessibili per aiutare i sudafricani ad operare meglio in modo che possano vivere meglio. In questo post, discutiamo della riuscita integrazione del connettore open source Amazon Redshift da parte del team Feature Platform dei servizi condivisi di Capitec. Come risultato dell'utilizzo dell'integrazione Amazon Redshift per Apache Spark, la produttività degli sviluppatori è aumentata di un fattore 10, le pipeline di generazione di funzionalità sono state semplificate e la duplicazione dei dati ridotta a zero.
L'opportunità commerciale
Sono disponibili 19 modelli predittivi per l'utilizzo di 93 funzionalità realizzate con AWS Glue nelle divisioni Credito al dettaglio di Capitec. I record delle funzionalità vengono arricchiti con fatti e dimensioni archiviati in Amazon Redshift. Apache PySpark è stato selezionato per creare funzionalità perché offre un meccanismo veloce, decentralizzato e scalabile per gestire i dati provenienti da diverse fonti.
Queste funzionalità di produzione svolgono un ruolo cruciale nel consentire richieste di prestiti a tempo determinato in tempo reale, richieste di carte di credito, monitoraggio batch del comportamento del credito mensile e identificazione batch di salari giornalieri all'interno dell'azienda.
Il problema della provenienza dei dati
Per garantire l'affidabilità delle pipeline di dati PySpark, è essenziale disporre di dati coerenti a livello di record provenienti da tabelle dimensionali e fattuali archiviate nell'Enterprise Data Warehouse (EDW). Queste tabelle vengono quindi unite alle tabelle dell'Enterprise Data Lake (EDL) in fase di esecuzione.
Durante lo sviluppo delle funzionalità, gli ingegneri dei dati necessitano di un'interfaccia continua con EDW. Questa interfaccia consente loro di accedere e integrare i dati necessari dall'EDW nelle pipeline di dati, consentendo uno sviluppo e un test efficienti delle funzionalità.
Processo di soluzione precedente
Nella soluzione precedente, i data engineer del team di prodotto impiegavano 30 minuti per esecuzione per esporre manualmente i dati Redshift a Spark. I passaggi includevano quanto segue:
- Costruisci una query con predicato in Python.
- Invia un SCARICARE interrogare tramite il API dati Amazon Redshift.
- Cataloga i dati nel catalogo dati di AWS Glue tramite l'SDK AWS per Panda utilizzando il campionamento.
Questo approccio poneva problemi per set di dati di grandi dimensioni, richiedeva una manutenzione ricorrente da parte del team della piattaforma ed era complesso da automatizzare.
Panoramica della soluzione attuale
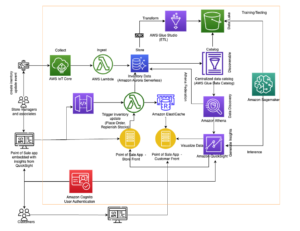
Capitec è stata in grado di risolvere questi problemi con l'integrazione di Amazon Redshift per Apache Spark all'interno delle pipeline di generazione di funzionalità. L'architettura è definita nel diagramma seguente.

Il flusso di lavoro include i seguenti passaggi:
- Le librerie interne vengono installate nel processo AWS Glue PySpark tramite Codice AWS Artefatto.
- Un lavoro AWS Glue recupera le credenziali del cluster Redshift da AWS Secrets Manager e configura la connessione Amazon Redshift (inserisce credenziali del cluster, posizioni di scarico, formati di file) tramite la libreria interna condivisa. Anche l'integrazione Amazon Redshift per Apache Spark supporta l'utilizzo Gestione dell'identità e dell'accesso di AWS (IAM) a recuperare le credenziali e connettersi ad Amazon Redshift.
- La query Spark viene tradotta in una query ottimizzata per Amazon Redshift e inviata all'EDW. Ciò è possibile grazie all'integrazione di Amazon Redshift per Apache Spark.
- Il set di dati EDW viene scaricato in un prefisso temporaneo in un file Servizio di archiviazione semplice Amazon (Amazon S3) secchio.
- Il set di dati EDW dal bucket S3 viene caricato negli esecutori Spark tramite l'integrazione Amazon Redshift per Apache Spark.
- Il set di dati EDL viene caricato negli esecutori Spark tramite il catalogo dati di AWS Glue.
Questi componenti lavorano insieme per garantire che gli ingegneri dei dati e le pipeline dei dati di produzione dispongano degli strumenti necessari per implementare l'integrazione di Amazon Redshift per Apache Spark, eseguire query e facilitare lo scaricamento dei dati da Amazon Redshift all'EDL.
Utilizzo dell'integrazione Amazon Redshift per Apache Spark in AWS Glue 4.0
In questa sezione dimostriamo l'utilità dell'integrazione Amazon Redshift per Apache Spark arricchendo una tabella di richiesta di prestito residente nel data Lake S3 con le informazioni sui clienti provenienti dal data warehouse Redshift in PySpark.
Il dimclient La tabella in Amazon Redshift contiene le seguenti colonne:
- ChiaveCliente –INT8
- ClientAltKey – VARCHAR50
- Numero identificativo della parte – VARCHAR20
- ClientCreateDate - DATA
- È annullato –INT2
- RowIsCurrent –INT2
Il loanapplication La tabella nel Catalogo dati di AWS Glue contiene le seguenti colonne:
- ID record – GRANDE
- LogDate – TIMESTAMP
- Numero identificativo della parte - CORDA
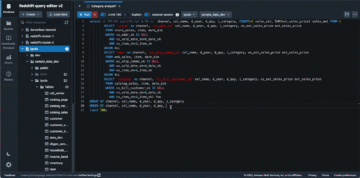
La tabella Redshift viene letta tramite l'integrazione Amazon Redshift per Apache Spark e memorizzata nella cache. Vedere il seguente codice:
I record delle richieste di prestito vengono letti dal data Lake S3 e arricchiti con il file dimclient tabella sulle informazioni di Amazon Redshift:
Di conseguenza, il record della richiesta di prestito (dal data Lake S3) si arricchisce del file ClientCreateDate colonna (da Amazon Redshift).

In che modo l'integrazione di Amazon Redshift per Apache Spark risolve il problema dell'approvvigionamento dei dati
L'integrazione di Amazon Redshift per Apache Spark risolve in modo efficace il problema dell'approvvigionamento dei dati attraverso i seguenti meccanismi:
- Lettura just-in-time – L'integrazione Amazon Redshift per il connettore Apache Spark legge le tabelle Redshift in modo just-in-time, garantendo la coerenza dei dati e dello schema. Ciò è particolarmente prezioso per Tipo 2 dimensione a cambiamento lento (SCD) e il periodo di tempo in cui si accumulano i fatti delle istantanee. Combinando queste tabelle Redshift con le tabelle del catalogo dati AWS Glue del sistema di origine dell'EDL all'interno delle pipeline PySpark di produzione, il connettore consente un'integrazione perfetta dei dati provenienti da più origini mantenendo l'integrità dei dati.
- Query Redshift ottimizzate – L'integrazione di Amazon Redshift per Apache Spark svolge un ruolo cruciale nella conversione del piano di query Spark in una query Redshift ottimizzata. Questo processo di conversione semplifica l'esperienza di sviluppo per il team di prodotto aderendo al principio della località dei dati. Le query ottimizzate utilizzano le funzionalità e le ottimizzazioni delle prestazioni di Amazon Redshift, garantendo un recupero e un'elaborazione efficienti dei dati da Amazon Redshift per le pipeline PySpark. Ciò aiuta a semplificare il processo di sviluppo migliorando al tempo stesso le prestazioni complessive delle operazioni di sourcing dei dati.
Ottenere la migliore prestazione
L'integrazione Amazon Redshift per Apache Spark applica automaticamente predicati e query pushdown per ottimizzare le prestazioni. Puoi ottenere miglioramenti delle prestazioni utilizzando il formato Parquet predefinito utilizzato per lo scarico con questa integrazione.
Per ulteriori dettagli ed esempi di codice, fare riferimento a Novità: integrazione di Amazon Redshift con Apache Spark.
Vantaggi della soluzione
L'adozione dell'integrazione ha prodotto numerosi vantaggi significativi per il team:
- Maggiore produttività degli sviluppatori – L'interfaccia PySpark fornita dall'integrazione ha aumentato la produttività degli sviluppatori di un fattore 10, consentendo un'interazione più fluida con Amazon Redshift.
- Eliminazione della duplicazione dei dati – Le tabelle Redshift duplicate e catalogate da AWS Glue nel data Lake sono state eliminate, con il risultato di un ambiente dati più snello.
- Carico EDW ridotto – L’integrazione ha facilitato lo scarico selettivo dei dati, riducendo al minimo il carico sull’EDW estraendo solo i dati necessari.
Utilizzando l'integrazione Amazon Redshift per Apache Spark, Capitec ha aperto la strada a una migliore elaborazione dei dati, una maggiore produttività e un ecosistema di progettazione delle funzionalità più efficiente.
Conclusione
In questo post, abbiamo discusso di come il team Capitec ha implementato con successo l'integrazione Apache Spark Amazon Redshift per Apache Spark per semplificare i flussi di lavoro di calcolo delle funzionalità. Hanno sottolineato l’importanza di utilizzare pipeline di dati PySpark decentralizzate e modulari per creare funzionalità di modelli predittivi.
Attualmente, l'integrazione di Amazon Redshift per Apache Spark è utilizzata da 7 pipeline di dati di produzione e 20 pipeline di sviluppo, dimostrando la sua efficacia all'interno dell'ambiente Capitec.
Guardando al futuro, il team Feature Platform dei servizi condivisi di Capitec prevede di espandere l'adozione dell'integrazione Amazon Redshift per Apache Spark in diverse aree di business, con l'obiettivo di migliorare ulteriormente le capacità di elaborazione dei dati e promuovere pratiche efficienti di ingegneria delle funzionalità.
Per ulteriori informazioni sull'utilizzo dell'integrazione Amazon Redshift per Apache Spark, fare riferimento alle seguenti risorse:
Informazioni sugli autori
 Preshen Goobiah è Lead Machine Learning Engineer per la Feature Platform di Capitec. Si concentra sulla progettazione e realizzazione di componenti Feature Store per uso aziendale. Nel tempo libero gli piace leggere e viaggiare.
Preshen Goobiah è Lead Machine Learning Engineer per la Feature Platform di Capitec. Si concentra sulla progettazione e realizzazione di componenti Feature Store per uso aziendale. Nel tempo libero gli piace leggere e viaggiare.
 Giovanni Olivier è un ingegnere senior di machine learning per la piattaforma modello di Capitec. È un imprenditore e un appassionato di problem solving. Gli piace la musica e socializzare nel tempo libero.
Giovanni Olivier è un ingegnere senior di machine learning per la piattaforma modello di Capitec. È un imprenditore e un appassionato di problem solving. Gli piace la musica e socializzare nel tempo libero.
 Sudipta Bagchi è un Senior Specialist Solutions Architect presso Amazon Web Services. Ha oltre 12 anni di esperienza nel campo dei dati e dell'analisi e aiuta i clienti a progettare e realizzare soluzioni di analisi scalabili e ad alte prestazioni. Fuori dal lavoro ama correre, viaggiare e giocare a cricket. Connettiti con lui su LinkedIn.
Sudipta Bagchi è un Senior Specialist Solutions Architect presso Amazon Web Services. Ha oltre 12 anni di esperienza nel campo dei dati e dell'analisi e aiuta i clienti a progettare e realizzare soluzioni di analisi scalabili e ad alte prestazioni. Fuori dal lavoro ama correre, viaggiare e giocare a cricket. Connettiti con lui su LinkedIn.
 Syed Humair è un Senior Analytics Specialist Solutions Architect presso Amazon Web Services (AWS). Ha oltre 17 anni di esperienza nell'architettura aziendale concentrandosi su dati e AI/ML, aiutando i clienti AWS a livello globale a soddisfare i propri requisiti tecnici e aziendali. Puoi connetterti con lui su LinkedIn.
Syed Humair è un Senior Analytics Specialist Solutions Architect presso Amazon Web Services (AWS). Ha oltre 17 anni di esperienza nell'architettura aziendale concentrandosi su dati e AI/ML, aiutando i clienti AWS a livello globale a soddisfare i propri requisiti tecnici e aziendali. Puoi connetterti con lui su LinkedIn.
 Vuyisa Maswana è Senior Solutions Architect presso AWS, con sede a Città del Capo. Vuyisa è fortemente impegnata ad aiutare i clienti a creare soluzioni tecniche per risolvere i problemi aziendali. Supporta Capitec nel suo viaggio in AWS dal 2019.
Vuyisa Maswana è Senior Solutions Architect presso AWS, con sede a Città del Capo. Vuyisa è fortemente impegnata ad aiutare i clienti a creare soluzioni tecniche per risolvere i problemi aziendali. Supporta Capitec nel suo viaggio in AWS dal 2019.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/simplifying-data-processing-at-capitec-with-amazon-redshift-integration-for-apache-spark/
- :ha
- :È
- $ SU
- 06
- 1
- 10
- 100
- 12
- 16
- 17
- 19
- 20
- 2019
- 30
- 7
- a
- capace
- accesso
- accessibile
- compiuto
- operanti in
- aggiuntivo
- Informazioni aggiuntive
- Inoltre
- indirizzo
- indirizzi
- aderendo
- Adozione
- conveniente
- AI / ML
- Mirare
- mira
- Consentire
- consente
- anche
- Amazon
- Amazon Web Services
- Amazon Web Services (AWS)
- tra
- an
- analitica
- ed
- Apache
- Apache Spark
- Applicazioni
- applicazioni
- si applica
- approccio
- architettura
- SONO
- aree
- AS
- At
- automatizzare
- automaticamente
- AWS
- Colla AWS
- Banca
- Settore bancario
- basato
- perché
- comportamento
- beneficio
- vantaggi
- MIGLIORE
- Meglio
- fra
- Maggiore
- Amplificato
- entrambi
- più ampia
- costruire
- Costruzione
- costruito
- affari
- by
- Materiale
- funzionalità
- mantellina
- carta
- catalogo
- cambiando
- cliente
- clienti
- Cluster
- CO
- codice
- Colonna
- colonne
- combinando
- complesso
- componenti
- calcolo
- Connettiti
- veloce
- coerente
- contiene
- contesto
- Conversione
- conversione
- creare
- Creazione
- Credenziali
- credito
- carta di credito
- cricket
- cruciale
- costume
- Clienti
- alle lezioni
- dati
- Lago di dati
- elaborazione dati
- data warehouse
- dataset
- decentrata
- Predefinito
- definito
- dimostrare
- Design
- progettazione
- dettagli
- sviluppare
- Costruttori
- sviluppatori
- Mercato
- diverso
- Dimensioni
- dimensioni
- discutere
- discusso
- distribuito
- paesaggio differenziato
- facilmente
- ecosistema
- in maniera efficace
- efficacia
- efficienza
- efficiente
- senza sforzo
- eliminato
- sottolineato
- Abilita
- consentendo
- ingegnere
- Ingegneria
- Ingegneri
- accrescere
- migliorando
- arricchito
- arricchendo
- garantire
- assicurando
- Impresa
- appassionato
- Imprenditore
- Ambiente
- essential
- Etere (ETH)
- esistente
- Espandere
- espande
- esperienza
- facilitare
- facilitato
- fatto
- fattore
- fatti
- FAST
- caratteristica
- Caratteristiche
- Compila il
- finanziario
- servizi finanziari
- trova
- Focus
- concentrato
- messa a fuoco
- i seguenti
- Nel
- formato
- Avanti
- frequente
- da
- funzioni
- ulteriormente
- Guadagno
- ELETTRICA
- ottenere
- GitHub
- Globalmente
- Manovrabilità
- Avere
- he
- Aiuto
- aiutare
- aiuta
- lui
- il suo
- Come
- HTML
- http
- HTTPS
- IAM
- Identificazione
- Identità
- realizzare
- implementato
- importare
- importanza
- migliorata
- miglioramenti
- in
- incluso
- inclusi
- è aumentato
- informazioni
- integrare
- integrazione
- interezza
- interazione
- Interfaccia
- interno
- ai miglioramenti
- sicurezza
- IT
- SUO
- Java
- Lavoro
- join
- congiunto
- viaggio
- lago
- Le Lingue
- grandi
- larga scala
- portare
- apprendimento
- a sinistra
- biblioteche
- Biblioteca
- piace
- vivere
- caricare
- prestito
- posizioni
- ama
- macchina
- machine learning
- mantenimento
- manutenzione
- Fare
- modo
- manualmente
- meccanismo
- meccanismi di
- milione
- minimizzando
- verbale
- ML
- modello
- modelli
- componibile
- monitoraggio
- mensile
- Scopri di più
- più efficiente
- multiplo
- Musica
- necessaria
- of
- Offerte
- Oliva
- on
- esclusivamente
- aprire
- open source
- Operazioni
- ottimale
- OTTIMIZZA
- ottimizzati
- minimo
- al di fuori
- ancora
- complessivo
- panda
- particolarmente
- Password
- per
- performance
- piano
- piani
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- Giocare
- gioco
- gioca
- Popolare
- posto
- possibilità
- Post
- pratiche
- predittiva
- precedente
- principio
- Problema
- problem-solving
- problemi
- processi
- lavorazione
- Prodotto
- Produzione
- della produttività
- promuoverlo
- fornire
- purché
- Python
- query
- rapidamente
- R
- gamma
- Leggi
- Lettura
- tempo reale
- record
- record
- ricorrenti
- Ridotto
- riferimento
- problemi di
- Rinomato
- richiedere
- necessario
- Requisiti
- risolvere
- Risorse
- colpevole
- risultante
- nello specifico retail
- Retail Banking
- Ruolo
- Correre
- running
- stipendio
- SC
- Scala
- scalabile
- portata
- sdk
- senza soluzione di continuità
- senza soluzione di continuità
- segreti
- Sezione
- vedere
- selezionato
- Selezione
- selettivo
- anziano
- Servizi
- Set
- alcuni
- condiviso
- vetrina
- significativa
- Un'espansione
- semplificare
- semplificando
- da
- Lentamente
- più liscia
- Istantanea
- So
- socializzare
- soluzione
- Soluzioni
- RISOLVERE
- risolve
- Fonte
- fonti
- Reperimento
- Sud
- Scintilla
- specialista
- esaurito
- SQL
- iniziato
- Passi
- conservazione
- memorizzati
- snellire
- aerodinamico
- Corda
- forte
- presentata
- di successo
- Con successo
- supportato
- supporti
- sistema
- tavolo
- team
- Consulenza
- temporaneo
- Testing
- che
- Il
- L’ORIGINE
- loro
- Li
- poi
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- Attraverso
- tempo
- a
- insieme
- strumenti
- città
- transazionale
- Di viaggio
- URL
- uso
- utilizzato
- utilizzando
- utilità
- utilizzati
- Utilizzando
- Prezioso
- via
- Magazzino
- Prima
- Modo..
- we
- sito web
- servizi web
- sono stati
- while
- con
- entro
- Lavora
- lavorare insieme
- flusso di lavoro
- flussi di lavoro
- lavoro
- scrivere
- anni
- dato
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro
- zero